基于改進(jìn)時(shí)間卷積網(wǎng)絡(luò)的日志序列異常檢測
2020-08-19 07:00:56楊瑞朋朱少衛(wèi)錢葉魁唐永旺
計(jì)算機(jī)工程 2020年8期
楊瑞朋,屈 丹,朱少衛(wèi),錢葉魁,唐永旺
(1.中國人民解放軍戰(zhàn)略支援部隊(duì)信息工程大學(xué) 信息系統(tǒng)工程學(xué)院,鄭州 450002;2.中國人民解放軍陸軍炮兵防空兵學(xué)院(鄭州校區(qū)),鄭州 450002)
0 概述
隨著網(wǎng)絡(luò)應(yīng)用和系統(tǒng)規(guī)模的不斷增大,程序的執(zhí)行路徑難以預(yù)測,并且硬件環(huán)境不再可靠,難以在部署前發(fā)現(xiàn)可能發(fā)生的錯(cuò)誤。另一方面,隨著互聯(lián)網(wǎng)的不斷發(fā)展,各類網(wǎng)絡(luò)應(yīng)用在生產(chǎn)生活中發(fā)揮著越來越重要的作用。但與此同時(shí),網(wǎng)絡(luò)環(huán)境日益復(fù)雜,針對網(wǎng)絡(luò)應(yīng)用和系統(tǒng)的攻擊不斷涌現(xiàn),且攻擊形式多樣。一旦針對網(wǎng)絡(luò)應(yīng)用和系統(tǒng)的攻擊成功或者網(wǎng)絡(luò)應(yīng)用自身出現(xiàn)異常,將給應(yīng)用的所有者及用戶帶來不可估量的損失。攻擊和錯(cuò)誤越早發(fā)現(xiàn),所能采用的補(bǔ)救措施就越多,造成的損失就會(huì)越少[1]。因此,研究異常檢測技術(shù)具有非常重要的意義。
在網(wǎng)絡(luò)應(yīng)用運(yùn)行的過程中,應(yīng)用本身和監(jiān)控程序都會(huì)產(chǎn)生各類日志來記錄應(yīng)用的狀態(tài)、重要的運(yùn)行事件和網(wǎng)絡(luò)流量,因此日志包含應(yīng)用運(yùn)行的動(dòng)態(tài)信息,適合用于異常檢測。通過日志對網(wǎng)絡(luò)行為和系統(tǒng)分析的異常檢測技術(shù)能夠充分挖掘、利用網(wǎng)絡(luò)內(nèi)在信息及其相互關(guān)系,具有較好的靈活性、適應(yīng)性,已成為目前異常檢測領(lǐng)域的研究熱點(diǎn)[2-4]。因日志本身就是序列數(shù)據(jù),日志的出現(xiàn)序列有一定的依賴關(guān)系,且有時(shí)依賴的長度較長。如一些新型攻擊一旦實(shí)施,并不會(huì)立即產(chǎn)生破壞,而是達(dá)到某些先決條件,或是進(jìn)行某些正常操作后才產(chǎn)生破壞,體現(xiàn)在日志序列中即長時(shí)依賴關(guān)系。
為更好地挖掘長時(shí)依賴關(guān)系,本文提出一種基于時(shí)間卷積網(wǎng)絡(luò)(Temporal Convolutional Network,TCN)的日志序列異常檢測框架TCNLog。時(shí)間卷積網(wǎng)絡(luò)基于卷積神經(jīng)網(wǎng)絡(luò),是一種能夠處理時(shí)間序列數(shù)據(jù)的網(wǎng)絡(luò)結(jié)構(gòu)。TCN引入padding機(jī)制,使模型的輸入和輸出長度相同,同時(shí)卷積后的特征較少丟失。該框架避免傳統(tǒng)機(jī)器學(xué)習(xí)方法復(fù)雜的特征提取步驟,并借助于深度學(xué)習(xí)強(qiáng)大的自動(dòng)學(xué)習(xí)特征的能力[5],將經(jīng)過充分訓(xùn)練的日志模板的語義向量表示輸入TCN網(wǎng)絡(luò),其中的空洞卷積機(jī)制能獲取日志序列更大的感受視野,實(shí)現(xiàn)沒有“漏接”的歷史信息,以更好地解決序列的長時(shí)依賴問題。
1 相關(guān)工作
異常檢測是保障網(wǎng)絡(luò)和系統(tǒng)安全的支撐技術(shù)之一,目前流行的異常檢測方法主要有基于網(wǎng)絡(luò)流量的異常檢測、基于惡意代碼的異常檢測和基于社交網(wǎng)絡(luò)安全事件的異常檢測[6]。但是網(wǎng)絡(luò)流量異常檢測技術(shù)容易漏過寬時(shí)間域內(nèi)的網(wǎng)絡(luò)攻擊。此外,現(xiàn)代網(wǎng)絡(luò)攻擊往往是多種攻擊手段的組合,而網(wǎng)絡(luò)流量異常檢測技術(shù)的數(shù)據(jù)源種類較為單一。因此,傳統(tǒng)網(wǎng)絡(luò)流量異常檢測技術(shù)存在局限性。惡意代碼異常檢測技術(shù)可以有效檢測數(shù)量快速增長的未知惡意程序。然而,新型攻擊中惡意代碼偽裝性和隱蔽性很高,惡意代碼異常檢測技術(shù)在應(yīng)對仍然存在時(shí)空關(guān)聯(lián)能力差和漏檢率較高等問題。社交網(wǎng)絡(luò)安全事件挖掘技術(shù)可以識別用戶行為異常,并為攻擊檢測提供指導(dǎo),但社交網(wǎng)絡(luò)中蘊(yùn)含的攻擊信息畢竟有限,該技術(shù)需要與其他異常檢測技術(shù)配合使用,才能更有效地檢測網(wǎng)絡(luò)攻擊。
日志中蘊(yùn)含著豐富的信息,面向異常檢測的日志挖掘作為近幾年新興的一類檢測手段,是建立安全可信計(jì)算機(jī)系統(tǒng)的一項(xiàng)重要任務(wù),具有攻擊問題分析準(zhǔn)確、攻擊鏈可重構(gòu)性等特點(diǎn)。傳統(tǒng)日志分析通過人工檢驗(yàn)或者使用事先定義好的異常規(guī)則來實(shí)現(xiàn)。當(dāng)日志大小有限以及異常類型可知時(shí),這些方法十分有效并且也比較靈活,但是對于當(dāng)前程序產(chǎn)生的百萬行規(guī)模的日志,人工檢測很難實(shí)現(xiàn)[7],提前獲取所有可能的異常也很困難[8]。隨著系統(tǒng)和應(yīng)用程序變得越來越復(fù)雜,攻擊者可能會(huì)利用更多的漏洞和弱點(diǎn)來發(fā)起攻擊。這樣,攻擊也變得越來越復(fù)雜,且日志的數(shù)據(jù)量太大,非結(jié)構(gòu)化、沒有領(lǐng)域知識、不易理解等都給分析造成很大的挑戰(zhàn)。因此,面向異常檢測的日志挖掘更具挑戰(zhàn)性。
隨著機(jī)器學(xué)習(xí)的發(fā)展,有很多研究采用特征工程,利用各種聚類[9]的方法發(fā)現(xiàn)異常點(diǎn)用于異常檢測。并且大量的異常檢測日志挖掘方法是為不同應(yīng)用設(shè)計(jì)的,這種方法雖然準(zhǔn)確,但是僅限于特定場景的應(yīng)用并且需要領(lǐng)域?qū)<摇;谌粘P蛄械漠惓z測方法也被廣泛研究。文獻(xiàn)[10]將痕跡視為序列數(shù)據(jù),并使用基于概率后綴樹的方法來組織和區(qū)分序列所具有的重要統(tǒng)計(jì)特性。隨著深度學(xué)習(xí)的發(fā)展,循環(huán)神經(jīng)網(wǎng)絡(luò)在序列數(shù)據(jù)中有很好的應(yīng)用,一些學(xué)者對日志序列的異常檢測問題運(yùn)用循環(huán)神經(jīng)網(wǎng)絡(luò)模型進(jìn)行一些嘗試。文獻(xiàn)[11]對來自多個(gè)日志源的原始日志文本使用聚類技術(shù)生成特征序列,并輸入到LSTM模型中以進(jìn)行故障預(yù)測。文獻(xiàn)[12]對系統(tǒng)日志的原始文本解析,生成日志模板序列輸入LSTM以檢測拒絕服務(wù)攻擊。最近的研究[13]表明,將時(shí)間卷積神經(jīng)網(wǎng)絡(luò)應(yīng)用到序列任務(wù)中,特別是處理長時(shí)依賴關(guān)系時(shí),具有比循環(huán)神經(jīng)網(wǎng)絡(luò)更好的效果。
對比傳統(tǒng)的日志序列異常檢測方法,本文的主要貢獻(xiàn)主要有以下3個(gè)方面:
1)提出一種基于時(shí)間卷積網(wǎng)絡(luò)的日志序列異常檢測框架,實(shí)驗(yàn)驗(yàn)證該框架在更長序列上有很好的異常檢測能力。
2)分析并對比了不同激活函數(shù)在異常檢測模型中的效果,說明了PReLU激活函數(shù)在該問題中的適用性。
3)分析了網(wǎng)絡(luò)中全連接層參數(shù)量大的不足,提出了用自適應(yīng)平均池化層代替全連接層,將1×1卷積層與全連接層進(jìn)行對比,證明了自適應(yīng)平均池化層的優(yōu)勢。
2 基于TCN的異常檢測框架
時(shí)間卷積網(wǎng)絡(luò)是一種基于卷積神經(jīng)網(wǎng)絡(luò)的能夠處理時(shí)間序列數(shù)據(jù)的網(wǎng)絡(luò)結(jié)構(gòu)。該網(wǎng)絡(luò)具有兩個(gè)特點(diǎn):一是網(wǎng)絡(luò)的輸入長度和輸出長度相等;二是沒有漏接的歷史信息。為使網(wǎng)絡(luò)輸入和輸出長度相等,TCN網(wǎng)絡(luò)采用一維全卷積,并在每層加入0-padding以實(shí)現(xiàn)輸入長度和輸出長度相等;為實(shí)現(xiàn)序列建模任務(wù),引入因果卷積[14],當(dāng)序列長度增加時(shí),為不遺漏歷史信息,需要增加網(wǎng)絡(luò)深度,但增加了參數(shù)量。為解決該問題,TCN引入空洞卷積[15],在不增加參數(shù)量的前提下,盡量少地增加網(wǎng)絡(luò)深度,擴(kuò)大感受視野。增加網(wǎng)絡(luò)深度會(huì)導(dǎo)致梯度彌散或梯度爆炸,但可通過確保中間的正則化層(Batch Normalization)解決該問題,這樣可以確保幾十層的網(wǎng)絡(luò)能夠收斂。雖然通過上述方法能夠進(jìn)行訓(xùn)練,但是又會(huì)出現(xiàn)退化問題。文獻(xiàn)[16]提出殘差網(wǎng)絡(luò)來解決退化問題。TCN的網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示。

圖1 TCN網(wǎng)絡(luò)結(jié)構(gòu)Fig.1 TCN network structure
一個(gè)日志文件包含多個(gè)事件類型,每個(gè)事件類型包含若干條日志,屬于同一個(gè)事件類型的日志有共同的模板,可以把一個(gè)日志序列理解為發(fā)生的一系列事件,即原始日志序列對應(yīng)的日志模板的序列。文獻(xiàn)[17]從原始日志中進(jìn)行日志模板的提取。本文的研究工作是:對原始日志序列對應(yīng)的日志模板序列的異常進(jìn)行檢測,判定異常的依據(jù)為根據(jù)當(dāng)前序列預(yù)測下一個(gè)日志模板,若預(yù)測值和實(shí)際模板相同,則認(rèn)為正常,否則認(rèn)為異常。
TCN結(jié)構(gòu)中激活函數(shù)使用ReLU[18],雖然收斂速度快,但容易引起神經(jīng)元“壞死”,無法學(xué)習(xí)到日志序列中更多的有效特征。另一個(gè)問題是檢測框架中的全連接層相當(dāng)于一個(gè)“分類器”,預(yù)測輸入序列的下一個(gè)日志模板。如果能減少參數(shù)量,則能有效地避免網(wǎng)絡(luò)的過擬合問題,但妨礙了整個(gè)網(wǎng)絡(luò)的泛化能力。針對上述問題,本文對基于TCN的日志序列檢測框架進(jìn)行了改進(jìn),即改進(jìn)激活函數(shù)與全連接層。異常檢測框架TCNLog如圖2所示。

圖2 日志序列異常檢測框架TCNLogFig.2 Anomaly detection framework TCNLog of log sequence
2.1 激活函數(shù)的選擇和改進(jìn)
卷積神經(jīng)網(wǎng)絡(luò)具有很強(qiáng)的建模能力,特別是加入了ReLU激活函數(shù)后,能夠表達(dá)輸入日志序列間的非線性關(guān)系。但是對日志序列的預(yù)測效果好壞與網(wǎng)絡(luò)訓(xùn)練的每個(gè)細(xì)節(jié)息息相關(guān)。本文從卷積神經(jīng)網(wǎng)絡(luò)的訓(xùn)練過程方面進(jìn)行優(yōu)化,對激活函數(shù)進(jìn)行比較和選擇。
原始TCN網(wǎng)絡(luò)中使用的是ReLU激活函數(shù)。ReLU函數(shù)屬于非飽和激活函數(shù),在正數(shù)不飽和,在負(fù)數(shù)硬飽和,如圖3(a)所示。它對正數(shù)原樣輸出,負(fù)數(shù)直接置零。冪運(yùn)算更節(jié)省計(jì)算量,因而收斂較快,在CNN中常用。但ReLU也有缺點(diǎn),即神經(jīng)元“壞死”(ReLU在負(fù)數(shù)區(qū)域被kill的現(xiàn)象叫做壞死),ReLU強(qiáng)制的稀疏處理會(huì)減少模型的有效容量,特征被屏蔽太多,導(dǎo)致模型無法學(xué)習(xí)到有效特征。由于ReLU在x<0時(shí)梯度為0,這樣就導(dǎo)致負(fù)的梯度在這個(gè)ReLU被置0,而且這個(gè)神經(jīng)元有可能再也不會(huì)被任何數(shù)據(jù)激活。例如,一個(gè)非常大的梯度流過一個(gè)ReLU神經(jīng)元,更新過參數(shù)之后,這個(gè)神經(jīng)元再也不會(huì)對任何數(shù)據(jù)有激活現(xiàn)象,那么這個(gè)神經(jīng)元的梯度就永遠(yuǎn)都會(huì)是0。
為解決這一問題,文獻(xiàn)[19]提出PReLU (Parametric Rectified Linear Unit)激活函數(shù)。帶參數(shù)的ReLU如圖3(b)所示,對應(yīng)中的參數(shù)a是可學(xué)習(xí)的,根據(jù)任務(wù)數(shù)據(jù)來定義,而非預(yù)先定義。這樣僅增加了一點(diǎn)額外的計(jì)算量和過擬合的風(fēng)險(xiǎn),但提高了零值附近的模型擬合能力。當(dāng)a=0時(shí),PReLU退化成ReLU,當(dāng)a是非常小的一個(gè)數(shù)如0.01時(shí),PReLU退化成Leaky ReLU[20]。Leaky ReLU在負(fù)軸上的斜率是一個(gè)固定的較小的常數(shù),雖然保留了一些負(fù)軸的值,使得負(fù)軸的信息不會(huì)全部丟失,但是這一事先指定的斜率不一定適合數(shù)據(jù)分布。激活函數(shù)ELUs如圖3(c)所示。
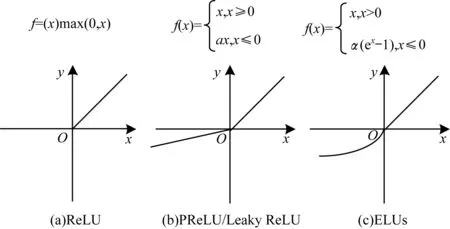
圖3 激活函數(shù)圖像對比Fig.3 Comparison of activation function images
以上是對ReLU負(fù)軸上的優(yōu)化策略,但對ReLU函數(shù)的正半軸不施加任何非線性約束,因此當(dāng)輸入為正大數(shù)時(shí),易引起正半軸上的梯度爆炸。Relu 6如式(1)所示:
f(x)=min(max(0,x),6)
(1)
它對正半軸施加了非線性約束,但并沒有消除神經(jīng)元“壞死”,壞死區(qū)域?yàn)镽elu的(-∞,0)~Relu 6的(-∞,0)∪(6,+∞)。
本文修改TCN網(wǎng)絡(luò)中的激活函數(shù)ReLU為PReLU,初始化參數(shù)a=0.25,網(wǎng)絡(luò)自動(dòng)學(xué)習(xí)更新參數(shù),在實(shí)驗(yàn)中,對Leaky ReLU、ELUs和ReLU 6激活函數(shù)進(jìn)行比較。
2.2 檢測模型
檢測模型包含embedding層、改進(jìn)的TCN層和自適應(yīng)平均池化層。
2.2.1 embedding層
embedding層是把日志模板序列作為輸入,用于異常檢測框架的前端輸入,將序列中的每個(gè)日志模板序號映射成密集的詞嵌入。embedding層作為異常檢測模型的一部分,生成詞向量時(shí)需要指定維度,向量以小的隨機(jī)數(shù)進(jìn)行初始化,采用反向傳播算法進(jìn)行訓(xùn)練更新。和開源的預(yù)訓(xùn)練包Word2Vec和GloVe相比,embedding層雖然是一個(gè)較慢的方法,但可以通過模型訓(xùn)練為特定的日志數(shù)據(jù)集定制詞嵌入。基于神經(jīng)網(wǎng)絡(luò)訓(xùn)練的詞嵌入包含豐富的上下文信息,既可以很好地表現(xiàn)目標(biāo)詞在當(dāng)前日志序列中的語義規(guī)則,又實(shí)現(xiàn)了降維的目的。
2.2.2 改進(jìn)的TCN層
日志模板序列經(jīng)過embedding層初始化后,需要以下步驟生成日志模板序列特征表示:
步驟1輸入第一個(gè)一維空洞卷積層,并進(jìn)行歸一化。需要指明的參數(shù)包括日志模板詞嵌入的維度、日志模板詞典的大小、卷積核尺寸、步長、padding大小及是否加入空洞。
步驟2根據(jù)第一個(gè)卷積層的輸出與padding的大小,對卷積后的張量進(jìn)行切片來實(shí)現(xiàn)因果卷積。因果卷積是利用卷積來學(xué)習(xí)當(dāng)前輸入模型的日志序列中最后一個(gè)日志模板前的日志模板序列(長度h),來預(yù)測下一個(gè)日志模板,即該卷積層的輸出僅依賴于序列步為1,2,…,h的輸入,不會(huì)依賴于h+1以及之后的輸入。
步驟3添加PReLU激活函數(shù)。
步驟4Dropout正則化方法完成第一個(gè)卷積塊,Dropout是在訓(xùn)練神經(jīng)網(wǎng)絡(luò)模型時(shí)樣本數(shù)據(jù)過少,防止過擬合而采用的策略。
步驟5堆疊同樣結(jié)構(gòu)的第2個(gè)卷積塊,這樣構(gòu)成了一個(gè)殘差塊。
2.2.3 替代全連接層的方案
原始TCN之后加入全連接層是一種線性變換,轉(zhuǎn)換成維數(shù)為日志模板詞典的大小的概率向量P=(p1,p2,…,pk)(日志文件中包含k個(gè)日志模板),pi表示對當(dāng)前序列預(yù)測的下一個(gè)日志模板為ei。假設(shè)序列長度為h,詞向量的維度為embedding,日志模板詞典大小為k,從參數(shù)量的角度考慮,全連接層需要學(xué)習(xí)的參數(shù)量是h×embedding×k。受文獻(xiàn)[21]提出的全局平均池化思想的啟發(fā),即卷積后加一個(gè)全局平均池化層替換全連接層,因?yàn)槌鼗恍枰?xùn)練模型參數(shù),所以減少了模型訓(xùn)練參數(shù)量。因?yàn)楸疚氖遣捎靡痪S全卷積,經(jīng)過TCN卷積后的輸出除去batch_size和序列長度外,是一個(gè)維度為詞嵌入長度的一維向量,所以不能對該輸出計(jì)算全局平均池化。經(jīng)過TCN模型輸出的形狀batch_size×h×embedding,經(jīng)過全連接層線性變換之后,輸出形狀變?yōu)閎atch_size×h×k,可以看出,僅是通道數(shù)的改變。為達(dá)到改變通道數(shù)的目的,防止過擬合并提高模型的泛化能力和準(zhǔn)確率,本文在改進(jìn)TCN模型基礎(chǔ)上通過用自適應(yīng)平均池化層(Adaptive Average Pooling,AAP)改變通道數(shù),用池化層代替全連接層。在算法中只需要設(shè)置該層的輸出維度為日志模板類別,自適應(yīng)平均池化層會(huì)根據(jù)輸入形狀和輸出維度的值,自動(dòng)計(jì)算卷積核尺寸及步長,確定每一步的卷積區(qū)域,并求出在該卷積塊上的均值。該算法的偽代碼如下(以一維為例):
for 輸出向量位置索引號←0 to 輸出長度
卷積塊起始位置= floor (索引號×輸入長度/輸出長度)
卷積塊終止位置= ceil ((索引號+1)×輸入長度/輸出長度)
ks←(卷積塊終止位置-卷積塊起始位置)
for 當(dāng)前卷積塊的起始位置←0 to ks
sum (輸入向量[卷積塊起始位置,卷積塊終止位置-1])
end
輸出向量當(dāng)前位置對應(yīng)的值←(sum/ks)
end
在算法中,floor函數(shù)表示取下限,ceil函數(shù)表示取上限。
從自適應(yīng)平均池化的執(zhí)行過程可以看出,當(dāng)輸入長度mod輸出長度≠0時(shí),卷積核尺寸和步長并不是固定不變的,而且卷積塊會(huì)在某些位置有重疊,池化操作后,每一維度的值可以理解為每個(gè)類別生成的一個(gè)特征值,向量中最大的特征值所在維度即為預(yù)測的日志模板編號。自適應(yīng)平均池化層沒有優(yōu)化參數(shù),提高了模型的訓(xùn)練時(shí)間和測試時(shí)間,避免在該層過擬合。自適應(yīng)平均池化對網(wǎng)絡(luò)在結(jié)構(gòu)上做正則化處理,其直接剔除了全連接層中黑箱的特征,直接賦予了每個(gè)通道實(shí)際的類別意義。
2.3 模型訓(xùn)練
假設(shè)一個(gè)日志文件中包含k個(gè)日志模板E={e1,e2,…,ek},訓(xùn)練階段的輸入為日志模板的序列,一個(gè)長度為h的日志序列l(wèi)t-h,…,lt-2,lt-1中包含的日志模板li∈E,t-h≤i≤t-1,且一個(gè)序列中的日志模板數(shù)|lt-h,…,lt-2,lt-1|=m≤h。為方便處理數(shù)據(jù),首先將每個(gè)日志模板對應(yīng)一個(gè)模板號,并生成日志模板詞典,然后把正常的日志模板序列生成輸入序列和目標(biāo)數(shù)據(jù)代入異常檢測模型進(jìn)行訓(xùn)練。序列建模學(xué)習(xí)的目標(biāo)是訓(xùn)練一個(gè)網(wǎng)絡(luò)f使得模型輸出和實(shí)際的日志模板之間的損失函數(shù)loss(lt,f(lt-h,lt-h+1,…,lt-1))最小,訓(xùn)練中的損失函數(shù)采用交叉熵。交叉熵誤差函數(shù)的表達(dá)式為:
(2)
其中,yi是類別i的真實(shí)標(biāo)簽,pi是softmax計(jì)算出的類別i的概率值,k是類別數(shù),N是樣本總數(shù)。
對損失函數(shù)的優(yōu)化采用自適應(yīng)梯度下降法(Stochastic Gradient Descent,SGD)。在訓(xùn)練時(shí),SGD算法是從樣本中隨機(jī)抽出一組,訓(xùn)練后按梯度更新一次,下一次訓(xùn)練再隨機(jī)抽取一組,再更新一次,因此,每次的學(xué)習(xí)速度較快。在樣本量非常大的情況下,不用訓(xùn)練完所有的樣本就可以獲得一個(gè)損失值在可接受范圍之內(nèi)的模型。SGD最大的缺點(diǎn)在于每次更新可能并不會(huì)按照正確的方向進(jìn)行,可以帶來優(yōu)化波動(dòng),這個(gè)波動(dòng)會(huì)使得優(yōu)化的方向從當(dāng)前的局部極小值點(diǎn)跳到另一個(gè)更好的局部極小值點(diǎn),因此會(huì)使得迭代次數(shù)(學(xué)習(xí)次數(shù))增多,即收斂速度變慢。為了加快收斂速度,在實(shí)驗(yàn)設(shè)置中,選擇SGD梯度下降算法,并使用學(xué)習(xí)速率(learing rate,lr)退火調(diào)整。針對本文任務(wù),經(jīng)過多次實(shí)驗(yàn),確定的退火方法為:lr=lr*(0.5**(epoch//10)),即每訓(xùn)練10次,學(xué)習(xí)率縮小2倍。
2.4 檢測階段
數(shù)據(jù)輸入的方法同訓(xùn)練階段,用訓(xùn)練階段生成的模型進(jìn)行異常檢測,模型輸出為一個(gè)概率向量P=(p1,p2,…,pk),pi表示目標(biāo)日志模板為ei的概率,模型直接的輸出實(shí)際上可以理解為多分類問題,但最后的結(jié)果為正常和異常的二分類問題,所以需要進(jìn)一步判定。依據(jù)經(jīng)驗(yàn),特別是在日志模板數(shù)較少的情況下,一個(gè)輸入序列的目標(biāo)日志模板不止一種情況,認(rèn)為P中的前g個(gè)大的概率值對應(yīng)的日志模板是正常的。圖2所示的“目標(biāo)是否在預(yù)測值內(nèi)”中的“預(yù)測值”是概率較大的前g個(gè)日志模板。如果實(shí)際目標(biāo)數(shù)據(jù)在預(yù)測值內(nèi),則判定為該日志序列正常,否則判定為異常。
3 實(shí)驗(yàn)結(jié)果與分析
3.1 實(shí)驗(yàn)環(huán)境與數(shù)據(jù)集
本文的實(shí)驗(yàn)環(huán)境采用Ubuntu 16.04 LT,64位系統(tǒng),62.8 GB內(nèi)存,Processor Intel Xeon?CPU E5-2620v4 @ 2.1 GHz×16處理器,Graphic Geforce GTX 1080 Ti/PCIe/SSE2雙GPU平臺(tái)。實(shí)驗(yàn)日志數(shù)據(jù)為BlueGene/L (BGL)日志數(shù)據(jù)集。數(shù)據(jù)集BlueGene/L(BGL)[22]包含215天的4 747 963條原始日志,大小為708 MB。本文對BGL數(shù)據(jù)集不進(jìn)行按固定時(shí)間窗進(jìn)行劃分,而是按模型參數(shù)中指定的序列長度進(jìn)行劃分并預(yù)測,并利用滑動(dòng)窗口的方法取下一個(gè)序列。選擇數(shù)據(jù)集80%的正常序列為訓(xùn)練集。數(shù)據(jù)集信息如表1所示。

表1 數(shù)據(jù)集信息Table 1 Data set information
3.2 評價(jià)標(biāo)準(zhǔn)
考慮到日志數(shù)據(jù)集多數(shù)是正常日志多、異常日志少的不平衡數(shù)據(jù)集。評價(jià)本文提出的基于時(shí)間卷積網(wǎng)絡(luò)異常檢測框架的檢測性能,主要采用檢測率、誤報(bào)率、準(zhǔn)確率3個(gè)指標(biāo),這樣分別考察真實(shí)樣本情況為異常日志序列和正常日志序列上的檢測效果,而不受“不平衡”這一特性的影響。日志序列異常檢測的混淆矩陣如表2所示。
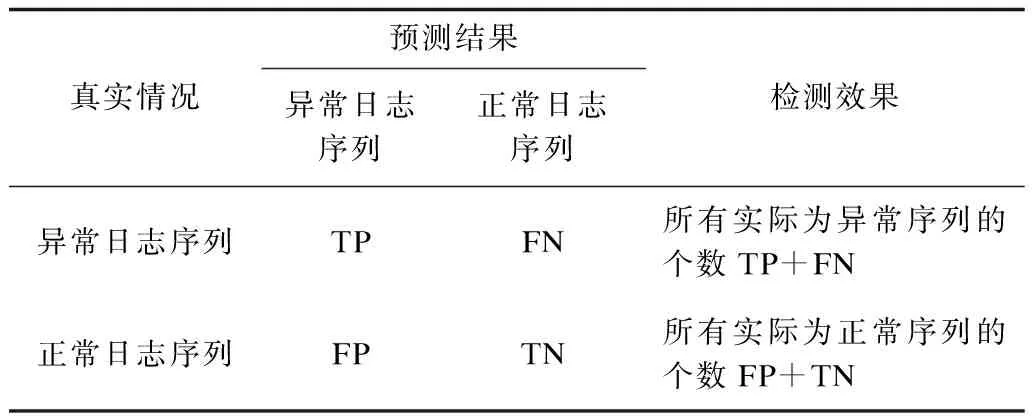
表2 日志序列異常檢測混淆矩陣Table 2 Confusion matrix of log sequence anomaly detection
在表2中,TP表示異常日志序列被正確檢測為異常的數(shù)量,FN表示異常日志序列被錯(cuò)誤檢測為正常的數(shù)量,FP表示正常日志序列被錯(cuò)誤檢測為異常的數(shù)量,TN表示正常日志序列被正確檢測為正常的數(shù)量。對應(yīng)的幾項(xiàng)評價(jià)指標(biāo)如下:
1)真正類率(True Positive Rate,TPR),又稱為檢測率,表示被正確檢測為異常的異常日志序列數(shù)占異常日志序列總數(shù)的比率,值越大,性能越好。計(jì)算公式為:
(3)
2)假正類率(False Positive Rate,FPR),又稱誤報(bào)率,表示被錯(cuò)誤檢測為異常的正常日志序列占實(shí)際正常日志序列總數(shù)的比率,值越小,性能越好。計(jì)算公式為:
(4)
3)準(zhǔn)確率(Accuracy),表示檢測結(jié)果是正確的樣本數(shù)占樣本總數(shù)的比率,值越大,性能越好。計(jì)算公式為:
(5)
對測試集中的正常日志集和異常日志集,取和訓(xùn)練過程中相同的序列長度,分別載入已訓(xùn)練好的模型進(jìn)行測試,如果模型對當(dāng)前序列預(yù)測得到的前g個(gè)日志模板中不包含實(shí)際的下一個(gè)日志模板,則對正常日志序列集,FP加1,對異常日志序列集,TP加1。
3.3 參數(shù)設(shè)置
本文通過反復(fù)實(shí)驗(yàn)不同的參數(shù)組合,確定了模型的最優(yōu)參數(shù)。后續(xù)實(shí)驗(yàn)均采用最優(yōu)參數(shù)進(jìn)行比對實(shí)驗(yàn)。詞嵌入維度input_size設(shè)置為100,卷積核尺寸k設(shè)置為3,每層的隱藏單元數(shù)hidden設(shè)置為100,embedding層的dropout設(shè)置為0.25,卷積層的dropout設(shè)置為0.45,初始學(xué)習(xí)率設(shè)置為4,在檢測階段,如2.4節(jié)所述,g被設(shè)置為20。
3.4 結(jié)果分析
Deeplog[12]分析并驗(yàn)證了2層LSTM在日志序列異常檢測的效果,本文在2層LSTM之上加上自注意力層,能更好地保留和控制序列的上下文信息,解決序列的長時(shí)依賴問題。文獻(xiàn)[13]通過理論分析和對文本數(shù)據(jù)集的實(shí)驗(yàn)驗(yàn)證,得到TCN對更長序列有很好的建模能力。為了考察本文改進(jìn)TCN的檢測模型對日志長序列的異常檢測能力,該實(shí)驗(yàn)選擇自注意力機(jī)制的LSTM作為本文的對比模型,對不同序列長度分別用本文方法和“2層LSTM+自注意力層”異常檢測模型進(jìn)行比較,實(shí)驗(yàn)結(jié)果如圖4所示。
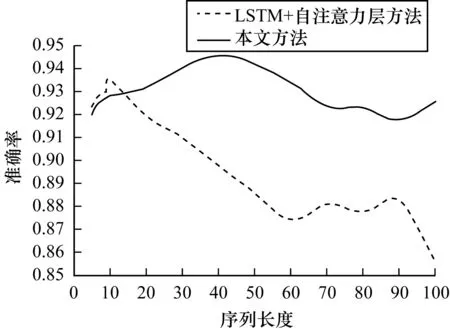
圖4 兩種方法對不同序列長度的準(zhǔn)確率比較Fig.4 Accuracy comparison of two methods for different sequence lengths
從圖4可以看出,在序列長度seq_len≤10時(shí),“LSTM+自注意力層”有更好的檢測能力;但seq_len>10時(shí),“LSTM+自注意力層”在seq_len>10之后,準(zhǔn)確率快速下降,而本文方法有很明顯的檢測優(yōu)勢。主要原因是LSTM的記憶門和忘記門在忘記不再需要的記憶并保存輸入信息的有用部分后,會(huì)得到更新后的長期記憶,但隱含層的輸入對于網(wǎng)絡(luò)輸出的影響隨著序列長度的不斷增加而衰退,丟失了很多細(xì)節(jié)信息。文獻(xiàn)[23]表明,當(dāng)序列長度非常長(>100 s)時(shí),LSTM很難訓(xùn)練。時(shí)間卷積網(wǎng)絡(luò)對長時(shí)間數(shù)據(jù)來建模,能調(diào)整感受野的長度以及卷積核大小靈活調(diào)整可以學(xué)習(xí)的序列的長度。本文的檢測模型在給定的參數(shù)設(shè)置下,實(shí)驗(yàn)結(jié)果顯示,在seq_len=40時(shí),最好的檢測準(zhǔn)確率為0.945 56,并在seq_len=70后,有相對穩(wěn)定的檢測效果,可見本文的改進(jìn)模型有更好的魯棒性。
為考察不同激活函數(shù)對模型檢測的影響,取序列長度h=100時(shí),分析“TCN+AAP”中時(shí)間卷積網(wǎng)絡(luò)分別采用PReLU、Leaky ReLU、ReLU6和ELUs激活函數(shù)的檢測性能,實(shí)驗(yàn)結(jié)果如圖5、圖6所示。
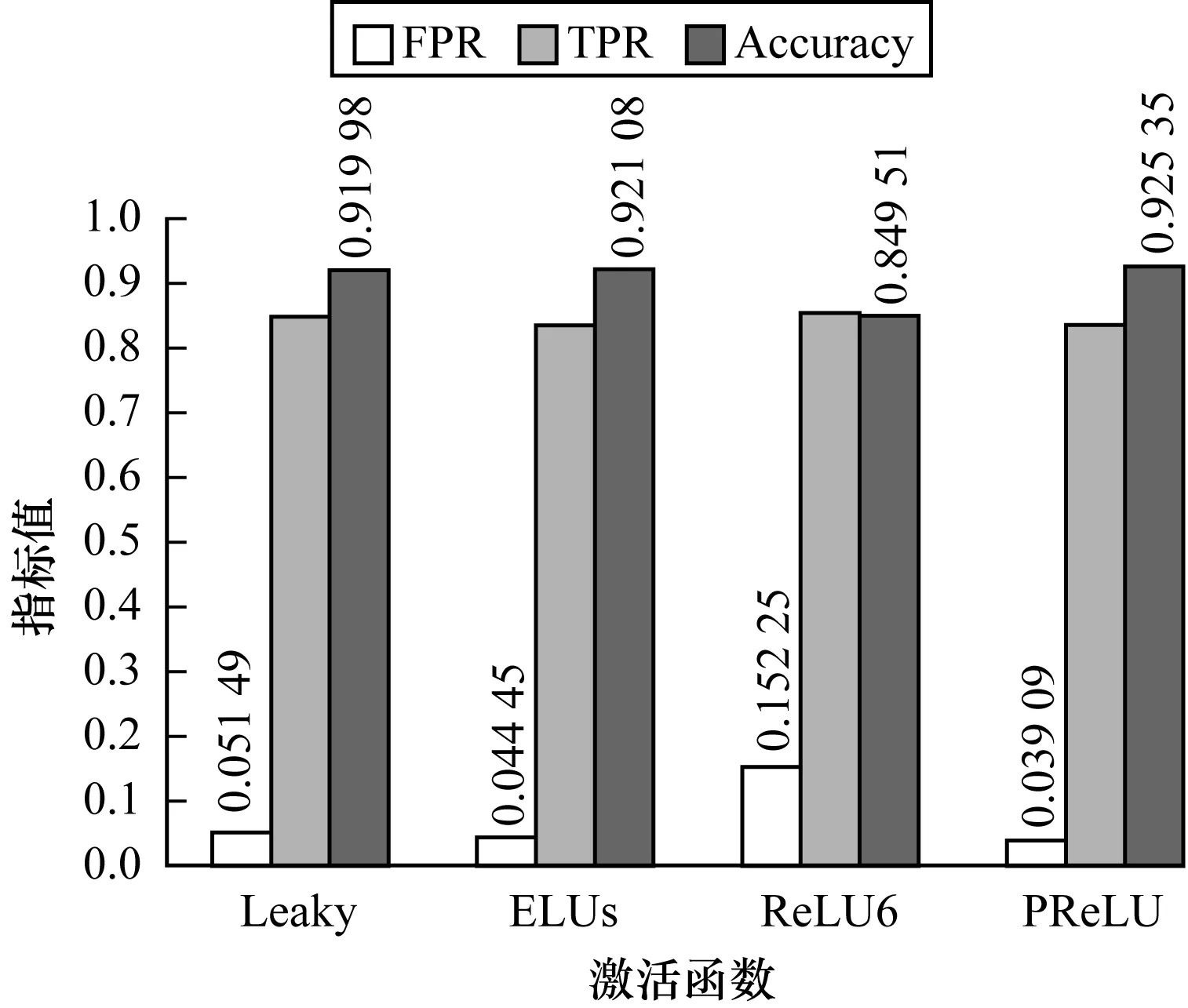
圖5 不同激活函數(shù)檢測性能對比Fig.5 Comparison of detection performance of different activation functions
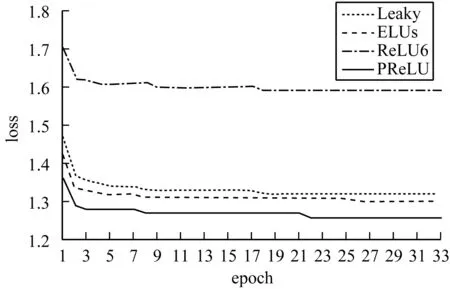
圖6 不同激活函數(shù)對損失函數(shù)的影響Fig.6 Effect of different activation functions on loss function
從圖5可以看出,在采用PReLU時(shí),檢測模型取得了最高的準(zhǔn)確率和最低的誤報(bào)率,綜合性能評價(jià)最優(yōu)。從圖6可以看出,雖然采用不同的激活函數(shù)收斂速度相當(dāng),但采用PReLU時(shí),有最小的損失函數(shù)值。
為考察自適應(yīng)均值池化層替換全連接層后對檢測模型精度的影響,在序列長度h=100時(shí)對比了時(shí)間卷積網(wǎng)絡(luò)分別采用TCN+Linear、TCN+AAP、改進(jìn)的TCN+AAP和改進(jìn)的TCN+Linear 4組檢測結(jié)果,如表3所示。從誤報(bào)率、檢測率和準(zhǔn)確率3個(gè)指標(biāo)可以看出,采用同樣的下層網(wǎng)絡(luò)結(jié)構(gòu)連接全連接層和自適應(yīng)均值池化層后,對日志序列的異常檢測能力均得到了提高。如下層網(wǎng)絡(luò)用TCN時(shí),采用自適應(yīng)均值池化層比全連接層誤報(bào)率降低了4.483%,檢測率提高了1.589%,準(zhǔn)確率提高了3.661%;下層網(wǎng)絡(luò)用改進(jìn)TCN網(wǎng)絡(luò)時(shí),采用自適應(yīng)均值池化層比全連接層誤報(bào)率降低了3.237%,準(zhǔn)確率提高了2.325%。因此,自適應(yīng)均值池化層代替全連接層后不僅該層的參數(shù)量從h×embedding×k降低到了0,而且檢測性能得到有效提升。
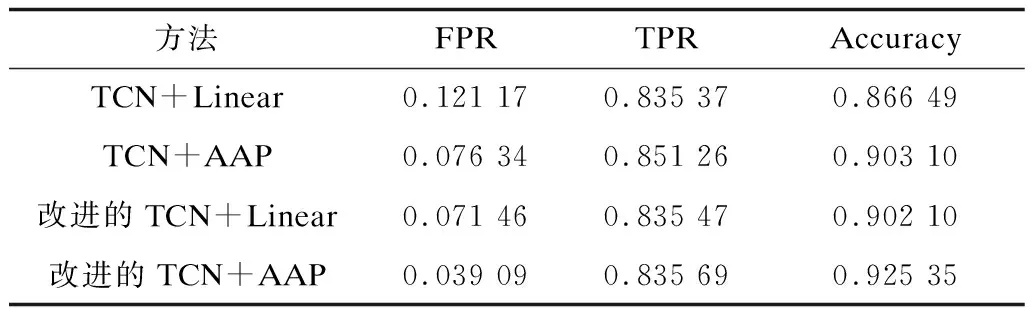
表3 自適應(yīng)池化層對檢測性能的影響Table 3 Influence of adaptive pooling layer on detection performance
文獻(xiàn)[21]提出1×1卷積核可用來改變通道數(shù),本文實(shí)驗(yàn)設(shè)置在基線模型基礎(chǔ)上通過用1×1卷積核改變通道數(shù),進(jìn)行卷積層代替全連接層及數(shù)據(jù)標(biāo)準(zhǔn)化處理。設(shè)置輸出通道數(shù)為日志模板類別,卷積后每一維度的值可以理解為每個(gè)類別生成的一個(gè)特征值,向量中最大的特征值所在維度即為預(yù)測的日志模板編號。采用1×1卷積核用到的參數(shù)量為:1×embedding×k,和全連接層相比,當(dāng)序列長度時(shí)間很長時(shí),有效降低參數(shù)量。這種通過強(qiáng)制特征值和類別之間的對應(yīng),是對卷積結(jié)構(gòu)更原始的反映。
為比較自適應(yīng)池化層和1×1卷積核在檢測模型上的準(zhǔn)確率和收斂速度,取序列長度h=100時(shí),分別對改進(jìn)的TCN + AAP和改進(jìn)的TCN + 1×1卷積核以及改進(jìn)的TCN + Linear進(jìn)行50輪實(shí)驗(yàn),從圖7可以看出,采用自適應(yīng)均值池化層,在epoch=10之前,檢測準(zhǔn)確度振蕩上升,之后準(zhǔn)確度相對穩(wěn)定,在epoch=33時(shí),達(dá)到最大的準(zhǔn)確率0.925 35;采用Linear全連接層,在epoch=4時(shí),達(dá)到89.319%的準(zhǔn)確率,在epoch=20時(shí),可以達(dá)到最大的準(zhǔn)確率0.900 44,采用1×1卷積核,在epoch=12之前,檢測準(zhǔn)確度振蕩快速上升,之后有個(gè)相對穩(wěn)定的準(zhǔn)確度,在epoch=37時(shí),達(dá)到最大的準(zhǔn)確率0.870 96。可以看出,采用自適應(yīng)均值池化和1×1卷積核2種方案收斂速度相當(dāng),但采用自適應(yīng)均值池化的準(zhǔn)確率明顯高于采用1×1卷積核。采用Linear全連接層,收斂速度較快,但準(zhǔn)確率不及采用自適應(yīng)均值池化。自適應(yīng)均值池化層既不含訓(xùn)練參數(shù),又達(dá)到了比使用Linear全連接層和1×1卷積核更高的準(zhǔn)確率。
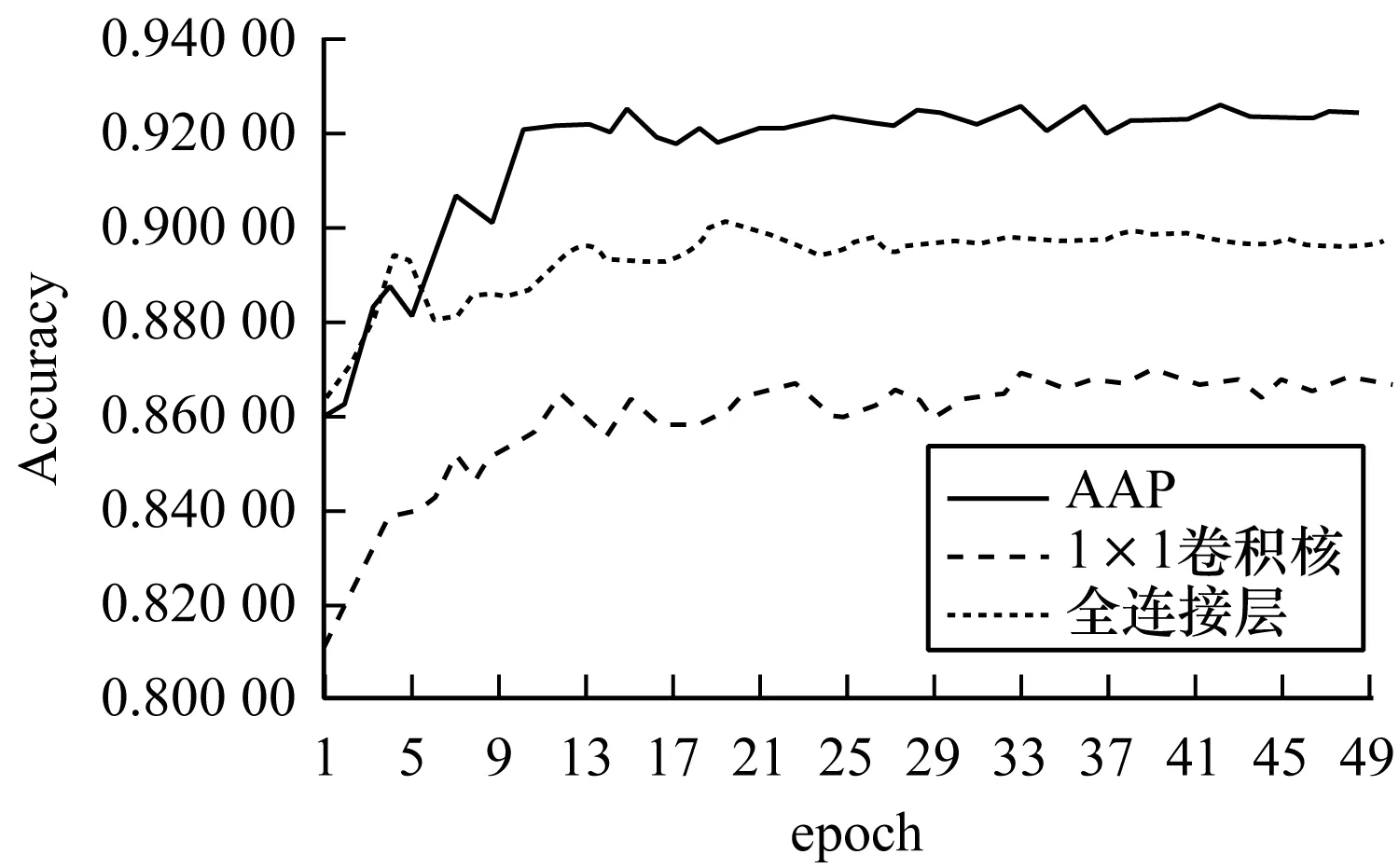
圖7 最后一層對準(zhǔn)確率和收斂速度的影響Fig.7 Effect of last layer on accuracy and convergence speed
4 結(jié)束語
日志中蘊(yùn)含了豐富的網(wǎng)絡(luò)和系統(tǒng)信息,通過分析日志可以檢測異常行為和挖掘潛在安全威脅。現(xiàn)有基于循環(huán)神經(jīng)網(wǎng)絡(luò)的日志序列異常檢測模型對較短序列有很好的檢測能力,但對長序列的檢測存在不足,針對時(shí)間卷積網(wǎng)絡(luò)中的激活函數(shù)ReLU容易引起神經(jīng)元“壞死”,以及無法學(xué)習(xí)到日志序列中更多有效特征的特點(diǎn),本文提出用帶參數(shù)的ReLU替換ReLU。針對全連接層因參數(shù)量較多,容易引起過擬合的問題,提出用不需要參數(shù)量的自適應(yīng)平均池化層替換全連接層,準(zhǔn)確率提高5.886%。實(shí)驗(yàn)結(jié)果表明,該檢測框架用于日志序列異常檢測的總體準(zhǔn)確率優(yōu)于TCN+Linear等方法,且自適應(yīng)池化層不需要參數(shù)量。下一步將研究異常檢測關(guān)鍵技術(shù),進(jìn)行異常定位并分析異常原因。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
