
基于SVM的融合多特征TextRank關(guān)鍵詞提取算法
2020-05-25 02:30:57朱衍丞蔡滿春蘆天亮石興華丁祎姍
軟件導(dǎo)刊 2020年2期
關(guān)鍵詞:提取
朱衍丞 蔡滿春 蘆天亮 石興華 丁祎姍
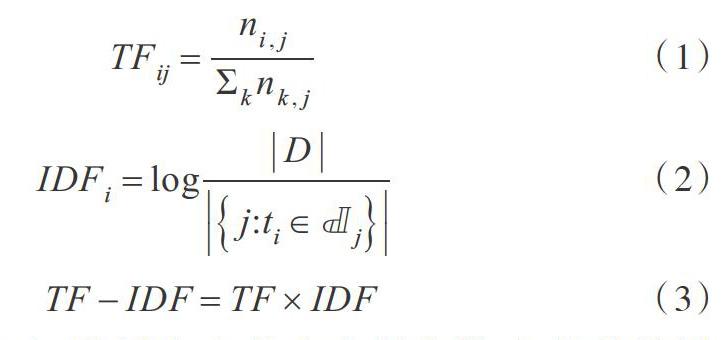


摘 要:網(wǎng)絡(luò)用戶通常使用關(guān)鍵詞篩選所需信息,但隨著網(wǎng)絡(luò)文本信息爆發(fā)式增長(zhǎng),且大多數(shù)文本信息不提供關(guān)鍵詞,用戶提取有效信息的難度不斷增大。利用關(guān)鍵詞提取算法可從文本數(shù)據(jù)中篩選出具有代表含義的關(guān)鍵詞,因此提出一種新型基于TextRank的關(guān)鍵詞提取算法。該算法利用每個(gè)詞的TF-IDF、詞向量、位置、詞性等特征,利用SVM訓(xùn)練得到的詞語(yǔ)初始權(quán)重,使用TextRank提取文本關(guān)鍵詞。實(shí)驗(yàn)表明,該算法準(zhǔn)確率達(dá)到78.09%,相較于傳統(tǒng)TextRank算法提高了32.18%,證明該算法具有一定的實(shí)用及參考價(jià)值。
關(guān)鍵詞:關(guān)鍵詞提取;支持向量機(jī);TextRank
DOI:10. 11907/rjdk. 192152 開(kāi)放科學(xué)(資源服務(wù))標(biāo)識(shí)碼(OSID):
中圖分類號(hào):TP312文獻(xiàn)標(biāo)識(shí)碼:A 文章編號(hào):1672-7800(2020)002-0088-04
英標(biāo):Research on SVM-based Fusion Multi-Feature Textrank Keyword Extraction Algorithm
英作:ZHU Yan-cheng,CAI Man-chun,SHI Xing-hua,LU Tian-liang,DING Yi-shan
英單:(Institute of Police Information and Cyber Security,Peoples Public Security University of China,Beijing 102628,China)
Abstract:Network users usually use keywords to filter the required information, but as the network text information grows explosively, and most text information does not provide keywords, it is more difficult for users to extract valid information. The keyword extraction algorithm can be used to filter out the keywords with representative meanings from the text data. Therefore, a new TextRank keyword extraction algorithm is proposed. This algorithm uses the TF-IDF, word2vec, position, part of speech and other attributes of each word as well as the initial weights of the words obtained by SVM training. On this basis, TextRank algorithm is used to extract the keyword. The experimental result shows that the accuracy of the algorithm reaches 78.09%, which is 32.18% higher than the traditional TextRank algorithm. The results prove that the algorithm designed in this paper has certain practical and reference value.
Key Words: keyword extraction; support vector machines; TextRank
0 引言
關(guān)鍵詞提取是自然語(yǔ)言處理中的一個(gè)重要子任務(wù)。關(guān)鍵詞是可反映文本主題或主要內(nèi)容的詞語(yǔ)。準(zhǔn)確提取文本關(guān)鍵詞在信息檢索、對(duì)話系統(tǒng)及文本分類方面具有重要意義。
在不支持全文搜索的文獻(xiàn)檢索初期,關(guān)鍵詞作為搜索論文的必要條件,是論文設(shè)計(jì)過(guò)程中不可或缺的部分,該項(xiàng)設(shè)置保留至今[1-2]。但近年來(lái),隨著網(wǎng)絡(luò)自媒體的快速發(fā)展,每個(gè)用戶都可成為網(wǎng)絡(luò)消息生產(chǎn)者、傳播者及消費(fèi)者,沒(méi)有提供關(guān)鍵詞的網(wǎng)絡(luò)信息每時(shí)每刻在大量產(chǎn)生。在實(shí)際應(yīng)用中,用戶通常更傾向于利用關(guān)鍵詞對(duì)網(wǎng)絡(luò)信息進(jìn)行識(shí)別、區(qū)分對(duì)自己有價(jià)值的信息,再對(duì)網(wǎng)絡(luò)信息進(jìn)行檢索、分類、聚類等操作。因此,一個(gè)有效的關(guān)鍵詞提取技術(shù)可幫助用戶實(shí)現(xiàn)快速搜索,獲取目標(biāo)信息。
傳統(tǒng)關(guān)鍵詞提取算法主要有TF-IDF、TextRank、LDA等基于無(wú)監(jiān)督的關(guān)鍵詞提取算法,這些算法通常建立在統(tǒng)計(jì)學(xué)分析基礎(chǔ)之上,基于候選詞詞頻、文檔頻率等統(tǒng)計(jì)信息篩選出關(guān)鍵詞,該類算法效率較高,在大量數(shù)據(jù)統(tǒng)計(jì)分析方面具有一定優(yōu)勢(shì),但同時(shí)往往忽略了候選詞所在文章的內(nèi)在結(jié)構(gòu)與關(guān)聯(lián)信息,導(dǎo)致關(guān)鍵詞提取效果不佳[3]。目前這些方法在英文文本上具有較好的效果,在中文中的應(yīng)用卻不盡如人意[4]。首先,漢語(yǔ)復(fù)雜性決定了任務(wù)難度,且大量長(zhǎng)句和復(fù)雜句法也給算法帶來(lái)了巨大挑戰(zhàn)[5]。此外,語(yǔ)料資源稀缺也是限制自然語(yǔ)言處理發(fā)展的重要原因之一[6]。
基于有監(jiān)督的關(guān)鍵詞提取方法,如SVM、Bayes等,利用提取算法分析大量文本,從而得到一種關(guān)鍵詞提取規(guī)則,該規(guī)則相較于基于無(wú)監(jiān)督的關(guān)鍵詞提取算法,獲取規(guī)則更加科學(xué)、有效,抽取的關(guān)鍵詞質(zhì)量大幅提高,但是基于有監(jiān)督的自動(dòng)關(guān)鍵詞提取算法不能提取文本關(guān)鍵詞,且操作過(guò)程較為復(fù)雜,使用不便[7-8]。
為提高關(guān)鍵詞提取準(zhǔn)確度,充分發(fā)揮有監(jiān)督與無(wú)監(jiān)督關(guān)鍵詞提取算法的優(yōu)點(diǎn)、克服其缺點(diǎn),本文提出一種基于TextRank的關(guān)鍵詞提取模型,該模型使用Word2Vec算法提取詞的語(yǔ)意屬性,結(jié)合位置權(quán)值、TF-IDF值,詞性等屬性,利用SVM算法,對(duì)文本不同詞進(jìn)行學(xué)習(xí),預(yù)測(cè)其為關(guān)鍵詞的可能性(用百分比表示),并作為TextRank初始權(quán)值,進(jìn)行關(guān)鍵詞提取[9-10]。
為降低語(yǔ)料規(guī)模與領(lǐng)域性方面的影響,本文使用共計(jì)65萬(wàn)多條所有欄目的新聞文本及新聞編輯篩選的關(guān)鍵詞作為訓(xùn)練及測(cè)試樣本[11]。
1 相關(guān)研究
1.1 數(shù)據(jù)分析
本文數(shù)據(jù)均來(lái)自于網(wǎng)上爬取的新聞數(shù)據(jù)及其關(guān)鍵詞(關(guān)鍵詞數(shù)量大于或等于1),利用Python的jieba包對(duì)文本數(shù)據(jù)進(jìn)行分詞并標(biāo)注詞性。在實(shí)際測(cè)試中,經(jīng)過(guò)人工篩選的關(guān)鍵詞往往屬于人名、地名及短語(yǔ),故將所有關(guān)鍵詞取出生成詞表,加入到j(luò)ieba詞典庫(kù)中,提高分詞效果,減小因分詞算法缺陷造成的誤差。
本文新聞樣本中的關(guān)鍵詞是編者基于真實(shí)用戶需求提取的,這些關(guān)鍵詞涵蓋了新聞關(guān)鍵信息,可使讀者更快速地了解相關(guān)新聞主旨并選擇是否詳細(xì)閱讀。從現(xiàn)狀來(lái)看,常規(guī)基于統(tǒng)計(jì)的關(guān)鍵詞提取算法在該類新聞樣本上測(cè)試效果不好。同時(shí)對(duì)于傳統(tǒng)算法,生成的結(jié)果形式是一個(gè)詞對(duì)應(yīng)一個(gè)權(quán)值,按照權(quán)值從大到小排序后,選取一定數(shù)量靠前的詞作為文本關(guān)鍵詞。考慮到現(xiàn)實(shí)情況,根據(jù)閾值對(duì)關(guān)鍵詞進(jìn)行篩選,該閾值為根據(jù)預(yù)測(cè)關(guān)鍵詞總數(shù)與實(shí)際關(guān)鍵詞總數(shù)比值約為2時(shí)對(duì)應(yīng)的閾值。
1.2 傳統(tǒng)算法測(cè)評(píng)
詞頻-逆文本頻率((Term Frequency-Inverse Document Frequency,TF-IDF)由兩部分組成。詞頻指某個(gè)給定的詞語(yǔ)在單個(gè)文本中出現(xiàn)的頻率;逆文本頻率由包含文本總數(shù)目除以包含該給定單詞的文本數(shù)目。計(jì)算公式為:
其中詞頻(TF)=某詞在文章中出現(xiàn)次數(shù)/文章的總詞數(shù),逆文檔頻率(IDF)=log(文本的總數(shù)/包含該詞的文本數(shù)+1)。
經(jīng)過(guò)統(tǒng)計(jì)分析,設(shè)定TF-IDF閾值為0.156,統(tǒng)計(jì)結(jié)果見(jiàn)表1。
TextRank算法基于PageRank,是一種基于圖的模型,通過(guò)構(gòu)建拓?fù)浣Y(jié)構(gòu)圖,對(duì)詞句進(jìn)行排序,一般用于為文本生成關(guān)鍵詞和摘要。在關(guān)鍵詞自動(dòng)抽取領(lǐng)域,TextRank作為當(dāng)前主流方法,在各領(lǐng)域已有較成熟的應(yīng)用。本文在對(duì)算法進(jìn)行簡(jiǎn)單介紹后,基于當(dāng)前數(shù)據(jù)集進(jìn)行測(cè)評(píng)。
根據(jù)TextRank的定義,可將PageRank的公式改寫為:
由式(4)、式(5)可知,如果某詞后來(lái)出現(xiàn)頻率高,則該詞將比較重要,即TextRank值很大;在TextRank值很大的詞后面出現(xiàn)的詞,TextRank值也會(huì)有一定增幅。
其中,[w(vj,vi)]表示節(jié)點(diǎn)[vj]到節(jié)點(diǎn)[vi]的邊的轉(zhuǎn)移概率,[out(vj)]表示節(jié)點(diǎn)[vj]指向的所有點(diǎn)集合,[In(vi)]表示節(jié)點(diǎn)指向[vi]的所有點(diǎn)集合,[w(vi)]表示節(jié)點(diǎn)[vi]權(quán)值,每個(gè)節(jié)點(diǎn)初始權(quán)值相同。
經(jīng)過(guò)統(tǒng)計(jì)分析,設(shè)定TextRank閾值為2.20,統(tǒng)計(jì)結(jié)果見(jiàn)表2。
改進(jìn)的TextRank算法基于TextRank原理,利用不同規(guī)則生成初始權(quán)值提高TextRank效果,需復(fù)現(xiàn)兩種算法:TFIDF-TextRank算法與融合多特征的TextRank算法[12]。
基于TextRank的計(jì)算公式,將[w(vi)]分別定義為:
式中[α]是一個(gè)常數(shù),對(duì)于式(6),每個(gè)單詞的權(quán)重由TF-IDF值決定,對(duì)于式(7),[WFreq]、[WPos]、[WLoc]分別表示單詞平均信息熵、詞性權(quán)重、位置權(quán)重,其中[α]、[β]、[γ]是系數(shù)。
經(jīng)過(guò)統(tǒng)計(jì)分析,設(shè)定TFIDF-TextRank的閾值為3.30,融合多特征TextRank的閾值為2.30,統(tǒng)計(jì)結(jié)果見(jiàn)表3。
對(duì)比TF-IDF與TextRank及其相關(guān)改進(jìn)算法的結(jié)果可知,基于統(tǒng)計(jì)分析的傳統(tǒng)關(guān)鍵詞提取算法在當(dāng)前數(shù)據(jù)集上的效果較差,提取的關(guān)鍵詞往往只能作為參考[13-14]。相比之下,改進(jìn)后的TextRank算法效率較高,由此可知,關(guān)鍵詞不僅與其詞頻有關(guān),還與詞的其它屬性有關(guān)[15]。所以,為獲得效率較高的關(guān)鍵詞提取算法,必須改進(jìn)TextRank算法,充分利用該關(guān)鍵詞在文章中的其它信息,生成更好的初始權(quán)重,以提高關(guān)鍵詞提取準(zhǔn)確率。
2 算法創(chuàng)新
2.1 詞屬性選擇
基于關(guān)鍵詞的特點(diǎn),從統(tǒng)計(jì)學(xué)角度分析發(fā)現(xiàn),關(guān)鍵詞與非關(guān)鍵詞在其詞性、首次出現(xiàn)的位置(位置權(quán)重標(biāo)準(zhǔn)見(jiàn)表7)、TF-IDF值均存在明顯差異。對(duì)當(dāng)前數(shù)據(jù)集進(jìn)行統(tǒng)計(jì),結(jié)果如表4—表6所示。
鑒于通過(guò)以上幾種屬性無(wú)法對(duì)詞進(jìn)行語(yǔ)義層面的劃分,所以在模型中引入詞向量(Word2Vec)屬性。詞向量模型是一種簡(jiǎn)化的神經(jīng)網(wǎng)絡(luò),利用one-hot對(duì)句子進(jìn)行編碼,以相似度計(jì)算的方式,用指定長(zhǎng)度的向量表示每一個(gè)在句子中出現(xiàn)的詞[16],這一特定長(zhǎng)度的向量便稱為詞向量。
2.2 初始權(quán)重生成
以上屬性較為復(fù)雜,維度較大,往往很難通過(guò)人工設(shè)置權(quán)重的方式進(jìn)行計(jì)算。采用支持向量機(jī)(SVM)對(duì)詞的屬性進(jìn)行訓(xùn)練,以生成TextRank的初始權(quán)重。SVM以統(tǒng)計(jì)學(xué)的VC維理論與結(jié)構(gòu)風(fēng)險(xiǎn)最小原理為基礎(chǔ),在解決一系列實(shí)際問(wèn)題中表現(xiàn)出優(yōu)良的學(xué)習(xí)能力[17]。SVM不同于決策樹(shù)(DT)、樸素貝葉斯(NB)等分類算法,不僅在高維模式識(shí)別中表現(xiàn)出較好的效果,同時(shí)具有較強(qiáng)的泛化能力[18]。可以推測(cè),通過(guò)給TextRank設(shè)置更優(yōu)的初始權(quán)值可提高準(zhǔn)確度。因此,本文利用SVM對(duì)文本中的詞進(jìn)行訓(xùn)練以生成初始權(quán)值[19]。
在數(shù)據(jù)準(zhǔn)備階段,首先計(jì)算并生成相關(guān)詞的屬性信息(見(jiàn)表7)。其中關(guān)鍵詞標(biāo)簽為pos,非關(guān)鍵詞標(biāo)簽為neg。
訓(xùn)練中使用Python 的sclera包中的SVM類,對(duì)以上數(shù)據(jù)進(jìn)行訓(xùn)練。其中,參數(shù)C=0.8,kernel=linear,gamma=1,同時(shí),為了可以得到概率,將probability設(shè)為true。實(shí)驗(yàn)證明,用以上參數(shù)對(duì)模型進(jìn)行訓(xùn)練可得到較好的訓(xùn)練結(jié)果。
考慮到計(jì)算時(shí)間,本文采用其中1萬(wàn)篇文章,共計(jì)6萬(wàn)余詞,其中關(guān)鍵詞和非關(guān)鍵詞的比例為1∶1,對(duì)模型進(jìn)行訓(xùn)練。最終利用SVM模型對(duì)文章中每一個(gè)詞進(jìn)行判斷,以模型判斷為pos的概率,并作為TextRank初始權(quán)值。
3 結(jié)果分析
在實(shí)際應(yīng)用過(guò)程中,因?yàn)槟P洼^為復(fù)雜,每一次搜索及運(yùn)算時(shí)耗較大,所以本文在測(cè)試集中隨機(jī)取3萬(wàn)條文本進(jìn)行3次統(tǒng)計(jì)分析,取其平均值作為最終結(jié)果。設(shè)定該算法閾值為4.20,統(tǒng)計(jì)結(jié)果如表8所示。
相較于其它幾種算法,結(jié)合SVM提取特征的TextRank關(guān)鍵詞提取算法效果較好,且在大規(guī)模數(shù)據(jù)量上也能達(dá)到較平均的水平。
從該結(jié)果可以推斷出,關(guān)鍵詞與其它詞在位置權(quán)重、詞性、TF-IDF值及詞向量等特征上具有明顯區(qū)別。在使用多種特征對(duì)詞進(jìn)行篩選時(shí),SVM可以對(duì)多種特征進(jìn)行有效整合,生成一個(gè)特征值,該特征值可作為權(quán)重使用,結(jié)合TextRank,得到的結(jié)果可超過(guò)其中單獨(dú)某個(gè)算法可達(dá)到的最佳值。
4 結(jié)語(yǔ)
與傳統(tǒng)TextRank及其它利用位置、TF-IDF等表征屬性的改進(jìn)型TextRank關(guān)鍵詞提取算法相比,本文結(jié)合SVM的TextRank關(guān)鍵詞提取算法在已有研究基礎(chǔ)之上,加入了詞性和詞向量等特征,并獨(dú)創(chuàng)性地使用SVM將這些特征有機(jī)結(jié)合起來(lái),顯著提高了TextRank算法效果。但該算法生成的模型較為簡(jiǎn)單,與基于理解的自然語(yǔ)言處理方法相比還存在較大差距[20],并且算法存在一定的局限性,還需進(jìn)一步優(yōu)化。
參考文獻(xiàn):
[1] 趙京勝,朱巧明,周國(guó)棟,等. 自動(dòng)關(guān)鍵詞抽取研究綜述[J]. 軟件學(xué)報(bào),2017,28(9):2431-2449.
[2] 劉嘯劍. 基于主題模型的關(guān)鍵詞抽取算法研究[D]. 合肥:合肥工業(yè)大學(xué), 2016.
[3] 方龍, 李信, 黃永,等. 學(xué)術(shù)文本的結(jié)構(gòu)功能識(shí)別——在關(guān)鍵詞自動(dòng)抽取中的應(yīng)用[J].? 情報(bào)學(xué)報(bào), 2017(6):67-73.
[4] NAN J,XIAO B,LIN Z, et al. Keywords extraction from chinese document based on complex network theory[C]. Hangzhou: 2014 Seventh International Symposium on Computational Intelligence and Design,2014.
[5] 張謙,高章敏,劉嘉勇,等. 基于Word2vec的微博短文本分類研究[J]. 信息網(wǎng)絡(luò)安全, 2017(1):57-62.
[6] 盛晨,孔芳,周國(guó)棟. 中文篇章零元素語(yǔ)料庫(kù)構(gòu)建[J]. 北京大學(xué)學(xué)報(bào):自然科學(xué)版, 2019, 55(1):18-24.
[7] GU Y,XIA T. Study on keyword extraction with LDA and TextRank combination[J].? New Technology of Library and Information Service, 2014,30:41-47.
[8] ZHANG K,XU H,TANG J,et al. Keyword extraction using support vector machine[M]. Berlin:Springer, 2006.
[9] 徐曉霖. 融合Log-Likelihood與TextRank的關(guān)鍵詞抽取研究[J].? 軟件導(dǎo)刊,2018,17(3):87-89.
[10] 寧建飛,劉降珍.? 融合Word2vec與TextRank的關(guān)鍵詞抽取研究[J].? 現(xiàn)代圖書(shū)情報(bào)技術(shù),2016(6):20-25.
[11] 徐冠華,趙景秀,楊紅亞,等. 文本特征提取方法研究綜述[J].? 軟件導(dǎo)刊,2018,17(5):17-22.
[12] 李航,唐超蘭, 楊賢,等.? 融合多特征的TextRank關(guān)鍵詞抽取方法[J].? 情報(bào)雜志, 2017(8):187-191.
[13] CHEN C H. Improved TFIDF in big news retrieval: an empirical study[J].? Pattern Recognition Letters, 2017,93:112-122.
[14] LI W,ZHAO J. TextRank algorithm by exploiting Wikipedia for short text keywords extraction[C]. IEEE International Conference on Information Science & Control Engineering,2016.
[15] TU S S, HUANG M L. Mining Microblog user interests based on TextRank with TF-IDF factor[J].? The Journal of China Universities of Posts and Telecommunications, 2016(5):44-50.
[16] ZUO X,ZHANG S,XIA J.? The enhancement of TextRank algorithm by using word2vec and its application on topic extraction[J].? Journal of Physics: Conference Series, 2017, 887:012028.
[17] GOLDBERG Y,ELHADAD M. splitSVM: fast, space-efficient, non-heuristic, polynomial kernel computation for NLP applications[C]. Meeting of the Association for Computational Linguistics on Human Language Technologies: Short Papers,2008:237-240.
[18] 丁世飛,齊丙娟,譚紅艷. 支持向量機(jī)理論與算法研究綜述[J].? 電子科技大學(xué)學(xué)報(bào),2011,40(1):2-10.
[19] 曹雪峰. SVM在決策樹(shù)歸納中的應(yīng)用[D]. 保定:河北大學(xué),2009.
[20] XU S, KONG F. Toward better keywords extraction[C].? Suzhou:International Conference on Asian Language Processing, 2015.
(責(zé)任編輯:江 艷)
猜你喜歡
法制博覽(2016年12期)2016-12-28 18:50:33
中國(guó)科技博覽(2016年24期)2016-12-28 17:53:32
綠色科技(2016年20期)2016-12-27 18:10:47
現(xiàn)代農(nóng)業(yè)科技(2016年20期)2016-12-20 14:58:09
文藝生活·中旬刊(2016年11期)2016-12-13 00:21:13
法制與社會(huì)(2016年32期)2016-12-01 16:28:51
中國(guó)科技縱橫(2016年17期)2016-11-30 11:49:34
企業(yè)技術(shù)開(kāi)發(fā)·下旬刊(2016年9期)2016-11-23 03:54:44
中學(xué)生物學(xué)(2016年10期)2016-11-19 12:48:29
文藝生活·中旬刊(2016年9期)2016-11-07 03:34:57
