隱私保護頻繁項集挖掘中的分組隨機化模型
2020-04-30 06:25:42郭宇紅童云海
華僑大學學報(自然科學版) 2020年2期
關鍵詞:模型
郭宇紅, 童云海
(1. 國際關系學院 信息科技學院, 北京 100091;2. 北京大學 智能科學系, 北京 100871)
數據挖掘能從大量數據中發現新穎的、潛在有用的、可被用戶理解的知識,成為一種有效的分析決策手段,在企事業中得到廣泛應用.頻繁項集挖掘是數據挖掘中的一個重要分支,能從大量數據中發現有趣的關聯關系.有效的數據分析需要有大量真實的數據做基礎,而人們對數據隱私和安全問題的日益關注,使得在數據收集階段中,出于隱私的考慮,人們可能不再愿意提供真實的數據供分析使用.因此,如何在基于隱私和安全考慮的環境中,很好地實施數據挖掘任務和各種應用,是隱私保護數據挖掘要解決的問題[1-3].
隨機化[4-5]是目前隱私保護數據挖掘中運用的主要方法,基本思想是通過向原始數據中加入噪音的方式來對數據作干擾以達到隱私信息的保護,同時數據的統計性質在隨機干擾后的數據中保持不變,以獲取正確的挖掘結果,包括隨機化干擾和隨機化回答兩種模型.其中,隨機化干擾模型主要用于數值數據,通過在原始數值數據上增加隨機干擾數實現;隨機化回答模型主要用于分類數據,通過對分類屬性值在不同取值間作隨機變換實現,該模型最先由沃納提出[6],被廣泛用于敏感性問題的調查中.在隱私保護頻繁模式挖掘[7-11]、隱私保護關聯規則挖掘[12-14]的應用方面,文獻[14]通過數據干擾和支持度重構實現了隱私數據保護的關聯規則挖掘;文獻[15]對MASK(mining associations with secrecy Konstraints)算法進行了擴展,提出“特定于符號(1和0)”的隨機化過程和相應的eMASK算法;文獻[16]提出“非統一”參數的隨機化過程和相應的項集支持度遞歸估計RE(recursive estimation)算法;文獻[17]對MASK算法在支持度重構復雜度方面進行了優化,提出了mMASK算法.
上述隨機化回答模型在隱私保護頻繁項集挖掘中取得很大進展,但存在以下2點問題.1) 隨機化模型類型單一,隨機化參數調控的數據范圍寬、粒度粗,對隱私數據保護粒度的控制缺乏靈活性.2) 已有模型沒有考慮不同個體隱私保護需求的差異性,而這種需求在現實應用中是客觀存在和急需解決的.針對以上問題,本文在沃納模型、單參數等隨機化模型的基礎上,提出個體分組多參隨機化模型PN/g,并結合例子對水平分組隨機化的支持度重構方法進行了探索.
1 沃納模型
沃納模型是最初由Warner在1965年針對“吸毒問題的調查”一類敏感問題提出的,可應用于單一屬性敏感性問題的統計學調查和分析.在“吸毒問題的調查”這類問題中,調查者想要知道一定人群中吸毒者的比例,但當面對“你是否曾經吸過毒”這類敏感問題的回答時,被調查者(尤其是吸毒者)很可能不愿意回答,或者給出一個虛假的回答.針對這類問題,沃納模型給出了解決辦法.
該模型在調查中設計下面兩個對立的問題供被調查者回答:1) 你是否吸過毒;2) 你是否沒吸過毒.同時,分給每個被調查者一個隨機數生成裝置,被調查者可根據生成的隨機數的不同,選擇回答第1個問題,還是第2個問題.比如調查者可以跟被調查者事先約定:當生成的隨機數小于p時,選第1個問題回答;大于等于p時,選第2個問題回答;無論選哪個問題,都要作出真實的回答.
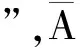
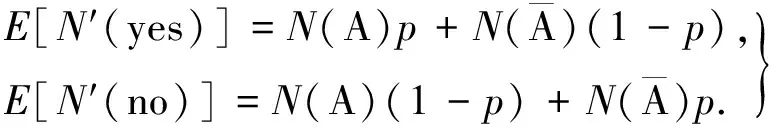
(1)
2 單參數隨機化模型
現有隱私保護數據挖掘方法所使用的隨機化回答技術,是在沃納模型的基礎上形成的.沃納模型只能用于單一敏感性問題的調查和分析,其核心思想是在保護個體數據隱私的同時,能求得單一屬性上的統計值.對于頻繁模式挖掘而言,其對應的數據通常會有多個屬性項,頻繁模式挖掘的目標則是通過對項集支持度的計算,發現在總體樣本中所占比例較高的項集(即頻繁項集).因此,對隱私保護頻繁模式挖掘,其目標是在保護個體隱私的同時,求取多屬性上的統計值——項集支持度.沃納模型中的公式只能解決隱私保護場景下1-項集支持度的計算.文獻[14]提出的MASK方法解決了隱私保護場景下k-項集的支持度計算問題,從而很好地解決了隱私保護頻繁模式挖掘問題,其原理如下.
1) 隨機化過程.假定用二維0-1矩陣表示原始事務集D,“1”和“0”分別表示對應的項出現和不出現在事務中,則單參數隨機化對于D中任意元素v∈{0,1},以p的概率取原值v,以1-p的概率取1-v,生成隨機化事務集D′.p稱作隨機化參數,p值越高,生成的D′中保留越多的原值v.
2) 支持度重構.假定A={I1,I2,…,Ik}為k-項集,A中的項可能全部或部分出現在D的事務T中.A∩T共有2k種可能的取值,每一種取值對應了A的一個子集fi(i∈{0,1,…,2k-1}),并假設在二維0-1矩陣表示D時,i的k位二進制數字恰好對應fi的從I1到Ik的k項0-1序列.即
同時,假定Cfi,Afi表示D(I1…Ik)中僅包含fi而不包含補集Afi中的任何項的事務數(fi在D(I1…Ik)中的凈計數).即D中對應A的k列0-1序列等于fi的事務數.當A在上下文中明確時,Cfi,Afi簡記為Cfi.Cf0,Cf1,…,Cf2k-1(簡記為C0,C1,…,C2k-1)構成向量CA,即CA=[C0,C1,…,C2k-1]T;相應地,C′f表示D′中僅包含f的事務數,向量C′A=[C′0,C′1,…,C′2k-1]T.則CA和C′A的期望值存在如下關系,即
E(C′A)=P·CA.
(2)
式(2)中:P=[pi,j]為隨機化概率參數p構成的2k×2k變換矩陣,pi,j表示D中僅包含fi(fi?A)的事務(即對應的從I1到Ik的k項0-1序列恰好為i的k位二進制值的事務)轉換成D′中僅包含fj(fj?A)的事務的概率.若i和j對應的k位二進制0-1串中值相同的位數為r,則pi,j=pr(1-p)k-r(0≤r≤k).為便于理解,給出單參數隨機化中3-項集的變換概率矩陣,如表1所示.
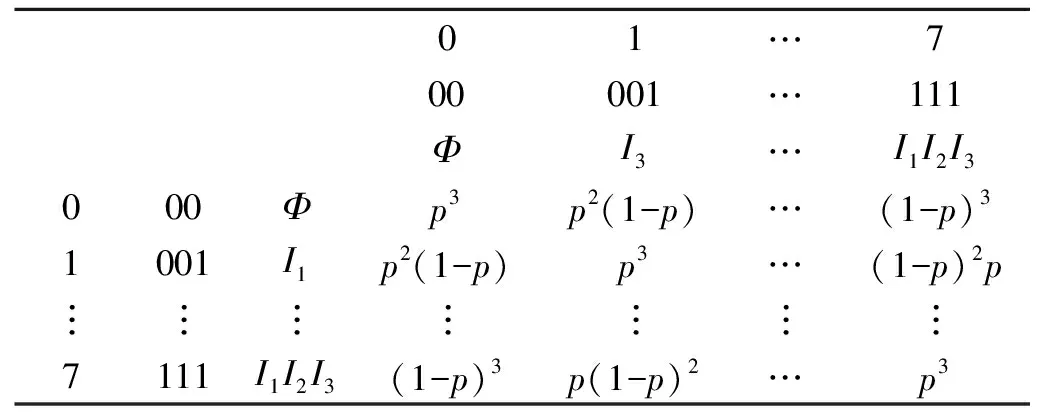
表1 單參數隨機化中3-項集的變換概率矩陣Tab.1 Transition probability matrix of 3-itemset in single-parameter randomization
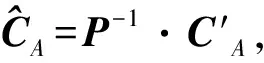
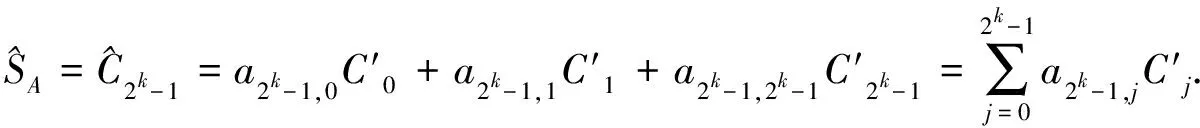
(3)
式(3)兩邊同除以事務總數∣D∣,可得MASK方法對項集A的重構支持度,即
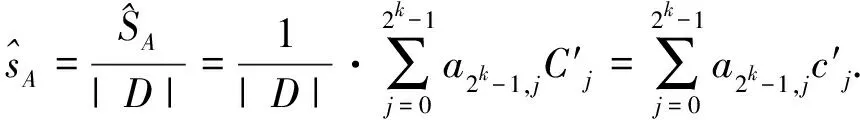
(4)
以上即為單參數隨機化MASK方法在隱私保護頻繁模式挖掘中的工作原理.該方法能保證在不訪問原始數據D的情況下,從隨機化后的數據集D′中估算出各項集的原始支持計數和支持度,從而得到頻繁項集和關聯規則挖掘結果.
單參數隨機化模型的缺點是,所有數據元素的隱私保護程度和最終挖掘結果的準確性全都受控于單一的隨機化參數p.這不僅忽視不同數據元素隱私保護需求的差異性,使隱私數據不能得到充分有效的保護,而且挖掘結果的準確性也不理想.挖掘結果受p的制約很大,p一旦確定,挖掘結果就確定,挖掘結果準確性上沒有任何可調控的余地;而同時對隱私的保護也顯得過于魯棒、不夠精準和粒度過粗.
3 分組多參隨機化PN/g模型
3.1 PN/g基本思想
不同于單參數隨機化,多參數隨機化用多個概率參數對數據隨機化.其思想是對數據中的不同元素設置不同的隱私保護級別,不同的隱私保護級別對應不同的隨機化參數,由參與調查的個體自行決定對其不同數據元素的隱私保護級別和相應的隨機化參數.參與調查的多個個體的隱私保護要求差不多,則可按個體水平分組隨機化,使同一組內共用一個隨機化參數,而每個隨機化參數控制組中的多行.假設參與調查的個體總數為N,若等分時,每組包含g行,則組數和隨機化參數個數為N/g,就形成分組多參隨機化模型.
3.2 PN/g模型舉例
為簡單起見,假定屬性取值均為布爾值“1”和“0”.由這N個個體的布爾屬性組成需要保護的、二維布爾矩陣表示的數據表D.事實上,數值類型屬性可以通過離散化轉變為多元分類屬性,即枚舉屬性,而多元分類屬性又可以轉變為布爾屬性,即一般的數據都可以轉變為二維布爾矩陣形式.
個體分組隨機化的例子,如表2所示.表2中:TID為事務標識號;左邊為原始事務集D,由10個被調查者的3個問題項(I1/I2/I3)組成,10個被調查者兩兩一組,同一組內共用同一個隨機化參數.對這五組數據分別隨機化后,生成的隨機化數據集如表2右邊3列數據所示.在表2中,由個體1和2構成的第1組數據選擇的隨機化概率參數p1=1,隨機化過程對該組數據以1的概率保持為真,以0的概率取反,得到的第1組隨機化數據完全保持不變.表明該組中的個體完全不顧及隱私,愿意完全真實地貢獻其數據.相反的,由個體9和10構成的第5組數據選擇的隨機化參數p5=0.6,隨機化過程對該組數據以0.6的概率保持為真,以0.4的概率取反,得到的第5組隨機化數據中有3個值保持不變,3個值被打亂取反.表明該組中的個體相對比較在乎隱私,只肯貢獻非常有限的數據.
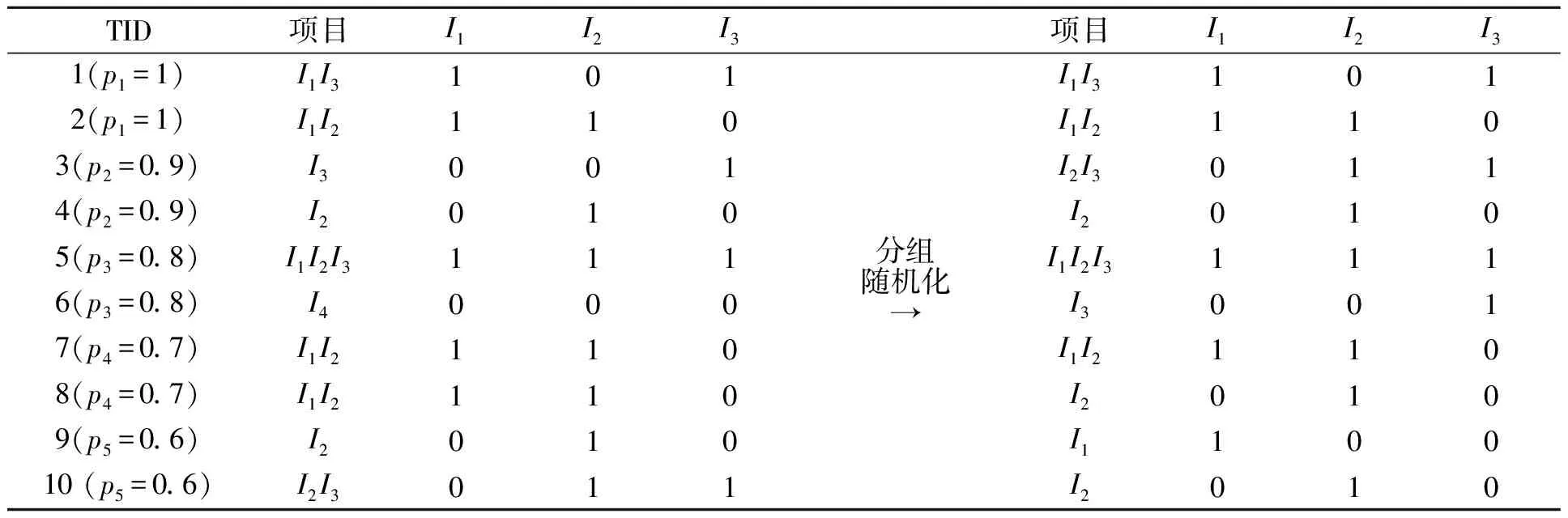
表2 數據集D分組隨機化PN/g模型Tab.2 Grouping randomization model of PN/g on dataset D
3.3 PN/g模型支持度重構
分組多參隨機化時,需要求得變換概率矩陣P和進行支持度重構.文中計算P中元素pi,j的基本思想是:D分組隨機化為D′作為整體來看時,項集fi轉變為fj的概率為各個分組將項集fi轉變為fj的概率之和.相應地,k-項集A對應的2k×2k變換概率矩陣Pk中的元素值為
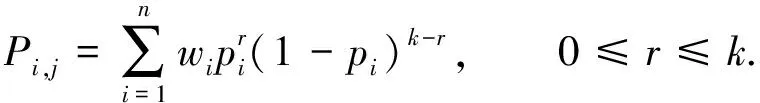
(5)
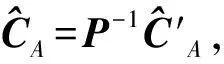
例如表2中的分組多參隨機化中,事務“000”轉變“000”的概率為
而“000”轉變為“111”(即空集轉變為事務{I1I2I3})的概率為
這樣便可得到3-項集{I1I2I3}對應的8×8變換概率矩陣P3中的所有元素.
分組隨機化PN/g模型變換概率矩陣P3,如表3所示.表3中:矩陣P3中的某一元素表示某個項集隨機化后轉變為另一個項集的概率.
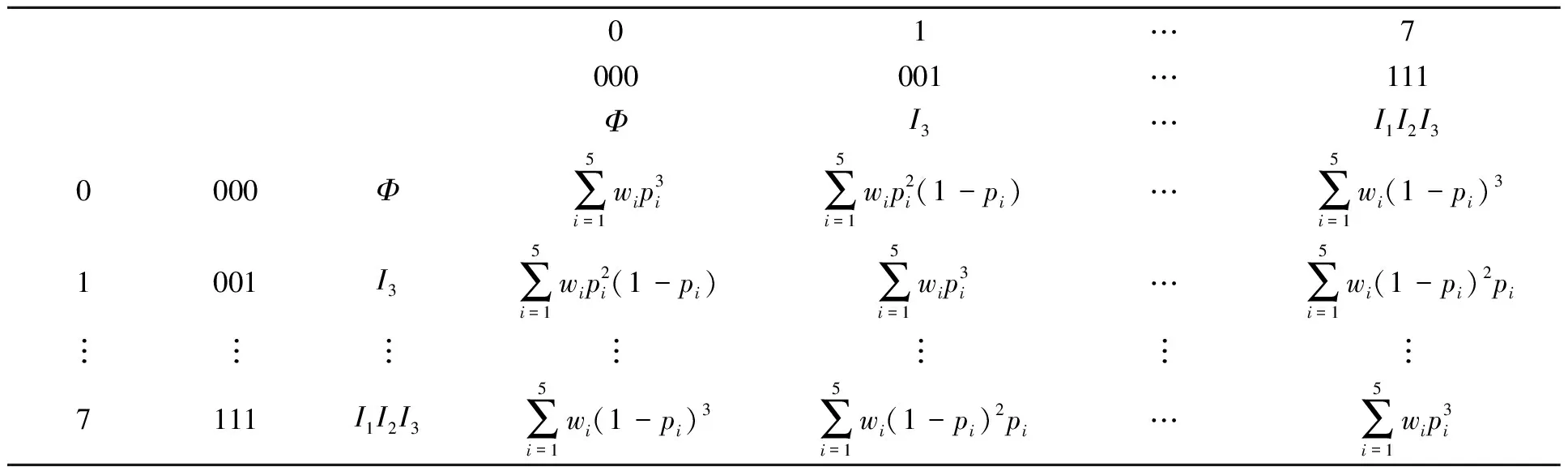
表3 分組隨機化PN/g模型變換概率矩陣P3Tab.3 Transition probability matrix P3 in grouping randomization of PN/g model
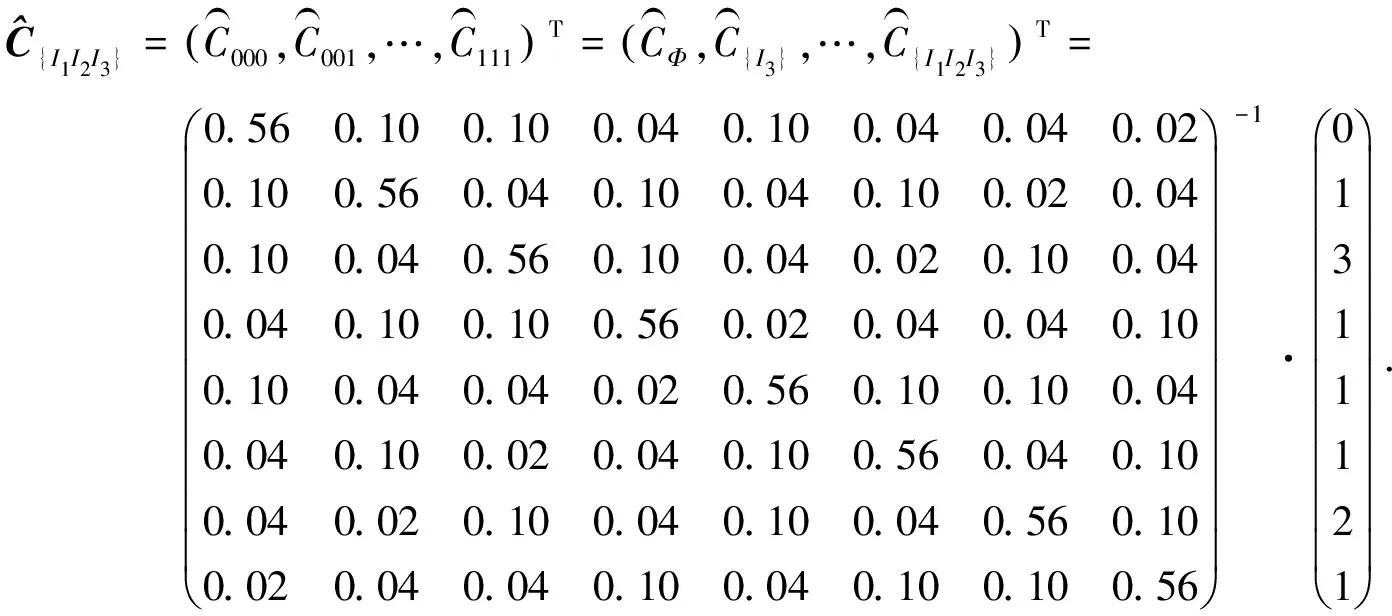
(6)
3.4 PN/g模型支持度重構示例分析
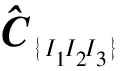
表4給出了表2數據集D對應的項集空間中,所有項集的重構支持計數和重構誤差.從表4可看出:7個項集支持計數重構總誤差為-1.92,平均每個項集的支持計數重構誤差為-0.27.即相對原數據,每個項集支持計數估計值比真實值少了0.27.該誤差較小,驗證了文中所提PN/g模型支持度重構方法的可行性和有效性.
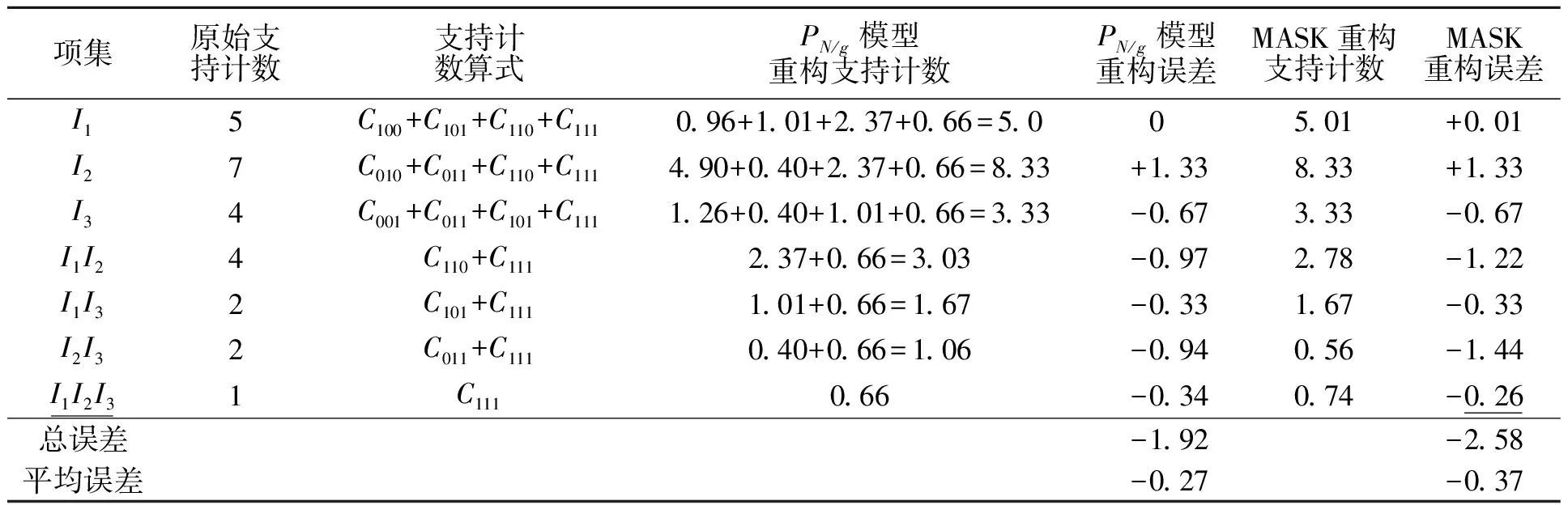
表4 PN/g和MASK支持計數重構對比Tab.4 Support count reconstruction comparison of PN/g and MASK
3.5 與MASK方法對比
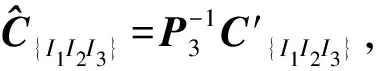
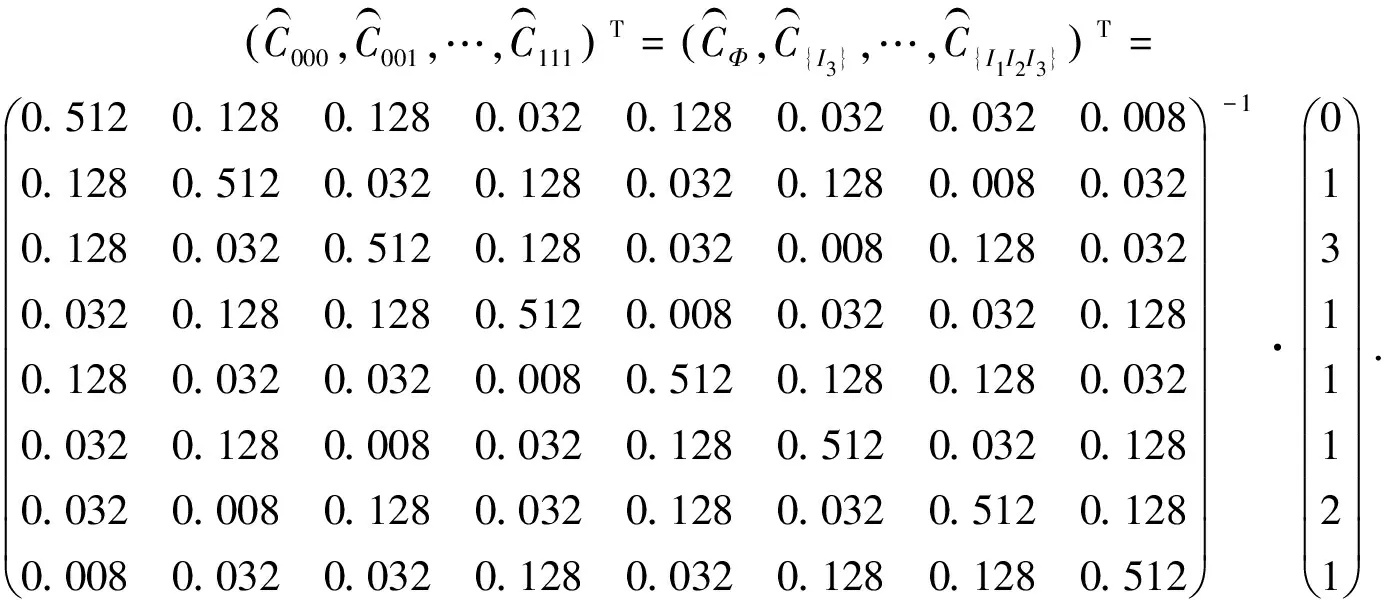
(7)
對比原始支持計數發現,相對于文中所提PN/g模型,MASK方法僅在支持計數低的項集I1I2I3上,重構支持計數誤差絕對值(0.26)更小,而在支持計數相對高的其他項集上,PN/g模型的重構誤差絕對值小于或等于MASK,這意味著對頻繁項集挖掘,PN/g模型在頻繁項集的支持度重構上將更為準確.由表4可知:整個項集空間支持計數重構的總誤差和平均誤差絕對值也小于MASK.這進一步驗證了文中所提PN/g模型用于隱私保護頻繁項集挖掘的有效性,即PN/g模型不僅能實現差異化的隱私保護,且能以小的誤差重構頻繁項集的支持度.同時,相對單參數隨機化MASK,多參數隨機化PN/g模型能在平均隱私保護度相同情況下,以更小的誤差重構頻繁項集的支持度,從而提高頻繁項集挖掘的準確性.
4 結論
針對頻繁項集挖掘中的隱私保護問題,提出個體分組多參隨機化PN/g模型,給出其在隱私保護頻繁項集挖掘中的支持度重構方法.最后,通過示例驗證了支持度重構方法的可行性和有效性.
作為個性化隱私保護挖掘的初步嘗試,還有如下一些工作需要進一步探究.1) 針對PN/g模型的支持度重構方法,理論推導出該方法所對應的支持計數重構公式和支持度重構偏差公式.2) 設計相應算法和基于大數據集進一步驗證方法的有效性,特別是挖掘結果的準確性.3) 基于新的頻繁項集挖掘算法[18],設計與之相適應的、更高效的隱私保護頻繁項集挖掘算法.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
