基于特征金字塔的多尺度特征融合網絡
2020-11-04 03:06:30郭啟帆徐文娟靖穩峰
工程數學學報 2020年5期
郭啟帆, 劉 磊, 張 珹, 徐文娟, 靖穩峰,?
(1- 西安交通大學數學與統計學院,西安 710049; 2- 中鐵第一勘察設計院集團有限公司,西安 710043)
1 引言
卷積神經網絡CNN 能夠學習圖像的高級特征表示,在計算機視覺中得到廣泛應用.自2012 年一種有效的CNN―AlexNet[1]出現之后,卷積神經網絡得到了快速發展,基于CNN 的VGGNet[2]、Inception[3]等網絡在工程圖像分類中取得了優異的表現.隨著ResNet 殘差網絡[4]的提出,CNN 向更深層次的網絡邁進,其圖像處理的性能不斷提升,已經在視覺檢測領域顯現出巨大的優勢.
近年來,圖像分類、目標檢測等計算機視覺算法隨著CNN 的改進快速發展.Girshick等提出了基于CNN 的R-CNN[5]用于目標檢測,使得兩階段的目標檢測成為主流.He 等人提出了SPPNet[6],有效解決了候選區域計算冗余的問題.Girshick 提出了Fast RCNN[7],實現了一種多任務學習方式,對目標分類和包圍框回歸的同步訓練.Ren 等人在Faster R-CNN[8]中提出RPN,將區域推薦階段和CNN 分類融到了一起,實現了一個完全意義上的端到端的CNN 目標檢測模型.Redmon 等人提出的YOLO[9]是第一個單階段卷積網絡檢測算法,僅通過一次前向傳播直接得到目標包圍框的位置和目標的類別,有著非常快的檢測速度,但是其精度較差.Liu 等人接著提出SSD 算法[10],吸收了YOLO 速度快和RPN 定位精準的優點,采用了RPN 中的多參考窗口技術,并進一步提出在多個分辨率的特征圖上進行檢測.為了提高單階段方法的檢測精度,Lin 等人提出了RetinaNet[11]檢測模型,對傳統的交叉熵損失函數進行修正,提出了“Focal Loss”,極大的提高了檢測精度.
特征金字塔網絡FPN[12]是傳統CNN 網絡對圖片信息進行表達輸出的一種有效方法,通過對不同層的特征圖進行特征融合,使用多尺度的特征圖進行預測.特征金字塔對多尺度特征圖的融合在目標檢測網絡中得到了廣泛應用,并取得了顯著的效果提升.然而,FPN 沒有將存在于低層特征圖準確定位信號反饋到高層語義特征圖,同時各層級之間的特征傳遞僅限于相鄰層級,導致了特征融合的不平衡性.在Liu 等人的Path Aggregation Network[13]中,引入bottom-up path augmentation 結構,利用網絡淺特征對FPN 特征進行融合.
針對FPN 的不足,本文提出基于特征金字塔的多尺度特征融合網絡模型(Muti-scale Feature Fusion Network, MSFFN).MSFFN 包含了混合特征金字塔(Mixed Feature Pyramid, MFP)和金字塔融合模塊(Pyramid Fusion Block, PFB).MFP 在FPN 的基礎上增加了自底向上的路徑,把FPN 中低層的細節信息傳遞到高層的語義特征圖,PFB 引入特征注意力機制,將不同層級的特征進行直接融合,同時保留其語義和位置信息,以此來平衡所有用來進行預測的層級.針對MSFFN,本文在MSCOCO 2014 和PASCAL VOC 2012 數據集上進行實驗,驗證了本文提出的MSFFN 方法的有效性.
2 相關工作
2.1 特征金字塔網絡(FPN)
特征金字塔網絡將低分辨率、高語義信息的高層特征和高分辨率、低語義信息的低層特征進行自上而下地側邊連接,使得所有尺度下的特征都有豐富的語義信息,其結構如圖1 所示.通過利用常規CNN 模型從底至上各個層對同一圖片不同維度的特征表達結構,可有效在單一圖像視圖下生成對其的多維度特征表達,其核心思想包括兩部分:自下至上的通路即自下至上的不同維度特征生成;自上至下的通路即自上至下的特征補充增強.
自下而上的部分是卷積神經網絡的前向過程.在前向過程中,特征圖的大小在經過一些層后會改變,而在經過其他一些層的時候不會改變,將不改變特征圖大小的層歸為一個階段,因此每次抽取的特征都是每個階段的最后一個層的輸出,這樣就能構成特征金字塔.具體地說,使用了ResNet 網絡Conv2-x、Conv3-x、Conv4-x 和Conv5-x 各階段的最后一個殘差結構的特征激活輸出.自上而下的過程采用上采樣,通過內插值方法,即在原有圖像像素的基礎上在像素點之間采用合適的插值算法插入新的元素,從而擴大原圖像的大小.通過對特征圖進行上采樣,使得上采樣后的特征圖具有和下一層的特征圖相同的大小.

圖1 特征金字塔結構
2.2 注意力機制
注意力機制是在特征提取的時候,著重關注圖像信息最顯著的組成部分.即讓網絡更關注有效特征,具體實施時一般在通道維度加入注意力. Hu 等人[14]提出了探索通道間關系的SE 注意力模塊,通過全局池化特征計算每個通道的注意力,SE 注意力模塊的結構如圖2 所示.
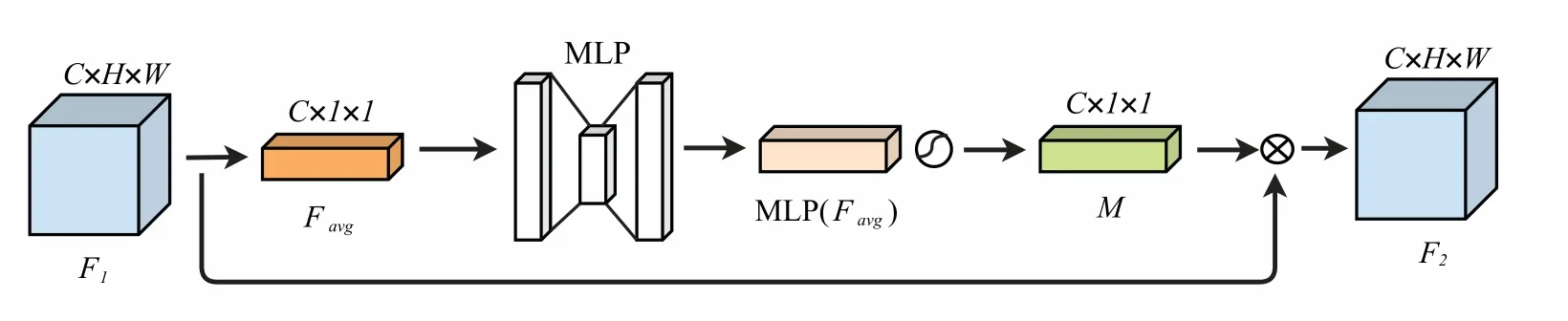
圖2 SE 注意力模塊
首先對進入SE 注意力模塊的特征圖F 進行卷積操作,生成特征圖F1, F1∈RH×W×C,SE 注意力模塊在通道維度關注輸入特征圖的有用部分,通過將特征圖F1全局平均池化生成一維注意力圖Favg,其中全局平均池化為了得到每個通道所有元素的反饋,再經過共享的多層感知機得到注意力特征圖,經過sigmoid 函數激活生成權重特征圖M, M ∈R1×1×C,即為通道注意力特征圖,公式表示為

其中σ 為sigmoid 函數.
將帶有注意力的權重M 加入網絡,M 與特征圖F1進行元素相乘得到SE 注意力模塊輸出特征圖F2,公式表示為
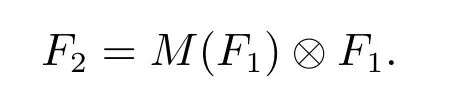
3 多尺度特征融合網絡
針對傳統特征提取網絡只能依靠深層語義信息來進行預測,而忽略網絡低層細節信息的不足,本文提出了多尺度特征融合網絡MSFFN,其結構如圖3 所示.MSFFN 在FPN主干網絡的基礎上,為了用低層細節信息增強特征金字塔,創建了自下而上的路徑,以增強低層細節信息到高層的傳遞.同時,MSFFN 對各層級的特征進行了融合,并反過來作用于相應層級的特征,來平衡各層級間的差異性,同時增強了有用特征的表達.本節首先介紹MSFFN 的用來路徑增強的混合特征金字塔網絡,然后描述金字塔融合模塊.
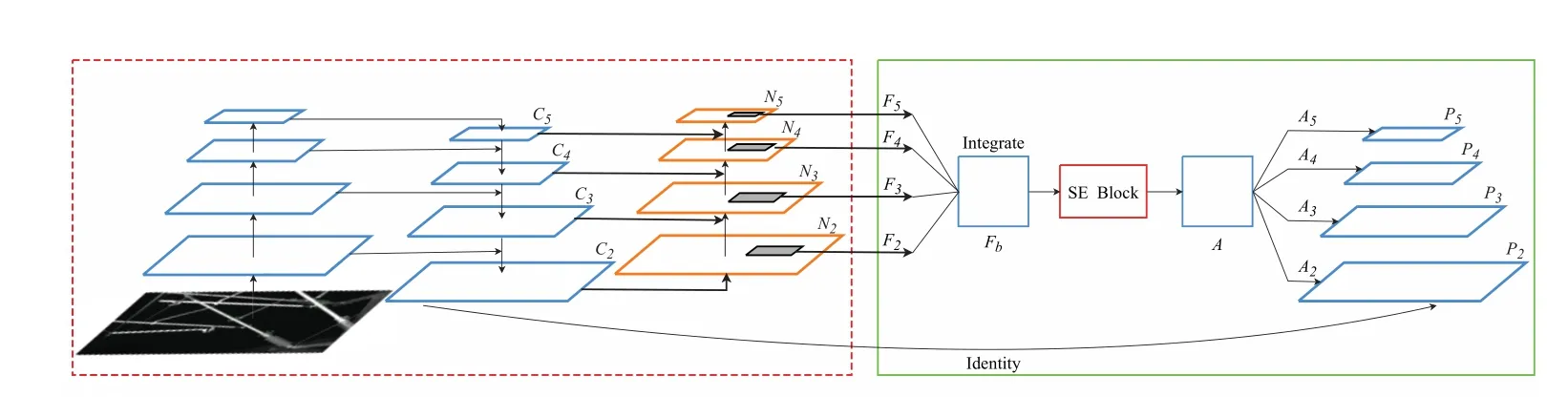
圖3 MSFFN 網絡結構
3.1 混合特征金字塔
混合特征金字塔MFP 在FPN 的基礎上,增加了自底向上的路徑,將FPN 中低層的細節信息傳遞到高層的語義特征圖.圖3 中矩形虛線框為MFP 的結構,N2~N5為自底向上的路徑增強.MFP 使用ResNet 作為基礎的特征提取網絡,使用ImageNet 上訓練好的權重作為預訓練模型,采用ResNet 網絡Conv2-x、Conv3-x、Conv4-x 和Conv5-x 各階段的最后一個殘差結構的特征激活輸出.根據FPN 的定義,將四種不同尺度的輸出生成與相同層空間維度大小一致的特征圖,記為{C2,C3,C4,C5}.
在此基礎上,本文設計了從低層到最高層的路徑.從C2開始一直到C5,空間尺寸逐漸采取下采樣.該過程新生成的與{C2,C3,C4,C5}相對應的特征圖記為{N2,N3,N4,N5}.圖4 描述了從Ni產生Ni+1的結構,每個Ni首先通過一個3×3,步長為2 的卷積層來減小尺寸,產生與Ci+1尺寸相同的特征圖.之后Ci+1與下采樣的特征圖元素相加.加和后的特征圖經過另外一個3×3 的卷積操作產生Ni+1.生成Ni+2的操作由Ni+1重復上述過程.圖4 結構的公式表示如下
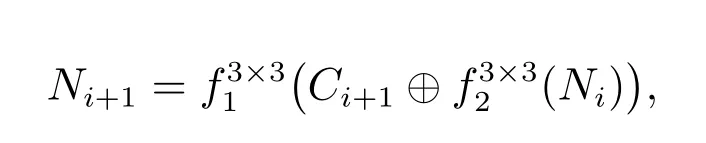
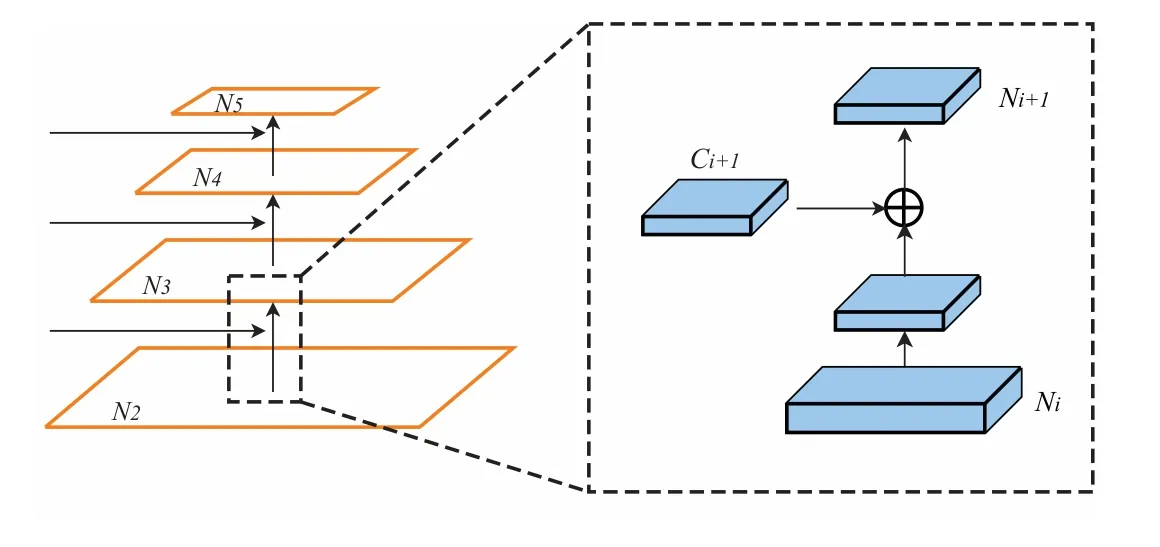
圖4 從底向上的路徑增強
3.2 金字塔融合模塊
MFP 中的路徑增強將低層細節信息和深層語義信息進行了傳遞.但是,這種傳遞僅限于相鄰層級,最高層的信息傳遞到最低層會變得較為微弱,造成了各層級之間信息的不平衡性.為了解決這個問題,本文提出了一個金字塔融合模塊PFB,將不同層級的特征進行直接融合,同時保留其語義和位置信息,以此來平衡所有用來進行預測的層級.PFB 的結構如圖3 中右邊的虛線框部分所示.首先將不同層級的特征{N2,N3,N4,N5}通過插值或最大池化重構為N4的尺寸大小,得到{F2,F3,F4,F5},之后,取其均值得到平衡語義特征Fb.在l 層分辨率的特征記作Fl,最低層及最高層特征的索引記作lmin, lmax.Fb的公式如下
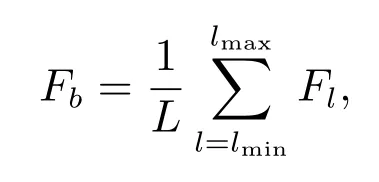
其中L 為金字塔的層數.
為減少平衡語義特征的信息冗余,進一步增強特征表達,本文采用了SE 注意力模塊[14],利用注意力機制對融合特征圖的有效特征進行了加強,并加入了殘差連接,其結構如圖5 所示.通過提取特征圖的通道維度的注意力,關注信息最顯著的組成部分,可以有效地增強平衡語義特征的特征表示.
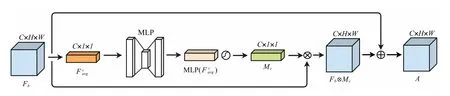
圖5 殘差注意力機制模塊
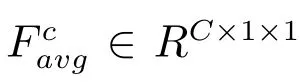

這里σ 表示sigmoid 函數,W0∈RC/r×C, W1∈RC×C/r,表示通道注意力分支中MLP 的權重參數.在上述操作之后,本文將得到注意力圖Mc作用于SE 注意力模塊的輸入特征圖Fb,得到經過注意力機制增強特征表示的A,公式如下
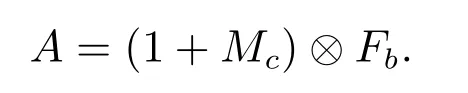
為了將平衡后語義特征信息反饋到每一個層級,將SE 注意力模塊的輸出A 使用相同但相反的過程,重構到與各層級對應相同的尺寸,得到{A2,A3,A4,A5},與{C2,C3,C4,C5}進行加和操作,得到{P2,P3,P4,P5}.其公式表示如下
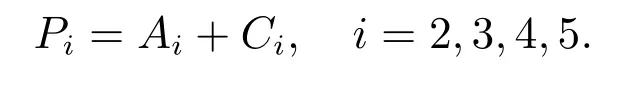
{P2,P3,P4,P5}與{C2,C3,C4,C5}相比,平衡了各層級間的差異性,增強了各層的原始特征.用于后續的目標檢測中,流程和FPN 相同.
4 實驗
本文實驗計算環境:CPU 為Xeon E5-2664 v4 Gold,主頻3.2 GHz,16 核;GPU 為NVIDIA Tesla P100,16 GB 顯存,3584 個核心.采用深度學習開源框架Pytorch1.1.0 進行深度網絡模型訓練和測試.
4.1 數據集
本實驗在PASCAL VOC 2012 和MS COCO 2014 數據集對本文提出的多尺度特征融合網絡進行測試.PASCAL VOC 2012 具有21 個類,訓練集包含5717 張圖像,驗證集包含5823 張圖像.MS COCO 2014 具有81 個類,訓練集包含82783 張圖像,驗證集包含40504 張圖像.
4.2 實驗細節
1) 訓練過程
本實驗使用Faster R-CNN 作為基礎目標檢測結構,使用ResNet 作為特征提取網絡,對所提出的多尺度特征融合網絡進行訓練.在PASCAL VOC 2012 數據集上,本文設置了12 個epoch,betchsize 大小為16,初始學習率為0.02,分別在第8 和第11 個epoch,學習率減小為原來的0.1 倍.在MS COCO 2014 數據集上,除了將初始學習率設置為0.01,其他設置與PASCAL VOC 2012 數據集相同.
2) 模型評估
本文使用MAP(Mean Average Precision)來評估所提出方法的性能,其公式如下
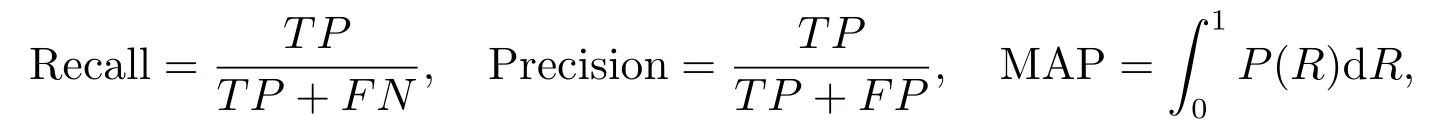
這里Recall(R)是召回率,Precision(P)是精確率,TP 為正樣本被分為正樣本的數量,FN 為正樣本被錯誤地分為負樣本的數量,FP 為負樣本被錯誤地分為正樣本的數量.TP +FN 為全部正樣本數量,TP +FP 全部被分為正樣本的數量.
TP 和FP 根據IOU(Intersection Over Union)閾值來判斷,IOU 公式如下

這里A 表示GT Box,B 表示檢測模型預測的anchor.假設IOU 閾值為0.5,如果IOU >0.5,則樣本為TP,否則為FP.
4.3 實驗結果及分析
在PASCAL VOC 2012 數據集的性能實驗中,本文使用Faster R-CNN 作為基礎檢測器,ResNet 作為特征提取網絡,來評估所提出的模型,使用5717 張圖像訓練模型,5823 張圖像進行測試.表1 顯示出MAP 值在三種深度的ResNet 上均得到了一定的提升,ResNet50、ResNet101 和ResNet152 分別提升1.1%、0.9%和0.6%.MSFFN 與FPN 的識別效果對比如圖6 所示,圖6(b)的小鳥和遠處的船只均被MSFFN 識別,而圖6(a)中FPN 則未檢測出,圖6(c)中左側的酒瓶被FPN 識別出兩個目標框,而圖6(d)中MSFFN 則準確地檢測出酒瓶.實驗說明本文使用注意力機制對FPN 各層特征進行了有效的融合.
為進一步驗證所提方法的性能,本文在MS COCO 2014 數據集上對模型進行測試.MS COCO 2014 數據集包含80 個類,超過80,000 張圖像用于訓練.表2 描述了本文使用ResNet50 和ResNet101 得到的檢測器在驗證集的性能表現.使用ResNet50 時MSF FN 比FPN 在AP@IOU=0.5 上高1.8%,AP@IOU=0.7 上高1%以及AP@IOU=0.5:0.95上高1.2%.使用ResNet101 時MSFFN 比FPN 在AP@IOU=0.5 上高1.6%,AP@IOU=0.7 上高1.2%以及AP@IOU=0.5:0.95 上高1.1%.總的來說,這個數據集上的實驗顯示了所提出的方法在Faster R-CNN 目標檢測網絡中所起到的性能提升作用.
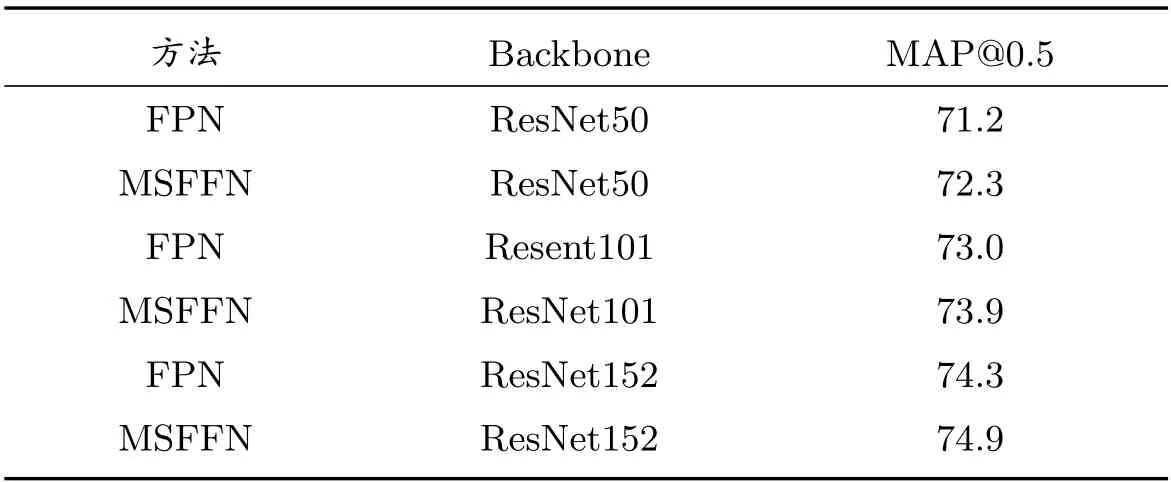
表1 PASCAL VOC 2012 數據集實驗結果
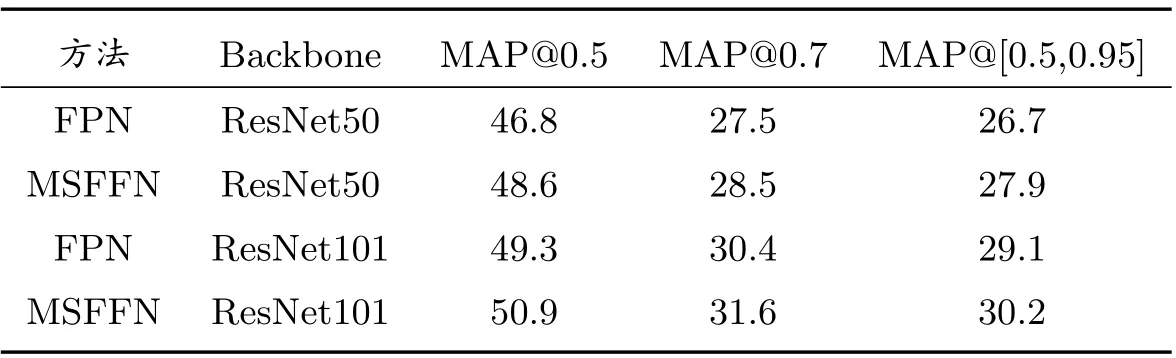
表2 MS COCO 2014 數據集實驗結果

圖6 MSFFN 與FPN 效果對比
5 結論
針對傳統的特征金字塔網絡只能依靠深層語義信息來進行預測,而忽略網絡低層細節信息的不足,本文提出了基于特征金字塔的多尺度特征融合網絡MSFFN.MSFFN 在FPN主干網絡的基礎上,設計了混合特征金字塔MFP 和金字塔融合模塊PFB.為了用低層的細節信息增強特征金字塔,MFP 創建了自下而上的路徑增強.同時,PFB 對各層級的特征進行了融合,并反過來作用于相應層級的特征,來平衡各層級間的差異性,增強了有用特征的表達.之后,在PASCAL VOC 2012 和MS COCO 2014 兩個數據集上進行的實驗證明了MSFFN 對特征融合的有效性.本文提出的多尺度特征融合網絡可以作為提升目標識別與跟蹤、異常檢測和圖像分割等圖像處理與視頻分析算法性能的基本模塊.
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
