基于文檔關系改進的向量空間模型
2020-07-23 04:47:16何丹丹吳樹芳徐建民
河北大學學報(自然科學版) 2020年3期
何丹丹,吳樹芳,徐建民
(1.河北大學 網絡空間安全與計算機學院,河北 保定 071002;2.河北大學 管理學院,河北 保定 071002)
向量空間模型是一種經典的信息檢索模型,目前對該模型的改進主要是查詢擴展.查詢擴展[1]的基本思想是利用與查詢術語相關的詞語對用戶原始查詢進行擴展,現有研究方法主要包括基于詞典的方法[2]、基于反饋的方法[3-5]和基于語義的方法[6]等.基于詞典的方法通常用同義詞典作為擴展源,給出與原始查詢詞相關的擴展詞,如文獻[2]利用語義詞典與詞向量相結合的方法進行查詢擴展.基于反饋的方法是從用戶認為相關的文檔或者前n篇文檔中選擇與查詢詞相關的詞語,從而實現對查詢詞的擴展.如文獻[5]將抽取的維基百科文章作為反饋文檔,提出了基于偽相關反饋的監督查詢擴展方法和無監督查詢擴展方法.基于語義的方法是指最大程度上保留原始查詢詞的語義信息,選擇與查詢詞語義相近的擴展詞.如文獻[6]以查詢詞作為根節點,與其有語義關系的詞作為子節點,構建概念語義空間,實現擴展研究.這些方法都是基于查詢端來研究的,且均取得了一定效果,此外還可以從文檔端的角度展開研究.
合理利用文檔關系可以提高模型的檢索性能[7].Balinski等[8]充分利用了文檔間的距離關系,并根據這些距離修改文檔的初始相關性權重,實現檢索結果重新排序.Plansangke等[9]根據文檔與查詢詞之間的相關性,并利用文檔關系,對文檔進行分類,然后重新對文檔進行排序.Acid等[10]在簡單貝葉斯網絡檢索模型中合理利用文檔關系,實現對模型的擴展研究,提高了查詢效果.徐建民等[7]通過在基本的信念網絡檢索模型中增加一層文檔節點,利用文檔間存在的相似關系對基本模型進行擴展研究,使得檢索效果有所提高,進而得到更加合理的相關文檔排序結果.然而目前利用文檔關系對傳統向量空間模型進行改進尚未研究.
基于此,本文提出一種基于文檔關系改進的向量空間模型,該模型將初始檢索結果中排名靠前的高相關文檔組成基準集,通過計算初始檢索結果集中每篇文檔與基準集的相似度,來修正文檔與查詢的相似度,作為最終的相似度,實現對向量空間模型的改進,并通過實驗驗證了方法的有效性.
1 文檔關系的度量
文檔之間的關系主要包括相關關系和相似關系,分別可以通過相關度和相似度來衡量.相關度一般是指語義相關度,即2個概念間的相關程度[11],其主要采用基于本體結構的語義相關度方法來度量;相似度是指2個或多個文檔中出現的詞語、句子、段落或者篇章的吻合程度,2篇文檔在詞語、句子、段落或者篇章上相似部分越多,代表這2篇文檔的相似度越高[12].相似度是相關度的一種特殊情況,相似度越高,則相關度越大,但是相關度越大并不能說明相似度越高[11].
本文以相似度為例度量文檔間關系.文檔相似度的研究既可以從文檔內容的角度,也可以從文檔間結構的角度來進行,其中,基于文檔內容的研究方法主要有向量空間模型的方法和集合運算模型的方法;基于文檔間結構的方法主要有基于文檔結構的方法和基于引文圖的方法.這幾種方法中應用較為普遍的是向量空間模型方法,故本文采用該方法來計算文檔間的相似度,實現對文檔關系的度量.為了方便表述本文的改進細節,下面對向量空間模型方法作一些簡單介紹.
在向量空間模型(VSM,vector space model)中,假設文檔集D中包含M個特征項,分別用k1,k2,…,kM表示,di=(wi1,wi2,…,wiM)表示文檔集中的第i篇文檔,wit表示特征項kt在文檔di中的權重,計算方法如公式(1)所示.
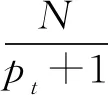
(1)
其中,tfit表示在文檔di中特征項kt出現的頻率,idft表示逆文檔頻率,N表示系統中所有文檔的數量,pt表示存在特征項kt的文檔數.
用戶的查詢q表示為q=(wq1,wq2,…,wqM),wqt為特征項kt在查詢q中的權重.查詢q和文檔di的相似度用文檔向量和查詢向量的夾角余弦值來衡量,如公式(2)所示.
(2)
2 基于文檔關系改進的向量空間模型
2.1 基本過程
本文提出的基于文檔關系改進的向量空間模型的基本過程主要包括3個階段,由圖1所示.
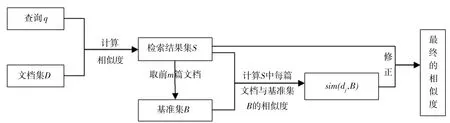
圖1 基于文檔關系改進的向量空間模型的基本過程Fig.1 Basic process of vector space model improved based on document relationship
1) 利用查詢術語實現查詢,并將文檔集的查詢結果進行降序排列,取前n篇文檔作為初始檢索結果集S={d1,d2,…,dn}.
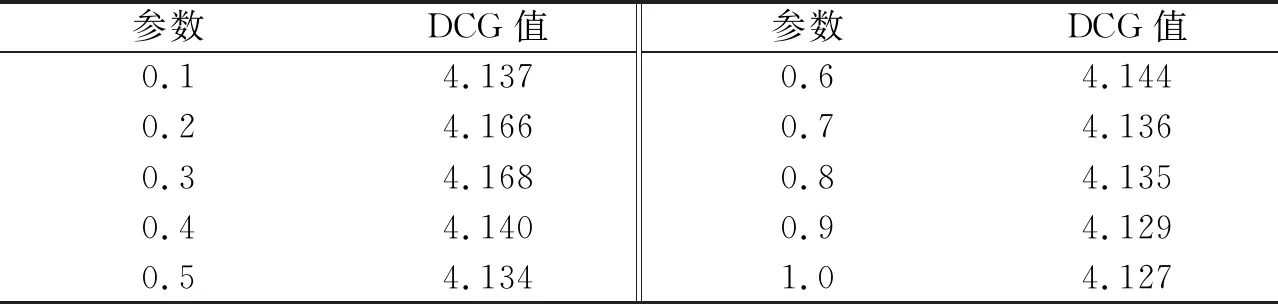
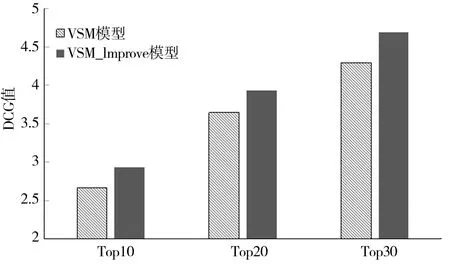
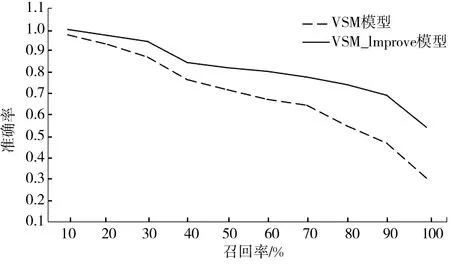
2)從初始檢索結果集S中選取前m篇文檔組成相關文檔的基準集B={d1,d2,…,dm},其中m取排名靠前的高相關文檔數(m 3)通過計算集合S中每篇文檔dj與基準集B的相似度sim(dj,B),用來修正原模型中文檔dj與查詢q的相似度,得到最終的相似度,從而實現對檢索結果的重排序,得到改進的向量空間模型.如果某篇文檔與查詢的相似度不高,但是與基準集的相似度高,則該文檔與查詢可能也是相關的,因此利用文檔與基準集的相似度來修正文檔與查詢的相似度,這樣可以使在前n篇之外的相關文檔排名靠前.同樣,基準集中的每篇文檔也用文檔與基準集的相似度來修正文檔與查詢的相似度,如果某篇文檔與查詢的相似度高,但是與基準集的相似度低,則該文檔與查詢可能不相關,利用該方法進行計算可以使得在前n篇文檔中相關度低的文檔排名靠后. 上述3個階段中,最關鍵的一步為第3步,當計算文檔與基準集的相似度時,如果直接利用文檔與基準集中每篇文檔的相似度來計算,存在一定的不足:基準集中每篇文檔與查詢的相關程度是不同的,故其權重理應是不同的.為解決該問題,將基準集中每篇文檔與查詢的初始相似度作為該文檔權重,結合權重來計算文檔與基準集的相似度,并給出了具體的計算方法,如公式(3)所示. (3) 其中,文檔di∈B;sim(dj,di)表示文檔dj與文檔di的相似度,sim(di,q)表示文檔di與查詢q的相似度,均采用向量空間模型方法來計算. 本文首先利用公式(3)度量出文檔間關系,然后在傳統的向量空間模型的基礎上融入文檔關系,實現對模型的改進. 檢索結果的前m篇文檔一般可以更好地表達用戶的查詢意圖,故利用集合S中的文檔dj與基準集B的相似度,來修正文檔dj與查詢q的相似度,實現對VSM模型的改進,如公式(4)所示,把這種檢索方法稱之為VSM_Improve模型. sim_improve(dj,q)=αsim(dj,q)+(1-α)sim(dj,B), (4) 其中,α為調和參數,sim(dj,q)為文檔dj與查詢q的相似度,sim_improve(dj,q)為文檔dj與查詢q改進后的相似度. 在信息檢索評測領域,目前沒有構建標準的中文信息檢索測試集[15].文獻[15]建立的中文信息檢索數據集,適合一般的小型實驗測試,并且在一些實驗中多次使用,因此本文采用該數據集進行實驗驗證.該數據集中共有1 578篇中文文檔,文本內容主要是與計算機相關的一些領域,其中主要包括5個查詢主題,每個查詢主題有各自的相關文檔集.專家已經對相關文檔集進行了相關性評分,評分取值為{0,0.1,0.2,…,1},評分的值越大文檔越相關,其中,1表示完全相關,0表示毫不相關. 論文采用信息檢索中常用的2種評價指標來檢測改進模型的有效性,分別是折損累計增益(discounted cumulative gain,DCG)和準確率-召回率曲線. DCG值[16]既考慮檢索結果中文檔的相關性,也考慮文檔在檢索結果中出現的位置,它是依據相關文檔在檢索結果中排序的位置來給出該文檔的分數,DCG值越大則說明排序結果越合理.假設相關文檔排序靠前,則其價值較高,否則價值較低,相應地做出貢獻則較少.DCG值計算方法如公式(5)所示. (5) 其中,|k|表示檢索結果按照相關性從大到小依次排列,取前k個結果組成的集合.Si表示結果列表前k個文檔集合中第i個文檔的相關性得分,它的取值為0~1.Si=0表示第i個文檔與查詢毫無關系,Si=1表示第i個文檔與查詢完全相關. 準確率-召回率曲線用來說明檢索結果中的相關文檔是否準確和全面[17].準確率(Precision)和召回率(Recall)的計算公式分別如公式(6)和公式(7)所示. (6) (7) 其中,|A|表示該系統中檢索到的所有文檔的數目,|B|表示該系統中與查詢有關的所有相關文檔數目,|R|表示該系統中檢索到的相關文檔數目. 3.3.1 相關參數的確定 1)相關文檔的數量m值的確定 基準集B中相關文檔的數量m的確定非常關鍵,如果選取的相關文檔太少,則文檔之間的關系無法充分發揮作用,便會遺漏掉一些相關信息;如果選取的相關文檔太多,不相關文檔的數量也會增多,則會引入大量噪聲.為了探討合適的基準集B,進行了參數訓練,分別計算出當相關文檔m的取值為5、10、15、20時,查詢在數據集中的平均DCG值,如表1所示. 表1 m不同取值下查詢的平均DCG值 從表1可以看出,當m=5時,查詢的平均DCG值較高.通過觀察初始查詢結果可以發現,查詢的前5篇文檔大部分是相關的,而隨著文檔數量的增多,會出現相關度不高的文檔以及不相關文檔,進而會引入噪聲.故對于本測試集來說,將相關文檔m的數量設定為5較好. 2)參數α的確定 為合理地將文檔與查詢的相似度、文檔與基準集的相似度進行融合,實驗對參數α的取值進行訓練.在α分別取0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9、1.0時,分別計算查詢在數據集中的平均DCG值,實驗結果如表2所示. 表2 參數α的不同取值下查詢的平均DCG值 從表2可以看出,當參數α=0.3時,查詢的平均DCG值達到較高值.由于基準集中包含了與查詢相關的術語,所以如果參數α取值較大,則在檢索結果中無法合理體現文檔關系的用途;而如果參數α取值較小,則用戶的初始查詢意圖無法很好地起到相應的作用.故本文將參數α的值設定為0.3. 3.3.2 實驗性能比較及分析 為驗證VSM_Improve模型的有效性和準確性,通過構建10個查詢,即在每個查詢主題下分別構建2個查詢,然后分別將VSM模型和VSM_Improve模型的檢索結果降序排列,并用DCG值、準確率-召回率曲線對這2個模型進行性能評價. 1)DCG值的比較 對于構建的10個查詢,分別在VSM模型和VSM_Improve模型中計算每篇文檔與查詢的匹配程度.由于用戶在查看搜索引擎結果時,用戶只關注前20~30個查詢結果[4],如果用戶在這其中未找到所需要的內容,用戶將會重新構造查詢.因此分別計算出這3種模型檢索結果的TOP-10、TOP-20、TOP-30的平均DCG值.圖2為10個查詢結果的TOP-10、TOP-20、TOP-30下的平均DCG對比圖. 從圖2可以看出, VSM_Improve模型的平均DCG值在TOP-10、TOP-20、 TOP-30下均高于VSM模型.產生這種結果的原因是:一般情況下,符合查詢需求的文檔排序比較靠前,換言之,查詢結果的前幾篇文檔更能充分表達用戶的查詢意圖;利用文檔關系,找出與基準集相似度高的文檔,這些文檔更能體現用戶的查詢需求,與簡短的查詢詞相比,會使得查詢結果更加準確和全面.故文中用文檔與基準集的相似度來修正文檔與查詢的相似度,得到文檔的最終相似度,實現對檢索結果的重排序.若某篇文檔與基準集相似并且與查詢匹配程度也較高時,則該文檔的排名會靠前,反之若與其中一個相似度較低時,文檔的排名則會靠后,因此VSM_Improve模型會提高相關文檔的排名,同時會剔除不相關的文檔. 圖2 2種模型的查詢結果在Top-10、Top-20、Top-30的DCG對比Fig.2 DCG comparison of query results of two models in Top-10、Top-20、Top-30 2)準確率和召回率的比較 這部分實驗分別計算了基本模型和改進模型在10個查詢下,當召回率的值為10%、20%、30%、40%、50%、60%、70%、80%、90%和100%時,其相應的準確率,最后計算出這10個查詢的平均準確率,并繪制出準確率-召回率曲線,如圖3所示. 圖3 準確率-召回率曲線Fig.3 Curve of precision-recall 由圖3可以發現,在召回率相同的情況下, VSM_Improve模型的準確率高于VSM模型.在召回率為10%、20%、30%、40%時,雖然VSM_Improve模型的準確率高于VSM模型,但是2個模型的準確率相差不大,因此可以看出,檢索模型的前幾篇文檔一般情況下是滿足用戶查詢需求的.通過模型的改進之后,會剔除一些排在前面的不相關文檔,并且提高相關文檔的檢索概率.產生這種結果的原因是:在實際信息檢索過程中,用戶輸入的查詢詞一般比較簡短且模糊,不能準確表達自身的信息需求,因此會導致查詢的準確率和召回率不理想.由于與查詢相關的文檔間會有一定的相似性,這些相關文檔在一定程度上可以很好地表達用戶的查詢意圖,故本文利用文檔間關系,通過找出與相關文檔集相似度較高的文檔,可以使得查詢結果更加全面和準確. 考慮到用戶輸入的查詢詞一般較少,對信息需求的表達往往不夠準確和全面,導致查詢結果不理想的問題,本文提出一種改進的向量空間模型,利用文檔間關系,找出與基準集中的篇文檔均相似的文檔,進而找出查詢的相關文檔,并將每篇文檔與基準集的相似度、每篇文檔與查詢的相似度進行融合,進而提高了檢索效果,使得檢索結果更加合理.接下來將嘗試分析文檔間的其他關系,并在信息檢索模型中進行實現.2.2 改進的向量空間模型
3 實驗
3.1 實驗數據集
3.2 評價標準
3.3 實驗結果及分析

4 結束語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
