天河超級計算機上超大規模高精度計算流體力學并行計算研究進展
2020-11-05 06:09:46徐傳福車永剛李大力王勇獻王正華
計算機工程與科學 2020年10期
徐傳福,車永剛,李大力,王勇獻,王正華
(1.國防科技大學高性能計算國家重點實驗室,湖南 長沙 410073;2.國防科技大學計算機學院,湖南 長沙 410073;3.國防科技大學氣象海洋學院,湖南 長沙 410073)
1 引言
計算流體力學CFD(Computational Fluid Dynamics)通過數值求解各種流體動力學控制方程,獲取各種條件下的流動數據和作用在繞流物體上的力、力矩和熱量等,從而達到研究各種流動現象和規律的目的。CFD是涉及流體力學、計算機科學與技術、計算數學等多個專業的交叉研究領域。隨著高性能計算機的飛速發展,CFD研究和工程實踐都取得了很大進步,20世紀90年代以來,基于雷諾平均Navier-Stokes方程求解的CFD技術已經廣泛應用于航空、航天、航海、能源動力、環境、機械裝備等諸多國民經濟和國防安全領域,取得了很好的應用效果。在航空航天領域,CFD已逐漸成為與理論分析、風洞實驗并列的流體力學3大主要方法之一。美國國家航天局(NASA)預測,21世紀,高效能計算機和CFD技術的進一步結合將給各類航空航天飛行器的氣動設計帶來一場革命[1]。
高性能計算技術的迅猛發展為大規模復雜CFD應用提供了重要支撐,當前,CFD已經成為高性能計算機上最重要的應用之一。隨著應用問題復雜度的增加,CFD要求的幾何外形、數值方法、物理化學模型等也日益復雜、精細,對大規模計算提出了更高要求。CFD對大規模計算的需求可以從能力計算(Capability Computing)和容量計算(Capacity Computing)2方面概括。容量計算指的是利用超級計算機同時完成大批量生產性業務,在CFD中通常用于復雜工程問題的設計與優化,例如飛行器全包線數據庫生產等。有學者在1997年估計,商業飛機巡航一秒鐘的計算,用每秒萬億次計算機需要數千年,高保真度全包線氣動數據庫的生產被認為是CFD一個長期的重大挑戰問題[2,3]。能力計算通常指的是利用超級計算機全系統計算能力求解單個大型任務,在CFD中通常用于簡單外形、復雜流動問題的基礎研究,例如采用直接數值模擬開展湍流流動機理研究等。據美國波音公司Tinoco博士2009年估計,以當時高性能計算機的發展速度,直到2080年左右才可能進行民航客機全機的DNS模擬;即便是進行大渦模擬也要等到2045年左右[4]。
CFD巨大的計算量對于超級計算機研制和超大規模并行計算研究提出了迫切需求,異構并行架構是當前構建超大規模高性能計算機系統的重要技術途徑之一[5]。異構超級計算機主要包括異構加速器和異構眾核2種實現方式。例如,我國的天河系列超級計算機采用了異構加速器,其中天河一號的加速器為通用GPU(Graphics Processing Unit),而天河二號的加速器為Intel集成眾核MIC(Many Integrated Cores)(升級后的天河二號采用了國產加速器Matrix2000);神威太湖之光則采用了“申威26010”異構眾核處理器,每個處理器包括4個主計算核,每個主計算核配有一個8×8的計算陣列(64個從計算核)。在2020年6月發布的世界超級計算機排行榜(TOP500)中,排名前10的超級計算機有8臺是異構超級計算機。異構超級計算機具有明顯的性能價格比、性能功耗比等優勢,但異構超級計算機具有異構的計算、存儲和通信能力以及編程環境,極大增加了高效、大規模CFD應用軟件開發的難度。在CFD應用領域,傳統CPU平臺并行計算主要采用分區并行方法,每個分區獨立進行求解,利用消息傳遞通信實現分區之間的任務并行以及共享存儲實現單個分區內部的線程并行[6 - 9]。異構超級計算機具有多層次、多粒度的異構并行性,應用并行性開發需要同時利用消息傳遞任務級并行、計算結點內CPU與加速器之間的協同并行、CPU/加速器上的共享存儲線程級并行和CPU/加速器上的向量化指令級并行,需要針對異構并行體系結構特征,設計多層次可擴展并行算法,才能實現CFD應用、算法與并行體系結構的“最佳適配”,充分挖掘超高性能計算機潛力。
國防科技大學不僅是我國高性能計算機系統研制的基地,也是我國高性能計算應用軟件研發的基地。長期以來,國防科技大學CFD應用軟件團隊依托天河/銀河系列超級計算機開展了超大規模復雜CFD并行計算和性能優化研究,突破了異構協同并行計算等關鍵技術,實現了HPC與CFD的深度融合,有力支撐了我國幾套重要的In-house CFD應用軟件在天河/銀河系列超級計算機上的大規模并行計算。本文歸納總結了作者團隊基于自主高精度CFD軟件,面向航空航天氣動數值模擬,在天河超級計算機上開展的超大規模高精度CFD并行計算研究,并對未來E級超級計算機上CFD并行應用開發進行了分析展望。
2 研究現狀
近年來,隨著P級超級計算機的研制成功,歐美日等發達國家在這些最高端的計算平臺上針對湍流等復雜流動機理研究開展了超大規模CFD并行計算。例如,2013年,德克薩斯州州立大學研究人員實現了P級高雷諾數槽道流的直接數值模擬,并行規模達到約78萬處理器核[10]。瑞士蘇黎世聯邦工學院、IBM蘇黎世實驗室等單位聯合完成了基于有限體積法的無粘可壓兩相流模擬,最大網格規模達13萬億網格點,獲得了11PFLOPS的持續性能,達到系統峰值性能的55%,該項工作獲得了2013年度戈登·貝爾獎[11]。
高性能異構并行體系結構發展至今,很多學者在GPU、MIC等異構超級計算機上開展了大規模CFD異構并行計算研究,取得了不錯的加速效果。GPU出現的早期,研究人員通常僅移植一些簡化的CFD代碼,以二階精度和一些簡單的流動問題模擬為主,計算平臺通常也僅包含1塊或幾塊GPU卡。通過早期實踐驗證GPU計算的加速效果后,大規模GPU異構并行逐漸成為CFD并行計算研究的熱點。例如,Jacobsen等[12]實現了一個支持GPU集群的不可壓CFD求解器,在美國國家超級計算應用中心的Tesla集群上利用64個結點(共128塊Tesla C1060 GPU卡)進行了測試,相對于8 CPU核獲得約130倍的加速比。他們同時在256塊GPU上開展了頂蓋方腔管道湍流的大渦模擬[13],采用了1維區域分解,對比了MPI+OpenMP+CUDA 并行和MPI+CUDA并行實現,但實際上他們的工作并未實現CPU-GPU協同,OpenMP僅用于代替結點內MPI通信。作者團隊在天河一號超級計算機上設計了基于MPI+CUDA+OpenMP的CPU-GPU異構協同并行算法,成功實現了當時世界上最大規模CPU-GPU協同并行高精度計算,模擬了三段翼構型高精度氣動聲學問題和大型客機C919的高精度氣動力預測問題,問題規模達8億網格單元,并行規模達1 024個計算結點[14 - 17]。MIC架構產品的出現晚于GPU,相關CFD問題應用優化與并行算法研究工作相對較少。德國宇航中心于2011年啟動了名為“面向眾核架構的CFD代碼高效實現HICFD(Highly Efficient Implementation of CFD codes for HPC many-core architectures)”的研究項目[18],面向眾核高性能計算機研究新的方法與工具,最優地利用系統的全部并行層級,包括在最高層使用MPI,在眾核加速卡級使用高度可擴展的MPI/OpenMP混合并行,在處理器核級高效利用SIMD部件。隨著天河二號超級計算機的發布,作者團隊又開展了MIC平臺上CFD并行計算和性能優化研究,設計了基于MPI+Offload+OpenMP+SIMD的CPU-MIC異構協同并行算法,實現了數十億網格規模的可壓縮拐角直接數值模擬,并行規模擴展到百萬異構計算核心[19 - 24]。
整體而言,國內多數CFD并行計算規模為數十到數百核,與國外相比仍然有較大差距。長期以來國內多數CFD軟件更加關注CFD自身的專業性,與高性能計算機系統的研制相互脫節,CFD軟件適應新型高性能并行體系結構的能力較弱,迫切需要開展CFD算法、應用和系統的深度融合研究,充分發揮新一代超級計算機系統的潛能。
3 CFD方法、軟件和計算平臺
3.1 數值方法和軟件
這里以一個In-house多區結構網格高精度CFD軟件為例,簡要介紹高精度CFD數值方法和軟件實現。直角坐標系下強守恒形式控制方程表示為:
上述方程通過坐標變換(x,y,z,t)→(ξ,η,ζ,τ)轉換為曲線坐標下方程:
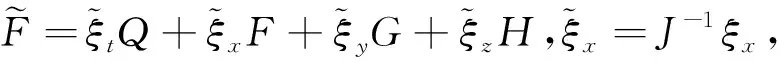
該結構網格高精度CFD軟件中實現了WCNS(Weighted Compact Non-linear Scheme)[25]、HDCS(Hybrid cell-edge and cell-node Dissipative Compact Scheme)[26]等我國自主發展的有限差分高精度計算格式,這里以5階顯式WCNS格式WCNS-E-5沿方向無粘通量導數離散為例,其內點格式可以表示為:
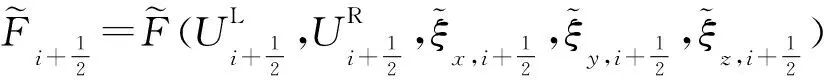
高精度CFD軟件計算流程如圖1所示。迭代(定常時間步迭代或非定常子迭代)開始施加邊界條件,之后交換虛網格單元和奇異網格單元原始變量值,接著在計算和交換原始變量梯度之前計算譜半徑增量和時間步。WCNS、HDCS等高精度格式在右端項(粘性項和無粘項)計算中實現,右端項計算結果也需要進行交換。軟件中實現了常見的LU-SGS、PR-SGS等隱式方法以及顯式Runge-Kutta方法,求得守恒變量增量后更新原始變量及殘差,循環結束。
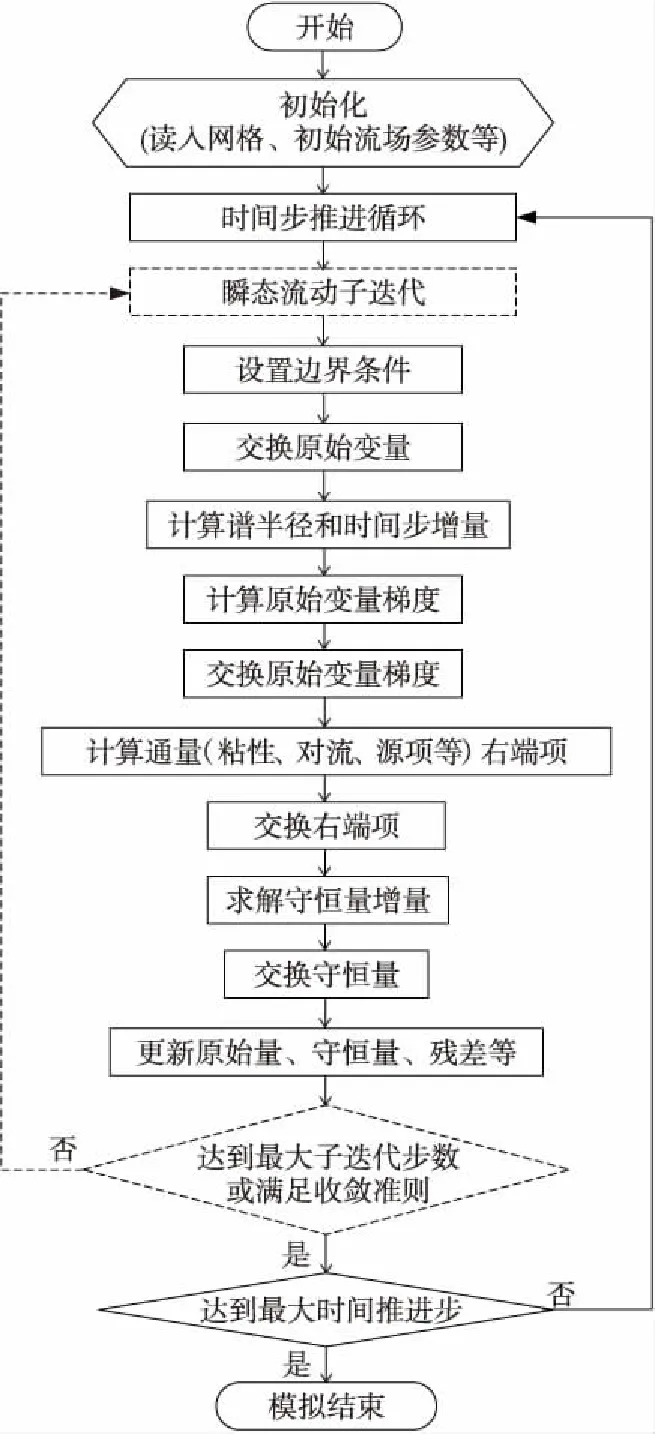
Figure 1 Flowchart of the structured high-order CFD圖1 高精度結構網格CFD軟件計算流程
3.2 異構計算平臺
圖2給出了采用加速器的異構計算平臺。圖2中每個計算結點包含若干共享內存的多核CPU,計算結點間通過高速互連網絡進行通信,每個計算結點包含若干加速器ACC(ACCelerator),加速器通常具有片上存儲,通過PCI-e與CPU進行數據交互。以天河一號為例,每個計算結點包含雙路Intel Xeon X5670 CPU和1個NVIDIA Tesla M2050 GPU;天河二號每個計算結點則包含雙路Intel Xeon E5-2692 v2 CPU和3塊MIC協處理器(Intel Xeon Phi 31S1P)。圖2同時給出了異構計算平臺各層次對應的編程模型。計算結點間通常采用消息傳遞接口MPI(Message Passing Interface)實現分布式并行,計算結點內各CPU核上通常采用OpenMP實現共享存儲并行。不同加速器通常需要采用不同的編程模型,既有GPU專用的CUDA和MIC專用的Intel OffLoad編程模型,也有同時支持GPU、MIC等多種計算平臺的OpenACC、OpenMP4.X等編程模型。CFD應用只有綜合利用上述并行編程模型,才能實現多層次并行算法。
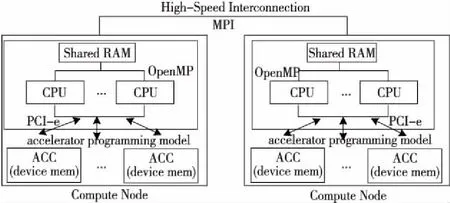
Figure 2 Accelerator-based heterogeneous computing platform and its programming models圖2 加速器異構計算平臺及其編程模型
4 超大規模異構協同并行計算
4.1 異構并行區域分解
區域分解是開展并行算法設計的第1步。圖3以三維多區網格CFD計算為例,給出了支持多層次異構協同并行算法的區域分解示意圖。圖3中CFD流場區域首先根據負載均衡策略劃分為多個網格塊(為了滿足大規模并行計算及其負載均衡需求,通常需要對原始生成的單塊或多塊網格進行二次剖分),每個MPI進程負責1個包含若干網格塊的分組,為了簡化編程,通常1個計算結點分配1個MPI進程。結點內網格塊分組需要根據CPU和加速器的計算、存儲能力在兩者之間進行均衡分配,考慮到編程復雜度和PCI-e通信開銷等,通常以整個網格塊作為分配單位。對于CPU或MIC,每個網格塊內沿著特定維度劃分為數據片(data chunk)分配給計算核實現OpenMP線程并行。MIC計算核較多,網格塊規模較小或所劃分的維度網格單元均較小時,可以采用嵌套OpenMP對網格塊的第2個維度進行進一步劃分。在CPU或MIC上,針對每個線程處理的數據片內的網格線可以實現向量化并行。
GPU上的任務分配則較為復雜。圖3中給出了一種2層分配策略,由于當前GPU均支持流處理,首先將網格塊分配給GPU流實現GPU上的任務級并行;進一步,在每個網格塊內,若CFD算法模型在計算中各網格單元沒有依賴關系,則可以設置三維的GPU線程塊,每個GPU線程處理1個網格單元。如果某一維度網格單元之間存在依賴關系,則可以考慮采用二維GPU線程塊。作者團隊在天河一號上針對多區結構網格高精度CFD軟件實現了這種2層策略,這種方法不僅可以充分挖掘GPU的多層次并行,同時可進一步利用流處理對GPU計算的區塊進行分組,克服了GPU存儲空間小對計算規模的限制,實現了CPU與GPU之間負載的靈活控制(CPU計算能力弱但存儲容量大,GPU計算能力強而存儲空間小)。
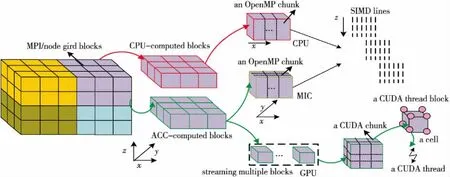
Figure 3 Domain decomposition for multi-level heterogeneous collaborative parallel computing圖3 多層次異構協同并行區域分解示意圖
在區域分解過程中,網格剖分通常采用獨立的工具實現,CPU或加速器上的計算任務分配需要在CFD求解器代碼中實現。與同構CPU平臺相比,異構并行平臺對區域分解和負載均衡提出了更新的要求。例如,為了更好的負載均衡,異構計算結點通常要求剖分的網格塊更多,考慮到加速器豐富的并行能力,分配給加速器的網格區塊又不宜太小。
4.2 異構協同并行
異構加速器極大地提升了異構超級計算機整體性能。以天河一號為例,每個計算結點CPU雙精度浮點性能約140 GFLOPS,GPU雙精度浮點性能約500 GFLOPS,在異構超級計算機上開展大規模CFD計算不僅需要用好CPU,更需要用好加速器,使得兩者能夠實現高效協同并行。本文歸納總結了2種協同并行模式[14]:基于嵌套OpenMP的協同和基于ACC異步執行的協同,如圖4所示。以每個計算結點配置1個加速器、網格包括NBLKCOMS個分塊為例:基于嵌套OpenMP的協同首先在CPU上創建第1層2個OpenMP線程,其中第1個線程控制編號為[1,ACC_BLOCK_NUM]的分塊在ACC上的計算,在第2個線程內創建嵌套OpenMP線程,啟動其他CPU核計算編號為[ACC_BLOCK_NUM+1,NBLKCOMS]的分塊。基于ACC異步執行的協同則利用了加速器異步編程模型和異步調度執行機制,CPU主線程異步啟動ACC計算任務后,控制權立刻返回CPU主線程,此時啟動CPU上的多線程計算。在上述2種模式中CPU與ACC上都能夠同時運行計算任務,從而實現協同并行。CFD計算過程通常涉及邊界處理、邊界數據交換等操作,為了保證CPU上具有最新的計算結果,協同并行結束時需要在CPU與ACC之間進行數據傳輸、同步等。
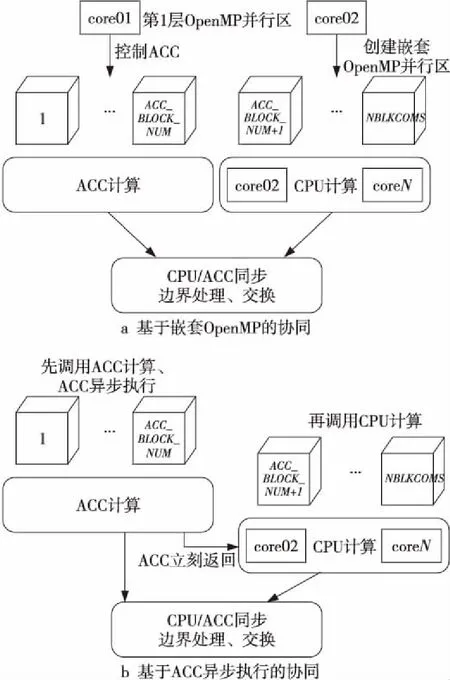
Figure 4 Two heterogeneous collaborative parallel modes圖4 2種異構協同并行模式
上述2種協同并行模式編程實現均較為簡單,目前GPU、MIC等異構加速器及CUDA、OpenMP4.X、OpenACC異構編程模型都支持異步執行和數據傳輸,開發人員可以在實際CFD程序中實現2種并行模式后針對不同的算例測試異構協同并行效果。盡管理論上基于ACC異步執行的協同并行似乎較為高效(無需專門留出CPU核控制ACC,所有CPU核均可參與計算),但在作者過去的實踐中,基于嵌套OpenMP的協同并行效果更佳。
4.3 GPU并行
MIC上的OpenMP并行與CPU上的類似,這里重點介紹作者團隊針對多塊網格CFD計算提出的2層GPU并行算法[14]:網格區塊內基于CUDA的細粒度數據并行算法和網格區塊間基于CUDA流處理機制的粗粒度任務并行算法,如圖5所示。圖5左邊給出的多塊網格CFD計算過程包含nblk個網格分塊的塊循環(block-loop),以及(K,J,I)三維大小為(NK,NJ,NI)網格分塊(虛邊界擴充ngn個網格單元)內的單元循環(cell-loop);右邊給出了2層并行算法實現的偽代碼,其中對網格區塊的循環(block-loop)和對網格單元的循環(cell-loop)分別映射到CUDA中的流處理循環(stream-loop)和CUDA計算核函數(CUDA kernel),這里假設GPU流的數量為num_stream。
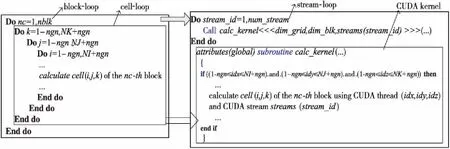
Figure 5 Schematic diagram of two-level GPU parallel algorithm for multi-block structured CFD圖5 多區結構網格CFD計算2層GPU并行算法示意圖
細粒度并行算法根據CFD不同計算過程所包括的循環內部對網格單元的處理是否具有數據依賴關系而設計。對于網格單元間完全獨立的計算過程(例如Jacobi迭代、譜半徑計算等),網格區塊采用三維分解,計算過程實現為三維的CUDA kernel,根據索引每個GPU線程可獨立計算1個網格單元。對于網格單元間存在依賴關系的計算過程(例如各方向的無粘、粘性通量計算),由于CUDA不支持全局線程同步,因此可以采用二維分解,實現為二維CUDA kernel,每個GPU線程計算1條網格線。
在多區網格CFD中,任意2次流場邊界信息交換之間的不同網格分區之間的計算是獨立的,可以并行處理。CUDA通過流處理(Streaming)機制支持任務級并行,允許用戶將應用問題分為多個相互獨立的任務,每個任務或者流定義了一個操作序列,同一流內的操作需要滿足一定的順序,而不同流則可以在GPU上亂序執行。粗粒度并行算法將每個GPU流綁定到一個網格區塊,同時在GPU上執行多個GPU流,實現多個網格區塊的并發處理。流機制的引入一方面滿足了應用問題多層次并行性開發的需求,另一方面很好地適應了GPU的硬件資源特點,提高了資源利用效率。在多GPU流處理機制上進一步設計了分組多流機制GBMS(Group-Based Multiple Streams)[14,15],圖6a給出了多GPU流并發處理多個區塊時的狀態圖,可以看出多GPU流能夠重疊多個分區的拷入、計算和拷出,隱藏CPU和GPU間數據傳輸開銷;圖6b GBMS將4個流/分區分為2組,這種方式可有效克服天河一號Tesla M2050存儲容量小的限制,允許GPU計算更多網格區塊。
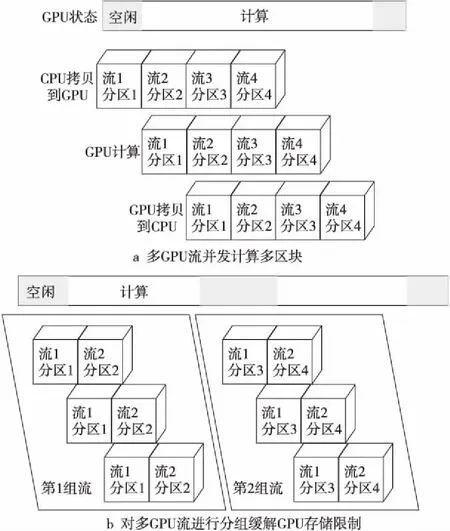
Figure 6 Schematic diagram of multi-stream parallel execution and GBMS for 4 grid blocks圖6 4個分區時多流并發執行和分組多流并行示意圖
4.4 OpenMP并行
若計算過程中網格單元之間沒有依賴關系,則網格分區內的OpenMP并行可以通過沿著網格單元循環(通常為最外層循環)添加OpenMP編譯指導語句實現,較為簡單,本節重點介紹作者團隊針對CFD中常用的具有強數據依賴關系的Gauss-Seidel迭代類算法(例如LU-SGS)改進的共享存儲并行算法。以三維結構網格為例(如圖7所示),在LU-SGS算法向前(下三角矩陣)掃描時,網格點(i,j,k)的更新計算需要依賴小號鄰居點(i-1,j,k)、(i,j-1,k)和(i,j,k-1)的更新值,反之向后(上三角矩陣)掃描過程中則需要依賴大號鄰居點(i+1,j,k)、(i,j+1,k)和(i,j,k+1)的更新值。由于這一數據依賴特點,無法直接添加OpenMP指導語句實現LU-SGS的共享存儲OpenMP并行。

Figure 7 Data dependence in forward computing of LU-SGS algorithm 圖7 LU-SGS算法向前掃描時的數據依賴關系
為了實現LU-SGS的OpenMP并行計算,NASA等機構的學者提出了對角-超平面和流水線2種并行算法[32,33],主要思想是開發LU-SGS算法中各個不同網格面和網格線上計算沒有依賴關系的網格點進行并行計算。在早期的多核處理器上,流水線LU-SGS并行算法取得了很好的并行加速比,然而我們的測試分析表明,在MIC新型眾核加速器上,228線程時并行效率急劇下降到25%以下,對于較小規模的算例甚至低至1%以下。其原因在于流水線并行效率受流水線建立和排空過程的限制。隨著流水線深度(線程數)增加,流水線建立和排空的開銷也隨之增加。對于外層循環長度小于流水線深度的網格塊而言,甚至沒有足夠的計算任務充分填充所有的流水線級。另一方面,隨著線程數的增加,各個線程上的計算負載均衡性也會越來越差。
為了破解傳統流水線并行LU-SGS在MIC加速器上的并行擴展性瓶頸,作者團隊針對三維網格(3個維度記為K、J、I,KmJn指的是K、J維的第m、n個網格單元)提出了一種改進的基于線程嵌套的2層流水線并行LU-SGS算法(簡稱TL_Pipeline[22 - 24]),如圖8所示。其基本思想就是通過將原來的1條長流水線(深度為dp)轉換成相對較短的2條嵌套的流水線,從而進一步開發原先每個線程上二維子任務(子平面)內蘊含的并行性。TL_Pipeline外層(第1層)流水線的深度為dp1,在每個流水線階段內又包含1個嵌套深度為dp2的內層(第2層)流水線,并且dp1×dp2=dp。其中內層流水線是在Jsub子平面上構造的,子任務中Jsub維各網格線組成流水線任務隊列,每一條網格線沿著I維靜態地剖分成dp2個子網格線。圖8給出的是算法的負載剖分和任務調度示意圖,其中dp1和dp2均為4,即共有16個并行線程。以第1層流水線的K4J1子任務為例,該子任務將進一步被劃分為若干更細粒度的子任務JmIi(i=1,2,3,4),然后在內層流水線上進行調度執行。
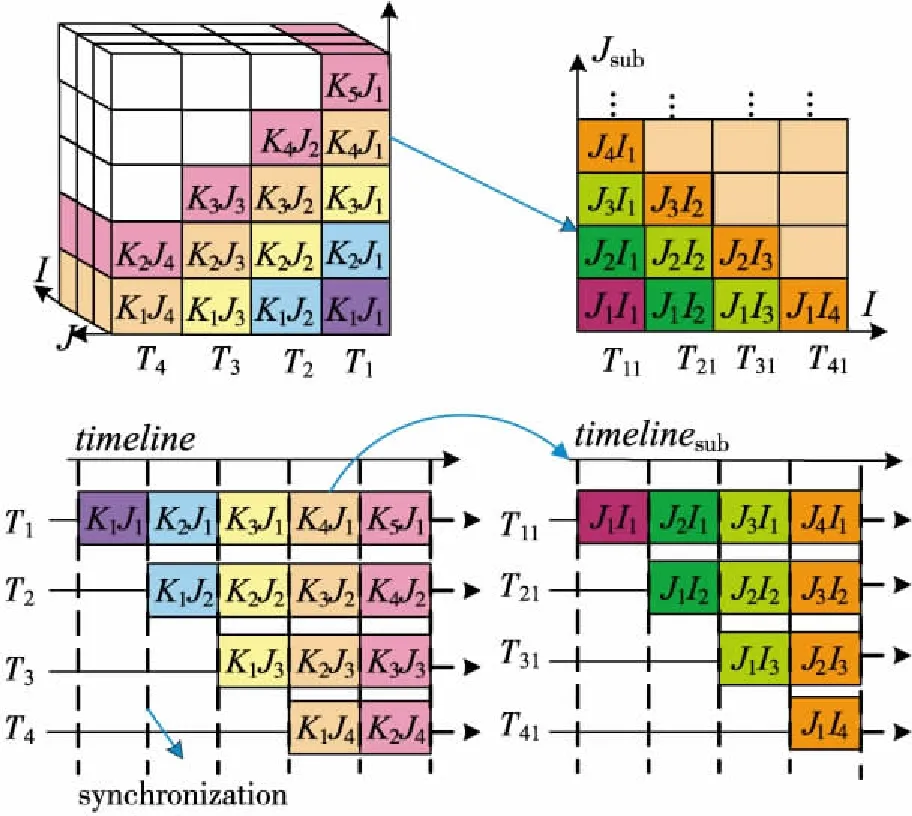
Figure 8 Illustration of task decomposition and execution timelines for the pipeline approach (left) with 4 threads/pipeline-stages,and the two-level pipeline approach (right) with 4 threads/pipeline-stages in the sub-pipeline圖8 4個線程/流水段時傳統流水線方法(左)和兩層流水線方法(右,子流水線也包含4個流水段)的任務分解和執行過程
4.5 向量化并行
當前很多CPU和加速器(例如MIC)均采用了寬向量設計(例如天河二號CPU的雙精度向量寬度為4,MIC 的雙精度向量寬度為8),如果沒有充分利用向量化并行,則應用的實際浮點性能將下降為峰值性能的1/v(設v為向量寬度)。對于一些復雜的CFD計算過程,直接添加向量化指導語句難以實現編譯器自動向量化或者向量化效率較低,需要對CFD計算及訪存特征等進行深入分析,必要時對數據結構進行重構并采用intrinsic向量化指令實現高效向量化并行。這里簡單介紹一下作者團隊針對高階精度有限差分格式WCNS在MIC架構上開展的向量化并行化研究[34]。
圖9給出了5階顯式WCNS格式(WCNS-E-5) 半節點重構模板計算特點。測試表明,250萬網格規模時半節點重構計算約占了總計算時間的1/3,說明這部分是整個計算的性能熱點。作者團隊采用MIC平臺特有的intrinsic向量化指令對WCNS-E-5代碼進行了重寫,使用的 intrinsic 語句主要包括_mm512_load_pd(對齊取數據,可一次訪存取8個雙精度浮點,有效降低訪存次數)、_mm512_fmadd_pd/_mm512_fmsub_pd(乘加/乘減,可通過運算指令融合提升性能)、_mm512_storenrngo_pd(對齊寫數據,將向量寄存器的8個雙精度浮點數寫入內存不緩存,對于只寫訪問有很好的Cache優化效果)等。此外,為了使WCNS-E-5更好地適應向量化計算,還對相關數據結構做了相應的調整。如圖10所示,首先將數據結構由結構體數組AOS(Array Of Structure)調整為數組結構SOA(Structure Of Array)形式,使得數組能夠大跨度地連續訪問;其次為了訪存的對齊,對原數組做擴充填補,保證數組的對齊(只寫)訪問。
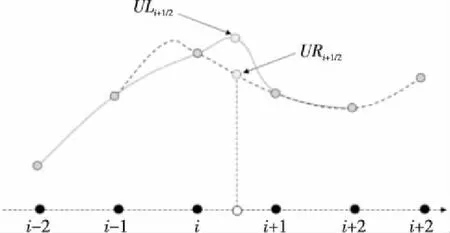
Figure 9 WCNS-E-5 interpolation template圖9 WCNS-E-5插值模板
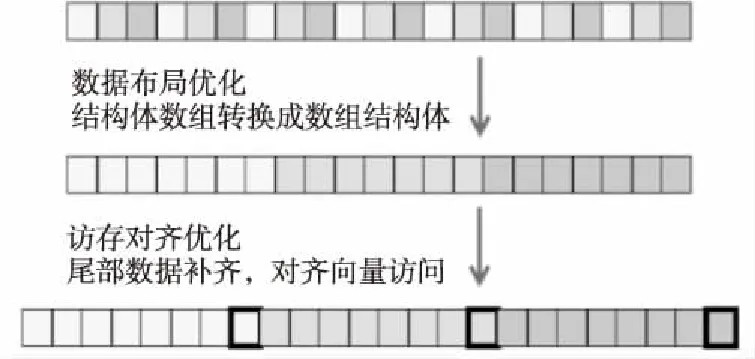
Figure 10 Data structure adjustment圖10 數據結構調整
4.6 實驗結果
本節將給出在天河系列超級計算機上的部分測試結果。首先定義協同效率CE(Collaborative Efficiency)以評估CPU-GPU協同并行中的效率損失:
其中,SPCPU和SPGPU分別是僅實現CPU和GPU并行時的加速比,SPCPU+GPU是CPU-GPU協同并行獲得的加速比(以SPCPU作為基準)。例如,SPCPU+GPU=1.8,SPGPU=1.3時,協同效率CE為1.8/(1.0+1.3)×100%≈78.3%,意味著協同并行中的效率損失約為22%。
表1給出了天河一號超級計算機的單塊Tesla M2050 GPU上不同流實現策略時的加速比。網格規模固定為128×128×128,網格分區數由2增加到8,以單流實現的性能作為基準。可以看出,采用CUDA多流在GPU上同時執行多個網格分區可提升25%~30%的性能。由于CPU-GPU同步以及一些變量的PCI-e傳輸,GBMS有一定的額外開銷,相對于多流有一定的性能損失(最多28%左右),但作者團隊設計的GBMS策略可以將高精度CFD軟件運行在單個M2050 GPU上的最大模擬容量從2百萬網格單元提升到4百萬網格單元,這為后續CPU-GPU協同并行的負載均衡奠定了基礎。
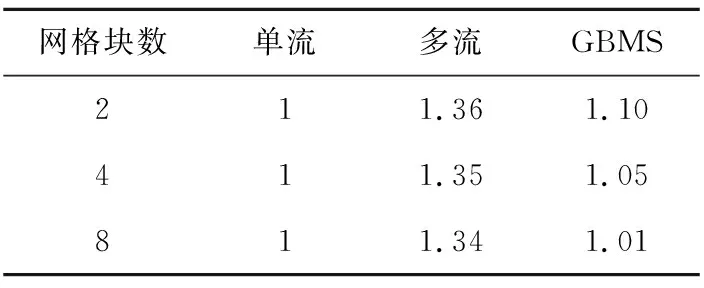
Table 1 Performance comparison of different CUDA stream implementations表1 GPU上不同流實現策略時的加速比
圖11給出了天河一號超級計算機單個計算結點內GPU并行、CPU-GPU協同并行以及實現GBMS策略時的加速比和協同并行效率。由于GPU存儲容量限制,僅針對前4個相對較小規模的網格給出了GPU并行加速比,對于網格規模256×128×128(約4百萬網格單元),必須采用GBMS策略,SPGPU由1.3降到1.05,對于前面4個小規模網格問題,協同并行不需要GBMS,SPCPU+GPU和CE分別可達到1.8和79%,協同并行相對于純GPU并行(GPU-only)提升了約45%的性能。對于更大規模的網格(大于4百萬網格單元),GBMS對于提升協同并行加速比和協同效率非常重要。以256×256×18(約8百萬網格單元)網格規模為例,如果不采用GBMS策略,則GPU只能模擬其中的2百萬網格單元,其他的6百萬網格單元只能在CPU上進行模擬,由于嚴重的負載不均衡,SPCPU+GPU僅為1.3,CE僅為57%。采用GBMS策略后,CPU和GPU均可以模擬4百萬網格單元,SPCPU+GPU和CE分別提高到1.79和89%。采用GBMS負載均衡情況下,高精度CFD軟件在一個天河一號計算結點上的模擬容量由3.5百萬網格單元提升到8百萬網格單元,提升了約2.3倍。進一步增加問題規模會導致協同并行加速比和效率明顯下降,原因是即使采用GBMS,GPU模擬負載最多仍然為4百萬網格單元。
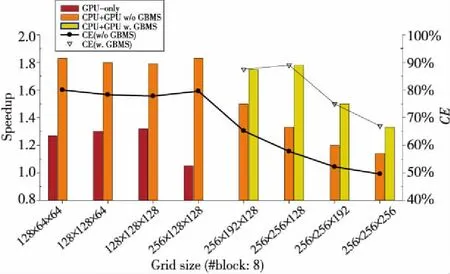
Figure 11 Intra-node collaborative speedup and efficiency圖11 計算結點內協同并行加速比及效率
圖12給出了天河二號MIC加速器(Intel Xeon Phi 31S1P)上針對LU-SGS設計的2層流水線OpenMP并行算法TL-Pipeline與傳統流水線OpenMP并行算法的加速比。可以看出,傳統流水線并行的最大加速比僅為15.5(此時對應的問題規模為64×64×64,線程數為57),當使用MIC全部的228個線程時,加速比降為5.0(32×64×128),7.1(64×64×64)和6.2(128×64×32),表明在眾核加速器上,隨著線程數量增加,傳統流水線并行存在嚴重的可擴展性瓶頸。與此同時,對于上面3個問題規模,即使采用全部228個線程,TL-Pipeline加速比也可分別達到69.1,82.3和98.3。注意到TL-Pipeline加速比的提升對于不同dp1×dp2的組合變化較大,這是因為流水線開銷以及線程/流水段負載均衡隨不同模擬變化較大。總之,TL-Pipeline為在MIC這樣的眾核加速器上實現LU-SGS等高數據依賴求解方法的可擴展OpenMP并行提供了新的方法。
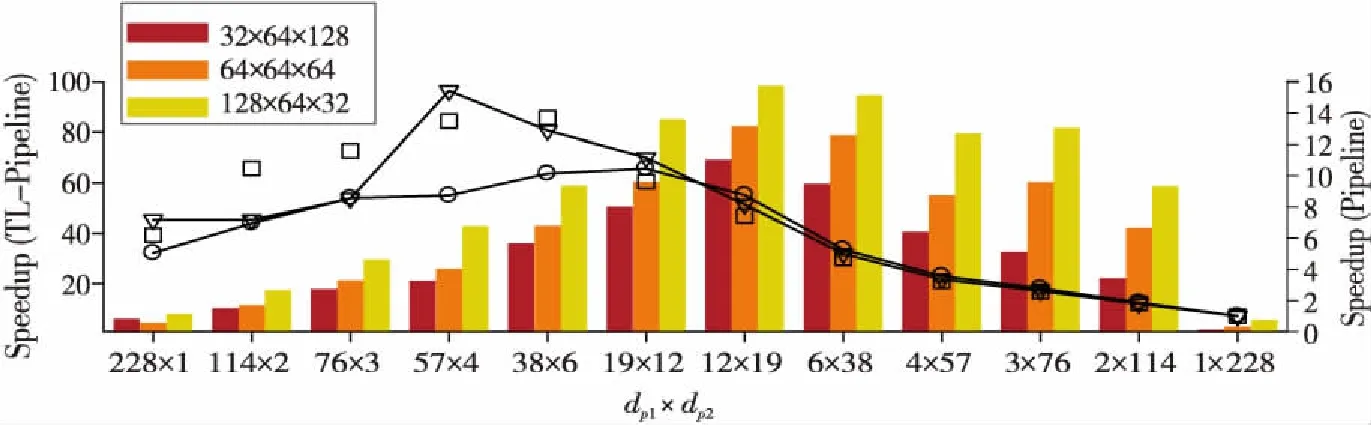
Figure 12 Improvements of TL-Pipeline over the traditional pipeline approach for three grids dimensions on Intel Xeon Phi圖12 3種網格規模下MIC上2層流水線并行相對于傳統流水線并行的性能提升
本文采用規模為256×256×256的算例,在天河二號的MIC協處理器上測試對比了WCNS半節點重構計算的基準版本和intrinsics向量化優化版本的性能改進(如圖13所示)。基準版本在MIC端當線程數為224的時候性能達到最優,相對MIC上單線程計算的加速比約為83.8倍。采用深度intrinsics向量化優化實現之后,在線程數規模不大的情況下,intrinsics優化實現同樣具有很好的線程可擴展性。得益于MIC更寬的向量位寬,深度intrinsics優化將最優性能提升到基準實現的4.5倍左右,在112線程時取得最大加速比,說明向量優化之后MIC上的寬向量部件性能得到了更充分的開發。
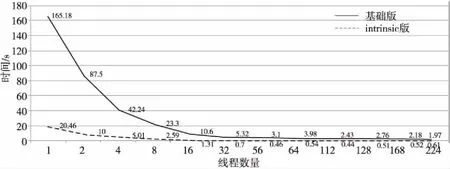
Figure 13 Performance comparison of baseline and intrinsic implementation for WCNS-E-5 interpolation on MIC圖13 WCNS半節點重構基準版本和intrinsic版本在MIC上的性能對比
5 結束語
當前,天河系列、神威太湖之光等超級計算機已多次排名世界第一,標志著我國超級計算機系統研制能力已進入世界前列。與此同時,國內很多單位在這些國產超級計算機上開展了大量CFD并行應用軟件開發和性能優化工作,取得了不錯的成果。長期以來,國防科技大學CFD應用軟件團隊以天河/銀河系列超級計算機為依托,開展了超大規模復雜CFD并行應用開發和性能優化研究,突破了新型異構協同并行計算等一系列關鍵技術,初步實現了HPC與CFD的深度融合,有力支撐了國產CFD軟件在天河/銀河系列超級計算機上的高效超大規模并行應用。
當前高性能計算發展的下一個里程碑是E級計算(Exascale Computing,百億億次浮點運算/每秒),美、日、歐洲、俄羅斯等都制定了E級超級計算機研制計劃。例如,2016年美國能源部正式啟動了E級計算計劃ECP(Exascale Computing Project)[35]。ECP特別強調應用軟件開發,將其作為第1個重點關注領域。我國也將E級超級計算機研制納入了國家“十三五”規劃,目前國防科技大學、江南計算技術研究所、中科曙光3家單位牽頭開展的E級超算原型系統研制項目已通過驗收,實際的國產E級超級計算機系統預期在2021年左右研制成功。我國E級計算計劃中同樣非常關注與E級計算機配套的高性能計算應用軟件研制,國家重點研發計劃中已部署了一批應用軟件研發項目,其中包括數值飛行器原型、數值發動機原型等CFD相關項目。可以預見,基于CFD與E級計算機融合的“數值風洞試驗”“數值優化設計”“數值虛擬飛行”將給航空航天飛行器設計帶來革命性的變化,并將推動流體力學和空氣動力學等學科的創新發展[36]。當前,E級系統CFD應用開發面臨巨大挑戰。一方面超級計算機體系結構異構、眾核、寬向量趨勢明顯,目前大多數CFD應用軟件只能在純CPU系統上運行,通常僅支持MPI并行計算,尚不具備利用新型異構眾核寬向量并行體系結構的能力,難以充分發揮超級計算機的多層次異構并行性能潛力。另一方面,CFD數值模擬實際浮點計算性能不高、并行可擴展性差的情況仍然普遍存在。對真實復雜CFD應用而言,機器浮點效率常常低于10%甚至5%,擴展到千核以上并行效率嚴重下降。如何高效地利用大量寬向量計算核心和異構體系結構,獲得實際計算的高性能,是一個嚴峻的挑戰,“應用墻”問題依然突出。因此,迫切需要從大規模CFD數值模擬應用的數值模型和算法特點出發,緊密結合新型異構眾核體系結構特征,針對性地開展并行算法研究工作,使應用程序充分發掘大規模新一代并行計算機性能,支撐實際CFD應用的高效能計算,滿足國家航空航天飛行器等重大型號工程氣動設計需求。
