淺議基于Hadoop 與SQL-Server2014 協(xié)作的無人機(jī)裝備訓(xùn)練數(shù)據(jù)存儲系統(tǒng)建立
2020-12-22 08:27:10尹承督
價(jià)值工程 2020年33期
關(guān)鍵詞:數(shù)據(jù)庫系統(tǒng)
尹承督
(32167 部隊(duì),拉薩 850000)
0 引言
本文主要基于Hadoop 系統(tǒng)與SQL-Server2014 分別就無人機(jī)裝備訓(xùn)練過程中的非結(jié)構(gòu)化數(shù)據(jù)與結(jié)構(gòu)化數(shù)據(jù)的存儲進(jìn)行了分析,鑒于部隊(duì)信息化建設(shè)以傳統(tǒng)數(shù)據(jù)倉庫為主的實(shí)際,在此我們建立Hadoop 平臺與傳統(tǒng)數(shù)據(jù)倉庫SQL-Server2014 協(xié)作的無人機(jī)裝備訓(xùn)練數(shù)據(jù)存儲系統(tǒng),從而突破數(shù)據(jù)存儲量擴(kuò)展的瓶頸,同時(shí)增強(qiáng)多結(jié)構(gòu)化數(shù)據(jù)的存儲與分析處理的能力。
1 數(shù)據(jù)庫整合工具Sqoop
Sqoop 的含義本質(zhì)是 Sql to Hadoop 的縮寫[1]。Sqoop 適用于Hadoop 系統(tǒng)與結(jié)構(gòu)化數(shù)據(jù)存儲系統(tǒng)(本文采用SQLServer2014)之間進(jìn)行數(shù)據(jù)交換的軟件,本文Hadoop 平臺與SQL-Server2014 之間進(jìn)行數(shù)據(jù)的交換,主要依靠Sqoop進(jìn)行數(shù)據(jù)的導(dǎo)入導(dǎo)出。其具體過程如圖1、圖2 所示。
1.1 數(shù)據(jù)導(dǎo)入過程 Sqoop 在導(dǎo)入數(shù)據(jù)的過程中主要依靠MapReduce 將任務(wù)通過規(guī)定的接口從數(shù)據(jù)庫讀取記錄,然后寫入HDFS 中的過程,這里所要求規(guī)定的關(guān)系型數(shù)據(jù)庫支持接口是JDBC(Java DataBase Connectivity),因此在使用Sqoop 進(jìn)行數(shù)據(jù)導(dǎo)入、導(dǎo)出時(shí),接口都采用JDBC技術(shù)。數(shù)據(jù)導(dǎo)入過程如圖1 所示。
具體數(shù)據(jù)導(dǎo)入步驟:
①導(dǎo)入數(shù)據(jù)庫的指令由客戶端在Sqoop,通過命令行方式輸入,指令明確數(shù)據(jù)所在的服務(wù)器位置、數(shù)據(jù)庫、數(shù)據(jù)表名稱等相關(guān)信息。

圖1 Sqoop 導(dǎo)入數(shù)據(jù)原理
②客戶端接收到導(dǎo)入數(shù)據(jù)指令后,需要對導(dǎo)入的字段類型與列信息經(jīng)JDBC 接口進(jìn)行檢索。Hadoop 支持的數(shù)據(jù)類型與檢索類型映射,然后適用于MapReduce 作業(yè)的相應(yīng)數(shù)據(jù)類型與生成數(shù)據(jù)表的類代碼。
③類代碼由Sqoop 根據(jù)字段類型與數(shù)據(jù)表列信息生成,其中包含有提取數(shù)據(jù)列的方法。
④經(jīng)過Sqoop 的規(guī)劃后的Map 任務(wù),主要為了利用Hadoop 的導(dǎo)入性能與高效數(shù)據(jù)并行處理。
⑤數(shù)據(jù)庫中讀取數(shù)據(jù)依然通過JDBC 接口,相應(yīng)節(jié)點(diǎn)執(zhí)行Map 任務(wù)。
⑥按照用戶的指定格式進(jìn)行數(shù)據(jù)讀取,備份存儲在HDFS,大多以二進(jìn)制或是文本形式存儲。
具體Sqoop 進(jìn)行無人機(jī)裝備訓(xùn)練數(shù)據(jù)導(dǎo)入過程:
無人機(jī)裝備訓(xùn)練管理原始數(shù)據(jù)保存在關(guān)系型數(shù)據(jù)庫中,開源的數(shù)據(jù)導(dǎo)入工具Sqoop 可將數(shù)據(jù)導(dǎo)入Hadoop 中去,導(dǎo)入時(shí)命令[2]:
% sqoop import - connect jdbc:sql://192.168.1.100/EMP
>--table uavtrainingdatainfo-m 2
Sqoop 中的import 指令會運(yùn)行一個(gè)MapReduce 作業(yè),用于連接關(guān)系型數(shù)據(jù)庫并從中讀取數(shù)據(jù)。192.168.1.100 是服務(wù)器sql 的IP 地址,此處EMP(Enterprise Monitoring Platform)是監(jiān)管數(shù)據(jù)庫名稱。uavtrainingdatainfo 是指無人機(jī)裝備訓(xùn)練數(shù)據(jù)信息,(-m2)說明使用map 任務(wù)2 個(gè)。重復(fù)Sqoop 命令,將無人機(jī)裝備訓(xùn)練數(shù)據(jù)表中數(shù)據(jù)導(dǎo)入到Hadoop 中。
1.2 數(shù)據(jù)導(dǎo)出過程 數(shù)據(jù)導(dǎo)出過程步驟如圖2 所示[3]。
①導(dǎo)出數(shù)據(jù)庫的指令由客戶端在Sqoop,通過命令行方式輸入,指令明確數(shù)據(jù)所在的服務(wù)器位置、數(shù)據(jù)庫、數(shù)據(jù)表名稱等相關(guān)信息。
②客戶端接收到導(dǎo)出數(shù)據(jù)指令后,需要對導(dǎo)出的字段類型與列信息經(jīng)JDBC 接口進(jìn)行檢索。Hadoop 支持的數(shù)據(jù)類型與檢索類型映射,然后適用于MapReduce 作業(yè)的相應(yīng)數(shù)據(jù)類型與生成數(shù)據(jù)表的類代碼。
③Sqoop 由字段類型與數(shù)據(jù)表信息生成所需要導(dǎo)出的數(shù)據(jù)表相應(yīng)的類代碼,用于解析HDFS 文件,從而生成數(shù)據(jù)庫記錄,進(jìn)而實(shí)現(xiàn)更新或是插入數(shù)據(jù)。
④同導(dǎo)入一樣為了實(shí)現(xiàn)Hadoop 的高效數(shù)據(jù)并行處理與性能,Sqoop 需要對導(dǎo)出的數(shù)據(jù)執(zhí)行Map 任務(wù)規(guī)劃。
⑤從HDFS 中讀取數(shù)據(jù),由節(jié)點(diǎn)執(zhí)行Map 任務(wù),并解析相關(guān)記錄。
⑥數(shù)據(jù)庫中的數(shù)據(jù)以Insert 或是Update 的形式存儲,通常采用一條請求對應(yīng)插入或更新多條數(shù)據(jù)的方式進(jìn)行。一般情況Sqoop 可以實(shí)現(xiàn)上千條記錄同時(shí)一起提交。由于Sqoop 目前進(jìn)行數(shù)據(jù)傳輸?shù)臋C(jī)制存在的弊端,由于網(wǎng)絡(luò)或是Map 任務(wù)提交失敗,容易造成數(shù)據(jù)的重復(fù)記錄現(xiàn)象。

圖2 數(shù)據(jù)導(dǎo)出過程
為了方便無人機(jī)裝備訓(xùn)練數(shù)據(jù)的查詢,通過Sqoop 可以把Hive 查詢的數(shù)據(jù)結(jié)果導(dǎo)出到傳統(tǒng)關(guān)系型數(shù)據(jù)庫中,從而可以節(jié)約裝備管理人員或是部隊(duì)指揮員對于Hive 在執(zhí)行查詢時(shí)的等待時(shí)間,因此在關(guān)系數(shù)據(jù)庫管理系統(tǒng)中創(chuàng)建接受數(shù)據(jù)的目標(biāo)表[4]:

Sqoop 導(dǎo)出命令:

查詢關(guān)系型數(shù)據(jù)庫中的數(shù)據(jù),并按照count 降序排列
Select*form alarm by type order by count desc;
2 協(xié)作系統(tǒng)功能模塊實(shí)現(xiàn)與程序流程
針對協(xié)作系統(tǒng)要實(shí)現(xiàn)數(shù)據(jù)采集、數(shù)據(jù)存儲、數(shù)據(jù)應(yīng)用的功能性需求,以及系統(tǒng)的通用性、易用性、可用性、健壯性、安全性和可擴(kuò)展性等非功能性需求,將整個(gè)系統(tǒng)分為數(shù)據(jù)采集、數(shù)據(jù)存儲、數(shù)據(jù)應(yīng)用[3]三大模塊。協(xié)作系統(tǒng)的三大模塊功能如圖3 所示。
此處采用程序流程圖的形式介紹大數(shù)據(jù)與傳統(tǒng)數(shù)據(jù)倉庫協(xié)作的過程,為接下來的無人機(jī)裝備訓(xùn)練數(shù)據(jù)倉庫架設(shè)提供依據(jù)。如圖4 所示。
通過對流程圖分析,整個(gè)系統(tǒng)從數(shù)據(jù)采集到數(shù)據(jù)應(yīng)用結(jié)束,整個(gè)過程需要依托Hadoop 平臺的支撐,其中最重要的環(huán)節(jié)是數(shù)據(jù)存儲、傳統(tǒng)數(shù)據(jù)倉庫與大數(shù)據(jù)平臺的數(shù)據(jù)通信問題。
總的來說,大數(shù)據(jù)平臺與傳統(tǒng)數(shù)據(jù)倉庫協(xié)作對無人機(jī)裝備訓(xùn)練數(shù)據(jù)進(jìn)行存儲,主要是在Hadoop 平臺下搭建,主要的關(guān)鍵軟件技術(shù)是Apache 項(xiàng)目下的三大模塊:Hadoop、Sqoop、Hive。系統(tǒng)可以實(shí)現(xiàn)多類型數(shù)據(jù)的采集,根據(jù)需要將數(shù)據(jù)存儲在Hadoop 下Hive 數(shù)據(jù)倉庫中,同時(shí)系統(tǒng)還能實(shí)現(xiàn)傳統(tǒng)數(shù)據(jù)倉庫與Hive 之間進(jìn)行數(shù)據(jù)傳輸與通信,最關(guān)鍵的的是使用Sqoop 實(shí)現(xiàn)數(shù)據(jù)在兩者之間的傳輸。傳統(tǒng)數(shù)據(jù)倉庫中的數(shù)據(jù)可以將許多長期不用的歷史數(shù)據(jù)存入Hadoop 平臺下,從而降低傳統(tǒng)數(shù)據(jù)倉庫的數(shù)據(jù)存儲負(fù)擔(dān)。而且可以實(shí)現(xiàn)對Hadoop 平臺中數(shù)據(jù)的刪除、增加、查詢等操作。
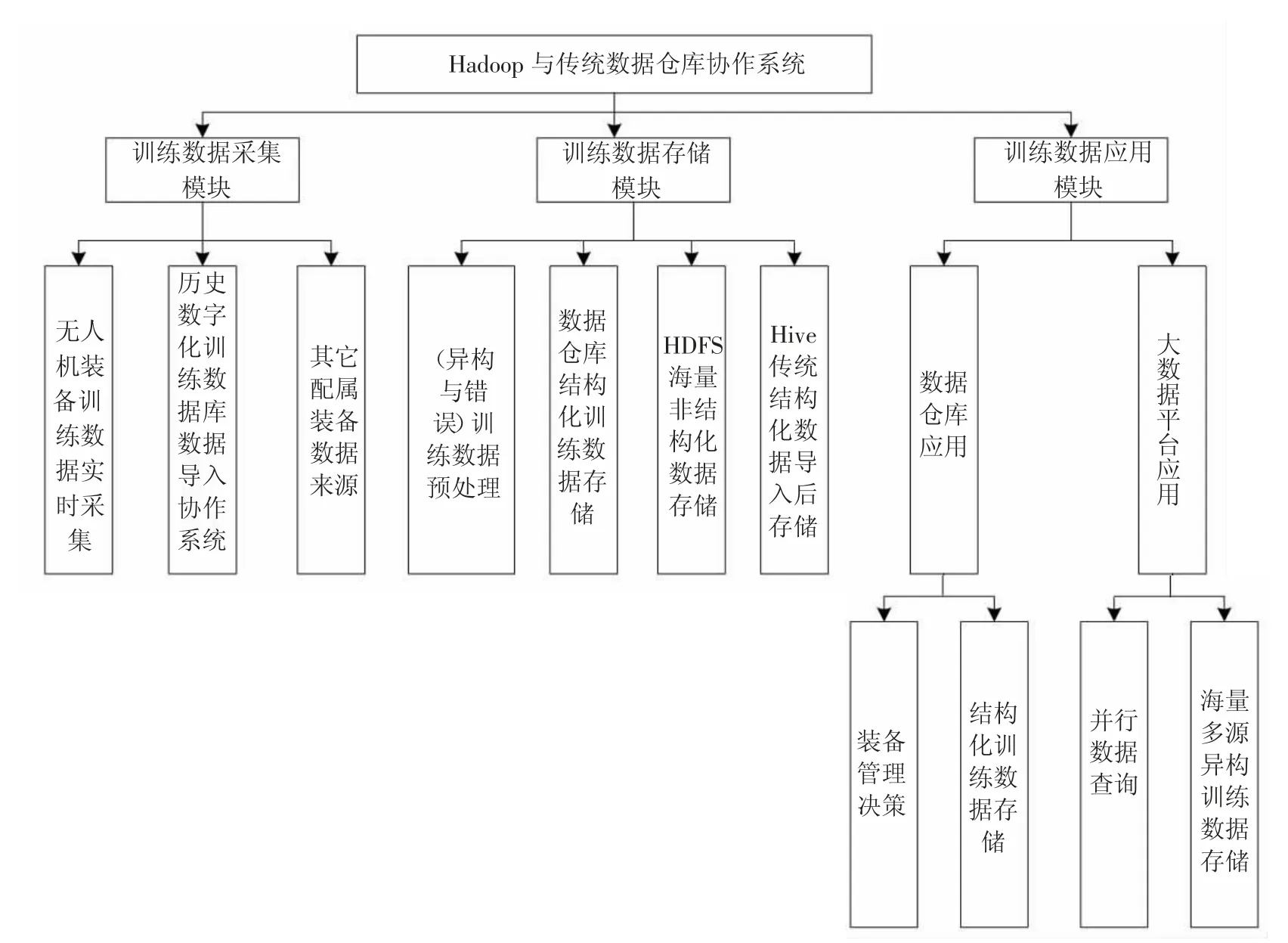
圖3 大數(shù)據(jù)與傳統(tǒng)數(shù)據(jù)倉庫協(xié)作系統(tǒng)功能模塊圖

圖4 協(xié)作存儲系統(tǒng)完整流程圖
3 協(xié)作存儲系統(tǒng)分析
協(xié)作系統(tǒng)實(shí)質(zhì)可以表示為SQL-Server2104+Sqoop+Hadoop=協(xié)作存儲系統(tǒng)。前面介紹了協(xié)作系統(tǒng)主要由三大功能模塊組成:數(shù)據(jù)采集、數(shù)據(jù)存儲、數(shù)據(jù)應(yīng)用。此處主要介紹數(shù)據(jù)的采集與存儲問題。其中的關(guān)鍵技術(shù)是Sqoop 對于SQLServer2104 與Hadoop 之間如何進(jìn)行數(shù)據(jù)通信。下面從模塊功能進(jìn)行介紹兩者是如何進(jìn)行協(xié)作的,如圖5 所示。
3.1 數(shù)據(jù)采集方面
數(shù)據(jù)采集是數(shù)據(jù)獲取的關(guān)鍵步驟,一般數(shù)據(jù)采集是分為傳統(tǒng)數(shù)據(jù)庫通過手動(dòng)輸入或是SQL語句及代碼編寫連接數(shù)據(jù)庫實(shí)現(xiàn)數(shù)據(jù)收集,這些數(shù)據(jù)大多經(jīng)過為經(jīng)過處理的結(jié)構(gòu)化數(shù)據(jù)為主。
另一種數(shù)據(jù)采集為大數(shù)據(jù)平臺下的數(shù)據(jù)從文件系統(tǒng)以代碼進(jìn)行連接獲取數(shù)據(jù)為主,這些數(shù)據(jù)不限大小、類型。
協(xié)作系統(tǒng)構(gòu)建之后隨之出現(xiàn)了第三種數(shù)據(jù)獲取方式,Sqoop 可以實(shí)現(xiàn)傳統(tǒng)關(guān)系型數(shù)據(jù)庫與大數(shù)據(jù)平臺下的文件系統(tǒng)數(shù)據(jù)的導(dǎo)入導(dǎo)出,大數(shù)據(jù)平臺下的規(guī)范化數(shù)據(jù)可以直接導(dǎo)入關(guān)系型數(shù)據(jù)庫搭建的數(shù)據(jù)倉庫,同樣,大數(shù)據(jù)平臺只要有符合支持的數(shù)據(jù)接口,同樣可以接受傳統(tǒng)數(shù)據(jù)倉庫的數(shù)據(jù)。

圖5 協(xié)作系統(tǒng)的功能模塊圖
3.2 數(shù)據(jù)存儲方面
在傳統(tǒng)單節(jié)點(diǎn)數(shù)據(jù)倉庫而言,數(shù)據(jù)主要存儲在節(jié)點(diǎn)服務(wù)器上;大數(shù)據(jù)平臺數(shù)據(jù)主要存儲在分布式數(shù)據(jù)文件系統(tǒng)HDFS,數(shù)據(jù)存儲平臺以集群形式存在,數(shù)據(jù)存儲的數(shù)據(jù)量以及數(shù)據(jù)類型都不受限制。本文研究的協(xié)作系統(tǒng)對于數(shù)據(jù)存儲分工是:傳統(tǒng)關(guān)系型數(shù)據(jù)倉庫主要用于存儲實(shí)時(shí)性結(jié)構(gòu)化數(shù)據(jù),其余數(shù)據(jù)均由大數(shù)據(jù)平臺存儲,當(dāng)傳統(tǒng)數(shù)據(jù)存儲達(dá)到上限時(shí),大數(shù)據(jù)平臺可以利用Sqoop 分擔(dān)傳統(tǒng)數(shù)據(jù)庫的壓力。
4 無人機(jī)裝備訓(xùn)練數(shù)據(jù)的存儲系統(tǒng)平臺搭建
本節(jié)對大數(shù)據(jù)存儲系統(tǒng)進(jìn)行搭建,繼而完成協(xié)作平臺的搭建,實(shí)現(xiàn)協(xié)作系統(tǒng)的數(shù)據(jù)采集、管理功能、數(shù)據(jù)應(yīng)用等工作,由于系統(tǒng)設(shè)計(jì)主要以代碼實(shí)現(xiàn)為主,具體代碼設(shè)計(jì)過程簡要介紹。
4.1 協(xié)作平臺的搭建及相關(guān)工具的準(zhǔn)備
本文針對無人機(jī)裝備訓(xùn)練數(shù)據(jù)進(jìn)行搭建一個(gè)Hadoop的小型集群,模擬無人機(jī)裝備訓(xùn)練時(shí)各系統(tǒng)單元組的數(shù)據(jù)采集節(jié)點(diǎn)。
假設(shè)由五個(gè)節(jié)點(diǎn)組成,其中一個(gè)節(jié)點(diǎn)作為NameNode、輔助 NameNode 與 TaskTracker,其余四個(gè)節(jié)點(diǎn)作為DataNode 和TaskTracker。此外還有一臺主機(jī)采用傳統(tǒng)數(shù)據(jù)倉庫進(jìn)行存儲結(jié)構(gòu)化數(shù)據(jù),用來存儲Hive 數(shù)據(jù)倉庫的元數(shù)據(jù),Hadoop 數(shù)據(jù)倉庫構(gòu)架如圖6 所示。

圖6 Hadoop 與傳統(tǒng)數(shù)據(jù)倉庫協(xié)作結(jié)構(gòu)示意圖
大數(shù)據(jù)存儲系統(tǒng)搭建的硬件準(zhǔn)備工具還需要很多的hadoop 的相關(guān)工具,它們主要包括數(shù)據(jù)傳輸工具Sqoop、大數(shù)據(jù)的數(shù)據(jù)倉庫工具Hive、傳統(tǒng)數(shù)據(jù)倉庫搭建工具SQL-Server2014、大數(shù)據(jù)hadoop 的開發(fā)軟件eclipse 等等。具體見表 1 所示[5]。
4.2 相關(guān)軟件在集群中的配置
首先對 Hive、Sqoop、MySQL 等軟件的安裝與配置,將 Hadoop、Hive、Sqoop、MySQL 在Master 節(jié)點(diǎn)上進(jìn)行配置,Slave 節(jié)點(diǎn)上與Master 配置的Hadoop 一樣進(jìn)行配置,且只需配置Hadoop。進(jìn)行正確配置后,然后進(jìn)行正確測試后才能進(jìn)行存儲系統(tǒng)的搭建。在此首先介紹協(xié)作系統(tǒng)的環(huán)境準(zhǔn)備過程,對于代碼實(shí)現(xiàn)簡單介紹。
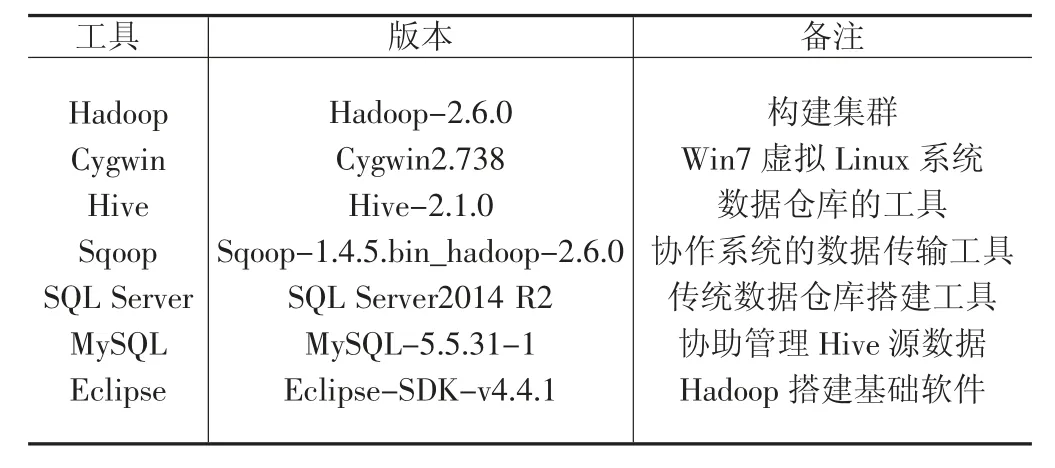
表1 工具硬件軟件準(zhǔn)備表
①安裝window7 專業(yè)版操作系統(tǒng),設(shè)置主機(jī)名稱(Master)、主機(jī)的 IP(192.168.100)地址,使用 SSH(Secure Shell Client)無密碼登入;
②安裝 JDK(Java Development Kit),Eclipse 軟件,搭建Java 運(yùn)行環(huán)境;大數(shù)據(jù)建立在Eclipse 的系統(tǒng)開發(fā)軟件下,首先電腦安裝 JDK(Java SE Development Kit),然后安裝Eclipse 軟件,打開Eclipse 軟件,將Hadoop 的插件hadoop-eclipse-plugin-2.7.1.jar 解壓在E:盤后加載Eclipse軟件下的plugins 文件中,如圖7 所示。

圖7 加載Hadoop 插件過程圖
加載插件后,重啟Eclipse 軟件,便可以運(yùn)行HDFS Locations。最后搭建大數(shù)據(jù)平臺過程,如圖8 所示。
③安裝Hadoop,在Hadoop-env.sh 文件中設(shè)置Java 環(huán)境,修改配置文件 master、slaves、cor-site.xml、mapred-site.xml、hafs-site.xml,加載 Hadoop 過程,如圖 9 所示。
至此Hadoop 在eclipse 的環(huán)境下安裝完畢,而且在eclipse 中集成了 HDFS 與 MapReduce 等 Hadoop 的分系統(tǒng),完成了環(huán)境的配置,接下來便可以進(jìn)行協(xié)作系統(tǒng)的開發(fā)了。這里需要注意一般Hadoop 是在Linux 系統(tǒng)下安裝,此處對于在Window 系統(tǒng)下安裝,需要修改相關(guān)配置與路徑。
圖8 搭建大數(shù)據(jù)Hadoop 數(shù)據(jù)倉庫過程
圖9 加載hadoop 系統(tǒng)
4.3 協(xié)作系統(tǒng)數(shù)據(jù)采集、管理、應(yīng)用的實(shí)現(xiàn)
前面已經(jīng)介紹了協(xié)作系統(tǒng)是由三大模塊組成,其中數(shù)據(jù)應(yīng)用模塊由兩部分組成:數(shù)據(jù)倉庫的應(yīng)用、大數(shù)據(jù)平臺應(yīng)用。此處從功能角度進(jìn)行介紹協(xié)作系統(tǒng)的實(shí)現(xiàn)過程。
①數(shù)據(jù)采集過程。此處主要介紹傳統(tǒng)數(shù)據(jù)倉庫中的數(shù)據(jù)如何傳輸?shù)酱髷?shù)據(jù)平臺,將傳統(tǒng)數(shù)據(jù)倉庫中存放的歷史數(shù)據(jù)、近期不常用的數(shù)據(jù)導(dǎo)入到大數(shù)據(jù)存儲系統(tǒng),解決單節(jié)點(diǎn)傳統(tǒng)數(shù)據(jù)倉庫的存儲量瓶頸問題。這里協(xié)作存儲主要用到Hadoop 的第三方工具模塊Sqoop,在Sqoop 的協(xié)助下可以輕松的實(shí)現(xiàn)數(shù)據(jù)在關(guān)系數(shù)據(jù)庫管理系統(tǒng)(RDBMS)與大數(shù)據(jù)平臺Hadoop 之間的傳輸。
對于數(shù)據(jù)采集過程,主要是采用Sqoop 工具,實(shí)現(xiàn)關(guān)系型數(shù)據(jù)輕松導(dǎo)入到Hadoop 平臺下的HBase 和Hive中。利用Java 語言實(shí)現(xiàn)大數(shù)據(jù)平臺下數(shù)據(jù)導(dǎo)入到HDFS文件系統(tǒng)中,導(dǎo)出數(shù)據(jù)過程類似導(dǎo)入過程,具體代碼如圖10 所示。
上面介紹的是數(shù)據(jù)存儲在HDFS 中,但是數(shù)據(jù)存儲在HDFS 中不便于應(yīng)用,結(jié)構(gòu)化數(shù)據(jù)導(dǎo)入到Hive 中可以采用Hive-SQL 語言HSQL 進(jìn)行管理,本質(zhì)上也是SQL 語言實(shí)現(xiàn)MapReduce 的過程,結(jié)構(gòu)化數(shù)據(jù)導(dǎo)入Hive 數(shù)據(jù)存儲的具體代碼如圖11 所示。
以上完成數(shù)據(jù)采集系統(tǒng)的搭建,數(shù)據(jù)的具體采集過程在此不做詳細(xì)介紹。

圖10 數(shù)據(jù)采集代碼1

圖11 數(shù)據(jù)采集代碼2
②數(shù)據(jù)管理、應(yīng)用過程。無人機(jī)裝備訓(xùn)練數(shù)據(jù)的種類多樣,要實(shí)現(xiàn)系統(tǒng)處理各種數(shù)據(jù)的能力,導(dǎo)致數(shù)據(jù)采集后存儲在HDFS 中,這對數(shù)據(jù)的應(yīng)用不利,因此考慮數(shù)據(jù)存儲在Hive 中,便于數(shù)據(jù)的管理。但是數(shù)據(jù)在大數(shù)據(jù)Hadoop 中存儲,基于HDFS 的高容錯(cuò)、低硬件要求,數(shù)據(jù)歸根到底還是存儲在HDFS 中。數(shù)據(jù)應(yīng)用主要是在數(shù)據(jù)采集、存儲后的最終步驟,數(shù)據(jù)應(yīng)用在此處分成傳統(tǒng)數(shù)據(jù)倉庫與大數(shù)據(jù)平臺兩部分。
無人機(jī)裝備訓(xùn)練數(shù)據(jù)存儲的協(xié)作系統(tǒng)的實(shí)現(xiàn),是基于Hadoop 平臺的分布式系統(tǒng),其次是其他相關(guān)軟件,如Hive、Sqoop 等的正確配置、安裝、調(diào)試、測試后進(jìn)行的。
5 結(jié)語
Sqoop 作為Hadoop 的第三方模塊,成功實(shí)現(xiàn)數(shù)據(jù)在關(guān)系型數(shù)據(jù)庫與Hadoop 平臺之間的導(dǎo)入與導(dǎo)出。成功解決了無人機(jī)裝備訓(xùn)練數(shù)據(jù)存儲的難題,協(xié)作系統(tǒng)的成功實(shí)現(xiàn)也是眾多系統(tǒng)、軟件的功能融合。本文研究的協(xié)作存儲系統(tǒng)不僅適用于無人機(jī)裝備訓(xùn)練數(shù)據(jù)的存儲,同樣適用于其它信息化裝備訓(xùn)練數(shù)據(jù)的存儲,尤其是未來聯(lián)合作戰(zhàn)中各種數(shù)據(jù)的存儲,因此該協(xié)作系統(tǒng)為未來部隊(duì)數(shù)據(jù)存儲提供了技術(shù)支撐,為未來數(shù)據(jù)在部隊(duì)中的實(shí)際應(yīng)用提供了現(xiàn)實(shí)依據(jù)。
猜你喜歡
工業(yè)設(shè)計(jì)(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(shù)(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
財(cái)經(jīng)(2017年15期)2017-07-03 22:40:49
財(cái)經(jīng)(2017年2期)2017-03-10 14:35:35
財(cái)經(jīng)(2016年15期)2016-06-03 07:38:02
財(cái)經(jīng)(2016年3期)2016-03-07 07:44:46
