基于虛擬網格存儲動態執行過程的研究
2020-04-25 10:59:06崔蓓蓓姜麗
信陽農林學院學報 2020年1期
關鍵詞:資源
崔蓓蓓,姜麗
(1.徽商職業學院 電子信息系,安徽 合肥 230001;2.國防科技大學 電子對抗學院,安徽 合肥 230000)
非結構化數據快速發展,存儲壓力進一步增大,而在云計算的環境中,存儲的分布式,網絡環境的虛擬化,使存儲資源進一步池化。如何減少存儲碎片化,提高云環境下存儲效率是本文考慮的重點,“存儲網格”是國際上提出的全新概念。
計算與存儲在過去30年中一直未能同步發展,回顧其發展歷程,處理器和網絡帶寬分別提升了3000倍和1000倍,而磁盤和內存帶寬僅提升120倍,落后于摩爾定律[1]。阿姆達爾定律認為,系統中最慢部分存儲的效率決定整個系統的效率。2012 年全球信息數據達到 2.1ZB(1ZB= 240GB)[2]。估計到 2020 年,全球總的數據量將達到35ZB,為了提升資源的利用效率,最終導致計算、存儲架構的分離,訪問控制技術朝著細化粒度、多級層次的方向發展,存儲虛擬化(storage virtualization)屏蔽物理層,實現物理存儲的邏輯化,提高了存儲效率,存儲網格式是在存儲虛擬化之上提出的新概念。存儲網格式在虛擬化[3]環境下解決了跨域的分散存儲,然而虛擬網格式存儲又給數據的容災備份和尋址帶來挑戰,本文在考慮通過低顆粒度存儲的同時,通過Erasure Code編碼的動態網格存儲技術,研究通過DHT尋址、從而提高虛擬存儲效率。
1 虛擬存儲模型
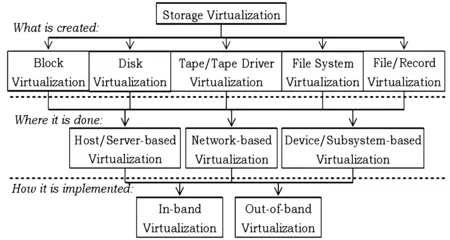
圖1 SNIA存儲虛擬技術的分類圖
虛擬化發展歷經了三個主要階段,從基于主機的虛擬化、基于設備的虛擬化到目前基于網絡的虛擬存儲。網絡虛擬存儲可以整合多個存儲子系統,目前的網絡存儲技術(Network Storage Technologies)大致分為三種:直連式存儲(DAS:Direct Attached Storage)、網絡存儲設備 (NAS:Network Attached Storage)和存儲網絡(SAN:Storage Area Network)[4]。現在借用SNIA(存儲網絡工業協會)的分類方法,來觀察網絡虛擬化存儲和系統資源的關系。圖1為SNIA虛擬化存儲層次圖。
虛擬存儲系統將各類存儲資源進行整合,形成一個統一的資源管理池,提高資源的利用率,解決非結構化數據快速增長與存儲力相對不足的矛盾。在虛擬管理模塊中,根據數據通道管理位置,分為帶內(In-Band)和帶外(Out-of-Band)管理[5]兩部分,屏蔽物理位置限制,形成一個大的“存儲池”,為網格存儲提供了資源依據,而采用Erasure code保證數據訪問的安全性,對于存儲資源的尋址采用負載均衡使用哈希數據路由[6]提高尋址效率。
2 Storage Grid用戶態的數據模型
Storage GRID存儲和管理大規模非結構化數據的下一代對象存儲,2017年NetApp推出了NetApp Storage GRID Webscale將存儲網格推向新的高度,NetApp在用戶端與SAN之間添加中繼層,擴展存儲網格。然而學術界尚未對網格存儲引起足夠重視,存儲網格為公有云提供了共享數據,分散用戶對數據的頻繁換進和換出,處理器以block塊為調度單位的顆粒度的較大,進一步細分Data Blocks,提供顆粒度更細的內容存儲,提高存儲資源的利用效率[7],圖2為DataBlocks數據結構圖。
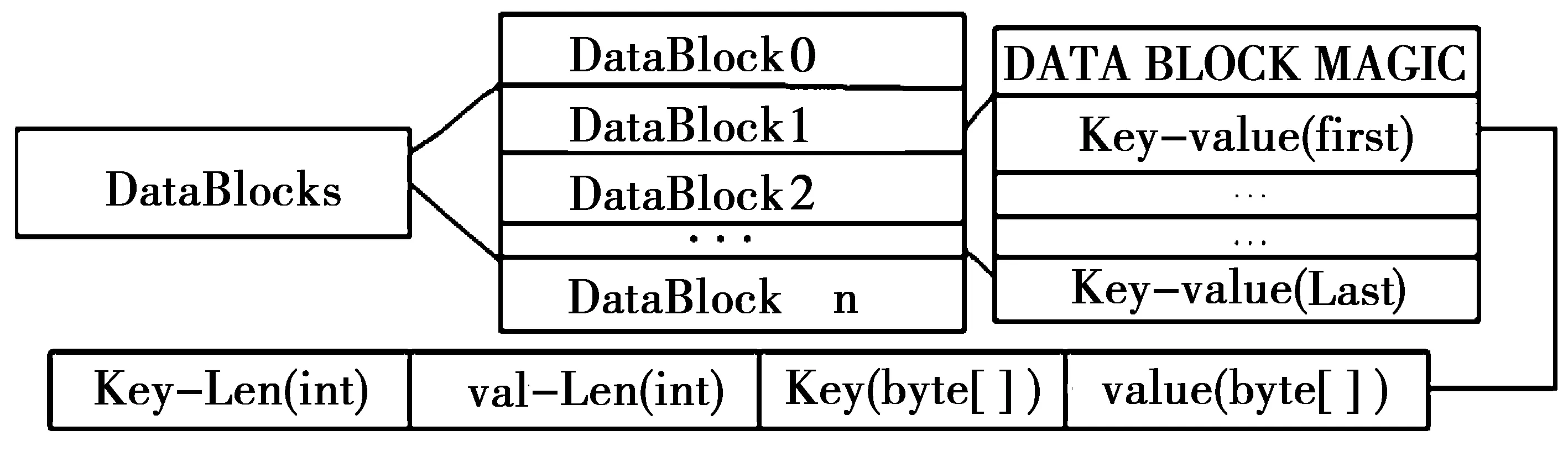
圖2 DataBlocks數據結構
將分散的DataBlocks定義為D={D1,D2,L,Dn},其中n表示 DataBlocks的數目,其資源在虛擬機的位置集合V={V1,V2,L,Vm},m表示虛擬機的總數。物理機上虛擬機位置向量為H={hi1,hi2,L,Dim},當系統調用存儲資源時,需要消耗cpu、內存、網絡帶寬和存儲用向量Pi=(SCi,SMi,SNi,SHi)表示,相應的虛擬機的系統態資源GridTablei=(sci,smi,sni,shi)。F=min(Pused),物理資源使用越少,資源利用率越高。
在進程調度過程中,用戶態下對資源的動態訪問的數據模型,可以定義為:GridTable[j]=(storage[j],active[j],domain[j],MaxOline[j])。
storage[j]是指第j個虛擬主機存儲云的存儲能力指數,單位為字節;
active[j],表示第j個虛擬機是否占用活動的資源;
domain[j],表示第j個虛擬機在虛擬云中區域范圍;
oline[j],表示第j個虛擬主機存儲云在線連接數;
MaxOline[j],表示第j個虛擬機能夠分配的最大在線連接數。
存儲節點存放Data Blocks文件,Storage Grid 根據這些信息執行數據管理,Grid主要從解決存儲資源的數量級的角度出發。Grid在使存儲的顆粒度變小的同時,考慮虛擬主機動態執行過程,將 blocks 塊進行網格式劃分,并將Storage Grid的動態化執行過程用簡單的算法模型表示,在網格存儲的顆粒度研究上具有一定的積極意義。
3 Erasure code 的數據冗余機制
3.1 Erasure code的編碼
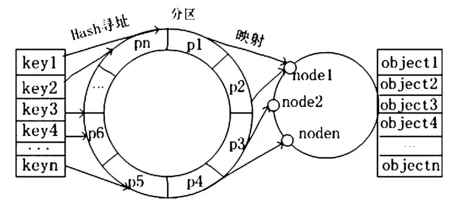
多資源池的數據同步訪問,需要跨站點的數據同步能力,在保持隨時隨地訪問數據能力的同時,要保持數據訪問的安全性,如何利用有限的存儲資源滿足迅速膨脹的存儲需求成為一個巨大挑戰。采用多副本策略在滿足存儲可靠、優化數據讀寫性能的同時可能造成資源利用率低的缺陷。Erasure code編碼的存儲策略可以提高存儲資源的利用效率。Erasure Code(N+M)的數據方式進行數據冗余保護,有效地提網格的利用效率,如果客戶端需要N個DataBlack,進行冗余校驗時需要M個校驗塊,其空間利用率為N/(M+N)。如果有任意小于M的數據失效,仍然能通過剩下的數據還原出來。也就是說,通常N+M的erasure編碼,能容M塊數據故障的場景,這時候的存儲成本是1+M/N,通常M Erasure Code對N個Data blocks原始數據塊進行編碼,編碼后產生M個數據塊(M>N),從編碼后的M個數據塊進行解碼還原出原始數據塊,而部分存儲的損失,不影響數據的恢復[9]。根據圖3可知,如n2、n4、n6出現存儲故障,系統態會從其他節點或硬盤把n2、n4、n6數據進行重建出來,n1、n3、n5、m1、m2、m3為一個EC條帶,當校驗塊增大時,開銷增大,圖3為DataBlack的Erasure Code冗余備份圖。 圖3 N+M的Erasure Code冗余 Erasure code編碼解決了存儲的穩定性,提高了空間的利用效率,但編碼、解碼尚屬于復雜的數學運算,是以犧牲一定的計算性能為代價的。目前erasure code還僅適用于對冷數據的離線處理階段,如何從根本上降低erasure code帶來的performance overhead,使得編碼存儲技術得以真正大量適用,將為大數據存儲[8]帶來不容質疑的重大意義。當前,Microsoft、Google、Facebook、Amazon、阿里巴巴等互聯網巨頭將erasure code編碼存儲技術應用于主流存儲系統中。 對存儲的研究除提高存儲效率,增加存儲的額外備份之外[9],最重要之處是保證數據的安全性,跨域的核心數據備份將能很大程度降低由于宕機而造成的數據丟失,本節通過跨域的冗余策略及DHT的尋址方式來闡述數據的完整性保護。新增或減少映射節點時盡可能少地避免原有的映射關系,使數據能均勻的分布在各個節點。我們稱這種算法為一致性Hash算法,又稱分布式哈希DHT[10]。 具體步驟為: (1)將共享存儲的數據塊用Erasure Code進行冗余編碼; (2)根據在線存儲節點的性能參數獲取存儲節點群,并將文件分布式地儲在當前域內的存儲節點中,保存文件的存儲路由表信息; (3)將文件的最低級目錄利用hash算法進行尋址。 采用DHT的方法,將物理節點node映射到2k的環狀拓撲結構上,總空間為2k-1,通過hash 圖4分布式存儲系統DHT數據路由 (node)%2k,物理節點建立了與hash環的聯系,如果在IPv4的環境下可以取k=32,node在hash環上的映射位置將表現為實際的物理地址,將存儲對象DataBlocks的數據塊以同樣的方式映射到hash環上,即hash(DataBlocks)%2k=key,這樣就建立了DataBlack和node的唯一聯系,當node的節點增加或減少時,只影響附近的一個節點,不會影響全部節點的數據。 分布式Hash技術,天然支持分布式自動精簡配置(Thin Provisioning),無須預先分配空間。由于DHT具有動態維護的特征,允許節點的自動加入或退出,在虛擬的計算環境中形成DHT的覆蓋網絡,而不考慮存儲節點的具體屬性。 存儲網格主要解決存儲資源的數量級的問題,Storage GRID 為存儲和管理大規模非結構化數據[10]的下一代對象存儲,StorageGRID 將架構在VMware虛擬機架構之上,將塊存儲以更小的網格化呈現,使算法在滿足用戶需求的前提下,提高存儲資源的利用率,減少碎片化的概率。 存儲網格主要解決了存儲資源的數量級的問題,并能提供支持多種應用,在研究過程中會遇到多應用,多站點,多種訪問協議的情況,可采用對存儲資源訪問保留策略,包括在一段時間內對放置位置、存儲級別、副本數量進行日志記錄和刪除。網格存儲采用分布式塊存儲,具有高性能,采用分布式哈希數據路由實現負載均衡,采用Erasure code對數據進行有效備份,用DHT的進行數據路由,使分布式網格存儲在虛擬化存儲的條件下具有更高的可靠性,單個物理設備的故障不影響業務使用,支持高擴展性非集中式訪問,支持平滑擴展,容量不受限制,易管理。3.2 Erasure Code的解碼
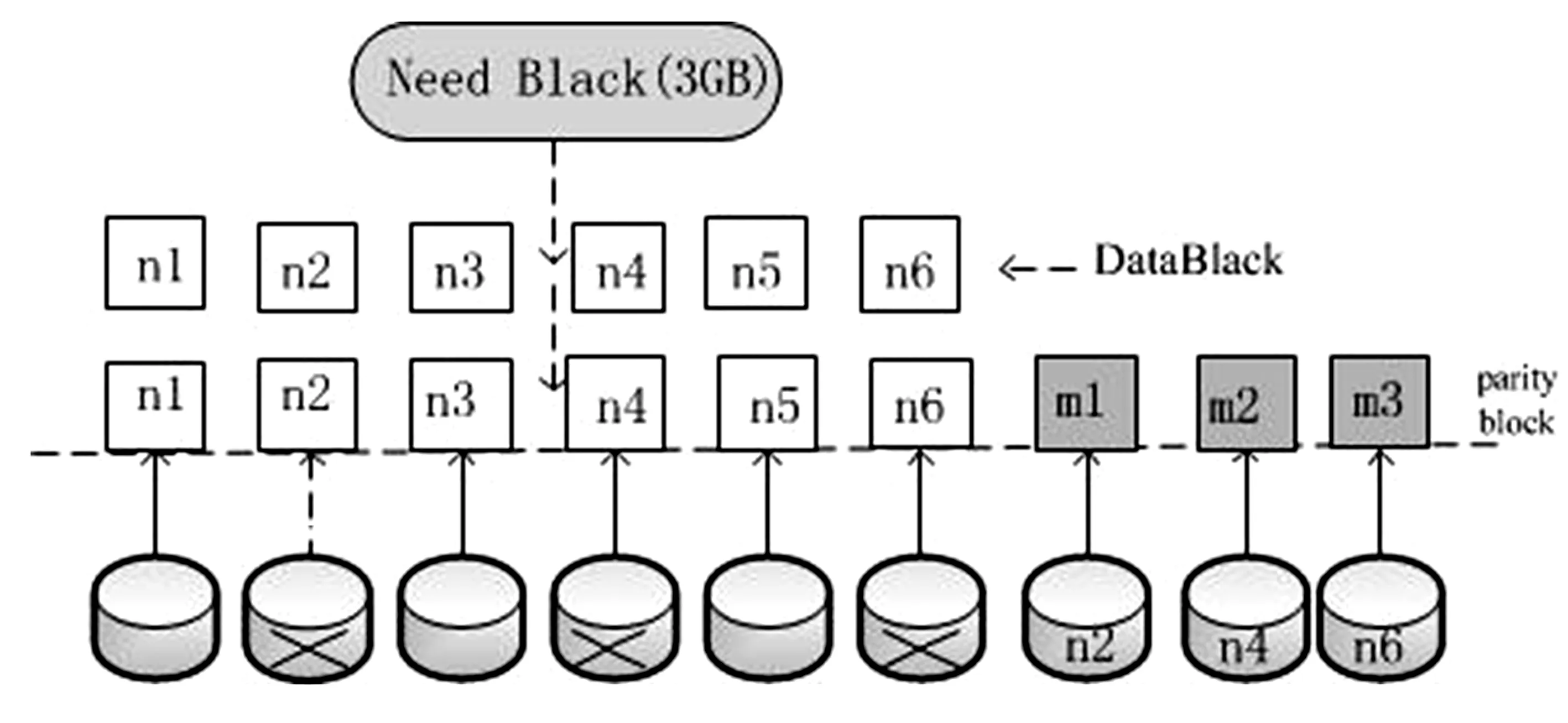
4 Erasure code 的冗余網格數據DHT尋址機制
5 結論
猜你喜歡
江蘇安全生產(2023年1期)2023-02-08 05:58:38
資源節約與環保(2022年8期)2022-09-20 02:25:22
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
藝術品鑒(2020年7期)2020-09-11 08:04:44
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
當代貴州(2018年28期)2018-09-19 06:39:04
資源再生(2017年3期)2017-06-01 12:20:59
決策(2015年9期)2015-09-10 07:22:44
