基于計量風格學的多層次特征在作者識別應用研究?
2020-07-13 12:48:24鐘敏汪洋
計算機與數字工程 2020年5期
關鍵詞:特征
鐘 敏 汪 洋
(1.武漢郵電科學研究院 武漢 430074)(2.南京烽火軟件科技有限公司 南京 210079)
1 引言
風格學一直以來被廣泛地研究討論,其主要內容是研究文章的特征。作為應用語言學一個分支,一般被語言學的研究人員用于分析文章風格,并用于幫助寫作人員提升寫作技巧[1]。作者風格可以認為是一系列風格學定義的屬性,最開始風格學在作者識別領域的研究基礎是基于對特定詞的使用或者不使用[2],隨后作者風格的研究上升到了語法等層面,以及統計學的發展與應用,風格學中引用了大量的統計學特征,風格學也發展成為了具有統計學特征的計量風格學[3~4]。作者識別問題的研究總是離不開討論風格學,使用計量風格學來進行作者識別的原理是建立在每個作者都有一個獨特并且可驗證特征的假設上,并通過定義高維的特征向量空間來實現識別。
國外最早使用風格學方法分析作者的是英國邏輯學家 Augustus De Morgan[4],他提出用長短詞分析作者風格,國外較為廣泛的研究是對莎士比亞作品的風格研究。我國是四大文明古國之一,具有悠久的歷史和燦爛的文化,但是不少膾炙人口的文學作品卻因為各種原因而無法確定作者,風格學的研究,正是在這種情況在發展起來,其中對紅樓夢的前80回與后60回是否為同一作者的研究最為廣泛。在此基礎上,中科院聲學所張運良等使用概念層次網絡(HNC)標注句類特征,并結合向量空間(VSM)的方式來實現對作者寫作風格分類,在11個作者的文本集上最好效果達到84.0%[5]。清華大學孫曉明,金奕江等使用虛詞和VSM結合的方式來實現小說的分類,在13個作者的數據集上,使用了模板匹配算法,KNN算法和SVM算法的最好準確率分別是 89.51%,91.54%,93.58%[6]。常淑惠等采用語言,結構和格式結合的方式,對5個作者共150個郵件進行識別,最好的F1值達到了98.36%[7]。
在詞匯層面的基礎上增加語義信息,能夠增強特征的可說服性,也就增加結果的可信服性[8]。語法層面的分析有很多種,以詞性為對象來研究作者特征,在英文作者識別中有較好的表現[9]。但是以詞性序列結合中文語法結構分析特點的研究還不是很多,本文提出了一種以文本詞性標注序列為數據集,采用關聯挖掘的Apriori算法來挖掘文本中具有一定關聯程度的詞性序列作為特征的方法,并結合虛詞詞性,中文知識庫HowNet的情感詞庫作情感映射得到文本的情感偏向[10],以及句長,詞長,詞語豐富程度等一些傳統結構上的特征,構成多層次的豐富特征向量,采用機器學習分類方法進行分類,實現了提升作者識別問題的準確性,以及理論上的可說服性。
2 詞和詞性序列
2.1 實詞和虛詞
根據現代漢語詞的語法特征,可以將詞分為實詞和虛詞兩類,實詞包括名詞、動詞、形容詞、數詞、量詞、代詞,虛詞包括副詞、介詞、連詞、助詞、嘆詞、擬聲詞[11]。漢語語法中的虛詞在英語語法中也稱為功能詞,與國外學者使用功能詞進行英文作者識別一樣,使用虛詞來進行中文作者識別的研究也有很多,使用實詞分析的方法較少。實際上,風格學認為,作者的風格是獨立于文章內容的,而實詞容易帶有作者的內容信息,實詞是不適合作為作者識別特征的。雖然實詞不適合用來作為作者識別的特征,但是實詞詞性可以用來研究作者寫句子時不同詞性的詞的使用規律。
2.2 詞性序列
如圖1所示,現代漢語語法的幾個層面分別是詞、短語、句子、段落文章。短語由詞組成,也是句子的組成成分,所以以短語作為研究對象相比詞能夠增加語義信息,相比句式,增加了靈活性。
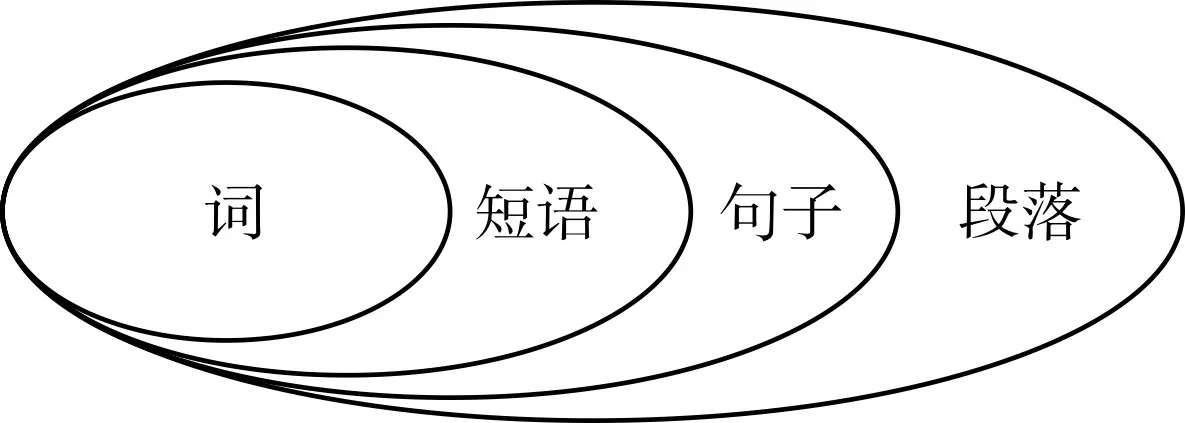
圖1 現代漢語語法層次
受到中科院聲學所張運良等使用概念層次網絡(HNC)標注句類特征理論基礎句子有限而句類無限的理論啟發[5],本文認為組成句子的短語雖然無限,但是短語的類型應該是有限的。短語的詞性序列能夠反映作者在寫作構成句子時的用詞搭配習慣,體現詞性之間的距離特點,理論上能達到區分作者的寫作風格差異的目的。所以本文使用詞性序列作為組成文本向量特征空間(Text Vectors Space)的組成成分之一的方法,用來提升作者識別的準確性和說服性。
本文采用的是哈工大發布的開源切詞工具hanlp作為切詞和詞性標注工具,hanlp詞性共148,二項詞性序列共有21904組合,三項詞性序列總計有3241792組合,不是所有序列組合都能出現在文章中,且并非所有在作者文章中出現的詞性序列都能作為作者的風格特征。因此需要采用一些篩選方法來選擇具有可靠性或者可信度的特征。因為篩選的目的是選取作者常用且具有一定可信度的詞性序列,而不是隨機組成的詞性序列,關聯挖掘方法Apriori算法是經典的挖掘頻繁項集的算法,也是挖掘關聯規則算法的常用算法之一,其應用主要是通過減少項集組合的數目,來達到減少搜索空間大小以及掃描次數的目的,恰好能挖掘得到可靠的詞性序列。本文以實驗文本中的句子詞性序列數據庫作為挖掘具有關聯的詞性序列,其流程如圖2所示。
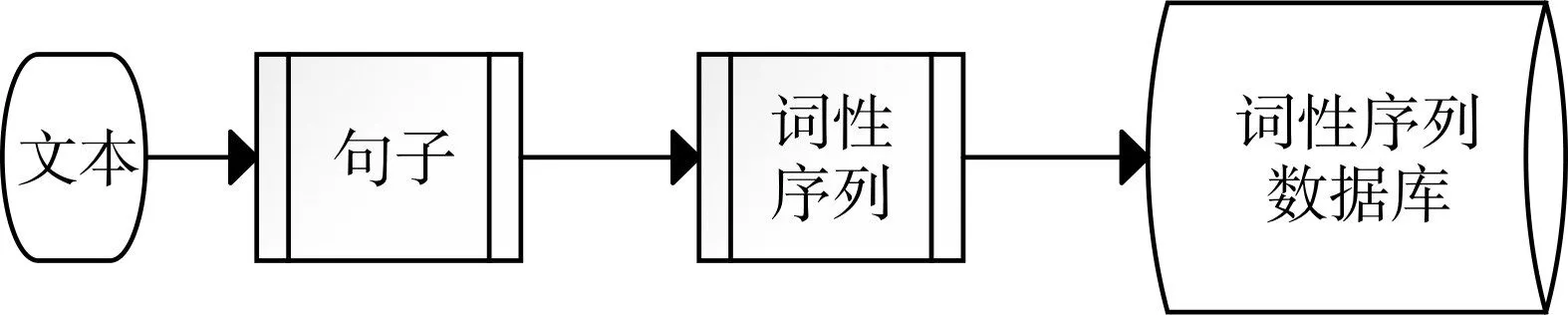
圖2 詞性序列數據庫生成流程
3 Apriori算法詞性序列挖掘過程
3.1 Apriori算法中的支持度與置信度
Apriori算法核心思想是通過連接產生候選項及其支持度,然后通過剪枝生成頻繁項集。其中項集是項的集合,包含k個項的項集稱為k項集。支持度反映兩個項同時出現的可能性,置信度反映了兩個項集之間的關聯強度[12]。項集A,B同時發生的概率為關聯規則的支持度,記為Support(A?B)(簡記為S(A?B)):
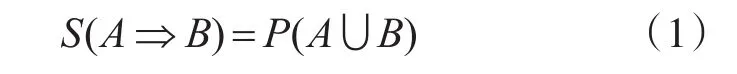
項集A發生的前提下,B發生的概率為關聯規則的置信度,記為Confidence(A?B)(簡記為C(A?B)):

項集A的支持度計數是項集的頻率或者計數,記A,B項集同時發生個數為S_count(A∩B),所有項集同時發生個數為Total_count(A),則項集A,B的支持度S(A?B)計算方式如下:
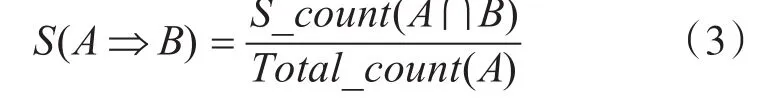
項集A,B的置信度:
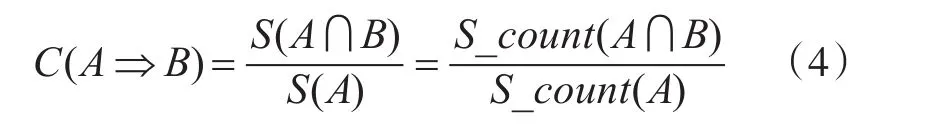
最小支持度是用戶或者專家定義的衡量支持度的一個閾值,標志項集在統計意義上的最低重要性,最小置信度是用戶或者專家定義的衡量置信度的一個閾值,標志關聯規則的最低可靠性,同時滿足最小支持度閾值和最小置信度閾值的規則稱作強規則。
3.2 詞性序列挖掘過程
Apriori算法主要為兩個過程,一個是找出所有頻繁項集,一個是由頻繁項集產生強關聯規則。在挖掘頻繁項集合最強規則前,需要給出最小支持度和最小置信度的值。因為支持度反映項集的出現頻率,本文選擇了小概率事件中的臨界概率0.01作為最小支持度。置信度反映的是規則的可靠程度,本文選擇0-1均勻分布的期望,也就是0-1事件的任一發生概率0.5,作為最小置信度來選擇詞性序列的頻繁項集。
詞性序列挖掘的第一步,找到所有的頻繁項集,首先和一項序列結合生成k+1項,再通過最小支持度和頻繁項集的子集也是頻繁項集這一原理進行剪枝,其過程如圖3所示。第二步是在所有頻繁項集的基礎上,計算項集的置信度,與最小置信度為篩選條件,得到滿足最強規則(最小支持度和最小置信度)的序列項集,其樣例如表1所示。
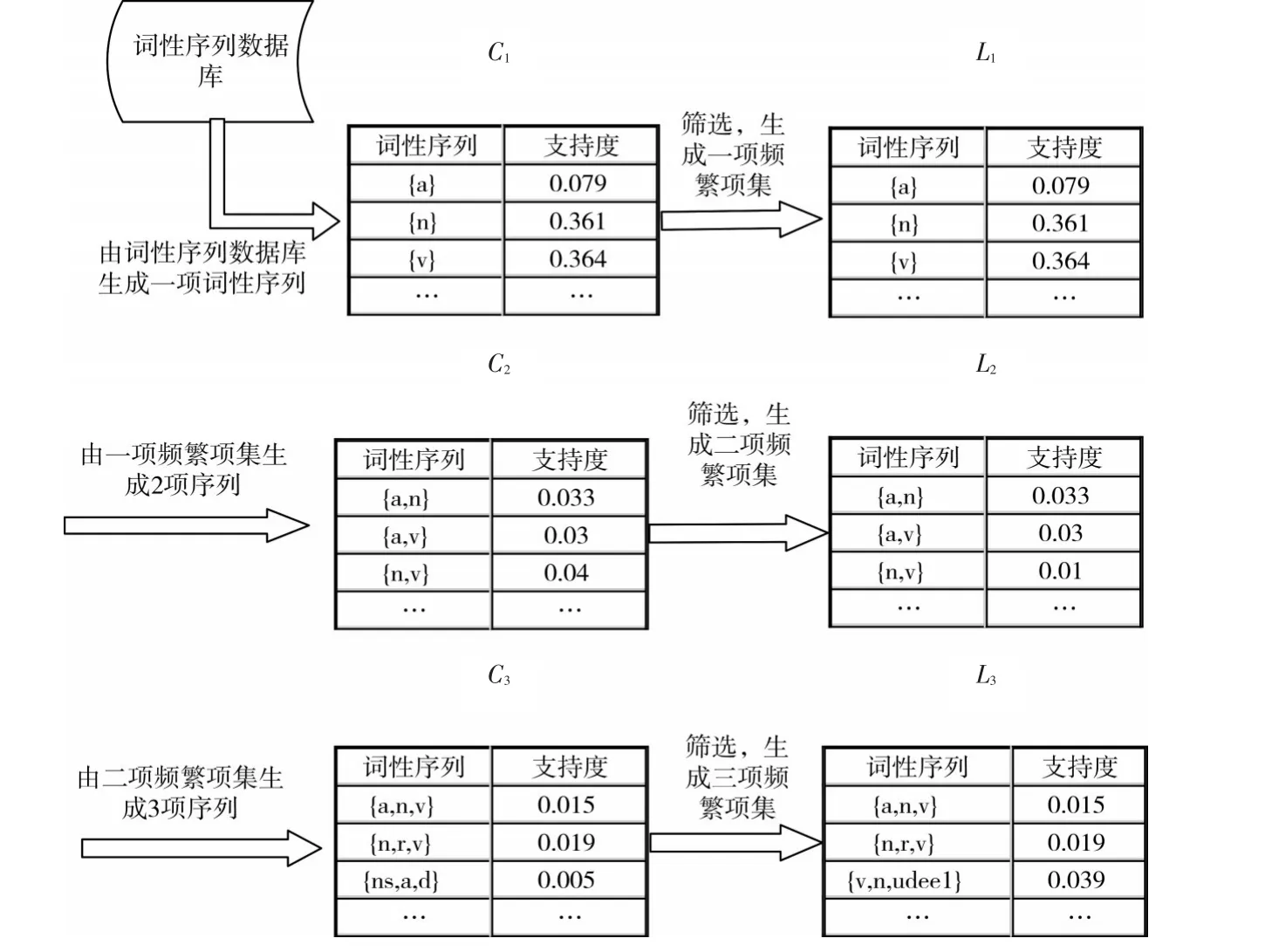
圖3 頻繁項集生成過程
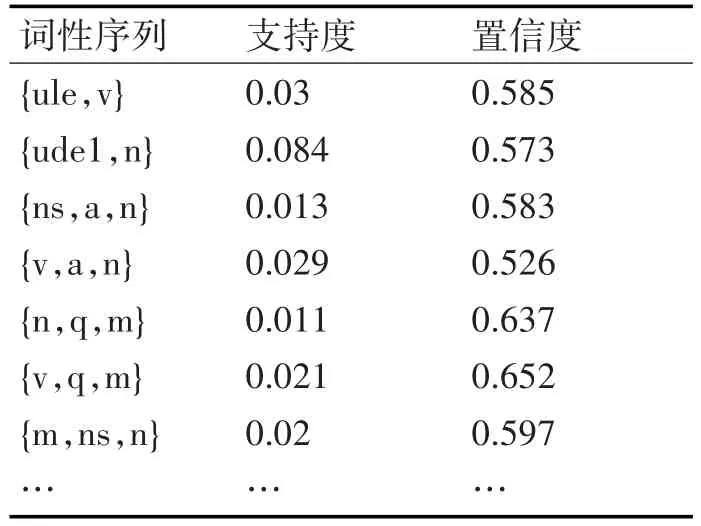
表1 關聯詞性序列樣例
使用以上方法挖掘得到的每位作者的頻繁項集,并通過取每一位作者與其他作者差集的方式,找到每個作者獨特的詞性序列組合,共得到22個詞性序列特征。
4 實驗數據與文本向量
4.1 實驗數據說明
從大眾的認知基礎上分析,如果作者的風格差異較大,比如魯迅和張愛玲的風格對比來看,魯迅是批判現實的短篇小說家,散文家,張愛玲是以描寫生活風月為主的小說作家,無論是人為的根據經驗,還是使用統計方法,都是比較容易區分的。武俠小說作者金庸、古龍、東方玉、梁羽生所處時代相似,都是比較有名且具有代表作品的武俠小說作者,因為創作時間和主題相似,且部分作品會受到先發表作品的作者影響而具有一定的風格相似性,如果不是有非常豐富的經驗,或者是采用復雜的統計學方法,是比較難以區分的[13]。所以本文使用Python爬蟲工具和解析工具從武俠小說網站清洗得到了四位作者的部分或者全部小說作品作為了本次的實驗數據如表2。
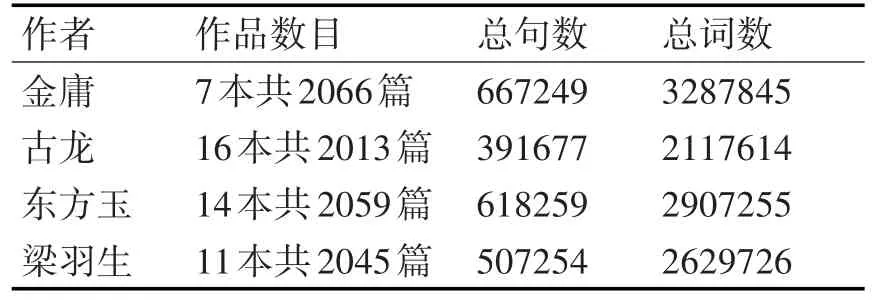
表2 實驗數據說明
4.2 文本向量構成
風格學研究至今,對寫作風格分析的特征選取一般分為詞匯特征,語法特征,結構特征,非語言特征四大模塊,這四個模塊分別包含一些小的可選取子模塊,其子模塊樣例如表3所示。
其中結構特征被廣泛認為是穩定可區分作者的特征,本文選取了詞長平均,詞長方差,句長平均,句長方差等常用的結構特征共7個。同時因為非語言模塊中作者的情感傾向也能反映作者的風格,本文以知網的hownet知識庫中的情感詞作為映射,統計文章的消極情感詞匯和積極情感詞匯,以及正面評價詞匯和負面評價詞匯占比等8個情感偏向特征作為特征向量成分之一。

表3 風格學特征模塊樣例
綜合以上分析,本次實驗特征向量構成成分分為四個部分,總共83個:
1)通過Apriori算法挖掘得到的關聯詞性序列22個;
2)虛詞詞性特征共46個;
3)包括詞長,句長等文本結構特征共7個;
4)包括情感詞和評價詞等情感特征共8個。
5 分類器選擇與結果分析
用于分類的機器學習方法有很多,常用的有邏輯回歸,隨機森林,K近鄰算法等等。隨機森林是集成學習器,具有較好的分類能力和穩定性[14]。邏輯回歸分類器是簡單易懂的分類器,其缺點是其適用場景和數據有限,不如隨機森林強[15]。K近鄰是理論比較成熟的方法,不需要訓練模型,只在測試數據中進行計算,其缺點是在在數據量小的時候容易誤分,只適合樣本容量比較大的數據[16]。本文使用以上三種分類器,采用F1值作為評價指標,計算十次實驗結果取平均值和方差,分別用來衡量分類器的并計算十次結果的方差(分類結果后括號內)的方差作為得到三個分類器表現如下表4所示。
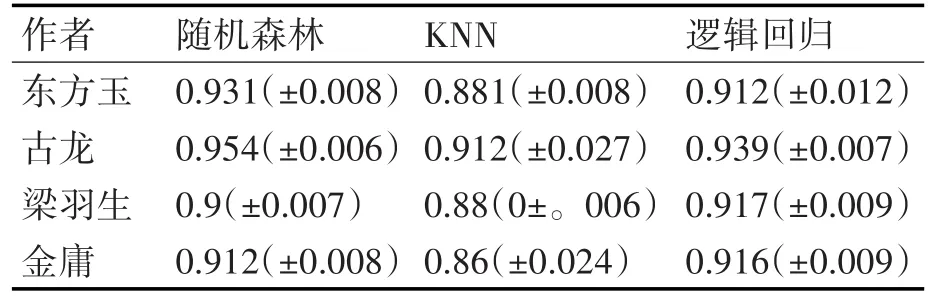
表4 作者識別結果
綜合表現來看,東方玉、古龍、金庸三位作者使用隨機森林做分類的準確率最高,梁羽生使用邏輯回歸的準確率最高,但是隨機森林分類結果的方差最小且最平穩,表明了隨機森林作為一種集成的分類器,其本身分類能力較好且穩定,適合作為作者識別模型的分類器。
同時,采用隨機森林重要程度排序的功能,對特征的重要程度排序,取前20個重要特征,排序結果如表5所示。

表5 隨機森林特征排序結果
根據排序可以看出,具有關聯特征的詞性序列在作者在區分作者寫作風格中具有一定的重要性,但是虛詞明顯比詞性序列作用更強,因此,對虛詞在在作者識別應用中的研究,可以作為下一步研究的方向之一。
此外,詞性序列寫作特征不僅可以用于作者識別中,結合現在十分火熱的機器寫作來看,因為其語法的約束性,也可以用于其中,為機器寫作增加一定的語法約束,提高寫作的水平。
6 結語
本文是受到HNC的句類理論啟發提出的使用具有關聯度的詞性序列作為特征向量組成成分之一,經過實踐驗證,具有關聯的詞性序列特征確實能達到提升識別作者的效果,但是隨機森林的特征排序結果顯示虛詞詞性的統計值在分類過程中影響程度更大,為此,在下一步研究中,將從虛詞特征著手,進一步通過提高特征質量來提高作者識別這一應用中的準確率和召回率。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
