藏語語言模型的研究現(xiàn)狀及展望
2020-05-21 05:54:57郭楊擁措
電腦知識與技術 2020年9期
郭楊 擁措
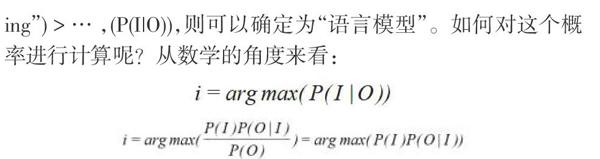
摘要:語言模型是自然語言處理研究的基礎,是計算機識別和自然語言理解的橋梁。到目前為止,語言模型走過來了三個階段:統(tǒng)計模型、神經網絡模型、深度神經網絡模型。隨著深度學習技術的廣泛應用,大規(guī)模數(shù)據(jù)集的使用、復雜的模型以及高昂的訓練代價稱為語言模型建模的特點。隨著信息化的高速發(fā)展,藏語的語言模型成為目前乃至以后的研究趨勢。文章全篇介紹了語言模型的研究現(xiàn)狀以及藏語語言模型的研究現(xiàn)狀,并探討了當前藏語語言模型在分析過程所經歷的難題,并提出可能的解決方案以及應用前景。
關鍵詞:語言模型;藏語;研究現(xiàn)狀
中圖分類號:G424 文獻標識碼:A
文章編號:1009-3044(2020)09-0181-04
引言
語言模型是許多自然語言處理任務的基礎部分,對語言模型的研究可以促進自然語言處理方面技術的攻堅克難。通過對藏語模型的研究,可以提高藏文文本的分詞技術,藏語語音的識別技術等,對于少數(shù)民族地區(qū)的民族化文化信息處理技術有著不可磨滅的重要性。
藏語是促進西藏文化和民族文化的主要工具和手段。因此,本文目標是基于對語言模型以及藏語語言模型的國內外最新研究的成果進行比較、分類、總結,從而探索出語言模型在自然語言處理方面的潛在趨勢,幫助其他愛好研究自然語言的研究者全方位、各層次、多角度的了解該領域內的算法與技術。
關于藏語模型的相關研究很少,傳統(tǒng)的N-gram語言模型仍在使用。最新的神經網絡語言模型尚未應用于藏文。本文將基于語言模型、藏語語言模型這兩個板塊,通過分析兩個板塊下最新的衍變模型來進行詳細闡述。
1 語言模型
自然語言從其出現(xiàn)開始,漸漸的變?yōu)橐环N在上下文的信息中表達和傳遞的方式,進而交付給計算機來處理自然語言。那么隨之而來的一個重要問題就是如何解決自然語言的語境相關性?經過探索和發(fā)現(xiàn),就是為自然語言建立數(shù)學模型。該數(shù)學模型是統(tǒng)計語言模型(Statistical Language Model),統(tǒng)計語言模型是現(xiàn)階段自然語言處理任務中最基礎的部分,在諸多任務中,如:文本分類、文本校對、機器翻譯和語音識別等都有著它潛移默化的身影。
那什么是語言模型?假設,對于一個觀測值:“yuyanmox-ing”,可能是由“語言模型”“寓言模型”“語言魔性”…等得到的,但是要想得到究竟是哪一個,通常需要計算它們的概率,比如:P('‘語言模型”"yuyanmoxing“)>P(“寓言模型”|“yuvanmox-ing”)>…,(P(110)),則可以確定為“語言模型”。如何對這個概率進行計算呢?從數(shù)學的角度來看:
如果我們直接用第一種方法,即為判別式模型,如果用第二種方法,即為生成式模型。當采用生成式模型的話,需要計算這個語句序列出現(xiàn)的概率即為P(I)的概率,如何計算P(I)的概率呢?計算一個文本序列w={w1,w2...wn)的概率,需要知道他們之間的關系,我們對這個關系的建模即為語言模型。
在研究白然語言處理的過程當中,總是有著各種各樣的嘗試,如何完美表達,完美計算和完美理解等。但是,由于基于手動規(guī)則的處理,早期模型在所有領域都不全面。手動規(guī)則已經達到了瓶頸,無法更深入的解決問題,于是在許多相關數(shù)學基礎的研究者探索和發(fā)現(xiàn)中,通過統(tǒng)計,在大量沒有標記的數(shù)據(jù)下進行有序的語法和語義的統(tǒng)計學習,從而取得一些成功。到目前為止,基于統(tǒng)計的語言模型已逐步從統(tǒng)計語言模型,神經網絡模型升級到深度神經網絡模型。
第一階段的統(tǒng)計語言模型分為生成模型和判別模型。序列可以是單詞,句子或整個章節(jié)。可以通過貝葉斯規(guī)則將生成的模型轉換為判別模型,并且將概率分配給術語序列中的可能項。概率越高,序列符合語言規(guī)則越多,它出現(xiàn)的越“合理”[1j。隨著時間的推移,學術探索者提出了許多語言模型,其中N-gram模型是最突出的代表。同時,還引入了N-gram模型的高級語言模型,如最大熵模型。
直到Bengio[21探索了一種新的模型一前饋神經網絡語言模型(Neural Network Language Model),才逐漸揭開語言模型的第二個神秘面紗。從最基礎的上下文計數(shù)(Context-counting)到上下文預測(Context-predicting)的創(chuàng)新成為了一種新的機遇和挑戰(zhàn)。同時,統(tǒng)計的基本單位從詞項變?yōu)樵~向量(Word Embed-ding),這是實現(xiàn)級別的主要變化,從而可以在識別和計算過程中更有效地進行改進。
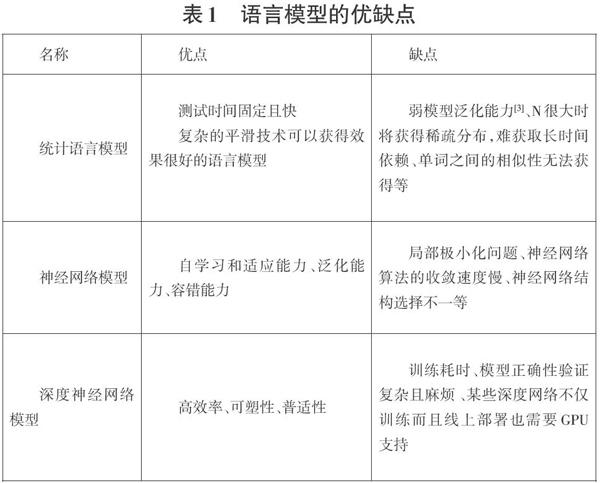
在語言模型研究的第三階段,深度學習在白然語言處理的應用中起著重要作用。遞歸神經網絡(Recurrent Neural Net-work)是深度神經網絡家族的一員,其特點是圖靈完整性和序列構建,已成為一種重要的語言建模方法。同時在深度神經網絡的欠缺方面,也進行了優(yōu)化,比如:模型結構、耗費時間、輸入輸出等層面。三個階段的語言模型的優(yōu)劣,見表1。
2 語言模型的研究現(xiàn)狀
在進入21世紀后,大數(shù)據(jù)、云計算等新興技術撲面而來,世界開始步人人工智能的時代,中國也在緊隨其后開始探索人工智能。最為突出的行業(yè)就是新聞行業(yè),國內許多知名的公司和機構開始逐一踏人自動化生產的潮流中,一場新聞機器人的熱浪蓄勢待發(fā)。
機器新聞寫作本質上是使用自然語言來生成文本的過程,實際就是生成(Natural Language Generation)編寫新聞的過程。機器新聞寫作的核心技術是自然語言生成、大數(shù)據(jù)和云計算的支持。目前,用于數(shù)據(jù)到文本生成的大多數(shù)神經網絡模型基于遞歸神經網絡。RNN的神經語言模型和Seq2 seq架構,同時使用了注意力模型。
文本生成本身就是一個輸入輸出的問題,輸出一個序列,出來一個結果,而RNN就一種很適合對文本序列數(shù)據(jù)進行建模統(tǒng)計的神經網絡。基于RNN的語言模型構建就是一種利用RNN的方法來表達語言序列的生成過程。同時與基礎的RNN的層級上來看,加入了詞向量層(Embedding)和softmax函數(shù),多層級的加入與計算,使語言模型更加完善。換一個NLP任務來說,在機器翻譯中,Seq2seq是RNN的變種,是EncoderDecoder的一種,同時注意力機制(Attention Mechanism)的引入,對于輸入的數(shù)據(jù)進行加權計算,矩陣的變換等,也使得序列對序列方式下的表現(xiàn)更為直觀,更為高效。
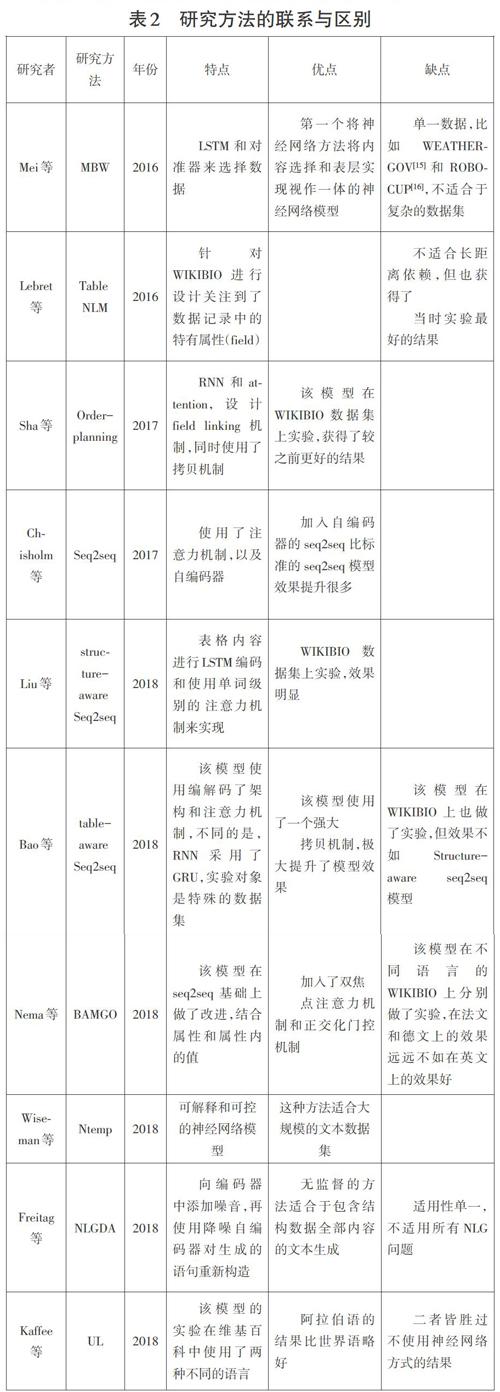
下面按照時間順序具體介紹一下最新的研究方法,并如何一步步改進完善的,并分析它們之間的聯(lián)系與區(qū)別。
Mei等人2016年提出一種端到端(End-to-End)新的神經網絡模型,是基于編碼解碼(Encoder-Decoder)框架為一身的(簡稱MBW)c4]。同時用到了RNN的變形,基于長短期記憶網絡(LongShort-term Memory)和對準器(Coarse-to-Fine Aligner)來實現(xiàn)文本的選取和文本的描述。
2016年,Lebret等人,通過爬取維基百科上面的人物傳記數(shù)據(jù)來生成人物傳記的句子,提出一種基于條件神經語言模型(Condition Neural Language Models)的神經模型(簡稱Table NLM)[5],在模型的構建中,使用了拷貝機制,通過計算向量與屬性和值的數(shù)量關系來選取最有可能的替代品來預測未知詞。
Sha等人2017年提出的神經網絡模型,是一種基于規(guī)劃順序(Order-planning)[6],通過不同field之間關系模擬,來實現(xiàn)更好的文本生成的順序排序,減少少見詞的出現(xiàn)(Rare Words),
Chisholm等人設計的一種白編碼器Seq2seq模型(簡稱S2SAE)[7],是針對一句話的人物傳記,從而實現(xiàn)了從維基百科人物傳記結構化數(shù)據(jù)報文本單句的生成。
Liu等人在2018年提出的模型中,是一種面向結構(Struc-ture-aware)的Seq2seq模型[8],通過對表格內容進行白定義屬性門 (Field-gating)LSTM編碼。
Bao等人2018年的Seq2seq模型[9],是一種面向表格(Table-aware)的模型,實驗對象具有特殊性,是一個開放領域的數(shù)據(jù)集WIKITABLETEXT,因為其特殊性,在模型的基礎上使用強大的拷貝機制(Copying Mechanism),在數(shù)據(jù)集的測試上,有了很大的提升。
Nema等人2018年提出了一種新的結構化描述(簡稱BAM-GO)[10j,同時使用雙焦點注意力機制和門控正交化,一方面結合了宏觀和微觀層面的信息,也在文本的生成過程中將已出現(xiàn)的屬性值在后續(xù)步驟中選擇性遺忘(Never Look Back)。
Wiseman等人2018年設計的抽取模板來生成的方式(簡稱Ntemp)[11],是基于隱藏的半馬爾科夫(HSMM)解碼器的生成模型。利用一個類似二進制的轉移概率來判斷兩種輸入情況,一種情況不在數(shù)據(jù)源中,通過原始詞來預測生成新的文本;另一種可直接生成本文,利用的是RNN來實現(xiàn)。
Freitag等人2018年構建的自然語言生成過程(簡稱NLG-DA)[12],實現(xiàn)了無監(jiān)督的學習方式,同時也使用了降噪自編碼器(Denoising-Autoencoder)來對生成的語句重新構造,會更好的生成正確的語句。該模型經常被用于E2E數(shù)據(jù)集[13]。 Kaffee等人2018年提出的針對單句的跨語言跨領域的神經網絡模型(簡稱UL)[l4]。基于編碼解碼(Encoder-Decoder)架構,利用數(shù)學上的三元組進行輸入,而解碼使用了一層GRU,3+1的多層次結合來生成文本,也利用了拷貝機制來加強文本生成的效果。
神經網絡模型的研究方法的聯(lián)系與區(qū)別:見表2
在語言模型預訓練的探索過程中,王英杰、謝彬和李寧波為了減輕模型對這種大型數(shù)據(jù)集的依賴,提出一種基于BERT針對中文科技自然語言處理小數(shù)據(jù)集任務的預訓練語言表征模型ALICE,實驗結果表明,與BERT相比,ALICE分別提高了1.2%的準確率與0.8%的F1值[17]。
3 藏語語言模型的研究現(xiàn)狀
藏語是一種少數(shù)民族語言,對藏語語言模型的研究目前還處于最基礎的,最初級階段,依然使用的是N-CRAM語言模型,是基于N元文法模型的研究,而對神經網絡方面的研究是少之又少。
2011年,北方民族大學多拉和才讓三智在研究中發(fā)現(xiàn),建立藏語語言模型,重新探索新的藏語語法體系[18]。根據(jù)藏語特點,2012年李冠宇和孟猛,提出了一種藏語識別聲學模型,并利用高級藏語知識來減少模式匹配的模糊性,在HTK平臺上建立了依賴于上下文的連續(xù)隱馬爾可夫聲學模型,實現(xiàn)了西藏拉薩的連續(xù)詞匯連續(xù)語音識別[191。最后發(fā)現(xiàn),在最優(yōu)情況下,模型詞的錯誤率大大降低。2014年,李照耀主要研究語言模型在藏文連續(xù)識別系統(tǒng)中的應用,結合西藏拉薩的特點,提出了一種新的文本篩選方案。通過比較各種算法的混淆和語音識別系統(tǒng)的識別率,將改進的Kneser-Ney平滑算法最終應用于基于HTK的藏文連續(xù)語音識別系統(tǒng)[20]。實驗結果表明,Kneser-Ney平滑算法的修改版本在各種平滑算法中具有最少的混淆。2015年青海民族大學仁青吉和安見才讓在對藏語語言模型的研究中,發(fā)現(xiàn)一個可靠的語言模型對比:在自然語言處理領域,例如語音識別,機器翻譯和文本校對,起著至關重要的作用。通過在藏語語音識別系統(tǒng)中構建藏語模型來提高識別率,采用了一些算法來比較混淆[21]。
以上都是語言模型在語音識別上面的重大應用。
2017年西北民族大學張?zhí)嶂饕芯柯晫W模型,就是以提高聲學模型參數(shù)的準確性為目的,通過最小音素誤差準則估計三音素模型的參數(shù),獲得具有更好識別效果的聲學模型[22]。
2017年中央民族大學周楠主要探討深度神經網絡在藏語拉薩話連續(xù)語音識別任務中的應用,研究了深度神經網絡的網絡結構,預訓練和參數(shù)設置,訓練的深度神經網絡的輸出層特征用于訓練HMM的聲學模型[23]。
2018年,天津大學研究中心發(fā)現(xiàn),循環(huán)神經網絡語言模型超過傳統(tǒng)的N- gram模型已成為主流的語言模型建模方法。申彤彤的研究主要從兩個方面解決了藏語RNNLM訓練數(shù)據(jù)缺失的問題:模型訓練技巧和藏文探究,分別提出了插值語言模型,領域自適應循環(huán)神經網絡語言模型和結合藏文成分的循環(huán)神經網絡語言模型[24]。
2018年,黃曉輝、李京探索將循環(huán)神經網絡和連接時序分類算法應用于藏語語音識別聲學建模,實現(xiàn)端到端的模型訓練。發(fā)現(xiàn)循環(huán)神經網絡模型有更好的識別性能,擁有更高的訓練和解碼效率[25]。
2019年,孫嬡、王麗客和郭莉莉等人提出了一種優(yōu)化詞向量的GRU神經網絡模型進行藏語實體關系抽取的方法,加入了優(yōu)化的詞向量,在傳統(tǒng)的詞向量模型中結合藏語音節(jié)向量、音節(jié)位置向量、詞性向量等特征對詞向量進一步優(yōu)化,并且選取了藏語詞匯特征和藏語句子特征[26]。
以上這些是研究者不懈努力的成果,是藏語語言模型最新的研究。
4 藏語語言模型的展望
許多研究證明神經網絡語言模型的性能已超過傳統(tǒng)的N-gram模型,但同時神經網絡語言模型的構建需要大量的訓練語料庫。對于藏語語言模型的研究,在訓練神經網絡模型的數(shù)據(jù)資源嚴重匱乏的情況下,如何選擇相對于目標任務的合適語言模型,如何找到適合藏語的訓練語言模型方法?如何對藏語語言模型的預訓練及后續(xù)的微調過程進行優(yōu)化等這些問題將成為研究藏語語言模型的重要途徑。
目前在還存在一些問題需要探索研究:
(1)藏語數(shù)據(jù)集的不足與缺乏。互聯(lián)網上公開共享的數(shù)據(jù)集非常缺少。
(2)藏語語言模型的研究領域單一。語言模型數(shù)據(jù)集集中在新聞領域,在社交媒體、法律等急需建設。
(3)評價標準不一致。研究員各抒己見,沒有嚴格的標準,導致評價不一致,加大了研究中的難度。
隨之時代的進步,數(shù)據(jù)的發(fā)展,文本生成、語音識別等越來越受到重視,希望在未來的研究探索中,有專門這個研究領域的奠基者,有公開數(shù)據(jù)集合和統(tǒng)一的評價標準,以及多領域、多語言等多方面、多層次的數(shù)據(jù)集供熱愛研究自然語言處理的研究員所使用。目前的神經網絡模型相比于之前的監(jiān)督和半監(jiān)督學習方式有了相當大的提高,但還是留有巨大進步的空間供我們學習,需要研究員們大膽的嘗試與探索,比如從自然語言處理最基礎的方面,研究結構化數(shù)據(jù)的特點等等,或者從自然語言處理任務中借鑒最新的研究成果等等。
近幾年數(shù)據(jù)到文本生成技術越來越受到重視,數(shù)據(jù)到語音識別技術也越來越受到重視,加上機器學習和深度學習的同步發(fā)展,多領域、多角度、多層級的研究也越來越多,當然,一個樹枝的發(fā)展需要樹干的發(fā)展,只有在神經網絡的研究不斷深入,各方面硬件水平提升,存儲能力得到擴展,各式各樣的研究和應用才能有更好的發(fā)展,更大的可能性。
參考文獻:
[1]王毅,謝娟,成穎.結合LSTM和CNN混合架構的深度神經網絡語言模型[J].情報學報,2018(2):194-205.
[2] Bengio Y,Schwenk H,Senecal J S,et aI.Neural probabilistic lan—guage models[M]Ulnnovations in Machine Learning. Berlin/Hei- delberg: Springer-Verlag,: 137-186.
[3]文娟 .統(tǒng) i+語模型的研究與應用[D].北京 :北京郵電大學。 2010.
[4] Mei H, UChicago T T l, Bansal M, et al. What to talk about and how? Selective Generation using LSTMs withCoarse-to- Fine Alignment[CV/Proceedings of the 2016 Conference of theNorth American Chapter of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2016: 720-730.
[5] Lebret R, Grangier D. Auli M. Neural Text Generation fromStructured Data with Application to the BiographyDomain[Cy/Proceedings of the 2016 Conference on Empirical Methods inNatural Language Processing. Strouds - burg, PA: ACL, 2016:1203-1213.
[6] Sha L, Mou L. Liu T, et al. Order-Planning Neural Text Gen-eration From Structured Data[C]//Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence. MenloPark, CA:AAAl, 2018: 5414-5421.
[7] Chisholm A, Radford W, Hachey B. Learning to GenerateOne-sentence Biographies from Wikidata[CV/Proceedingsofthe 15th Conference of the European Chapter of the Associa-tion for Computational Linguistics. Stroudsburg, PA: ACL,2017: 633-642.
[8] Liu T, Wang K, Sha L, et al. Table-to-text generation byStructure-aware Seq2seq Learning[Cy/Proceedingsof the Thir-ty-Second AAAI Conference on Artificial Intelligence. MenloPark. CA:AAAI, 2018: 4881-4888.
[9] Bao J, Tang D, Duan N, et al. Table-to-text: Describing Ta-ble Region with Nlatural Language[C]//Proceedingsof the Thir-ty-Second AAAI Conference on Anificial Intelligence. MenloPark, CA:AAAl, 2018: 5020-5027.
[10] Nema P, Shetty S, Jain P, et al. Generating Descriptions fromStructured Data using a Bifocal Attention Mechanism and Gat-ed Orthogonalization[C]//Proceedings of the 2018 Conference of the North American Chapter of the Association for Computa - tional Linguistics. Stroudsburg,PA:ACL, 2018: 1539-1550.
[11] Wiseman S. Shieber S M. Rush A M. Learning Neural Tem-plates for Text Generation[CV/Proceedings of the 2018 Confer-ence on Empirical Methods in Natural Language Processing.Stroudsburg,PA:ACL, 2018: 3174-3187.
[12] Freitag M, Roy S. Unsupervised Natural Language Genera-tion with Denoising Autoencoders[C]//Proceedings of the 2018Conference on Empirical Methods in Natural Language Pro -cessing. Stroudsburg,PA:ACL, 2018:3922-3929.
[13] Novikova J, Dusek 0, Rieser V. The E2E Dataset: New Chal- lenges For End-to-End Generation[Cy/Proceedings of the18th Annual SIGdial Meeting on Discourse and Dialogue.Stroudsburg,PA:ACL, 2017: 201-206.
[14] Kaffee L A, Elsahar H, Vougiouklis P, et al. Learning to Gen- erate Wikipedia Summaries for Underserved Languages fromWikidata[C]//Proceedings of the 2018 Conference of the NorthAmerican Chapter of the Association for Computational Lin-guistics. Stroudsburg,PA:ACL, 2018: 640-645.
[15] Liang P,Jordan M I,Dan K.Learning Semantic Correspon- ences with Less Supervision[C]//Joint Conference of the Meet- ing of the ACL and the International Joint Conference on Na-tu- ral Language Processing of the Afnlp:Volume. Stroudsburg,PA: ACL, 2009:91-99.
[16] Chen D L,Mooney R J.Learning to Sportscast:A Test ofGrounded Language[Cy/Proceedings of the 25th internationalconference on Machine learning - lC- ML '08, July 5-9,2008. Helsinki, Finland. New York, USA: ACM Press, 2008:128-135.
[17]王英杰,謝彬,李寧波.ALICE:面向科技文本分析的預訓練語表征模型[EB/O Ll.[2019-08-21]. http://kns.cnki.net/kcms/de - tail/31.1289.TP.20190821.1541.009.html
[18]多拉,才讓三智.信息處理用藏語語法模型知識庫研究[J].西北民族大學學報(自然科學版),2011,32(3):13-18.
[19]李冠宇,孟猛.藏語拉薩話大詞表連續(xù)語音識別聲學模型研 究[J].計算機工程,2012,38(5):189-191.
[20]李照耀,藏語連續(xù)語音識別的語言模型研究[D].蘭州:西北民族大學,2014.
[21]仁青吉,安見才讓.藏語語言模型的研究[J].信息與電腦(理論版),2015(6):94,96.
[22]張?zhí)?基于MPE藏語拉薩話區(qū)分度聲學模型研究[D].蘭州:西北民族大學,2017.
[23]周楠,基于深度學習的藏語非特定人連續(xù)語音識別研究[D].北京:中央民族大學,2017.
[24]申彤彤.基于循環(huán)神經網絡的藏語語言模型研究[D].天津大學,2018.
[25]黃曉輝,李京.基于循環(huán)神經網絡的藏語語音識別聲學模型[Jl.中文信息學報,2018,32(5):49-55.
[26]孫媛,王麗客,郭莉莉,基于改進詞向量GRU神經網絡模型的藏語實體關系抽取[J].中文信息學報,2019,33(6):35-41.
【通聯(lián)編輯:唐一東】
基金項目:本文受國家重點研發(fā)計劃重點專項《藏文文獻資源數(shù)字化技術集成與應用示范(2017YFB1402200)》和西藏自治區(qū)教育廳“計算機及藏文信息技術國家級團隊和重點實驗室建設”(藏教財指[2018]81號)資助
作者簡介:郭楊(1992-),男,山西長治人,西藏大學在讀研究生,研究方向:藏語語言模型;通訊作者簡介:擁措(1974-),女(藏族),通信作者,副教授,主要研究領域:自然語言處理,模式識別。
