基于稀疏子空間的局部異常值檢測算法
2020-10-10 01:00:20覃鳳婷楊有龍仇海全
計算機工程與應用 2020年19期
覃鳳婷,楊有龍,仇海全,2
1.西安電子科技大學 數學與統計學院,西安710126
2.安徽科技學院 信息與網絡工程學院,安徽 鳳陽233100
1 引言
隨著信息科學技術的發展,越來越多的數據被收集和儲存在數據庫中。從海量的數據中挖掘一些新穎的、潛在有用的、最終可理解的知識是非常有意義的。大部分研究的重點是構造一個對大多數數據(正常值)的通用模式映射,然而,從知識發現的角度來看,異常數據通常比正常的更有趣,因為它們包含異常行為背后的有用信息。因此,異常值檢測漸漸引起廣大研究者的關注,成為數據挖掘領域的重要組成部分。其主要任務是識別出與大多數據明顯不同的數據。異常值檢測(也稱離群點檢測)往往在網絡入侵檢測[1-2]、電話和信用卡欺詐檢測[3]、醫療診斷[4]等方面有著重要的研究價值。例如,在醫療診斷中,誤診的情況遠遠少于確診的情況,但是誤診付出的代價往往比確診要高很多。
現有的異常值檢測方法大部分側重于從全局角度識別異常值,但是隨著數據量和維度的爆炸性增長,全局異常值的挖掘變得很難實現。為了克服這個困難,局部異常值檢測技術逐漸引起研究者的重視。文獻[5]最早提出了局部異常值概念,該方法依據對象與其k 近鄰的差異定義對象的異常度,高于給定閾值的數據對象即為異常值,但該方法并不適用于大規模高維數據集。因為高維數據集中存在部分不相關的屬性,導致一些異常值在全維空間中可能無法檢測出來。而且這種不相關的維度會影響異常值檢測的效率,同時會減小異常值挖掘的準確性。換言之,如果數據點的異常度是從全維空間中得到的,則大多數現有的異常值檢測算法的效率會非常的低。
在高維數據集中,異常值通常包含在一些由部分維度構成低維子空間中,并且不同的異常對象可能存在于由不同的部分屬性張成的不同子空間中[6],因此,如何找到包含局部異常值的子空間是高維異常值挖掘的一個非常關鍵的問題。另外,在全維空間中一般無法體現異常數據與其他正常數據的偏差,這些偏差往往嵌入在一些低維的子空間中。即,局部異常值可以投影到低維的子空間中,因此目標可轉為搜索有利于表征異常值的子空間。但是,數據集中的維度和數據對象的指數型增長使得異常子空間檢測成為一個NP 難問題[7]。直接使用窮舉搜索一一列舉顯然是不可行的。
為克服高維數據異常值檢測的缺點,本文提出了一種基于稀疏子空間的局部異常值檢測技術(Sparse Subspace-based method for Local Outliers Detection,SSLOD)。該方法首先在每個維度上分析每個對象的局部異常程度,據此刪減高維數據集中與異常值不相關的維度以及冗余的數據,對初始的數據集進行一個初步的約簡。然后,給出了滿足稀疏子空間的判斷標準。最后,利用改進的粒子群優化算法在約簡屬性和對象后的子空間中搜索稀疏子空間,從而挖掘出異常值。實驗結果表明,SSLOD算法具有良好的性能。
2 相關工作
在數據集中,異常值往往是與大多數對象表現相對不一致的數據對象,以至于懷疑它是由其他機制產生的。現存的異常值檢測方法可分為以下幾個類[8-9]:基于分布的、基于距離的、基于聚類的、基于密度的、基于角度的、基于子空間的。
基于分布的方法源自統計,它基于一些標準分布模型(正態、泊松等),如果一個數據點偏離標準分布的程度太大,則該數據點被認為是異常值[10]。例如,在正態分布中,異常值與數據期望的距離大于方差的3 倍[11]。但是在現實世界中,數據的分布函數的情況通常是未知的,尤其是對于高維數據集。由于在實際應用中,數據并不能保證服從某一標準分布,從而無法從數據中找出異常值。
基于距離的方法不需要假設任何數據的分布情況,其基本思想是利用已有的距離度量方法(如曼哈頓距離、歐幾里得距離等)計算所有數據點之間的距離,根據距離關系識別異常值。文獻[12]將異常值定義為:當某個數據點與數據集中p%的數據點的距離超過d 時,該數據點被認為是異常值。該方法的難點是參數p 和d對異常值檢測結果影響大,且不易找到合適的值。同時,對于高維數據集在計算距離之前首先需要降維。
基于聚類的異常值檢測方法是由聚類算法優化而來的[13]。在基于聚類的方法中,常見的異常值定義有兩種。一種是將聚類后的較小的簇視為異常值,但是不能判斷單獨的點是否是異常值;另一種是聚類后將不屬于任何簇的數據點視為異常值,但是聚類結果很影響異常值檢測的結果。
基于密度的方法的基本思想是通過數據點的局部密度檢測異常值,局部密度較低的數據點是異常值的可能性大。此類方法將異常值定義為局部密度與其鄰域內的其他點明顯不同的數據點,換句話說就是正常點的局部密度與其鄰域點的密度非常相似。最早的基于局部密度的異常值檢測方法是LOF(Local Outlier Factor)[5],該方法根據局部鄰域密度為每個數據點分配一個局部異常因子LOF,LOF值高的數據點視為異常值。隨后又出現了LOF模型的幾個擴展,例如,基于連接的異常值算法(Connection-based Outliers Factor,COF)[14]、不確定的局部離群因子(Uncertain Local Outlier Factor,ULOF)[15]、核密度估計異常分數(Kernel Density Estimates,Outiler Score,KDEOS)[16]、基于排序差的異常值檢測(Rank-difference based Outlier Detection,ROD)[17]、基于局部相對核密度的異常值檢測(Relative Density-based Outlier Score,RDOS)[18]等。這些方法在一定程度上提高了異常值檢測能力,但是,在測試階段的時間復雜度偏高。
基于角度的方法一般用于檢測高維數據集中的異常值。因為高維數據集一般分布在一個超球體的表面,此時歐式距離將隨著維度的增加漸漸失效。基于角度的異常值檢測方法將對象與其k 個近鄰兩兩之間的夾角的方差作為判斷異常值的準則[19]。方差越小越說明該對象分布在整體數據的邊緣,越有可能是異常值。但是該方法無法將被幾個簇包圍的局部異常值檢測出來。另外,由于每次都需要計算對象與其近鄰兩兩之間的夾角,因此算法的復雜度非常高,導致算法的效率較低。
基于子空間的方法被設計為通過搜索子空間來檢測異常值。由于高維空間中的數據對象是稀疏的,異常值是根據部分維度而不是整個空間來確定的。因此一般是將數據集映射到子空間,在子空間中搜索異常數據。根據子空間的度量方法不同,基于子空間的異常值檢測方法又可以分為兩類:相關子空間投影方法和稀疏子空間投影方法。
相關子空間投影方法是在數據集中選出對異常值有意義的屬性構建子空間來進行異常值檢測,投影方法一般有兩種:基于線性相關的[20]和基于統計模型的[21]。前者使用局部參考集之間的線性相關性創建子空間,而后者通過在局部參考集上應用統計模型構建子空間。例如,文獻[19]提出了一種在高維空間的軸平行子空間中檢測異常值的方法,該方法主要是在子空間中描述數據對象的異常度。文獻[22]用統計方法選擇相關子空間,然后在該子空間中根據數據的偏差程度確定了異常值排名算法,數據集中每個對象均對應一個相關子空間。文獻[21]提出了一種子空間搜索方法來建立高對比度子空間,確定了基于密度的異常值排序。
稀疏子空間由密度明顯低于平均值的數據點構成的,密度可以根據稀疏系數來測量。根據稀疏系數閾值,可以將高維數據集投影到稀疏子空間中,該稀疏子空間的點可設想為異常值。文獻[23]提出了一種高維異常值檢測算法,其主要思想是將高維數據投影到低維子空間,利用遺傳算法來確定異常值。該算法雖然提高了異常值檢測的效率,但是異常值的完整性和準確性并不能得到保證。為了解決這個問題,文獻[24]利用異常值的概念和改進的遺傳算法搜索子空間。文獻[25]利用網格概念來表示子空間,并研究了一種通過引入密度系數來提取稀疏子空間的方法,該方法提高了異常值檢測的準確性和完整性,但是由于構造概念格的復雜性導致其檢測效率較低。文獻[26]為提出了一種基于屬性相關性的局部異常值檢測算法,該算法不同于上面方法的是使用粒子群算法搜索子空間,大大提高了異常數據的挖掘效率。
3 約簡數據集
在高維數據集中實現異常值檢測的高精度和高效率是一個挑戰。本章提出了一種新的數據集約簡方法,其作用是進行異常值檢測算法之前減少數據對象和維數。該方法通過每個維度上分析數據對象的異常度,將與異常值無關的維度與異常值相關的維度分來,將與異常值無關的冗余數據識別出來。
假設D 是N×d 維的空間,A={A1,A2,…,Ad}表示屬性集,X={X1,X2,…,XN}表示N 個數據點,其中Xi={xi1,xi2,…,xid}。對象Xi在屬性Aj上所對應的值表示為xij(i=1,2,…,N;j=1,2,…,d)。通過檢測每個維度上數據點的密度,識別與異常值不相關的屬性和數據對象。密度較大的數據點一般聚集在密集區域,而密集區域的數據點是由一些相似特征構成的,這些特征對于檢測異常值往往作用不大。因此,在每個維度上分析對象的密度可以更好地區分與異常值不相關的維度和相關的維度。這里利用對象在每個屬性上的k 最近鄰估計其在該屬性上的密度。
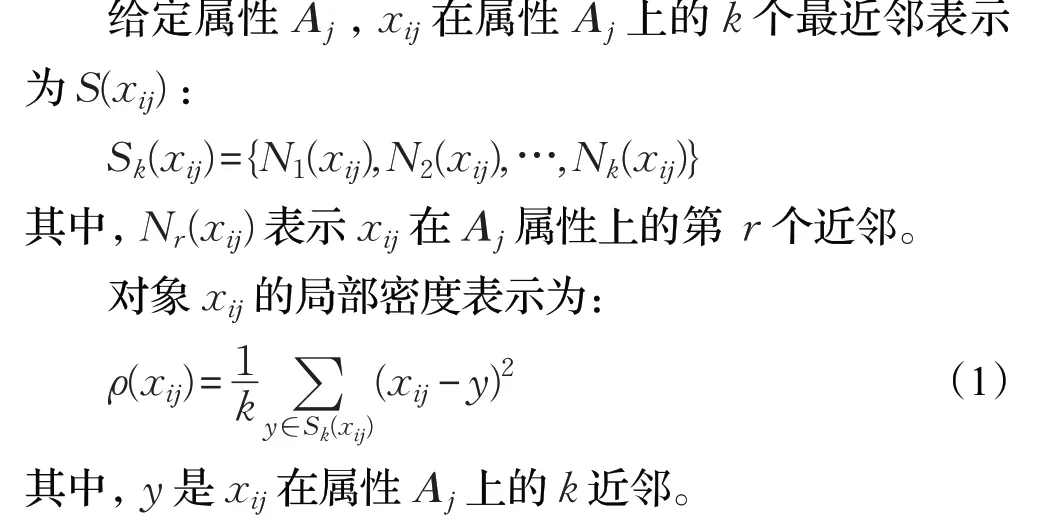
直觀上講,ρ(xij)的值越大,就意味著xij是在該維度上是正常值的可能性越大,因此其在密集區域的可能性就越大;反之,表示xij在該維度上是異常值的可能性越大,即其在稀疏區域的可能性較大。
由于密集區域往往由具有相似特征的數據點構成。為了找到密集的區域,用γij=1/ρ(xij)表示一維對象xij的異常因子。顯然,λij的值越大,xij在屬性Aj上越可能是異常的,說明xij越可能在稀疏區域,反之亦然。
接下來用K(N×d)表示原始數據集所對應的稀疏密度矩陣,Kij(i=1,2,…,N;j=1,2,…,d)表示矩陣K 中的元素。給定異常因子閾值 τ ,若 γij<τ ,將Kij設置為1,表示xij是在屬性Aj上是正常值,包含在密集區域;若 γij>τ ,將Kij設置為0,表示xij在屬性Aj上是異常值,在一個稀疏區域。在形成稀疏密度矩陣K 的過程中涉及到參數k 的選取問題。k 值表示在一維屬性上對象的近鄰數,取值較小時,異常因子γij幾乎沒有意義。顯而易見,k 值應該小于N(數據集中對象的數量)。參考其他屬性約簡方法PCKA[27],將k 值設置為。當然,在實際應用中,參數k 也可以由用戶根據相關領域的知識自行設定并且調優。
下面用一個簡單的例子說明生成稀疏密度矩陣的過程。表1 是由一個病例信息組成的數據集,包括7 個屬性和12個數據對象。屬性A1表示性別,0表示女性,1表示男性;屬性A2表示年齡;屬性A3和A4分別表示鼻塞程度和頭疼程度,其值范圍從0到5,表示癥狀從輕微到嚴重。屬性A5的值為0時表示喉嚨不痛,1時表示喉嚨痛;屬性A6代表患者的體溫;屬性A7的值從0 取到3,分別表示感冒程度是由輕微到嚴重。根據以上參數k 的取值方法,k=3,計算每一個屬性下的一維數據點的異常因子γij,設定異常因子閾值τ 的取值為0.7,進一步得到該數據集對應的稀疏密度矩陣,如表2所示。
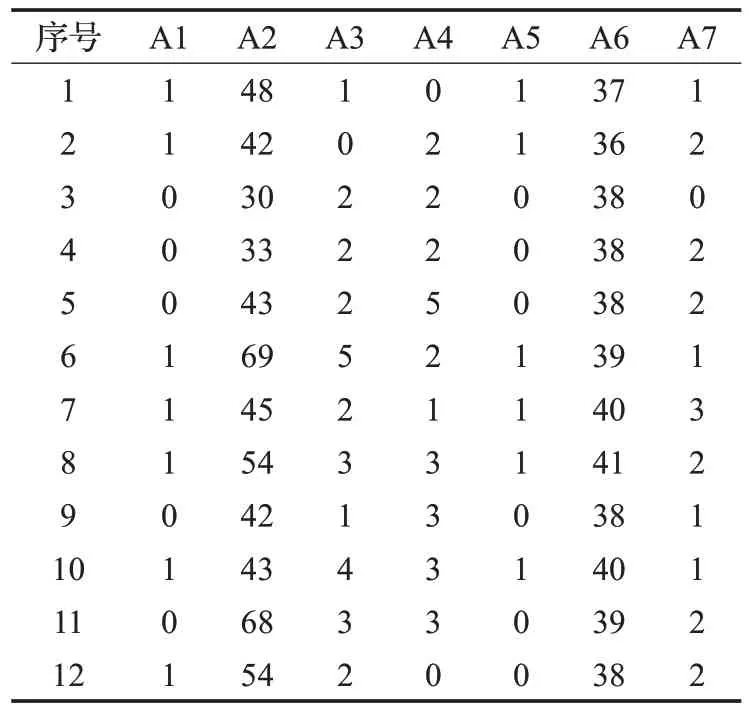
表1 病例信息數據
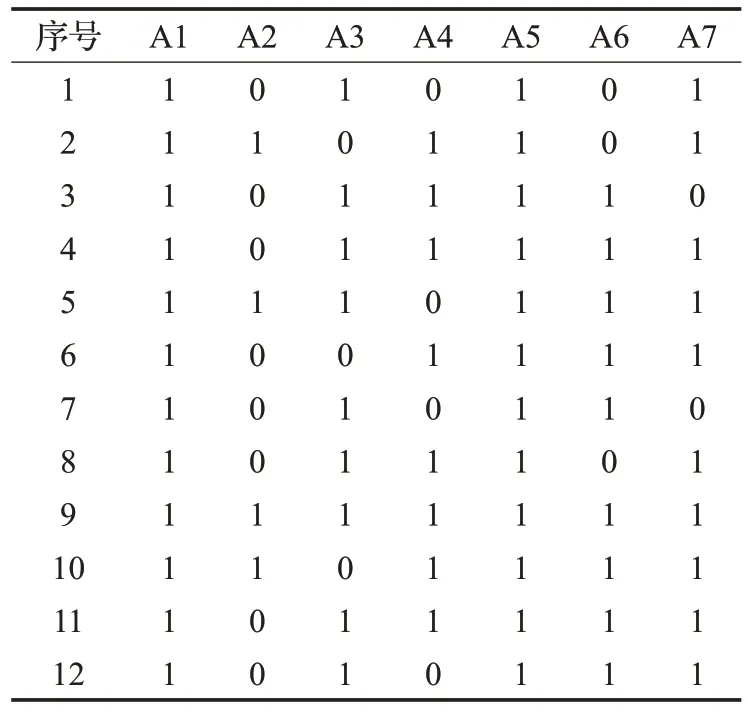
表2 病例信息數據的稀疏密度矩陣
在表2中,屬性A1和A5在稀疏密度矩陣中的值都是1,說明這兩個屬性上的對象均是正常值,處在一個相對密集的區域,這些屬性顯然對異常值檢測沒有作用,這表明了屬性A1和A5是與異常值不相關的屬性。因此,在檢測異常值之前,就可以先將這兩個屬性修剪掉。同理,第9 條數據在各個維度上的Kij值均為1,說明其在各個維度上均為正常值,為冗余數據,應修剪掉。當然,在不影響挖掘結果的正確性的前提下,對這些屬性和對象進行初步約簡可以顯著地提高異常值挖掘的效率,數據集初步約簡方法總結見算法1和算法2。
算法1稀疏密度矩陣的形成


4 基于初步約簡的稀疏子空間
4.1 稀疏子空間
局部異常值是在部分維空間中與其他數據點表現明顯不一致的數據對象。本文利用搜索數據空間中稀疏子空間的方法檢測局部異常值。稀疏子空間是指數據的密度明顯低于平均值的數據點構成的子空間,其中的數據對象即為異常值[23]。下面介紹稀疏子空間的相關知識。
給定一個N×d高維數據集D,將每個屬性上的數據劃分為φ個離散區間。這些離散區間是在等深的基礎上劃分的,因此每個區間上都包含g=1φ的對象。這里使用等深劃分而不是等頻劃分的原因是不同位置的數據可能具有不同的密度。在d維屬性上選擇t個屬性構成一個t維的數據集,記為D1。如果屬性在統計上是獨立的,根據伯努利概率,N個對象在t維屬性上隨機分布的概率是gt,對應的數學期望可以表示為N?gt,標準差是在選擇出的t個屬性上分別取一個區間,構成另一個t維數據集,記為D2。由于真實數據集在統計上并不一定是獨立的,因此t維數據集D2中對象的實際分布與原數據集D1的期望值存在著顯著地差異。那些低于平均值的異常偏差通常是由異常數據造成的,因此更有利于異常值檢測。
假設數據是均勻分布的,t維數據集D2中的對象總個數可以近似為正態分布。設n(D2)是t維數據集D2中對象的個數,為了度量子空間中數據的偏離程度,D2的稀疏系數[23]定義為:
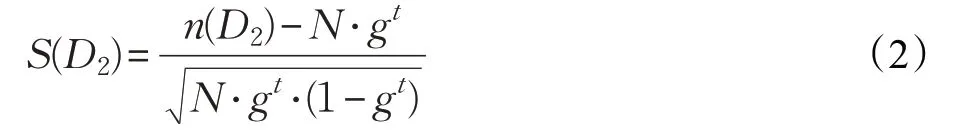
從(2)式中可以得到,若D2是稀疏子空間,那么D2中的數據點個數會小于平均值,n(D2)<N?gt。此時,S(D2)的值定是一個負數。然而,異常值往往分布在比較稀疏的區域,即包含在某個稀疏子空間中。
因此,稀疏子空間即為:當S(D2)小于某一個閾值θ(θ <0)時,D2就是一個稀疏子空間,其中的數據對象就是異常值,n(D2)即為異常值的個數。
要找到準確稀疏子空間的一個重要問題是如何選擇參數t和φ。在d維屬性中選擇t個屬性形成N×t的子空間,每個子空間含有期望數是N?(1/φ)t的數據對象。因此,當t很大時,N?(1/φ)t的值會很小,而稀疏因子閾值θ是一個負數,導致n(D2)很小,從而無法檢測出異常值。例如,若φ=10,t=5,t維子空間中數據對象的個數須大于105,否則數據對象的期望值將會比1小,即t維子空間中包含小于1 個點數據點,這意味著不可能找到有著高稀疏系數且至少包含一個數據點的稀疏子空間。因此,參數t和φ的值應該設置的足夠小,使得恰好包含一個數據點的子空間的稀疏系數是一個合理的負值。同時φ應該設置的夠大,使得每個維度上有足夠數量的區間對應一個合理的局部性概念。一旦給定了參數φ,參數t的范圍將由極端情況導出。假設t維子空間是一個空子空間,有n(D2)=0,計算該空子空間的稀疏系數,可得:

本文的算法均選取參數t的上界。對于參數θ的取值,θ=-3 是決定參數t的一個很好的參考值[23]。在具體應用中,用戶也可以根據實際情況設定不同的θ值,以確定適當的t值。
4.2 改進的粒子群算法搜索稀疏子空間
粒子群優化(Particle Swarm Optimization,PSO)算法一種基于群體的智能全局搜索優化算法[28]。由于概念簡單,參數少,收斂速度快,PSO算法漸漸被應用到各類算法中。本文將使用改進的粒子群算法搜索稀疏子空間。
4.2.1 標準粒子群算法
PSO算法首先初始化一群粒子,即優化問題的候選解。每個粒子都有一個位置向量和一個決定方向和步長的速度向量,并且都有一個由優化函數給出的適應值。然后粒子在解空間中跟隨最優的粒子進行搜索并且更新自身的位置和速度。同時粒子自身的最優位置(稱為Pbest)和整個種群的最優位置(稱為Gbest)也在算法的每次迭代中不斷地更新直到達到終止條件,最后得到的全局最優位置就是優化問題的最優解。粒子的速度和位置可表示為:

4.2.2 改進的粒子群算法
隨機慣性權重在PSO算法中,慣性權重控制粒子的歷史因素對其當前狀態的影響程度。為了平衡算法的全局搜索能力以及它的局部搜索能力,可以對慣性權重進行調整。在大多數改進的PSO 算法中,權重ω一般使用線性遞減的方法進行更新。這種更新方法在搜索算法的前期時,ω有利于取到全局搜索的最優值但是搜索效率比較低;在后期時ω雖然有利于加快算法的收斂速度,但是很容易導致算法陷入局部最優。
為了克服這個缺點,可以將慣性權重設置為隨機變量。慣性權重的隨機性可以使粒子在前期和后期都有可能取到較大或較小的權值,有利于算法跳出局部最優,同時可以提高算法的全局搜索能力。因此,提出以下慣性權重的公式:
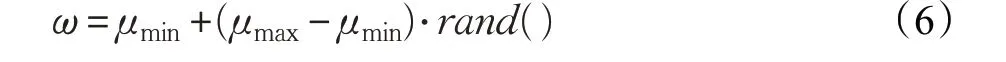
其中,μmin表示隨機慣性權重的最小值,μmax表示其最大值,rand( )是[0,1]之間的隨機數。μmin和μmax的初始值分別設定為0.5和0.95。
異步學習因子在PSO 中,若學習因子c1和c2在優化問題過程中有著不同的變化方式,那這兩個學習因子就是異步變化的。異步學習因子表示為:
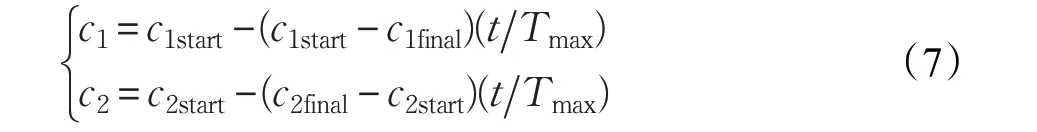
其中,c1start和c2start分別是c1和c2的初始值,c1final和c2final分別表示其迭代后的終值。t是當前迭代次數,Tmax是最大迭代次數。
若在前期階段取較大的c1和較小的c2,會使得粒子更多地向自身最優學習而較少地向全局最優學習,可以使粒子的全局搜索能力得到提升。在后期取較小的c1和較大的c2,會使得粒子更多地向全局最優學習而較少地向自身最優學習,有利于算法快速收斂到全局最優解。因此,改進PSO 算法的初始參數設定如下:c1start=2,c1final=0.5,c2start=0.5,c2final=2。
假設約簡后的數據集D1的維度是d1。本文利用該改進的粒子群算法在約簡的數據集中搜索稀疏子空間。在d1中選擇t個屬性,而每個屬性被劃分為φ份,此時將會有φt種子空間,每一種子空間即為粒子群算法的一個候選解。粒子群算法從p個隨機解開始,隨后根據局部最優Pgest和全局最優Gbest對隨機解的位置和速度進行迭代和更新,并且對可能的子空間進行隨機搜索。每一個可能的子空間D2都有一個稀疏系數S(D2),稀疏系數S(D2)即為粒子群優化算法對應的適應度函數。迭代中Pgest和Gbest都是通過適應度函數得到的。這個過程一直持續到達到最大迭代次數為止。在算法的每一個階段都是在追隨最佳的t個屬性(即具有最小的稀疏系數),在算法的最后階段,這t個屬性為數據集中與異常值最相關的特征集。粒子群搜索算法的總體過程見算法3。
算法3 用改進的粒子群算法搜索稀疏子空間
輸入:約簡后的數據集D1,稀疏因子閾值θ,原始數據集數據對象的總數N=||D。
輸出:異常值集合O。

5 實驗結果分析
為了說明SSLOD算法的有效性和異常因子閾值以及稀疏因子閾值方法的準確性,在仿真數據集上和UCI數據庫真實數據集上進行了測試。
仿真數據集:用文獻[26]的產生數據方法生成了3個仿真數據集。假設數據服從正態分布,首先生成均值是0,方差是1的數據集;其次向數據集額外增加0.1%的點作為異常值,加入的數據服從0到1的均勻分布;最后不斷復制第一步生成的數據集擴充數據量。基本信息見表3。首先說明在算法過程中的屬性初步約簡的性能,表4列出了約簡的數據屬性和對象隨著異常因子閾值τ的變化趨勢。可以發現,異常因子閾值τ的增大,屬性和對象個數顯著減少。例如,當τ=0.005 時,仿真數據集Data1、Data2、Data3減少的屬性所占比例分別是16%、17%、20.7%,減少的數據對象所占的比例分別是13.31%、18.45%、14.29%。將一個N×d高維數據集D每個屬性上的數據劃分為φ個離散區間,在d維屬性中選擇t個,那么這t維屬性就可以構成φt種子空間。所以減少屬性和數據對象,以減少需要搜索的子空間的個數,有利于提高算法的效率。
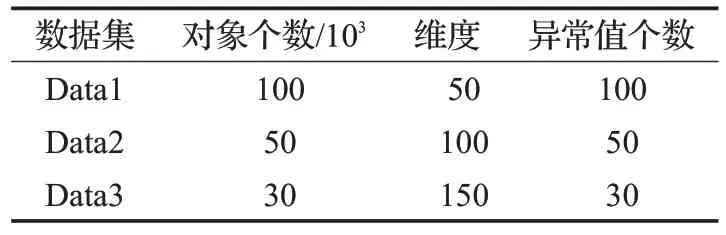
表3 仿真數據集信息
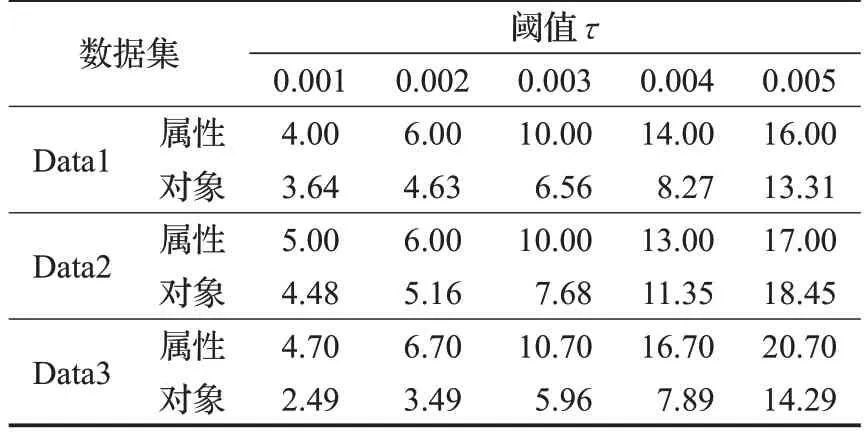
表4 約簡對象及屬性的比例%
分析了異常因子閾值τ和稀疏系數閾值θ對算法精度(Accuracy)的影響。為表示精度,先給出混淆矩陣,見表5。混淆矩陣一般應用在二分類中,這里將異常值認為是正類。精度[29]的計算公式如下:
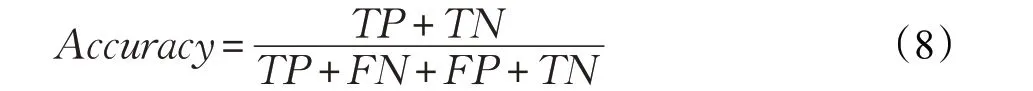

表5 混淆矩陣
如圖1 給出了算法精度隨異常因子閾值τ變化情況,可以看出,當異常因子閾值τ逐漸增大時,算法的精度會略下降。這是因為τ越大,被減少的屬性和對象就越多,使得產生的稀疏子空間可能會丟失一些有用的信息,導致算法的精度出現下降的趨勢,由圖2 的信息可以看出隨著稀疏系數閾值θ的增大,算法的精度在漸漸地上升,但是在后期上升的速度要緩慢一些。這說明在后期算法的精度前后相差不大,這種現象可以給在實際試驗中如何取θ值做一個較佳的參考。

圖1 異常因子閾值τ 對算法精度的影響
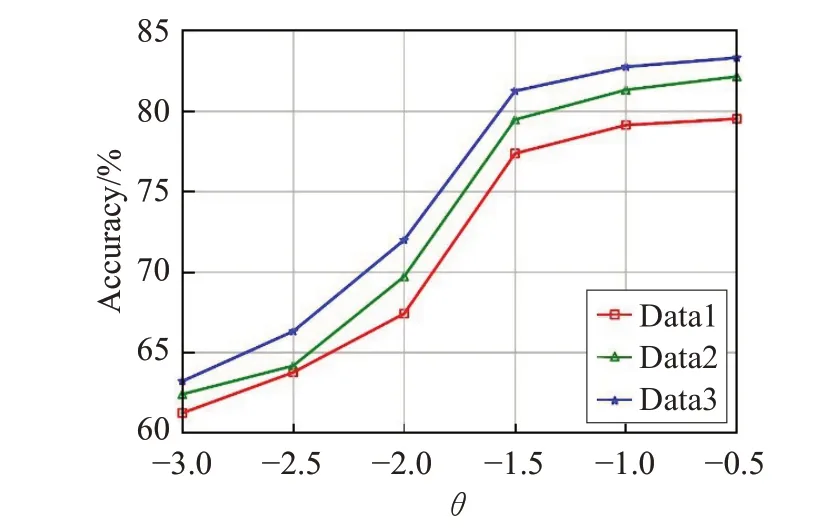
圖2 稀疏系數閾值θ 對算法精度的影響
UCI數據集:在3個真實的數據集上實現SSLOD算法,這些數據集是高度類不平衡的,一般應用在數據分類和其他機器學習算法中,數據集中的少數類認為是異常值,多數類是正常值。另外,在實驗之前還對數據進行了清洗以便處理分類屬性和缺失數據。表6 給出了UCI真實數據集的基本信息。對于這3個不同的數據集均將參數φ設置為7,稀疏系數閾值θ可根據仿真數據集的分析結果選擇,建議在[-1.5,-0.5]之間選擇,其余參數的設定已在相關章節給出。將算法SSLOD的精度和效率與遺傳算法和標準粒子群算法進行了對比。觀察表7,在相同的數據集下,提出的算法SSLOD 算法的精度均高于其余兩種算法,特別是對于數據集Internet Usage Data,SSLOD 的精度比遺傳算法的精度提高了13.07%。由圖3中可以看出,SSLOD的效率在不同的數據集上均高于其余兩種算法。這是因為SSLOD算法在搜索稀疏子空間之前先用算法1和2約簡了原始數據集維度和對象,然后用算法3對標準粒子群算法慣性權重隨機化,對其學習因子異步化,使搜索算法不易陷入局部最優,同時又可以快速收斂到全局最優。與標準粒子群算法相比,進一步提高了算法效率。與遺傳算法相比,不需要進行交叉變異等遺傳操作,降低了計算復雜度,提高了算法效率。
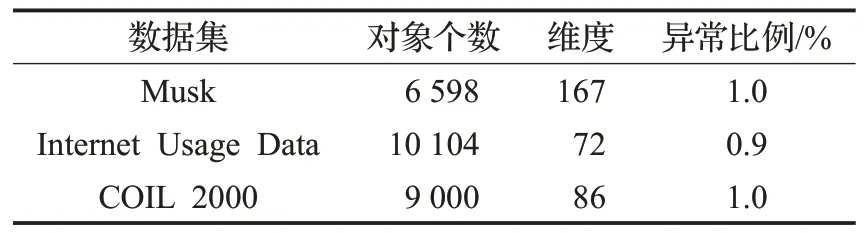
表6 UCI數據集信息
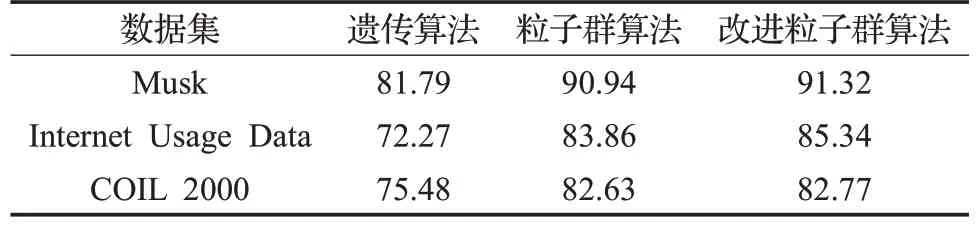
表7 3種算法精度比較%
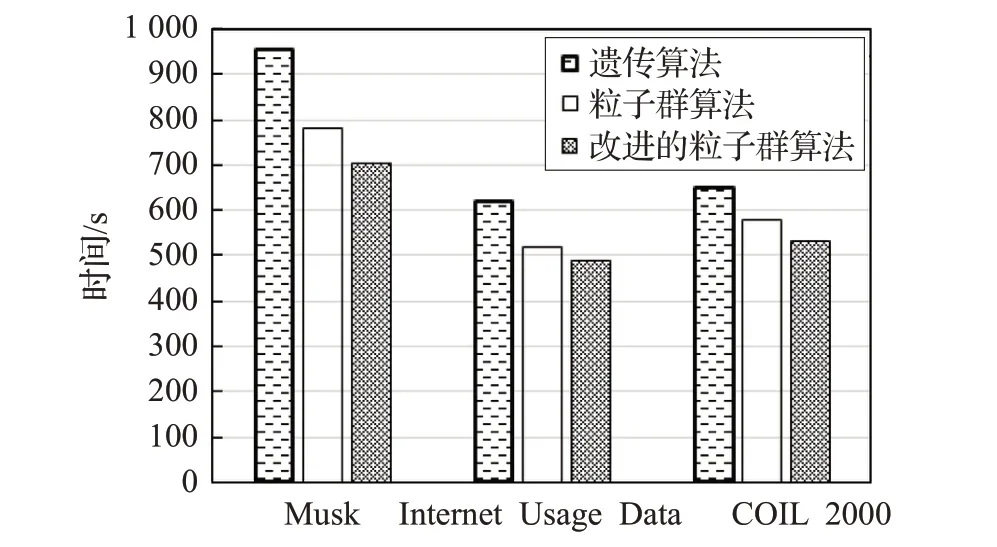
圖3 3種方法的效率比較
算法1 的復雜度主要體現在第3 步到第5 步,若采用蠻力法構造KNN 圖,N個對象的計算復雜度為O(N2),而使用R*-tree索引結構可以將搜索k近鄰的復雜度減少到O(N?lgN),第6步到第11步以及算法2復雜度均為線性階,因此算法1 和算法2 的復雜度即為O(N?lgN)。算法3 的計算量主要體現在更新速度、位置和計算適應度函數。設粒子規模是p,最大迭代次數是T,約簡后數據集的大小是N,待搜索的空間被劃分為φ×t份。速度和位置更新的復雜度為O(T?p?2N),計算適應度函數的復雜度是O(T?p?φ?t)。因此,SSLOD算法總時間復雜度為O(N?lgN)+O(T?p?2N)+O(T?p?φ?t)。
6 結束語
在高維數據集中,異常數據往往在部分維度構成的子空間中能被識別,而在高維空間中表現并不異常,這使得高維空間中直接檢測異常值變得困難。此外,不同的異常值可能存在于由不同屬性張成的不同子空間中,因此需要搜索有利于表征異常值的子空間。本文針對上述問題,在檢測異常值之前先對屬性和數據對象進行約簡,并用改進的粒子群搜索算法在約簡后的數據集中搜索稀疏的子空間,進一步將局部異常值挖掘出來。在仿真數據集上充分分析了SSLOD 算法的有效性,并將該算法與遺傳算法和標準粒子群算法在真實數據集上作比較。綜合實驗結果表明,本文所提出的基于稀疏子空間局部異常值算法具有良好的性能和較高的效率。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
兒童故事畫報(2019年5期)2019-05-26 14:26:14
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
