基于改進SLIC的光照干擾下茶樹冠層圖像分割
2020-09-10 04:01:06劉連忠李孟杰寧井銘
江蘇農業學報 2020年4期
劉連忠, 李孟杰, 寧井銘
(1.安徽農業大學信息與計算機學院,安徽 合肥 230036; 2.茶樹生物學與資源利用國家重點實驗室,安徽 合肥 230036)
近年來,人工智能以其非線性、自學習、適用性強的優勢,在多個領域得到廣泛應用。機器視覺作為其關鍵技術之一,也得到了極大的發展,目前已較為廣泛地應用于農業研究[1-4]。機器視覺在農作物生長信息監測方面的應用,推動了農業信息化、智能化、精細化進程[5]。Revathi等[6]利用移動設備采集棉花葉斑病圖像,使用基于邊緣檢測的圖像分割得到病斑部分,并提出棉花病害檢測的同類像素計數技術(Homogeneous pixel counting technique for cotton diseases detection, HPCCDD)對分割出的病斑部分進行分類。Silva等[7]使用人工視覺系統(Artificial visual system, AVS)提取玉米葉片圖像的缺陷特征,診斷出玉米葉片中鎂的濃度。張玨等[8]利用數碼相機獲取甜菜冠層數字圖像,基于灰度值的閾值分割方法提取冠層圖像的R、G、B值,交互調優R、G、B單色分量權重,提出三原色權值調優方法,用調優參數BOP(Basic optimal parameter)、NOP(normalized optimal parameter)建立的甜菜氮素營養監測模型預測精度均高于用常規參數G/R、紅光標準值 (NRI)建立的模型。
獲得穩定的圖像特征參數是使用機器視覺的前提條件。然而,自然條件下太陽光照變化復雜,會在作物圖像上產生反光、陰影等干擾因素,導致難以獲取穩定的圖像特征。為了避免光照干擾對結果的影響,目前大多數農業圖像方面的研究刻意選擇在無陽光直射時采集圖像,或通過對圖像進行色彩調整來模擬光照變化。吳雪梅等[9]基于圖像的顏色信息進行茶葉嫩葉識別時,為避免光照的干擾,選擇在無陽光直射的時間采集圖像。孫肖肖等[10]基于深度學習算法識別茶樹嫩芽時,為了更好地增強模型對不同光照的適應能力,對采集的茶葉圖像進行了改變光照亮度操作。前者的研究結果具有極大的局限性,無法應用到實際生產中;后者的方法無法對真實光照情況進行建模仿真,難免在實際應用時出現不確定的結果。
傳統的閾值分割、聚類分割等分割方法雖然能進行像素級別的精準分割,但均存在一定缺陷[11]。閾值分割法通過設定不同的特征閾值把圖像像素點分為若干類,一方面需要人為設定閾值,該閾值需要根據光照度的不同進行調整以獲得最佳分割效果;另一方面,閾值分割的效果對閾值非常敏感,閾值的變化會直接影響圖像特征參數的數值。聚類分割法通過特定算法把具有相似特征的數據點聚類或分組到一起,它不需要根據圖像設定閾值,但容易出現過分割現象,分割后的圖像往往變得無法觀察,且會丟失圖像細節信息。自然環境下農業圖像極容易受光照、遮擋、背景等因素的影響,傳統分割方法在此環境下魯棒性較差[12-13]。
本研究提出一種能在光照干擾情況下進行圖像分割,獲取穩定圖像特征參數的方法。以茶樹冠層圖像為研究對象,首先對圖像使用改進的超像素分割方法獲取超像素塊,接著使用支持向量機(Support vector machine,SVM)分類器將超像素塊分為3類區域(背景、正常區域、反光區域),進而分割出不含反光區域和背景的正常區域,然后提取正常區域的圖像特征參數,最后對特征參數的穩定性進行分析。
1 材料與方法
1.1 試驗對象
試驗地位于安徽省合肥市高新技術農業園,以園內種植的農抗早茶樹品種為研究對象。茶園環境如圖1所示。

圖1 茶園環境Fig.1 The environment of the tea plantation
1.2 改進SLIC的超像素分割
超像素是指圖像中局部的、具有一致性的、能夠保持一定圖像局部結構特征的子區域。超像素分割就是將像素聚合成超像素的處理過程[14]。目前使用較多且效果較好的方法是簡單線性迭代聚類(Simple linear iterative clustering, SLIC)的超像素算法[15]。該算法基于顏色相似度和空間距離關系進行迭代,將圖像像素進行聚類。
SLIC分割不涉及具體的分割對象,對于農業圖像而言,需要綜合考慮作物圖像的空間分布特點。圖2為光照干擾下的茶樹局部圖像及其像素點(1/8稀疏化)L*、a*、b*與R、G、B值分布圖。農業圖像大多以綠色為主,枯葉、土壤等與綠葉顏色差異較大,較容易分割,而本研究主要目的是消除光照影響,故將與亮度相關的L通道信息保留。從圖2中可看出,無論是哪個區域,a和b值都較穩定,變化很小,對聚類的貢獻度低,所以舍去a和b通道值;R和G值在不同區域變化范圍較B值大,所以可將R和G通道值替代a、b通道值。G值變化范圍雖然大,但在0.6以下的值區分度不高。考慮到農業圖像受光照影響后會產生光斑及陰影區域,與正常區域有明顯邊界,另外,農作物葉片、花瓣、果實等也有較為顯著的邊界,所以將圖像的Sobel邊緣信息添加到G通道上,構成G-S通道。
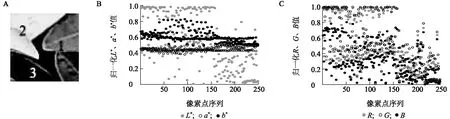
A為光照干擾下的茶樹局部圖像(1為正常區域,2為反光區域,3為背景區域),B和C分別為圖a的像素點(1/8稀疏化)L*、a*、b*與R、G、B值分布圖。圖2 光照干擾下的茶樹局部圖像及其顏色特征值分布Fig.2 Local image of tea plant under light interference and its distribution of color characteristic values
綜上所述,本研究針對作物圖像的特點提出一種改進SLIC的超像素分割方法,通過重新定義聚類向量,將傳統SLIC的聚類向量[L*,a*,b*,x,y]改為[L*,R,G-S,x,y],使其更適用于作物圖像的超像素分割。
1.3 茶樹冠層圖像分割
SVM是Vladimir[16]根據神經網絡思想提出的一種新的學習方法。它基于統計學中的VC維(Vapnik-Chervonenkis Dimension)理論和結構風險最小化理論,通過核函數將輸入空間映射到高維的特征空間,然后在高維空間中尋找最優解。它可以根據有限的樣本信息,在模型的復雜性和學習能力之間尋求最佳折衷,在解決小樣本、非線性、高維數和局部極小點等問題上有著獨特的優勢[17]。SVM普遍應用于分類及回歸問題。為克服光照和背景對茶樹冠層圖像特征的影響,將像素塊分為正常區域、背景區域及反光區域3類,提取每個像素塊的13個圖像特征參數(R、G、B、H、S、V、L*、a*、b*、熵、能量、對比度、逆差矩)組成向量,通過SVM對所有超像素塊進行分類。分類輸出的正常區域即為消除光照和背景干擾的茶樹冠層圖像。
2 結果與分析
2.1 SLIC及其改進算法分割結果對比
分別用原始SLIC算法、本研究改進SLIC算法以及其他改進算法SLICO(SLIC零參版)[18]、MSLIC (Manifold SLIC)[19]對茶樹冠層進行超像素分割,分割結果的細節部分對比如圖3所示。該細節部分選自像素塊為400左右的分割結果中,初始圖像大小為639像素×490像素。從圖3中可看出,改進SLIC與原始SLIC的分割效果相近,但改進SLIC對亮斑的分割更精確,而MSLIC、SLICO的分割效果均不理想。
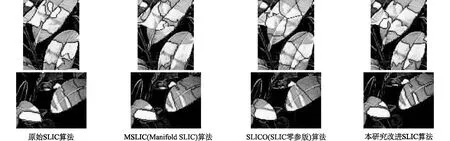
圖3 原始SLIC算法及其3種改進算法分割結果對比Fig.3 Comparison of segmentation results obtained by SLIC and its improved algorithms
2.2 超像素分割性能評價
根據校正欠分割錯誤率(CUE)、邊緣召回率(BR)、可達分割精度(ASA)和算法耗時幾個評價指標[20]對超像素分割結果進行對比(圖4)。試驗在i7-6700CPU@3.40Hz、8G內存、Windows7環境下進行。由于超像素塊是根據圖像內容進行迭代產生的,無法準確控制其最終數量,故實際像素塊數目與整百數的誤差在±10以內。
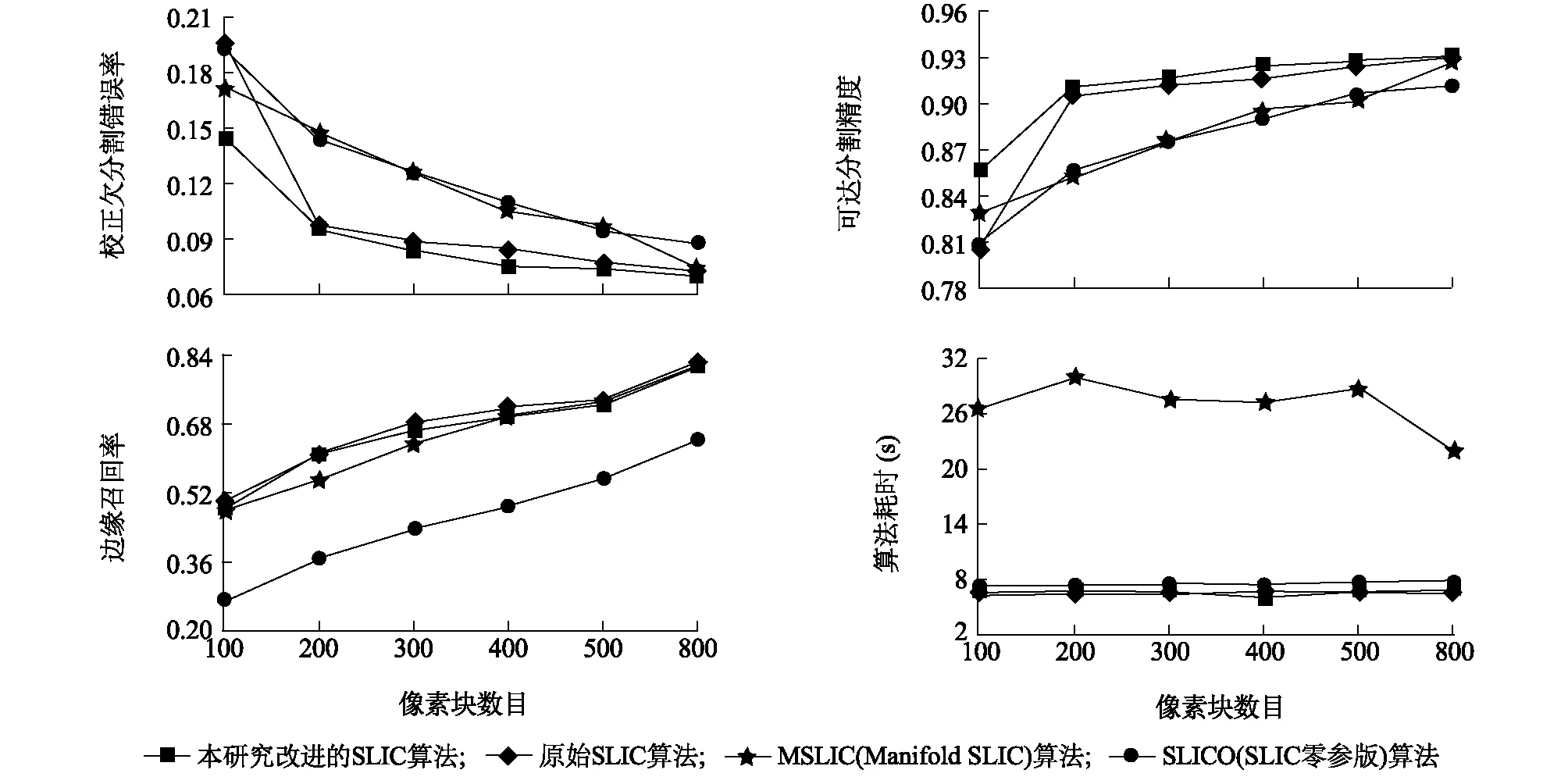
圖4 4種超像素分割算法的性能評價指標對比圖Fig.4 Indices for performance evaluation of four superpixel segmentation algorithms
從圖4的4個評價指標折線圖中可以看出,改進后的SLIC算法的CUE與ASA表現最好,其次為原始SLIC算法。在BR的表現上,改進后的SLIC算法、原始SLIC算法與MSLIC算法的表現相近,均好于SLICO算法。而在時間消耗上,相同迭代次數下,MSLIC算法需要計算7維向量的距離,消耗的時間是其余3個算法的3~4倍,故改進SLIC算法在茶樹冠層圖像的分割效果上表現出一定優勢。由于受初始圖像大小的限制,繼續增加最終像素塊數目所得到的分割效果提升并不明顯,且像素塊數目越多則像素塊越小,不利于后續像素塊的分類及特征信息提取,故試驗確定超像素分割的像素塊數量為800。
2.3 不同核函數的SVM模型在超像素塊分類上的對比
選取8張有不同光照度、4張無明顯光照的茶樹冠層圖像(圖像大小為639像素×490像素),每張圖像均使用超像素分割法分割為近800個像素塊,從中選擇特征明顯的8 870個像素塊作為分類模型的訓練樣本。測試集為4張有不同光照度、2張無明顯光照的茶樹冠層圖像,每張圖像同樣使用超像素分割法分割為近800像素塊,選取4 788個像素塊。提取每個像素塊的9種顏色特征參數和4種紋理參數組成向量,使用LIBSVM進行訓練。SVM的類型為C-SVC,分別選擇線性、多項式和徑向基(Radial basis function, RBF)核函數進行對比。
根據尋找的最優參數(懲罰系數與伽馬參數)對訓練集進行訓練,得到SVM分類模型,然后使用驗證集數據對模型進行檢驗。結果(表1)表明,線性核函數模型在2個數據集上準確率均最低。多項式核函數模型雖在訓練集上略高于RBF核函數模型,但在驗證集上的準確率不及RBF核函數模型,綜合考慮后,選擇RBF核函數的SVM模型(RBF-SVM)作為超像素塊分類模型。
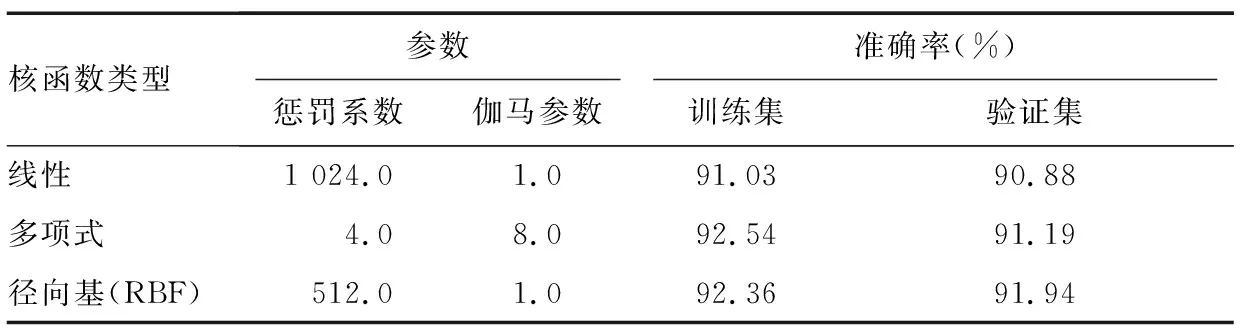
表1 不同核函數的SVM模型準確性檢驗
2.4 基于改進SLIC+SVM的圖像分割結果
首先使用改進SLIC算法將茶樹冠層圖像分割為近800個像素塊,然后分別提取每個像素塊的13個圖像特征(R、G、B、H、S、V、L*、a*、b*、熵、能量、對比度、逆差矩),使用訓練好的RBF-SVM模型對像素塊進行分類,標注出正常區域、背景區域及反光區域的像素塊,進而得到消除光照影響的茶樹冠層圖像(圖5)。
2.5 改進SLIC算法的有效性
為驗證分割方法的有效性,對分割前、后的圖像特征參數的穩定性進行分析。在茶園隨機選擇1個監測點,獲取該監測點某個晴天上午7∶00至下午5∶00期間的10張圖像(每隔1 h獲取1張)。以下午5∶00無光照干擾的圖像為基準圖像,計算13個特征參數的最大偏差、標準差、平均相對誤差,比較使用改進SLIC算法分割后的圖像與原始圖像的特征參數的穩定性。從表2可以看出,除參數B、H、S和b*外,經改進SLIC+SVM算法分割后的圖像特征參數與基準圖像特征參數的最大偏差、標準差、平均相對誤差均較未經處理的原始圖像特征參數與基準圖像特征參數的小,表現更為穩定,驗證了本分割方法的有效性。

圖5 基于改進SLIC+SVM的圖像分割結果Fig.5 Results of image segmentation based on improved SLIC+SVM

表2 特征參數穩定性評價
3 結 論
針對自然環境下光照干擾作物成像的問題,提出了一種基于改進SLIC+SVM的分割方法。該方法首先使用改進SLIC算法對原始圖像進行超像素分割,再對超像素塊進行SVM分類,最終分割出不含背景及反光區域的作物圖像,在光照干擾情況下所提取的圖像特征參數比原始圖像具有更好的穩定性。下一步將對其他作物圖像進行試驗,檢驗此方法的適用性。本研究結果為自然環境下提取穩定的作物圖像特征提供了一種思路,使機器視覺技術能夠更好地應用到農業生產實際中。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
核科學與工程(2015年4期)2015-09-26 11:59:03
電測與儀表(2015年5期)2015-04-09 11:30:52
