基于降噪自編碼器的社會化推薦算法*
2020-06-02 00:19:02楊豐瑞李前洋羅思煩
計算機工程與科學 2020年5期
關鍵詞:用戶
楊豐瑞,李前洋,羅思煩
(1.重慶郵電大學通信與信息工程學院,重慶 400065;2.重慶郵電大學通信新技術應用研究中心,重慶 400065;3.重慶重郵信科(集團)股份有限公司,重慶 401121)
1 引言
隨著各類媒體和Web服務的快速發展,網絡中存儲的用戶信息迅速增長,信息超載成為一個重要的挑戰,如何幫助用戶定位自己感興趣的信息正變得空前重要。傳統的推薦系統僅僅挖掘用戶項目評級矩陣來提供建議,并不能提供足夠準確和可靠的預測。隨著在線交互平臺的出現,基于社交網絡的推薦方法得到了廣泛的應用。結合社交信息的推薦算法融入了用戶之間的關聯及其引發的相互影響,從而使得系統模型的建立更加真實和周全,推薦性能得以進一步提升[1 - 3]。針對用戶的偏好往往受其朋友影響的現象[4,5],相關學者提出了許多將社交信任信息集成到推薦系統的方法[6 - 9]。其結果表明,信任關系對于完善用戶偏好和提高推薦性能是有效的。
盡管現有研究提出了將信任信息納入推薦的不同算法,然而這些信任感知算法仍然存在2個關鍵問題。首先,它們大多采用淺模型直接建模信任關系,沒有利用到信任用戶的深層偏好信息。其次,現有推薦算法也未對信任用戶的影響程度進行有效的衡量。基于此,本文提出了利用深度學習技術有效衡量信任數據影響的算法。主要內容如下所示:
(1)利用2個降噪自編碼器來分別學習用戶及其信任用戶的高階潛在偏好,并將2個自編碼器與加權層融合,提出了SDAE(Social recommendation algorithm based on Denoising Auto-Encoder)算法,用于衡量信任用戶偏好對其目標用戶的影響。
(2)利用目標用戶與其信任用戶的評分差進行用戶聚類,為不同類的用戶分配不同的影響權重,提高推薦質量。
(3)在Epinions數據集上證明了相比于現有社會化推薦算法,本文算法在推薦精度上有所提升。
2 相關工作
近年來,可信推薦算法在提高推薦質量方面顯示出了巨大的潛力。特別地,Ma等人[3]提出了SoRec(Social Recommendation using probabilistic matrix factorization)算法,它是基于概率矩陣分解的推薦模型,通過共享用戶隱藏特征矩陣的方式整合了用戶的評分信息和用戶的社交信任信息。為了對推薦過程進行更加直觀、準確的模擬,Ma等人[10]進一步提出了RSTE(learning to Recommend with Social Trust Ensemble)算法,它綜合考慮了朋友喜好和用戶自身喜好,并假定用戶最終決定是兩者的折衷。Jamali等人[9]利用信任傳播機制對用戶偏好進行建模,并結合矩陣因子分解進行推薦,提出了SocialMF(a transitivity aware Matrix Factorization model for recommendation in Social networks)模型。Yang等人[7]在觀察到用戶對信任者和受信人的角色表現出不同偏好的基礎上,提出了TrustMF(Matrix Factorization based social collaborative filtering)算法來進一步提高推薦性能。
然而,這些算法都是利用淺層次的信任數據,忽略了用戶之間深層的潛在偏好交互。要從這些數據中學習高階信息,一個很大的挑戰是信任關系非常稀疏。針對這一問題,本文提出了一個深度模型來學習稀疏的淺層用戶數據,同時考慮信任用戶評級信息。該模型將2個獨立的降噪自編碼器[11]中間層融合到1個共享層中,使模型能夠有效地從這些數據的低層表示中提取高階關聯,為推薦提供依據。另外,針對不同用戶受信任關系影響程度的不同,本文通過聚類為用戶分配個性化權重,以進一步改善推薦質量。
2.1 社交關系
社交網絡是一種由多個節點和節點之間關系構成的社會結構[12]。其中,節點表示1個人或者社交網絡的1個參與者。社會化推薦算法一般基于這樣的假設:社交網絡中用戶喜好受其信任朋友偏好的影響,并且朋友之間具備類似的偏好。因此存在社交關系的用戶在選擇或傾向上,往往基于相互信任而表現出一定的相似性[13],在線社交網絡數據的日益可用性,讓社交網絡的潛力得以充分展現。在實際的社交評論網站 Epinions上,用戶可以在信任列表中添加自己信任的用戶。圖 1 是簡單的社交信任網絡圖,箭頭表示用戶的信任關系,其中雙向箭頭表示相互信任。在線社交網絡提供了一個獨立的信息源,可以使用它來提高推薦的質量[14]。

Figure 1 Schematic diagram of social trust relationship圖1 社交信任關系示意圖
2.2 降噪自編碼器
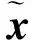

(1)

(2)
(3)
(4)
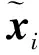
(5)

3 基于降噪自編碼器的社會化推薦算法
3.1 SDAE算法
基于社交趨同性的假設,社交網絡中存在關聯的人互相交流偏好信息,相互影響對方的決策[14,17]。信任用戶的影響,一方面體現在對目標用戶潛在偏好的改變,用戶對1件物品的偏好程度,一部分由自己產生,一部分受信任用戶影響,最終的用戶決策是兩者的綜合考量。另一方面體現在信任用戶偏好對目標用戶偏好的彌補,這種情況下的用戶往往直接借鑒其信任用戶的選擇,實際中稀疏的評分數據并不能完全表示出用戶的偏好信息。如圖2所示,為了對信任用戶的影響機制進行有效模擬,本文使用2個自動編碼器分別學習用戶及其信任用戶的評分數據,得到的用戶及其信任用戶的低維偏好,通過1個加權隱藏層來平衡隱藏層表示的重要性,有效建模用戶偏好的深層交互。本文提出的深度模型能從額外的社交信任信息中充分挖掘目標用戶的潛在偏好,進而改善推薦性能。
本節所述的混合模型如圖2所示,信任用戶評分數據由式(6)給出:
(6)
其中,Su表示用戶u的評分向量,Uu表示用戶u的信任用戶集合,Iu表示用戶u的信任用戶數,T表示社交信任網絡中得出的用戶信任值數據,通常為0或1。

Figure 2 Graphical model of SDAE圖2 SDAE圖模型
通過2個自編碼器隱藏層特征的加權融合來為信任用戶對目標用戶的潛在影響建模,首先使用編碼器層將目標用戶評級和信任用戶評級輸入映射到低維空間,該編碼層由式(7)和式(8)表示:
(7)
(8)

F為加權隱藏層的輸出,用來融合信任用戶偏好的間接影響,表示為:
(9)
其中,α是平衡信任用戶影響的權重因子,最后通過2個解碼器層對原始輸入數據進行重構。這2層由式(10)和式(11)表示:
(10)
(11)

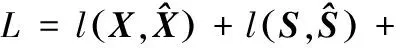
λΩ(WX,WS,W′X,W′S,b,c,b′,c′)
(12)
其中,l(·)為計算重構誤差的損失函數,Ω(·)為正則化項,定義為:
(13)
3.2 個性化權值計算
對信任影響機制進行深入探究,不難發現如果一名用戶傾向于接受來自好友偏好的影響,其評分相似性也會相對一致。因此,本文從用戶與其信任好友的評分一致性作為研究切入點,對用戶受其信任用戶的影響程度進行衡量。
若2個用戶具有較強的評分相似性,那么他們也應具有較小的評分差,本文利用評分差來衡量評分相似性,計算每個用戶的聚類特征,最后進行用戶聚類及區分。如圖3所示,首先計算目標用戶與其每個信任用戶在各個項目上的評分差,統計所有值為{0,1,2,3,4}的評分差的個數,并將其歸一化后作為目標用戶的分類特征。這樣得出的特征消除了項目之間的差異,能從整體上衡量用戶之間的評分差,且維度僅僅為5,計算復雜度較低。最后一步是將用戶按照分類特征進行聚類,通過為每個類別中的用戶賦予相同權值,得到個性化權值α。具體做法如下所示。
首先初始化特征中心,任意選擇m個用戶的分類特征向量作為m個類別d1,d2,…,dm的初始特征,以用戶與各個初始聚類中心的余弦相似度為依據,為其分配相似度最大的聚類中心所在類別。相似度計算如式(14)所示:
(14)
其中,fi,j表示用戶ui的信任特征的第j個分量,dk,j表示類別dk的特征的第j個分量。
下一次迭代時聚類中心dk更新為該類中所有用戶特征的均值。
最后以聚類中心所代表的評分差為依據為其代表的類別分配權重。聚類中心代表的評分差為其特征與{0,1,2,3,4}的內積,表示用戶在所有項目上的平均評分差值。評分差較大,說明該用戶與其他用戶的評分相似性較低,則為其代表的類別分配較大的權重α,表示此類用戶不易受好友影響;反之,則分配小權重。初始權重為3.1節確定的總體平衡點處的權重α,通過在其周圍均勻地取值為每一類用戶分配個性化權重。

Figure 3 Schematic diagram for calculating rating difference圖3 評分差計算示意圖
4 實驗分析
4.1 實驗數據和評價標準
為了驗證本文算法的有效性,在2個開源數據集Epinions(https:∥en.wikipedia.org/wiki/Epinions)和Ciao(https:∥en.wikipedia.org/wiki/Ciao_%28website%29)上進行驗證。本文對2個數據集進行了劃分,選取了其中對商品評價個數大于1并且至少有10個信任關系的用戶,經過過濾之后的數據集信息如表1所示。

Table 1 Statistics of experimental datasets
為了評估本文算法的有效性,從數據集中隨機選取80%的數據作為訓練集,留下20%作為測試集。本文采用五折交叉驗證的方法,取實驗結果的平均值作為實驗的最終結果。網絡采用隨機梯度下降法對損失函數進行優化,其網絡設置如表2所示。

Table 2 Parameter settings
本文采用常用的2種評測標準平均絕對誤差(MAE)和均方根誤差(RMSE)來量化算法的性能,其定義如下所示:
(15)
(16)
其中,n表示預測評分項的個數,rij表示用戶ui對項目vj的預測值,xij表示用戶ui對項目vj的真實的評分。MAE和RMSE值越小,說明算法性能越好,算法的預測值越接近于實際值。本文算法將與SoRec算法、RSTE算法、SocailMF算法、TrustMF算法進行對比實驗。
4.2 超參數對實驗的影響
本節主要討論2個參數λ和α對推薦效果的影響,其中λ為防止網絡過擬合的正則項系數,α為衡量信任用戶影響的因子。在驗證某個參數對實驗的影響時固定其它參數。
(1)確定參數α。
參數α主要作用是平衡信任用戶偏好的影響,如圖4所示,實驗中設定參數α的值為0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,1。其中α=0和α=1分別表示網絡只根據用戶評分和信任數據進行評分預測,2個數據集上效果皆不是最佳。這說明本文混合信任用戶評分偏好改善了系統整體的推薦性能。在Ciao和Epinions數據集上,當α=0.4和α=0.5時系統分別達到了一個平衡點,此時算法推薦性能最佳,當α取值過小時信任用戶作用過小,由于評分數據稀疏性,導致誤差大。當α取值過大時,信任用戶偏好所占比重過大,產生了多余的干擾,也會導致誤差過大,另外由于Epinions的數據相對更為稀疏,信任用戶對推薦的影響更顯著,因此最佳點處α較大。
(2)確定參數λ。
參數λ的作用是避免網絡過擬合,如圖5所示,在實驗中λ的取值分別為0.001,0.01,0.02,0.05,0.1,0.2,0.5。由圖5可以看出,在2個數據集Epinions和Ciao 上過擬合參數保持在一個數量級,λ取0.1時誤差最小,λ大于0.1時網絡過擬合,λ小于0.1時網絡欠擬合,效果皆不佳。

Figure 4 Effect of parameter α on recommendation accuracy圖4 參數α對推薦準確度的影響

Figure 5 Effect of parameter λ on recommendation accuracy圖5 參數λ對推薦準確度的影響
4.3 個性化權重的影響
實驗將聚類后的類別設置為2,具體的個性化權重的取值如表3所示,為了更全面地比較個性化權重算法的實驗效果,本節以上文得出的最佳α為基準點,并在基準點附近設置較大的初始波動范圍,后面的情形將2個類的差異逐漸縮小,各取5組實驗結果進行對比。具體的算法個性化權重取值如表3所示,α=0.62/0.18表示2類用戶的α分別取值為0.62和0.18。

Table 3 α values for SDAE algorithm
圖6中所示為通過用戶聚類為每一類用戶分配不同權重后的實驗結果。情形2至情形5中,2個數據集Ciao和Epinions 所對應的RMSE值分別優于α固定取0.4和0.5的情形,說明不同用戶受信任用戶的影響程度是不同的,采用個性化權重能夠改善系統的推薦性能。在情形1下,2個數據集對應的RMSE值比最優固定權重值時的RMSE值更大,分析其原因就是情形1的分配方案均較大地偏離了原有2類用戶的實際比重,導致實驗結果不佳。

Figure 6 Recommended results for personalized algorithm圖6 個性化算法推薦結果
4.4 訓練集的劃分影響
為了展現在不同比例訓練集下算法的推薦效果,本節分別對Ciao和Epinions數據集進行40%~80%訓練集劃分,實驗結果如圖7和圖8所示。

Figure 7 Comparison results on Ciao dataset圖7 Ciao數據集上對比結果

Figure 8 Comparison results on Epinions dataset圖8 Epinions數據集上對比結果
觀察圖7和圖8可以發現,隨著訓練集劃分比例的增加,各個算法的推薦效果不斷提高,原因是訓練集比例的增加減少了數據稀疏的影響。另外,本文算法在各個比例訓練集上都表現出良好的推薦效果,這是由于算法建模了信任用戶深度的偏好影響機制,從而獲得了更好的推薦性能。
4.5 最終對比實驗
本節實驗比較了SoRec、RSTE、SocialMF、TrustMF算法在Epinions數據集上的推薦效果,為了方便展示,將本文未加個性化權重的算法取名為SDAE,引入個性化權重后的算法取名為SDAE+,均取參數最優時的結果,即在Ciao數據集上SDAE取α=0.4,λ=0.1,SDAE+取α=0.52/0.28。在Epinions數據集上SDAE取α=0.5,λ=0.1,SDAE+取α=0.61/0.39。本節算法的對比實驗結果如表4所示。
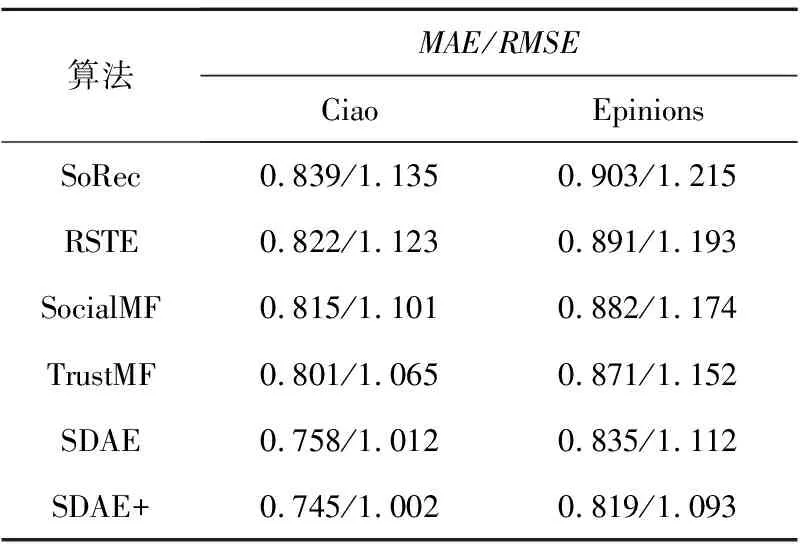
Table 4 Performance comparison of algorithms
從表4中可以看出,與其它算法相比,本文算法在推薦精度上有了明顯的提高,在Ciao數據集上SDAE算法相比于其他4種算法,MAE值和RMSE值分別降低了5.3%~9.6%和4.9%~10.8%,SDAE+算法的MAE值和RMSE值分別降低了6.9%~11.2%和5.9%~11.7%。在Epinions數據集上,SDAE的MAE值和RMSE值分別降低了4.1%~7.5%和3.4%~8.4%,SDAE+算法的MAE值和RMSE值分別降低了5.9%~9.3%和5.1%~10%。總體上來看,用戶評分數和信任數越稠密,算法效果越好。算法考慮了用戶及其信任用戶的高階潛在交互,能夠發現淺層線性模型無法挖掘的用戶潛在偏好,實驗結果充分證明了算法的正確性。另外為每類用戶分配不同的信任影響權重,取得了更好的推薦效果,也證明了實際社交網絡中的用戶受信任用戶的影響程度是不同的,可以借此來改善推薦質量。
5 結束語
本文提出了基于降噪自編碼器的社會化推薦算法,通過1個共享層將2個降噪自編碼器結合起來,從用戶及其信任用戶數據中學習深層的偏好信息,有效挖掘了社交關系中信任用戶的潛在作用。另外,本文通過分析用戶的評分相關性進行用戶聚類,并引入個性化權重值,實驗結果表明,本文算法是有效的。隨著數據采集技術的發展,推薦系統已經搜集到豐富的多源信息,設計可擴展性高的社交推薦模型,將更多額外信息有效融入推薦模型中將是下一步研究重點。同時,未來還將考慮到用戶興趣隨時間的變化,圍繞如何感知、建模這一規律展開研究。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
