基于數據挖掘判別用電類別異常的分析與研究
2020-06-08 08:31:54金昌鉉朱宇龍馬博劉森黎晚晴陳玲娜
科技與創新 2020年10期
金昌鉉,朱宇龍,馬博,劉森,黎晚晴,陳玲娜
基于數據挖掘判別用電類別異常的分析與研究
金昌鉉1,朱宇龍1,馬博1,劉森1,黎晚晴2,陳玲娜2
(1.中國南方電網有限責任公司,廣東 廣州 510000;2.南方電網數字電網研究院有限公司,廣東 廣州 510000)
隨著電網企業全面實現智能電表全覆蓋和低壓集抄全覆蓋,產生了海量實時的計量數據,這些數據通過分析挖掘技術,可在輔助電網規劃、電網運行狀態監控、負荷預測等方面發揮價值。然而,利用傳統的統計分析挖掘技術,較難處理如此海量的計量數據,也無法識別異常數據蘊藏的企業經營風險問題,因此,有必要引入大數據分析挖掘技術,運用分類預測算法進行異常分析,有效識別電網高價值用戶的用電類別異常。對電網企業用戶如高耗能行業用戶、一般工商業用戶、大工業用戶以及居民用戶的用電數據進行深入研究,從宏觀和微觀角度分別對用電行為數據進行特征提取和行為分析,刻畫出不同用電類別用戶的負荷曲線,歸納用電行為特征,運用有效監督的數據挖掘算法構建用電類別異常識別模型,并和用戶檔案中的用電類別數據進行核對,找出異常數據,輔助識別電能計算裝置使用異常、用戶檔案信息錯亂和電費收取錯誤等異常。
用電行為;數據挖掘;日負荷曲線;決策樹算法
1 引言
隨著智能電網的普及,電力自動化數據日漸增多,如何從這些海量的數據中挖掘出其隱藏的價值便顯得尤為重要。整個社會的用電量是無法估量的,用電的時間段、用電高峰的電力負荷、用電的需求這些都處于時時變化的狀態。大數據時代的到來,已推進了新興技術的突破,其中,分布式分析挖掘計算引擎Spark也帶給了人們挖掘海量數據的可能性,而數據的背后通常也隱藏了事物發展的潛在規律,用電數據也不例外。運用分類預測算法,從海量數據中挖掘出不同類別用戶的用電行為規律,是本文研究的核心內容。
通過閱讀大量的文獻發現,當前對用電用戶的研究大多集中在運用用戶基本信息和客戶服務數據構建標簽的用戶畫像相關的技術,但因數據質量問題,用戶標簽和其用電行為標簽未能完全匹配。
本研究運用大數據挖掘技術對電力客戶進行用電特征的分類分析,將得到的用戶分類與原始分類指標作對比,找出用電類別異常的用戶,輔助電網企業追回損失,也加深對客戶的了解,便于針對不同的用戶群制訂服務策略,實現精準客戶服務。
2 大數據挖掘算法
大數據挖掘是當今社會研究的熱點問題,所謂數據挖掘,是指從大量數據中揭示出隱含的、先前未知的并有潛在價值的信息的非平凡過程。通常分為有監督學習算法和無監督學習算法。其中,無監督學習算法是對沒有分類標記的訓練樣本識別其結構性知識,比如聚類分析。而有監督學習算法,是事先對具有標記(分類)信息的訓練樣本進行學習,再對樣本外的數據進行分類預測,也稱分類算法。常見的分類算法有決策樹、神經網絡、支撐向量機和貝葉斯等,不同的分類算法,由于原理的不同,存在各自的優缺點和適合的應用場景,各個算法的優缺點如表1所示。
表1 各個算法的優缺點
算法優點缺點 決策樹①不需要任何領域知識;②不需要參數假設;③適合維度較多的數據;④簡單、易用、容易理解;⑤執行效率高;⑥可同時處理數值型和字符型字段①當訓練樣本失衡時,信息增益偏向于那些具有更多數值的特征;②容易出現過擬合現象;③常忽略字段間的相關性;④不支持在線學習 神經網絡①分類準確率高;②并行處理能力強;③分布式存儲和學習能力強;④魯棒性較強,不易受噪聲影響①需要大量參數;②結果難以解釋;③訓練時間過長 支持向量機①可以解決小樣本下機器學習的問題;②提高泛化性能;③可以解決高維、非線性問題;④可以超高維文本分類問題;⑤避免神經網絡結構選擇和局部極小的問題①對缺失數據敏感;②內存消耗大,難以解釋;③運行和調參較為麻煩 貝葉斯①所需估計的參數少,對于缺失數據不敏;②有著堅實的數學基礎以及穩定的分類效率①需要假設字段間相互獨立;②需要知道先驗概率;③分類決策存在錯誤率
3 用電數據集與數據清洗
3.1 數據集
基于企業大數據中心,讀取企業營銷自動化積累的電量數據,選擇參與模型訓練的數據,主要包括計量點表、運行電能表、運行電能表日凍結電能量表、運行電能表日負荷極值表和用戶信息表等。其中運行電能表日凍結電能量表記錄
的是電能表總正向有功以及峰、平、谷各時間段的正向有功,用來說明用戶固定時間段的用電量;運行電能表日負荷極值表用于記錄電能表功率、電壓和電流等信息。
經篩選抽取后的數據基礎表結構如表2所示。
表2 數據基礎表結構
數據表構建指標數據類型指標說明 用電量計量點編號VARCHAR2(20)計量點的唯一編號 用戶編號VARCHAR2(20)用電客戶的唯一編號 用電時間Date包含日期和時分秒 最大功率Number(8,3)一天內最大的有功功率,即一天內最大負荷 平均功率Number(8,3)一天內有功功率平均值 用電客戶用戶編號VARCHAR2(20)用電客戶的唯一編號 負荷性質代碼VARCHAR2(8)負荷的重要程度分類 用電類別代碼VARCHAR2(8)定義客戶用電基本屬性分類及代碼,又稱用電類別 電壓等級代碼VARCHAR2(8)用電客戶受電點的電壓等級 行業分類代碼VARCHAR2(8)用電客戶的行業分類代碼 用戶類別代碼VARCHAR2(8)用戶一種常用的分類方式,方便用戶的管理 高耗能行業類別代碼VARCHAR2(8)依據國家最新的高耗能行業劃分 用電性質VARCHAR2(8)用電性質 用戶狀態代碼VARCHAR2(8)用電客戶的狀態說明 客戶分群標志VARCHAR2(8)客戶重要性分類類型(客戶分群代碼) 運行容量Number(15,4)用電客戶正在使用的合同容量 行政區域代碼VARCHAR2(8)用電客戶所在地址的行政區劃代碼 城鄉代碼VARCHAR2(8)用電客戶所在地址的城鄉代碼 計量點計量點編號VARCHAR2(20)計量點的唯一編號 用戶編號VARCHAR2(20)用電客戶的唯一編號 計量方式代碼VARCHAR2(8)主計量方式 計量點電壓等級代碼VARCHAR2(8)標明計量點的計量電壓等級 計量裝置分類代碼VARCHAR2(8)計量裝置分類主要根據用電量進行區分 計量點狀態代碼VARCHAR2(8)標明計量點的當前狀態 計量點類別代碼VARCHAR2(8)計量點類別代碼 計量點用途代碼VARCHAR2(8)定義計量點的主要用途 計量點位置代碼VARCHAR2(8)標明計量點所屬的具體位置 接線方式代碼VARCHAR2(8)計量點接線方式 用電容量Number(15,4)計量點用電容量 計量點類型代碼VARCHAR2(8)計量點類型代碼 運行電能表標識VARCHAR2(16)運行電能表的唯一標識
3.2 數據清洗
數據清洗是發現并糾正錯誤數據的第一道程序,包括檢查數據一致性、處理無效數據和缺失值等,數據清洗的目的是為了得到高質量的建模輸入數據,而分類算法通常要求輸入數據進行歸一化等方法處理,以便提高數據挖掘算法的執行效率。同時,由于數據挖掘算法往往只能對單一的數據表進行分析,因此就需要將相關數據整合成一個“寬表”,這個表每行都是代表一個用電戶,每列代表與用電戶用電性質潛在相關的影響因素,最后一列“用電性質”為分類算法的目標列。相關數據整合成的“寬表”如表3所示。
4 用電類別異常識別
4.1 模型變量選擇
4.1.1 特征選擇
為了縮小選擇范圍,提高模型的性能,需要對數據清洗后得到的“寬表”進行特征選擇,即字段篩選,通常采用以下幾種方式:根據數據的特征質量,過濾掉數據質量很差的字段;計算剩余的輸入字段對目標“用電性質”的重要性,選取一些對用目標字段影響較大的字段,減少數據挖掘算法的計算量,提高執行效率。
4.1.2 樣本數據選取
通常一個電網公司的用電戶數據量達千萬級別,如果在模型訓練階段就將所有的用電戶數據參與建模,則會出現算法執行時間過長,甚至細微的參數調整都會帶來重復執行的需求;另一方面,大工業用戶、一般工商業用戶、居民用戶的本身體量也不屬于一個數量等級,容易導致樣本失衡的問題。因此使用抽樣技術,分別選取不同類別的典型用戶數據參與模型訓練,可以有效提高算法執行效率。本文選取10個典型行業的計量點在當前年的所有特征指標及其組合指標,分析用戶的用電行為,既能保證樣本的抽樣覆蓋,也能避免遺漏用戶的季節性用電特征。
表3 相關數據整合成的“寬表”
構建指標數據類型指標說明 用戶編號VARCHAR2(20)用電客戶的唯一編號 用電日期Date數據時間 年份VARCHAR2(8)數據年份 月份VARCHAR2(8)數據月份 星期VARCHAR2(20)判斷數據日期是星期幾 是否節假日VARCHAR2(20)判斷當天是不是節假日 正向有功總Number(15,4)全天總用電量 正向9_12Number(15,4)一天時間段(09:00—12:00)用電量 正向14_17Number(15,4)一天時間段(14:00—17:00)用電量 正向19_22Number(15,4)一天時間段(19:00—22:00)用電量 正向2_5Number(15,4)一天時間段(02:00—05:00)用電量 最大功率Number(8,3)一天內最大的有功功率,即一天內最大負荷 平均功率Number(8,3)一天內有功功率平均值 負荷性質代碼VARCHAR2(8)負荷的重要程度分類 用電類別代碼VARCHAR2(8)定義客戶用電基本屬性分類及代碼,又稱用電類別 電壓等級代碼VARCHAR2(8)用電客戶受電點的電壓等級 行業分類代碼VARCHAR2(8)用電客戶的行業分類代碼 用戶類別代碼VARCHAR2(8)用戶一種常用的分類方式,方便用戶的管理 高耗能行業類別代碼VARCHAR2(8)依據國家最新的高耗能行業劃分 用戶狀態代碼VARCHAR2(8)用電客戶的狀態說明 客戶分群標志VARCHAR2(8)客戶重要性分類類型(客戶分群代碼) 運行容量Number(15,4)用電客戶正在使用的合同容量 行政區域代碼VARCHAR2(8)用電客戶所在地址的行政區劃代碼 城鄉代碼VARCHAR2(8)用電客戶所在地址的城鄉代碼 計量方式代碼VARCHAR2(8)主計量方式 計量點電壓等級代碼VARCHAR2(8)標明計量點的計量電壓等級 計量裝置分類代碼VARCHAR2(8)計量裝置分類主要根據用電量進行區分 計量點狀態代碼VARCHAR2(8)標明計量點的當前狀態 計量點類別代碼VARCHAR2(8)計量點類別代碼 計量點用途代碼VARCHAR2(8)定義計量點的主要用途 計量點位置代碼VARCHAR2(8)標明計量點所屬的具體位置 接線方式代碼VARCHAR2(8)計量點接線方式 用電容量Number(15,4)計量點用電容量 計量點類型代碼VARCHAR2(8)計量點類型代碼 用電性質VARCHAR2(8)用電性質
4.1.3 最終模型分析指標
將負荷波動特性指標、時間指標、分類指標排列組合得出最終用于模型分析的各項指標,具體指標如表4所示。
4.2 模型構建
采用70%的數據作為訓練數據,分別采用決策樹、神經網絡、支撐向量機、樸素貝葉斯等算法建立了模型,并用剩余30%數據進行了測試。
各算法建模參數和測試結果如圖1所示。神經網絡建模參數如圖2所示。支撐向量機建模參數如圖3所示。樸素貝葉斯建模參數如圖4所示。
4.3 模型結果
主要選取了總體正確分類率、Kappa統計量這兩個評估指標作為模型評估參數,各算法建立的模型測試結果如表5所示。從結果看,神經網絡算法得到的模型準確率最高,其次是決策樹算法。
考慮到業務實際情況,除了需要知道哪些企業用電性質申報存在欺詐,還需要了解對方具有什么用電特征,因此相比神經網絡為黑盒模型,決策樹模型可以得到顯性的業務規則,因此最終選擇決策樹模型作為最終的模型。通過決策樹算法對用電數據進行分析建模,最終得到如圖5所示的用電性質識別模型,決策樹的根節點到每個葉子結點形成的路徑就對應一條用電性質決策規則。
例如,圖5深色的路徑就表示“19:00—22:00用電占比小于18%,且09:00—12:00用電占比小于12.25%,且最大功率大于582 W,則100%是工商業用電”。
5 業務應用分析
基于此模型,對轄區內目前登記為“居民生活”用電性質的所有企業進行了分析,如表6所示。
表4 模型分析的各項指標
數據表構建指標數據類型 用電類別分析表計量點編號VARCHAR2(20) 一月工作日正向有功總Number(15,4) 一月周末正向有功總Number(15,4) 一月工作日峰總比Number(4,3) 一月周末峰總比Number(4,3) 一月工作日平總比Number(4,3) 一月周末平總比Number(4,3) 一月工作日谷總比Number(4,3) 一月周末谷總比Number(4,3) 一月工作日最大功率Number(8,3) 一月周末最大功率Number(8,3) 一月工作日負荷率Number(4,3) 一月周末負荷率Number(4,3) …… 十二月工作日正向有功總Number(15,4) 十二月周末正向有功總Number(15,4) 十二月工作日峰總比Number(4,3) 十二月周末峰總比Number(4,3) 十二月工作日平總比Number(4,3) 十二月周末平總比Number(4,3) 十二月工作日谷總比Number(4,3) 十二月周末谷總比Number(4,3) 十二月工作日最大功率Number(8,3) 十二月周末最大功率Number(8,3) 十二月工作日負荷率Number(4,3) 十二月周末負荷率Number(4,3) 負荷性質VARCHAR2(8) 電壓等級VARCHAR2(8) 行業分類VARCHAR2(8) 用戶類別VARCHAR2(8) 高耗能行業類別VARCHAR2(8) 電源類型VARCHAR2(8) 行政區域VARCHAR2(8) 城鄉代碼VARCHAR2(8) 計量方式VARCHAR2(8) 計量點電壓等級VARCHAR2(8) 接線方式VARCHAR2(8) 用電容量Number(15,4) 計量點類型VARCHAR2(8) 用電類別VARCHAR2(8)

圖1 決策樹建模參數
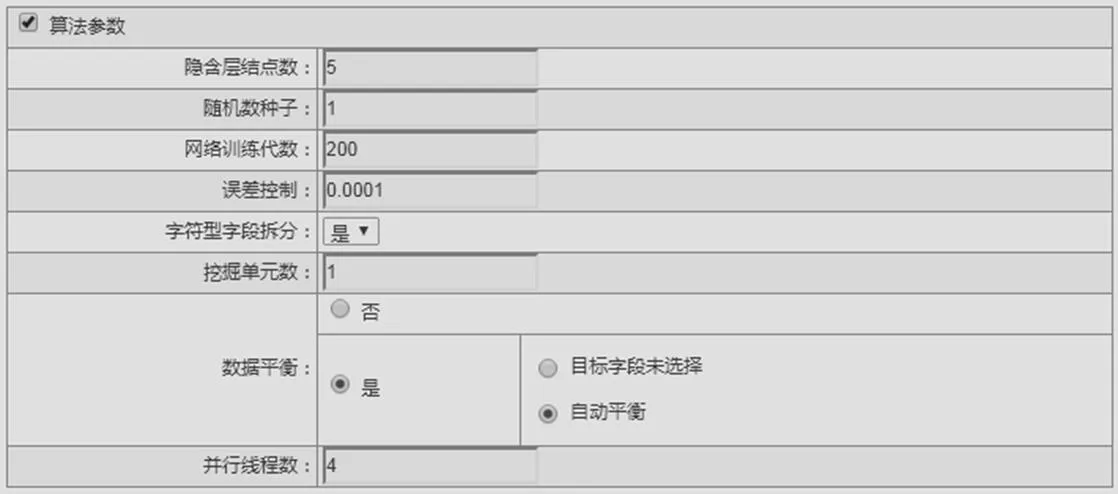
圖2 神經網絡建模參數
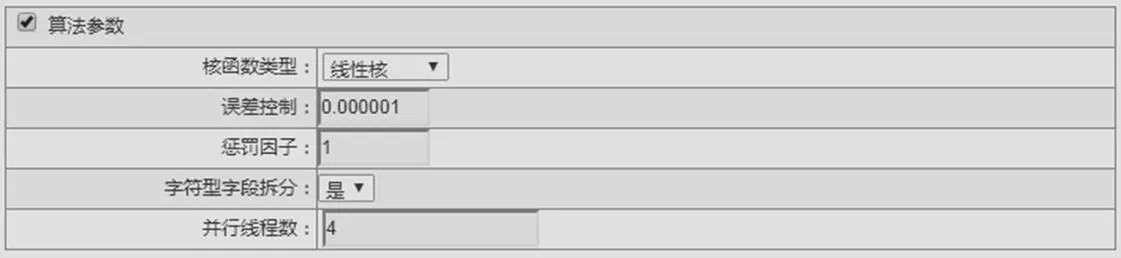
圖3 支撐向量機建模參數

圖4 樸素貝葉斯建模參數
表5 模型結果
模型評估指標算法 決策樹神經網絡支撐向量機樸素貝葉斯 窗體頂端正確分類率/(%)窗體底端98.8198.83窗體頂端94.05窗體底端窗體頂端93.45窗體底端 Kappa統計量0.968 8窗體底端0.9690.837 7窗體底端0.838 9
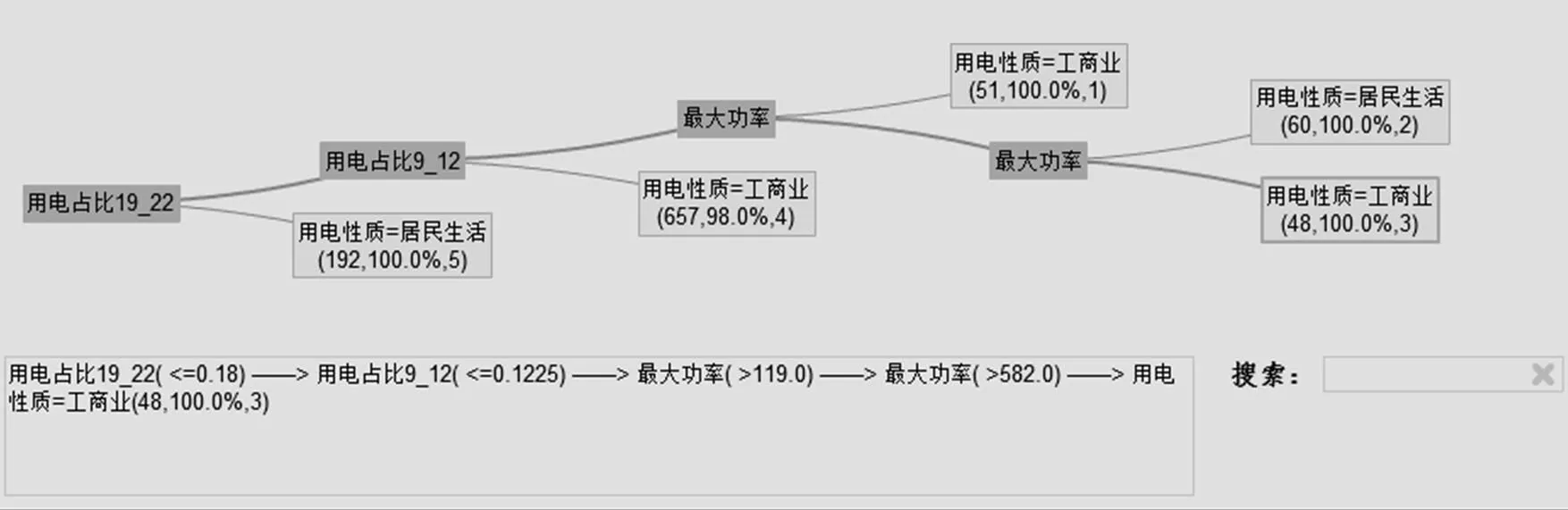
圖5 用電性質識別決策數模型
發現存在部分企業被識別為“工商業”用電性質,并且這些企業具有顯著的工商業企業用電特征,因此被納入審計調查的范圍,并追回了大量經濟損失,在審計工作中發揮了重要的作用。
此模型為電力行業基于數據挖掘技術進行精細化管理提供了有效的示范,后期將進一步利用數據挖掘技術推動電網運營管理的精細化和智能化發展。
表6 “居民生活”用電性質分析表
用戶編號年份月份星期是否節假日平均功率最大功率用電占比9_12用電占比14_17用電占比19_22用電占比2_5當前用電性質預測用電性質 87316201901星期一否2113550.2460.2220.1340.010居民生活工商業 52141201806星期二否2404090.2470.2450.1390.014居民生活工商業 6632201903星期三否1832550.2270.2340.1370.019居民生活工商業
[1]高琳琳.基于數據挖掘的短期負荷預測[D].南昌:南昌大學,2014.
[2]陸園園,王成然.基于電力負荷模式分類的短期電力負荷預測[J].中國高新技術企業,2014(1):69-70.
[3]董莉麗.基于大數據挖掘的客戶用電行為分析[J].黑龍江科技信息,2016(4):45.
[4]高旭旭.基于深度學習的分類預測算法研究及實現[D].北京:北京郵電大學,2019.
2095-6835(2020)10-0014-04
TM715
A
10.15913/j.cnki.kjycx.2020.10.005
〔編輯:張思楠〕
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
電力與能源(2017年6期)2017-05-14 06:19:37
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
信息通信技術(2015年6期)2015-12-26 01:16:46
