電商時代線上商家的用戶評價挖掘模型研究
2020-08-04 05:02:42
商展經濟 2020年4期
中央民族大學信息工程學院 伍逸興
中央民族大學經濟學院 李秦青
近年來,互聯網的快速發展,網絡已成為人們生活中重要的信息來源,也是人們表達個人意向的重要途徑。人們在購買商品前,都習慣在網上查看他人對同一產品的評價;另外,人們也越來越喜歡在網上分享他們對使用過的產品的看法。同時,作為電子商務的重要載體,互聯網上的內容對商家也存在導向作用。通過對網絡上顧客反饋的挖掘,商家可以及時了解市場行情,完善商品的質量和營銷手段。
進軍一個新市場是有風險的,但如果事先做了周密的調查就沒有相關風險。如今,產品評論對于在線銷售至關重要,因為它們反映了產品的市場接受度,而這是銷售策略的核心。眾所周知,世界上最大的網購平臺亞馬遜提供了三種評論:以星級的形式進行評價(star ratings),用戶的文字評論,以及用戶和非用戶對原始評論的意見,稱為“幫助度”(helpfulness rating)。
本研究以吹風機、微波爐、嬰兒奶嘴為例。公司已經準備了客戶評論的數據集,這些數據集不僅包含上述類型,而且還指明了時間段。在整個分析過程中,本研究不會使用除它們之外的任何數據。
簡而言之,研究的工作包括以下幾方面。
任務(1)描述性地分析數據并勾勒出粗略的市場圖景。任務(2)向公司營銷總監展示如何衡量這些數據,并獲得其想要的結果。這包括數學建模和數據處理的步驟。任務(3)確定衡量在線評論的關鍵因素。隨著時間的推移,發現銷售趨勢,并確定哪種產品是真正“成功”或“失敗”的。任務(4)揭示原始評論和二級評級(幫助性評級)之間的關系。任務(5)將以上步驟組織成建議。
1 模型描述
1.1 假設
由于缺乏必要的數據和知識有限,通過以下假設來幫助我們建模和分析。這些假設將是之后分析的先決條件。
(1)明星評論和客戶評論同等重要,重要性權重不會隨著時間而改變。(2) 顧客對三種產品的評價模式是相似的。(3)數據真實準確。
1.2 數據處理
我們刪除了包含缺失值和異常值的行。經過簡短的選擇,我們發現三個數據集中有缺失值和離群值的行。例如,星級理論上從1星~5星,但一些產品被評為0星、10星,甚至144星。對于vine和verified purchase的標簽,應該是yes或no。因此,我們刪除了兩者都不包含的行。與此同時,有些線條還不完整。這些行總數很小,這不會對刪除后的總體數據輸出產生負面影響。最后,我們得到一個過濾后的數據記錄可以分析。
1.3 簡要分析
在對數據進行預處理后,我們有意地從三個元素進行分析,如圖1所示。
從圖1可知,vine上的會員只占審稿人總數的一小部分(低于2%),這意味著高可信度的客戶很少,所以我們必須仔細推測星級評分和評論之間的關系。
我們根據不同評級的人數制定三個獨立的星級評級直方圖。
我們還考察了驗證采購在總采購中的比例。深藍色扇區表示“N”,淺藍色表示“Y”。可以看出,吹風機和嬰兒奶嘴產品在質量和服務上都是值得信賴的,通過認證購買的產品占總交易量的86%,而微波爐的性能則值得懷疑,因為未經認證購買的產品占總交易量的30%以上。
2 顧客滿意度模型
為了幫助公司更好地了解市場,我們將客戶評價量化,并結合星級評分提出客戶滿意度模型:
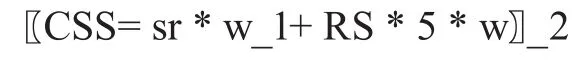
總分從0~10。分數越高,客戶滿意度越高。
建立該模型是為了計算客戶滿意度得分,使公司能夠實時跟蹤市場情緒。
在長短期記憶神經網絡(LSTM)中,每個細胞都持有已記憶的值。當我們更新當前單元格的輸出時,還需要決定在當前單元格中可以記錄什么。長短期記憶神經網絡于1997年正式提出,包括遺忘門、輸入門、輸出門這三個結構,如圖2所示。
遺忘門決定哪些信息應該被丟棄或保留。之前隱藏狀態的信息和當前輸入的信息同時加載到Sigmoid函數中。輸出值在0和1之間變化。1表示“完全保留”,而0表示“完全刪除”。因此,這個函數可以決定哪些信息應該刪除。
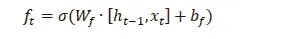
輸入門用于更新單元狀態。之前的門已經決定了要做什么,我們只需要實際去做。首先,將之前隱藏的狀態信息和當前的輸入信息輸入到Sigmoid函數中,并將輸出值調整為0~1,以決定更新哪些信息。0表示不重要,1表示重要。另一種可能的解決方法是通過函數將隱藏狀態和電腦輸入放入,壓縮到-1~1來調整網絡,然后乘以s型門的輸出。Sigmoid函數將決定輸出中哪些信息是重要的,哪些信息需要保留。
控制Ct輸出的門稱為輸出門。一個輸出門決定下一個隱藏狀態的值,它包含關于前一個輸入的信息。隱藏狀態也可以用于預測。首先,將先前的隱藏狀態和當前輸入到Sigmoid函數中;其次,將新得到的單位態代入Tanh函數;再次,將Tanh輸出與Sigmoid輸出相乘,確定隱藏狀態應該攜帶的信息;最后,將隱藏狀態作為當前單元輸出,并將新的單元狀態和新的隱藏狀態傳輸到下一個時間。
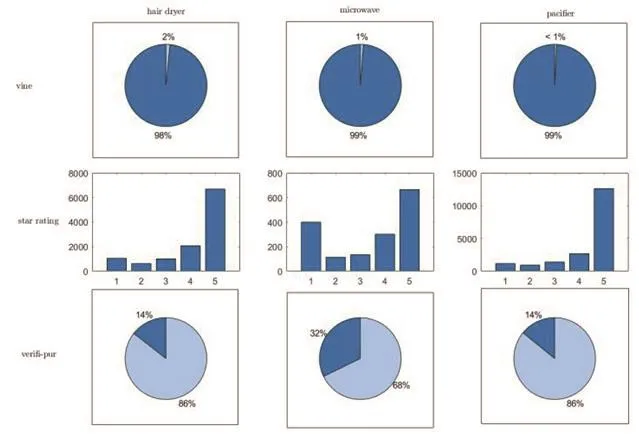
圖1 數據分析
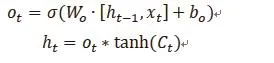
3 結果分析
由于星級評分已經是可以直接分析的數據,因此,我們需要將用戶的文本進行數據化。同樣采用長短期記憶神經網絡來為顧客的評論打分,LSTM單元數至64個,分類類別至2個,并使用24500個帶有情感標簽(0和1)的評論文本作為模型培訓的培訓材料。
在模型訓練過程中,我們對不同訓練次數下生成的模型進行準確性和反向傳播損耗的評估,如表1所示。
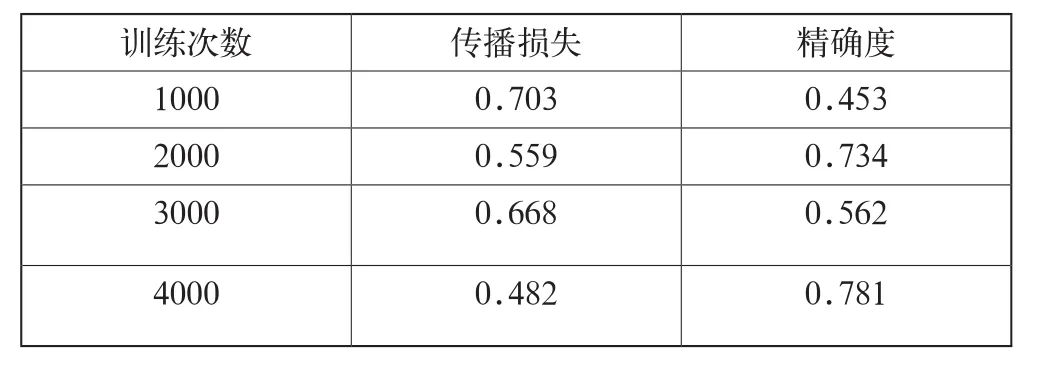
表1 準確度評估結果
對模型進行設置后,以嬰兒奶嘴產品的評論主體作為模型輸入,得到輸出,即每次評論顯示積極情緒的可能性。
然后基于顧客滿意度模型,將評價分數代入函數中,將結果(顧客滿意度分數)分為高[6,10]、平均[3,6]、低[0-3]三個層次。在確定人數后將結果可視化。
4 結語
優點:(1)在從評論中提取特征詞時,首先對詞的詞性進行篩選,分別提取名詞、動詞、形容詞,然后計算這些詞出現的頻率,再進行比較。再處理,如刪除無意義的介詞,極大地簡化了計算,提高了模型的效率。(2)選取LSTM模型時,收集了大量的樣本對其進行訓練,提高了精度。更改了模型中的參數,以檢查它是否會影響輸出結果。最后,模型是穩定的。(3)對時間序列進行預測,使用了prophet模型。與傳統的時間序列預測方法(如ARIMA模型)相比,ARIMA模型通常存在適用時間序列數據量小、缺失值需要填充、靈活性差、指導性差的局限性。prophet模型更簡單、更靈活,解決了預測定制季節和假期效果的時間問題。
缺點:(1)由于帶有投票的評論很少,為了簡化模型,我們沒有過多考慮有用評論數的影響,這可能會對分析造成一定的誤差。(2)雖然特征詞提取的結果有效地揭示了客戶的主要關注點,但出現頻率最高的詞包含無意義詞(如baby等)。這在一定程度上是因為奶嘴產品是針對嬰兒的。
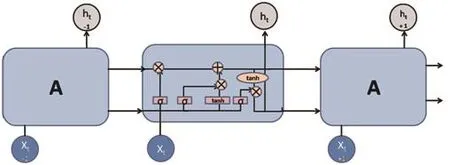
圖2 LSTM的網絡結構
猜你喜歡
工會博覽(2023年3期)2023-04-06 15:52:34
小康(2021年7期)2021-03-15 05:29:03
活力(2019年19期)2020-01-06 07:34:38
雜文月刊(2019年15期)2019-09-26 00:53:54
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2015年1期)2015-08-13 02:23:50
中外會展(2014年4期)2014-11-27 07:46:46
玩具(2009年10期)2009-11-04 02:33:14
個人電腦(2009年9期)2009-09-14 03:18:46
舒適廣告(2008年9期)2008-09-22 10:02:48
