基于深度學習的青椒質量分類
2020-05-13 09:48:34孫福振
山東理工大學學報(自然科學版) 2020年4期
鄭 凱,方 春,孫福振
(山東理工大學 計算機科學與技術學院, 山東 淄博 255049)
青椒具有刺激性辣味,可刺激味蕾[1],增進食欲,其維生素C的含量在眾多蔬菜中更是居首, 具有良好的食用價值,市場需求也隨之上升。目前青椒的質量分類是在采摘過程中依靠人工完成的,整個過程人力消耗大、效率低、用工成本高,因此,迫切需要一種操作簡單、分類速度快、準確率高、能大規模自動化分揀的青椒質量分類機器。青椒在生長過程中,由于受到外界干擾(搭在了枝葉或吊繩上)而發育得歪歪扭扭,這種情況在大棚種植中是不可避免的[2-4],長相不好的青椒嚴重影響其銷售價格和消費者的購買行為,故在裝箱銷售之前要將質量差的選出,如何在大量的青椒中將品相不好的青椒快速且準確地選出是青椒質量分揀機的關鍵。
深度學習方法在農業領域特別是蔬菜質量檢測方面的應用越來越普遍與廣泛。王樹文等[5]在計算機視覺技術上運用神經網絡等深度學習方法完成了對番茄外部損傷的質量分類研究;展慧等[6]在板栗圖像上利用基于BP神經網絡與特征圖像的方法對其完成了分級任務;韓東偉等[7]在煙葉質量的分類任務中采用改進的卷積神經網絡,達到了99.92%的識別準確度。將深度學習方法應用于計算機視覺,為蔬菜和水果的質量分類提供了新的解決辦法。
水果和蔬菜的自動外部質量檢查仍然是一項具有挑戰性的工作。張烈平等[8]使用計算機視覺和BP神經網絡對芒果圖像進行圖像分割、圖像增強和特征提取等復雜操作完成分級任務,雖取得了比較不錯的成果,但過程復雜,易受外部環境的影響。Satpute等[9]在利用計算機視覺檢測水果缺陷時先將RGB圖像轉換為灰色圖像,然后再進行邊緣檢測和斑點檢測,在尺寸檢測中將灰色圖像進行二進制閾值化,然后進行一系列的形態學操作,通過計算長軸和短軸長度判斷果實大小,最后兩者結合完成了對西紅柿的分級任務。這種方法易受光線等外界環境的影響且操作復雜,對小規模的分揀任務有較好的結果,對青椒這類數量多,體積小的分類任務效果不太理想。吳華友[10]發明的青椒分級機通過物理機械的方法完成對青椒的分揀。這種方法雖然效率高,但分類準確度并不理想,且在經過機械滾筒與篩選孔過程中易對青椒表皮造成二次傷害。
隨著人工智能的興起,基于深度學習方法的計算機視覺技術也廣泛應用于農業生產,比如果實采摘機器人、檢測農作物長勢、農產品品質檢測與預防病蟲害等[11-14]。近幾年,深度學習中的卷積神經網絡(convolutional neural networks, CNN)引起了學者的高度關注[15-16],局部權值共享的方法使其在圖像處理和語音識別等方面表現出了強大的優勢。它可以將原始的圖像數據作為直接輸入,自行從圖像中抽取特征,無需人工干預特征提取(包括輪廓、色澤、結構等)過程,網絡布局模仿了實際的生物神經網絡,使其對圖像的處理能力達到了幾近人力的水平。在圖像識別領域每一個重大突破的背后都可以看到卷積神經網絡的影子。本文以青椒整體圖像作為研究對象,采用CNN深度學習方法的同時結合Python語言和Keras學習框架,幫助果實分揀機實現對青椒的自動分揀過程。
1 數據準備
1.1 圖像的收集
本文共采集到來自壽光蔬菜大棚種植條件下的4 160 張青椒圖像作為數據樣本,其中正樣本為符合商家收購標準,品相較好的青椒圖像共2 060張;負樣本為未達到商家收購標準,品相不好需要降價收購或需要剔除處理的青椒圖像共2 100 張。采樣過程中選取了與青椒有明顯對比度且反光度弱的白色粗糙紙張作為背景。取樣時將白色面板固定在水平面上,將普通智能手機置于青椒上方合適位置,在正常條件下進行拍攝,禁用美顏功能,以保留圖片的真實性。因智能手機拍攝的照片像素非常高,為便于本文實驗的進行以及方便后續的計算和處理,在不改變原本圖像格式(JPG)和比例的情況下,使用圖片批處理工具進行了統一像素(150*150)轉換,處理后的青椒圖像如圖1、圖2所示。

圖1 符合收購標準的青椒圖像Fig.1 Images of green peppers that meet acquisition criteria

圖2 不符合收購標準的青椒圖像Fig.2 Images of green peppers that do not meet the acquisition criteria
1.2 訓練集與測試集
本文實驗選取正負樣本各1 600張組成訓練集train3200,剩余的960張圖像作為測試集test,劃分比例接近8∶2。
2 模型設計
2.1 CNN理論基礎
在傳統的神經網絡中每個神經元都和相鄰層的神經元相連接,因此網絡中包含大量的參數。而圖像本身具有局部特性,其并不一定需要全連接的神經元連接方式。例如看到一只狗的圖片,不一定要看到全圖,可能只看到狗的嘴巴的時候就知道這是一只狗。卷積就是用特殊的方法對圖像的重要特征進行提取,用于識別本圖片或與其他圖片的不同。
CNN包括卷積層(Convolutional Layer)和池化層(Pooling Layer)兩個重要部分。在卷積層中通過卷積核或濾波器(Filter)來獲取圖像特征(Feature map)。采用權值共享即在特征提取過程中用同一個卷積核提取同一個特征,這樣一組連接可以共享同一個權重,不同的卷積核攜帶不同的權重提取不同的特征。此方法減少了參數量,提高了對高維數據的處理能力。3*3卷積核處理4*4像素圖片過程如圖3所示。

圖3 3*3卷積核處理4*4圖片過程Fig.3 3*3 size convolution kernel processing 4*4 size picture process
池化層利用圖像局部相關性的原理對特征圖像進行子抽樣,通過去掉Feature map中不重要的特征數據,增強了所提取特征的魯棒性,進一步減少了參數數量。池化過程與池化結果如圖4所示。
2.2 模型結構
在綜合了模型復雜度及其他影響因素之后,設計了表1所示的三層CNN結構來處理青椒的質量分類任務。該模型采用三個卷積層加三個全連接層的方法,并在三個全連接層之間加入Dropout層來防止過擬合。
表1 三層CNN結構模型
Tab.1 Three-layered CNN structural model

Layer (type)InputOutputShapeConv2d_1_input:InputLayerinput(None,150,150,3)output(None,150,150,3)Conv2d_1:Conv2Dinput(None,150,150,3)output(None,150,150,32)Max_pooling2d_1:MaxPooling2Dinput(None,150,150,32)output(None,75,75,32)Conv2d_2:Conv2Dinput(None,75,75,32)output(None,75,75,32)Max_pooling2d_2:MaxPooling2Dinput(None,75,75,32)output(None,37,37,32)Conv2d_3:Conv2Dinput(None,37,37,32)output(None,37,37,64)Max_pooling2d_3:MaxPooling2Dinput(None,37,37,64)output(None,18,18,64)Flatten_1:Flatteninput(None,18,18,64)output(None,20736)Dense_1:Denseinput(None,20736)output(None,1024)dropout_1:Dropoutinput(None,1024)output(None,1024)Dense _2:Denseinput(None,1024)output(None,512)dropout_2:Dropoutinput(None,512)output(None,512)Dense_3:Denseinput(None,512)output(None,2)
3 結果與分析
3.1 不同卷積層數對模型準確率的影響
本文對青椒圖像的質量分類本質上是圖像二分類問題,即判別圖像中青椒質量是否符合商家收購標準。為了探究CNN模型深度對模型識別準確度的影響,本文在train3200的數據集上對比分析了當分別采用1~4個卷積層時模型的準確率。各模型在測試集test上的準確率如圖5所示,相對應的損失函數loss的分布如圖6所示。

圖5 不同卷積層數的模型在測試集上的準確率Fig.5 Accuracy of models with different convolutional layers on the test set
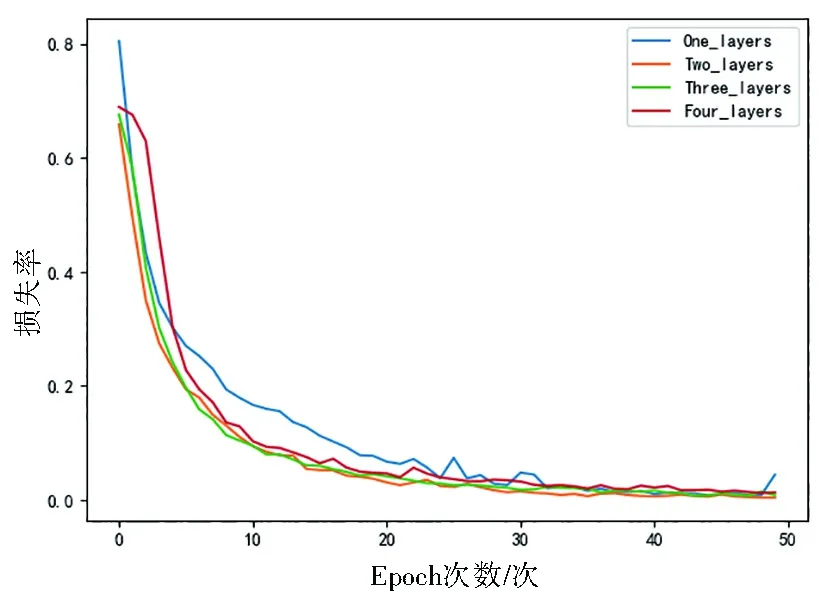
圖6 不同卷積層數的模型在測試集上的損失率Fig.6 Loss of models with different convolutional layers on the test set
從圖5、圖6中可以看出,四個模型在青椒質量分類問題上均取得了不錯的結果,其中一層卷積模型的識別準確率明顯不如其他模型的,二層卷積模型準確率有所提升但并不穩定,三、四層卷積模型的相差不大,而三層卷積層時相應的損失率更低,實驗說明模型深度對模型性能確實有影響,三層卷積模型更適合本文數據集。
3.2 優化函數對模型準確率的影響
深度學習中優化函數包括經典的SGD (Stochastic Gradient Descent , 隨機梯度下降)優化,以及常用的RMSProp(Root Mean Square Prop,均方根反向傳播)優化和Adam(Adaptive Moment Estimation, 自適應矩估計)優化等。SGD優化算法是一種貪心算法,其優化過程好比一個人在有大霧的山中尋找山谷最低點,由于大霧的影響并不知道當前找到的最低點是否是整座山谷的最低點;RMSProp優化算法通過對權重和偏置的梯度進行微分平方加權平均數,很好地解決了在更新損失函數過程中存在擺動幅度過大的問題,并且能幫助函數更快地收斂。前兩種算法一種可以使用動量來累積梯度,另一種可以使得損失函數波動幅度減小的同時加快收斂速度。而Adam則是在兩種算法結合下產生的,適用于不穩定目標函數,能自然地實現步長退火過程。合適的優化器可以幫助模型更快地收斂并快速了解網絡模型在所處理問題上的性能。為了探究不同優化器對模型的收斂速度及性能的影響,本研究對三種不同優化函數進行了比較。實驗結果如圖7、圖8所示。

圖7 不同優化函數下模型準確率Fig.7 Model accuracy under different optimization functions
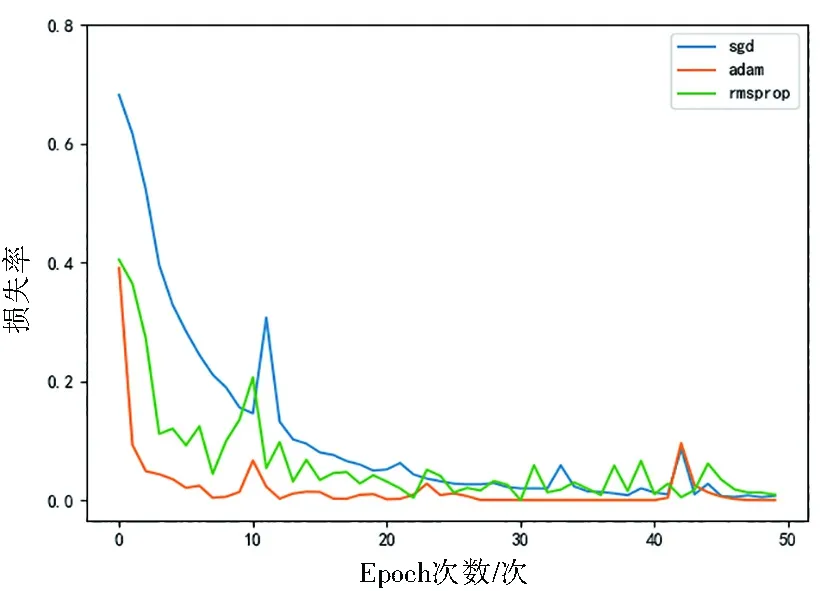
圖8 不同優化函數下模型損失率Fig.8 Loss of models under different optimization functions
由圖7、圖8對比可知,Adam(橙色)優化函數不僅加快了模型收斂速度還減小了損失函數的波動幅度。三者在測試集上的模型準確率為SGD 96.44%、Adam 97.80% 、RMSProp 97.49%。因此,Adam在本文研究數據集中獲得了較好的表現。
3.3 不同尺寸卷積核對模型性能的影響
卷積核又叫濾波器,能夠提取輸入圖像的不同特征,例如邊角和紋理特征等。增大卷積核可以帶來更大的感受野[17],提高網絡的性能,但同時網絡參數成倍增加,因此選取合適的卷積核對簡化網絡和提升模型性能是至關重要的。為找到合適的卷積核,本文在已確定的三層卷積網絡和Adam優化函數下采用網格搜索的方法,分別對1*1、3*3、5*5和7*7大小的卷積核進行比較。Epoch為50時模型識別準確率如圖9所示,可以看出1*1的卷積核模型準確率雖高但波動幅度較大,其余尺寸的卷積核模型相差不大。在測試集上的識別準確率分別為98.75%、97.60%、97.08%、96.88%。在綜合考慮數據集圖片尺寸,模型復雜度及在測試集上的分類效果后,最終選擇了3*3尺寸的卷積核。

圖9 不同尺寸卷積核的模型準確率Fig.9Model accuracy under convolution nuclei of different sizes

圖10 不同尺寸卷積核在測試集上的ROC曲線Fig.10 ROC curve of convolution nuclei of different sizes on the test set
不同尺寸卷積核的四種模型在測試集上的ROC(接受者操作特性曲線,receiver operating characteristic curve)曲線如圖10所示。曲線下的面積越大,說明該分類器的分類效果越好,由圖10可以看出,四種尺寸的卷積核模型都表現出了不錯的分類效果。表2為不同尺寸的卷積核模型在測試集上的AUC(Area Under Curve)值,即ROC曲線下的面積,AUC的值越接近于1,代表分類模型的分類能力越強,可以更加直觀地顯示模型的分類效果。實驗結果表明,運用Adam優化函數和3*3卷積核的三層CNN結構模型在測試集上的識別準確率達到了97.60%,AUC值為0.996,模型獲得了良好的分類效果。
表2 不同尺寸卷積核的AUC值
Tab.2 AUC values under convolution kernels of different sizes

卷積核大小AUC值1?10.9983?30.9965?50.9917?70.993
3.4 硬件環境
本文實驗使用的硬件運行環境見表3。
表3 硬件運行環境
Tab.3 Hardware operating environment

硬件詳細信息系統Windows 7 旗艦版CPUIntel(R) Xeon E3-1225 v5 @ 3.30 GHz四核內存海力士8 GB DDR4 2 133MHz顯卡NVIDIA Quadro K620硬盤希捷 1 TB 7 200 r/min
4 結束語
本文利用了CNN在圖像處理方面的優勢,提出了基于深度學習的青椒質量分類算法。通過實驗分析驗證了網絡深度、卷積核和優化函數對基于深度學習的青椒質量分類模型的影響,設計好的模型在3 200張青椒圖像數據集上進行訓練,在960張獨立測試集上進行測試,識別準確率達到了97.60%,AUC值達到了0.996。證明了CNN深度學習方法對青椒分類問題的適用性。本文為解決青椒質量分類問題與促進智慧農業的發展提供了新思路。
本數據集中的青椒圖像大部分取樣于畸形青椒,在今后工作中準備采集有蟲害或有霉病的青椒圖像進一步擴充數據集,繼續訓練優化該模型,并將該模型推廣到農作物選種及病蟲害識別方面。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
