基于大數據云平臺的深度學習預測模型研究
2020-06-22 13:15:56陳亮亮邵雄凱高榕
軟件導刊 2020年5期
陳亮亮 邵雄凱 高榕


摘 要:近年來,隨著云計算、大數據等技術的迅猛發展,如何快速、有效地從紛繁復雜的數據中獲取有價值的信息成為當前大數據應用的關鍵問題。為此,對基于大數據云平臺的深度學習預測模型進行研究,以對未來序列數據走勢進行有效預測。首先對幾種基于深度學習的長短序列預測模型進行對比分析,分析其與傳統預測模型的區別及優勢,提出一種加入dropout的輕量級GRU預測模型。采用代表性天氣數據作為實驗對象,實驗結果表明,該方法的實驗預測指標MAE(平均絕對誤差)的平均值相比傳統預測方法有所提高,從而有效驗證了輕量級GRU預測方法的正確性與有效性。
關鍵詞:大數據;云平臺;深度學習;預測模型;數據倉庫
DOI:10. 11907/rjdk. 191883 開放科學(資源服務)標識碼(OSID):
中圖分類號:TP306文獻標識碼:A 文章編號:1672-7800(2020)005-0042-06
0 引言
隨著大數據時代的到來,如何處理海量數據對于如今的數據處理技術提出了更高要求,因此大數據管理平臺、數據倉庫技術以及BI(Business Intelligence)工具等應運而生。其中,etl(抽取,轉換,加載)是BI和數據倉庫的核心與靈魂,能夠按照統一規則集成并提高數據價值。這些數據管理工具可為商務決策分析提供支持,使人們從海量數據中挖掘出所需的信息。但由于數據體量龐大,容器技術又為云計算的發展開辟了新的道路,使系統資源的利用效率越來越高。傳統大數據分析模塊能對平臺數據作基本的挖掘與分析,但數據中通常還包含一些深層次信息,因此需要對數據作更深入的處理。區別于傳統機器學習方法,深度神經網絡是一個逐層提取特征的過程,并且是由計算機從中自動提取數據,而不需要人類干預提取過程。特別是在預測領域,深度學習能夠更精準地預測未來趨勢。
針對預測算法及相關模型,特別對于天氣序列數據方面的預測,很多學者進行了大量研究。傳統預測方法主要包括懲罰線性回歸方法和集成方法。一些學者提出利用機器學習方法進行預測,如張鑫等[7]針對隨機森林的強度和相關度對其進行剪枝,使得剪枝的隨機森林算法在所應用的數據上表現出優于傳統隨機森林算法的性能;王定成等[12]提出一種多元時間序列局部支持向量回歸的日氣溫預測方法,以日最高、最低氣溫為例,使用C-C方法與最小預測誤差法構造日最高、最低氣溫的多元時間序列,并將分段提取最近鄰點方法應用于局部支持向量回歸,建立提前1天的每日最高、最低氣溫局部預測模型。之后還有學者提出采用集成方法進行預測模型構建,集成方法的關鍵是通過結合這些弱學習器的偏置和或方差,從而創建一個強學習器(或集成模型),從而獲得更好的性能。底層算法又稱為基學習器,基學習器是單個機器學習算法,上層算法通過對基學習器進行巧妙的處理,使模型相對獨立。有很多算法都可作為基學習器,如二元決策樹、支持向量機等。
之后深度學習也逐漸進入預測領域,主要有基于CNN與RNN神經網絡的預測模型等,也能達到較好的預測效果。如楊函[16]提出通過滑動時間窗手段改造,使普通神經網絡也能學習到歷史時序特征;鄧鳳欣[4]利用LSTM神經網絡研究股票時間序列的可行性。以上文獻都為本文研究提供了思路。
1 大數據平臺架構介紹
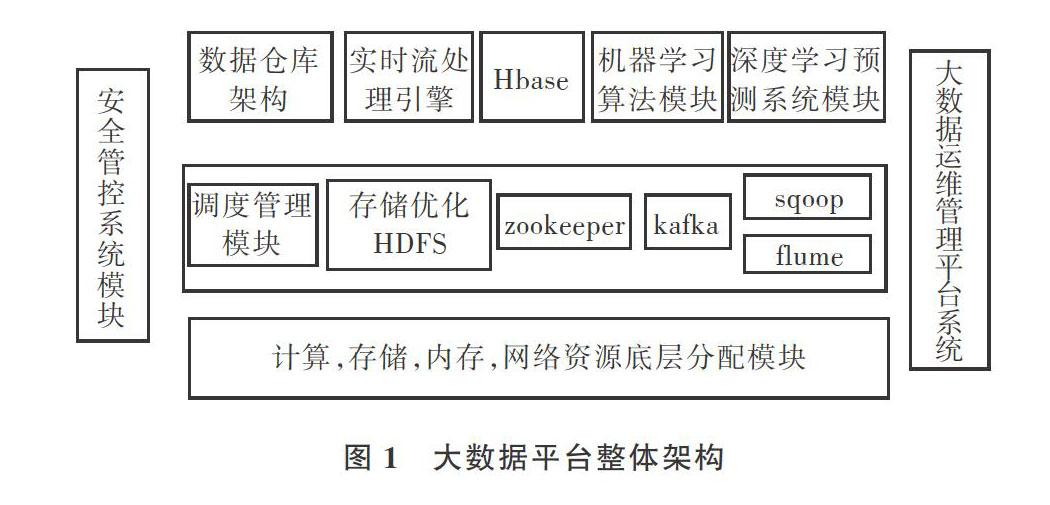
大數據平臺包含了大數據處理整套流程,平臺整體架構如圖1所示。
首先數據來源于數據倉庫架構,具體為db2本地數據接口,通過傳感器采集到天氣數據信息并傳入本地數據庫作初步處理;之后通過sqoop、flume組件進行數據的采集抽取,可以根據維度進行匯總劃分;上傳到hdfs后,再次進行相關的etl操作,如碼值轉換、merge等。
大數據平臺還有HBase和kafka等數據存儲組件,以應對海量數據存儲。HBase位于結構化存儲層,Hadoop HDFS為HBase提供了可靠性較高的底層存儲支持,Hadoop MapReduce為HBase提供了高性能計算能力;Zookeeper為HBase提供了穩定的服務和failover機制;kafka滿足了日志處理以及高吞吐量的需求;Zookeeper則用于分配集群資源,同時負責組件間的通信;調度模塊方便人們對數據倉庫中的etl程序、shell腳本運行狀態進行管理,同時了解程序運行狀態。
算法模塊包括spark的MLlib傳統機器學習模塊和深度學習模塊。本文主要討論深度學習模型在大數據平臺上的應用,以及如何與大數據運維管理模塊進行交互。大數據運維管理平臺是整個集群的靈魂所在,能夠保障集群的穩定性及高效性。主要表現在以下幾個方面:①保障各數據節點的可用性;②保障計算、存儲網絡等資源的合理分配以及集群資源利用率,方便集群中程序的順利執行;③對shell腳本進行管理,大數據集群與Linux系統密不可分,很多時候為了實現集群運維管理的自動化,需要定時采用shell腳本處理一些問題,或開啟守護進程監控部分關鍵位置;④每天能及時統計一些關鍵指標點,并進行報表展現;⑤對相關etl程序以及存儲過程程序進行監控,保障程序正常運行。
2 LSTM與GRU原理
傳統線性模型難以解決多變量或多輸入問題,而RNN解決了這一問題。RNN 是包含循環的網絡,當時間間隔不斷增大時,RNN 則無法學習到連接較遠信息的能力,而神經網絡如LSTM擅長處理多個變量的長連接問題,該特性有助于解決長時間序列預測問題。LSTM模型是對RNN卷積神經網絡進行改進得到的(見圖2),由于存在梯度消失或梯度爆炸問題,傳統RNN在實際中很難處理長期依賴關系,而LSTM繞開了這些問題,依然可以從數據語料中學習到長期依賴關系。
在t時刻,LSTM的輸入有3個:當前時刻網絡輸入值x_t、上一時刻 LSTM輸出值h_t-1,以及上一時刻單元狀態c_t-1;LSTM 的輸出有兩個:當前時刻 LSTM 輸出值h_t與當前時刻單元狀態c_t。
為了控制長期狀態,這里設置3個控制開關,第一個開關負責控制繼續保存長期狀態c,第二個開關負責把即時狀態信息傳遞給長期狀態c,第三個開關負責控制是否將長期狀態c作為當前的LSTM輸出,如圖4所示。
(1)前向計算每個神經元輸出值如圖5所示,共有5個變量。
(2)反向計算每個神經元的誤差項值。與 RNN 一樣,LSTM 誤差項反向傳播也包括兩個方向:一個是沿時間的反向傳播,即從當前 t 時刻開始,計算每個時刻的誤差項,一個是將誤差項向上一層傳播。
(3)根據相應誤差項,計算每個權重梯度。調參目標是要學習8組參數(W分別代表權重矩陣和偏置項),如圖6所示。
為了提升訓練效率以及簡化模型架構,一個基于LSTM的改進版模型GRU應運而生。GRU是LSTM網絡的變體,其較LSTM網絡結構更加簡單,而且效果很好,因此也是當前非常流行的一種網絡。
GRU可以解決RNN網絡中的長依賴問題,在GRU模型中只有兩個門:更新門和重置門,如圖7所示。更新門決定有多少過去信息可用來利用,重置門決定丟棄多少過去信息。zt代表更新門操作,ht代表重置門操作。一般來說,GRU計算速度較快,計算精度略低于LSTM。
候選隱藏狀態只與輸入以及上一刻的隱藏狀態 h(t-1)有關。這里的重點是,h(t-1)與 r 重置門相關,r取值在 0~1 之間,如果其趨近于 0,候選隱藏狀態上一刻信息即被遺忘。當前隱藏狀態取決于 h(t-1)和h~,如果 z 趨近于 0,則表示上一時刻信息被遺忘;如果 z 趨近于 1,表示當前輸入信息被遺忘。
3 加入dropout的輕量級GRU預測模型在序列數據上的應用
通常增加網絡容量的做法是增加每層單元數或增加層數。循環層堆疊(Recurrent Layer Stacking)是構建更強大循環網絡的經典方法,例如,目前谷歌翻譯算法就是7個大型LSTM層的堆疊。在 Keras 中逐個堆疊循環層,所有中間層都應該返回完整的輸出序列(一個 3D 張量),而不是僅返回最后一個時間步的輸出,這可以通過指定return_sequences=True實現。但由于數據量以及網絡規模過大,會產生過擬合現象。于是引入dropout正則化方法降低過擬合,dropout不同的隱藏神經元就類似訓練不同網絡(隨機刪掉一半隱藏神經元導致網絡結構已經不同),整個dropout過程則相當于對多個不同神經網絡取平均,而不同網絡產生不同的過擬合,一些互為“反向”的擬合相互抵消即可達到整體上減少過擬合的效果。
(1)采用Web前后端知識體系搭建大數據管理平臺基本框架,基本模塊主要包括數據量指標管理模塊、程序管理模塊、腳本管理模塊與日志管理模塊。
(2)循環 dropout(recurrent dropout)。這是一種特殊的內置方法,在循環層中使用 dropout降低過擬合,并堆疊循環層(stacking recurrent layers)提高網絡表示能力(代價是更高的計算負荷)。
(3)訓練測試數據準備。使用的數據主要是由德國馬克思·普朗克生物地球化學研究所氣象站記錄的天氣時間序列數據,本文使用的是2009-2016年的數據。
(4)將數據預處理為神經網絡可以處理的格式。數據中的每個時間序列位于不同范圍(比如溫度通道位于-20~+30之間,氣壓為1 000mb左右)。因此,需要對每個時間序列分別作標準化處理,讓其在相似范圍內都取較小的值。
(5)算法模型搭建。主要有基于機器學習的密集連接模型、使用dropout正則化的LSTM長短記憶模型和GRU模型,以及 dropout 正則化的堆疊 GRU 模型。
(6)數據集劃分。本文創建一個抽象的generator函數,并用該函數實例化3個生成器:一個用于訓練,一個用于驗證,還有一個用于測試。每個生成器分別讀取原始數據的不同時間段:訓練生成器讀取前200 000個時間步,驗證生成器讀取隨后的100 000個時間步。
(7)假設溫度時間序列是連續的(明天溫度很可能接近今天溫度),并且每天具有周期性變化。因此,一種基于常識的方法就是始終預測24小時后的溫度等于現在的溫度。本實驗使用平均絕對誤差(MAE)作為評估指標。
(8)構建模型。本文準備了一個輕量級網絡,最簡單的數據模型Sequential是由多個網絡層線性堆疊的棧。對于更復雜的結構應該使用Keras函數式,其允許構建任意的神經網絡圖。
(9)將網絡訓練歷史輪次數據通過圖表形式表現出來,可以清楚、直觀地看到各輪次訓練情況,以便對訓練輪次及權重進行調整。
(10)在LSTM模型中,隱藏層有50個神經元,輸出層有1個神經元(回歸問題),輸入變量是一個時間步(t-1)的特征,損失函數采用Mean Absolute Error(MSE),優化算法采用Adam,模型采用40個epochs,并且每個step大小為500。
(11)本實驗3種模型都采用Mean Absolute Error對整個訓練輪次平均值進行評估。
(12)將最終訓練結果通過圖表形式展現出來,參考Validation loss以及Training loss的圖形變化情況,對比模型訓練效果。
(13)評估模型預測效果,以選取最好的模型。
4 實驗與分析
4.1 數據集
數據集主要是由德國馬克思·普朗克生物地球化學研究所氣象站記錄的天氣時間序列數據集。在該數據集中,每10分鐘記錄14個不同的量(如氣溫、氣壓、濕度、風向等),其中包含多年的記錄。原始數據可追溯到2003年,但本文僅選用2009-2016年的數據。
4.2 數據生成器
猜你喜歡
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
軟件工程(2016年8期)2016-10-25 15:47:34
中國市場(2016年36期)2016-10-19 04:43:09
中國新通信(2016年16期)2016-10-18 10:45:11
科技視界(2016年20期)2016-09-29 10:53:22
企業導報(2016年11期)2016-06-16 15:36:34
企業導報(2016年5期)2016-04-05 14:19:22
