隨機森林模型和Logistic回歸模型在高尿酸血癥預測中的應用效果比較
2020-05-09 01:23:14梁冰倩黃志碧賴銀娟莫海娟陸華媛陳青云
廣西醫學 2020年6期
梁冰倩 黃志碧 賴銀娟 莫海娟 陸華媛 陳青云
(1 廣西醫科大學公共衛生學院, 南寧市 530021,電子郵箱:289059086@qq.com;2 廣西醫科大學第一附屬醫院體檢中心, 南寧市 530021)
高尿酸血癥是一種常見且具有廣泛危害的代謝性疾病,可引起人體多器官系統的損害,且與多種心腦血管疾病有關[1]。目前,我國高尿酸血癥患病率高達13.0%,男性和女性患病率分別為18.5%和8%,男性患病率高于女性[2]。但是,我國高尿酸血癥的知曉率、治療率都很低[3],成為嚴重影響我國人民身體健康的公共衛生問題。因此,預防和控制高尿酸血癥具有重要意義。
在醫學信息化的今天,醫療大數據內在信息價值的挖掘成為服務臨床的一門技術。機器學習技術在醫療領域應用廣泛[4],隨機森林是一種集成學習算法的機器學習之一,具有精度高、抗噪聲、不受共線影響和不存在過擬合等優點[5],在數據分析和挖掘中具有較高的應用價值,且可以很好地克服線性回歸模型存在的缺陷。本研究將數據挖掘技術引入到高尿酸血癥患病風險預測研究中,基于多因素Logistic回歸分析和隨機森林算法構建高尿酸血癥風險預測模型,為高尿酸血癥的預防控制工作提供科學依據。
1 資料與方法
1.1 臨床資料 選擇2016年9月至2017年2月期間在廣西醫科大學第一附屬醫院體檢中心進行體檢的2 754例體檢個體作為研究對象。納入標準:(1)年齡18~85歲,男女不限;(2)同意進行問卷調查并簽署知情同意。排除患有惡性腫瘤、先天性肝腎功能不全、遺傳病、傳染性疾病、藥物性疾病者。其中,男性1 044例(37.9%)、女性1 710例(62.1%);年齡20~84(52.79±11.83)歲,20~<45歲616例(22.4%)、45~<60歲1 177例(42.7%)、≥60歲961例(34.9%)。
1.2 高尿酸血癥診斷標準 根據血尿酸水平進行診斷,男性血尿酸水平>420 μmol/L,女性血尿酸水平>357 μmol/L,即診斷為高尿酸血癥[6]。
1.3 調查內容 收集的數據資料包括問卷調查資料、體格測量資料、實驗室檢測指標3部分。共27項指標:性別、年齡、教育水平、糖尿病史、高血壓史、吸煙史、飲酒史、蔬菜食用情況、水果食用情況、肉類食物食用情況、鍛煉情況、腰圍、體質指數、舒張壓、收縮壓、糖化血紅蛋白、白細胞計數、尿素氮、餐后2 h血糖、血紅蛋白、尿酸、空腹血糖、LDL-C、血小板、HDL-C、三酰甘油、血肌酐。其中,依據《中國慢性病及其危險因素監測報告,2010》[7]對吸煙、飲酒指標進行定義:吸煙定義為每天至少吸20支煙且持續時間為半年以上;飲酒定義為在一年時間內,每天飲用啤酒、白酒、糯米酒等其中一種酒類50 mL及以上。肉類食物食用情況以每天100 g以上為很多、50~100 g為一般、50 g以下為很少;蔬菜食用情況以每天600 g以上為很多、300~600 g為一般、300 g以下為很少;水果食用情況以每天500 g以上為很多、200~500 g為一般、200 g以下為很少;鍛煉情況以每周1~3次為偶爾鍛煉,每周0~1次為不鍛煉,每次正常步行30 min及以上。
1.4 統計學分析 采用SPSS 24.0和R 3.6.0軟件進行統計分析。根據診斷標準,將研究對象分為高尿酸血癥組和非高尿酸血癥組,將兩組對象進行編號,然后采用單純隨機抽樣的方法,從兩組中分別隨機抽取80%的樣本量組成訓練集樣本用于構建模型,其余20%樣本量作為測試集用于評價模型效能。在所有研究對象中先將27項指標采用單因素分析方法進行篩選,服從正態分布的計量資料以(x±s)表示,比較采用獨立t檢驗,不服從正態分布的資料以中位數(M)和四分位數間距(Q)表示,比較采用秩和檢驗;分類變量以率或構成比表示,比較采用χ2檢驗。將單因素分析中P<0.05的變量,采用訓練集數據分別建立Logistic回歸預測模型和隨機森林預測模型。最后,根據測試集數據應用兩種預測模型對高尿酸血癥患病風險進行預測,采用受試者工作特征(receiver operating characteristic,ROC)曲線下面積(area under the curve,AUC)比較兩種預測模型預測效果的差異。
1.4.1 隨機森林預測模型的建立:運用R 3.6.0軟件進行分析和建模,根據訓練集數據,調用Random Forest包進行隨機森林模型的訓練,并對重要參數ntree和mtry進行調試。經測試集檢驗,當ntree=500、mtry=6時,隨機森林模型達到最優。
1.4.2 Logistic回歸預測模型的建立:在訓練集數據上,使用R語言中的glm函數構建Logistic模型,并利用step函數對構建的初始Logistic模型進行基于AIC準則的逐步回歸變量篩選。
1.4.3 驗證模型: 采用簡單交叉驗證,根據擬合出的兩個預測模型,采用測試集數據繪制ROC曲線,根據ROC曲線及AUC對模型預測的優劣進行評價。
2 結 果
2.1 高尿酸血癥檢出情況及單因素分析結果 2 754例研究對象中,共檢出454例高尿酸血癥,陽性檢出率為16.49%。其中,男性患者249例,陽性檢出率為23.85%(249/1 044),女性患者205例,陽性檢出率為11.99%(205/1 710)。單因素分析結果顯示,在所分析的27個指標中,15個指標差異有統計學意義(均P<0.05),見表1。
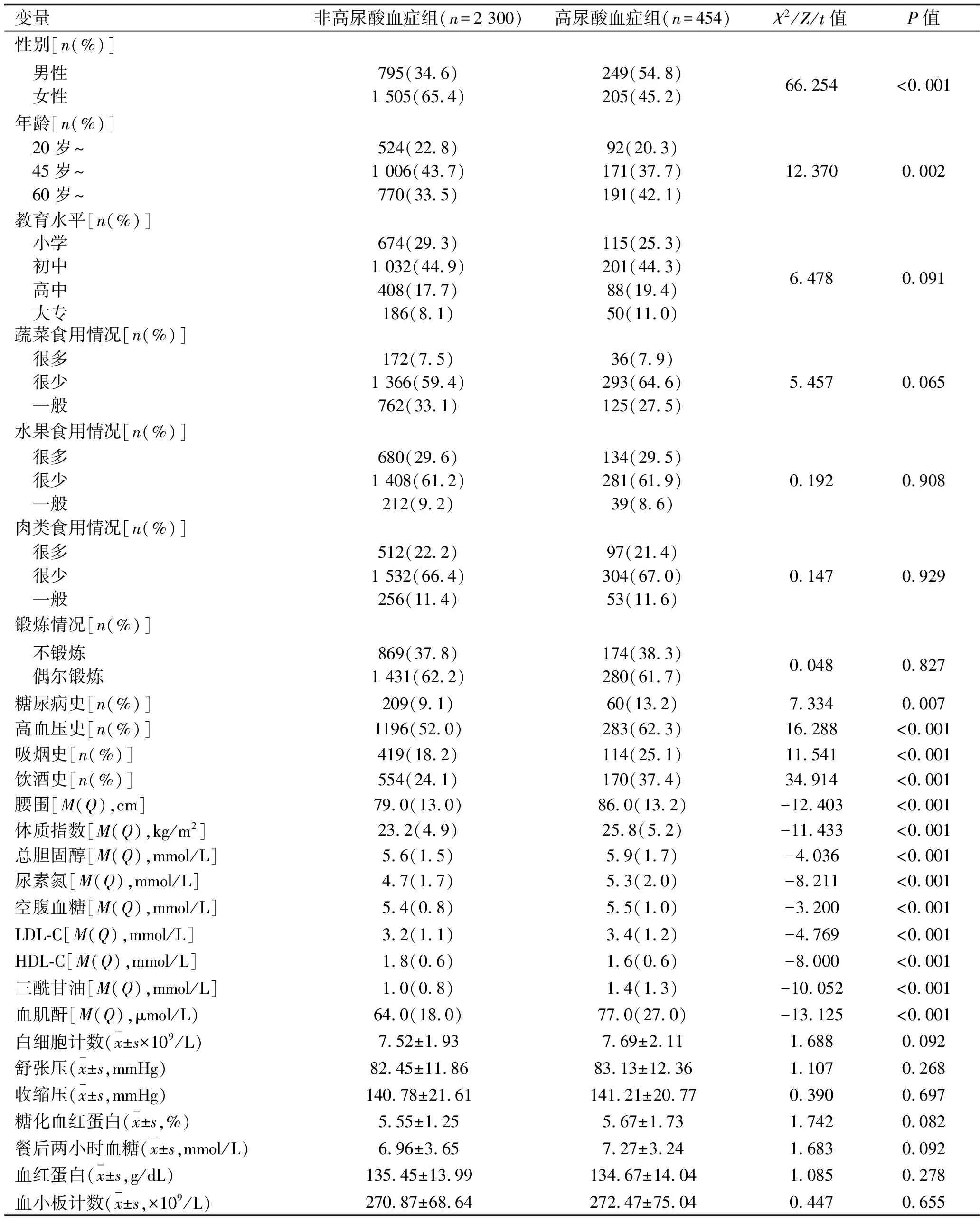
表1 單因素分析結果
2.2 隨機森林預測模型分析結果 訓練樣本為2 212例,ntree=500,mtry=6,基于此參數設置對測試集數據進行分類;經測試集檢驗,模型預測的準確率為92%。隨機森林模型袋外錯誤率為10.05%,說明模型泛化性較好,不存在過擬合。隨機森林模型中各變量重要性排序見表2,其中0和1列分別顯示各個變量對預測為非高尿酸血癥和高尿酸血癥的貢獻大小,平均基尼降低值顯示變量對最終預測的重要程度。
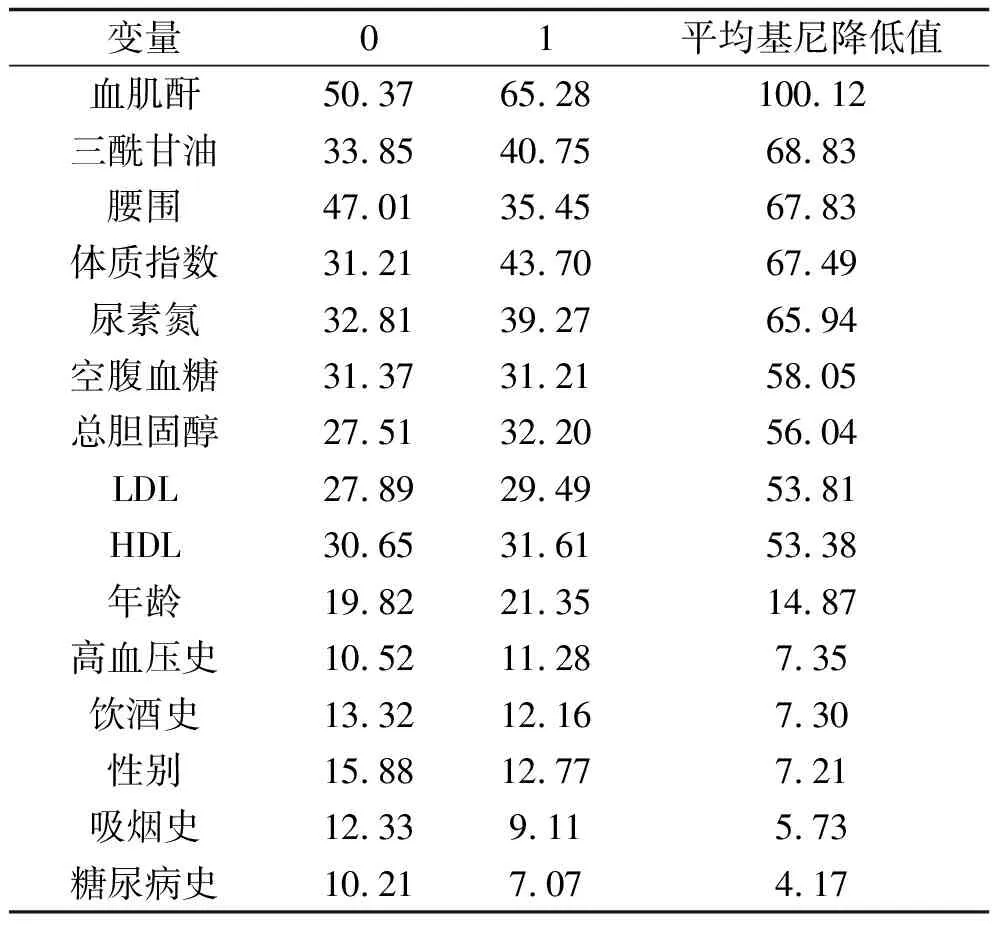
表2 隨機森林預測模型分析結果
2.3 Logistic回歸模型分析結果 以是否患高尿酸血癥為因變量,以體質指數、性別、年齡、糖尿病史、高血壓史、飲酒史、吸煙史、腰圍、總膽固醇、尿素氮、空腹血糖、LDL-C、HDL-C、三酰甘油、血肌酐等15個指標為自變量進行多因素非條件Logistic回歸分析,采用后退法篩選變量,變量進入模型的水準α=0.05,變量剔出模型的水準α=0.10,分析的變量及其賦值方法見表3。結果顯示,男性、腰圍和體質指數增加,以及三酰甘油、血肌酐水平升高均增加高尿酸血癥發生的危險性(均P<0.05),見表4。
表3 分析變量及賦值方法

變量賦值方法高尿酸血癥無=0,有=1性別男=0,女=1年齡20歲~=0,45歲~=1,60歲~=2糖尿病史無=0,有=1高血壓史無=0,有=1吸煙史無=0,有=1飲酒史無=0,有=1腰圍(cm)連續型變量體質指數(kg/m2)連續型變量總膽固醇(mmol/L)連續型變量尿素氮(mmol/L)連續型變量空腹血糖(mmol/L)連續型變量LDL-C(mmol/L)連續型變量HDL-C(mmol/L)連續型變量三酰甘油(mmol/L)連續型變量血肌酐(μmol/L)連續型變量

表4 影響高尿酸血癥發生的多因素Logistic回歸分析結果
2.4 兩種模型的預測效果比較 將建立的預測模型應用于測試集,比較兩種模型對高尿酸血癥的預測效果。Logistic回歸預測模型的AUC為0.658(P<0.001,95%CI:0.647~0.669),隨機森林預測模型的AUC為0.759(P<0.001,95%CI:0.746~0.772)。隨機森林預測模型的AUC大于Logistic回歸預測模型的AUC(P=0.002)。選擇正確指數最高的點作為最佳臨界點,此時Logistic回歸預測模型的靈敏度、特異度、準確率分別為87.7%、43.9%、82.3%,而隨機森林預測模型的靈敏度、特異度、準確率分別為97.2%、54.5%、92.0%,見圖1。

圖1 兩種模型預測高尿酸血癥發生的ROC曲線
3 討 論
隨著我國社會經濟的發展和城市化進程的加快,高尿酸血癥的患病率明顯增加,且發病呈年輕化的趨勢,預測高尿酸血癥患病風險有助于及早發現和實施干預措施,從而提高人群健康水平。
目前,隨機森林模型應用領域非常廣泛,特別在金融學、醫學以及生物學等領域均獲得不錯的評價[8],可以用于疾病發生風險的預測。該模型雖結構復雜但卻容易使用,需要假設的條件比Logistic回歸模型要少。同時,隨機森林也不需要檢驗變量的非線性作用和交互作用是否顯著[9]。隨機森林模型通過隨機選取一個特征子空間,再選取具有最佳Gini值的特征因子作為分割[10],其不僅具有優越的預測能力,而且可判別各影響變量的重要性程度。
本研究建立了隨機森林預測模型和Logistic回歸預測模型,并比較兩種模型對高尿酸血癥的預測效能,結果顯示,隨機森林預測模型的AUC為0.759, 提示其對高尿酸血癥有一定的預測效能,且其AUC、靈敏度、特異度、準確率均優于Logistic回歸預測模型,表明隨機森林模型對高尿酸血癥的預測能力優于Logistic回歸預測模型。隨機森林預測模型最大的優勢是能夠分析復雜非線性關系的數據以及對預測變量的數目沒有限制[11],且能在變量個數大于樣本個數的數據中進行判別和分類[12];同時,其能提供各個自變量對模型預測的重要性分析,可以作為高尿酸血癥影響因素的重點觀察指標。Logistic回歸模型是常用的概率預測模型,使用方法簡單,預測能力較強,但是不能給出各個自變量對模型預測的重要性,Logistic回歸預測模型優勢在于可以直觀解釋影響因素的相對危險度。
本研究在隨機森林模型特征變量的重要性分析中,排名前5位的變量依次是血肌酐、三酰甘油、腰圍、體質指數、尿素氮;而Logistic回歸分析顯示,性別、腰圍、體質指數、三酰甘油、血肌酐是高尿酸血癥發病的重要影響因素。兩種模型的分析結果相似,說明預測結果穩定可靠。結果提示,男性人群以及血肌酐、三酰甘油、腰圍、體質指數、尿素氮異常者發生高尿酸血癥的風險增加(P<0.05),需注意監測血尿酸水平,防止高尿酸血癥的發生。
綜上所述,隨機森林模型對高尿酸血癥預測效果較好,可以作為Logistic回歸預測模型的補充,充分發揮兩種預測模型的優越性。男性人群以及血肌酐、三酰甘油、腰圍、體質指數、尿素氮異常者,應定期進行尿酸水平檢測,如發現這些指標異常增高,應盡早采取相應的干預措施,以期降低高尿酸血癥發生的風險。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
