以編譯為導向的Matrix-DSP程序分析與優化
2020-11-05 04:43:00荀長慶陳照云孫海燕馬奕民
計算機工程與科學 2020年10期
荀長慶,陳照云,文 梅,孫海燕,馬奕民
(國防科技大學計算機學院,湖南 長沙 410073)
1 引言
數字信號處理器DSP(Digital Signal Processor)在圖形圖像處理、視頻編解碼、工業自動化控制、無人駕駛、雷達信號處理和電子對抗等領域中具有廣泛應用[1]。隨著應用領域更加密集的數據處理需求,新一代DSP的架構設計和計算能力面臨著更高的挑戰。目前主流的DSP芯片大多以單指令多數據SIMD(Single Instruction Multiple Data)+超長指令字VLIW(Very Long Instruction Word)的向量化架構為發展方向,VLIW構架可以大大加強DSP處理器的指令并行能力,而SIMD指令集能夠大幅度提高數據并行處理能力[2]。DSP計算處理能力的不斷提升帶來的重要挑戰就是如何能夠完成應用算法的向量化高效設計與實現。
離開特定的體系結構談程序性能優化往往沒有意義。面向向量化架構DSP的算法設計與優化需要基于向量結構特點和程序特征分析,實現算法的合理劃分映射,并采用多種優化手段,充分挖掘程序中可利用的并行性,提高對存儲層次的利用效率,從而大幅提高程序的執行性能[3]。大型科學計算應用往往包含若干熱點內核程序,其性能優化對整個應用具有巨大提升效果。此外,程序的性能也和編譯器息息相關,要想獲得高效的程序性能,需要對編譯器的優化能力(冗余刪除、計算強度削弱、指令合并與調度、優化范圍擴大等)有一個大致的分析,程序員需要結合編譯器特點來調整向量編程方式,從而最大程度地使編譯器理解程序員的并行優化意圖,使程序員為編譯器提供更多的優化機會[4]。因此,面向DSP的向量化程序設計與優化,與設計高性能DSP具有同等重要的地位,同時也具備相當大的難度和挑戰性。
Matrix是自主研制的高性能數字信號處理器,具有向量處理、SIMD支持和超長指令字的特征。該DSP同時具有標量與向量功能部件,支持定點與浮點計算,在無線通信、科學計算、圖像處理等多個領域具有廣泛應用。本文基于Matrix DSP的體系結構特點,以編譯器特性為導向,梳理內核級程序向量化設計分析與優化的一般步驟,并結合通用矩陣乘GEMM(GEneral Matrix Multiplication)例子進行具體展示,最后對未來優化方向提出思考與討論。
2 Matrix DSP結構特點及向量化編程
作為自主研發的一款高性能DSP,Matrix具有典型的SIMD+VLIW的特征,其內核部分的主要結構如圖1所示。該處理器主要包括標量部件和向量部件,由指令派發部件同時為標量和向量提供指令。標量部件中的標量處理單元SPU(Scalar Processing Unit)主要負責執行串行任務,同時負責對向量部件的控制。而向量部件中的向量處理單元VPU(Vector Processing Engine)主要負責執行計算密集的并行任務。其中向量處理單元采用一種可擴展的運算簇結構,由16個同構向量計算引擎VPE(Vector Processing Engine)構成,每個VPE中包含了3個浮點乘加器MAC,同時支持2個向量的訪存操作(Load/Store)。核內的陣列存儲器AM(Array Memory)可實現16路SIMD寬度的向量數據訪問,為VPU提供較高的訪存帶寬。核內的存儲器直接訪問部件DMA可支持標量和向量的高效數據搬移與供給。整個Matrix采用可變長的VLIW架構,最大可支持11發射(包括標量指令和向量指令),從而最大程度上開發指令級并行與向量部分的數據級并行。
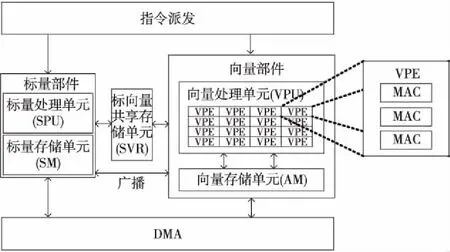
Figure 1 Kernel structure of Matrix DSP圖1 Matrix DSP內核結構
對用戶而言,向量化編程大體上可以分為3種,即自動向量化、手寫匯編和基于向量擴展的高級語言編程。盡管自動向量化技術已經在學術界和工業界經歷了多年的研究與探索,但是其性能還是不甚理想[5]。雖然手寫匯編一定程度上能夠完成高效的算法設計,但是其所需的技術積累、人力成本和開發周期都是極高的。Matrix DSP采用基于向量擴展的C語言方式,在實現整套基于GCC編譯器工具鏈移植的基礎上,提供一系列用于向量操作的內聯函數接口,程序員可以調用向量函數接口,編譯時可以直接將內聯函數映射成向量指令[6]。該方式旨在通過程序員挖掘應用中存在的大量細粒度、同質、獨立的數據操作,并基于向量化架構中的多個浮點運算單元,將上述數據操作通過向量指令實現并發執行,從而顯著提高應用性能。
然而,面向這種基于向量擴展的高級語言若要實現高效編程,需要依賴程序員結合硬件結構的特點完成并行算法映射,同時熟悉編譯器的編譯能力和特性,完成特定高效的編程,來實現應用性能的優化加速。向量化編程對程序員提出了巨大的挑戰,具體包括:
(1)程序員開發時需要顯式接觸硬件體系結構和硬件資源,包括浮點計算單元和數據通路等;
(2)程序員需要進行數據對齊和數據連續排布;
(3)程序員需要完成對應用中并行性的挖掘與探索,并完成面向特定體系結構的映射;
(4)控制流引入的開銷問題;
(5)熟悉編譯器自身的編譯特性與編譯優化能力,采用特定的編程方式為編譯器提供更多優化機會。
結合Matrix DSP體系結構特點,以基于GCC移植的編譯器工具鏈特性為導向,本文將以一個內核級代碼(通用矩陣乘)為示例,對面向Matrix DSP的向量化算法設計分析與優化進行探索,并總結相關經驗和思考。
3 以編譯為導向的程序分析與優化
要實現高效的程序設計與優化往往需要程序員和編譯器兩方面共同配合,一個優秀的程序員可以盡可能降低對編譯器的依賴,而一個高效的編譯器對于程序員編程可提供極大的方便。本文著重基于Matrix DSP體系結構,結合編譯器特性來進行程序分析與優化探索,以通用矩陣乘為示例進行展示,并總結梳理程序向量化設計優化的經驗。
3.1 通用矩陣乘算法并行性分析和基本算法映射
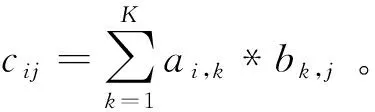
矩陣乘的并行算法有很多選擇,結合Matrix DSP的向量處理單元包含16個VPE的結構特點,可以考慮最樸素的向量化映射方法,即將矩陣B按列劃分,每個VPE處理不同的列數據,從而對應計算出矩陣C不同列的結果。同時,每個VPE中包含3個MAC單元,為了最大化數據并行效率,每個MAC可以再按列進行細粒度的數據劃分,這樣理論上每拍最多同時執行48個浮點乘加運算,將整個核內48個MAC部件全部充分利用。而矩陣A的數據需要16個VPE共享,因此為了提高片上存儲效率,本文將矩陣A的數據存儲在標量處理單元的數據存儲部件SM(Scalar Memory)內,并通過全局共享寄存器廣播給所有的VPE。矩陣B和矩陣C將存放在陣列存儲器(AM)內。
整個Matmult向量化算法映射如圖2所示,具體流程如下:
(1)矩陣A存放在標量數據存儲部件(SM)中,矩陣B和矩陣C保存在陣列存儲器(AM)內;
(2)標量單元將矩陣A元素按行訪存并廣播到16個VPE的向量寄存器;
(3)每個VPE根據按列劃分的矩陣B和矩陣C進行訪存,并與矩陣A廣播的數據進行乘加計算,其中每次乘加計算利用3個MAC同時處理3列數據,16個VPE同時計算48列數據;
(4)將計算結果保存到矩陣C;
(5)循環直至所有結果計算完畢。
圖2只展示了一個VPE內的計算過程,其他VPE內計算過程與之相同。

Figure 2 A basic vectorization algorithm of Matmult圖2 Matmult基本向量化算法
為了最大化內核級代碼計算效率同時避免冗余計算,內核級代碼所計算的數據塊大小同樣需要精心考慮設計。矩陣C的列數N可以設置為48(16 VPE*3 MAC);同時保證數據對齊提高DMA傳輸效率,矩陣A的列數K可以設置為8的倍數(256 bit對齊),而矩陣A的行數M可以參考設置為6(具體原因參見3.2節)。
由于本文聚焦于內核級代碼的程序優化,為了方便后續優化討論,因此假設當前通用矩陣乘內核代碼的規模為:矩陣A為6*512,矩陣B為512*48,矩陣C為6*48,同時所需的數據已經通過DMA搬移到片上,該數據規模不會超過片上存儲容量。整個內核級向量C代碼和部分匯編代碼(即v1版本的Matmult代碼)如圖3所示,匯編代碼共96行,其中最內層循環代碼51行,單次內循環執行周期為64拍,在M7002芯片(Matrix DSP系列的一個芯片產品)上測試其執行時間為198.36 μs,編譯選項統一采用-o2-funroll-loops。

Figure 3 Vectorization code and partial assembly code of Matmult v1圖3 Matmult v1向量化和匯編代碼片段
3.2 代碼重構
通過對圖3中代碼分析可以看出,內循環中因為要完成一個完整的行向量和列向量的相乘累加計算,因此矩陣C在每次循環之間都存在著數據依賴(MatC),導致即使采用了循環展開的編譯選項,仍然無法進行展開優化。從匯編代碼上分析,內循環沒有實現循環展開,循環體內仍然只有3個浮點乘加指令(灰色背景指令),同時VPE中3個MAC并沒有充分并行,導致MAC資源的空閑浪費,整個內循環的指令效率有待提升。
從算法上分析,之所以會出現數據依賴是因為矩陣A按行廣播,內循環需要完成累加計算,因此可以考慮將內外循環進行交換,即進行代碼重構。調整后的算法將矩陣A按列廣播,與矩陣B固定某一行進行對應乘法計算,并將結果累加到矩陣C中對應位置。當矩陣A完成1列數據的廣播,矩陣B只需訪問1行數據,而矩陣C需要完成所有位置的元素累加更新,這樣調整可以最大程度上提高浮點乘加的并行性,具體過程如圖4所示。鑒于指令集浮點乘加指令為6拍,同時為了保證寄存器使用時不溢出,矩陣A列數M可以參考設置為6。代碼重構后內循環不再存在數據依賴,具體內核代碼(即v2版本的Matmult代碼)如圖5所示,整個匯編代碼長度351行,內循環完全展開,整個外循環代碼占307行,單次循環內執行節拍數為309,芯片上測試其執行時間為159.40 μs。
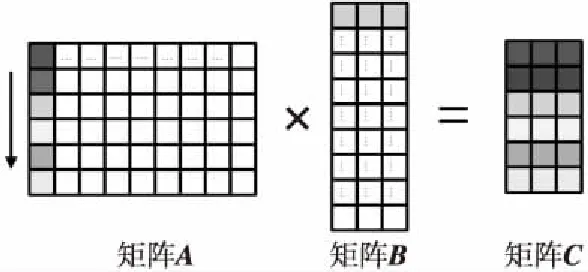
Figure 4 Optimized vectorization algorithm of Matmult圖4 優化后的Matmult向量化算法
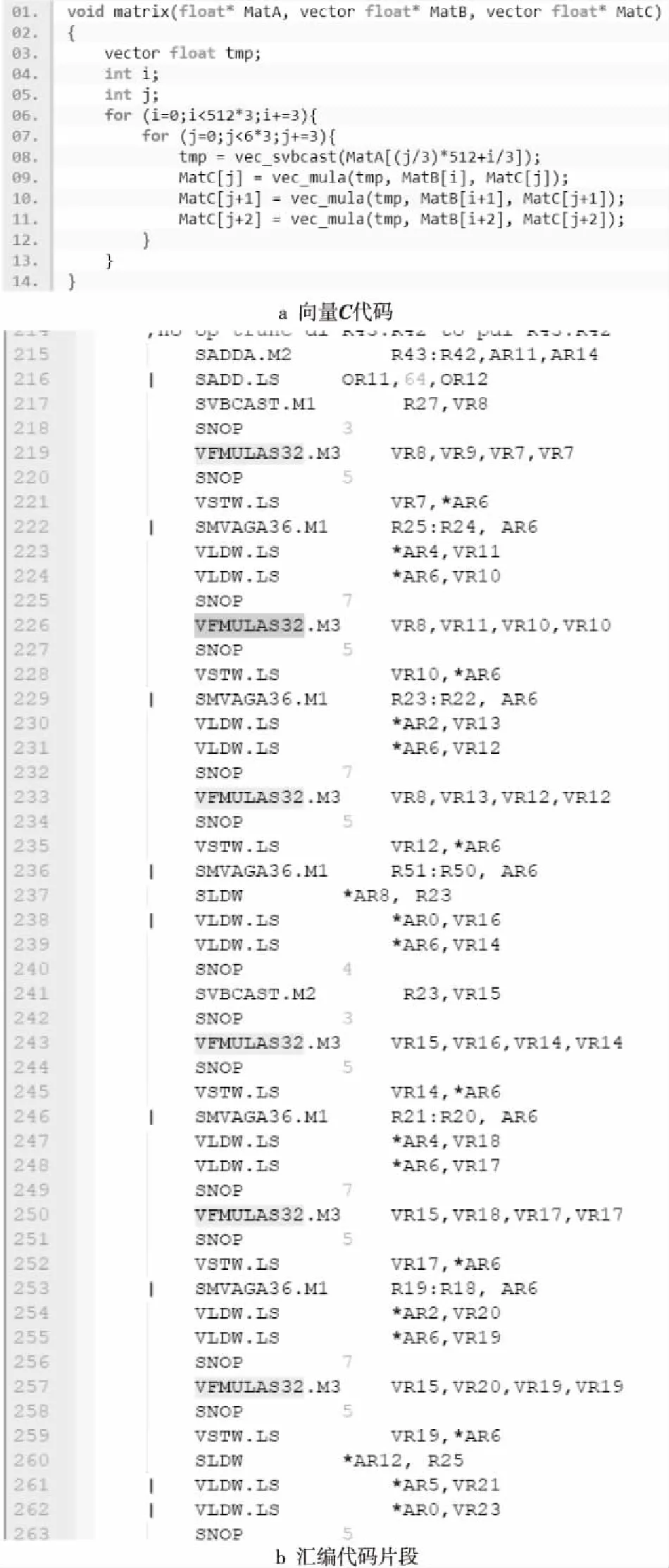
Figure 5 Vectorization code and partial assembly code of Matmult v2圖5 Matmult v2向量化代碼和匯編代碼片段
3.3 計算訪存解耦合
盡管進行了循環展開(從匯編代碼上能看到同時存在多個浮點乘加指令),但在向量C代碼第9~11行的計算過程中,由于單條語句包含了多個訪存(矩陣B與矩陣C)操作,從匯編代碼上看,浮點乘加指令中間存在著訪存指令(VLDW/VSTW)。由于編譯器中指令調度窗口大小有限,導致內循環多條指令的訪存和計算串行執行,每個VPE中3個MAC的利用效率大大下降。大多數編譯器能夠從代碼中提取的并行性信息有限,對一些復雜的處理過程,即使存在并行開發的可能,編譯器也可能無法成功識別,因此需要程序員來輔助編譯器完成并行性的挖掘與利用。
本文采用計算與訪存解耦合的方式來對代碼進行進一步優化,主要方法是將數組訪存的部分從語句中分離出來,單獨用中間變量來保存,并用中間變量替換計算語句中的輸入。此外,本文發現在內循環中矩陣B的數據被反復訪存,但事實上其數據僅依賴外循環,因此將矩陣B的訪存移出內循環,從而進一步提高執行效率。優化后該部分代碼(即v3版本的Matmult代碼)如圖6所示,整個匯編代碼長度為296行,其中循環體占260行,單次循環執行周期為137拍,在芯片上測試其執行時間為70.33 μs。

Figure 6 Vectorization code and partial assembly code of Matmult in v3圖6 Matmult v3向量化代碼和匯編代碼片段
3.4 合并訪存與寄存器優化
通過計算訪存的解耦合,可以發現在內循環中需要對結果矩陣C每個元素進行反復訪存。從匯編代碼上來看,盡管浮點乘加計算指令能夠實現并發,但是整個內循環中訪存指令數目(VLDW/VSTW)較多,而浮點乘加計算指令周期只占整個循環執行周期的13%左右,核心循環的計算效率并不高,訪存的次數為外循環的次數(512次*2,讀寫各一次)。鑒于本文優化的代碼中矩陣C規模較小(每個VPE處理6*3規模的子矩陣),可以考慮通過寄存器來降低訪存的次數,從而實現程序效率進一步提升。
本文將矩陣C中每個元素都在整個循環外賦值給中間變量,并將內循環完全手動展開,在循環內采用中間變量參與乘加計算,在整個循環外再將所有中間變量賦值到矩陣C對應元素的位置上。優化后的代碼只需要對矩陣C中每個元素進行一次讀和一次寫操作,大大降低了訪存開銷,提高了整個代碼的執行效率。該部分代碼(即v4版本的Matmult代碼)如圖7所示,整個匯編代碼共253行,其中循環體占125行,單次循環執行共71拍,在芯片上測試其執行時間為36.12 μs。

Figure 7 Vectorization code and partial assembly code of Matmult v4圖7 Matmult v4向量化代碼和匯編代碼片段
3.5 計算強度削弱:除乘法轉換
為了提高MAC利用率,程序中存在連續3條乘加計算語句,導致圖7a代碼中MatA和MatB的數組下標訪問中用到了整數除法。而除法所需要的執行周期比較長,降低了程序執行效率。如圖8所示,核心循環的匯編代碼中為了實現整數除法,需要進行多次迭代移位(SSHFLL/SSHFAR等移位指令)計算,大大增加了核心循環的指令條數,因此可以考慮用乘法來替換除法計算,削弱計算強度,從而降低冗余的指令數,提高執行效率。

Figure 8 Partial assembly code of Matmult v4圖8 Matmult v4匯編代碼片段
本文將代碼中的循環變量和數組訪問下標都進行調整,把除法計算調整為乘法計算,其過程如圖9所示。編譯器本身具有除乘法轉換的優化功能,但是其主要針對除數為2的整數次冪,可以將除法轉化為移位運算。而對于該優化代碼中除數為3的情形,程序員可以手動調整編程方式,削弱計算強度。由于循環次數較多,循環內微小的優化能夠對程序性能起到重要提升作用,優化后的代碼(即v5版本的Matmult代碼)如圖10所示,整個匯編代碼共230行,其中循環體占83行,單次循環執行共39拍,在芯片上的執行時間為20.27 μs。

Figure 9 Transforming division into multiplication圖9 除法轉換為乘法

Figure 10 Partial assembly code of Matmult v5圖10 Matmult v5匯編代碼片段
3.6 手動軟件流水優化
從代碼中可以發現,單次循環內的訪存、廣播與計算具有嚴格的數據依賴,無法進一步挖掘并行性。但是,每次循環迭代之間可以通過重疊執行來提高程序性能,充分利用處理器的所有資源。雖然循環展開之后一定程度上可以提高代碼的并行執行效率,但是被展開循環之間的界限仍然為代碼移動設置了障礙,同時大幅增加了整個代碼的長度。因此,本文考慮采用軟流水來充分釋放循環間的并行性,同時生成高效緊湊的代碼。
循環內的主要執行過程包括矩陣B的訪存、矩陣A的廣播和矩陣C的乘加計算。顯然訪存與廣播之間沒有數據依賴,可以并發執行,但計算則依賴于訪存與廣播的結果。同時不同循環間由于需要進行累加計算,因此第i+1次循環的訪存與廣播的數據寫入不能早于第i次的乘加計算的數據讀取。通過分析可以發現,不同循環間可能存在的并行性就是通過細粒度排布使得第i次乘加計算與第i+1次訪存和廣播部分重疊執行,同時還要嚴格保證數據讀取和寫入的順序。調整后的代碼還需要在循環外增加進入穩定循環態前后的額外部分。由于數據間的依賴約束比較嚴格,而高級語言編程無法完全細粒度地進行指令排布,只能將盡可能優化的空間展示給編譯器,由編譯器進一步完成。在進行手動軟流水優化之后,整個匯編代碼長度為274行,其中循環體占76行,單次循環執行周期為27拍,代碼在芯片上的執行時間為14.09 μs。
3.7 優化手段總結與評測
結合程序自身并行性和編譯器自身特性,本文采用了一系列程序優化手段不斷提升其執行性能。具體包括:
(1)代碼重構:即根據應用本身特性對算法進行合理的向量化映射調整,能夠盡可能挖掘程序自身的并行性,充分利用硬件體系結構的計算資源。
(2)計算訪存解耦合:為了提高代碼中可并行性的挖掘與利用,盡可能將每一條語句功能簡單化,將同一條語句中的計算和訪存解耦合出來,為編譯器優化提供盡可能充足的空間。
(3)合并訪存與寄存器優化:降低訪存次數或對訪存進行隱藏是程序優化的重要手段。程序員在編程時需要利用數據可重用性來減少非必要的訪存次數,同時多采用寄存器來提高對體系結構存儲層次的利用。
(4)計算強度削弱:對于類似除法的計算,可以考慮將其手動或自動轉換為等價且計算強度更低的運算來替代,從而提高程序執行效率。
(5)軟件流水:除了挖掘單次循環內的程序并行性,還可以嘗試分析不同循環迭代間的數據依賴,并通過軟件流水來實現循環間的重疊執行,從而大幅提高程序性能。
上述優化手段并沒有特定的使用約束,程序員可結合自身程序特性進行分析與調整。通過應用上述多種優化手段,本文以通用矩陣乘的內核級程序為例,將其執行性能從原始向量化版本的198.36 μs優化到14.09 μs,最高提升了1個數量級,其主要影響因素取決于單次循環體內的執行節拍數。各個優化版本的執行時間和性能提升如表1所示,數據均來自于實際M7002芯片級測試,采用的編譯選項為-o2-funroll-loops。最終優化前后編譯生成的匯編代碼VLIW指令調度如圖11所示,可以看出整個代碼調度更加緊湊高效。

Figure 11 VLIW scheduling diagram for the kernel loop in Matmult v1 and Matmult v6圖11 Matmult v1和Matmult v6版本核心循環代碼的VLIW指令調度圖

Table 1 Summary of optimization tips and results表1 各版本采用的優化手段與優化效果匯總
4 思考與討論
面向特定體系結構實現高效的程序設計與優化本身就具有很大的挑戰,而這其中需要程序員和編譯器的共同協作,相輔相成。同樣地,基于Matrix DSP開發高效的向量化應用或程序,除了上述總結的常用優化手段可以借鑒參考,本文也提出了對編譯器未來優化方向和程序員的高效程序設計的一些思考和探索。
從編譯器的角度來說,可以考慮從以下幾個方面來進一步優化和提升,從而降低程序員編程的難度:
(1)自動向量化。Intel早在1996年就開始推出SIMD的向量指令擴展,并持續推進自動向量化的研究,即用戶仍然采用串行思想進行編程,利用編譯器中的自動向量分析器(auto-vectorizer)對代碼進行分析并生成SIMD指令。自動向量化對用戶編程極為友好,但是對編譯器的挑戰極大,目前自動向量化的效果不是特別理想,或者仍然需要程序員提供一些并行性提示來輔助編譯器挖掘代碼中的并行性。
(2)并行編程模型或編譯制導。為了能夠給編譯器提供更多優化的可能,編譯制導語句可以從開發者的角度提供給編譯器更多編譯期間無法提取的信息,提高編譯器將代碼向量化的概率。主流的并行編程框架OpenMP和OpenACC都是采用這種方式,只需要在程序中增加#pragma的語義提示,編譯器就可以識別并對該部分代碼進行并行優化[7 - 9]。另一種就是類似CUDA的編程模型,用戶可以任意組織線程的層次結構和每個線程所執行的kernel計算,然后輕松映射到任意型號的GPU設備。
(3)軟件流水,指令打包與調度。由于大部分應用領域代碼的內核代碼都是以循環為主,因此循環的優化對整個程序的性能起到重要作用。而軟件流水功能是循環性能提升最關鍵因素之一,因此使編譯器實現對循環的自動軟流水,是一個重要的研究方向[10]。同樣地,對于Matrix DSP的VLIW結構,指令調度和打包直接影響計算部件的利用率和程序的并行性,也同樣是編譯器自身性能的核心因素。
(4)大規模庫函數開發。為了進一步拓展Matrix DSP的軟件生態,尤其是拓展更多的應用領域,各類庫函數是必不可少的。而庫函數通常充分挖掘了指令集的特性,具有較高的計算效率。通過庫函數的開發可以給用戶提供高級語言接口調用,而將底層硬件信息隱藏,給用戶更接近行為體驗的語法,但是大規模庫函數的開發需要極大的人力與時間代價。
從程序員的角度來說,要想設計高效的向量化代碼,除了上述通用的優化手段和編譯器的輔助,還需要從以下幾點進一步挖掘與提升:
(1)用向量化的思想來完成程序算法分析和面向體系結構的映射。一方面要求程序員充分分析與挖掘應用算法的并行性,另一方面需要對體系結構的硬件資源具有清晰的把握。然后以特定的編程方式完成算法到體系結構的映射,盡可能提高硬件資源利用率和算法的并行性,這本身就是一項極難的挑戰。
(2)嘗試利用內存層次來提高數據訪問效率。一般來說硬件體系結構會具有多個存儲層次,例如寄存器、Cache、memory等。程序員需要考慮將不同的數據排布到不同的存儲空間,盡可能利用數據重用來降低數據訪存開銷,或將長距離的訪存延遲進行隱藏,例如常用的雙緩沖機制。針對規模較大的數值算法,進行合理的數據塊劃分往往需要綜合考慮數據供給的速率和計算部件消耗數據的速率,從而實現較優的計算資源利用率和程序執行性能。
5 結束語
本文面向Matrix DSP架構,以編譯器性能為導向,對向量化內核程序的分析與優化進行了一系列的梳理與總結,包括代碼重構、計算訪存解耦合、合并訪存與寄存器優化、計算強度削弱和軟件流水等手段。通過運用上述優化手段,將一個通用矩陣乘的內核代碼執行性能提升了1個數量級。在程序優化與總結的基礎上,圍繞Matrix DSP的高效編程,進一步從編譯器優化和程序員算法設計2個角度,提出了一些思考和討論。未來將沿著該方向持續開展面向Matrix DSP的程序高效分析與優化工作。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
電信科學(2016年10期)2016-11-23 05:11:56
現代企業(2015年2期)2015-02-28 18:45:09
