基于稠密自編碼器的無監(jiān)督番茄植株圖像深度估計模型
2020-07-22 14:37:12周云成鄧寒冰許童羽
農(nóng)業(yè)工程學(xué)報 2020年11期
周云成,鄧寒冰,許童羽,苗 騰,吳 瓊
(沈陽農(nóng)業(yè)大學(xué)信息與電氣工程學(xué)院,沈陽 110866)
0 引 言
由于作物生長等,日光溫室通常為不斷變化的非結(jié)構(gòu)化環(huán)境,在該環(huán)境下自主作業(yè)的移動機(jī)器人需要識別行進(jìn)通道與障礙物[1],規(guī)劃作業(yè)路徑[2],同時在采摘[3]、施藥[4]等生產(chǎn)過程中則需要定位作業(yè)目標(biāo)。這要求機(jī)器人首先能夠利用自身視覺系統(tǒng)探索出工作環(huán)境的三維空間結(jié)構(gòu)信息,而深度估計是實現(xiàn)這一任務(wù)的關(guān)鍵,也是視覺系統(tǒng)的基本問題之一。
激光雷達(dá)(Light Detection and Ranging,LiDAR)、Kinect 等有源傳感器和圖像技術(shù)常被用于深度信息獲取。Masuzawa 等[5]用LiDAR 感知深度,結(jié)合數(shù)碼相機(jī),開發(fā)了溫室花卉收獲移動機(jī)器人原型。孫國祥等[6]基于Kinect,用多視角RGB-D(紅綠藍(lán)—深)位姿自主標(biāo)定法和相位相關(guān)技術(shù),結(jié)合多光譜數(shù)據(jù),重建溫室番茄植株多模態(tài)三維模型。肖珂等[2]用形態(tài)學(xué)方法從Kinect 的RGB 圖像中分割葡萄園葉墻區(qū)域,結(jié)合深度數(shù)據(jù),基于樣條區(qū)域計算葉墻平均距離,用于規(guī)劃自走式農(nóng)藥噴施試驗平臺的行進(jìn)路徑。有源傳感器可直接感知深度,但目前還存在著一些制約因素。LiDAR 成本高昂[7],且僅有深度信息,通常需要和其他成像設(shè)備集成才能構(gòu)成作業(yè)平臺的視覺系統(tǒng)。Kinect 采用光飛行時間技術(shù)獲取深度信息,但其投射的紅外激光極易受日光干擾,深度數(shù)據(jù)噪聲大,溫室環(huán)境適應(yīng)性差。基于圖像的立體匹配是另一種常用的深度信息獲取技術(shù)。翟志強(qiáng)等[8]用最小核值相似算子提取棉田圖像角點特征,通過基于Census 變換的立體匹配計算作物行特征點坐標(biāo),用于擬合其中心線。植株圖像紋理單一、重復(fù),人工設(shè)計的特征提取算子可區(qū)分度小,誤匹配嚴(yán)重。近年來,以卷積神經(jīng)網(wǎng)絡(luò)(Convolution Neural Network,CNN)為代表的深度學(xué)習(xí)技術(shù)在單目深度估計中取得了重要進(jìn)展[9-14],逐漸成為圖像深度恢復(fù)的主要方法。區(qū)別于人工特征,CNN 用自動提取的豐富卷積特征實現(xiàn)基于圖像的深度恢復(fù)。通過使用帶有深度標(biāo)注的圖像,Eigen 等[9]用有監(jiān)督學(xué)習(xí)法訓(xùn)練了一個基于CNN 的深度估計模型。然而采集大量含高精度深度信息的多樣性圖像數(shù)據(jù)是極具挑戰(zhàn)性的[10],且有監(jiān)督學(xué)習(xí)無法適應(yīng)變化的環(huán)境。近期有學(xué)者研究僅利用同步立體圖像或視頻流訓(xùn)練單目深度估計模型。Godard等[11]提出一種基于左右目約束的無監(jiān)督深度估計方法。Wang 等[12]將可微分視覺里程計集成到單目模型中,用連續(xù)視頻幀做輸入,通過無監(jiān)督學(xué)習(xí),實現(xiàn)深度和位姿變換的同步預(yù)測。Pilzer 等[13]通過知識蒸餾技術(shù)無監(jiān)督訓(xùn)練單目深度估計模型。單目深度估計存在尺度模糊問題,深度預(yù)測值和實際值之間存在著一個未知比例系數(shù),且用視頻流訓(xùn)練單目模型的前提假設(shè)是場景靜止[14],即只有相機(jī)相對于場景做運(yùn)動。由于作物植株體為柔性材料,機(jī)器人運(yùn)動以及風(fēng)對植株的擾動,使得場景并非絕對靜止。
鑒于溫室移動機(jī)器人對深度信息獲取的實際需求,以及單目深度估計模型存在的問題,提出一種基于稠密卷積自編碼器的無監(jiān)督植株圖像深度估計模型,該模型用雙目相機(jī)采集的左、右目圖像進(jìn)行訓(xùn)練,通過圖像采集的同步性及相機(jī)已知參數(shù)來克服單目深度估計存在的問題。借鑒已有研究成果,優(yōu)化設(shè)計深度卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)和模型損失函數(shù),以模型估計的深度值誤差及閾值精度等為判據(jù),以番茄植株圖像為例,驗證模型的有效性,以期為溫室移動機(jī)器人視覺系統(tǒng)設(shè)計提供參考。
1 植株雙目圖像數(shù)據(jù)集構(gòu)建
用Stereolabs ZED 2k 雙目相機(jī)采集數(shù)據(jù),該設(shè)備可同步采集左、右目 RGB 圖像,單目圖像分辨率為1 920×1 080 像素,有效采樣距離為0.5~20 m。為獲取相機(jī)參數(shù)并矯正圖像畸變問題,基于Zhang[15]的方法,采集高精度棋盤格圖像,并采用MATLAB R2018a 中的立體相機(jī)標(biāo)定工具箱對相機(jī)進(jìn)行標(biāo)定,得到雙目相機(jī)的焦距f、像平面主點坐標(biāo)[ cx, cy]、左右鏡頭光心間的基線距離(b,mm)以及畸變系數(shù)等內(nèi)、外參數(shù)。
圖像數(shù)據(jù)于2019 年1-3 月采集自沈陽農(nóng)業(yè)大學(xué)實驗基地某遼沈IV 型節(jié)能日光溫室(60 m×10 m)和沈陽市遼中區(qū)某生產(chǎn)用日光溫室(150 m×9 m),種植作物為番茄,掉蔓生長,株高1.5~2.7 m,行距0.8~1.0 m,株距0.25~0.35 m,處于結(jié)果期。分別在陰天、多云和晴朗天氣的9:00-15:00時段采集多種光照條件下的植株圖像并記錄天氣狀況。在行間不同高度沿株行方向多角度對相機(jī)前方場景成像,并在離株行0.5 m 以上距離對一側(cè)植株成像,同時沿溫室行走通道對含植株的場景進(jìn)行圖像采集,以盡量提高樣本的多樣性。共采集番茄植株雙目圖像16 000 對。
基于相機(jī)內(nèi)、外參數(shù),采用Bouguet 法[16],對雙目圖像進(jìn)行校正,使相機(jī)光軸平行,同一空間點在左、右目圖像上所成像素行對齊(行號相同)。對于每一對校正后的雙目圖像,采用立體匹配法獲取稀疏視差值,用尺度不變特征變換(Scale-Invariant Feature Transform,SIFT)算子[17]分別提取左、右目圖像的特征點,用K 最近鄰算法對雙目圖像中的特征點進(jìn)行匹配,并用人工走查的方式剔除誤匹配點。根據(jù)匹配特征點的坐標(biāo),得到稀疏特征點間的實際視差值。全部雙目圖像及相應(yīng)稀疏視差值共同構(gòu)成番茄植株雙目圖像數(shù)據(jù)集。
2 無監(jiān)督植株圖像深度估計模型的提出
2.1 圖像視差及置信度估計方法
設(shè)空間點P 在左、右目圖像上的投影像素(稱為對應(yīng)像素)坐標(biāo)分別為[ xl, yl]、[ xr, yr],根據(jù)雙目視覺原理如式(1)所示

式中 d = xl- xr表示視差,[ X , Y , Z ]為P 的三維坐標(biāo),mm。如f、b、[ cx, cy]已知,通過估計對應(yīng)像素間的視差,可實現(xiàn)場景深度Z 及三維結(jié)構(gòu)信息的恢復(fù)。

式中 lpe 為對 Il~ 與 Il的相似度度量,并規(guī)定其值越小相似度越高。同理,用 rpe 表示 Ir~ 與 Ir的相似度。采用深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Network,DNN)來逼近函數(shù)g,以為主要優(yōu)化目標(biāo),用雙目圖像對其進(jìn)行訓(xùn)練。該方法無需深度數(shù)據(jù)作標(biāo)注,屬無監(jiān)督學(xué)習(xí)。
2.2 損失函數(shù)的定義
2.2.1 圖像重構(gòu)損失
現(xiàn)有研究采用光度誤差和結(jié)構(gòu)近似度指數(shù)(Structural Similarity Index,SSIM)[18]的組合作為pe 函數(shù)[11-14]。植株器官非理想朗伯體,且左、右目相機(jī)物理特性存在差異,對應(yīng)像素在雙目圖像上的光度值可能不同,即使DNN預(yù)測的視差是準(zhǔn)確的,重構(gòu)圖像與目標(biāo)圖像也會有差異,僅含光度、對比度和簡單結(jié)構(gòu)特征比較的光度誤差和SSIM 組合不足以度量植株圖像的相似性。本研究引入更加多樣性[19]的卷積特征比較。用完成訓(xùn)練的Inception V3網(wǎng)絡(luò)的前4 層[20]卷積特征來進(jìn)一步度量2 幅圖像的相似性,如式(3)所示
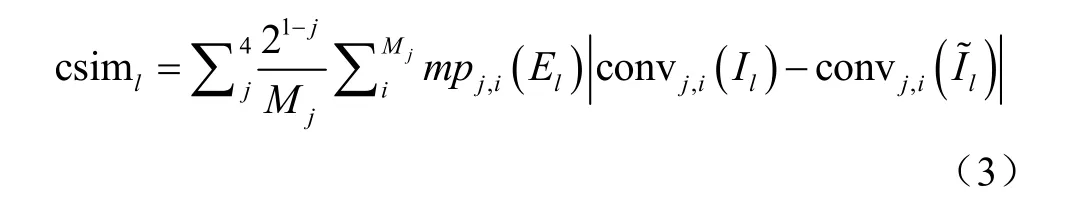
式中csiml表示l與 Il的卷積特征近似性,convj為Inception V3 網(wǎng)絡(luò)的第j 層卷積操作,c onvj,i( Il)為圖像 Il的第j 層卷積特征圖的第i 個像素, Mj為第j 層特征圖的像素數(shù),mp 表示最大池化(max-pooling),用 21-j作為系數(shù),調(diào)整各層特征對近似性度量的貢獻(xiàn)。采用置信度 El抑制因消失點而無法重構(gòu)的像素所引入的問題梯度,式(3)的計算需要置信度圖與卷積特征圖在空間尺度上相同,用mp 對 El進(jìn)行空間降維,使 jmp 與convj的累積感受野相同。用L1(1 范數(shù))形式光度誤差、SSIM和csim 的線性組合重新定義pe 函數(shù)如式(4)所示

式中M 為圖像像素數(shù), I,li等表示 Il的第i 個像素,α 、β 、γ 為各項的比例調(diào)整系數(shù)。
2.2.2 約束項
在式(4)基礎(chǔ)上進(jìn)一步為DNN 的訓(xùn)練引入多個約束項。視差跳變通常在具有顯著圖像梯度的目標(biāo)邊緣區(qū)域。采用二階Laplacian 算子2?提取圖像梯度,對低圖像梯度區(qū)域的視差跳變進(jìn)行局部平滑約束,如式(5)所示

式中Lsm,l表示左目視差局部平滑約束, ?xx、 ?yy、 ?xy表示在x、y 方向和對角線上的二階梯度。由像素對應(yīng)關(guān)系,在 Dr上采樣重構(gòu)的左目視差圖應(yīng)和 Dl具有一致性,采用式(6)對視差一致性進(jìn)行約束。


2.2.3 損失函數(shù)
以圖像重構(gòu)損失和各約束項的線性組合作為DNN優(yōu)化訓(xùn)練的損失函數(shù),如式(8)所示

式中 ,t lL 表示針對左目視差和置信度的損失,η、λ、ζ 表示各項損失的比例系數(shù)。基于 Ir、r、Dr、 Er,按式(3)~式(8)方式構(gòu)建右目視差和置信度損失 ,t rL ,左、右目總損失為
2.3 視差估計精度判據(jù)
設(shè)番茄植株雙目圖像數(shù)據(jù)集中視差值已知的稀疏點數(shù)量為N, di為像素i(N 中的1 個)的實際視差值, di為DNN 估計視差值。由式(1)計算出i 在左目相機(jī)坐標(biāo)系下的三維實際坐標(biāo)[ Xi, Yi, Zi]和估計坐標(biāo)。基于此,按現(xiàn)有研究常采用的標(biāo)準(zhǔn)評估指標(biāo)評價視差估計精度[9-14],主要包括估計深度i和實際深度 Zi間的平均相 對 誤 差( Mean Relative Error , Rel ) 為平方相對誤差(Squared Relative Error,Sq Rel,mm)為平均絕
對 誤 差( Mean Absolute Error , MAE , mm) 為均方根誤差(Root Mean Squared Error,RMSE,mm)為10log RMSE(RMSElog)為閾值精度,%,即滿足的點i 占總量N 的比例(本研究設(shè)置從而,進(jìn)一步引入估計坐標(biāo)和實際坐標(biāo)間的平均距離誤差(Mean Range Error,MRE,mm)為來衡量估計視差的精度。各誤差指標(biāo)越小、閾值精度指標(biāo)越大,則說明視差估計的精度越高。
同時用重構(gòu)圖像 Il~ 與目標(biāo)圖像 Il的相似度來間接度量視差圖精度。本研究采用與主觀評價法具有高度一致性的特征相似性指數(shù)(Feature Similarity Index,F(xiàn)SIM)[21]、信息內(nèi)容加權(quán)SSIM(Information Content Weighted SSIM,IW-SSIM)[22]和梯度相似性指數(shù)(Gradient Similarity Index,GSIM)[23]作為相似度(%)評價指標(biāo),指標(biāo)值越高說明圖像相似度越大。
3 深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計
以姿態(tài)估計[24]、語義分割[25]等任務(wù)中常用的卷積自編碼器(Convolutional Auto-Encoder,CAE)作為逼近函數(shù)g 的DNN 基本結(jié)構(gòu),并進(jìn)行設(shè)計優(yōu)化。
3.1 基于可分卷積的稠密卷積模塊設(shè)計
受Jégou 等[26]的研究啟發(fā),用稠密卷積模塊(Dense Convolution Block,DB)[27]作為CAE 的構(gòu)建組件。對于有n 層卷積(n 為超參數(shù))構(gòu)成的DB 模塊,其第j 層輸出特征圖 xj是定義在模塊初始輸入 x0及j 層之前各層輸出( x1~xj-1)上的非線性變換,如式(9)所示

式中 jH 為第j 層的非線性變換,[ ]… 表示在通道維上的特征圖連接。DB 模塊的每層卷積均固定輸出k 個特征圖,k 稱為增長率超參數(shù),在通道維上連接n 層輸出,構(gòu)成nk個通道的特征圖作為其最終輸出。
用可分卷積(Separable Convolution,SepConv)[28]替換原DB 模塊[27]中的標(biāo)準(zhǔn)卷積,用SepConv、批歸一化(Batch Normalization,BN)和激活函數(shù)的順序組合作為非線性變換H,構(gòu)建基于SepConv 的DB 模塊(圖1a)。SepConv 首先在輸入特征圖的每個獨立通道上用步長(stride,s)為1 且啟用邊界填充(pad)的3×3 深度卷積來映射空間相關(guān)性,然后用1×1 點卷積來映射通道間相關(guān)性。設(shè)SepConv 的輸入、輸出通道數(shù)分別為A 和B,其權(quán)重參數(shù)數(shù)量而對應(yīng)標(biāo)準(zhǔn)卷積的參數(shù)量為當(dāng)B 較大時,SepConv的參數(shù)量約為后者的1/9。因此,基于SepConv 構(gòu)建 DB模塊能有效降低參數(shù)數(shù)量。
3.2 卷積自編碼器構(gòu)建
基于DB 模塊構(gòu)建CAE(圖1)。其中編碼器包括1個輸入模塊(Input Block,IB)、4 個帶旁路連接的DB模塊(圖1b)和4 個下采樣層。IB(圖1c)采用s 為2、啟用pad 且輸出通道數(shù)為2 倍增長率的5×5 卷積(conv 2k, 5×5, s=2, pad)對在通道維上連接后的雙目圖像進(jìn)行卷積運(yùn)算,使輸出特征圖在空間維減半[29]。下采樣層采用s為2、啟用pad 且輸出通道數(shù)與輸入相同的3×3 可分卷積(SepConv 3×3, s=2, pad),該層在對特征圖進(jìn)行空間降維的同時,提取和融合DB 模塊的輸出特征。解碼器對應(yīng)包含4 個上采樣層、4 個DB 模塊和1 個終端模塊(Ending Block,EB)。上采樣層采用s 為2、啟用pad、輸出通道數(shù)與輸入相同的 3×3 轉(zhuǎn)置卷積(Transposed Convolution,TransConv)使特征圖在空間維擴(kuò)大2 倍。EB(圖1d)先用上采樣層將特征圖恢復(fù)為輸入圖像相同尺寸,再用啟用pad 的SepConv k,3×3 的特征圖作為輸出,用于進(jìn)一步的視差和置信度預(yù)測。解碼器的DB 模塊不采用旁路連接,避免經(jīng)上采樣層逐漸放大后的特征圖因不斷累積而帶來的巨量計算和存儲需求。CAE 的瓶頸層同樣采用DB 模塊。

圖1 卷積模塊 Fig.1 Convolution blocks
編、解碼器之間的跨越連接[9-14]可解決下采樣造成的目標(biāo)邊緣、位置等細(xì)節(jié)信息消失問題。假設(shè)CAE 對視差的預(yù)測依賴于對應(yīng)像素在空間維上建立的相關(guān)性,則視差較大的對應(yīng)像素需經(jīng)過多層下采樣才可建立相關(guān)性,這將降低位置信息的準(zhǔn)確性,進(jìn)而影響視差預(yù)測精度。基于該假設(shè),提出在跨越連接上引入跨越模塊(Skip Block,SKB),通過SKB(圖1e)的累積感受野來降低為建立相關(guān)性而需經(jīng)過的下采樣層數(shù)。SKB 在內(nèi)部采用DB 模塊擴(kuò)大累積感受野,在輸入端用輸出通道數(shù)為該DB 模塊輸出通道數(shù)一半的conv nk/2,1×1,s=1 壓縮來自編碼器的特征通道維數(shù),輸出端則用conv nk,1×1,s=1融合DB 模塊的輸出特征。
3.3 視差及置信度預(yù)測
采用conv 4,3×3,s=1,pad 標(biāo)準(zhǔn)卷積作為視差及置信度預(yù)測模塊(Disparity and Confidence Block,DCB),該模塊(圖1f)用Sigmoid 函數(shù)對4 個輸出特征圖進(jìn)行歸一化,其中2 個作為對 Dl、Dr的歸一化預(yù)測,另外2個作為對 El、 Er的預(yù)測。設(shè)歸一化視差值為d˙,最大視差占圖像寬度 W 的比例不高于ω ,則實際視差值歸一化處理可避免DCB 預(yù)測出異常( 0d< 或d W> )視差。
fw對采樣點鄰近像素采樣來重構(gòu)圖像,其回傳梯度具有局部性,不利于網(wǎng)絡(luò)在大尺度范圍內(nèi)探索對應(yīng)像素間的相關(guān)性[10-11]。本研究通過預(yù)測多尺度視差圖來克服該問題,將4 個DCB 分別連接到解碼器EB 及末端3 個DB 上。與輸入圖像尺寸相比,DCB1~DCB4分別預(yù)測1、1/2、1/4 及1/8 尺度的視差及置信度圖。同時,將DCB的預(yù)測結(jié)果在通道維上與相應(yīng)DB 的輸出特征圖連接(圖 1g)后送入下一模塊,用于下一尺度視差及置信度圖的預(yù)測。分別計算每一尺度視差及置信度損失網(wǎng)絡(luò)的總損失由各尺度損失求和得到通過以式(10)為CAE 的訓(xùn)練優(yōu)化目標(biāo),得到各尺度視差及置信度圖。


圖2 稠密卷積自編碼器 Fig.2 Dense convolutional auto-encoder
在 L(p)t的計算中,本研究分別將DCB2~DCB4預(yù)測的視差及置信度圖上采樣到網(wǎng)絡(luò)輸入圖像的尺度后再進(jìn)行圖像重構(gòu)和損失計算(圖3),以提高回傳梯度的質(zhì)量。

圖3 上采樣及損失計算模型 Fig.3 Up-sampling and loss calculation model
4 深度估計試驗與結(jié)果分析
4.1 參數(shù)設(shè)置及網(wǎng)絡(luò)訓(xùn)練
(CNT K)v2.7[29]基礎(chǔ)上,采用其提供的Python 接口編程在深度學(xué)習(xí)計算框架 Microsoft Cognitive Tools實現(xiàn)無監(jiān)督植株圖像深度估計網(wǎng)絡(luò)模型。 fw用空間變換網(wǎng)絡(luò)(Spatial Transformer Network,STN)[30]的可微分雙線性插值采樣函數(shù)實現(xiàn)。根據(jù)預(yù)試驗,損失函數(shù)的調(diào)整系數(shù)分別設(shè)置為 α=0.15、 β=0.85、 γ=1.0、 η=1.0、λ=0.15、 ζ=8.0可取得理想結(jié)果。根據(jù)雙目圖像采集設(shè)備的參數(shù),設(shè)置最大視差占圖像寬度比例系數(shù) ω=0.3。
用在計算機(jī)視覺任務(wù)[24-27]中廣泛采用的自適應(yīng)矩(Adaptive Moment,Adam)優(yōu)化器訓(xùn)練網(wǎng)絡(luò)模型,設(shè)置1 階矩指數(shù)衰減率 β1=0.9、2 階矩指數(shù)衰減率 β2=0.999、權(quán)重衰減系數(shù)為10-4,用初始學(xué)習(xí)率2.5×10-4進(jìn)行20 輪(epochs)迭代訓(xùn)練,此后每經(jīng)10 輪迭代,學(xué)習(xí)率下降10 倍[14]。預(yù)試驗表明,經(jīng)過40 輪迭代,網(wǎng)絡(luò)損失可收斂到穩(wěn)定值。
網(wǎng)絡(luò)模型的訓(xùn)練和測試試驗在Tesla K40c 計算卡上進(jìn)行,試驗用計算機(jī)配置有32 GB 內(nèi)存,雙路Intel Xeon E2603 處理器,Windows Server 2012 操作系統(tǒng)。每個網(wǎng)絡(luò)重復(fù)試驗5 次,每次試驗從由16 000 對番茄植株雙目圖像構(gòu)成的數(shù)據(jù)集中隨機(jī)選擇85%的樣本用于網(wǎng)絡(luò)模型訓(xùn)練,其余15%的樣本(測試集)用于網(wǎng)絡(luò)精度的測試。
網(wǎng)絡(luò)輸入圖像的大小設(shè)置為512×384 像素。網(wǎng)絡(luò)訓(xùn)練過程中采用數(shù)據(jù)增廣技術(shù)來提高其泛化效果。首先對原雙目圖像進(jìn)行裁剪,方法為對雙目圖像上的相同位置進(jìn)行隨機(jī)裁剪(crop),裁剪后的寬、高不低于原圖像的85%,然后將裁剪后的圖像用最鄰近插值法調(diào)整為輸入大小。接著對調(diào)整大小后的圖像進(jìn)行隨機(jī)水平翻轉(zhuǎn)和垂直翻轉(zhuǎn),并對其亮度、對比度和飽和度作隨機(jī)調(diào)整,用以模擬多種光環(huán)境下的RGB 成像,提高網(wǎng)絡(luò)對光環(huán)境變化的魯棒性。其中亮度和對比度的調(diào)整用實現(xiàn),pix 為像素顏色分量,2 個參數(shù)分別用于隨機(jī)調(diào)節(jié)對比度和亮度。飽和度的調(diào)整需將圖像由RGB 轉(zhuǎn)換為HSV(Hue-Saturation-Value,色相-飽和度-明度)空間,對飽和度S 執(zhí)行[0.85,1.15]范圍內(nèi)的隨機(jī)倍數(shù)變換后,再轉(zhuǎn)回RGB 空間。增廣后的圖像在輸入模塊中用對各像素分量進(jìn)行[-1,1]歸一化,以加快網(wǎng)絡(luò)收斂速度[28]。
4.2 網(wǎng)絡(luò)測試與分析
參照J(rèn)égou 等[26],CAE 網(wǎng)絡(luò)的DB 模塊的超參數(shù)設(shè)置為n=4(瓶頸DB 除外,其n=8)、k=24,為分析網(wǎng)絡(luò)結(jié)構(gòu)對視差預(yù)測精度的影響,通過采用不同處理(表1),構(gòu)建了8 種結(jié)構(gòu)(A~H)的CAE。其中啟用跨越模塊處理指在CAE 的跨越連接上引入SKB,否則采用直連方式。預(yù)測置信度處理指DCB 同時預(yù)測視差圖及相應(yīng)置信度圖,否則僅預(yù)測視差圖(此時,置信度不再參與損失計算,相當(dāng)于置信度圖的所有元素為1)。連接視差圖處理指圖1g 所示的模塊中,僅將DCB 預(yù)測的視差圖連接到對應(yīng)DB 的輸出上,連接置信度處理指僅將置信度圖連接到輸出特征圖上,否則不再連接視差圖或置信度圖。上采樣視差圖處理指將DCB 預(yù)測的低分辨率視差及置信度圖上采樣到與輸入圖像相同尺寸后,進(jìn)行圖像重構(gòu)和損失計算,否則直接在低分辨率預(yù)測結(jié)果上進(jìn)行損失計算。
激活函數(shù)是影響網(wǎng)絡(luò)非線性能力和訓(xùn)練穩(wěn)定性的重要因素。以結(jié)構(gòu)A 為深度估計模型的基礎(chǔ)網(wǎng)絡(luò),在DB模塊的H 函數(shù)和除DCB 模塊以外的其他卷積操作中分別采用指數(shù)線性單元(Exponential Linear Unit,ELU)[31]、縮放ELU(Scaled-ELU,SELU)[32]、修正線性單元(Rectified Linear Unit,ReLU)[19]、滲漏型 ReLU (Leaky-ReLU)[33]和參數(shù)化ReLU(Param-ReLU)[34]共5種在CNN 中常用的非線性變換作為激活函數(shù),開展訓(xùn)練和測試試驗,結(jié)果如表2 所示。

表1 采用不同處理方法的8 種網(wǎng)絡(luò)結(jié)構(gòu) Table 1 Eight network structures with different treatments

表2 激活函數(shù)對深度估計精度的影響 Table 2 Effect of the activation function on accuracy of depth estimation
由表2 可知,激活函數(shù)影響深度估計精度。總體上含ReLU 的激活函數(shù)的各項指標(biāo)都優(yōu)于ELU 和SELU,這可能和后兩者在輸入<0 時易限入飽和區(qū)域,網(wǎng)絡(luò)更新緩慢有關(guān)。ReLU 和Leaky-ReLU 的各項深度估計誤差平均值均低于或顯著低于Param-ReLU,閾值精度也顯著高于后者。最小化圖像重構(gòu)損失是網(wǎng)絡(luò)的主要優(yōu)化目標(biāo),Param-ReLU 包含額外的可學(xué)習(xí)參數(shù),易產(chǎn)生過擬合,這是其圖像相似度平均值高于ReLU 和Leaky-ReLU,但誤差和閾值精度指標(biāo)卻相對較差的原因。Leaky-ReLU 和ReLU 的各項指標(biāo)均沒有顯著差異,但前者具有更小的誤差和更高的閾值精度平均值,這與后者導(dǎo)致的輸出偏移和部分神經(jīng)元死亡有關(guān)。因此,選擇Leaky-ReLU 作為網(wǎng)絡(luò)激活函數(shù),分別對表1 中的8 種結(jié)構(gòu)模型進(jìn)行訓(xùn)練與測試,結(jié)果如表3 所示。

表3 網(wǎng)絡(luò)結(jié)構(gòu)對深度估計精度的影響 Table 3 Influence of the network structure on accuracy of depth estimation
由表3 可知,網(wǎng)絡(luò)結(jié)構(gòu)顯著影響深度估計精度。結(jié)構(gòu)A 在B 的基礎(chǔ)上啟用了SKB,使A 在5 種深度估計誤差平均值上低于B,在閾值精度和圖像相似度上也高于后者,說明SKB 對提高深度估計精度具有一定作用。A 在C 的基礎(chǔ)上增加了視差置信度預(yù)測,這種處理使A 的6種誤差指標(biāo)均顯著低于C,其中MAE 和RMSE 分別降低了55.2%和33.0%,同時閾值精度顯著高于后者,A 具有更高的深度估計精度。由于消失點問題,重構(gòu)圖像的部分像素?zé)o法采樣重建,在pe 函數(shù)中缺少置信度對這些像素比較的抑制,會造成問題梯度回傳,使網(wǎng)絡(luò)在采樣圖像上搜索與目標(biāo)圖像近似的像素來降低重構(gòu)誤差,從而產(chǎn)生錯誤的視差預(yù)測,這可能是C 的圖像相似度高于A,但模型精度卻顯著低于A 的原因。D 在A 的基礎(chǔ)上,將DCB 預(yù)測的視差圖連接到相應(yīng)DB 模塊,除RMSE 顯著降低外,其他誤差指標(biāo)都有所升高(其中2 種顯著升高),閾值精度有所下降(其中1 種顯著下降),說明僅將視差圖連接到DB 對提高深度預(yù)測精度是無效的。對比E和A 可知,將視差置信度圖接入DB 模塊也未能提高模型精度。
F 在A 的基礎(chǔ)上,將網(wǎng)絡(luò)預(yù)測的多尺度視差及置信度圖上采樣到輸入圖像尺寸后進(jìn)行圖像重構(gòu)和損失計算,該處理使F 的5 種誤差平均值有所下降,2 種閾值精度和3 種圖像相似度指標(biāo)有所提高(其中IW-SSIM 顯著提高),說明上采樣處理對提高深度估計精度是有一定作用的。對比G 和A、D、F,同時采用連接視差圖和上采樣處理的結(jié)構(gòu)G,顯著降低了深度估計誤差、提高了閾值精度,G 對A 的MAE 和RMSE 分別降低了23.7%和27.5%。相對于在小尺度模糊圖像上的損失計算,更大尺度的圖像具有更高的清晰性,網(wǎng)絡(luò)回傳的誤差梯度質(zhì)量更高,基于更高質(zhì)量梯度訓(xùn)練的DCB 模塊能夠預(yù)測出更高質(zhì)量的多尺度視差圖,將更高質(zhì)量的視差圖輸入到解碼器中,可進(jìn)一步提高后續(xù)DCB 模塊的預(yù)測能力。D 的DCB 誤差梯度來源于小尺度模糊圖像,梯度質(zhì)量低,進(jìn)而產(chǎn)生低精度或錯誤的多尺度視差圖,將這種視差圖輸入編碼器,會干擾后續(xù)DCB 對視差的預(yù)測,這可能是D 相對于A,其深度估計精度下降的原因。H在G 的基礎(chǔ)上增加連接視差置信度圖處理,但性能未能進(jìn)一步提高,因此本研究以G 作為深度估計模型的最終結(jié)構(gòu)。
4.3 方法比較與分析
在近幾年出現(xiàn)的無監(jiān)督深度估計方法中,Monodepth2[14]和DepthGAN[35]是2 個可以通過輸入雙目圖像進(jìn)行訓(xùn)練和測試的典型代表,具有最高的深度估計精度。同時,為分析網(wǎng)絡(luò)寬度和深度對視差預(yù)測性能的影響,以G 為基礎(chǔ),在固定SKB 的前提下,引入G-I 和G-II,其中G-I 維持G 的超參數(shù)n 不變,減小DB 模塊的增長率為k=16,即降低G-I 中DB 模塊的輸出通道數(shù)(網(wǎng)絡(luò)寬度),G-II 則保持k 不變,減小DB 模塊的超參數(shù)為n=3(瓶頸DB 的n=6),即降低G-II 的網(wǎng)絡(luò)深度。對本研究網(wǎng)絡(luò)G、G-I、G-II 與Monodepth2、DepthGAN 在番茄植株圖像深度估計上的精度及計算速度進(jìn)行比較,并以Stereolabs ZED 2k 雙目相機(jī)軟件開發(fā)包(Software Development Kit,SDK)計算的深度數(shù)據(jù)作為基準(zhǔn)之一,結(jié)果如表4 所示。

表4 不同深度估計方法性能比較 Table 4 Performance comparison of different depth estimation methods
由表4 可知,就番茄植株圖像深度估計任務(wù)而言,開發(fā)包和DepthGAN 的精度較低。開發(fā)包具有較高的計算速度,但各項深度估計精度指標(biāo)均顯著低于本研究網(wǎng)絡(luò)。與DepthGAN 相比,除圖像相似度外,本研究網(wǎng)絡(luò)在其他指標(biāo)上都顯著優(yōu)于該方法。DepthGAN 是一種生成對抗模型,而生成對抗存在著梯度消失、難以收斂到納什均衡的問題,本研究模型的梯度主要來源于圖像人工特征和卷積特征的比較,梯度穩(wěn)定且無消失問題。與Monodepth2 相比,G 在5 種誤差指標(biāo)上顯著低于前者,其中Rel、MAE 和MRE 分別降低了46.0%、26.0%和25.5%,同時在閾值精度上也顯著高于前者,表明本研究模型具有更高的精度。Monodepth2 僅采用光度值和人工特征比較圖像相似度,且沒有采取任何措施來抑制消失點引入的問題梯度,其以最小化圖像重構(gòu)誤差為優(yōu)化目標(biāo),將產(chǎn)生高質(zhì)量的重構(gòu)圖像,但也會產(chǎn)生部分錯誤的視差預(yù)測,這是該方法圖像相似度指標(biāo)高于本研究方法,但其視差估計性能卻低于本研究網(wǎng)絡(luò)的原因。G 的圖像相似度指標(biāo)顯著高于G-I、G-II,其他各項精度指標(biāo)雖無顯著差異,但G 具有更低的誤差和更高的閾值精度平均值,表明增加網(wǎng)絡(luò)的寬度或深度可提高深度估計性能,這得益于更寬、更深的網(wǎng)絡(luò)可提取更多和更高層的圖像特征。G 和G-I、G-II 的比較也表明,通過調(diào)整超參數(shù)n、k,可對模型的精度和計算速度進(jìn)行平衡。與G 相比,G-I和G-II 的速度顯著提高,分別為13.9 和14.2 幀/s,同時在除RMSE 和圖像相似度之外的各項性能指標(biāo)上也優(yōu)于Monodepth2。鑒于G 具有更高的精度,采用其對番茄植株雙目圖像測試集中部分圖像的深度進(jìn)行預(yù)測,結(jié)果如圖4 和圖5 所示。
由圖4 可以看出,圖像對應(yīng)的視差(深度)圖能夠反映其三維結(jié)構(gòu),樣本1 的視差圖(圖4b)反映了株與株之間的間隔,樣本2 的視差圖表示出了2 株行間的行走通道,以及行內(nèi)目標(biāo)的遠(yuǎn)近。由視差置信度(圖 4c)對左目圖像的遮罩(圖4d)可以看出,模型對圖像左邊緣像素的視差預(yù)測的置信度偏低,這與由于視角原因,左目圖像的左邊緣像素在右目圖像以外,模型無法通過對應(yīng)像素匹配實現(xiàn)視差精確預(yù)測的實際情況相符。同時對于圖像模糊(圖4a 樣本1 左上方)區(qū)域,其視差置信度也偏低,因此,為提高模型預(yù)測精度,應(yīng)改善圖像采樣的清晰度。樣本1 遮罩結(jié)果表明,番茄果實區(qū)域具有較高的置信度,即該區(qū)域的視差精度較高,這為模型應(yīng)用于基于視覺定位的果實采摘或?qū)Π惺┧幍忍峁┝丝赡堋?/p>

圖4 番茄植株圖像視差及置信度預(yù)測 Fig.4 Disparity and confidence estimation for tomato plant images

圖5 番茄植株圖像深度估計示例 Fig.5 Examples of tomato plant image depth estimation
圖5 表明,模型預(yù)測出了多個視角下的行間行走通道,這說明模型用于溫室移動機(jī)器人作業(yè)導(dǎo)航是可行的。圖5a和圖5b 為在陰天、逆光條件下的成像,模型也較好的預(yù)測出了其對應(yīng)的三維空間結(jié)構(gòu)。圖5e 和圖5f 包含了紋理單一的溫室后保溫墻,從對應(yīng)視差圖可以看出,模型預(yù)測出了后保溫墻的平滑的深度變化,說明模型能夠克服傳統(tǒng)立體圖像匹配法無法對低紋理區(qū)域?qū)崿F(xiàn)有效匹配的問題。由圖5k 和圖5l 的視差圖可以看出,模型對纖細(xì)的番茄植株莖稈部分也給出了較好的預(yù)測,這為模型應(yīng)用于避障提供了可能。
為明確深度估計模型預(yù)測的各尺度視差圖的差異,進(jìn)一步對以G 為基礎(chǔ)的模型預(yù)測的各尺度視差圖的精度進(jìn)行分析,結(jié)果如表5 所示。
由表5 可知,隨著視差圖尺度的縮小,圖像相似度指標(biāo)逐漸縮小,深度估計誤差整體呈上升趨勢,最小尺度視差圖在Sq Rel、MAE、RMSE 和MRE 誤差上顯著高于其他尺度,其他2 種誤差則各尺度之間差異不顯著。總體來看,DCB1和DCB2預(yù)測的視差精度要高于DCB3和DCB4,DCB1和DCB2之間則無顯著差異,表明終端模塊對DCB1視差預(yù)測精度的提高沒有明顯貢獻(xiàn),CAE 結(jié)構(gòu)的優(yōu)化值得進(jìn)一步深入探討。

表5 多尺度視差圖精度比較 Table 5 Accuracy comparison between multi-scale disparity maps
4.4 空間點深度及光照條件對深度估計精度的影響
根據(jù)番茄植株雙目圖像測試集中已知視差值的稀疏點的深度值iZ ,分別提取出深度在0~3、0~6 和0~9 m的空間點,并根據(jù)模型G 估計的這些點的視差值,計算深度估計誤差及閾值精度,分析空間點深度對深度估計精度的影響,結(jié)果如表6 所示。

表6 空間點深度對深度估計精度的影響 Table 6 Effect of the spatial point depth on accuracy of depth estimation
由表6 可知,除Rel 和RMSElog無顯著差異外,其他誤差隨空間點深度的減小而顯著降低。這是因為,空間點深度越小,其視差值越大,根據(jù)式(1),相同的視差偏移對小深度空間點造成的深度誤差小于大深度空間點。同時,表6 表明,閾值精度不隨空間點深度的變化而顯著變化。在9 m 范圍內(nèi),模型估計深度的MAE為140.8 mm(<14.1 cm),在6 m 范圍內(nèi),MAE 為93.3 mm(<9.4 cm),在3 m 范圍內(nèi),MAE 降為66.0 mm(<7.0 cm)。
按番茄植株雙目圖像測試集樣本采樣時記錄的天氣狀況,將其分成陰天、多云和晴朗3 類,分析光照條件對深度估計精度的影響,結(jié)果如表7 所示。

表7 光照條件對深度估計精度的影響 Table 7 Influence of illumination conditions on accuracy of depth estimation
由表7 可知,就各項指標(biāo)平均值而言,多云條件下的深度估計精度要好于陰天和晴朗天氣,這和陰天弱光條件下采集的圖像對比度差,晴朗天氣強(qiáng)光條件下光暗對比過大,圖像部分區(qū)域曝光不充分,影響了模型對圖像特征的提取有關(guān),表明光照條件對深度估計性能具有一定影響。但除GSIM 外,其他各項指標(biāo)差異并不顯著,這也說明本研究模型對光環(huán)境變化具有一定的魯棒性。
5 結(jié) 論
提出一種基于稠密卷積自編碼器的無監(jiān)督植株圖像深度估計模型,該模型可通過雙目圖像進(jìn)行訓(xùn)練。以深度估計誤差、閾值精度及圖像相似度為判據(jù),在番茄植株雙目圖像上進(jìn)行訓(xùn)練和測試試驗,結(jié)果表明:
1)深度估計模型通過預(yù)測視差置信度,抑制問題梯度回傳,顯著提高了深度估計精度,其平均絕對誤差(Mean Absolute Error,MAE)和均方根誤差(Root Mean Squared Error,RMSE)分別降低了55.2%和33.0%。
2)同時將網(wǎng)絡(luò)預(yù)測的多尺度視差圖接入編碼器并將其上采樣到輸入圖像尺度后參與損失計算,估計深度的MAE 和RMSE 進(jìn)一步降低了23.7%和27.5%,該處理對提高深度估計精度是有效的。
3)深度估計誤差隨空間點深度的減小而顯著降低,當(dāng)空間點深度在9 m以內(nèi)時,估計深度的MAE < 14.1 cm,當(dāng)在3 m 以內(nèi)時,則MAE < 7 cm。
4)光照條件對深度估計模型精度的影響不顯著,本研究方法對光環(huán)境變化具有一定的魯棒性。
5)與已有研究相比,本研究方法的平均相對誤差、MAE 和平均距離誤差分別降低了46.0%、26.0%和25.5%,深度估計精度顯著提高。本研究可為溫室移動機(jī)器人視覺系統(tǒng)設(shè)計提供參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
藝術(shù)品鑒證.中國藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國藝術(shù)金融(2018年6期)2019-01-08 02:43:04
藝術(shù)品鑒證.中國藝術(shù)金融(2018年12期)2018-08-26 06:03:48
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
