機器人目標抓取區域實時檢測方法
2020-10-10 01:00:34盧智亮劉瑞雪
計算機工程與應用 2020年19期
盧智亮,林 偉,曾 碧,劉瑞雪
廣東工業大學 計算機學院,廣州510006
1 引言
在家庭和工業場景下,抓取物體是機器人進行人機協作任務的關鍵步驟。人類可以準確且穩定地執行抓取形狀不規則以及任意姿態的物體。然而對于機器人而言,準確地抓取各式各樣、任意姿態的物體依舊是一種挑戰。機器人若要抓取目標物體,需要預先檢測該物體的抓取區域,不適當的抓取區域將導致機器人無法穩定地抓取物體。因此,如何實時且準確地檢測目標抓取區域,是機器人領域中一個重要研究方向。
近年來,國內外學者對機器人抓取區域檢測的研究已有不錯的成果。Lenz 等[1]率先采用深度學習的方法提取RGB-D 多模態特征,基于滑動窗口檢測框架同時使用支持向量機(Support Vector Machine,SVM)作為分類器,預測輸入圖像中的一小塊圖像是否存在合適的抓取位置。與Jiang等[2]使用傳統機器學習方法相比,該方法不需要人為針對特定物體設計視覺特征,而是以自主學習的方式提取抓取區域的特征。在Cornell 數據集[3]上,上述方法達到73.9%的準確率。然而采用滑動窗口的方法會導致搜索抓取區域耗費時間長且計算量大。杜學丹等[4]在檢測抓取位置前,先使用Faster R-CNN二階目標檢測算法[5]預測被抓物體的大致區域,縮小搜索范圍以減少搜索時間,但該方法并未從本質上減少檢測時間且計算量仍舊偏大,無法達到實時檢測的要求。
Redmon等[6]不再基于滑動窗口框架搜索抓取框,而是利用AlexNet 網絡[7]強大的特征提取能力,直接在整個圖像上回歸抓取框參數。將輸入的圖像劃分成N×N個網格單元,每個網格單元預測一個抓取配置參數及適合抓取的概率,取其中概率最高的作為預測結果。在相同數據集上達到88.0%的準確率,平均檢測時間為76 ms。Kumra等[8]也采用全局抓取預測的方法,使用網絡結構更復雜的ResNet-50[9]提取多模態特征,準確率相應提高1.21%。以上兩種方法借助性能強大的特征提取網絡力求盡可能提高檢測速度和檢測準確率,但是直接回歸抓取框參數容易導致預測的抓取框趨向于物體的中心,對于如盤子等抓取部位為物體邊緣的情況,預測的效果并不理想。
Chu 等[10]提出旋轉抓取框的方法,將方向預測視為抓取角度分類問題,借鑒Faster R-CNN二階目標檢測算法的思想,首先判斷由GPN(Grasp Proposal Network)推薦的多個抓取候選區域能否用于抓取目標物體,然后判斷剩余的抓取候選區域角度所屬類別。該方法使用三種基礎面積以及三種不同長寬比的錨框(Anchor)搜索抓取候選區域,達到96%的準確率,平均檢測時間為120 ms。該方法雖然大幅度減少文獻[1]和[4]中算法的檢測時間,但依舊無法滿足動態環境或動態物體下實時抓取檢測的要求,并且僅利用特征提取網絡中最后一層的特征圖進行預測,傾向于檢測較大的抓取框,對小抓取框檢測性能不足,檢測精確性有待提高。
綜上國內外學者的抓取檢測算法已達到不錯的效果,但是仍然存在以下兩個問題:第一,高準確率下檢測抓取框時間過長,不滿足機器人抓取檢測的實時性要求;第二,容易忽略目標物中可用于抓取的小部位信息,檢測出來的抓取框偏大、精確度不足。
針對以上問題,本文提出一種基于嵌入通道注意力結構SENet[11]的一階抓取檢測網絡(Squeeze and Excitation Networks-RetinaNet used for Grasp,SE-Retina-Grasp)模型的機器人抓取區域實時檢測方法。該方法采用快速的一階目標檢測模型RetinaNet[12]作為基本結構,在其特征提取網絡中嵌入通道注意力模塊SENet以提升重要特征通道的權重,確保檢測精度;而且為了解決原RetinaNet模型特征融合中僅關注相鄰層特征信息的問題,結合平衡特征金字塔[13](Balance Feature Pyramid,BFP)思想,充分融合高低層的特征信息,加強檢測小抓取框的能力。
2 抓取框在圖像空間的表達方式
給定包含目標物的圖像I,檢測該目標物的最優抓取框G,需要先明確抓取框在圖像空間的表達方式。本文針對末端執行器為平行夾爪的情況,采用文獻[1]提出的抓取框表達方法表示機器人抓取的具體位置,如圖1所示,公式表示為:

其中,(x,y)為抓取框的中心點;h、w分別表示機器人平行夾爪的高度、平行夾爪張開的距離大小;θ為沿w方向與圖像x軸正方向之間的夾角。過大的抓取框容易導致抓取中心點的偏移和預測的w遠大于夾爪實際可張開的大小,抓取框的精確性直接影響機器人能否穩定地抓取目標物。
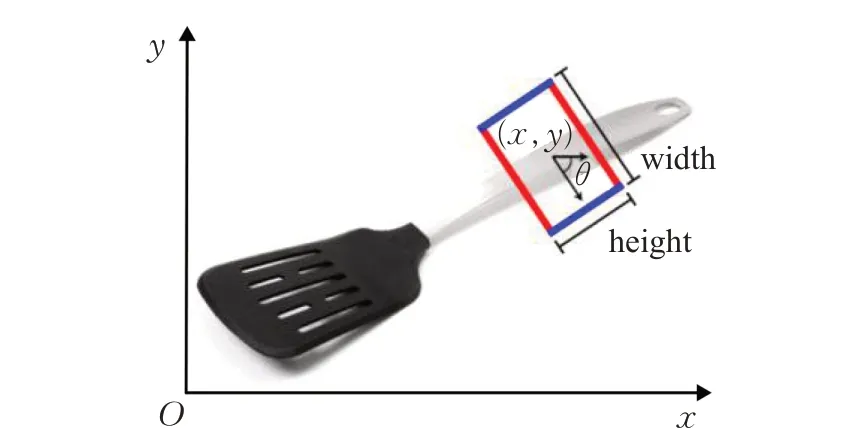
圖1 抓取框在圖像空間的表達方式
3 SE-RetinaGrasp模型
機器人目標抓取區域實時檢測算法流程框圖如圖2 所示。首先,獲取包含目標物的RGB 場景圖像;其次對該圖像進行數據預處理操作后,作為抓取檢測網絡模型的輸入;最后模型生成可用于抓取目標物的抓取框,機械臂利用抓取框的位置姿態信息,完成抓取目標物的任務。
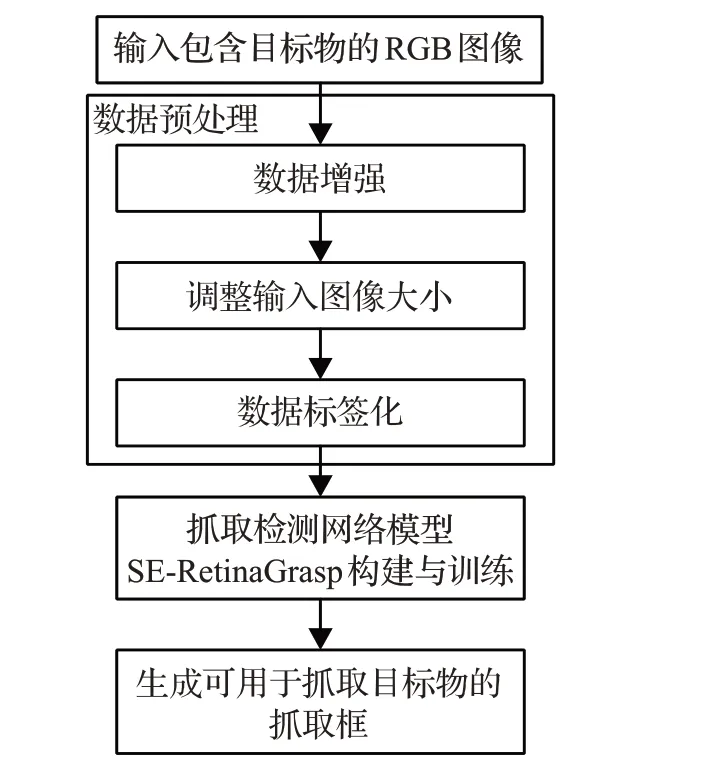
圖2 機器人目標抓取區域實時檢測算法流程
本文提出的SE-RetinaGrasp 模型如圖3 所示。圖(a)表示特征提取網絡,在深度殘差網絡ResNet-50中嵌入SENet模塊,對抓取檢測任務起積極作用的特征通道加強權重;圖(b)表示平衡金字塔結構,進一步融合特征金字塔結構FPN(Feature Pyramid Networks)[14]中高低層的特征信息;圖(c)表示兩個FCN(Fully Convolutional Networks)[15]子網絡,分別用于抓取框的定位以及抓取角度的分類。
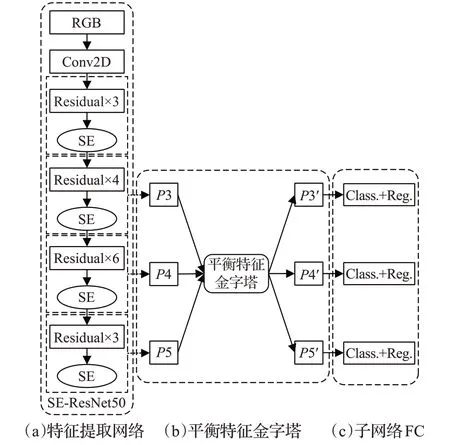
圖3 SE-RetinaGrasp模型結構
3.1 RetinaNet一階目標檢測模型
一階目標檢測模型RetinaNet是由文獻[12]提出,用以驗證提出的Focal Loss 函數對解決訓練過程中正負樣本類別失衡問題的效果。考慮到目標物僅占輸入圖像中的一部分,為解決一階目標檢測模型中密集采樣候選機制導致的正負樣本失衡的問題,本文采用Focal Loss 函數作為分類損失函數、光滑L1 函數處理抓取框參數的回歸問題。
其中,Focal Loss函數是一種改進的交叉熵(Cross-Entropy,CE)損失函數,通過在原有的交叉熵損失函數中乘上使易檢測目標對模型訓練貢獻削弱的指數式,成功減少目標檢測損失值容易被大批量負樣本左右的現象。Focal Loss函數定義如下:
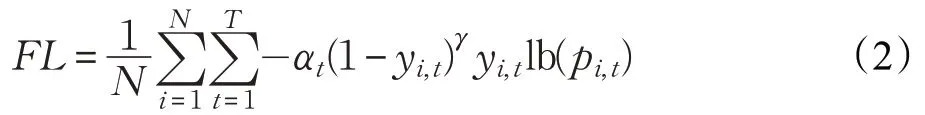
假設有N個樣本,總共有T種分類,y為真實標簽,pi,t為第i個樣本被預測為第t類目標的概率大小;平衡參數α用以調整正負樣本對總分類損失的貢獻;(1-yi,t)γ為Focal Loss函數添加的指數式系數,用以降低易分類樣本的權重,將更多注意力放在難分類樣本的訓練上。其中,α、γ為超參數,不參與模型的訓練過程。
RetinaNet 檢測模型主要由ResNet-50 提取特征網絡、特征金字塔FPN 結構以及兩個FCN 子網絡組成。RetinaNet檢測模型,如圖4所示。
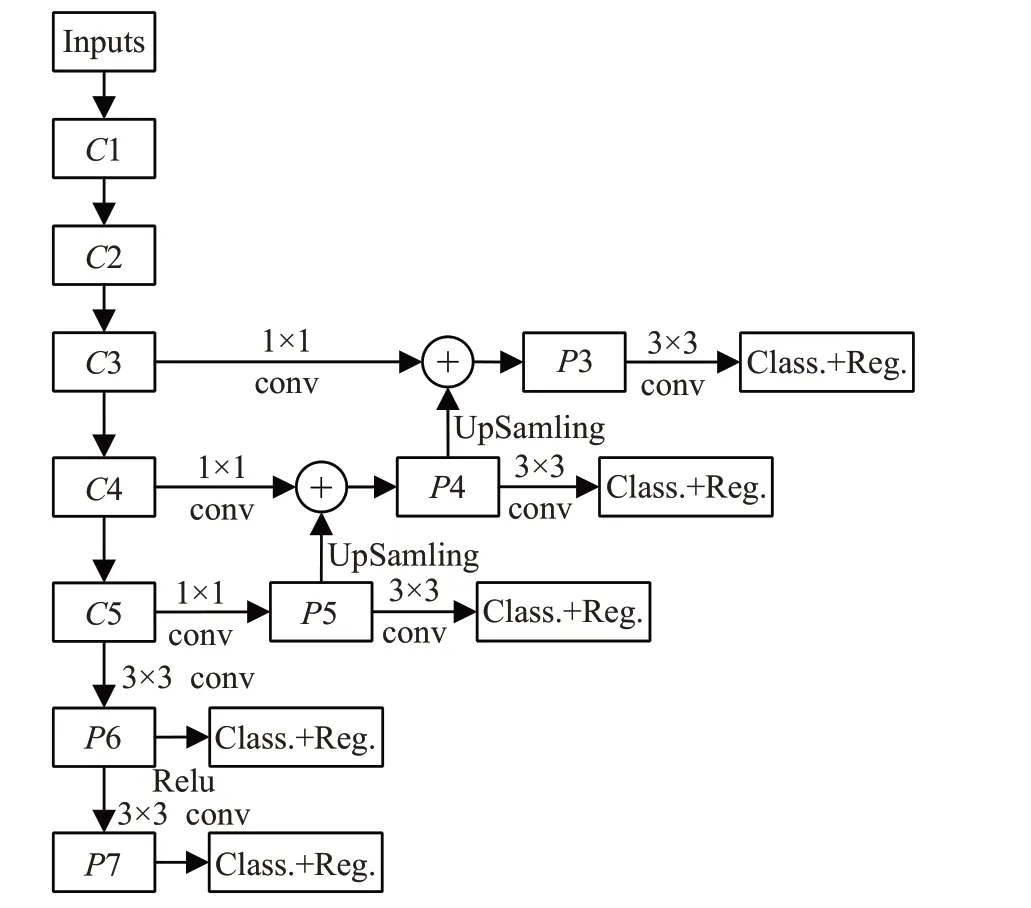
圖4 RetinaNet檢測模型結構
C1、C2、C3、C4、C5 分別為ResNet50網絡中采用不同個數殘差塊(Residual)提取的不同分辨率大小特征圖。根據低層特征語義信息弱,目標位置清晰;高層特征語義信息強,目標位置模糊的特點,FPN 結構通過自底向上連接、自頂向下連接以及橫向連接,對不同層的特征信息進行融合。與原FPN結構不同的是:
(1)RetinaNet 模型僅利用C3、C4、C5 特征圖,避免在高分辨率C2 特征圖中生成Anchor,減少模型檢測時間。
(2)對C5 特征圖進行卷積核為3×3,步長為2 的卷積運算得到P6 網絡結構;對P6 使用Relu 激活函數增加非線性后再進行相同的卷積運算得到P7 結構,通過在P6、P7 生成較大面積的候選區域增強模型檢測大物體的性能。
與目標檢測任務不同的是,抓取檢測任務是檢測可用于抓取目標物的區域位置,并非檢測目標物自身的位置。針對目標物抓取區域面積較小的特點,為使RetinaNet模型更好地應用于抓取檢測任務中,本文僅在P3、P4、P5 三個層次生成抓取候選區域,采用{82,162,322}基礎大小的候選窗口,加入三種不同的尺度和{1∶2,1∶1,2∶1}三種不同的長寬比,搜索各種尺寸大小的抓取候選框。
3.2 SENet結構
從文獻[10]的實驗發現,將特征提取網絡Vgg16[16]替換為ResNet-50僅提高0.5%的準確率,證明當網絡達到一定深度時,繼續加深網絡層數并不能對準確率有較大的提升。本文從考慮特征通道之間的關系出發,在特征提取網絡ResNet-50中的每一個殘差塊后嵌入SENet模塊,增強抓取檢測任務中關鍵通道的注意力,以提升檢測準確度。SENet結構,如圖5所示。

圖5 SENet結構
SENet模塊主要采用擠壓(Squeeze)、激勵(Excitation)以及特征重標定(Scale)三個操作完成特征通道自適應校準。
首先使用全局平均池化壓縮每一個特征圖,將C個特征圖轉換成1×1×C的實數數列,使每一個實數具有全局感受野。然后本文通過兩個卷積層完成降維與升維的操作,第一個卷積層將特征維度降低到原來的C r后通過Relu激活函數增加非線性;第二個卷積層恢復原來的特征維度,經過Sigmoid函數得到歸一化的權重,最后通過乘法逐通道加權到原來的特征通道上,對原始特征進行重標定。擠壓、激勵以及特征重標定公式如下所示:
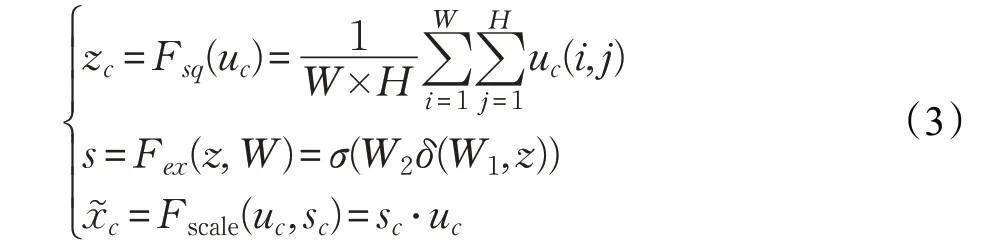
3.3 平衡特征金字塔
針對原RetinaNet模型中FPN結構僅融合相鄰層次的特征信息,導致高低層特征信息利用不平衡的現象。為進一步加強檢測小抓取框的效果,充分利用不同分辨率下的特征信息,本文受文獻[13]中平衡特征金字塔結構的啟發,對原RetinaNet 模型中的特征金字塔結構進行改進。平衡特征金字塔結構如圖6 所示。提取P3、P4、P5 三個層次的特征圖,對P3、P5 分別采用最大池化操作、上采樣操作,使P3、P5 的特征圖分辨率與P4特征圖保持一致,三者對應元素相加取平均,得到平衡特征圖P′,公式如下:

其中,Pl表示第l層特征;本文中lmin、lmax代表最低層數、最高層,分別為3、5;N代表累加的層數量。對平衡特征圖P′進行卷積核為3×3,步長為1 的卷積運算得到進一步提煉的特征圖Pr,使特征信息更具有判別性。最后調整提煉后的特征圖Pr分辨率大小分別與P3、P4、P5 層次的特征圖分辨率大小一致,與原層次的特征對應元素相加,分別得到增強原層次特征表征能力的P3′、P4′、P5′,特征圖,從而增強模型捕捉細節信息的能力,有助于檢測小抓取框。
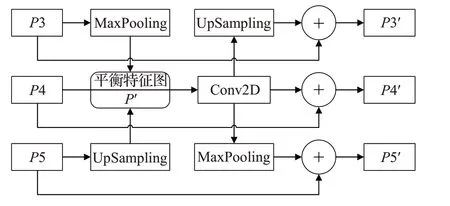
圖6 平衡特征金字塔結構
4 實驗
4.1 實驗環境
本文的實驗機器是一臺配置型號為Intel?Core?i7-8750H 的CPU 和NVIDIA GeForce GTX 1070 的GPU的個人計算機,內存以及顯存大小分別為32 GB、8 GB。該機在Ubuntu 16.04 上運行,基于深度學習框架keras使用Python 語言編寫,借助CUDA(Compute Unified Device Architecture)加速運算。
4.2 實驗數據集
本文采用Cornell數據集作為訓練數據,圖7為數據集中的部分圖片。該數據集總共有885張圖片,其中包含了244種不同種類的物體,每一種物體均有不同的擺放位置及姿態。數據集對每一張圖片中的目標物體的抓取位置進行標記,共標記5 110 個可用于抓取目標物的矩形框和2 909個不可用于抓取的矩形框。本文實驗將抓取數據集依照以下兩種方式進行劃分,得到708張圖片作為訓練樣本、177張圖片作為測試樣本。

圖7 Cornell數據集
方式1 按圖片隨機劃分。將數據集圖片隨機劃分至訓練集和驗證集中,以驗證模型對已見過的、不同擺放位置的物體的泛化能力。
方式2 按物體種類隨機劃分。使訓練集中并不含有測試集中的物體種類,以驗證模型對未曾見過的新物體的泛化能力。
4.3 數據預處理
盡管Cornell 數據集包含的物體種類豐富,但數據量較小,為了使訓練樣本盡可能地涵蓋各種可能出現的情況,本文對訓練樣本進行擴充:
首先對原始圖像在x軸、y軸各做50 個像素點內的隨機平移;然后對平移后的圖片進行中心剪裁得到321×321 大小的圖像;處理后的圖像再進行0°~360°范圍內的隨機旋轉;為了方便與其他算法進行比較,本文將原始圖像分辨率大小為480×640 調整為227×227 作為網絡模型的輸入;
最后如文獻[10]一樣將抓取角度進行類別劃分,考慮到抓取角度的對稱性,本文將180°均分成19個區域,加上背景分類,本文實驗共有20 種類別。標簽中的角度值相應分配至最近的區域,將原本帶有方向性的矩形框置為沒有角度傾斜的矩形框,模型訓練時擬合這些垂直于圖像x軸的矩形框,并預測這些矩形框屬于哪種角度類別。
4.4 模型訓練的實現
考慮到RetinaNet模型內部層數較多且結構相對復雜,對于目前數據集數據規模較小的情況容易導致過擬合。為此本文采用遷移學習的方法進行抓取檢測模型訓練,將在微軟COCO 數據集訓練好的ResNet-50 模型參數作為初始值,在此基礎上進行微調,網絡中其余的參數采用標準高斯分布進行初始化。以圖像RGB作為模型輸入,學習率初始化為0.000 1,學習率衰減因子為5,設置每批訓練圖片數為2,epoch初始化為20,采用隨機梯度下降法(SGD)對模型進行訓練。
4.5 評估指標
通常有兩種評估方法來衡量模型預測抓取姿態的效果:一種是點度量方法,另一種是矩形度量方法。
點度量評估方法主要以模型預測的抓取框中心點與標注真值框的中心點之間的距離作為衡量標準,當兩點之間的距離小于預定的閾值,則認為預測結果可用于抓取目標物體并取最小值作為最佳抓取框。然而以往算法中沒有公開點度量評估方法所使用的閾值,并且該方法沒有將抓取角度納入評估范疇中,所以更多的算法采用矩形度量作為評估方法。
矩形度量方法采用抓取矩形來衡量模型預測的效果,當預測的矩形框同時滿足以下兩個條件時,則認為該矩形框可用于抓取物體:
(1)預測的抓取角度與標注真值框的抓取角度之差小于30°。
(2)Jaccard 相似系數大于0.25,其中Jaccard 相似系數計算公式如下:

其中,gp為預測抓取矩形區域,gt為標注真值框的抓取矩形區域。本文采用矩形度量的評估方法,取預選抓取框中評判值最大的作為模型預測結果。
4.6 實驗結果與分析
本文使用Cornell 數據集對提出的算法進行測試,測試結果如圖8 和圖9 所示:圖8 展示模型預測的部分正確抓取框;圖9展示模型預測結果中錯誤抓取框。

圖8 模型預測的部分正確抓取框

圖9 模型預測結果中錯誤抓取框
為進一步驗證本文算法的有效性,本文進行以下兩部分實驗:
(1)原RetinaNet模型和SE-RetinaGrasp模型檢測效果對比
將數據集按圖片隨機劃分的方式切分訓練集和測試集,利用原RetinaNet模型和SE-RetinaGrasp模型對測試集進行抓取檢測,實驗結果如表1所示。
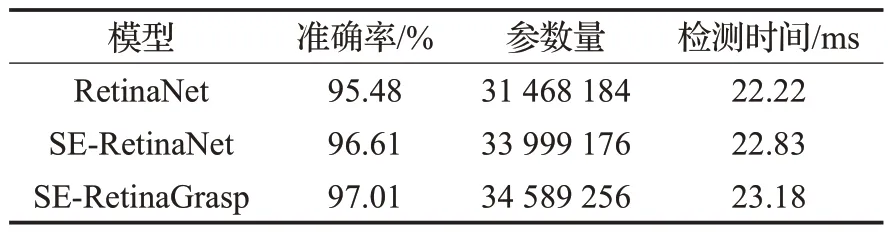
表1 原RetinaNet模型、SE-RetinaGrasp模型結果對比
從表1中可以看出,嵌入SENet結構的RetinaNet模型較原RetinaNet模型準確率提高了1.13%,參數量較原RetinaNet模型增加8%,而平均檢測時間幾乎沒有增加;基于SE-RetinaNet 模型的基礎上引入平衡金字塔的思想,準確率進一步提升0.4%,參數量較SE-RetinaNet 模型僅增加1%,總體平均檢測時間較原RetinaNet模型增加了1 ms。
實驗分析可知,嵌入SENet結構有助于挖掘抓取檢測任務中重要的特征通道,增強特征圖的感受野;而引入平衡特征金字塔的思想進一步融合不同層次的特征信息,加強原來各層次中特征的表達能力,有助于檢測物體中各種大小的抓取框。由于主要采用上采樣以及最大池化操作,模型參數數量基本不變,并有效提高了檢測準確率。本文算法與原RetinaNet檢測效果如圖10所示。

圖10 原RetinaNet模型、SE-RetinaGrasp模型效果對比
由圖10 可發現,對于同一種物體,原RetinaNet 檢測的抓取框趨向于兩端且仍有抓取框偏大的現象,而SE-RetinaGrasp 模型的抓取框更趨向于物體的中間位置且抓取框更為精準,提高了機器人抓取目標物體的穩定性。
(2)本文算法和其他算法檢測效果對比
將本文算法與以往提出的算法進行對比,并比較不同方式劃分數據集下檢測準確率以及檢測時間。對比結果如表2所示。
實驗結果顯示,本文算法可在保持高準確率的前提下,以實時速度檢測抓取框,比文獻[10]算法的檢測速度快了將近6倍。
按方式1劃分數據集,本文算法準確率均高于其他檢測算法;按方式2 劃分數據集,準確率稍低于文獻[10]。本文算法的執行效率均高于其他經典抓取檢測算法,盡管本文模型在生成候選抓取框時耗費了一定的時間,但本文算法的網絡模型為全卷積網絡且無文獻[10]算法中區域生成網絡該一步驟,有效地減少檢測時間。
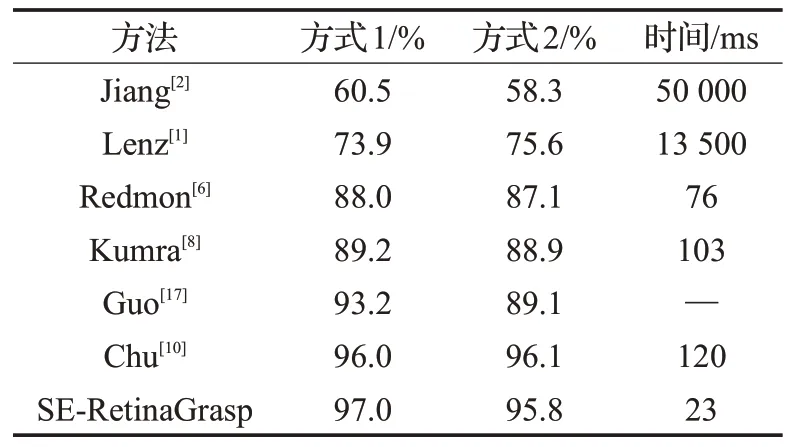
表2 本文算法與其他算法結果對比
為進一步體現本文算法性能,表3 展示了在不同Jaccard閾值下檢測精度結果。結果表明,在更嚴格的評價標準中,本文算法仍保持較高的檢測準確率,有助于機器人精確地抓取目標物。
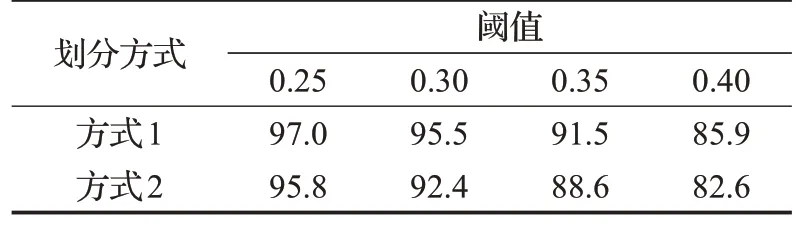
表3 不同Jaccard閾值下的檢測精度 %
本文通過復現文獻[10]的抓取檢測算法,與本文算法進行對比,具體效果如圖11所示。

圖11 本文算法與其他算法效果對比
由圖11 的對比效果可發現,對于檢測同一種物體不同擺放姿態下的抓取位置,文獻[10]檢測的抓取框偏大,精確度不足;本文算法預測的抓取框更加精細,主要原因在于本文算法充分利用不同層次的特征信息,并在不同層的特征圖上檢測抓取框,與文獻[10]在提取特征網絡的最后一層特征圖上進行檢測相比,本文算法能更好地捕抓目標物的細節信息,加強小抓取框的檢測效果。
5 結束語
為了使機器人實時且準確地抓取目標物體,本文提出并驗證了一種基于SE-RetinaGrasp 的神經網絡模型。該模型以一階目標檢測算法RetinaNet 為基礎,一方面,通過通道注意力SENet 結構,建立特征通道之間的相互依賴關系,提升對抓取檢測任務起積極作用的特征并抑制用處不大的特征,從而提高檢測準確率;另一方面,利用平衡金字塔的思想,在不增加太多參數的前提下,進一步融合不同層次的特征信息,加強模型對細節信息的捕抓能力。在Cornell 數據集上的實驗證明,相比于傳統抓取檢測模型,SE-RetinaGrasp 模型保持高檢測準確率的同時,實時性高,并且一定程度上提高了抓取框的精細程度。
然而,Cornell數據集針對的圖像僅包含單一目標物體,對于現實生活中多物體堆疊的情況尚未能很好的解決,因此,如何能在多物體堆疊的場景下,實時準確地抓取相應物體是下一步的研究內容。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
