解決ICRA RoboMaster AI 挑戰與深度學習的研究
2020-09-29 06:54:40陳明陽茆意風
科學技術創新 2020年29期
陳明陽 劉 博 茆意風
(美國賓夕法尼亞大學,美國 賓夕法尼亞州19019)
1 概述
本文采用一個通用的強化學習算法,并通過自我發揮和學習,不斷優化算法,研究在AlphaGo 中應用的自我游戲策略和AlphaZero 的變化。由于AlphaZero 不會增加訓練數據,也不會在MCTS 期間變換板的位置。因此,使用蒙特卡羅樹搜索代替beta搜索,采用通過改變其他對稱方面來訓練非對稱情況下的策略,研究這種方法,找到一種通用的自我游戲強化學習方法。
本文主要是將深度強化學習應用于街機學習環境中訓練7款Atari 游戲,該方法采用Q 函數的神經網絡訓練模型,模型的輸入為像素,輸出為評估未來回報的價值函數。本文的關鍵點是Actor-Critic 算法,它是提出并分析一類基于隨機平穩策略的馬爾可夫決策過程優化的算法,也是兩個時間尺度的算法,其中,Critic 使用具有線性近似結構的時域學習,并且基于Critic提供的信息,在近似梯度方向上更新Actor。通過研究表明,Critic 的特征應該跨越由Actor 的選擇所規定的子空間,提出收斂性和有待解決的問題。
2 虛擬機器人環境——PyGame
2.1 設置虛擬機器人環境——PyGame
PyGame 是一個基于python 的虛擬格斗游戲環境,在此過程中接收來自鍵盤和鼠標的輸入,一組應用編程接口和預定義的類降低了虛擬環境創建的難度。ICRA 挑戰賽的真實環境為8 米*5 米的場地,兩個機器人的出場地位于左上角和右下角,補充場地位于黃色十字區域。機器人在補給區被修復,當它們站在補給區時,它們的生命值會持續上升,ICRA 的真實現場環境如圖1 所示。
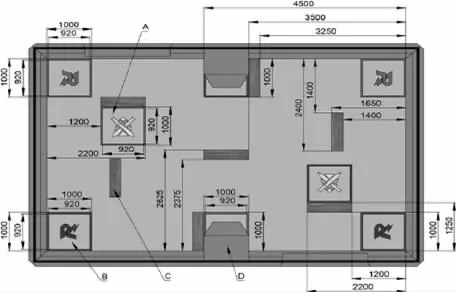
圖1 ICRA 的真實現場環境
在圖1 中,機器人無法通過的障礙物被顯示為深灰色矩形。通過研究決定,采用重新創建ICRA AI 挑戰賽的新戰斗環境,如圖2 所示,其中,障礙物和補給區域與原來的位置相同。為了增加決策的復雜性,增設彈藥重裝區,圖中的彈藥重裝區域顯示為綠色區域,機器人可以在此區域進行重新裝彈,以避免子彈耗盡。
獎勵規則設置如下:在所有迭代開始時,獎勵被初始化為零。如果敵人被擊中,那么射手的獎勵將增加10 點,而敵人將減少20 點。如果敵人被摧毀,獎勵會激增到100 點,如果玩家被摧毀,獎勵本身會下降到200 點。彈藥和生命點不會影響獎勵,而生存時間將以對數形式加入獎勵。
2.2 優化深度學習的算法
實現的深度Q 學習是基于Pytorch 的卷積神經網絡。網絡的輸入是模型訓練過程中PyGame 環境的一個截圖,輸出是給定輸入環境下的一個預測動作。該動作包括四個方向的移動(上、下、左、打),兩個槍操作方向(順時針、逆時針)和射擊。該神經網絡為三層卷積神經網絡,具有不同大小的核和漏項。激活層被分配給非線性ReLU 層,我們選擇時間差異誤差作為損失函數,兩者具有相同的損失函數。把具有相同的最佳點作為傳統的Q-learning 函數。下面列出了這個損失函數的梯度下降:
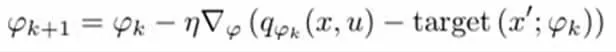
因此,Q-learning 的目標函數為:
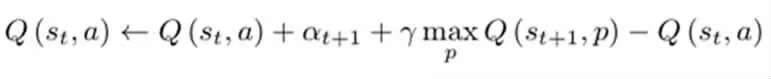
本模型的目標是利用神經網絡的非線性特性來模擬這個函數,該模型產生Q-learning 函數的估計,而TD 誤差在Q-learning 中找到相同的最優值。
2.3 Actor-critic 模型設計
實現角色評論設模型設定在pytorch 中完成,模型的輸入是抽象的狀態元組,狀態元組代表在某一時刻坦克的狀態,包括:坦克中的位置、速度、運行狀況和子彈數量等。Critic 模型采用價值函數進行估計,其中,選擇Q 值作為估計的目標值。而Actor模型是決策制定的,該模型按照Critic 建議的方向更新政策分配,其中,Critic 函數和Actor 函數都屬于神經網絡模擬。
2.4 多人戰斗模型設計
上述模型設計是在單人游戲環境中實現的,通過計算機自動控制敵人,電腦玩家可以忽略障礙物的封鎖,并且擁有無限數量的彈藥。優化后的虛擬環境中可以實現2 人戰斗,兩個玩家在后端由兩個獨立的模型控制,通過重新部署AlphaGo 戰略,試圖找出讓機器人從零開始學習規則的策略。
3 仿真結果
3.1 DQN 模型結果
通過采用DQN 模型仿真結果對比,DQN 的訓練效果明顯優于Actor-Critic 的訓練效果,并且convolutional neural network在決策過程中更能有效的找到合適的動作,這是因為圖像的復雜性使得模型更容易判斷游戲情況,優化后的圖像包含許多有用信息,如封鎖區域和不同的供電區域位置。然而,有時這種模式會以錯誤的方式表現,比如向空中射擊和在進入近距離戰斗前浪費彈藥,采用的DQN 模型獎勵功能如圖3 所示。
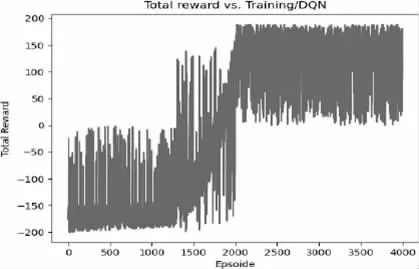
圖3 DQN 模型獎勵功能圖
3.2 Actor-Critic 結果
由于選擇有限維數的狀態元組,模型只能感知坦克的當前狀態,而無法告訴模型上電區域和障礙物的位置。此外,這種方法的訓練難度大于前一種方法,這意味著訓練時間較短,可能會導致模型無法收斂到更大的期望回報。從圖4 中可以看出,該模型在提高獎勵期望方面并不有效。
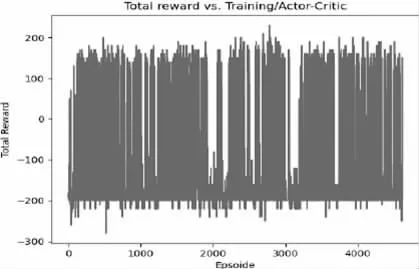
圖4 演員評論模型獎勵功能圖
3.3 多人戰斗模型結果
從獎勵情節中可以看到,有時玩家能夠找到消滅敵人的策略,而有時兩名玩家在空白區域徘徊。這是因為訓練時間有限,這導致模型無法探索虛擬環境中的所有可能性,圖5 和圖6 列出了兩個玩家的獎勵結果。
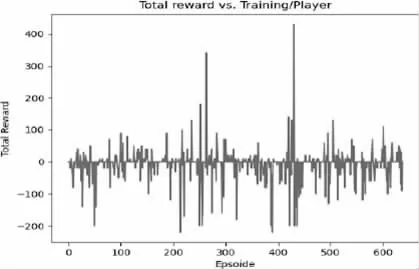
圖5 Player1 獎勵功能情節
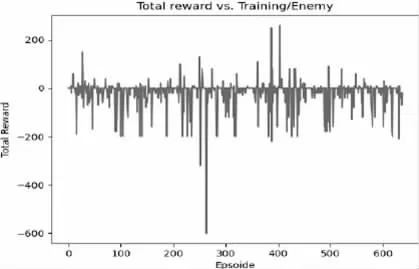
圖6 Player2 獎勵功能情節
4 結論
在后續的工作中,需要更多的時間和更先進的設備來完善本模型,pygame 環境每次都需要截屏,這會浪費大量的計算資源,因此以后選擇更加簡練的環境,以此來提高效率。未來,可以通過調整該模型的神經網絡和學習策略來實施進一步優化。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2020年6期)2020-02-01 06:28:50
中國生殖健康(2019年11期)2019-01-07 01:28:02
光學精密工程(2016年6期)2016-11-07 09:07:19
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
