日本留學生普通話前后鼻音發音偏誤實驗
2020-06-09 02:02:30西安外事學院
長江叢刊 2020年12期
關鍵詞:實驗
■陳 思/西安外事學院
受到母語負遷移的影響,由于普通話中后鼻音的音色與學習者母語中[N]的音色更接近[4][7],在和日本同學交流以及對日本學生的漢語作為第二語言教學實踐的過程中,我們發現,日本學生在前后鼻音尾韻母的聽辨以及發音上都存在著不小的問題。日本玉川大學的奧山望先生在他的《對日本學生的語音教學》一文中指出,對日本學生來說最難辨、最難發的是漢語語音中的前鼻音/-n/和后鼻音/-ng/[5]。日本的澀谷周二先生在其《日本學生漢語學習難點和重點的報告中》一文中,通過統計和分析的結果表明,日本學生在漢語語音學習過程中,無論是初級階段還是中、高級階段,舌尖鼻音韻母都是漢語語音學習的難點和重點,特別是在初級階段,鼻音韻母的難點在所有難點中所占比例高達70%以上[6]。
一、實驗過程
整個實驗包括兩部分:一是感知實驗 ;二是發音實驗。在感知實驗部分所用的字表是單字表;除去“üan”后,十六個鼻音尾韻母可以形成7對14個前后鼻音尾韻母的對立,每對對立韻母各取4個代表字,共28個字;這些選字來自于《漢語水平詞匯與漢字等級大綱》中的甲級和乙級詞,僅對于乙級詞進行標記 ;后鼻音尾韻母兒化時所產生的鼻化韻現象不在本文和字表的考慮范圍之內。除了字表,還有與字表相配便于被試者進行判斷的選擇題。發音實驗部分所用的字表也是單字表,所取鼻音尾韻母對數、選字來源以及對兒化韻的考慮同感知字表相同,只是發音字表共44個字,因為為了分散被試者對于鼻音尾韻母字或詞組的注意力,其中插入非鼻音尾韻母字或詞組。感知實驗中的發音人是2個普通話水平為一級乙等水平的中國研究生;聽辨人是3個漢語水平為中級的日本留學生。發音實驗中的發音人是3個漢語水平為中級的日本留學生,聽辨人是2個普通話水平為一級乙等水平的中國研究生。他們的年齡均在20歲左右。我們采用的方法是:發音字表、聽辨分析和語圖分析。我們采用的實驗工具是北京語言大學對外漢語研究中心語音實驗室錄音設備。實驗錄音均在安靜的環境下進行,分析工具是 praat語音分析軟件。在感知實驗中,先由中國學生錄制發音,然后由日本學生進行聽辨測試,發音實驗的順序正好相反。所有的發音人在自然狀態下用正常語速朗讀實驗材料。
二、實驗結果
(一)感知實驗結果分析
前鼻音尾韻母和后鼻音尾韻尾感知表中的每個字由兩位中國發音人分別發音,3位日本留學生作為被試在答卷上勾出他們認為正確的拼音。實驗結束后,被試表示“an-ang”以及“in-ing”這兩對韻母聽辨能力最弱,基本無法感知其差異。我們將三位被試的錯誤率單獨統計之后算出平均值,得出最后的平均錯誤率,由此我們將錯誤率由高到低的順序進行總排序:uan > uang >in > an、ang、ian、en、eng、uen、ing > iang、ong。由此我們可以得出以下結論:日本學習者對于前鼻音韻母的感知能力弱于對后鼻音韻母的感知能力,即日本學習者將-n類誤認為-ng的情況要多于將-ng類誤認為-n的情況。這說明,日本學習者對于母語中不存在的兩個帶鼻音的對立音位的感知困難程度是不一樣的,不可同一而語。從數據中可以看出,被試感知困難最大的是/ua/組的韻母,我們認為,鼻音尾韻母的韻頭對于日本學習者感知整個韻母也產生了一定的影響。
(二)發音實驗分析
我們對于3名被試者進行了聽辨和語圖的分析。被試者所發的in和ian的發音正確率為100%;ing、en、iong還有uang的錯誤率為50%;由于2名被試者本身習得的錯誤,eng被發成了另外的發音,故沒有計入統計數據內;剩下的無論是an、uan還是ang、iang,錯誤率都是100%,所以它們是我們分析的重點,再加上在之前的感知實驗中3位聽辨人都把“反”聽成了介乎于“反”和“訪”之間的一個音,把“晚”聽成了“wang(上聲)”,錯誤率為100%。因此我們以“反”和“晚”為分析對象。中國發音人的“反”和被試者“反”的對比如圖1。
語圖分析表明:從元音的第二共振峰來看,被試者的第二共振峰要明顯低于中國發音人發音中的第二共振峰的。這就說明,被試者的舌位靠后,與發音人相比-n前的元音更接近于-ng前的ɑ[ɑ]。從鼻音的濁音寬橫杠所在的區域看,中國發音人的濁音寬橫杠和前面元音共振峰的交接處形成了錯層,并且位于濁音寬橫杠上方的高頻區域內并沒有很強能量的集聚區,只有很弱的寬橫杠出現。但是,日本發音人的濁音寬橫杠和前邊元音共振峰的交界處卻比較平緩,說明他所發出的-n的位置偏后,而且他的濁音寬橫杠上方的高頻區域內出現了強頻集中區。根據王理嘉先生在《音系學基礎》中提出的共鳴特征集聚性/分散性區別對立特征,發-n時,舌尖與齒齦接觸的最窄緊收點把口腔分為了前腔和后腔,這時所分出的前腔小而后腔大,-n是一個分散音。但是,發-ng時,舌面與軟腭接觸的最窄收緊點所分出的前腔大而后腔小,-ng就為集聚音[1]。所以,從語圖上來看,日本發音人所發出的-n不是個分散音,而是一個類似于-ng的集聚音。我們對于“晚”字所采取分析角度和上邊的分析角度有所不同。被試人的“晚”和“忘”的對比如圖2。
由于發音實驗中,對3名日本被試人“忘”字的聽辨結果是100%的正確,所以我們選取了其中一名被試人自己所發音的這兩個字進行對比。在前面分析結果的基礎上,通過語圖2我們可以明顯地看到,無論是從元音的第二共振峰的位置,濁音寬橫杠與前面元音的交界處,還是高頻能量集中區來看,“晚”和“忘”的語圖表現形式都非常的相似。這說明,被試者把an發成了ang。由實驗我們可以預測到,對于日本人來說鼻音韻尾韻母中最容易發錯的就是an和ang。通過對于3名被試者語圖的分析,發音形式可以分為四種情況:第一種:an和uan出現-n的后化的現象,如:短、安、歡。“短”“安”“歡”在聽感上有韻尾后化現象,它們的-n濁音寬橫杠上方的高頻區域內出現了強頻集中區。第二種:an和uan出現a和-n都后化的現象,如:煩、傘。“煩”字被發成了fang(陽平),“傘”字被發成了sang(上聲),表現為韻腹及韻尾后化現象。3名被試者的韻尾-n出現強頻集中區。第三種:ang、iang和uang出現a的前化現象,如:講、樣、場、裝、香、張。“講”“樣”“場”“裝”“香”“張”在聽感上有韻腹前化現象。第四種:ang出現-ng的短化現象,如:樣。3名被試者的“樣”出現了-ng短化現象,-ng的時長為0.13s。
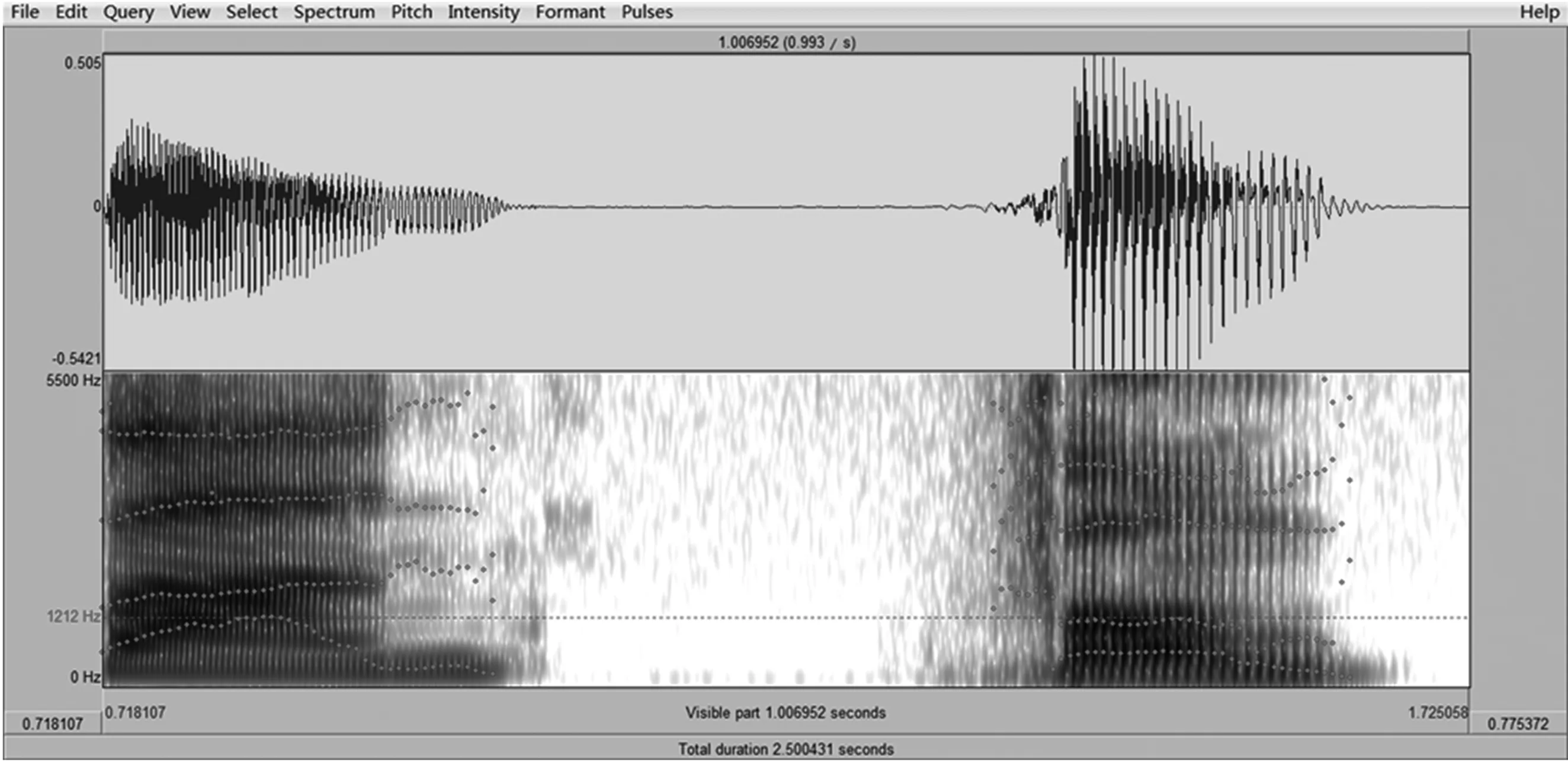
圖1 選取1人的發音語圖
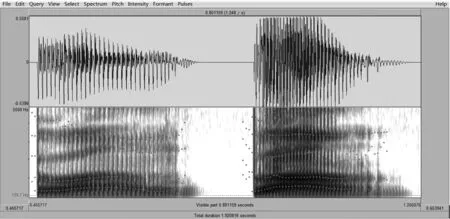
圖2 選取1人的發音語圖
三、結語
通過對感知實驗和發音實驗的分析我們得出以下結論:一是日本留學生在漢語語音學習中,對于后鼻音的辨認能力高于前鼻音韻母,后鼻音韻母的發音正確率有高于前鼻音的傾向,這是由后鼻音的音色與學習者母語中[N]的音色更接近導致的;二是 鼻音尾韻母的韻頭對于日本學習者感知整個韻母產生了一定的影響;三是日本學生在發漢語的前鼻音韻尾音節時出現了明顯的-n后化現象,把分散音-n發成了類似于聚合音-ng的音;4.因為日語中的[N]不具有區別意義的作用而漢語中的/-n/、/-ng/具有嚴格的區別意義的作用[2][3],所以日本學習者在二語習得過程中對對漢語的前后鼻音不完全理解。
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
