基于ARIMA-BP組合模型的房地產(chǎn)價格預(yù)測方法研究
2020-05-21 05:54:57尤豫心陳繼紅
電腦知識與技術(shù) 2020年9期
尤豫心 陳繼紅

摘要:針對使用單一預(yù)測模型存在數(shù)據(jù)特征提取不充分,預(yù)測精度不高的問題,提出了一種基于ARIMA-BP組合模型的房地產(chǎn)價格預(yù)測方法。結(jié)合ARIMA模型處理線性問題的優(yōu)勢以及BP神經(jīng)網(wǎng)絡(luò)模型在非線性問題上的優(yōu)勢,利用誤差方差加權(quán)平均訓(xùn)練法訓(xùn)練出最佳權(quán)重的組合并建立組合模型對某市區(qū)房地產(chǎn)價格和趨勢預(yù)測進行實證分析。理論分析和實驗結(jié)果表明,所提兩者的組合模型有效解決了不能充分提取數(shù)據(jù)特征,預(yù)測精度不理想的問題,比單一預(yù)測模型能獲得更準(zhǔn)確的預(yù)測效果。
關(guān)鍵詞:房地產(chǎn)價格;ARIMA模型;BP神經(jīng)網(wǎng)絡(luò)模型;組合模型;趨勢預(yù)測
中圖分類號:TP391文獻標(biāo)識碼:A
文章編號:1009-3044(2020)09-0264-06
1 引言
當(dāng)今時代,房地產(chǎn)業(yè)是我國國民經(jīng)濟的支柱型產(chǎn)業(yè),它在國民經(jīng)濟中具有高度的產(chǎn)業(yè)關(guān)聯(lián)度,是推動整個國家國民經(jīng)濟發(fā)展、加速實現(xiàn)工業(yè)化和城市化的主導(dǎo)力量。房地產(chǎn)業(yè)持續(xù)健康有序的發(fā)展在國家經(jīng)濟的運作、政治的建筑、人民生活水平的改善中占據(jù)舉足輕重的地位。然而,由于影響房地產(chǎn)發(fā)展的因素多種多樣,例如,社會狀況、人口密度、房地產(chǎn)價格政策、稅收政策、城市發(fā)展規(guī)劃、宏觀經(jīng)濟狀況、物價狀況、居民收入狀況、自然因素和區(qū)域因素等都對房地產(chǎn)的發(fā)展有著不同程度的影響,致使房地產(chǎn)市場發(fā)展不成熟,部分城市存在嚴(yán)重的區(qū)域差異問題,嚴(yán)重影響我國經(jīng)濟的突飛猛進以及進入世界強國的步伐。因此,基于數(shù)據(jù)挖掘技術(shù)探索出一套實用的預(yù)測方案研究房地產(chǎn)價格的變化趨勢迫在眉睫。面對海量的房地產(chǎn)數(shù)據(jù),如何分析挖掘出有價值的數(shù)據(jù),如何通過大量數(shù)據(jù)揭示一種新的關(guān)系、趨勢和模式成為一個研究熱點。
文獻[1]結(jié)合AR模型良好的模型辨識能力和神經(jīng)網(wǎng)絡(luò)良好的非線性映射能力以及遺傳算法的全局最優(yōu)能力,改進算法并建立IGA-NARLMBP預(yù)測模型用來預(yù)測都江堰上游來水。
文獻[2]利用時間序列分析方法,以時間序列的平均值、標(biāo)準(zhǔn)差、ACF系數(shù)、PACF系數(shù)及AIC值、BIC值等參數(shù)與模型的評價準(zhǔn)則,建立陜西省GDP時間序列模型,預(yù)測未來6年的經(jīng)濟發(fā)展。
文獻[3]基于具有代表性的ARIMA模型與BP神經(jīng)網(wǎng)絡(luò)模型建立了針對某餐飲020企業(yè)的組合模型,并分別對整體、商家、城市三種企業(yè)不同的預(yù)測場景進行了模型的實現(xiàn)與驗證。
除此之外,文獻[4]采用時間序列AR模型進行震動趨勢預(yù)測,通過ARIMA模型的平穩(wěn)化處理,將非平穩(wěn)的序列平穩(wěn)化,模型參數(shù)估計使用了參數(shù)估計無偏、精度高的最小二乘法,驗證結(jié)果表明AR模型能夠很好地擬合振動信號時間序列,達到了理想的預(yù)測精度。文獻[5]提出了組合預(yù)測的思想,將參與組合的各種預(yù)測結(jié)果通過合適的方法進行組合,取其精華,棄其糟粕,獲取最優(yōu)預(yù)測結(jié)果。
目前,組合預(yù)測理論已經(jīng)證明:多種預(yù)測模型的組合在一定的條件下能更有效地改善模型的擬合能力和提高預(yù)測精度[6]。將統(tǒng)計方法的代表ARIMA模型與人工智能方法BP神經(jīng)網(wǎng)絡(luò)有機結(jié)合,充分發(fā)揮二者的優(yōu)勢,建立房地產(chǎn)價格預(yù)測模型,研究房價的變化趨勢并對房價進行預(yù)測,有助于房地產(chǎn)行業(yè)有序發(fā)展。
2 房地產(chǎn)價格預(yù)測模型
2.1 ARIMA模型
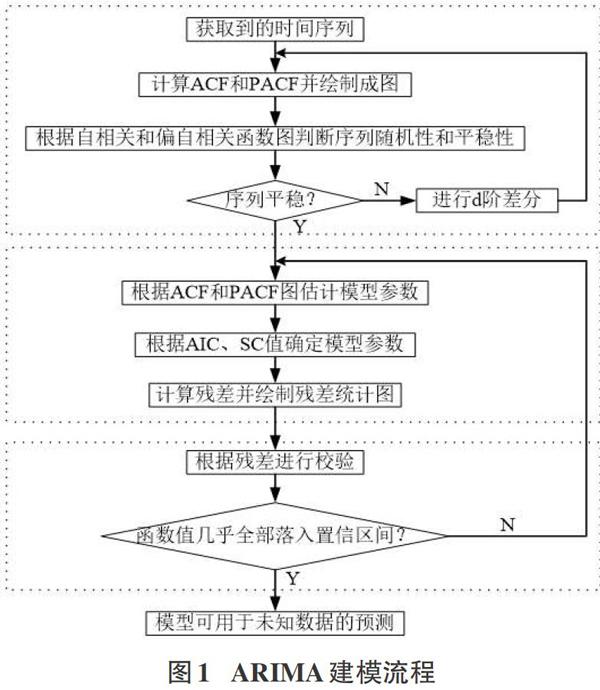
時間序列模型是一種重要的現(xiàn)代統(tǒng)計分析方法,廣泛應(yīng)用于自然領(lǐng)域、社會領(lǐng)域和科學(xué)研究等。作為一種重要的時間序列模型,差分自回歸移動平均模型( Autoregressive IntegratedMoving Average Model,ARIMA),得到了廣泛的應(yīng)用[7,8]。它是由Box等[9]提出的一種時間序列建模方法,主要由三部分組成,分別為AR(P)自回歸模型、MA(q)模型、ARMA(p,q)模型,模型建模步驟簡單,其變量主要借助內(nèi)生而不依賴于其他外生變量,但在建模前必須要求序列具備平穩(wěn)性與隨機性特征。基于ARI-MA模型的房地產(chǎn)價格趨勢預(yù)測方法的建模主要涉及四個步驟:數(shù)據(jù)的平穩(wěn)化處理,序列平穩(wěn)化,模型的識別與定階,模型的校驗,具體流程如圖1所示。
在模型的識別與定階階段,重點在于根據(jù)自相關(guān)與偏自相關(guān)函數(shù)的拖尾、截尾情況來確定具體需建立哪種模型最為合適,具體的模型識別規(guī)則參照表1。
2.2 BP神經(jīng)網(wǎng)絡(luò)模型
大數(shù)據(jù)時代,人工智能方法在預(yù)測、關(guān)系擬合、分類等領(lǐng)域已廣泛應(yīng)用。對于非線性系統(tǒng),神經(jīng)網(wǎng)絡(luò)具有通過學(xué)習(xí)逼近任意非線性映射的能力,將神經(jīng)網(wǎng)絡(luò)應(yīng)用于非線性系統(tǒng)的辨識和預(yù)測,可以不受非線性模型的限制。
自1982年Hopfield發(fā)表了關(guān)于自反饋神經(jīng)網(wǎng)絡(luò)的文章[10]以及Rumelhart等人發(fā)表了專著PDP[11]以來,研究神經(jīng)網(wǎng)絡(luò)的熱潮便在世界范圍內(nèi)掀起。隨后,BP神經(jīng)網(wǎng)絡(luò)在1986年由Ru-melhart和McCelland為首的科學(xué)小組提出,是一種按照誤差逆向傳播算法訓(xùn)練的多層前饋網(wǎng)絡(luò),由1個輸入層、若干隱含層和1個輸出層構(gòu)成[12]。同層的神經(jīng)元之間并無關(guān)聯(lián),異層的神經(jīng)元之間則前向連接。BP神經(jīng)網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)如圖2所示。
在整個BP中,重要的是兩個環(huán)節(jié),第一環(huán)節(jié)是信號實現(xiàn)從輸入層到輸出層的前向傳播,另一部分是在輸出層未得到期望輸出時,誤差信號則會繼續(xù)沿著原來的網(wǎng)絡(luò)連接路線返回并通過不斷修改各層之間的權(quán)值以得到最終的期望誤差。目前,BP神經(jīng)網(wǎng)絡(luò)在函數(shù)逼近、系統(tǒng)辨識與預(yù)測、分類以及數(shù)據(jù)壓縮等方面均發(fā)揮著不可替代的作用,成為人工智能領(lǐng)域的熱門[13]。
BP神經(jīng)網(wǎng)絡(luò)作為人工智能領(lǐng)域的代表,具有較強的非線性映射能力,能夠以任意精度逼近任何非線性連續(xù)函數(shù);良好的自學(xué)習(xí)和自適應(yīng)能力,便于將學(xué)習(xí)內(nèi)容記憶到網(wǎng)絡(luò)的權(quán)值中去;良好的泛化能力與容錯能力,有益于將學(xué)習(xí)成果應(yīng)用于新知識。當(dāng)然,BP算法也有其固有的缺點[l4],算法容易陷入局部極值導(dǎo)致網(wǎng)絡(luò)訓(xùn)練失敗、算法存在預(yù)測能力與訓(xùn)練能力矛盾問題,有時訓(xùn)練達到某種極限后,訓(xùn)練能力雖然提高了,預(yù)測能力反而會下降,導(dǎo)致過擬合現(xiàn)象。一般情況下,BP神經(jīng)網(wǎng)絡(luò)建模過程為:
(1)網(wǎng)絡(luò)初始化,即給輸入變量,各連接權(quán)值等分別賦予一個數(shù)據(jù)歸一化變換,將數(shù)據(jù)映射為[-1,1]內(nèi)的隨機數(shù),并設(shè)定好相關(guān)參數(shù),誤差函數(shù)、精度值以及最大的學(xué)習(xí)次數(shù)等[15]。隨后,取樣本序列作為輸入,并選出合適的激活函數(shù),一般Sigmoid函數(shù)較為常用,公式為:
(2)信號利用激活函數(shù)沿著網(wǎng)絡(luò)正向傳遞,分別得到隱含層和輸出層的輸出以及損失函數(shù)的期望值,損失函數(shù)計算公式為:
其中0表示參數(shù)集合,y表示真實值,y表示預(yù)測值,1/n表示總誤差的平均值。
(3)若輸出結(jié)果未達到期望誤差,則誤差信號在網(wǎng)絡(luò)中反向傳播,并根據(jù)誤差不斷更新網(wǎng)絡(luò)中的權(quán)值和偏置項。
(4)重復(fù)以上2-3步,直到最大學(xué)習(xí)次數(shù)用完或者損失函數(shù)小于事先給定的閾值,此時網(wǎng)絡(luò)中的各參數(shù)即為模型最佳參數(shù),則模型訓(xùn)練結(jié)束,可用于實時預(yù)測。
2.3 組合模型
各個單項預(yù)測模型的方法和原理各不相同,不同預(yù)測模型挖掘信息的角度也不同,它們之間的關(guān)系不是相互沖突的,而是相互關(guān)聯(lián),互相補充的[16]。在實際預(yù)測中,如果因為某項模型預(yù)測誤差偏大而丟棄,則會導(dǎo)致該項模型所能挖掘出的有用信息缺失,造成更大的誤差。多項研究證明,將多個單項預(yù)測模型選擇性結(jié)合形成組合模型,更能有效降低預(yù)測誤差,提高模型精度,進而提出組合模型的概念。
組合模型是提高模型預(yù)測精度的最佳方法之一,可依據(jù)特定的方法對各種子模型預(yù)測精度效果進行權(quán)衡、分配權(quán)重,基于預(yù)測精度高的模型權(quán)重大,預(yù)測精度小的模型權(quán)重小的原則,選取合適的權(quán)重判定方法對組合模型進行驗證對最終的預(yù)測效果至關(guān)重要。常用的組合模型判定方法有以下三種:
1)等權(quán)平均法:即將各子模型的權(quán)重平均化,各子模型權(quán)重相等,權(quán)重總和為1。公式為:
通過組合模型的創(chuàng)建,綜合多種單項預(yù)測模型的結(jié)果,可為數(shù)據(jù)的預(yù)測和分析提供更精準(zhǔn)的預(yù)測方法,得到更為系統(tǒng)、全面的預(yù)測效果。
3 模型應(yīng)用
作為江蘇長江經(jīng)濟帶的重要組成部分,南通集“黃金海岸”和“黃金水道”優(yōu)勢于一體,具有巨大的發(fā)展?jié)摿Α1疚倪x取南通市某區(qū)2013年01月至2017年12月,共計60個月的數(shù)據(jù)用于建立模型,2018年01月至02月的數(shù)據(jù)為校驗數(shù)據(jù),驗證模型的精確度。以此為例,闡述預(yù)測過程。
3.1 ARIMA模型建立
1)數(shù)據(jù)清洗
借助SQL Sever平臺提取2013-2017年房地產(chǎn)每月銷售均價,對其進行數(shù)據(jù)清洗工作,剔除保障性限價房、安置房、車庫等特殊房源數(shù)據(jù),利用SPSS工具對一些離群點進行數(shù)據(jù)轉(zhuǎn)換,使其在一定程度上接近正常值,盡可能減少對預(yù)測結(jié)果的影響。
2)序列平穩(wěn)化處理
對于時間序列的平穩(wěn)性處理與判定,本文案例基于兩種數(shù)據(jù)分析工具,采用兩種方法進行判定。初步采用SPSS 23.0工具繪制時間序列的自相關(guān)與偏自相關(guān)函數(shù)圖進行判定,若序列平穩(wěn),則不做處理,若不平穩(wěn),則通過差分平穩(wěn)化,本文案例通過一階差分后的自相關(guān)與偏自相關(guān)函數(shù)如圖3所示:
由上圖可知當(dāng)K>3時,自相關(guān)函數(shù)圖都落人置信區(qū)間,且逐漸趨向于0,證明序列具備平穩(wěn)性和隨機性,驗證了差分次數(shù)的正確性。
為了再次驗證其準(zhǔn)確性,基于Eviewsl0.0工具,對上述差分次數(shù)后的時間序列進行單位根校驗,校驗結(jié)果如圖4所示:
由一階差分后的單位根校驗結(jié)果圖可知,在1%,5%和10%的顯著性水平下,檢驗統(tǒng)計量均小于相應(yīng)的DW臨界值,從而拒絕H0,再次驗證序列的平穩(wěn)性與隨機性,可用于模型的識別與定階。
3)模型識別與定階
ARIMA模型的建立涉及參數(shù)的估計與階數(shù)的確定,可基于計算時間序列yt的自相關(guān)與偏自相關(guān)函數(shù),即觀察上述圖3,并根據(jù)模型識別規(guī)則來確定,借助Eviewsl0.0工具所計算出模型參數(shù)估計如圖5所示:
4)模型校驗
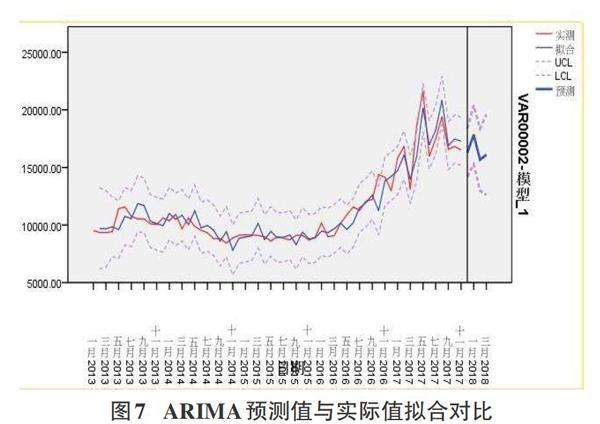
傳統(tǒng)的模型檢驗為DW統(tǒng)計量檢驗,使用該檢驗方法需滿足三個條件:一階自相關(guān)、回歸中有截距項、回歸因子無滯后項[7]。而本文案例采用觀察殘差自相關(guān)函數(shù)圖的結(jié)果以及最終ARIMA模型擬合圖進行校驗,校驗結(jié)果如圖6、7所示。
由上圖可知,殘差序列幾乎全部落人置信區(qū)間,驗證了數(shù)據(jù)序列為白噪聲,即通過檢驗。月均價實際值與模型預(yù)測值達到了很好地擬合,再次驗證模型通過校驗。
3.2 BP神經(jīng)網(wǎng)絡(luò)模型建立
1)數(shù)據(jù)預(yù)處理
BP神經(jīng)網(wǎng)絡(luò)收集到的數(shù)據(jù)與網(wǎng)絡(luò)模型算法要求的數(shù)據(jù)具備一致性,在建模之前,需對數(shù)據(jù)進行歸一化處理,借助MAT-LAB的Mapminmax函數(shù)實現(xiàn),函數(shù)負(fù)責(zé)將矩陣的每一行數(shù)據(jù)壓縮到[-1,l]。基于數(shù)據(jù)挖掘技術(shù)可得到月均價時間序列x0, X1, X2,…,Xk, Xk+l, Xk+2,",Xk+i,將XO, X1,X2,…,Xk作為訓(xùn)練樣本用于建立模型,Xk+1,Xk+2,…,Xk+1作為測試樣本用于驗證模型的準(zhǔn)確性。房價數(shù)據(jù)具備波動性,每個月不斷地更新變化,選取距離當(dāng)下日期越近的數(shù)據(jù)用于建模,模型對未來預(yù)測準(zhǔn)確性的影響力度越大。本文案例中,為了充分利用數(shù)據(jù),不斷使新數(shù)據(jù)覆蓋舊數(shù)據(jù),選取每相鄰三個月的數(shù)據(jù)預(yù)測下一個月的數(shù)據(jù),如對2018年01月的數(shù)據(jù)進行預(yù)測,則選取2017年10月、11月、12月的數(shù)據(jù)用于訓(xùn)練。
2)網(wǎng)絡(luò)參數(shù)設(shè)計
(1)輸入層與輸出層節(jié)點設(shè)置
本文案例中,選取的策略是以近鄰三個月的數(shù)據(jù)預(yù)測下一個月的數(shù)據(jù),即可確定輸入層節(jié)點數(shù)為3,輸出層節(jié)點數(shù)為1。
(2)隱含層節(jié)點的設(shè)置
隱含層節(jié)點數(shù)的選擇直接影響神經(jīng)網(wǎng)絡(luò)模型的各項性能指標(biāo)。根據(jù)眾多研究學(xué)者的研究經(jīng)驗可得公式來確定具體的節(jié)點數(shù):h=√m+n+a,其中,h代表隱含層的節(jié)點數(shù),m、n代表輸入層與輸出層節(jié)點個數(shù),a為1-10之間的調(diào)節(jié)常數(shù),具體的h值可以通過實驗進行試探性的確定。
(3)訓(xùn)練函數(shù)的確定
BP中的訓(xùn)練函數(shù)直接影響B(tài)P算法的預(yù)測結(jié)果,負(fù)責(zé)調(diào)解權(quán)值和閾值,以使整體誤差最小化。具體選取的訓(xùn)練函數(shù)可以根據(jù)數(shù)據(jù)的特征以及經(jīng)驗試探性來確定。
(4)學(xué)習(xí)速率的確定
在BP神經(jīng)網(wǎng)絡(luò)中,學(xué)習(xí)速率的選擇直接影響算法迭代效率。本文案例選取的學(xué)習(xí)速率為0.01。
(5)期望誤差值
BP中的期望誤差值可以根據(jù)每次訓(xùn)練的結(jié)果對比來確定。通過多次實驗研究對比,本文案例的期望誤差值選取為0.001。
在數(shù)據(jù)預(yù)處理與建模思路確定以后,便可基于MATLAB環(huán)境搭建BP神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)預(yù)測模型,建立的BP神經(jīng)網(wǎng)絡(luò)訓(xùn)練圖及均方誤差圖如圖8、9所示。
依據(jù)圖8、9可知,本案例采取Levenberg- Marquardt算法,算法訓(xùn)練迭代次數(shù)達到113次時,均方誤差已達到期望誤差,訓(xùn)練結(jié)束,最終BP訓(xùn)練出的月均價擬合如圖10所示。
由擬合圖可以看出,網(wǎng)絡(luò)輸出房價與實際房價達到了較好的擬合效果。通過研究分析,自2013年01月至2017年12月,不同月份之間的月均價上下波動,但總體的房地產(chǎn)價格走勢呈現(xiàn)上升趨勢,由前期48個月的緩慢上升,到后期12個月的迅速上升趨勢,可總結(jié)出2017年的房價較其他幾年數(shù)據(jù)呈現(xiàn)極端性,這可能是因為國家經(jīng)濟宏觀調(diào)控、城市規(guī)劃變動或其他因素所致,對于房地產(chǎn)的趨勢預(yù)測來說,是一個值得額外關(guān)注的重點,更值得引起相關(guān)部門的關(guān)注。
綜合圖7和圖10中ARIMA和BP神經(jīng)網(wǎng)絡(luò)擬合結(jié)果可以看出,ARIMA模型很好的提取了數(shù)據(jù)的線性特征,模型預(yù)測出的房價趨勢與實際房價具備一致性,但對于個別區(qū)間的極值,未能準(zhǔn)確擬合。而通過BP神經(jīng)網(wǎng)絡(luò)的多次訓(xùn)練,除了預(yù)測趨勢一致外,實際值與預(yù)測值達到了高于ARIMA模型的擬合效果,幾乎全部擬合。
3.3 組合模型建立及校驗
通過實例分析可知,ARIMA模型能夠更好地提取出房地產(chǎn)數(shù)據(jù)之間的線性特征部分,而BP神經(jīng)網(wǎng)絡(luò)模型則最大限度地發(fā)揮了數(shù)據(jù)之間的非線性優(yōu)勢,因此,根據(jù)組合模型的相關(guān)理論,將二者結(jié)合建立組合模型效果更為有效。為了保持?jǐn)?shù)據(jù)集的一致性,選取南通市近60個月的房價數(shù)據(jù)進行建模。基于組合模型現(xiàn)有的權(quán)重判定理論,通過多次實驗對比分析,本文案例在原有誤差方差加權(quán)平均法的基礎(chǔ)上進行改進,采用誤差方差加權(quán)平均訓(xùn)練法對模型進行權(quán)重判定,建立ARIMA-BP并聯(lián)組合模型,對房價進行預(yù)測分析。建模具體思想為將ARI-MA模型和BP神經(jīng)網(wǎng)絡(luò)模型的訓(xùn)練擬合值作為組合模型的輸入向量,依據(jù)ARIMA模型與BP神經(jīng)網(wǎng)絡(luò)模型的預(yù)測結(jié)果計算誤差方差,再對其進行排序,隨后基于單一模型權(quán)重與誤差方差成反比原理賦予權(quán)重,并通過多次訓(xùn)練對比,不斷調(diào)整權(quán)重參數(shù),訓(xùn)練組合模型,以實現(xiàn)ARIMA-BP并聯(lián)組合模型的建立。組合模型為:
f(x)=w1 V1(X)+w2V2(X)
(12)
其中,wi為第i種模型的權(quán)重,V1 (X)、V2 (X)分別為ARI-MA模型和BP神經(jīng)網(wǎng)絡(luò)模型在x時間下的預(yù)測值。實驗結(jié)果顯示,ARIMA模型的誤差方差較大,預(yù)測精度相對較小,而BP神經(jīng)網(wǎng)絡(luò)模型的誤差方差較小,預(yù)測精度較大,且本文案例僅涉及兩種單項預(yù)測模型,故按照誤差方差加權(quán)平均法原則以及多次的實驗訓(xùn)練對比分析,借助Lingo軟件平臺,利用兩種單項預(yù)測模型的房價擬合值,最終計算得到組合模型的權(quán)重分別為0.33和0.67。
依據(jù)模型各項評價指標(biāo)理論基礎(chǔ),本文案例中用來驗證模型精度的指標(biāo)如下:
平均絕對百分比誤差(MAPE):
其中,yi表示真實值,yi表示預(yù)測值,n為單一模型的個數(shù)。
基于以上三種方法得到的各單項模型與組合模型擬合及預(yù)測對比結(jié)果如表2和表3所示:
從實驗結(jié)果可以看出,基于誤差方差加權(quán)平均訓(xùn)練法的組合模型具有較高的預(yù)測精度,在訓(xùn)練數(shù)據(jù)集一致的情況下,ARIMA模型的評價指標(biāo)較大,平均絕對百分比誤差為10%,BP神經(jīng)網(wǎng)絡(luò)模型次之,且精度明顯得以提高,而兩者的組合模型指標(biāo)又有了進一步的改善,為8.0%,顯示組合模型效果最佳。 本文在研究了近60個月份房地產(chǎn)價格的變化趨勢下,為了再次驗證組合模型的實用性,對2006年-2020年南通市崇川區(qū)商品住宅的銷售價格進行了預(yù)測分析,選取2006年-2018年的數(shù)據(jù)為訓(xùn)練集,2019、2020年的數(shù)據(jù)為測試集,預(yù)測結(jié)果如圖11所示。
由圖11實驗結(jié)果可知,隨著年份的更新迭代,崇川區(qū)的房價整體呈現(xiàn)增長趨勢,自2006至2011年增長趨勢較為平穩(wěn),在2011年呈現(xiàn)局部極大值,隨后四年有緩慢下降趨勢,過程較為平緩,但在2017年和2018年出現(xiàn)急劇增長,波動較大,這與國家政策的宏觀調(diào)控以及人們?nèi)粘5膭傂杈o密相關(guān)。基于對三種模型的比較分析,可以明顯看出三種模型的預(yù)測系列線與崇川區(qū)年均價系列線基本擬合,其中,組合模型幾乎完全擬合,達到了最為理想的效果,驗證了組合模型的實用性與優(yōu)越性。
4 結(jié)束語
利用各種單項模型建立組合模型實現(xiàn)對房地產(chǎn)價格的預(yù)測研究是一種有效的方法,具有較高的理論與實踐價值。本文介紹的基于誤差方差加權(quán)平均訓(xùn)練法的ARIMA-BP并聯(lián)組合模型實現(xiàn)了對房地產(chǎn)價格的精確預(yù)測效果,模型可靠,易于實現(xiàn),具有一定的應(yīng)用價值。
本文建立的模型也存在一些不足,以下幾個方面有待進一步的改進:
(1) BP神經(jīng)網(wǎng)絡(luò)易使算法陷入局部極值,致使最終訓(xùn)練失敗。本文所論述的組合模型對BP神經(jīng)網(wǎng)絡(luò)模型分配了較大的權(quán)重,可能會因此帶來弊端,影響預(yù)測效果,是需要進一步改善的地方。
(2)房地產(chǎn)價格的影響因素眾多,本文所做的各項研究均是基于時間序列預(yù)測方法進行的,未將影響房價變化的各種因素考慮在內(nèi),可能會使預(yù)測的結(jié)果較為片面,這需要進一步的擴展研究。
(3)數(shù)據(jù)集的數(shù)量多,參考的依據(jù)范圍大,對于模型預(yù)測的結(jié)果說服力度更強,本文所選取的數(shù)據(jù)集在數(shù)量上有所欠缺,這也需要在后期的研究中做出改進。
目前,組合模型的研究遍布于統(tǒng)計學(xué)、計算機學(xué)、大數(shù)據(jù)領(lǐng)域。綜合多個單項預(yù)測模型優(yōu)缺點建立組合模型的研究方向已得到一定的進展。隨著研究的深入,組合模型將具備更好的可用性與優(yōu)越性,應(yīng)用的領(lǐng)域空間必將得到進一步拓展。
參考文獻:
[1]羅鳳曼.時間序列預(yù)測模型及其算法研究[D].成都:四川大學(xué),2006.
[2]魏寧.時間序列分析方法研究及其在陜西省GDP預(yù)測中的應(yīng)用[D].楊凌:西北農(nóng)林科技大學(xué),2010.
[3]施佳.基于ARIMA-BP組合模型的某餐飲0:0企業(yè)訂單預(yù)測研究[D].北京:北京交通大學(xué),2018.
[4]徐峰,王志芳,王寶圣.AR模型應(yīng)用于振動信號趨勢預(yù)測的研究[J].清華大學(xué)學(xué)報(自然科學(xué)版),1999,39(4).
[5] Bates J M,Granger C W J.The combination of forecasts[J].Jour-nal of the Operational Research Society, 1969,20(4):451-468.
[6]秦大建,李志蜀.基于神經(jīng)網(wǎng)絡(luò)的時間序列組合預(yù)測模型研究及應(yīng)用[J].計算機應(yīng)用,2006,26(S1):129-131.
[7] Zhang G.Time series forecasting using a hybrid ARIMA and neural network modeI[J].Neurocomputing, 2003,50:159-175.
[8] Contreras J,Espinola R,Nogales F J,et al-ARIMA models topredict next-day electricity prices[Jl. IEEE Transactions onPower Systems, 2003,18(3):1014-1020.
[9] BOX G E P,JENKINS G M.Time Series Analysis, Forecast-ing and ControI[Ml. San Francisco: Holden day, 1970.
[10] Hopfield J J.Neural networks andphysical systems with emer-gent collective computational abilities.[Jl. PROCEEDINGS OFTHE NATIONAL ACADEMY OF SCIENCES OF THE UNIT-ED STATES OF AMERICA,1982,79:2554-2558.
[11] Rumelhart D E,McClelland J L,.Parallel distributed process-ing[M].The MIT Press, 1986.
[12]陳基純,王楓.房地產(chǎn)價格時間序列預(yù)測的BP神經(jīng)網(wǎng)絡(luò)方 法[J].統(tǒng)計與決策,2008(14):42-43. [13]李萍,曾令可,稅安澤,等,基于MATLAB的BP神經(jīng)網(wǎng)絡(luò)預(yù)測系統(tǒng)的設(shè)計[J].計算機應(yīng)用與軟件,2008,25 (4):149-150,184.
[14]楊曉帆,陳廷槐.人工神經(jīng)網(wǎng)絡(luò)固有的優(yōu)點和缺點[J].計算機科學(xué),1994,21(2):23-26.
[15]樊振宇.BP神經(jīng)網(wǎng)絡(luò)模型與學(xué)習(xí)算法[J].軟件導(dǎo)刊,2011,10(7):66-68.
[16]閆海霞.灰色組合預(yù)測方法在糧食產(chǎn)量中的應(yīng)用[D].西安:西安理工大學(xué),2009.
[17] Berkhin P.A Survey of Clustering Data Mining Techniques[J]. Grouping Multidimensional Data, 2006, 43(1):25-71.
【通聯(lián)編輯:梁書】
基金項目:國家自然科學(xué)基金自助項目(61872263)
作者簡介:尤豫心(1996-),女,河南南陽人,碩士研究生,研究方向為數(shù)據(jù)挖掘;陳繼紅(1966-),男,江蘇南通人,碩士研究生,副教授,研究方向為數(shù)據(jù)挖掘。
