應用隨機森林和支持向量機對三陰性乳腺癌基因數據的降維和篩選
2020-06-28 10:30:56郭志旺郭維恒劉學慧王立芹
中國衛生統計 2020年3期
秦 璞 郭志旺 郭維恒 張 蕊 劉學慧 王立芹,△
【提 要】 目的 應用隨機森林和支持向量機算法處理乳腺癌基因數據,篩選三陰性和非三陰性乳腺癌的差異基因,為臨床應用提供更多的參考靶點。方法 使用TCGA乳腺癌基因數據,通過t檢驗和隨機森林進行降維處理,然后使用支持向量機、支持向量機遞歸特征消除法、隨機森林進行變量重要性排序,將隨機森林和支持向量機與向前變量選擇法結合進行模型預測并完成最終變量篩選,通過Holdout驗證評價模型效果。結果 數據經t檢驗的FDR降維后剩余18702個基因,經隨機森林降維后剩余6326個基因;對降維后經三種方法排序的數據建立預測模型,獲得各模型約登指數等評價指標;對排序結果中靠前的基因進行文獻搜索,發現大部分基因和三陰性乳腺癌的轉移或者預后有關。結論 針對高維基因表達數據進行變量選擇,使用t檢驗的FDR進行降維、隨機森林對變量進行排序篩選、支持向量機進行預測效果最佳;通過檢索重要性排序靠前基因發現大多數與三陰性乳腺癌有關,但某些靠前基因與三陰性乳腺癌無文獻研究,建議研究這些基因與三陰性乳腺癌的相關性。
隨著云計算、計算機智能存儲等技術的快速發展,海量高維數據已滲入到各個領域,在醫學研究中比較常見的高維數據就是基因表達數據。傳統統計方法難以對基因表達數據進行有效的處理分析,機器學習[1]是目前處理高維數據的主要方法,這類方法具有強大的特征識別、分類和預測的能力。通過機器學習的方法從基因表達數據中篩選出與疾病密切相關的基因,可指導基礎研究和臨床實踐,降低基礎研究費用,便于研究靶向治療藥物,減輕患者痛苦,因此疾病相關基因的篩選對疾病的診斷和治療具有重要的現實意義[2-3]。
三陰性乳腺癌是指癌組織免疫組織化學檢查結果為雌激素受體、孕激素受體及人表皮生長因子受體2均為陰性的乳腺癌,約占乳腺癌的20%左右[4-5],具有惡性程度高、侵襲能力強和易遠處轉移等特點,與其他類型的乳腺癌相比5年生存率更低[6-9]。本研究應用隨機森林(random forest,RF)和支持向量機(support vector machine,SVM)處理三陰性乳腺癌患者和非三陰性乳腺癌患者的基因表達數據,篩選與三陰性乳腺癌有關的基因并通過一些指標組合進行模型評價,為臨床診斷、治療和基礎研究提供參考。
資料與方法
1.數據
使用癌癥基因組圖譜(the cancer genome atlas,TCGA)公共數據庫的乳腺癌RNA-seq數據,應用GDC Data Transfer Tool軟件下載數據樣本,對數據進行合并處理后,通過臨床數據癌組織免疫組織化學檢查結果可明確診斷為三陰性乳腺癌病人169例,非三陰性乳腺癌病人820例,共989個樣本,每個樣本測得60483個基因。
2.原理與方法
(1)隨機森林
(2)支持向量機
支持向量機以統計學習理論為基礎,基于結構風險最小化原則,在小樣本含量條件下具有較好的推廣能力和良好的泛化能力[12]。支持向量機可以通過核函數將原本線性不可分的數據轉化為線性可分數據,本研究使用運算速度較快的線性核。使用R3.5.1軟件中的“e1071”包進行分析。
(3)遞歸特征消除算法(recursive feature elimination,RFE)
遞歸特征消除法的主要思想是反復的構建模型,該方法是一個循環過程,每個過程都包含以下3個步驟:①用當前數據集訓練分類器,獲得與分類器特征相關的信息即每個特征的權重;②根據事先制定的規則,計算所有特征的排序準則分數ci;③在當前數據集中移除對應于最小排序準則分數的特征。該循環過程一直執行到特征集合中剩余最后一個變量時結束,執行的結果為獲得一列按照特征重要性排序的特征序號列表,這個迭代循環過程實際上是一個序列后向選擇的過程,它在整個循環過程中先是去除了與判別不相關的特征,保留了對判別相對重要的優化特征子集,因而可以達到優化特征子集選擇,提高判別精度的目的。
將支持向量機與RFE算法整合可有較好的變量篩選效果,即SVM-RFE,該算法是由Isabelle Guyon等人[13]于2002年提出的,即SVM-RFE。該算法利用SVM線性核模型對數據集進行訓練,得到每個特征的權向量,然后遞歸地刪除秩最小的特征,并將其存儲在堆棧數據結構中,迭代過程一直持續到最后一個特征保留下來。使用R3.5.1軟件中“sigFeature”包進行分析。
(4)變量重要性
變量重要性就是每個變量對分類結果的影響,變量的重要性評分是用來衡量預測變量對結局變量影響大小的評價指標。本研究隨機森林變量重要性采用的是基尼系數下降值,支持向量機采用的是判別函數系數值w2。
(5)假發現率(false discovery rate,FDR)
FDR[14]是對一個多重假設檢驗陽性結果中誤差比例的度量。通常直接經t檢驗得到的P值,若不經過矯正發現的差異表達基因,則會存在大量的“假陽性”,而通過FDR矯正則會降低其中假陽性的比例。使用R3.5.1軟件中“qvalue”包進行分析。
(6)統計分析方法
本研究基因表達數據有60483個基因,若使用全部基因建模,很多模型會出現高維失效,導致模型效果較差或者無法求解,因此對數據進行降維處理。最常用的降維方法為t-FDR,即對t檢驗得到的P值進行FDR多重校正,刪除無統計學意義的基因。本研究還使用隨機森林進行降維,計算每個變量基尼系數下降值和所有變量基尼系數下降值的均值,刪除基尼系數下降值位于均值以下的基因。
使用隨機森林、支持向量機、SVM-RFE來計算變量重要性,使用向前變量選擇法按照變量重要性評分,從大到小逐個引入變量,每加入一個變量就重新構建一次模型。通過Holdout驗證法對模型進行評價,將數據隨機分割成兩部分,其中2/3的樣本為訓練集,另外1/3的樣本為測試集,計算測試集訓練結果的敏感度、特異度、陽性預測值(positive predictive value,PPV)、陰性預測值(negative predictive value,NPV)、準確率、約登指數和F1統計量。本研究應變量樣本不平衡,使用約登指數和F1統計量為主要評價指標,數據分析流程見圖1。
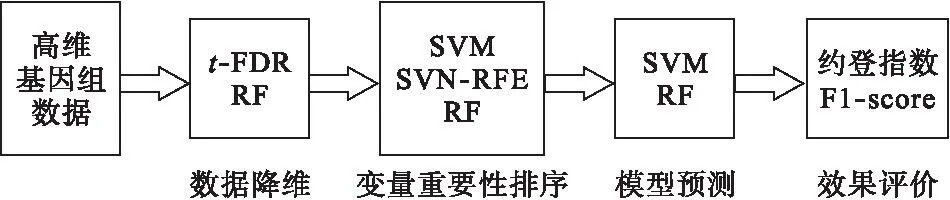
圖1 統計分析流程圖
(7)統計分析軟件及程序包
本研究使用R3.5.1軟件進行數據處理和分析,除上述程序包以外還使用了“caret”等基礎軟件包。
結 果
1.降維
通過t-FDR降維,剩余18702個基因。通過隨機森林降維,剩余6326個基因。
2.變量排序結果
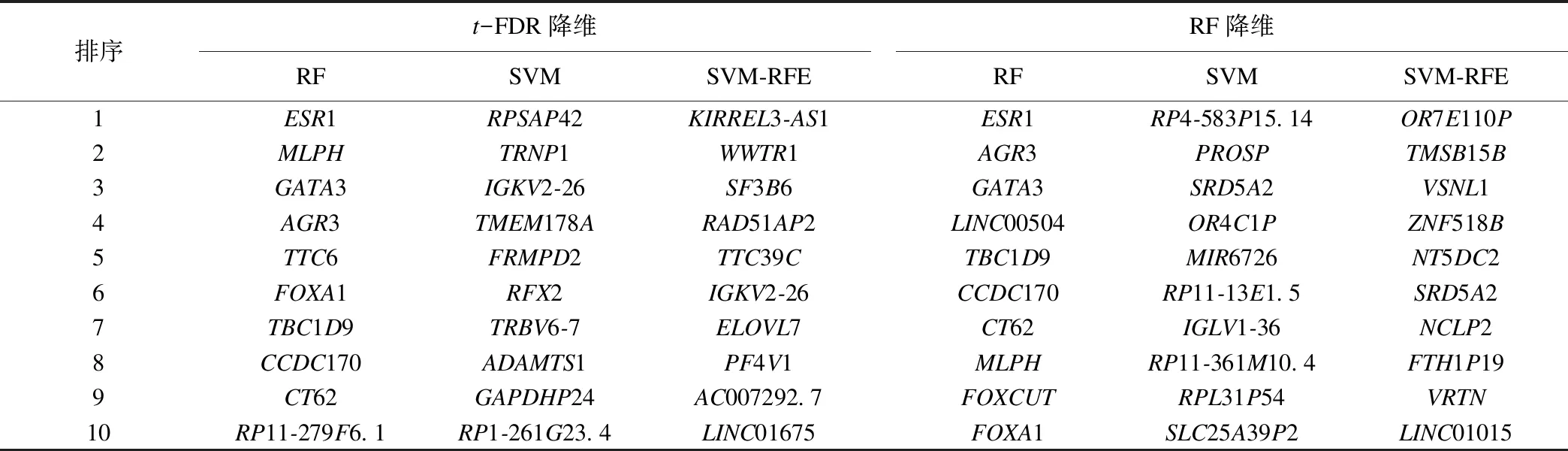
經t-FDR和隨機森林降維后,分別使用隨機森林、支持向量機、SVM-RFE對基因變量的重要性進行排序,前10位基因見表1。
3.預測結果與模型評價
使用隨機森林和支持向量機兩種分類器,對排序基因采用向前變量選擇法對是否為三陰性乳腺癌患者進行分類,變量個數與評價指標存在一定關系,結果見圖2~4。隨著納入模型的變量個數增多,指標會有一定的上升趨勢,而繼續增多則會趨向于平穩,綜合考慮變量個數和評價指標,選取變量少而評價指標高的模型作為最終模型,最終模型選出變量個數及評價指標見表2~4。
經隨機森林降維結果各評價指標不及經t-FDR降維結果。使用SVM-RFE方法進行重要性排序,建模后約登指數最高為0.8271;使用支持向量機進行重要性排序,建模后約登指數最高為0.8392;兩種排序方法建模效果均不及隨機森林排序效果。
經t-FDR降維、使用隨機森林排序后,使用隨機森林建模,入選變量個數為8個時,模型各評價指標均達到最優;若使用支持向量機建模,入選變量個數為8個時模型整體效果最好。經隨機森林降維、使用隨機森林排序后,使用隨機森林建模,入選變量個數為8個時,模型各評價指標均達到最優;若使用支持向量機建模,入選變量個數為5個時模型整體效果最好,結果詳見圖2。
預測模型支持向量機的敏感度要遠高于隨機森林,而隨機森林的陽性預測值要高于支持向量機,但整體上用支持向量機分類要優于隨機森林。
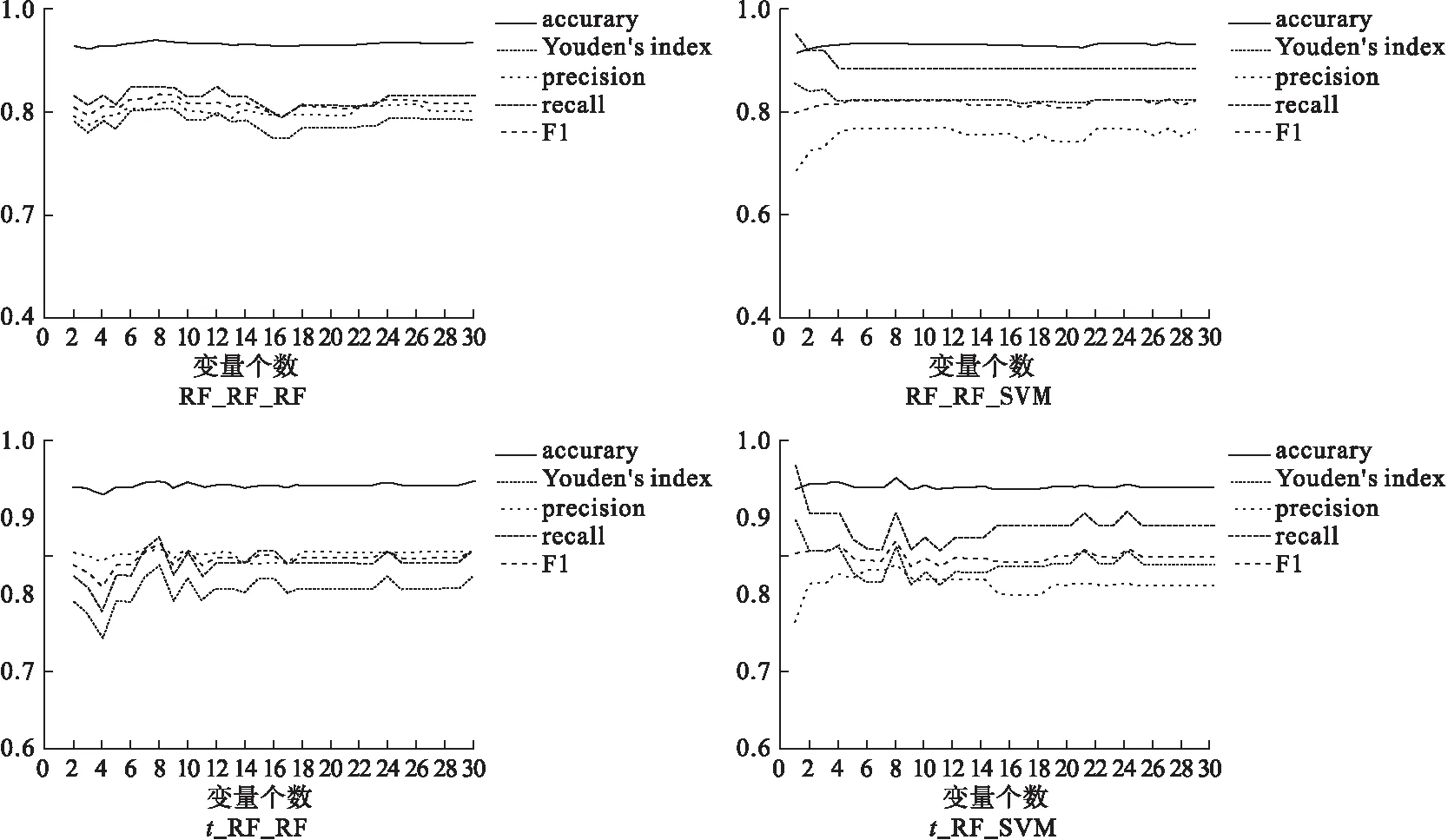
圖2 基于RF重要性排序各模型評價指標隨變量個數變化趨勢圖
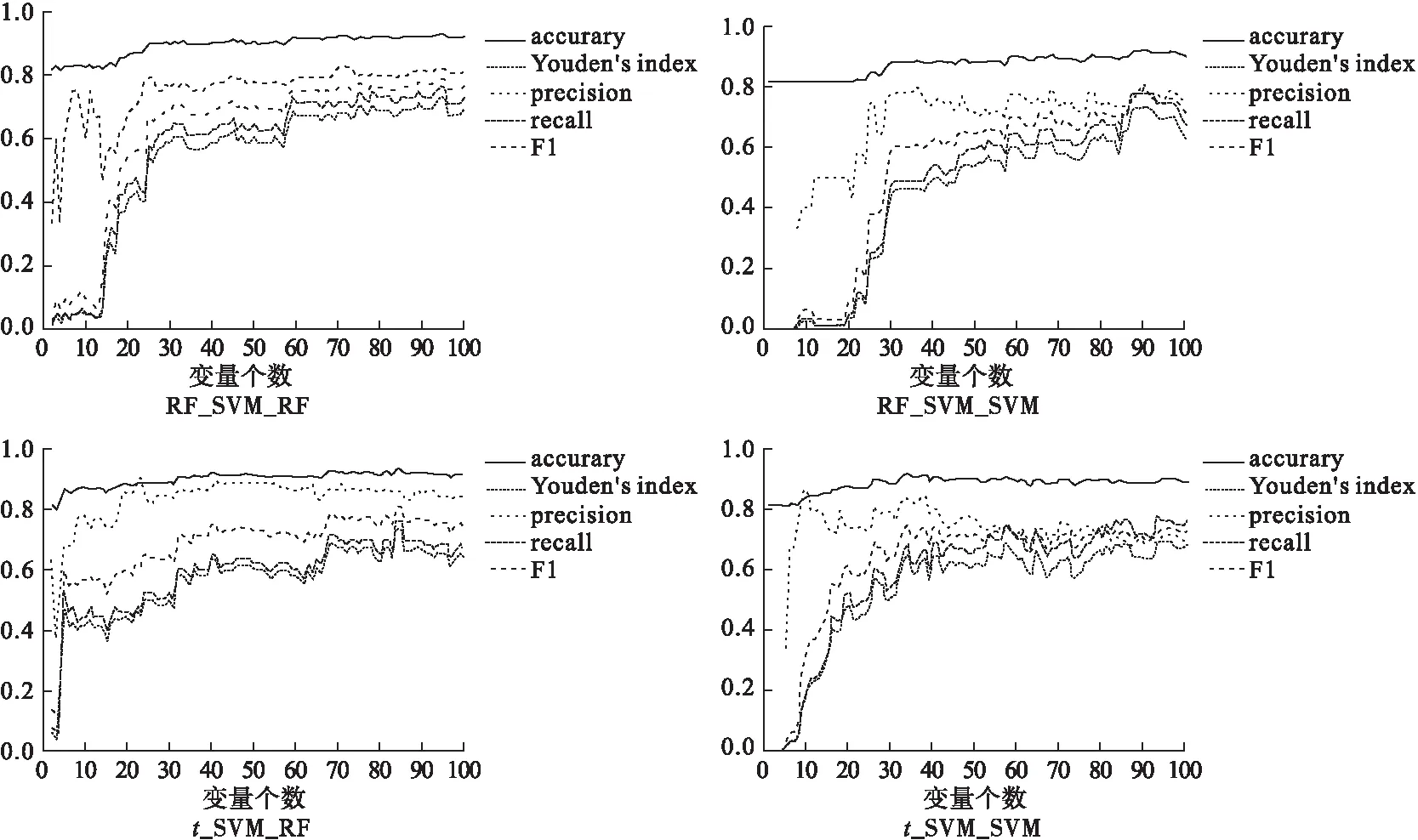
圖3 基于SVM重要性排序各模型評價指標隨變量個數變化趨勢圖
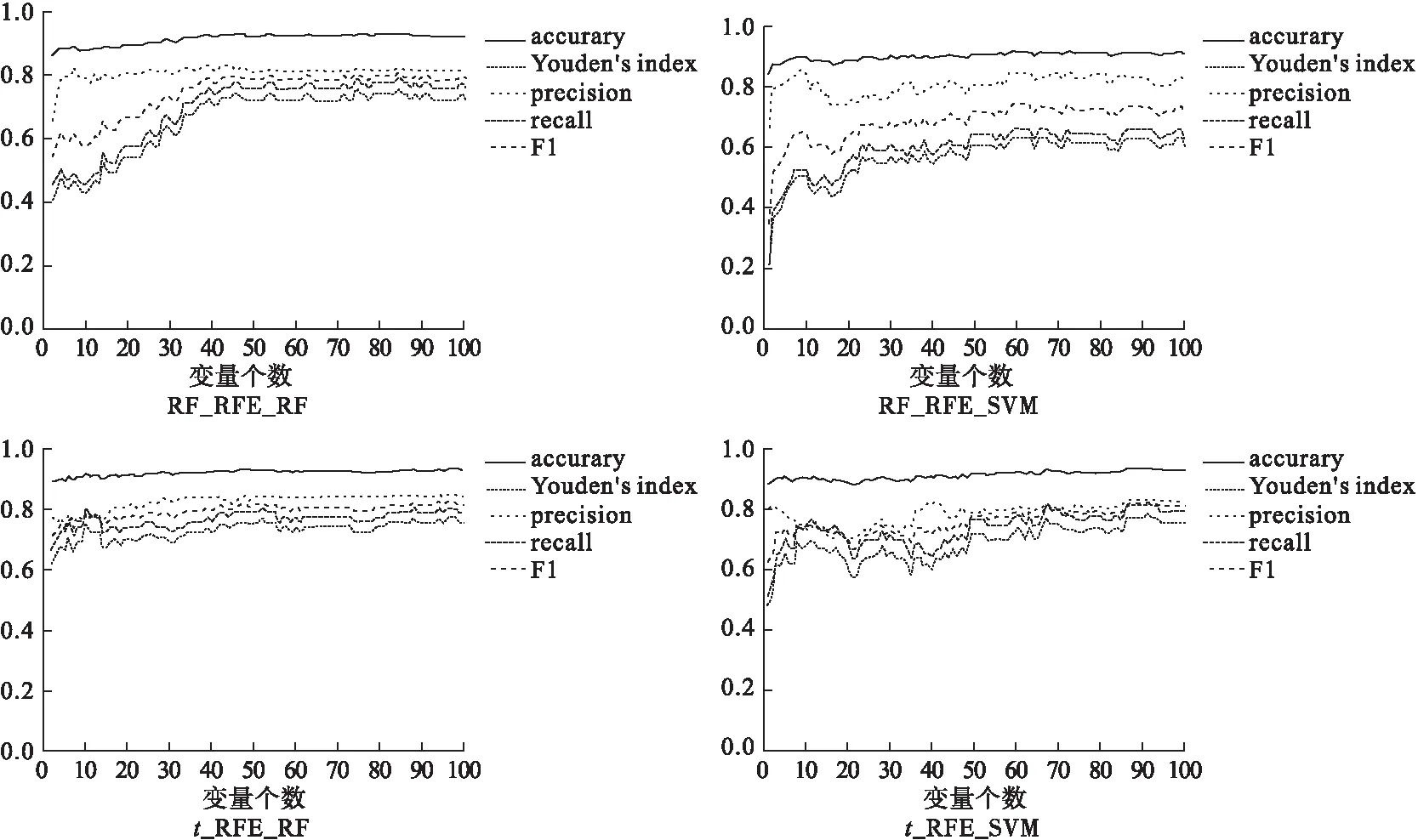
圖4 基于SVM-RFE重要性排序各模型評價指標隨變量個數變化趨勢圖
排序t-FDR降維RFSVMSVM-RFERF降維RFSVMSVM-RFE1ESR1RPSAP42KIRREL3-AS1ESR1RP4-583P15.14OR7E110P2MLPHTRNP1WWTR1AGR3PROSPTMSB15B3GATA3IGKV2-26SF3B6GATA3SRD5A2VSNL14AGR3TMEM178ARAD51AP2LINC00504OR4C1PZNF518B5TTC6FRMPD2TTC39CTBC1D9MIR6726NT5DC26FOXA1RFX2IGKV2-26CCDC170RP11-13E1.5SRD5A27TBC1D9TRBV6-7ELOVL7CT62IGLV1-36NCLP28CCDC170ADAMTS1PF4V1MLPHRP11-361M10.4FTH1P199CT62GAPDHP24AC007292.7FOXCUTRPL31P54VRTN10RP11-279F6.1RP1-261G23.4LINC01675FOXA1SLC25A39P2LINC01015

表2 基于RF重要性排序各個模型評價指標結果

表3 基于SVM重要性排序各個模型評價指標結果

表4 基于SVM-RFE重要性排序各個模型評價指標結果
4.統計分析結果與基因文獻研究的關聯性結果
對本研究的六種基因排序方法中排序前50的基因進行文獻搜索,發現ESR1、AR、CCDC170、ERBB4、GATA3、FOXA1、THSD4、AGR2、AGR3、CXXC5、FAM171A1、FSIP1、CA12、FOXCUT、RHOB、SPDEF、TFF1、TFF3、MLPH、ADAMTS1等基因與三陰性乳腺癌相關;ACADSB、BCAS1、DNALI1、SRD5A2等基因與乳腺癌相關;AC007255.8、ANXA9、B3GNT5、CCDC125、DSC2、FZD9、MYB、SRARP、TTC6、LINC00504、LMX1B、ELOVL7、FRMPD2、RFX2、SF3B6等基因與其他癌癥有關;因此排在前面的基因大部分和三陰性乳腺癌或者其他癌癥的轉移或者預后相關,并且其中大部分基因是基于隨機森林重要性評分篩選出來的且多數是編碼基因,基于t_RF篩選出來的有31個,基于RF_RF篩選出來的有28個,基于t_SVM篩選出來的有3個,基于RF_SVM篩選出來的1個,基于t_RFE篩選出來的有2個,基于RF_RFE篩選出來的有2個。
討 論
本研究顯示:t-FDR降維處理結果好于隨機森林降維結果,使用隨機森林重要性評分排序結果最好,使用支持向量機建模預測效果優于隨機森林。
本研究數據有60483個基因,屬于超高維數據,直接分析花費時間長、模型效果差,因此本研究先對數據降維處理。應用隨機森林降維時,以所有變量基尼系數下降值的均值為截斷點進行變量刪除,降維后剩余基因數量遠少于t-FDR降維,最終模型效果也不及t-FDR降維效果,可能是截斷點選取過大導致某些重要基因被刪除,使得結果差于t-FDR降維結果,所以在使用隨機森林降維時選用指標及臨界值的設置有待深入研究。
本研究比較了SVM、SVM-RFE、RF三種基因排序方法,結果顯示隨機森林算法最優。由于硬件設施的限制,放棄了SVM非線性核算法,僅使用SVM線性核算法進行重要性排序,但是變量間可能存在非線性關系,最終導致變量的重要性排序不夠穩定。RF本身就可處理線性和非線性問題,所以RF的基因重要性排序較好,后期還可研究使用SVM非線性核算法進行變量排序的效果如何。
Isabelle Guyon等人[15]將遞歸特征消除的思想與SVM相結合,這種融合后的方法選擇的基因具有更好的分類性能和生物學性能。通過SVM和SVM-RFE兩種排序方法最終模型效果比較,可以看出SVM-RFE基因排序效果明顯好于僅用SVM排序效果,指標波動有了很大收斂,見圖3~4。可能由于本研究SVM僅使用線性核的限制,導致SVM-RFE排序結果差于RF排序結果,后期還可將遞歸特征消除的思想與RF相結合做更深入的研究。
本研究顯示支持向量機進行建模分類時結果好于隨機森林,使用支持向量機預測能力更強。機器學習方法中經驗風險指的是訓練集的平均損失,當樣本容量足夠大時,經驗風險最小化能保證很好的學習效果,但樣本容量較小時會導致過擬合現象。支持向量機[16-20]以結構風險最小化為準則,在經驗風險上加上表示模型復雜度的正則化項,通過最大化不同類別之間的距離來尋找最優分類超平面,提高了分類模型的泛化性,對維度過高和過擬合等問題有著較好的抗性。
搜索文獻發現本研究中排序靠前的基因大部分已有基礎研究,并且與乳腺癌密切相關。其中有研究表明[21]ESR1啟動子的高甲基化導致雌激素受體表觀遺傳沉默;孫嘉慧等人[22]研究發現ESR1基因敲除能夠增強乳腺癌細胞的侵襲能力。多項研究[23-26]表明基因CCDC170與ESR1表達高度相關,還與不同的乳腺癌病理分子分型相關,而且影響乳腺癌患者的預后,因此CCDC170可能參與乳腺癌的發病與轉移進展,并影響患者的治療和預后。雄激素受體基因AR在三陰性乳腺癌中研究廣泛,大量臨床前研究[5,27-33]證實了AR在癌組織細胞增殖過程中的作用,并通過一系列的臨床試驗對AR拮抗劑在乳腺癌中的安全性和有效性進行了進一步評估,得到AR可能成為治療三陰性乳腺癌的潛在靶點。最近基因SRARP[34]被鑒定為雄激素受體AR的一種新型輔抑制因子,SRARP與生存的基因組和表觀基因組范圍的關聯強烈支持它們的腫瘤抑制功能,特別是DNA高甲基化、低表達、體細胞突變和低拷貝數的SRARP與不良的癌癥結局相關。對于基因ERBB4、TFF1、TFF3、GATA3、FOXCUT等,目前均有研究[35-42]表明這些位點與三陰性乳腺癌診斷或預后相關。
猜你喜歡
中老年保健(2022年6期)2022-08-19 01:41:48
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:02
中國生殖健康(2020年4期)2021-01-18 02:58:26
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
甘肅教育(2020年21期)2020-04-13 08:09:24
中國生殖健康(2019年2期)2019-08-23 08:11:42
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
中國生殖健康(2019年6期)2019-01-06 09:20:12
祝您健康(2018年5期)2018-05-16 17:10:16
