基于深度殘差網絡的多損失頭部姿態估計
2020-12-16 02:18:14齊永鋒馬中玉
計算機工程 2020年12期
齊永鋒,馬中玉
(西北師范大學 計算機科學與工程學院,蘭州 730070)
0 概述
頭部姿態估計是通過檢測人臉方向與判斷人眼注意力估計整個頭部姿態,可應用于駕駛員監控[1]、注意力識別[2]以及面部分析等,例如交通管控人員對駕駛員頭部姿態進行精準估計與預測能有效降低交通事故發生率,教師在課堂教學時通過估計與分析學生頭部姿態,可判斷其聽講情況及對課程的興趣程度。近年來,頭部姿態估計已成為計算機視覺領域的研究熱點[3],研究人員采用不同儀器設備對其進行研究。其中,相機陣列、激光指示器、立體相機、深度相機、磁性與慣性傳感器等可在成像環境受限情況下獲得穩定的姿態估計圖像[4]。然而上述設備需要人體穿戴或者在室內使用,使得頭部姿態估計無法在自然場景下進行,此外穿戴設備的高成本也使其大范圍推廣應用受到限制。由于單目攝像機、手機、筆記本電腦等均可拍攝RGB圖像,便于頭部姿態估計的廣泛應用[5],因此目前通常采用RGB圖像進行頭部姿態估計與分析。基于RGB圖像的頭部姿態估計方法包括基于外觀的方法、基于模型的方法、流形嵌入方法以及非線性回歸方法[6]。其中,基于外觀的方法將頭部視圖與代表姿勢標簽的離散模型進行對比[7],利用不同類型模板匹配技術,評估輸入特征與樣本集的相似性。該方法主要通過對比人臉樣本圖像與二維人臉地標圖像的特定關系來估計頭部姿態,實現相對簡單,但在實際場景中應用局限性較大[5],例如在不使用插值方法的情況下無法估計離散姿態位置。基于模型的方法使用幾何信息、非剛性面部模型或者界標位置來估計頭部姿態,該方法關鍵在于找到共面的面部關鍵點并估計與參考坐標系的距離[8],然而其對角度數據精確度要求較高,無法在角度退化的情況下使用。此外,基于模型的方法還可通過多個非共面關鍵點位置來評估,假設地標之間存在固定幾何關系,將上述關鍵點位置與測量人體獲得的平均掩模進行對比[9]來估計頭部姿態。基于模型方法的準確性與從圖像中所推理幾何關系的真實性及數量相關,雖然關鍵點檢測和跟蹤技術發展較快[10],但是該方法的應用仍受到地標檢測技術限制。例如,當頭部姿態估計應用于智能系統身份和行為檢測時,光照變化、遮擋、分辨率等因素都會對檢測結果造成較大影響[11-12]。
隨著深度學習技術的發展,基于深度學習的頭部姿態估計得到深入研究并取得一系列成果。文獻[5]采用淺層卷積神經網絡分析頭部姿態算法的魯棒性,發現自適應梯度神經網絡能更好地訓練模型。文獻[13]通過卷積神經網絡將3D人臉模型與RGB圖像進行擬合,使用密集的3D模型對齊面部標志得到3D頭部姿態,但是引入了固有誤差。文獻[14]使用改進的GoogleNet[15]并利用多任務共同學習面部標志和頭部姿態。文獻[16]采用由5個卷積層和3個全連接層組成的卷積神經網絡HyperFace進行頭部姿態估計、人臉對齊與性別分類。文獻[17]利用All-In-One神經網絡為HyperFace增加微笑預測與年齡估計功能。上述方法雖然在一定程度上解決了自然環境中面部檢測和頭部姿態估計的問題,但是所得結果存在較大誤差。
文獻[18]在深度學習架構下使用更高級別的表示方法用于回歸頭部姿態,在選定的面部標志上使用2D熱圖形式的不確定性圖,并將其通過卷積神經網絡作為輸入通道來回歸頭部姿態,然而該方法僅采用5個面部標志,對被遮擋頭部姿態的識別十分有限[19]。上述方法對人臉特征點檢測精度要求較高,在視線或光照不佳、遮擋嚴重等情況下其檢測性能較差甚至檢測失效。為解決該問題,文獻[20]采用簡單的卷積神經網絡回歸3D頭部姿態,但只專注于面部對齊,未在公共數據集上進行頭部姿態估計。文獻[21]提出無關鍵點的頭部姿態估計方法,劃分3個分支對頭部姿態的3個角度進行聯合預測,每個分支通過分類和積分回歸組合。文獻[22]提出一種基于卷積神經網絡的模型,該模型通過線性逆回歸高斯混合來回歸頭部姿態。文獻[23]結合無監督流形學習和逆回歸質量的方法在光照、面部方向和外觀變化等方面進行改進,提高了魯棒性。以上方法都是采用地標檢測進行姿態估計,雖然基于地標的方法在給定地標時能較好地預測頭部姿態,但是在真實場景地標準確性較低的情況下會降低姿態估計精度。
為解決上述問題,本文提出一種基于深度學習的無關鍵點頭部姿態估計方法,采用更多層的深度殘差網絡RestNet101[24]進行多角度回歸損失設計,在文獻[19]的基礎上對梯度下降模式進行優化,同時與自適應方法相結合,使用卷積神經網絡從圖像強度估計頭部姿態,并對不同數據集上頭部姿態估計效果與測試精度進行分析。
1 頭部姿態估計方法
1.1 頭部姿態表示
頭部姿態估計方法主要分為基于2D關鍵點檢測的3D姿態推算方法以及無關鍵點檢測的直接預測方法。其中,前者需對人臉關鍵點進行檢測及分析,即通過建立關鍵點和3D頭部模型之間的對應關系并執行對準來恢復頭部3D姿態,這種使用卷積神經網絡提取面部關鍵點的方法靈活性較好,但未使用面部全部信息,在未能檢測到面部關鍵點的情況下,無法準確進行頭部姿態估計。因此,本文提出一種無關鍵點的頭部姿態估計方法[21],利用單目攝像機獲取人體頭部圖像,采用歐拉角表示頭部姿態,如圖1所示。從偏航角(yaw)、仰俯角(pitch)、旋轉角(roll)3個角度描述頭部空間姿態。由文獻[21]證明結果可知,使用卷積神經網絡從圖像強度估計3D頭部姿態具有較高的準確性。

圖1 采用歐拉角表示的頭部姿態Fig.1 Head posture expressed by Euler angle
1.2 網絡設計
傳統無關鍵點檢測的頭部姿態估計方法使用卷積神經網絡直接預測歐拉角,在大規模訓練中存在訓練不穩定、識別性能較差與速度較慢等問題,因此,本文使用更多層的深度殘差網絡RestNet101,將全連接層輸出設置為198層,其中66層及其以下用于粗分類以輔助學習,66層以上用于精細分類以進行頭部姿態預測。同時選擇更好的優化器AdaBound[25]在訓練網絡中進行梯度優化,本文方法網絡結構如圖2所示。

圖2 本文方法網絡結構Fig.2 Network structure of the proposed method
采用Softmax分類器獲得每層輸出的交叉熵損失,同時計算偏航角、仰俯角、旋轉角的均方誤差,并聯合其他層輸出損失計算總損失,損失計算方法將在1.3節中具體介紹。本文方法所用網絡的訓練參數設置如下:訓練迭代次數為200,每次迭代處理樣本數量為36,學習率為0.001。對數據集處理如下:對于頭部翻轉的圖像,改變偏航角和旋轉角方向進行翻轉處理;對于模糊圖像,采用濾波器進行去模糊處理。
1.3 損失計算
Softmax回歸由邏輯回歸演化而來,用于解決多分類問題,屬于有監督的學習方法。神經網絡最后一層為Softmax函數,其與深度學習方法結合可用來區分輸入圖像的角度類別。
交叉熵損失計算在Softmax回歸后進行,該計算在深度學習中使用較多。在神經網絡中,交叉熵通常與Softmax函數組合使用,本文網絡仍采用該模式以便對頭部姿態進行有效預測。交叉熵函數的計算公式為:
(1)
其中,N為樣本數,i、j為二維矩陣中的元素,h為分類概率。
本文所用回歸損失函數為均方誤差(Mean Square Error,MSE),即預測值與目標值之間差值的平方和,計算公式如下:
(2)
其中,y、y′分別表示真實值和預測值。
每個角度的損失表示為:
(3)
其中,L和MSE分別為交叉熵損失和均方誤差損失函數,n為分類分支數量。本文中α、βi均為訓練參數,α=2,βi={2,7,5,3,1,1}
2 實驗與結果分析
本文使用AFLW2000[24]、 BIWI[26]和300W_LP[13]3個數據集進行分析和驗證。AFLW2000數據集包含野外與姿態變化較大的2 000張人臉圖像(偏航角為-90°~90°),并使用68個3D地標進行注釋。BIWI數據集是應用較廣泛的面部數據集,其中包含15 000張人臉圖像(取自6位女性和14位男性)。BIWI數據集對于每一幀圖像均提供深度圖像、相應的RGB圖像(640像素×480像素)和注釋。300W_LP數據集廣泛用于面部識別與頭部姿態分析,是常用的野外2D地標數據集,由包含大量頭部姿態的61 225張圖像組成,并通過翻轉擴展至122 450張圖像。圖3為AFLW2000數據集、BIWI數據集和300W_LP數據集的部分圖像示例。頭部姿態范圍設置如下:偏航角為±75°,俯仰角為±60°,旋轉角為±50°。地標真值以頭部的三維位置及其旋轉形式提供。

圖3 3種數據集部分圖像示例Fig.3 Sample images of three datasets
本文實驗采用Windows10操作系統,CPU為Intel?CoreTMi3-8100,主頻為3.6 GHz,顯卡為Nvidia RTX2060,顯存為6 GB,圖形支持為CUDA10,實驗環境配置為深度學習框架Pytorch1.0與OpenCV 3.4。通過計算偏航角、仰俯角、旋轉角3個參數的均方誤差與平均絕對誤差(Mean Absolute Error,MAE)來評估本文方法在不同數據集上的表現,并分別給出相應數據集上頭部姿態表示結果。采用圖1中頭部姿態表示方法,向下的軸線表示偏航角方向,向右的軸線表示仰俯角方向,垂直面部向前的軸線表示旋轉角方向,從而立體化表示三維空間頭部姿態信息,并通過可視化直觀展示來評估頭部轉向與位置信息。
2.1 AFLW2000數據集上頭部姿態估計
圖4為本文方法在AFLW2000數據集上的部分頭部姿態估計結果。可以看出,本文方法對不同圖像的頭部姿態估計穩定可靠,能較好地表示頭部姿態,在室內外場景中魯棒性均表現良好。

圖4 AFLW2000數據集上的部分頭部姿態估計結果Fig.4 Results of partial head poseture estimation onAFLW2000 dataset
本文使用粗、細粒度分類任務進行頭部姿態估計,通過粗粒度回歸定位人臉,采用細粒度評估姿態。將本文方法與FAN[24]地標[27]檢測方法(以下稱為FAN方法)以及文獻[21]中無關鍵點的細粒度頭部姿態估計方法(以下稱為文獻[21]方法)在AFLW2000數據集上的平均絕對誤差進行對比,由于AFLW2000圖像尺寸較小,而裁剪操作在臉部周圍進行,因此更易檢測到人臉區域,結果如表1所示。可以看出,在偏航角、仰俯角、旋轉角3個角度的評估上,本文方法的平均絕對誤差相較文獻[20]方法下降0.759個百分點,表明本文方法對小圖像的頭部姿態估計性能較好,能在小分辨率與弱光下檢測和評估頭部信息。

表1 3種方法在AFLW2000數據集上的實驗結果Table 1 Experimental results of three methods onAFLW2000 dataset
2.2 BIWI數據集上頭部姿態估計
本文使用每個顏色通道ImageNet均值和標準偏差來標準化訓練前的數據,并將BIWI數據集作為網絡的大規模輸入,通過RestNet101主干網絡以及損失分類得到最終頭部姿態估計結果。圖5為本文方法在BIWI數據集上的部分頭部姿態估計結果。可以看出,通過對BIWI數據集的簡單處理,其更利于網絡訓練,該數據集圖像中頭部姿態角度覆蓋范圍更廣,網絡訓練后頭部姿態檢測效果較好。

圖5 BIWI數據集上的部分頭部姿態估計結果Fig.5 Results of partial head poseture estimation onBIWI dataset
將本文方法與FAN方法和文獻[21]方法在BIWI數據集上的平均絕對誤差進行對比,結果如表2所示。可以看出,與其他兩種方法相比,本文方法的偏航角、仰俯角和旋轉角平均絕對誤差更小,且MAE值降幅較小,這是因為BIWI數據集具有一定的幀間信息,使平均絕對誤差降幅較小。

表2 3種方法在BIWI數據集上的實驗結果Table 2 Experimental results of three methods onBIWI dataset
2.3 300W_LP數據集上頭部姿態估計
圖6為本文方法在300W_LP數據集上的部分頭部姿態估計結果,從左到右4張圖像的光線環境分別為室內、室外、正常光照和暗光環境。可以看出,本文方法的姿態估計均較準確,可適用于不同光照環境下的頭部姿態估計。

圖6 300W_LP數據集上的部分頭部姿態估計結果Fig.6 Results of partial head poseture estimation on300W_LP dataset
使用300W_LP數據集分析訓練過程并測試網絡性能,并將本文所用AdaBound優化器與SGD、AMSGrad和Adam優化器進行對比以驗證本文優化器的有效性。圖7是RestNet101網絡使用上述4種優化器在300W_LP數據集上所得訓練精度與測試精度。可以看出:在訓練階段前150次迭代中,AdaBound優化器的訓練精度接近98%,高于其他優化器,AMSGrad優化器的訓練精度排在第二位;在訓練階段迭代150次后,各優化器的訓練精度均明顯提升,其中AdaBound優化器增幅最大,收斂速度最快;在測試階段,SGD優化器測試精度曲線震蕩較強烈,梯度下降不穩定,AdaBound優化器測試精度曲線收斂較快,梯度下降較穩定,測試精度達到95%以上,高于其他兩種優化器。
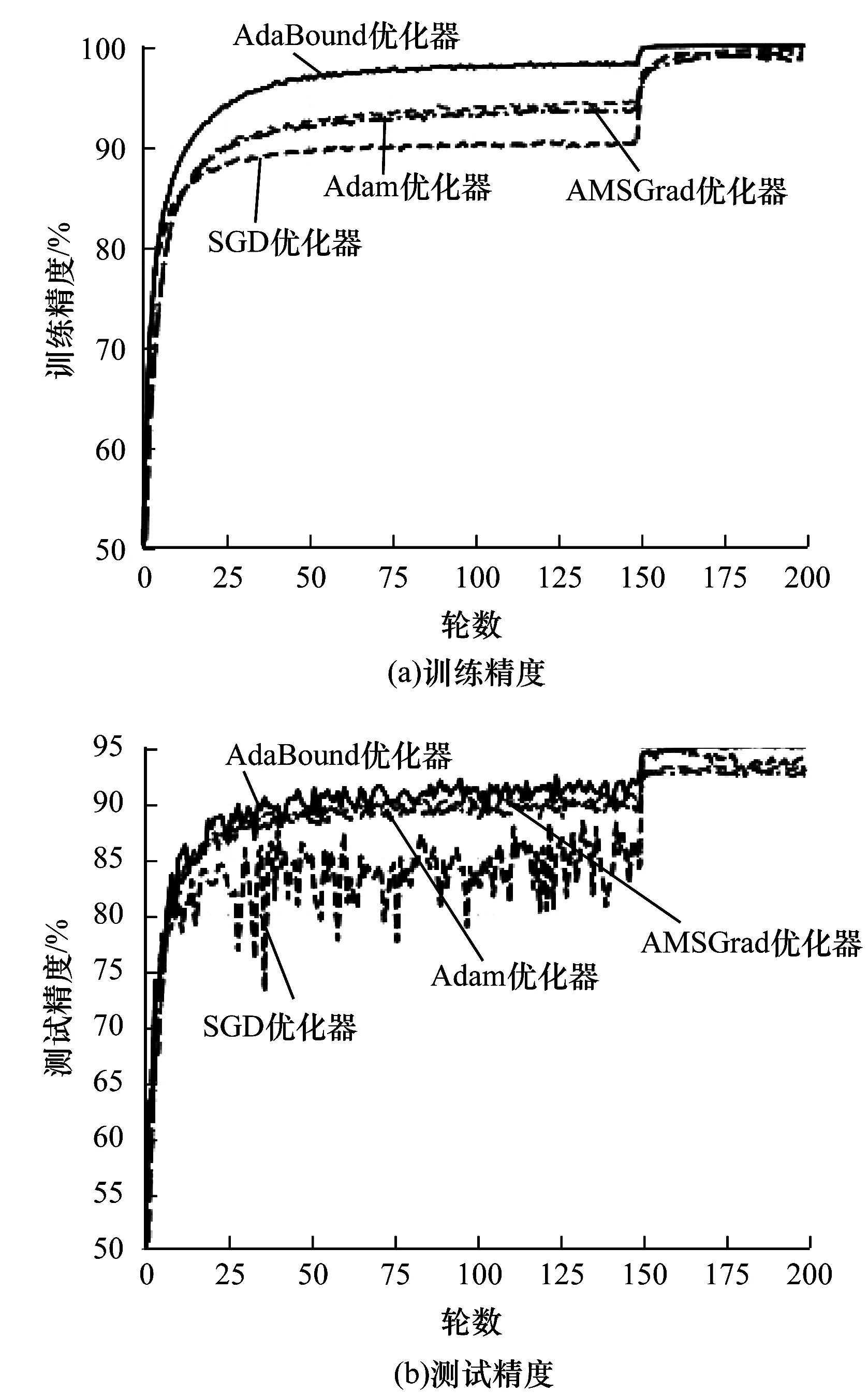
圖7 4種優化器在300W_LP數據集上的訓練精度與測試精度Fig.7 Training accuracy and test accuracy of fouroptimizers on 300W_LP dataset
在300W_LP數據集上的姿態評估測試中,本文方法在偏航角、仰俯角和旋轉角上的平均絕對誤差為1.801 6(FAN方法和文獻[21]方法沒有在相同條件下的實驗數據),姿態估計性能較好。上述結果表明,本文通過增加網絡層數、優化下降梯度,可提升訓練速度與訓練精度。
2.4 性能測試
2.4.1 魯棒性分析
為進一步驗證本文方法在真實環境中的魯棒性,使用訓練好的RestNet101網絡模型在復雜光照、部分遮擋及極限姿態情況下進行測試,結果如圖8所示。其中,圖8中左起第1張和第2張圖像為復雜光照環境,左起第3張和第4張圖像分別為部分遮擋和極限姿態情況。可以看出,本文方法在復雜光照、部分遮擋以及極限姿態情況下頭像姿態識別良好,具有較好的魯棒性,滿足復雜條件下頭部姿態估計要求。

圖8 本文方法魯棒性測試結果Fig.8 Robustness test results of the proposed method
2.4.2 位姿估計的運算復雜度與實時性分析
為檢驗頭部位姿運算復雜度,需分析頭部姿態估計模型加載和處理時間,表3為本文方法在模型初始化、網絡姿態角回歸以及頭部姿態估計3個階段的耗時情況。可以看出在模型初始化階段,由于需進行頭部模型庫調用與模型加載,因此初始化所用時間較長。在網絡姿態角回歸階段,主要進行姿態回歸和網絡損失計算,在頭部姿態估計階段,主要進行輸入幀模型對比與圖像生成處理。3個階段總耗時為89.16 ms,所用時間較短。

表3 本文方法在3個階段的耗時情況Table 3 Time consumption of the proposed methodin three stages ms
在真實室內環境下,使用網絡攝像頭加載訓練好的RestNet101網絡模型,得到頭部姿態測試結果如圖9所示,視頻幀尺寸為1 024像素×576像素。可見實際場景下頭部姿態識別準確,說明該模型能較好地捕捉未訓練過的目標。網絡攝像頭實際運行測試顯示網絡模型在 GPU 上每秒傳輸幀數(Frames Per Second,FPS)達到31,滿足實時處理的需求。

圖9 網絡攝像頭所得頭部姿態測試結果Fig.9 Head posture test result obtained by Webcam
3 結束語
針對傳統無關鍵點檢測方法識別較差且速度較慢的問題,本文提出一種采用深度殘差網絡RestNet101的頭部姿態估計方法,利用多損失分類訓練深度殘差網絡,使用無關鍵點細粒度方法估計頭部姿態,通過網絡粗、細分類的分層設計進行頭部姿態預測,并在訓練階段使用AdaBound優化器進行梯度優化。實驗結果表明,與FAN地標檢測方法和無關鍵點細粒度方法相比,該方法在AFLW2000和BIWI數據集上平均絕對誤差更小。后續將在深度學習的基礎上,從網絡模型改進和數據集處理方面進行研究,進一步提高頭部姿態估計精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(2021年8期)2021-11-28 05:07:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中國衛生(2014年2期)2014-11-12 13:00:16
