基于集成學習方法的PPP項目結果預測
2020-06-29 09:40:31劉爽
大眾科學·上旬 2020年7期
關鍵詞:數據挖掘
劉爽
摘 要:隨著政府與社會資本合作模式在基礎設施建設當中的推廣與應用,探究PPP(public-private partnership)項目能否實施成功的關鍵影響因素和判斷項目實施結果等問題已經引起了學者們的關注。根據已有文獻中總結出的PPP項目成效關鍵影響因素,提出一種結合SMOTE(synthetic minority over-sampling technique)過采樣技術和Random Forest算法的集成學習分類模型,該模型可幫助研究人員預測PPP項目實施結果的成敗。通過與其他十個基線分類器進行對比實驗,可以證明SMOTE過采樣技術對PPP項目數據集中不平衡數據的處理是有效的。研究結果表明所提模型在Presicion、F-measure和ROC Area三個指標上比基線分類器具有更好的性能表現。
關鍵詞:政府和社會資本合作(PPP);數據挖掘;集成學習;預測
0引言
基礎設施建設作為影響國家產品服務的質量和效率的重要因素,對經濟發展具有深遠的影響。一些發展中國家雖然意識到了基礎設施建設的重要性,但受到政府資源、融資、技術缺乏等方面的限制。因此,引入私人投資作為基礎設施建設的融資渠道被視為可行的方法之一。政府與社會資本合作模式有效解決了基礎設施融資難題,提高了基礎設施產出的經濟價值。以我國為例,財政部政府和社會資本合作中心官網的數據顯示,截止到2020年4月16日,全國PPP綜合信息平臺項目管理庫的入庫項目數量達到9456個,入庫項目金額達到144075億元。
數據挖掘方法可用于從目標數據集中提取信息、模式和規律來預測目標的未來趨勢。常用集成學習算法包括Bagging和Logit Boost等。它們都涉及到結合獨立分類器并提供集合而成的最有效結果。本文的數據來源為由世界銀行建立的Private Participation in Infrastructure(PPI)數據庫。該數據庫旨在識別和傳播發展中國家基礎設施建設項目中私人部門參與的信息,涵蓋各國基礎建設項目的數量超過6400個。
在本研究中提出了一種基于Random Forest[1]算法的集成機器學習模型,來預測PPP項目實施結果,并通過與其他10個基分類器的預測準確性進行比較,證明了所提出模型的優越性。
1相關工作
在對國內外文獻的梳理中,我們可以總結出以下影響PPP項目成效的因素:
(1)PPP項目開展時所在區域是否有PPP成功實施的經驗。在公共采購中,PPP模式可以將服務的不確定性最大程度地降低,從而帶來潛在收益。這些服務領域存在過去的經驗以告知參與方在事態發展時會產生的狀況。
(2)PPP項目的內部風險因素。Ahmadabadi等人[2]基于其開發的PLS-SEM模型評估關鍵成功因素對PPP項目成功的影響,提出私營部門能力直接影響項目成功。
(3)PPP項目所屬國家的政治和社會環境。政治和社會環境與特定地區密切相關,我們無法輕易量化這些因素。
(4)PPP項目所屬國家的宏觀經濟環境。隨著宏觀經濟條件的改善,公共項目將會對私人部門投資具有更大的吸引力。
學者們對PPP項目成功關鍵因素的研究方法以文獻、案例分析以及訪談等定性研究方法為主,或是使用傳統的統計學模型探究PPP項目產出效率的影響因素。羅煜[3]等人采用Probit模型對二值因變量進行回歸分析從而判斷PPP項目的成敗。劉窮志[4]等人采用隨機前沿模型分析中國PPP水務項目的22個省份非平衡面板數據,對項目投資效率及其影響因素進行研究。
PPI數據庫中存在大量失敗的基礎設施PPP項目,使得私人投資者和政府部門遭受經濟損失,降低了社會整體福利水平。本文結合不平衡數據處理和集成學習方法,根據已有研究成果設置參數,將機器學習方法運用到PPP項目實施結果的預測當中,可為私人部門對PPP項目的投資決策提供參考。
2集成學習模型
本文提出一種集成機器學習模型來預測PPP項目實施結果,結合了一系列數據預處理步驟。其中PPP項目數據取自世界銀行主導建立的Private Participation in Infrastructure(PPI)數據庫,選取了PPI數據庫中有數據收錄的已得出實施結果的全部項目數據作為研究對象。實驗工具為Weka Data Mining Tool for Java。
2.1數據描述
該數據集包含700個實例,每個實例有10個屬性,如表1所示。在該數據集的預測期內,有476個失敗的PPP項目,224個成功的PPP項目。
2.2數據預處理
根據PPP項目運行結果關鍵影響因素,選取區域(Region)、國家收入水平(Income Group)、項目類型(Type of PPI/Subtype of PPI)、所投資部門(Sector)、投資規模(Total Investment/Investment Range)、項目啟動年份(Financial Closure Year)以及過往成功的項目數量(Number of Successful Projects)作為特征屬性,項目現狀(Project Status)為預測類別標簽。其中各區域過往成功的項目數量經過手工整理得來,Total Investment存在缺失值,用0值代替。正在運行的項目結果具有較大不確定性,因此只考慮已完結的項目或合約。合同結束即視為項目成功,使Project Status取值為1,項目取消和項目危機即視為項目失敗,使Project Status取值為0[3]。
2.3建模
在本節中共使用11種分類器來預測PPP項目運行的結果,該模型包括三個部分:
(1)依次使用Standardize、Normalize 、Add Cluster、Numeric To Nominal方法對數據集進行特征處理;
(2)采用Synthetic Minority Over-sampling Technique(SMOTE)技術處理此模型中的不平衡數據集;
(3)使用Random Forest[1]分類器學習訓練數據集并進行評估。
通過該模型對測試數據集進行分類和驗證后,將預測準確性與其他10個基分類器進行比較,可證明此模型的優越性。
2.3.1特征工程
為最大限度地從原始數據中提取特征供算法和模型使用,提高模型的預測精度,我們采用下列步驟對其進行特征處理。Standardize可標準化給定數據集中的所有數字屬性,使其具有零均值和單位方差。Normalize用于規范化給定數據集中的所有數值。Add Cluster作為一個添加新名義屬性的過濾器,表示由指定的聚類算法分配給每個實例的集群。Numeric To Nominal是將數字屬性轉換為名義屬性的過濾器。
2.3.2SMOTE
過采樣技術可用于解決數據集不平衡的問題,然而通過簡單復制數據集中少數類的已有元素容易使模型過擬合,不利于模型的推廣與應用。SMOTE技術可根據少數類元素的分布來人工創造新樣本,隨后被廣泛運用于高維不平衡數據集處理流程當中。它包含兩個主要步驟:第一步為定義每個少數類元素的鄰域,第二步為隨機選擇鄰域內元素并通過插值法創造新樣本。由于SMOTE獨立于分類器,它可以與任何算法組合使用。
2.3.3Random Forest
Random Forest[1]算法是一種集成機器學習模型,它的基本思想是將多個決策樹集成到一個更強大的分類器中,每棵樹獨立作出預測,最終通過加權得出結果。Random Forest實際上是一種特殊的Bagging方法,它將決策樹用作Bagging中的模型,用bootstrap方法生成m個訓練集后在決策樹每個節點的特征中隨機抽取子集,尋找最優解并進行分裂。因此它可避免樣本過度擬合的問題。
3實驗
本節包括所提出模型的實驗過程和使用各分類器進行對比實驗的結果。我們將原始數據集中的80%劃分為訓練數據集,依次使用Standardize、Normalize、Add Cluster以及Numeric To Nominal進行特征處理。由SMOTE技術將數據集調整為平衡數據集后,通過Random Forest分類器學習訓練數據集,并使用測試數據集測試模型性能,獲取驗證結果。我們進行了多次實驗以確保模型分類結果是可靠的。
3.1模型評估指標
本研究中的分類器需解決的是二分類問題,即PPP項目運行結果是成功還是失敗。可能發生如下四種情況:a) True Positive(TP):將正類預測為正類數;b) True Negative(TN):將負類預測為負類數;c) False Positive(FP):將負類預測為正類數,即誤報 (Type I error);d) False Negative(FN):將正類預測為負類數,即漏報 (Type II error)。本文中將PPP項目成功定義為正類,項目失敗定義為負類。我們選用Precision、F-Measure和ROC Area來評估所提出的模型。
3.2實驗結果與分析
3.2.1基線分類器的性能
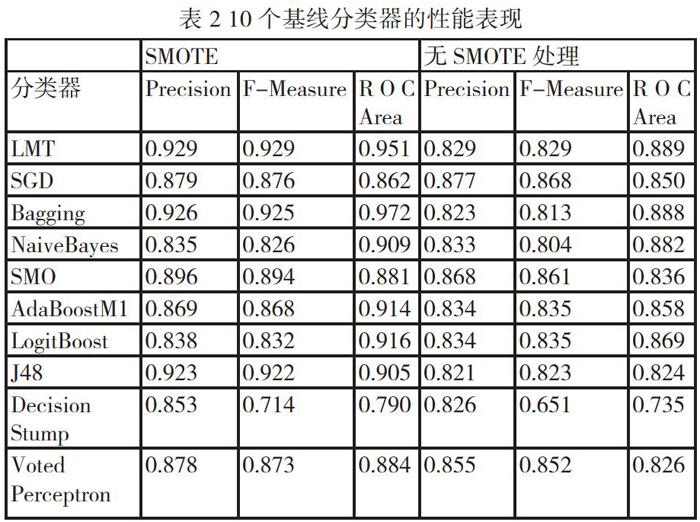
為了與我們提出模型的性能進行比較,在本節中展現了10個基線分類器的性能表現,實驗結果如表3所示。為確保實驗結果的穩健性,我們進行了5次重復實驗。其中未進行SMOTE技術處理的數據集所得出分類器精度作為對照組同樣呈現在表2中。
結果顯示,在經過SMOTE技術處理前后LMT和SGD算法都是表現最佳的兩個算法。
3.2.2建議模型的性能與分析
在本節中我們測試了所提出模型的精度,并將其結果與最佳基線分類器的結果進行了比較。與上節操作相同,進行了5次重復實驗。
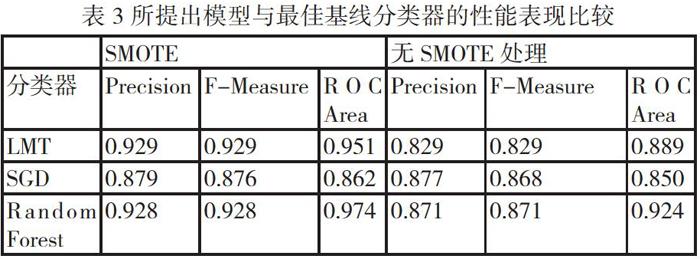
我們分別將經過相同的SMOTE過采樣技術處理之后的數據集和未經過SMOTE過采樣技術處理的數據集在所提出模型及最佳基線分類器下得出的預測準確性進行比較,具體結果如表3所示。
我們可以看出,經過SMOTE技術處理之后,基線分類器與我們所提出模型的Precison、F-Measure和ROC Area得到了全面的提升,說明SMOTE技術對PPP項目數據集中不平衡數據的處理是有效的。SMOTE技術使Random Forest和LMT的預測精度得到了整體的提升,而SGD的性能提升并不明顯。Random Forest的Precision和F-Measure略低于LMT,而ROC Area顯然優于LMT,因此綜合性能表現最良好。
4結果與討論
PPP模式要求政府和私人部門承擔不同等級風險,合作提供公共服務,已成為眾多發展中國家實施基礎設施建設時選擇的途徑。然而PPP項目的運行結果存在風險,因此對PPP項目成功關鍵因素及運行結果預測的相關研究日益引起學者們的關注。
在本文中,我們構建了一個基于集成學習的模型來預測PPP項目實施的結果,使用特征處理步驟和SMOTE過采樣技術之后利用Random Forest算法對數據集進行預測。通過與其他10個基線分類器的性能表現作比較,我們可以證明所提出模型在Precision、F-Measure和ROC Area三個指標上的優越性。同時,我們可以驗證SMOTE技術在處理本數據集中的不平衡問題時表現突出,使Random Forest的三個評估指標數值都得到了顯著提高。
由于數據集中總投資金額這列屬性存在缺失值,可能影響分類器的預測精度。此外,由于數據集屬性數量較少,我們應尋找是否存在遺漏變量,以便于提升模型的性能,在未來的工作中我們將繼續進行研究并加以改進。
參考文獻
[1]Cheng L, Chen X, Vos J D. Applying a random forest method approach to model travel mode choice behavior[J]. Travel Behaviour and Society, 2019, 14:1-10.
[2]Ahmadabadi A A, Heravi G. The effect of critical success factors on project success in Public-Private Partnership projects: a case study of highway projects in Iran[J]. Transport Policy, 2019, 73: 152-161.
[3]羅煜, 王芳, 陳熙. 制度質量和國際金融機構如何影響 PPP 項目的成效——基于“一帶一路”46 國經驗數據的研究[J]. 金融研究, 2017, 4: 61-77.
[4]劉窮志, 彭彥辰. 中國PPP項目投資效率及決定因素研究[J]. 財政研究, 2017, 11: 34-46.
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
