基于機器學習的垃圾短信識別應用
2020-04-08 09:30:50石鳳貴
電腦知識與技術 2020年3期
關鍵詞:機器學習
石鳳貴


摘要:隨著科技的快速發展,手持終端已成為我們日常生活和工作中不可或缺的一部分。信息技術正在不斷改變我們的工作和生活,但信息安全問題也給我們的信息和財產安全帶來了威脅,垃圾短信層出不窮。對于垃圾短信,應該構建一種智能化的攔截和過濾機制進行自動識別處理。本文介紹了機器學習算法和中文信息處理技術并構建了短信識別應用。
關鍵詞:機器學習;樸素貝葉斯;Scikit-Leam;垃圾短信
中圖分類號:TP181
文獻標識碼:A
文章編號:1009-3044(2020)03-0202-03
當前,信息技術正處于高速發展階段,各類詐騙電話、詐騙短信、垃圾短信層出不窮,這些垃圾類短信直接威脅到人們的日常生活和工作,稍有不慎就會導致經濟損失。對于對這些垃圾信息識別能力較差的人群更容易上當受騙。盡管現在出現了各類垃圾短信識別軟件,但對信息不能進行個性化攔截,大多還是依賴于黑白名單,識別攔截垃圾短信需要更加智能化。
短信內容屬于中文本數據,對垃圾短信應采用文本處理和分類技術進行文本挖掘。機器學習是一門多領域交叉學科,主要涉及概率與統計、計算機算法等,研究計算機模擬人類學習獲取新知識和技能,改進知識結構和性能。機器學習是人工智能的核心,人工智能通過機器學習得意實現。機器學習的研究主要包括決策樹、隨機森林、人工神經網絡、貝葉斯、支持向量機等。
本文介紹了使用機器學習方法來智能化識別垃圾短信,包括樸素貝葉斯算法、Sciki-Learn機器學習算法庫、TF-IDF、分類模型構建及測試評估。
1 機器學習
機器學習是計算機科學與人工智能的重要分支領域。計算機通過“數據”學習,“數據”相當于人的經驗,通過學習這些經驗數據生成一個算法模型,對于新的數據可以利用生成的模型進行判斷,這就是機器學習。機器學習就是從數據中產生模型的算法。數據集中的每條記錄是對一個事件或對象的描述,稱為樣本。從數據中獲得模型的過程稱為訓練即學習,這個過程中使用的數據稱為訓練數據。模型有時也稱為學習器,
機器學習過程如圖1所示。
Python Scikit-Leam庫封裝了多種機器學習算法,提供各種機器學習算法接口,可以讓用戶簡單、高效地進行數據挖掘和數據分析。本文使用Scikit-Learn進行垃圾短信文本數據分析。
2 樸素貝葉斯算法
樸素貝葉斯算法是一種分類算法,用于構建分類模型即分類器,允許使用概率給出一組特征來預測一個類,需要的訓練比較少。樸素貝葉斯是一種運用廣泛,分類效果比較突出的分類方法,特別是在處理文本分類任務,是一種分類效果比較好的方法。
3.1貝葉斯定理
3 相關關鍵技術
3.1 中文分詞
中文語句結構復雜,語句中詞語沒有明顯的分隔符號。詞是構成中文語句的基本單元,詞語之間緊密連接在一起組成語句。因此,理解語句需要先理解詞語,分詞質量的高低直接影響文本分詞效果。目前,中文分詞技術不斷完善,主要的分詞工具有NLPIR (Natural Language Processing&Information Re-trieval)、THULAC f THU LexicalAnalvzer for Chinese)、jieba分詞和Snow NLP等分詞器[2]。使用時,根據項目應用場景選用合適的中文分詞器。
文本的分類,基本上是基于詞袋模型,也就是一個文本中包含多少詞以及各個詞的頻率。對于英文,其天生的句子空格可以很容易分割單詞。但是中文就得先進行分詞處理,也就是將一個完整的中文分割為一個一個詞。Python提供了第三方模塊-jieba分詞來對中文進行分詞。
jieba中文分詞基于前綴詞典實現高效詞圖掃描,對句子中所有可能生成詞情況構成有向無環圖(DAG),采用動態查找最大概率路徑,切分出基于詞頻的最大切分組合。對于未登陸詞,采用漢字成詞HMM模型即隱馬爾科夫模型。對于停用詞,可以自定義。jieba分詞器被廣泛應用在中文分詞,用Python語言開發的開源免費分詞工具,同時根據文本內容可以自定義詞典和修改詞典。因此,本文采用jieba中文分詞器對短信內容進行分詞。
3.2 特征提取
特征數據表示輸入的數據,目標數據則是輸入數據的屬性,本文中,短信內容就是特征數據,短信的分類就是目標數據。本文使用機器學習Scikit-Leam算法庫實現應用。從文本中提取特征,需要利用到Scikit-Learn中的CountVectorizer0方法和TfidfTransformer0方法。CountVectorizer0用于將文本從標量轉換為向量,Tfidfl ransformer0則將向量文本轉換為tf-idf矩陣。
3.3 TF-IDF
TF-IDF(Term Frequency - Inverse Document Frequency)為“詞頻一逆文本頻率”,包括TF和IDF兩部分。TF為“詞頻”即文本中詞的出現頻率統計,作為文本特征。IDF為“逆文本頻率”,反應一個詞在所有文檔中出現的頻率。如果一個詞在多個文本中出現,則IDF值低;如果一個詞在較少的文本中出現,則IDF值高;如果一個詞在所有文本中均出現,則IDF值為0。IDF基本計算公式如公式10所示,N表示語料庫中文本數,Ⅳ(x)表示其中包含詞x的文本數:
4 應用實現
4.1 對短信內容進行分詞
jieba中文分詞支持三種模式[3]:
1)全模式
seg_list= jieba.cut(”我來到北京清華大學”,cut_aIl=True)
print(”全模式:”+”/¨.join(seg_list》
分詞結果:我/來到/北京/清華/清華大學/華大/大學
2)精確模式
seg_list= jieba.cut(”我來到北京清華大學”,cut_aIl=False)
print(”精準模式:”+”/”.join(seg_list》
分詞結果:我/來到/北京/清華大學
默認模式是精確模式
3)搜索引擎模式
seg_list= jieba. cut_for_search('小明碩士畢業于中國科學院計算所,后在日本京都大學深造”)
print(”,”.join(seg_list》
分詞結果:小明,碩士,畢業,于,中國,科學,學院,科學院,中國科學院,計算,計算所,后,在,日本,京都,大學,日本京都大學,深造
本文分詞模式采用默認,語料中增加一列存放分詞結果:
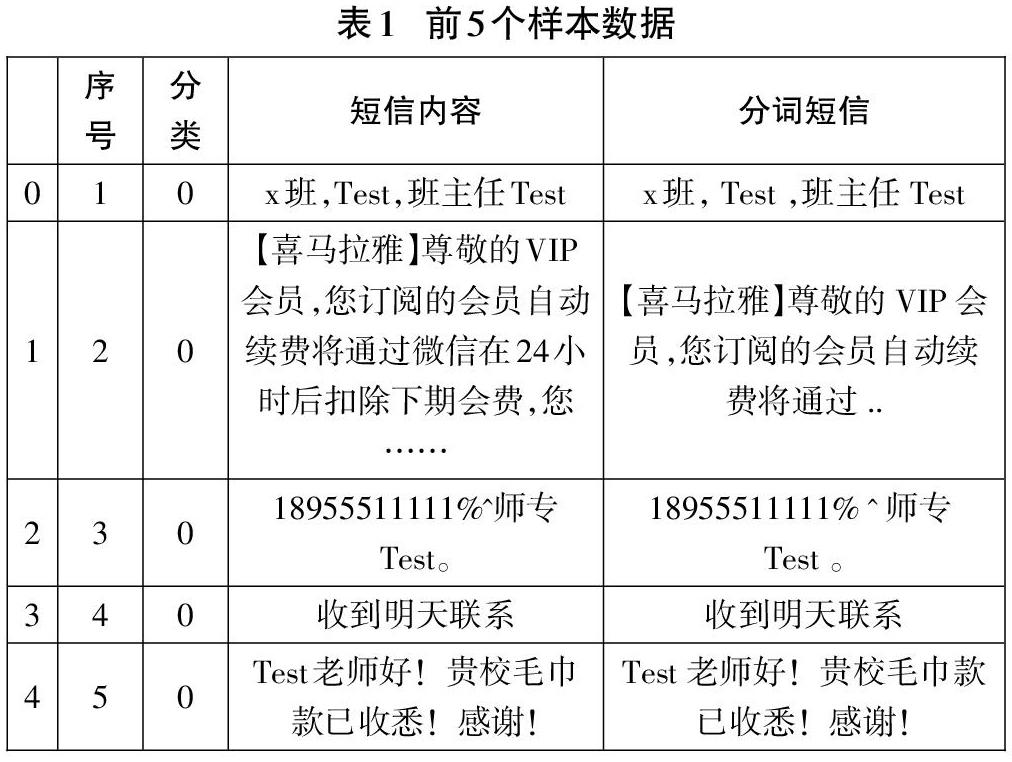
data= pd.read_csv(r”./data/rubmessage. csv”, encoding= 'utf_8,sep=,,)#導入短信數據
data[,分詞短信]-data[,短信內容].apply(lambda x:””.join(jieba.cut(x》)
data.head0#顯示前5個樣本
4.2 特征提取及分割數據集
特征數據表示輸入的數據,目標數據則是輸入數據的屬性。短信內容就是特征數據,短信的分類就是目標數據。代碼如下:
x= data[”分詞短信”].values
y= data[,分類,].values
使用skleam的分割模塊分割出訓練集和測試集,直接使用train_test_split0:
x_train, x_test. y_train. y_test=train_test_split(x,y,test_size=0.11
4.3 文本特征數字化
from sklearn. feature_extraction. text import TfidfTransformer,CountVectorizer
#定義向量轉換器和TF-IDF轉換器
vectorizer= CountVectorizer0
tfidf_transformer= TfidfTransformer0
#訓練集數字化
x_train_termcounts= vectorizer.fit_transform(x_train)
x_train_tfidf
=
tfidf_ transformer.fit_transform(x_train_termcounts)
#測試集數字化
x—test termcounts= vectorizer.transform(x_test)
x_test_tfidf= tfidf_transformer.transform(x_test_termcounts)
4.4 模型構建、測試及評估
1)構建樸素貝葉斯分類模型并訓練
from sklearn.naive_bayes import MultinomialNB
classifier= MultinomialNB O.fit(x_train_tfidf, y_train)
2)測試模型
predicted_categories= classifier.predict(x_test_tfidf)
print(predicted_categories)
結果:
[0 00001000000000000000000100000000 0 0 0000000 0 0 0 0 0 000000 0 0 0 1 0 0000000 0 00 0]
3)評估模型
from sklearn.metrics import accuracy_score print(”準確率:”,accuracy_score(y_test,predicted_c ategories》
評估結果:
準確率:0.9420289855072463
參考文獻:
[1]劉秋陽,林澤鋒,欒青青.基于樸素貝葉斯算法的垃圾短信智能識別系統[J].電腦知識與技術,2016,12(12):190-192.
[2]賴文輝,喬宇鵬.基于詞向量和卷積神經網絡的垃圾短信識別方法[J].計算機應用,2018,38(9):2469-2476.
[3]結巴中文分詞[EB/OL].https://github.com/fxsjy/jieba.
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
