元器件信息識別系統的設計及應用
2020-06-09 10:52:42徐永進沈曙明嚴華江武占河
浙江電力 2020年5期
魯 然 ,徐永進,李 晨,沈曙明,嚴華江,任 旭,武占河
(1.國網浙江省電力有限公司電力科學研究院,杭州 310014;2.華立科技股份有限公司,杭州 310023)
0 引言
隨著采集終端的逐步推廣與普及[1],其產品的質量及可靠性是行業關注的重點,而送檢的采集終端是否滿足樣品一致性要求,對產品質量及可靠性有直接影響。采集終端元器件更改后,如未經檢測而直接應用于工作現場,將會存在批量性的質量事故隱患[2-4]。目前國內多個省級電力公司采取將送檢元器件信息識別進行比對的方式來排除此類隱患[5-7]。現有的元器件信息識別工作從抽樣到比對全過程均采用人工作業[8-9],無專用的信息識別系統裝置和處理技術[10-14],存在人工比對工作量大,比對效率低,易出現漏判、錯判等情況,信息識別質量難以有效保證,給元器件在現場的安全運行帶來風險與隱患[15-22]。
針對現有技術缺陷,為提高元器件信息識別可靠性及檢測效率,設計并實現了一種元器件信息識別系統。系統通過元器件信息采集裝置與圖像識別技術的結合,實現元器件信息識別從信息采集、信息處理到元器件的智能化比對工作。
1 系統組成及功能特點
元器件信息識別系統主要由硬件及軟件兩部分組成。該系統由待測采集終端位置自動確定所需比對的對象,根據智能識別匹配原則,自動完成對采集終端外觀信息、內部元器件信息的采集及比對工作,并生成比對結果。系統基本功能模塊如圖1 所示。

圖1 系統基本功能模塊
1.1 硬件結構
系統中硬件部分指信息采集裝置,分為機械運動單元和圖像采集單元。其內部組成包括: 底座及360°旋轉的圓盤、工業級高分辨率主相機及輔相機、補償光源等。其中,底座及360°旋轉的圓盤屬于機械運動模塊,通過執行運動控制軟件指令對待測采集終端進行左右移動、圓盤指定角度旋轉等動作,實現待測采集終端的自動機械對焦功能,完成對采集終端外觀及內部元器件的信息采集工作。針對同一類產品可實現自動信息識別,人工干預少,且通過側面增加一個相機的方式,對圓柱形高位置元器件以及絲印位于側面的元器件進行側面360°方向信息采集。系統硬件結構如圖2 所示。
1.2 軟件架構

圖2 系統硬件結構
1.2.1 系統軟件設計
元器件信息識別系統系統軟件基于.NET 平臺的多層技術架構,軟件開發采用C 語言、Python,運行主機平臺支持Windows 7 操作系統,基本開發工具為Pycharm。
元器件信息識別系統軟件架構組成包括數據采集層、數據處理層和應用平臺層,各層作用分別為:
(1)數據采集層: 可以通過以太網、RS232 及RS485 等接口與裝置進行通信,讀取所需數據并存儲于數據庫中,供數據處理層進行處理。
(2)數據處理層: 對數據采集層的數據進行收集、匯總、處理及分析,通過歸類處理后將數據存儲于數據庫及系統中,可供需要時隨時調用。
(3)應用平臺層: 可視化操作界面,通過軟件界面中各操作模塊獲取數據處理層數據,直觀地將各類數據展示于操作界面層,便于實時對裝置運行狀態進行監測與操作。
系統軟件架構如圖3 所示。
1.2.2 系統軟件功能組成
系統軟件包括運動控制軟件、信息處理軟件及元器件比對軟件。
3)0.6mm滲層刀片不論是在滲層厚度、組織硬度,還是在組織硬度梯度等方面,都介于其他兩種滲層刀片之間。雖然在部分位置上出現一定程度的崩刃現象,但磨損量比0.3mm滲層刀片要小,大部分情況下與0.9mm滲層刀片的磨損量相差不大,甚至磨損量比0.9mm滲層刀片要小,崩刃現象也比0.9mm滲層刀片出現的少。因此,0.6mm滲層刀片在磨損量上總體效果最好。
運動控制軟件控制信息采集裝置按照待測采集終端樣品類型進行移動與姿態調整,操控信息采集裝置進行高精度機械運動。
信息處理軟件根據分析采集終端外觀銘牌信息、內部元器件品牌信息、內部元器件型號信息等特征值,運用圖像識別技術進行有針對性的信息處理工作。
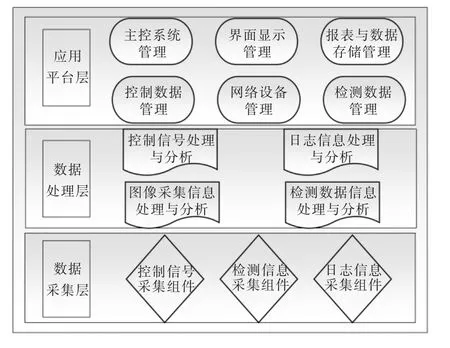
圖3 系統軟件架構
元器件比對軟件負責完成元器件比對工作,本模塊功能通過上位機軟件實現,將樣品信息與封樣的元器件清單逐一進行比對、判斷,并以報告形式輸出結果,同時可將比對結果作為歷史數據保存于數據庫中。
2 關鍵技術
2.1 機械運動單元
機械運動單元包含底座運動模塊和相機運動模塊。底座上安裝可旋轉360°的圓盤以及帶有標尺的測試平臺,圓盤上有帶凹槽的柔性夾具。采集終端整機測試時放置于帶有標尺的測試平臺上;采集終端內部元器件測試時需將帶有元器件的線路板置于柔性夾具的凹槽內固定。底座運動模塊運動方式分為底座平臺水平移動方式和圓盤360°方向旋轉方式,主要支持采集終端外觀圖像采集時的底座左右方向水平移動,以及采集終端內部元器件圖像采集時的圓盤360°旋轉運動。相機運動模塊運動方式為垂直升降式,主要支持主相機對采集終端外觀及元器件正面圖像采集過程中的調焦功能。
機械運動單元可實現工業相機的機械對焦功能,對焦成功后,由圖像采集單元對采集終端樣品信息進行采集。針對較高元器件或圓柱形元器件的樣品信息采集流程,需要控制單元配合來實現機械對焦功能。由于正面相機的中心點與控制圓盤中心點一致,因此可以通過三角函數計算出圓盤旋轉后任意元器件的像素位置坐標。正面圖像采集坐標如圖4 所示,其中,A(a2,b2)為根據主相機采集的圖像信息確定的較高元器件或圓柱形元器件所在的像素位置坐標,B(x,y)為元器件旋轉α 角度后的像素位置坐標,O(a1,b1)為正面相機正下方原點像素位置,通過旋轉后兩邊相等,其公式如下:

根據余弦公式,可計算出AB 值,進而根據坐標值A(a2,b2)可推算出B 點坐標值:
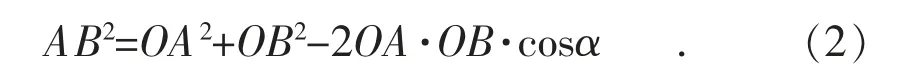

圖4 正面圖像采集坐標
輔助相機對較高元器件或圓柱形元器件進行側面圖像采集,其坐標如圖5 所示。C 點為對焦位置,需要把元器件側面位置移動到C 點平面上。根據坐標B(x,y),計算其移動到側面相機對焦位置C 點的距離f(x)為:
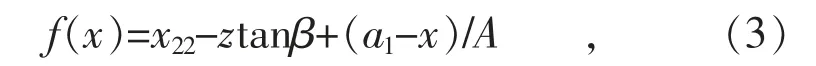
式中: x22為2 個相機中心點水平距離;z 為相機中心點到采集終端樣品水平面的距離;β 為輔相機與垂直方向夾角;a1為像素位置坐標O(a1,b1)在x 軸上的投影(坐標值);x 為像素位置坐標B(x,y)在x 軸上的投影(坐標值);A 為圖片坐標像素與實際尺寸的比值系數。B(x,y)坐標對側面相機對焦取水平x 軸坐標,通過式(1)和式(2)求解得到B 點x 軸坐標為:把x 帶入對焦位置式(3),即可求出對焦移動距離f(x)。

2.2 圖像采集單元

圖5 側面圖像采集坐標
2.3 信息處理軟件
信息處理軟件設計采用圖像識別技術對信息采集模塊采集到的采集終端外觀圖像及內部元器件圖像進行處理。其中,外觀信息主要為銘牌信息,內部元器件信息主要為元器件的品牌與型號信息。根據這些信息的特點,提出對于富有設計性圖形圖案的銘牌及品牌信息的識別,采用模板匹配方法;而對于型號信息及字符類的品牌信息識別,采用基于深度神經網絡的文本識別方法。
2.3.1 模板匹配法
模板匹配方法研究某一特定圖案在圖像中的位置,其原理為在待檢測圖像上,從左到右、從上向下計算模板圖像與重疊子圖像的匹配度,匹配程度越大,兩者相同的可能性越大。其中,采用標準相關性系數R 計算模板與子圖像的匹配度,即計算模版對其均值的相對值與子圖像對其均值的相對值的內積,如式(5)所示:

式中: T′為模板圖像;I′為待匹配子圖像;x′為模板圖像的像素值橫坐標;y′為模板圖像的像素值縱坐標;x 為待匹配子圖像的像素值橫坐標;y 為待匹配子圖像的像素值縱坐標;T′(x′,y′)為減去均值的模板像素值;I′(x+x′,y+y′)為減去均值的子圖像像素值。
以用電信息采集領域常見的micron 存儲芯片為例,其品牌信息為富有設計性的圖形圖案組成,以此進行模板匹配測試。首先截取存儲芯片各個方向、各種形態下的清晰圖像作為品牌模板圖像,同時將該元器件品牌中英文全稱、縮寫與之關聯,并標注后保存于品牌模板庫中,如圖6所示。進行元器件匹配識別時,將品牌模板庫中的所有品牌模板與待匹配元器件圖像進行匹配,根據標準相關性系數R 計算模板與子圖像的匹配度,匹配度在95%以上,默認將品牌模板庫中關聯的品牌信息以客戶指定格式映射輸出。圖7為待匹配元器件圖像,圖8 為匹配結果,其中以白色框標識識別到的品牌圖案。

圖6 品牌模板圖像

圖7 待匹配元器件圖像

圖8 匹配結果
2.3.2 基于深度神經網絡學習的文本識別法
基于深度神經網絡學習的文本識別法,首先需要進行文本檢測,即確定文本的位置,然后進一步識別檢測到的文本圖像中的文本序列信息。傳統技術解決方案中,分別訓練文字檢測和文本識別2 個模型,然后在服務實施階段將2 個模型串聯到數據流水線中組成圖文識別系統。該類方法需要執行2 次特征提取的計算,較為繁瑣。本解決方案中將文本檢測與文本識別2 個目標融入到一個框架中,采用多目標網絡直接訓練端到端的模型,不僅可以共享特征,而且文本檢測與文本識別相輔相成,達到更高的識別精度。在訓練階段,模型的輸入是訓練圖像及圖中文本坐標、文本內容,模型優化目標是文本框坐標預測誤差與文本內容預測誤差的加權和。在服務實施階段,將原始圖片輸入訓練好的模型,直接輸出預測文本信息。相比于傳統方案,該方案中模型訓練效率更高、服務運營階段資源開銷更少。
以較高元器件Rubycon 電解電容為例,其元器件信息包含型號信息及字符類的品牌信息識別,以此進行基于深度神經網絡學習的文本識別功能測試。文本識別模型如圖9 所示。

圖9 文本識別網絡模型
圖9 中輸入圖片由圖像采集單元對電解電容進行側面圖像采集,因電解電容的形狀為圓柱形,其元器件信息印刷位置具有不一致性,因此采取對電解電容前、后、左、右4 個方向進行圖像采集。
通過文本檢測與識別網絡對元器件上的文本進行較為準確的檢測及識別,但出現了文本框重疊的現象,因此,需對預測結果進行重疊的判斷及消除重復識別字符的處理。由于重疊現象均發生在同一行文本中,所以首先對文本框的縱坐標進行判斷,若2 個文本框的縱坐標相似,則可判斷其為同一行。如圖10 所示,左側文本框的頂點坐標為Bi(Xi,Yi),i∈[1,2,3,4],右側文本框的頂點坐標為Ri(xi,yi),i∈[1,2,3,4],計算2 個文本框在x 方向的重疊率,如式(6)所示:

式中: B1(X1,Y1),B2(X2,Y2),B3(X3,Y3),B4(X4,Y4)為左側文本框中的4 個頂點坐標;R1(x1,y1),R2(x2,y2),R3(x3,y3),R4(x4,y4)為右側文本框中的4 個頂點坐標;D 為2 個文本框在x 方向的重疊率。

圖10 文本框交疊示意
若重疊率D 大于閾值,則可判斷2 個文本框位于同一行,進一步判斷是否有重疊。首先判斷左側文本框最后一個字符和右側文本框第一個字符是否為同一字符,若2 個字符不相同,則判斷2 個文本框未重疊;若2 個字符相同,比較y 方向重疊長度(y4-Y1)和單個字符長度l,若y4-Y1>0.5l,則判斷2 個文本框重疊一個字符。通過以上方式,去除文本識別結果中的重復字符,并將所有識別出的字符串按照從上向下、從左向右的順序串聯為一個字符串。例如,圖9 中所有識別出的字符串串聯為一個字符串為“yxjy20 μ f25v2200 μ f 25v0rubyconr2rubycon3”。最后,在識別出的長字符串中查找廠家給出的型號字符串(YXJ 25v2200μF)和品牌字符串(Rubycon)。
2.4 元器件比對軟件
元器件比對軟件通過與封樣的元器件清單進行采集終端內部元器件比對,與地方供貨要求文件進行銘牌信息比對。識別的結果與元器件清單進行比對,輸出包含具有元器件信息、銘牌信息及匹配置信度信息的結論。比對結果可分為2 種形式體現。第一種是在界面上,識別結果根據用戶需求設計以列表的形式可視化展示,對于不同的識別結果可自定義使用不同的顏色背景加以區分,使用戶方便找到不合格的元器件,如圖11所示;第二種是直接生成結果文件,用戶可定制報告的基礎信息,根據報告模板,在需要時生成需要的文件格式的比對報告,如表1 所示。

表1 采集終端樣品比對實驗結果

圖11 界面可視化比對結果
3 系統運行效果與分析
文中根據采集終端元器件的不同特征,采用不同的信息采集方法及信息處理方法,信息處理的結果以與封樣的采集終端元器件清單進行比對為例,輸出包含具有元器件信息及匹配置信度信息的結論。對于型號與品牌全部與所提供元器件清單一致的元器件,置信度為1,結論為合格;對于所識別的信息與元器件清單部分一致的,通過計算得出其置信度值,根據應用方需求設計,如置信度值小于1,判定結論為不合格;對于未能識別的元器件或所識別的元器件不是目標元器件,置信度為0 或者小于0.5,結論為不合格。某公司的采集終端樣品比對實驗結果見表1。
4 結語
本元器件信息識別系統的應用提高了元器件信息識別系統的成功率,同時提高了采集終端樣品比對環節的檢測效率,可以有效代替人工作業,并且進一步促進了采集終端樣品比對檢測技術的升級,具有較好的推廣前景與應用價值。
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
