一種混合推薦算法的Mahout實現
2020-06-21 15:16:16唐科
軟件工程 2020年6期
關鍵詞:機器學習
唐科
摘? 要:推薦算法作為推薦引擎實現的核心而得到廣泛研究。在各類推薦算法中,大部分對于用戶行為特征屬性、用戶人口屬性、物品特征屬性,以及用戶—物品關聯特征屬性等參數的應用方式存在局限性。它們一般采用相似度計算、或模型計算等方法,其特征提取及參數的調優依賴于事前定義,存在參數優化效率低的問題。本文結合機器學習技術,提出一種混合推薦算法,即(MMLHC算法),以多層神經網絡作為參數優化計算的模型,應用Mahout庫實現算法,實驗結果顯示算法能有效去除原始輸入數據的噪聲、奇異點,在模型的各層之間優化權重參數與偏差,輸出數據去噪平滑,正常擬合。相似度與精確度的計算指標良好。
關鍵詞:推薦算法;機器學習;多層神經網絡;隱藏層;可視層
Abstract: Recommendation algorithms are widely studied as the core of recommendation engine implementation, but most types of the current recommendation algorithms have limitations on the application of user behavior characteristic attribute, user population attribute, item characteristic attribute and user-item relation characteristic attribute. They generally use similarity-based calculation, or model-based calculation methods, and their feature extraction and parameter tuning depends on prior definition, with low effectiveness of parameter optimization. This paper proposes a hybrid recommendation algorithm of Multilayer Machine Learning Hybrid Compute (MMLHC). Multi-layer neural networks are considered as model of parameter optimization calculation and Apache Mahout implements the algorithms. The experimental results show that the algorithm can effectively remove the noise and singular points of the original input data, optimize the weight parameters and deviations between the layers of the model, and smooth the output data denoising and normal fitting. The index of similarity and accuracy is improved.
Keywords: recommendation algorithm; machine learning; multi-layer neural network; hidden layer; visual layer
1? ?引言(Introduction)
圍繞互聯網及其應用的各類信息技術持續地迅猛發展,各類電子商務交易系統平臺、網絡學習平臺、音樂社交網絡應用、新聞網站、視頻網站等層出不窮,這些應用往往通過建立推薦引擎來為用戶提供令其滿意的個性化優質服務,而推薦引擎的核心就是推薦算法的設計實現。目前大多數的推薦算法是基于內容的推薦算法,基于協同過濾的推薦算法,基于關聯規則知識的推薦算法等。在這些算法中,完成推薦的方式各不相同。有的是通過向量化特征計算相似度,有的是通過建立用戶—物品矩陣并分解矩陣,計算得出物品的特征向量,還有的是通過挖掘關聯規則,由頻繁項集生成強關聯規則,并計算其置信度。在這些算法的研究實現中,大部分對于用戶行為特征屬性、用戶人口屬性、物品特征屬性,以及用戶—物品關聯特征屬性等參數的應用方式采用了相似度計算、或模型計算等,當與機器學習技術結合后,學習過程中的特征提取,以及參數的調優都依賴于事前的手工定義,所以,存在參數優化的效率不高這一問題。因此,本文在這些算法的工作基礎上,設計了一種可在學習過程中持續自動優化參數的模型,并基于此模型,提出了一種混合推薦算法(MMLHC算法)。該算法通過綜合應用各個特征參數,在模型的各層中以交叉關聯的方式進行學習,即多次的輸入與輸出的關聯,初次的參數輸入經過學習后,產生了特征的輸出,而這些輸出又作為第二次的輸入,繼續進行學習優化,一直持續下去,直到獲取最優參數為止。算法的設計實現則利用Apache開源的Mahout庫中的類和自定義類,并分別在各自相同的數據集Movielens-ml-20M中運行后,計算平均絕對誤差、均方根誤差、準確率、召回率等指標,MMLHC算法達到了較好的推薦效果。
2? 推薦算法的相關研究工作(Related studies of recommendation algorithms)
通過應用矩陣分解技術進行重構評級矩陣,并與自動編碼方法結合實現預測,從而構建出推薦系統[1]。估計分布算法[2]則應用了真實用戶信息和音頻數據高級表示的推薦算法設計,從用戶感興趣的歌曲特征中捕捉個人的聽力行為,實現了音樂推薦。袁正午等學者提出一種基于多層次混合相似度的協同過濾推薦算法[3],改進了數據稀疏的性能缺陷和單一度量問題。黃震華等學者綜述了排序技術與推薦算法融合的各類算法技術,對關鍵技術和應用進展等進行概括、比較和分析[4],并提出未來的發展趨勢。楊佳莉等學者提出一種自適應混合協同推薦算法,該算法基于張量分解計算物品間的相似度,通過短路徑枚舉疊加生成預測結果[5]。曹占偉等學者提出了結合LDA主題模型的矩陣分解推薦算法[6],解決了冷啟動及數據稀疏問題。楊豐瑞等學者提出一種結合特征傳遞和概率矩陣分解的社交網絡推薦算法[7],實現概率矩陣因式分解,緩解冷啟動并提高了算法的精確度。劉晴晴等學者提出基于SVD填充的混合推薦算法[8],采用奇異值分解技術分解項目評分矩陣[8],獲得了優化的評分結果。
3? 混合推薦算法設計與模型(Design and model of the hybrid recommendation algorithm)
傳統的推薦算法中的參數調優,以及學習過程中的特征提取依賴于事前的手動定義,參數優化的效率不高,針對參數優化問題,本文提出一種多層神經網絡模型,結合算法中的迭代計算解決該問題。
3.1? ?模型與算法設計
在機器學習領域,主要的理論基礎是概率論、數理統計、線性代數和數學分析,其核心技術是數據、算法和模型的綜合應用。本文所提出的MMLHC算法涉及其中的邏輯回歸與神經網絡,邏輯回歸是數據分析中的常用算法,它輸出概率估算值,并將此值用Sigmoid函數映射到[0,1],以實現樣本分類。神經網絡則是基于歷史數據構建的模型,隨新數據的產生進行動態優化,并應用新數據重新訓練模型,以及調整參數值。
MMLHC算法所用的模型是基于多層神經網絡的模型,其結構如圖1所示。當該模型處于工作狀態時,其權重參數是需要進行調整的,之后可以使各個單元的狀態發生改變,最終讓整個網絡的誤差函數最小化,由此可以去除輸入數據的噪聲,并將其作為整體來提取特征。
在輸入數據中存在不完整、被破壞的情況,這是帶有噪聲的輸入數據。設輸入數據(含中間輸入,即輸出再次作為輸入)單元集合,模型的最終輸出(即可視層)單元集合。隱藏層單元集合。在輸入數據中,用于表示帶噪聲的輸入數據,則隱藏層單元的輸出,可視層單元的輸出分別表示如下:
式(1)中,代表隱藏層的偏差,代表隱藏層的權重,式(2)中,代表可視層的偏差,代表可視層的權重。是邏輯回歸函數。根據算法的模型結構,輸入層到隱藏層有一個映射過程,稱輸入帶噪聲的數據并映射到隱藏層的過程為編碼。反之,將編碼后的數據反向再變為原始輸入數據的過程稱為解碼。則估計函數可以表示為一個對數似然函數,這個對數似然函數是關于和的。
式(3)中,模型的參數由表示,它包括了可視層與隱藏層的偏差和權重。通過計算出參數的梯度,并依次求導,在此過程中,應用邏輯回歸函數求導,由這些求導計算得出各個參數的更新,即權重的更新以及偏差的更新,同時還確定了參數優化迭代的次數,最終完成模型參數的計算。
為便于求導計算,應用換元法,引入兩個中間變量和,分別替換式(1)和式(2)中的函數中的自變量表達式,如下所示:
在推薦算法的設計中,對基于內容的過濾與協同過濾方法的綜合應用,形成了混合推薦算法。模型的參數包含了用戶評分、用戶—物品關聯特征、用戶之間的相似度、項之間的相似度等。
MMLHC算法的實現依賴于模型的逐層訓練,并在此過程中進行參數的優化調節。逐層訓練分為兩個階段,第一個階段是預訓練,第二個階段則是精確調校。在整個網絡模型中,權重參數與偏差在模型的各個層之間都需要進行調整。因此,模型中的前面層向后傳遞的值會成為當前層的輸入,輸入輸出的角色動態地交替。由模型的輸入層輸入數據,經過隱藏層后再回到輸入層,而此時的輸入層就會承擔輸出層的作用,但同時它也依然不會拋棄輸入的職責。在這個過程中,模型算法會調整網絡的權重參數,同時消除誤差。那么,前層學習到的特征會成為當前層的輸入,所以,在整個模型中,輸入數據會從逐層學習到新特征。
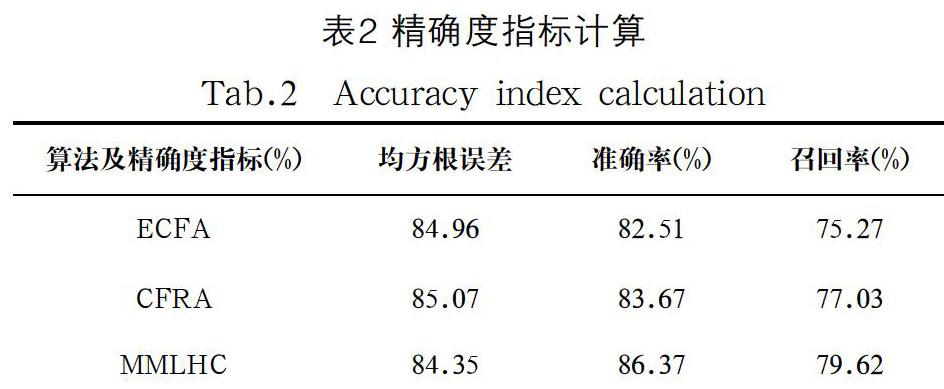
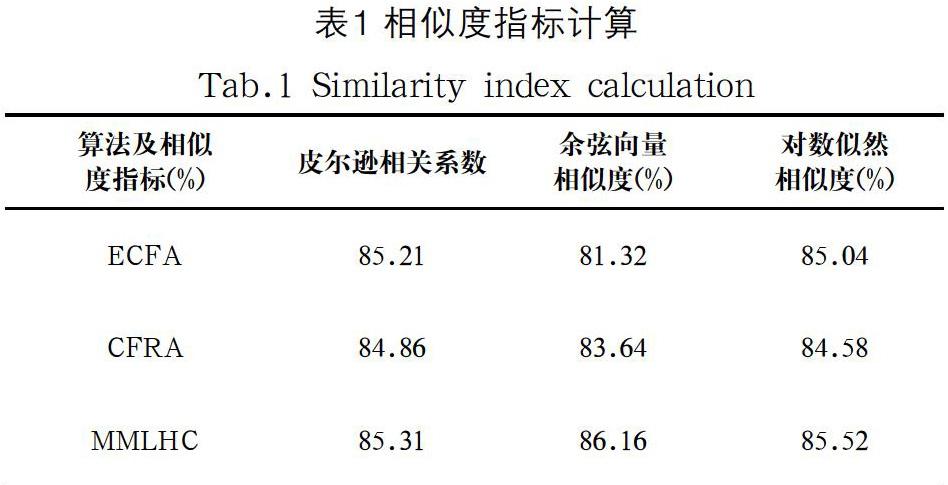
在模型的預訓練階段,通過權重參數的調節以更好地匹配通用特征,同時減少噪聲部分的權重參數。在模型的精確調校階段,進行有監督的機器學習,即監督訓練,以解決分類問題,完成目標的推薦。MMLHC算法結合Apache Mahout庫中的推薦引擎實現了混合推薦的指標計算,即相似度參數、預測準確度、均方根誤差、準確率和召回率。
3.2? ?實驗驗證
算法的實驗驗證基于單機運行方式下完成,硬件配置如下:CPU是Intel Core i7-4790@3.60GHz,內存32GB,操作系統為Windows7-64位。軟件配置,基于Maven插件的Eclipse4.11.0,配置Apache Mahout 0.13.0,單機運行,無Hadoop配置。Windows7操作系統下安裝JDK12.0.1,并配置好相應的環境變量。訓練與測試數據集應用Movielens-ml-20M。
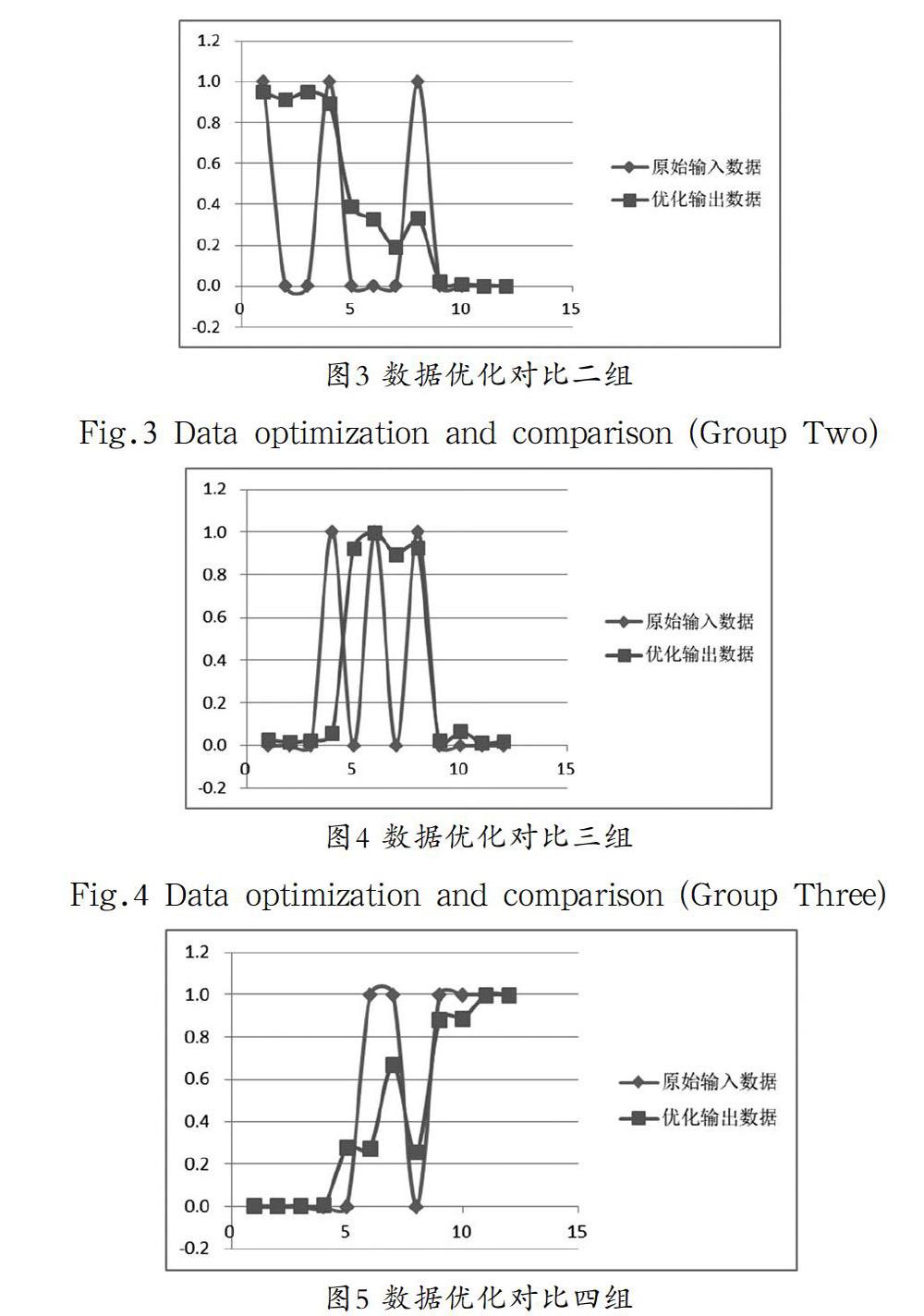
在Eclipse4.11.0中運行各個自定義實現類,經過迭代優化后,調用相應的方法獲取輸出數據。在實驗中,模型初始參數設定為隱藏層單元數20,輸入/輸出層單元數200,可視層單元數200,預訓練階段迭代次數最大1000,精確調校階段迭代次數最大1000,預訓練階段學習率20%,精確調校階段學習率15%。分別給出四組原始輸入數據(即含噪聲的輸入數據),運行并采集優化后的輸出數據。得出圖2、圖3、圖4、圖5的四組對比,原始輸入明顯存在奇異點,這是包含損毀噪聲的數據,而輸出的結果則顯示去除噪聲后的平滑特征,并且與原始數據正常擬合,未有欠擬合及過擬合現象。實驗結果驗證了算法模型具有較好的參數優化能力。
推薦算法的評測指標可在不同的方面反映出算法的性能。在實驗中,通過相似度的計算來標明各個屬性特征之間的量化相關性,并作為推薦結果的評價依據。表1分別比較了MMLHC算法、ECFA算法[1]、CFRA算法[3]各自的皮爾遜相關系數、余弦向量相似度、對數似然相似度的計算結果。從表中可以看出,它們的相似度指標近乎一致,至多相差1%—2%,因此,在相似度指標的評價中,這幾個算法具有相同的性質。
除相似度外,均方根誤差、準確率及召回率的計算比較如表2所示。表中反映出MMLHC算法相比于其他算法,均方根誤差略低,準確率與召回率高出3%,性能上的提高得益于算法模型中對參數的迭代優化,最終使得屬性特征的提取數據達到了最優狀態,驗證了算法的較好精確度。
4? ?結論(Conclusion)
基于MMLHC算法模型結構與Apache Mahout庫結合,實現了一種混合推薦算法。算法模型建立在多層神經網絡之上,通過對權重參數的迭代優化計算,排除了損毀數據對屬性特征提取的干擾,降低了整個模型網絡的誤差,輸出最優參數。通過實驗驗證了該算法的相關度以及精確度,達到了較好的狀態。
今后的研究將進一步著眼于提高算法的性能,充分利用Mahout庫支持分布式系統的特征。將Mahout庫配置于Hadoop之上,可獲得分布式計算的能力,在此基礎上,繼續改進算法的性能,并使之能滿足大容量特征數據的處理需求。
參考文獻(References)
[1] F.STRUB, J MARY, R GAUDEL. Hybrid recommender system based on autoencoders [C]. in Proc. of the 1st Workshop on Deep Learning for Recommender Systems (DLRS 2016), Boston, 2016: 11-16.
[2] P CHILIGUANO, G FAZEKAS. Hybrid music recommender using content-based and social information[C]. in Proc. of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP2016), Shanghai, China, 2016: 28-38.
[3] 袁正午,陳然.基于多層次混合相似度的協同過濾推薦算法[J].計算機應用,2018,38(3):633-638.
[4] 黃震華,張佳雯,田春岐,等.基于排序學習的推薦算法研究綜述[J].軟件學報,2016,27(3):691?713.
[5] 楊佳莉,李直旭,許佳捷,等.一種自適應的混合協同過濾推薦算法[J].計算機工程,2019,45(7):222-228.
[6] 曹占偉,胡曉鵬.一種結合主題模型的推薦算法[J].計算機應用研究,2019,36(6):1638-1642.
[7] 楊豐瑞,鄭云俊,張昌.結合概率矩陣分解的混合型推薦算法[J].計算機應用,2018,38(3):644-649.
[8] 劉晴晴,羅永龍,汪逸飛.基于SVD 填充的混合推薦算法[J].計算機科學,2019,46(6A):468-472.
作者簡介:
唐? 科(1969-),男,碩士,講師/經濟師.研究領域:移動互聯應用,JavaEE軟件開發,機器學習.
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
