GPU上典型存儲器難散列函數的優化
2020-11-05 04:43:08韓建國
計算機工程與科學 2020年10期
關鍵詞:方法
陳 虎,韓建國
(1.華南理工大學軟件學院,廣東 廣州 510006;2.廣東省科技基礎條件平臺中心,廣東 廣州 510006)
1 引言
在口令安全機制中,往往基于一般散列函數構造特定的口令散列函數。在設置口令時,口令驗證方計算并存儲用戶口令明文對應的口令散列函數值(密文),從而避免口令明文的泄露。在驗證口令時,口令驗證方計算用戶輸入口令對應的口令散列函數值并與存儲的密文進行對比。在恢復口令時,可以并行計算多個口令明文的散列值,并與待猜測的密文比較。因此,口令散列函數的計算性能成為口令攻防兩方面的關鍵性問題。可以使用MD5[1]、SHA1[2]等簡單散列函數作為口令散列函數,其計算過程較為簡單,但難以抵抗較大規模的口令攻擊。也可以使用PBKDF2[3]等構造口令散列函數,其通過多次迭代簡單散列函數以增加計算量,但是此類計算密集型的散列函數易于在FPGA、ASIC等專用硬件上[4,5]并行計算多條口令明文的散列函數實例,具有較高的性能,對口令安全構成潛在威脅。
存儲器難散列函數(Memory-Hard Hash Functions)[6]具備抗ASIC攻擊的能力,有望成為新型的口令散列函數。這類散列函數在執行過程中需要較大的存儲器容量,而且計算和訪存的比例相近。這使得ASIC上實現該類函數面臨困難:如果將散列函數計算所需要的存儲器都放置在ASIC芯片上,將占用大量的晶體管,從而降低芯片的計算能力;如果采用片外存儲器存儲,芯片的存儲器訪問帶寬可能會成為系統瓶頸,而且存儲器訪問的功耗依然與傳統的CPU/GPU系統相當[7]。
得益于強大的計算能力和完整的生態環境,高性能的通用GPU[8,9]是當前口令恢復的主要硬件平臺。hashcat[10]、John the Ripper[11]等高效的口令猜測軟件對傳統的口令散列函數進行了深入的優化,具有很高的執行效率,但是在GPU上優化實現存儲器難散列函數的方法還沒有得到深入的研究。
本文主要研究利用GPU體系結構的特點提升存儲器難散列函數計算吞吐率的方法。GPU的片上存儲器容量非常有限,難以在片上存放這些散列函數所需要的存儲空間。但是,GPU提供了很高的存儲器訪問帶寬和較大容量的全局存儲器,可以在全局存儲器中存放存儲器難散列函數所需要的內容。為了更有效地發揮GPU潛在的計算能力,本文一方面研究了存儲器難散列函數的數據布局,以提升存儲器的訪問效率;另一方面利用GPU上多線程間寄存器交換數據的方法,使多個線程協作執行同一個散列函數實例,從而增加線程的數量,更好地隱蔽存儲器的訪問延遲,提升吞吐率。
本文以經典的存儲器難散列函數Scrypt[12]為例說明了GPU上優化實現方法,并使用該方法優化實現了較為復雜的存儲器難散列函數Argon2d[13]。與hashcat的實現方法相比,本文提出的優化方法使得Scrypt的性能提升了2.03倍。
本文第2節介紹存儲器難散列函數和GPU體系結構的基本特點;第3節介紹對Scrypt的優化實現方法;第4節討論Scrypt性能測試結果,并簡要介紹Argon2d算法的性能,說明本文提出的方法可以優化多種存儲器難散列函數;第5節總結了本文的工作。
2 相關工作
2.1 存儲器難散列函數
存儲器難散列函數的主要特征包括:(1)每個實例執行過程中需要占用較大容量的存儲器,其存儲器容量參數往往可以配置,從數百K字節到數G字節不等。從口令安全的實際應用場景看,其存儲器容量往往介于數百K字節至數M字節。(2)可以分為獨立型和依賴型2種。前者的存儲訪問地址序列固定,與輸入的明文無關,具有較好的抗側信道攻擊能力,但由于地址序列固定,可以通過預先優化存儲器布局獲得較高的計算性能[14,15]。后者的存儲器訪問地址依賴于散列函數的輸入明文,事先難以確定存儲器訪問的地址序列,這使得系統實現更為困難。(3)散列函數執行過程中計算和訪存比例較為接近,在實現的過程中如果減少內存的使用量,則會顯著增加計算量。這個特征使得在ASIC上使用較少的片上存儲器壓縮存儲變得得不償失。
典型的存儲器難散列函數包括Scrypt、Argoon2、Lyra[16]和Ballon[17]等,其中Scrypt是出現較早的存儲器難散列函數,目前已經成為RFC標準[18]。Argon2是2015年口令散列函數競賽[19]的優勝者,包含依賴型和獨立型2種類型:Argon2d和Argon2i。Argon2原理較為復雜,限于篇幅,本文僅介紹Scrypt的原理。
Scrypt的配置參數包括:CPU/存儲器開銷參數N、塊大小r、并行度p和輸出長度dkLen,輸入包括口令pwd和鹽salt。Scrypt的原理如圖1所示,分為3個步驟:
(1)使用PBKDF2_HMAC_SHA256(pwd,salt,p×128r)生成p個128r字節的初始數據塊,分別作為p個線程的輸入B。
(2)p個線程使用ROMix算法分別填充p塊容量為N×128r字節的存儲器,并迭代得到128r字節的結果B′。
(3)對p個結果使用PBKDF2_HMAC_SHA256生成長度為dkLen位的散列函數值。
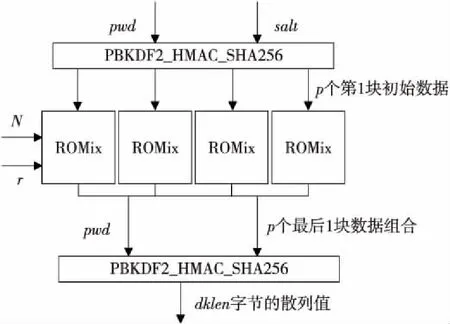
Figure 1 Structure of Scrypt圖1 Scrypt結構
ROMix算法包含了N個128r字節塊構成的數組V,其中第1塊V0由PBKDF2_HMAC_SHA256()所產生的1個128r字節塊B初始化。在第1階段(第2~4行)中,Scrypt按照順序依次使用BlockMix算法填充數組V,其中Vi僅僅依賴于Vi-1。在第2階段(第5~7行)中,第6步的Integerify函數取X的最后64字節作為一個小端對齊的整數,并由此隨機選擇V中的一個塊,在第7步中更新X。經過N次迭代后,得到128r字節的輸出B′。ROMix算法依賴關系如圖2所示,其中X0,…,XN-1對應算法1中第7步X在第i次循環時的值,節點之間的實線為必然的依賴關系,虛線為隨機的依賴關系。
算法1ROMix算法
Input:B,r,N。
Output:B′。
1:X←B;//X為中間變量
2:forifrom 0 toN-1do
3:Vi←X;
4:X←BlockMix(X)
5:endfor
6:forifrom 0 toN-1do
7:j←Integerify(X) modN;
8:X←BlockMix(X^Vj);
9:endfor
10:B′ ←X;
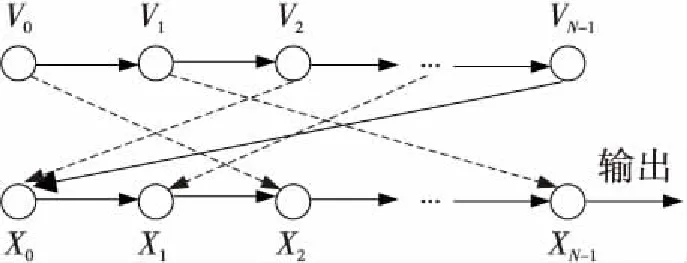
Figure 2 Dependency graph of ROMix圖2 ROMix算法的數據依賴圖
BlockMix算法由Salsa20/8散列函數派生得到,其輸入和輸出都是2r個64字節的數據塊,如算法2所示。
算法2BlockMix算法
Input:2r個64字節的數據塊B0…B2r-1。
Output:更新后的2r個64字節的數據塊B′0…B′2r-1。
1:X←B2r-1;//X為中間變量
2:forifrom 0 to 2r-1do
3:T←X^Bi;//T為中間變量
4:X←salsa20/8(T);
5:Yi←X;//Yi(0≤i≤2r-1)為中間變量
6:endfor
7:B′←(Y0,Y2,…,Y2r-2,Y1,Y3,…,Y2r-1)
存儲器難散列函數Scrypt具有以下特點[12]:
(1)在串行隨機訪問的計算機上,需要的存儲空間為O(N),計算次數T(N)=O(N)。
(2)在具有S*(N)=M(N)個處理器和S*(N)存儲空間的并行隨機訪問計算機上,算法執行時間T*(N)=O(N2/M(N)),即SN(N)×T*(N)=O(N2)。
Scrypt的主要特點是計算次數和所需要的存儲器容量成正比,且在并行計算機上其時空乘積為O(N2),這使得它在并行計算機上的速度提升無法按照硬件資源的數量增加呈線性關系。
2.2 GPU體系結構特點
與CPU相比,GPU使用了更多的晶體管構造計算單元,片上存儲器容量非常小。GPU中包含了多個流多處理器組SM(Stream Multiprocessors),每個SM包含了多個計算單元、64~192 KB的共享存儲器/Cache和大容量的寄存器文件。一個SM上可以同時并發運行多個輕量級線程,并且零開銷實現線程切換。
NVIDIA公司的GPU采用了單指令多線程SIMT(Single Instruction Multiple Threads)[8]的并行方式,即多個線程執行相同的指令,但是使用不同的數據。SM調度的基本單位是由32個線程構成的warp,同一個warp的所有線程執行相同的指令。同一warp內的線程可以使用混洗指令直接交換數據,無需訪存存儲器,執行開銷很小。一個warp執行高延遲的訪存指令時,將會掛起直至訪存指令結束。在此期間,執行算術邏輯指令的其他warp仍可以并發執行,可以在一定程度上隱藏內存訪問的延遲。
GPU訪問全局存儲器的基本單位[20]是以128字節為單位的區段。一個warp的32個線程可以同時訪問32個不同地址。如果這32個地址均處于一個區段內,一次全局存儲器訪問就可以滿足這個訪問請求。如果這32個地址分散在m個區段,則需要m次全局存儲器訪問,存儲器訪問效率降低為1/m。
3 GPU上Scrypt算法的優化
存儲器難散列函數在執行過程中使用的內存容量較大,同時伴隨著大量的訪存操作。需要優化全局存儲器的數據布局,提高存儲器帶寬的利用率。與此同時,口令恢復過程可以并行執行多個散列函數實例。如果一個GPU線程計算一個散列函數實例,由于受到顯存大小的約束,GPU中線程數量受限,難以隱藏存儲器訪問帶來的延遲。
本文采用多個線程協作計算一個散列函數實例的方法,使得在同樣散列函數實例的情況下,具有更多的工作線程,更為有效地隱藏存儲器訪問延遲。
3.1 2種存儲器布局
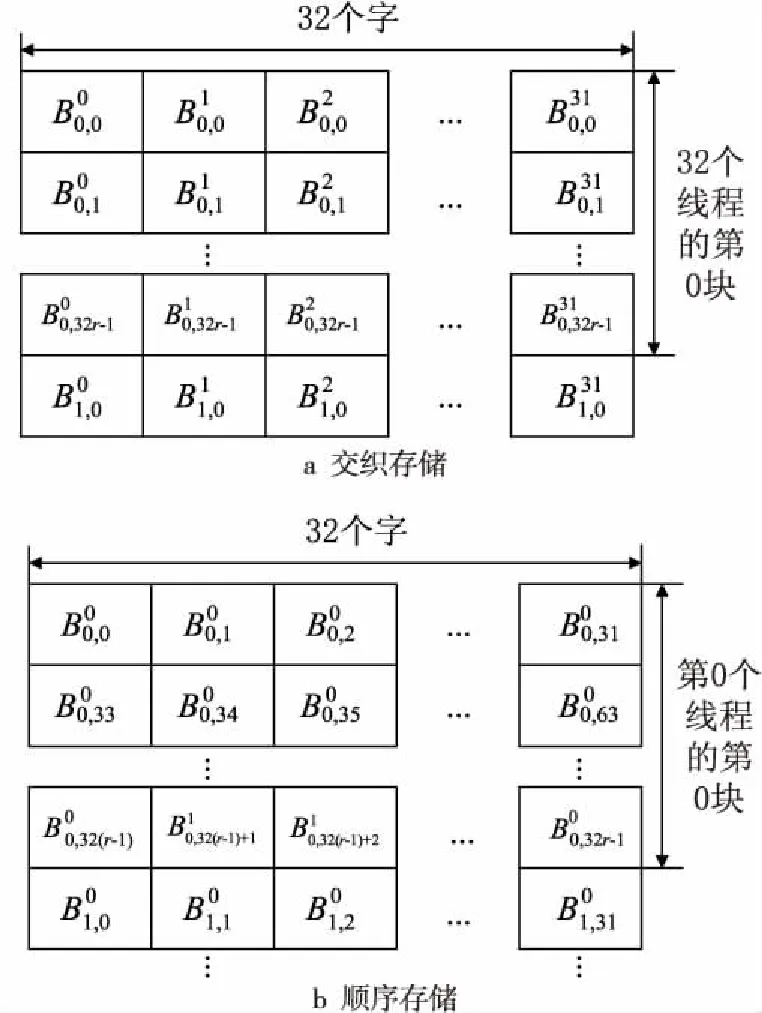
Figure 3 Two storage methods圖3 2種存儲方式
在交織存儲方式中,每個warp交織存儲32個線程的內容,即不同線程的相同位置的字連續存放。在順序存儲方式中,同一個線程對應數據連續存放,不同線程的存儲區域不發生交疊。對于一個warp中第t個線程的第i個塊的第j個字,交織存儲的地址AI和順序存儲的地址AN的計算方法分別如式(1)和式(2)所示:
AI(t,i,j)=32×(32r×i+j)+t
(1)
AN=32r×N×t+32r×i+j
(2)
其中,0≤t≤31,0≤i≤N-1,0≤j≤32r-1。
交織存儲方式中,一個warp中的32個線程同時計算32個Scrypt散列函數實例,且每個線程按照32位無符號整數的方式并行訪問存儲器。ROMix算法的第1階段,32個線程發出的存儲器訪問地址處于一個128字節的區段中,GPU的帶寬利用率為100%。但是,在第2階段中,32個線程可能訪問不同的塊,導致32個地址處于不同的區段中。在最壞的情況下,所需要讀取的數據分布于32個不同的區段,此時存儲器帶寬的利用率僅為1/32。
在順序存儲方式中,每個線程計算一個Scrypt實例且僅使用32位存儲器訪問時,存儲器帶寬利用率為1/32。為了避免這個問題,可以使用16字節的存儲器訪問。CUDA的程序設計指導[20]指出,如果warp中每個線程均訪問16個字節存儲器,則GPU產生4個存儲器訪問請求,且每個請求完成8個線程的存儲器訪問。如果這8個線程計算不同的實例,其地址將處于不同的區段,在Scrypt的2個階段中存儲器帶寬的利用率均為1/8。
3.2 多線程協同計算
由于GPU的顯存容量有限,在N較大的情況下,可以同時支持的Scrypt散列函數實例數受到限制,導致能并發計算的線程數有限,從而影響系統的吞吐率。為此,本文考慮4個線程協同計算1個散列函數的實例。
Scrypt的主要計算基于散列函數Salsa20/8[21],其偽代碼如下所示,其中R(d,s)表示對32位無符號整數d循環右移s位。
算法3Salsa20/8
{//b0…b15:16個32位的字輸入

//x0,…,x15:16個中間變量
1:x0…x15←b0…b15;
2:forifrom 0 to 3do
3:x4^=R(x0+x12,7);x8^=R(x4+x0,9);
4:x12^=R(x8+x4,13);x0^=R(x12+x8,18);
5:x9^=R(x5+x1,7);x13^=R(x9+x5,9);
6:x1^=R(x13+x9,13);x5^=R(x1+x13,18);
7:x14^=R(x10+x6,7);x2^=R(x14+x10,9);
8:x6^=R(x2+x14,13);x10^=R(x6+x2,18);
9:x3^=R(x15+x11,7);x7^=R(x3+x15,9);
10:x11^=R(x7+x3,13);x15^=R(x11+x7,18);
11:x1^=R(x0+x3,7);x2^=R(x1+x0,9);
12:x3^=R(x2+x1,13);x0^=R(x3+x2,18);
13:x6^=R(x5+x4,7);x7^=R(x6+x5,9);
14:x4^=R(x7+x6,13);x5^=R(x4+x7,18);
15:x11^=R(x10+x9,7);x8^=R(x11+x10,9);
16:x9^=R(x8+x11,13);x10^=R(x9+x8,18);
17:x12^=R(x15+x14,7);x13^=R(x12+x15,9);
18:x14^=R(x13+x12,13);x15^=R(x14+x13,18);
19:endfor
20:forifrom 0 to 15do
}
上述函數可以分為2段:第1段是第3行到第10行,第2段是第11行到第18行。將16個中間變量劃分為{x0,x4,x8,x12},{x1,x5,x9,x13},{x2,x6,x10,x14}和{x3,x7,x11,x15}4個集合。基于此數據劃分,第1段的16個移位/加法操作可以按照下述計算次序由4個線程分4步并行完成:〈x4,x9,x14,x3〉,〈x8,x13,x2,x7〉,〈x12,x1,x6,x11〉,〈x0,x5,x10,x15〉。同理,第2段的計算過程中,4個線程使用的數據集合分別為{x0,x1,x2,x3},{x4,x5,x6,x7},{x8,x9,x10,x11},{x12,x13,x14,x15},并行計算次序為:〈x1,x6,x11,x12〉,〈x2,x7,x8,x13〉,〈x3,x4,x9,x14〉,〈x0,x5,x10,x15〉。由此可以看出,可以使用4個線程同時完成一個Salsa20/8散列函數的計算。需要設計中間變量x0, …,x15的存儲布局和交換方法,使得每個線程分別包含4個局部變量,并行執行第1段操作,然后進行一次數據交換,再并行執行第2段操作。
在GPU中可以使用共享存儲器或warp混洗函數實現同一個warp內多個線程間數據交換。共享存儲器分為16個存儲器體,如果1個warp中的16個線程同時訪問不同體,可以達到共享存儲器體的最大訪問帶寬。可以將協同計算同一個實例的4個不同線程的中間變量x0, …,x15分布到不同的存儲器體上,并精心排布第2段計算的次序(如圖4所示),使得4個協作線程在整個Salsa20/8計算過程中不發生體沖突,但是這將引入比較復雜的地址計算。另外一種方法使用了NVIDIA公司特有的warp混洗函數實現同一個warp內的多個線程間快速數據交換。測試表明,使用warp混洗函數的性能稍高于使用共享存儲器的性能,這可能是因為共享存儲器地址計算的開銷和較高的存儲器訪問延遲導致的。因此,本文在NIVIDIA公司的GPU上使用了混洗函數。在不支持warp混洗函數的其他類型GPU上可以考慮采用局部存儲器的交換方法。
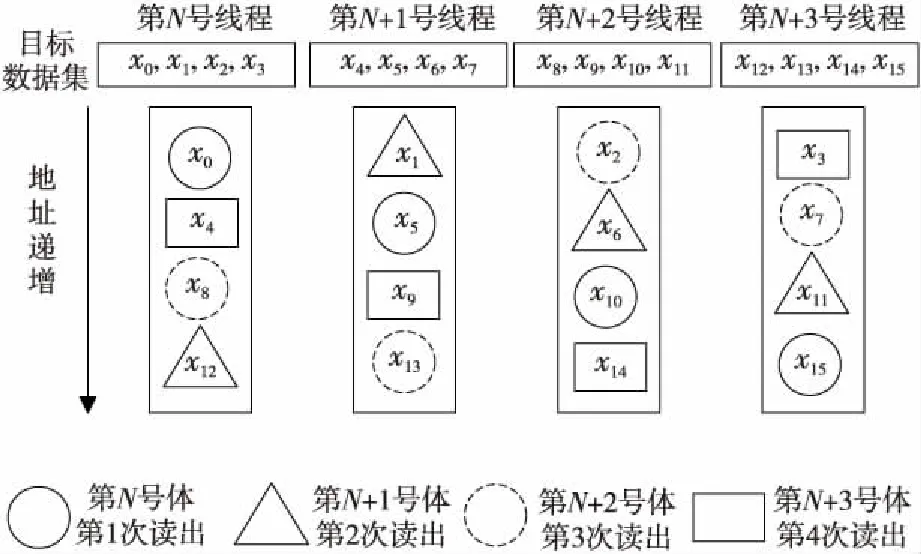
Figure 4 Layout of intermediate variables in Salsa20/8圖4 Salsa20/8中間變量的存儲布局
4 測試與分析
本節在GTX TITAN X上進行性能測試,其硬件參數如表1所示。測試主要包括3個方面:(1)在(N,p,r)=(1024,1,1)的參數配置下,比較交叉存儲、單線程順序存儲和4線程順序存儲3種方法實現Scrypt的性能;(2)上述3種方法實現Argon2d的性能;(3)所需存儲容量變化時,散列函數的性能。
在 (N,p,r)=(1024,1,1)情況下,3種不同方法實現Scrypt性能如表2所示,其中hashcat使用了單線程順序存儲方法。由表2可以看出,4線程順序存儲方法具有最高的性能,是hashcat實現方法的2.03倍。

Table 2 Scrypt performance of three different methods(N=1024, p=1, r=1)表2 3種不同方法的Scrypt性能(N=1024,p=1,r=1)
Argon2d也是一種典型的存儲器難散列函數,其主要配置參數包括:并行度p,存儲器容量m,迭代次數T。一個Argon2d實例所需要的存儲容量為1204mp個字節。它在填充存儲器階段采用基于blake2b[22]的壓縮函數。與Salsa20/8類似,該函數可以由4個線程并行實現,也可以使用本文所述的4線程順序存儲方法。表3給出了3種方法的性能比較,可以看出,4線程順序存儲方法的性能是交織存儲方法性能的310%。

Table 3 Argon2d performance of three different methods(m=64, p=1, T=1)表3 3種不同方法的Argon2d性能(m=64,p=1,T=1)
當N=1024時,一個Scrypt散列函數的實例需要128 KB的全局存儲器容量。在總容量為12 GB的顯存中,約有8~9 GB存儲器可供使用。在此配置下,4線程順序存儲方法可以使用的線程數為252K個,每個SM容納2K個線程。
受到顯存容量的限制,當N增加時,單個GPU上可以并行計算的實例數(線程數)也在不斷下降,如表4和圖5a所示。在Scrypt散列函數中,N增加一倍,計算和訪存的數量也都相應增加一倍。在理想的情況下,N增加一倍,計算性能應降低一半。但是,實際性能降低的速度遠遠高于50%。例如,在N=2048時,計算性能僅為N=1024時性能的12.65%。發生這種情況的主要原因是GPU中對全局存儲器訪問的延遲高達200~400個周期,需要依賴大量計算密集型的線程隱藏存儲器訪問導致的延遲。但是,N(單個實例的內存使用量)增加時,可以并行計算的線程數隨之減少,降低了對存儲器訪問的隱藏能力,導致系統資源利用率和吞吐率顯著下降。

Table 4 Scrypt performance with different storage capacity (p=1, r=1)表4 Scrypt散列函數存儲容量變化時的性能(p=1,r=1)
與Scrypt類似,在其他參數不發生變化時,Argon2d的存儲容量增加一倍,其計算量和存儲器訪問量也增加一倍,理論計算性能應該降低一半。存儲器容量發生變化時,Argon2d在GPU上的性能如表5和圖5b所示。在單個實例的存儲器容量從128 KB增加到256 KB時,其性能下降為128 KB時性能的25.71%。可以看出,在GPU上執行這一類存儲器難散列函數的最重要問題是顯存容量有限,導致可以運行的線程數受限,從而降低了GPU利用計算過程隱藏存儲器訪問的能力,影響了系統的資源利用率和吞吐率。
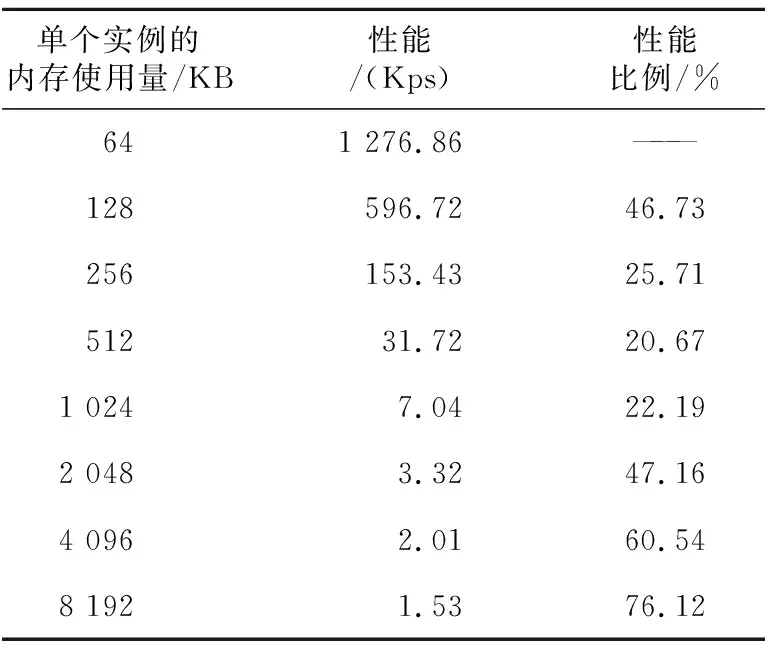
Table 5 Argon2d performance with different storage capacity (p=1, T=1)表5 Argon2d散列函數存儲容量變化時的性能(p=1,T=1)
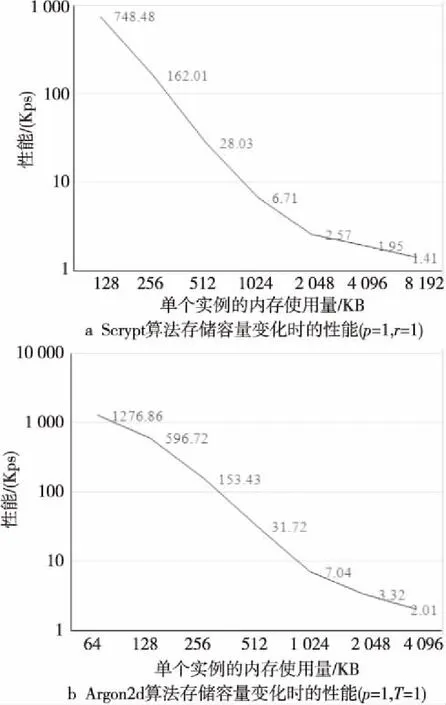
Figure 5 Performance vs storage capacity of Scrypt and Argon2d圖5 存儲容量變化時Scrypt和Argon2d的性能
在GPU上使用4線程協同計算和順序存儲方法計算存儲器難散列函數,具有以下優點:(1)在相同的顯存容量下,相對于1個線程計算1個實例,4個線程同時計算1個實例使得可以并發執行的線程數量增加4倍,增加了系統的并發能力。(2)在Salsa20/8的計算過程中,每個線程僅僅使用了4個32位字保存中間變量,寄存器使用量控制在32個字,提高了SM的使用率。(3)每個線程都使用16個字節的存儲器訪問而且采取了順序存儲方式,此時每個存儲器請求包含了8個線程的存儲器訪問。由于使用了4個線程同時計算一個實例,存儲器帶寬利用率也從原有單線程模式的1/8提高到50%。
5 結束語
由于抗ASIC的特征,存儲器難散列函數很有可能成為未來的口令散列函數。本文以典型的Scrypt和Argon2d為目標,研究了GPU上存儲器難散列函數的性能優化方法,比較和分析了交織存儲和順序存儲2種方法的存儲器帶寬利用率,指出使用16字節存儲器訪問和順序存儲方法可以更有效地利用GPU的存儲器帶寬。同時,本文提出了使用多個線程協作計算一個散列函數實例并使用warp間混洗函數交換數據的方法,有效減少了每個線程占用的資源,增加了可以并行運行的線程數量,更為有效地隱藏了存儲器訪存的延遲,并將存儲器訪問帶寬的利用率提高到50%,較hashcat中的Scrypt實現,性能提升了2.03倍。
本文還使用4線程順序存儲方法實現了較為復雜的Argon2d散列函數,對于Argon2d依然具有較好的性能,說明了其對于不同存儲器難散列函數的適應性。
本文比較了2種存儲器難散列函數在不同存儲器容量需求下性能的變化情況。實驗表明,由于顯存容量有限,可以并行執行的散列函數實例受到約束,減少了GPU上可以并發執行的線程數,使計算操作難以隱藏存儲器訪問延遲,從而降低了資源利用率,在GPU上執行散列函數的性能大幅度下降。
如何克服顯存容量的瓶頸,保持可以并行工作的線程數量將是后續在GPU上優化實現存儲器難散列函數的主要問題。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
