基于網絡搜索信息的農村水環境質量灰色預測模型
2020-07-22 07:21:28鐘秋萍曲品品
中國管理科學 2020年6期
張 可,鐘秋萍,曲品品,殷 要,左 媛
(1.河海大學商學院,江蘇 南京 211100;2.河海大學項目管理研究所,江蘇 南京 211100)
1 引言
隨著農村社會經濟的迅速發展,農村水環境污染問題日益嚴重。2018年聯合國糧食及農業組織和國際水資源管理研究所聯合發布的《農業水污染全球評論》報告指出,農業生產排放的有機物、農業殘留等污染物已成為全球水污染的重要源頭。最新統計數據表明,我國農業源的化學需氧量和氨氮排放量,分別占總排放量的48%,31%。農村水環境質量關乎飲水安全和食品安全,直接影響周圍居民的健康,甚至可能威脅農村公共安全[1]。為此,《關于全面推行河長制的意見》將“綜合整治農村水環境,推進美麗鄉村建設”作為了加強水環境治理的重要內容。而水質預測是農村水環境污染防治工作的重點之一,準確的水質預測結果將顯著提升水環境污染防治的及時性和有效性。
水質預測模型一般可以劃分為機理性和非機理性兩大類。機理性模型主要通過研究污染物擴散遷移時的一般規律,以及內在機理進行水質預測。非機理性依據經濟社會驅動因素構建模型,主要包括人工神經網絡預測模型[2-3]、灰色系統預測模型[4]、數理統計預測模型[5]、模糊數學預測模型[6]以及與“3S”技術相結合的預測方法[7]。機理性模型構建過程復雜,適用于基礎資料和監測數據完整的水環境質量預測[8];非機理性模型不需要對水質變化的內在規律進行描述,更適用于信息不夠完備的水環境。其中灰色系統預測模型對水質監測數據信息量要求較少,符合農村地區缺乏水環境監測信息的現狀[9]。本文將農村水環境視為“部分信息已知、部分信息未知”的灰色系統,通過采集、提取與農村水環境相關的網絡搜索數據,深入挖掘系統間接信息,不斷“白化”系統機理,并構建多變量灰色離散模型預測水環境演化趨勢。最后,以廣西梧州界首斷面的水質監測數據為例進行實例分析,結果表明引入網絡搜索信息能夠顯著提高水質預測精度。
2 相關研究評述
國外關于農村水環境質量的預測研究多采用經濟社會驅動的非機理性模型。例如:Ali等[10]構建了巴基斯坦農村水環境污染的環境庫茲涅茲曲線模型,預測綠色革命背景下水環境變化趨勢。Alamdarlo[11]采用空間距離函數預測了印度經濟增長環境對農村水環境的影響。Udeigwe[12]研究了農業生產行為對于水環境的影響模型。
我國農村水環境監測數據相對缺乏,因此灰色系統是較為常用的水質預測方法之一,通常可以分為單純灰色預測模型和組合灰色預測模型兩類。單純灰色預測模型主要采用GM(1,1)模型實現水質指標的預測。例如:張可等[13]構建了環境政策作用下農村水環境的灰色預測模型。徐玉妃等[14]構建了水質單因子的灰色預測模型。Lee[15]的研究表明相對于傳統的數值預測方法,灰色系統模型能在水質數據貧乏的情況下擁有較高的預測精度。
隨著水質預測方法的不斷發展,出現與灰色系統理論相結合的組合預測方法。例如:Li Zhenbo等[16]、劉東君和鄒志紅[17]分別將灰色預測模型與神經網絡相結合構建水質預測模型。Luo Yi等[18]提出自適應灰色模型,并與神經網絡相結合構建太湖流域水質預測模型。劉秀麗和涂卓卓[19]結合熵權法、灰色關聯分析等方法研究2006-2014年間京津冀地區水環境安全趨勢。鐘文武等[20]將殘差修正GM(1,1)與Markov相結合構建水環境指標預測方法。此外,灰色系統模型還可以與模糊集合理論[21]、小波變換分析[22]、趨勢外推法[23]等其他理論方法結合,以提高水環境質量預測的準確性。
上述研究為水環境監測和保護提供了理論支撐,但由于農村區域水環境監測數據少,且缺乏直接表征因素作為輸入變量,已有算法多依據水質數據自身規律進行預測,預測精度受到限制。因此,迫切需要挖掘非直接相關數據補充模型信息。已有研究表明,引入網絡搜索信息能夠提高不同領域預測模型的及時性和精確性。例如:Polgreen等[24]和Ginsberg[25]最早使用網絡搜索信息預測流感。Fantazzini和Toktamysova[26]采用谷歌數據提高汽車銷售預測精度。Clark等[27]采用谷歌趨勢構建了游客預測模型。Papanagnou和Matthews-Amune[28]綜合互聯網信息構建了藥品需求的VARX模型。蔣翠清等[29]采用網絡文本軟信息建立P2P網絡借貸違約預測方法。王娜[30]采用百度搜索指數和媒體指數信息構建碳價預測的自回歸分布滯后模型。此外,網絡信息在金融市場[31]、房地產價格[32]、CPI[33]預測等領域均取得了較好的應用效果。
為此,本文嘗試將網絡搜索信息引入傳統灰色預測模型中,從大量非直接監測數據中提取、篩選農村水環境關聯因素,從而提高模型預測精度。首先分析網絡搜索信息與農村水環境質量的關系;其次,綜合專家咨詢建議和數據可獲取性構建網絡搜索關鍵詞清單,采集關鍵詞搜索數據,并利用主成分分析法提取主要特征,形成初始網絡搜索變量;然后,利用灰色關聯分析法識別強關聯的網絡搜索變量;最后,構建不同頻率數據的DGM(1,N)模型,建立基于網絡搜索信息的農村水環境灰色預測模型,并將預測結果與傳統灰色模型進行比較。
3 理論分析
農村水環境直接監測和表征數據較少,依據《水環境監測規范》(SL 219-2013)規定,國家重點水質站、國際河段、重要省際河流、污染嚴重河流等敏感水域每月采樣1次,全年不少于12次。國家一般水質站、河流水系監測斷面等全年采樣不少于6次。雖然我國已部分實現地表水水質自動監測和實時發布,但受監測成本、維護成本等方面的限制,水質自動監測網的覆蓋范圍主要包括重點河流干流、一級支流、重點湖泊和水庫等。就農村水環境而言,短期內難以全面實現水質自動化監測,大部分區域的水質監測信息仍然較為貧乏。因此,需要增加外部信息以提高水質預測的精度。
周圍居民對水環境質量的感知具有直觀性和準確性。宋國君等人以沿河居住的農民、漁民和城市居民為對象,通過問卷對淮河流域的水環境狀況進行了調查[34]。調查結果與監測數據相比,在河流層次上,兩者基本保持一致;在斷面層次上,多數斷面的調查結果與監測是一致的,部分斷面的調查水質優于監測。由此可以看出,居民對水環境質量的認知與監測數據總體上是一致的,具有直觀性。
互聯網用戶有關水環境的搜索記錄是對水環境質量直觀感受的體現,能夠間接反映水環境質量的變化。網絡的興起為獲取周圍居民對水環境質量的直觀感受提供了便利。若某地區的水環境質量狀態發生變化,會對居民日常用水造成一定影響。而居民網絡搜索行為源自水環境質量存在問題,并且因相關知識和信息的缺乏,往往需要借助他人的知識來解決自己的問題[35]。2014年4·10蘭州自來水苯超標事件發生期間,“水污染”這一關鍵詞在蘭州的百度搜索指數于4月10日至4月11日急劇攀升,如圖1所示。其中值得關注的是,在事件爆發前兩三天,“水污染”關鍵詞的搜索指數曾出現一次小波峰。由此可見,水環境相關關鍵詞搜索指數的變動能夠及時地反映出水環境質量的變化情況。
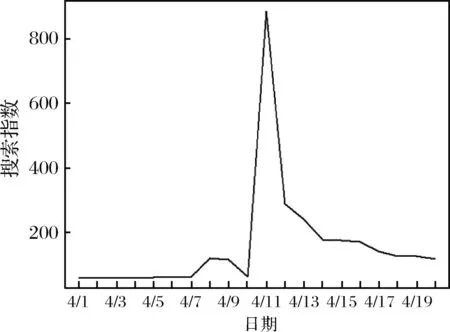
圖1 蘭州水污染事件中“水污染”關鍵詞百度搜索指數
網絡搜索信息產生于民眾自發的網絡搜索行為,能夠直接反映民眾的意圖,且具有實時性、規模性的特點。截止2018年12月,我國農村網民數量達到2.22億。隨著農村地區網民數量的增加以及網絡搜索信息的不斷累積,未來獲取到的搜索關鍵詞將會更加完善。在互聯網用戶針對水環境的檢索行為中,特定的檢索詞條是為了得到有關水環境的信息,如“有什么辦法可以減少河水污染”。與其他領域利用網絡搜索信息進行預測的方法相同,本文研究的關注點不在于對信息內容進行語義理解,而是找出相關關鍵詞的使用頻率與水環境質量之間的聯系,并形成網絡搜索關鍵詞組合,運用于特定的預測模型。
4 模型構建
為了提高農村水環境質量的預測準確度,本文在已有灰色預測模型的基礎上,引入網絡搜索信息,提出一種新的預測方法。該方法利用網絡搜索信息降低農村水環境系統的不確定性,這些網絡搜索信息經過采集、篩選、組合構成灰色模型的輸入變量。模型構建分為3個步驟:首先采集農村水環境質量相關的網絡搜索信息,構建初始網絡搜索變量;然后利用灰色絕對關聯度過濾出強關聯變量,和歷史水質監測數據一同作為模型輸入;最后建立不同頻率數據的多變量離散灰色模型,從而構建水環境質量預測方法。
4.1 初始網絡搜索變量構建
互聯網用戶常用的網絡信息源包括搜索引擎、門戶網站、論壇以及微博等社交軟件。其中搜索引擎是整合網絡信息資源的有效工具,逐漸成為互聯網用戶發現和搜尋知識的主要途徑。因此,本文以搜索引擎作為網絡搜索信息源,對涉及水環境關鍵詞的搜索信息進行采集,利用數據降維等處理方法將原始數據轉化為初始網絡搜索變量。
首先,以環境質量評價中常用的“壓力-狀態-相應”(Pressure-State-Response,PSR)模型為基礎,并增加水環境一般性詞匯,構建初始搜索關鍵詞清單;通過咨詢相關專家,以及考慮關鍵詞的可獲得性,選擇“化肥、農藥、畜禽養殖、廢水污染”等詞作為基準關鍵詞;其次,利用搜索引擎的熱詞推薦功能對詞條進行擴展。擴展后的搜索詞主要包含以下四個方面,如表1所示。

表1 關鍵詞清單
通常網絡搜索信息以天為單位,而農村水環境監測頻率為周或月。因此,網絡搜索信息的頻率高于或等于水質監測數據頻率。在預測模型構建時需要解決數據頻率不同問題。
假設研究地區的水環境質量指標n期監測數據記為X=(x(1),x(2),…,x(n))。網絡搜索信息的頻率是監測數據的N倍。在關鍵詞的初選階段共搜集到t項關鍵詞,則可以將t項關鍵詞記為KW1,KW2,…,KWt。針對每一個關鍵詞,收集n期的網絡搜索數據,可以將t個關鍵詞的n期網絡搜索數據表示為:
KW1=(kw1(1),kw1(2),…,kw1(n))
KW2=(kw2(1),kw2(2),…,kw2(n))
…
KWt=(kwt(1),kwt(2),…,kwt(n))
(1)
其中:
kwi(j)=(kwi(j,1),kwi(j,2),…,kwi(j,N))
kwi(j)表示第i個搜索詞與水環境監測數據第j期相對應的數據子序列。由于同一類問題的搜索詞之間可能存在較高的相關性,本文采用主成分分析法對水環境的網絡搜索數據進行降維,整合關聯度較高的關鍵詞,保證降維后的各個指標之間相互獨立。假設KW1,KW2,…,KWt為初始網絡搜索數據,采用主成分分析法提取的m個主成分U1,U2,…,Um為初始網絡搜索變量。
4.2 關鍵變量選擇
不同初始網絡搜索變量涵蓋的信息價值存在一定差異,因此需要運用科學的方法對初始網絡搜索變量進行篩選,選擇和農村水環境質量相關的關鍵變量,以提升預測模型效率及準確性。本文將采用灰色關聯分析法量化計算初始網絡搜索變量與農村水環境質量之間的關系密切程度,并過濾出強關聯的網絡搜索變量作為后序模型的輸入。
設水質監測數據為X=(x(1),x(2),…,x(n)),初始網絡搜索變量為:
Ui=(ui(1),ui(2),…,ui(n)),i=1,2,…,m
其中:
ui(j)=(ui(j,1),ui(j,2),…,ui(j,N))
兩者的始點零化像分別為:
X0=(x0(1),x0(2),…,x0(n))
其中:
X={x(k)+(t-k)(x(k+1)-x(k))|k=1,2,…,n-1;t∈[k,k+1]}
Ui={ui(k)+(t-k)(ui(k+1)-ui(k))|k=1,2,…,n-1;t∈[k,k+1]}
由于網絡搜索數據與實際監測數據頻率不同,且水環境各類搜索詞的峰值特征對水質預測更有意義。為此,在各時期內采用取最大值方式保留搜索詞信息并降頻至監測數據頻率。初始網絡搜索變量的降頻序列為:
(2)
網絡搜索變量的降頻序列與水質監測數據頻率一致,因此可以采用灰色關聯分析法過濾出強關聯的網絡搜索變量作為模型的輸入。由于水環境特征序列和各初始網絡搜索變量序列的意義、量綱差異較大,故考慮運用灰色絕對關聯度衡量初始網絡搜索變量與水質間的關聯程度[36]。
令
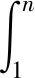
則稱
(3)
為初始網絡搜索變量與水質序列的灰色絕對關聯度。根據灰色絕對關聯度,ε0i的取值介于0和1之間,且僅與X和Vi折線的幾何形狀有關。即水環境監測數據折線與網絡搜索變量的折線在幾何形狀上越相似,兩者間的關聯程度就越強。因此,可以根據不同網絡搜索變量與水質序列的關聯度選取關鍵變量,將其引入預測模型。
4.3 預測模型建立
傳統的GM(1,1)水質預測模型利用少量水質監測數據,通過數據累加變換強化序列規律特征,實現水環境預測。但該方法屬于單因子自身預測,雖然能夠在一定程度上降低原始數據的不確定性,但難以通過增加水環境的白化信息,達到提高水環境質量預測精度的目的。
本文以多變量離散灰色模型為基礎,引入關鍵網絡搜索變量構建水環境預測模型。由于網絡搜索變量的數據頻率高于水質監測數據,為此需要構建不同頻率數據的多變量離散灰色模型。
設原始序列為X(0)=(x(0)(1),x(0)(2),…,x(0)(n)),第i個初始網絡搜索變量的原始序列為:
其中ui(j)=(ui(j,1),ui(j,2),…,ui(j,N))。經(3)式獲取關鍵網絡搜索變量記為:
則稱
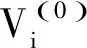
(4)
為基于網絡搜索信息的跨頻率DGM(1,N)預測模型。其中β1,β2,…,βN+1為模型的參數,可以采用文獻[36-37]的方法進行參數估計。
不同頻率數據DGM(1,N)不僅具有傳統灰色模型的特點,而且能夠有效引入高頻率網絡信息白化系統,建立大量間接數據與少量實測數據混合建模的橋梁。在確定關鍵網絡搜索變量后,可以構建跨頻率DGM(1,N)模型對農村水環境質量展開灰色預測。在建模過程中,將與農村水環境質量相關的若干網絡搜索變量作為驅動項,而將所有未知因素視為灰作用量,通過驅動項和灰作用量共同建立差分方程預測水質的發展趨勢,能夠有效彌補傳統單因素預測的不足。
5 實例分析
廣西壯族自治區(以下簡稱廣西)處于中國華南地區,氣候溫暖而濕潤,河流眾多,是我國糧食和甘蔗的重要產區。隨著廣西農業生產的迅速發展,當地水資源受到污染,對農業發展可持續化造成了阻礙。根據《2017年廣西壯族自治區環境統計年報》的調查數據,農業源化學需氧量、氨氮排放量均超過工業源的排放量,農業源成為影響水環境的第二大污染源。
考慮到一般的農村水環境質量監測數據較難獲取,本研究以廣西梧州界首斷面監測數據為對象進行實例分析。該斷面位于桂-粵省界,是珠江流域的重點水質監測斷面。采集該斷面2014年1月5日至4月20日期間15周的化學需氧量COD數據,數據采集頻率為周。具體如圖2所示。同時,將前12期的數據作為訓練集,后3期的數據作為預測集。
圖2 廣西梧州界首斷面COD監測數據
(1)構建初始網絡搜索變量。本文構建的初始關鍵詞清單共包含161個網絡搜索詞。以百度搜索引擎為網絡搜索信息源,通過其產品百度指數采集用戶的關鍵詞搜索概況,數據頻率為日。其中部分關鍵詞的獲取需要另付較高的查詢費用,因此僅以可直接獲取的關鍵詞為數據源,共收集73組關鍵詞的搜索數據。由于研究的時間跨度不長,在收集的73組數據中,部分搜索詞出現的頻率過低。考慮到計算復雜度以及低頻搜索詞對研究貢獻較小,在詢問專家的建議后,按百度指數提供的檢索頻次篩選關鍵詞,最終將27個關鍵詞納入搜索變量的構建步驟。
通過主成分分析法進一步對關鍵詞進行降維,共計提取9個主成分U1-U9。這9個主成分的方差貢獻率逐漸遞減,攜帶原始信息的累積方差貢獻率為96.721%。從因子得分系數矩陣來看,U1,U4,U8中“環境保護”、“污水處理”、“生態農業”等關鍵詞的系數較大,主要反映的是居民對水環境保護信息的搜索情況。U2,U3,U7中“養殖”、“磷”、“鉀”等關鍵詞的系數較大,主要反映的是居民對農村水環境影響因素及成因的搜索情況。U5,U6,U9中“化糞池”、“汞中毒”、“水俁病”等關鍵詞的系數較大,主要反映的是居民對水污染危害的搜索情況。
(2)選擇關鍵網絡搜索變量。根據式(2)、(3)計算U1-U9與COD實際值的灰色絕對關聯度,取關聯度閾值為0.7。當關聯度大于等于0.7時,認為該主成分與COD實際值之間強關聯。從多次試驗過程來看,當網絡搜索變量與COD實際值的整體關聯度都較低時,不應輕易降低關聯度閾值,而應重新構建網絡搜索變量,以避免輸入關聯度較低的網絡搜索變量影響模型的準確性和穩定性。
本次研究最終確定五個主成分U2、U3、U5、U8、U9,記為V1、V2、V3、V4、V5,作為關鍵網絡搜索變量輸入灰色模型。主成分分析與灰色絕對關聯度的計算結果如表2所示。
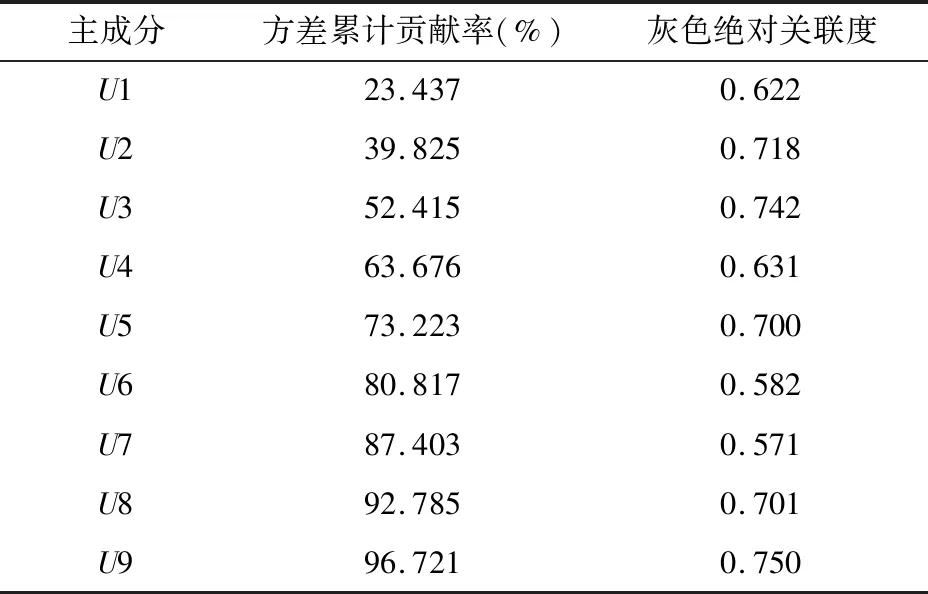
表2 主成分分析與灰色絕對關聯度結果
(3)建立預測模型。利用DGM(1,N)模型對水環境質量進行擬合和預測。為避免數據偶然性影響水質預測結果,采用五個網絡搜索變量逐步進入模型的方式,一共得到31種不同變量組合的模型,分別計算對應的預測值。同時,運用GM(1,1)模型對水質進行預測作為對比,以平均絕對誤差(MAE)、均方誤差(MSE)、平均絕對百分比誤差(MAPE)這3種常見的誤差指標評價模型預測精度。
(4)模型精度對比。預測效果前五的模型如表3所示,其中V1,V2,V3,V4變量組合的灰色模型預測效果最佳。針對擬合結果,31種DGM(1,N)模型的平均MAE、MSE、MAPE值分別為0.301,0.116,0.202。針對預測結果,31種DGM(1,N)模型的平均MAE、MSE、MAPE值分別為0.744,0.440,0.298。無論是擬合還是預測結果,DGM(1,N)模型各項誤差指標的平均值皆小于傳統GM(1,1)模型。由此可見,從整體上來說,DGM(1,N)模型的預測結果更準確。然而,仍有部分變量組合模型的預測精度低于傳統的灰色模型,最大預測誤差MAE值達到0.993。這是因為網絡搜素變量由分散的信息碎片組合而成,其作用機制具有復雜性和不確定性。因此在實際利用網絡搜索變量進行水質預測之前,應盡量對各種組合模型的預測效果進行測試,以便篩選出最優模型。
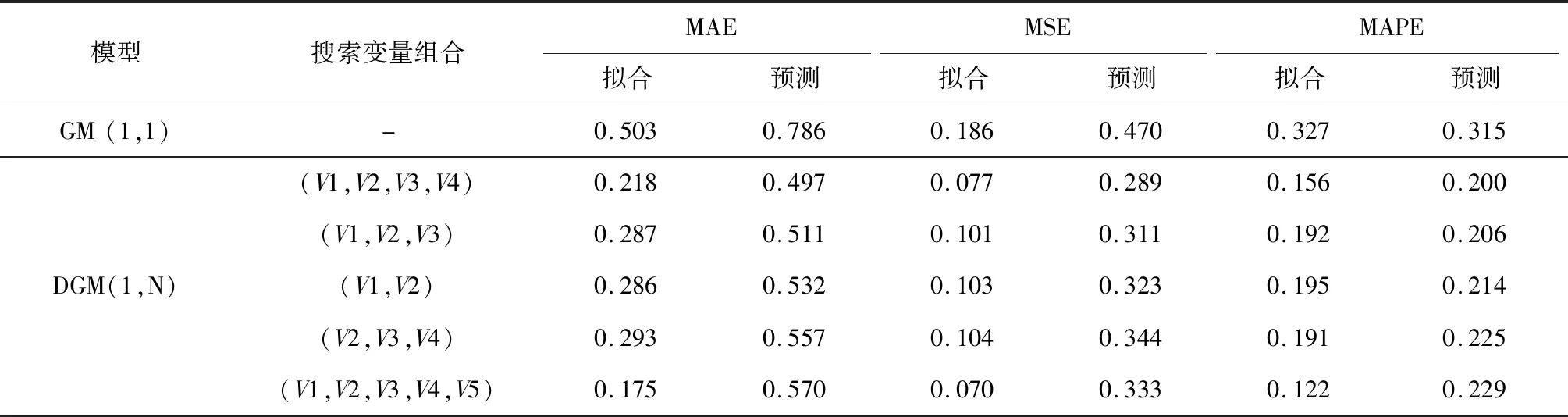
表3 Top5模型預測效果
另外,通過觀察預測效果前三的模型可以發現,隨著輸入網絡搜索變量數目的增加,模型的預測效果變好。遺憾的是在加入全部變量后,模型的預測效果反而下降,說明本文在構建網絡搜索變量的過程中還存在數據搜集不全面、特征提取不精確等問題,進而影響了模型預測效果。
取網絡搜索變量組合V1,V2,V3,V4組建模型,得到的水質預測序列為:
{1.600,3.022,1.529,1.892,1.350,1.095,2.058,1.465,1.590,1.220,0.960,2.671,2.061,1.818,2.129}。通過繪制預測序列折線圖,進一步觀察模型預測效果,如圖3所示。相對于GM(1,1)模型,V1,V2,V3,V4變量組合的灰色模型不僅擁有較高的預測精度,對COD數據的波動也能夠有效地貼合,較好地擬合了水質監測數據的波動趨勢。可見,加入網絡搜索變量能夠顯著提高水質預測的效果。
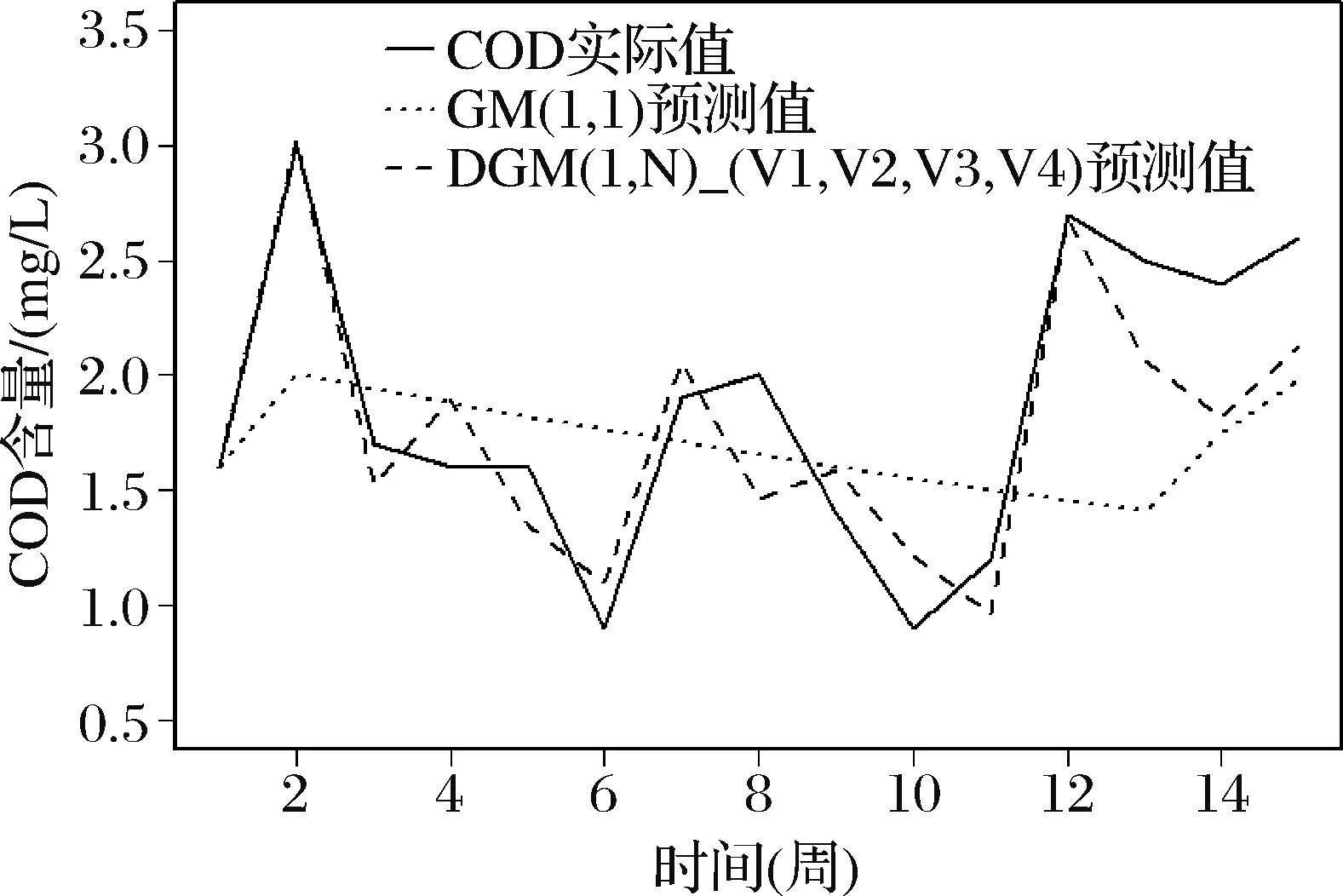
圖3 COD數據的實際值與DGM(1,N)_(V1,V2,V3,V4)模型預測值
6 結語
本文在分析網絡搜索信息與農村水環境質量相關關系的基礎上,利用網絡搜索信息降低農村水環境的不確定性,提出以網絡搜索變量作為驅動因素的灰色預測方法。通過模型構建以及實例分析主要得到以下幾點結論:
(1)網絡搜索信息與水環境質量之間存在相關關系。網絡搜索信息是居民對水環境質量直觀感受的體現,能夠在一定程度上反映農村水環境的變化情況。隨著農村互聯網的普及,網絡搜索信息能更加真實、準確地反映水環境的質量狀況,未來搜索數據量的差異還可以體現農村水環境質量的變化程度,有利于迅速、有效地確定農村水環境污染的整治方案。
(2)實例分析結果表明:加入網絡搜索信息可以顯著改善水質灰色預測模型的準確度。對比傳統灰色預測模型,本文提出的跨頻率DGM(1,N)模型不僅能夠提高預測精度,還可以有效地擬合水質的波動特征。同時,在一定程度上,隨著網絡搜索變量數目的增加,模型的預測效果更佳。
(3)網絡搜索變量的組合方式顯著影響模型的預測精度。研究發現,網絡搜索變量的作用機制具有復雜性和不確定性,不同變量組合模型之間的預測結果差異明顯。因此,在實際運用過程中,可以通過對變量組合方式的比較、篩選,確定最優的水質灰色預測模型。
本文的研究還存在一些不足之處,一方面初始關鍵詞搜索清單難以覆蓋所有用戶,需要不斷地對搜索關鍵詞進行補充和完善;另一方面網絡搜索變量的作用機制復雜,構建模型時還存在一定風險。后續的研究可以對網絡搜索變量進行優化和控制,以降低模型的預測風險,更好地為農村水環境污染的防治工作提供決策支持。
猜你喜歡
環境(2023年5期)2023-06-30 01:20:01
今日農業(2022年1期)2022-11-16 21:20:05
今日農業(2021年21期)2022-01-12 06:32:04
當代水產(2019年1期)2019-05-16 02:42:04
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
中國記者(2014年2期)2014-03-01 01:38:08
河南科技(2014年23期)2014-02-27 14:19:07
河南科技(2014年18期)2014-02-27 14:14:54
中國火炬(2011年5期)2011-07-25 10:27:55
