NLP在銀行網絡金融業務中的應用
2020-12-07 10:53:22張彥超王杰陳生王彥博
銀行家 2020年11期
張彥超 王杰 陳生 王彥博

后疫情時代,數字經濟的重要性日益凸顯。習近平總書記多次強調要加速建設數字中國,更好地服務我國經濟社會發展和改善人民生活。數字經濟時代的到來,一方面有望重塑商業銀行整體格局,打破傳統信貸的壟斷格局,深度洞察和充分挖掘客戶需求將成為商業銀行創新發展的必由之路;另一方面,隨著金融科技異軍突起,商業銀行在科技與業務深度融合的過程中有了更加豐富的決策選項。其中,以NLP(Natural Language Processing,自然語言處理)情感分析技術為代表的人工智能技術,得益于其對于客戶信息挖掘和分析能力的優秀表現,有利于銀行建立統一視圖的客戶信息體系、保持自身的長期戰略定位,引起業界的高度關注。在金融科技時代,對于大部分金融機構而言,非結構化數據的占比已達到銀行信息總量的80%,甚至更高。但由于該類數據的存儲格式不統一、存儲位置分散、數據量大且增長速度快,而處于長期“睡眠狀態”。有效利用NLP技術深度挖掘非結構化數據,不僅有助于商業銀行深入洞察客戶需求、優化業務流程,而且可以對銀行提升自身治理能力起到關鍵作用。我們聚焦于NLP情感分析技術在我國商業銀行網絡金融業務場景中的實際應用,以期為數字經濟時代商業銀行金融科技的發展提供借鑒。
基于NLP的情感分析技術簡述
NLP作為人工智能的一個熱門領域,憑借其在與人類交互中體現出的獨有價值和魅力,往往被譽為人工智能皇冠上的明珠。從業界應用來看,NLP情感分析在客戶評價以及網絡輿情分析等方面表現出良好的應用效果。通過對文本或音頻的關鍵詞提取并進行情感分析可以有效地從大量的評論數據中獲取有效信息,從而獲得對服務的有效反饋,有針對性地進行改進。
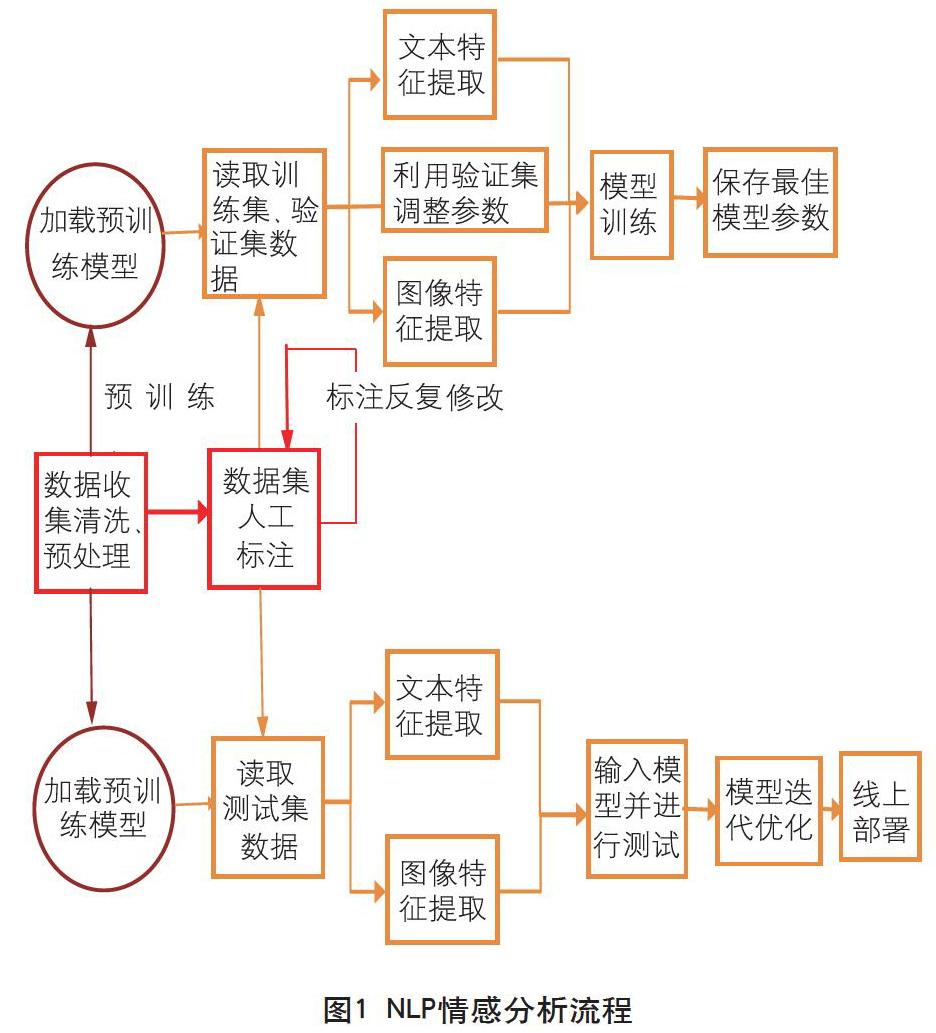
NLP情感分析的研究路徑可大致劃分為“基于詞典和規則的方法”和“基于多類標分類的機器學習方法”。對于情緒分類問題,最早有人采用KNN(K-NearestNeighbor,K最近鄰)算法,通過學習標注數據來識別句子中的情緒類別;也有人采用SVM(Support Vector Machine,支持向量機)算法,通過文本標注建模的方法來識別語料中的情緒標簽。上述方法只能挑選出情緒標簽,無法反映每種情緒屬性的強烈程度。當前普遍采用的方法是用參數量較多的深度學習模型結構,對文本進行上下文關聯建模,提取更深層的語義信息,并最終計算出所有情緒的極性強弱,再根據各情緒的極性強弱挑選出極性最強的情緒作為文本的情緒標簽。NLP情感分析的具體流程如圖1所示。
網絡金融NLP情感分析的應用
我們聚焦于運用NLP情感分析技術對商業銀行網絡金融業務中的客戶評價以及網絡輿情進行監測分析。情緒分類的對象是一段語料中所蘊含的主體情緒,是對蘊含主觀情感色彩的文本進行分析、處理、歸納以及推理的過程。商業銀行日常經營活動中產生了大量的、對于銀行服務和產品有價值的評論信息。例如,工單數據中不僅包括具體問題,還包括處理方法、過程、結果以及客戶反饋,是較好的文本數據。該類評論信息中往往可以體現出客戶的批評、贊揚等多種主觀情感表現。采用NLP技術將客戶評論中包含的情感進行量化分析,有利于銀行客觀評價服務質量并進行后續的改進和提升。以某銀行為例,NLP情感分析可以根據手機銀行客戶點評的內容分析出客戶的情緒是正面、中性還是負面(見表1)。
根據商業銀行手機銀行客戶的點評內容,NLP情感分析會通過以下流程將點評內容轉化為點評情緒信息。
數據收集和預處理
對于銀行而言,其非結構化數據來源包括網上銀行及手機銀行中的客戶點評、客戶咨詢、網絡輿情等。在收集行內外相關數據后,NLP情感分析技術將對文本進行預處理,一般包括文本清洗、去停用詞及符號等。
如果對數據分類采用的是有監督學習(從標簽化訓練數據集中推斷出函數的機器學習任務)這一方式,需要對數據進行前期的人工標注工作,采用交叉驗證、算法模型結合反饋的方式可以保證數據標注的準確性。標注數據一般分為以下四個部分。一是標注訓練數據。用于模型初步訓練,包括文本內容和圖片內容兩部分。二是訓練測試數據。每次訓練過程中,需要簡單驗證模型的各個指標,包括但不限于準確率、召回率和F1等指標。三是擴充標注數據。主要針對前期標注過程中的分布相關問題,對數據分布不均衡問題進行調整,這也是對模型泛化能力的一個優化手段。四是標注測試數據。這是為最終確定驗收、測算指標而選取的測試數據,也可以作為后期優化迭代的測試數據集。
特征提取
通過對特征提取進行深入研究,可以很好地提取出海量數據中蘊含的文本信息和圖像信息的重要特征。一般而言,文本的特征提取可以通過 word2vec、glove、Elmo、BERT 等預訓練方式,將文本信息有效地轉化為計算機可以識別的向量信息。需要注意的是,word2vec、glove 等方法難以解決中文中一詞多義的問題,如“蘋果”一詞在不同語境下可能代表手機品牌或水果,這是由于 word2vec 和 glove 訓練出來的詞向量只能反映出一個固定的語義。但是,Elmo 和 BERT 等預訓練模型可以通過保存上下文語義的方式很好地解決一詞多義的問題。
數據分類
當前主流的數據分類研究方向包括單模態和多模態兩種,內容涵蓋敏感圖片識別、敏感文本信息識別和圖像、文本融合的多模態敏感數據識別等。對于單模態文本信息識別,可以通過包括LSTM、BERT、Xlnet等深度學習以及預訓練模型相結合的有監督學習方式實現95%以上敏感信息的分類提取。在多模態領域,可以采用對文本信息和圖像信息特征提取相結合的方式實現數據敏感信息的分類提取。特征提取一般可以得到普通特征和聚合特征。通常而言,普通特征主要為頁面、文本、圖像和標題等單純特征;聚合特征則將各個普通特征進行組合和有監督訓練,轉換為多個子模型,然后將這些子模型的輸出作為聚合特征,將這些聚合特征分類可以實現90%以上的敏感分類識別。
模型訓練或模型預訓練
深度學習常見的模型結構包括RNN(Recurrent Neural Network, 循環神經網絡)、CNN(Convolutional Neural Networks,卷積神經網絡)、Google提出的Transformer結構和很多基于它們實現的變形結構。不同的學習模型各有利弊,RNN、CNN、LSTM等模型的特點在于其具備強大的序列建模能力。
模型預訓練階段采用BERT模型。Google于2018年推出BERT模型,BERT模型是基于大規模語料的LM預訓練模型,BERT預訓練模型具有強大的特征提取能力,可以很好地解決不同語境下的一詞多義問題,具有很強的魯棒性(控制系統在一定的參數攝動下,維持其他某些性能的特性)和泛化能力(機器學習算法對新鮮樣本的適應能力)。在模型訓練之前需要有針對性地使用具體應用場景下銀行的自有數據,從相關數據庫中采集一批數據進行深入的預訓練,使得所構建的模型在項目場景下具備很強的魯棒性,然后在人工標注的訓練集上進行模型訓練。通過不斷迭代優化參數的方式得到最佳模型,以達到90%以上的準確率。
優化調整
NLP情感分析會根據不同的指標對模型進行評估,模型的評價指標主要有準確率、錯誤率、召回率、精準度、F1值、ROC和AUC曲線等,根據評估的結果對模型進行優化調整。在機器學習過程中,主要應用于梯度下降(迭代法的一種,可以用于求解最小二乘問題),如傳統的優化器主要結合數據集,通過變化單次循環所采用的數據量的大小對梯度下降進行控制;非傳統的調優則綜合考量數據集特點與模型訓練時間,通過多種方式實現梯度下降的學習率。常見的優化器有SGD、BGD、MBGD、Momentum、Adagrad、RMSprop、Adam等。
實證結果
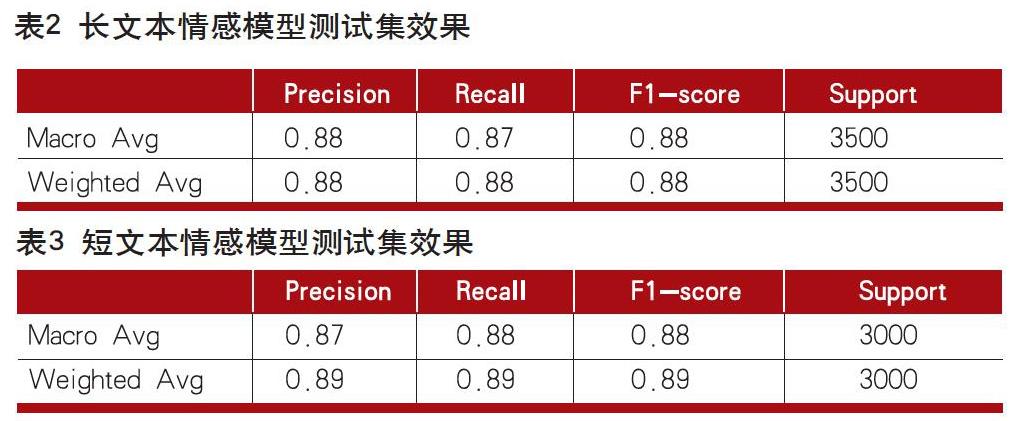
基于上述實證研究,我們對目標銀行2020年6月至2020年8月千余條客戶點評的文本數據進行分析,對每條點評生成的情感分析結果進行判斷。從模型效果指標來看,長文本和短文本測試結果的準確率如表2、表3所示,效果顯著。
從業務方面看,以某商業銀行正面情緒的語料分析為例,通過NLP分析技術可生成詞云,進行可視化展現,一方面可供業務管理部門第一時間掌握用戶反饋信息,把握輿情動態;另一方面可根據客戶反饋的意見,及時對業務進行優化,并有針對性地與客戶進行溝通,把握先手棋,提升客戶體驗。具體來看,在交互方式方面,客戶高度關注手機銀行的便捷性和易用性,以指紋識別、人臉識別等為代表的生物識別方式對提升用戶體驗具有較為顯著的作用。針對不同的客戶反饋,后續手機銀行登錄界面將推送個性化的登錄方式選項,并在登錄首頁進行差異化的功能設定,以提升手機銀行的便捷性。在客戶感受方面,客戶對手機銀行的版本迭代有較高的期待,頁面版本優化所帶來的功能提升和視覺更新往往更容易得到用戶的認可。普遍來看,清新簡潔的風格在用戶中受歡迎程度較高,為后續手機銀行的視覺設計風格提供了重要的參考依據。在獲客引流方面,信用卡、日常轉賬和存款是手機銀行用戶激活的主要業務,后續獲客過程中持續優化信用卡的便捷性、拓展日常支付場景有望成為客群增長的重要路徑。
結語
一直以來,由于NLP技術可以實現針對文本、語音等非結構化數據的價值挖掘,因此在營銷、運營等場景中可以對智能化決策進行支持。我們聚焦于某商業銀行網絡金融業務手機銀行客戶的反饋數據,基于NLP情感分析技術對客戶點評進行標注和識別,并將此分析結果轉化為業務建議,輔助銀行進行客群管理與經營,以提升銀行的服務能力。
(文章僅代表個人觀點,與所在單位無關)
(作者張彥超、王杰工作單位為華夏銀行股份有限公司, 陳生、王彥博工作單位為龍盈智達(北京)科技有限公司)
猜你喜歡
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
風流一代·青春(2018年2期)2018-02-26 15:27:06
風流一代·青春(2017年6期)2018-02-14 19:28:55
風流一代·青春(2017年5期)2018-02-14 09:32:37
High Technology Letters(2017年3期)2017-09-25 12:53:30
中國老區建設(2016年3期)2017-01-15 13:53:21
創新作文(小學版)(2016年20期)2016-08-22 09:11:22
小學教學參考(2015年20期)2016-01-15 08:44:38
上海國資(2015年8期)2015-12-23 01:47:31
