基于BERT的復合網(wǎng)絡模型的中文文本分類
2020-12-23 09:10:14方曉東劉昌輝王麗亞
武漢工程大學學報 2020年6期
方曉東,劉昌輝,王麗亞,殷 興
武漢工程大學計算機科學與工程學院,湖北 武漢430205
文本分類[1]是自然語言處理(natural language process,NLP)任務的基礎工作也是其研究領域的熱點之一,主要目的是針對文本進行歸類,便于對文本進行高效管理配置與檢索并解決信息過載的問題。由于網(wǎng)絡上產(chǎn)生的媒體新聞、科技、報告、電子郵件、網(wǎng)頁、書籍、微博等文本內(nèi)容呈現(xiàn)指數(shù)增長,需要對這些文本進行歸類加以組織管理,也可根據(jù)用戶的偏好,進行信息過濾或精確優(yōu)先推薦,增強用戶黏性,因此具有一定的應用研究價值。
transformers的 雙 向 編 碼 器(bidirectional encoder representations from transformer,BERT)在文本分類上的成功應用,有效地促進了文本分類的研究與發(fā)展[2]。但基于BERT的文本主題分類大多數(shù)都是以英文數(shù)據(jù)集為對象,針對中文網(wǎng)絡新聞文本的研究多數(shù)都是在詞語級詞向量的基礎上提出網(wǎng)絡模型結構。本文通過學習BERT模型、雙向門控循環(huán)神經(jīng)網(wǎng)絡(bi-directional gated recur?rent unit,BiGRU)模型,為提高文本主題分類的準確率,提出基于BERT的復合網(wǎng)絡模型(BiGRU+BERT混合模型,bG-BERT)的文本主題分類方法,在實驗所用中文新聞數(shù)據(jù)集上使用NLP的綜合評價指標Accuracy值、F1值,證明了bG-BERT模型在文本分類方面的有效性。
1 相關研究
文本主題分類方法主要有詞匹配法、統(tǒng)計學習方法和基于深度學習的方法[3]。詞匹配法是根據(jù)查詢文檔中的詞語是否出現(xiàn)在需要分類的文檔內(nèi)容中,這種方法沒有考慮上下文聯(lián)系,方法過于簡單機械。統(tǒng)計和機器學習的方法[4-5],是通過特征工程然后再結合機器學習的方法,首先將標注的訓練集的內(nèi)容部分轉(zhuǎn)換為特征,再使用特征提取分類特征,最后使用樸素貝葉斯、回歸模型、支持向量機等文本分類器進行分類。由于分類器性能的好壞主要依賴查詢詞典設計有效的特征,需要專業(yè)知識豐富的的專家來設計分類特征,人為影響因素大。因此早期的文本分類方法難以勝任復雜的篇章級別新聞文本主題分類任務。后期出現(xiàn)的基于深度學習的方法是傳統(tǒng)機器學習的重要分支。
文本表示方面,Zhang等[6]應用的word2vec模型,其核心思想是通過上下文得到字詞的向量化表示,一種根據(jù)前后的字詞預測中間字詞的CBOW模型和另一種利用中間字詞去預測前后的字詞的Skip-gram模型,解決了高效表達一篇文檔的難點。鄭亞南等[7]使用glove模型進行特征提取,再使用SVM進行分類。趙亞歐等[8]使用ELMo模型,動態(tài)調(diào)整word emdedding,解決了詞語用法的復雜性以及這些復雜用法在不同上下文中的變化。胡春濤等[9]使用BERT模型,采用雙向Trans?former進行句子篇章級別的提取特征,彌補了word2vec無法理解不同字詞在不同位置語義不同的不足,相對ELMo的單向Transformer,BERT綜合考慮前后兩個方向的信息,具有更優(yōu)的并行性。
構建語言模型方面,陳巧紅等[10]將卷積神經(jīng)網(wǎng)絡(convolutional neural networks,CNN)應用于文本分類,將經(jīng)過向量化的文本作為輸入,最大程度提取深層局部特征,但缺少學習序列相關性的能力。孫敏等[11]把長短時記憶網(wǎng)絡(long short-term memory,LSTM)應用于情感分析,由若干遺忘記憶模塊組成復雜網(wǎng)絡結構,能更好獲取上下文特征,有效解決梯度消失問題。盧健等[12]提到門控循環(huán)神經(jīng)網(wǎng)絡(gated recurrent unit,GRU),是由LSTM而來,其結構更簡單,收斂速率更快。吳小華等[13]將雙向長短時記憶網(wǎng)絡(bi-directional long short-term memory,BiLSTM)用于情感分析,BiL?STM由雙向的LSTM網(wǎng)絡組成,可更好獲取文本句法信息。王麗亞等[14]等將雙向門控循環(huán)神經(jīng)網(wǎng)絡的雙通道模型用于文本分類,BiGRU是由正向的、方向相反的,且輸出由這兩個GRU的狀態(tài)共同決定的GRU組成的神經(jīng)網(wǎng)絡模型,并且能有效彌補LSTM訓練時間長,GRU不能同時捕獲前后詞的特征的不足。
本文針對中文新聞文本,綜合考慮BERT模型在文本表示方面,BiGRU在語言模型構建的特征優(yōu)化方面的優(yōu)點,提出了基于BERT的復合網(wǎng)絡模型(bG-BERT)。充分利用BERT模型強大的語義信息獲取能力,提取語句特征,然后使用BiGRU網(wǎng)絡強化在不同時間段更新后的上下文特征,減少特征在傳遞過程中的信息損失,篩選出豐富包含全局特征,深化模型的特征學習能力,從而提高新聞文本分類的準確率和高效性,減少訓練時長,實驗最后驗證了模型的實際應用能力。
2 基于BERT的復合網(wǎng)絡模型
基于BERT的復合網(wǎng)絡模型(bG-BERT),主要圍繞以下三部分展開:第一部分為BERT模型輸入和預訓練,第二部分為bG-BERT模型網(wǎng)絡結構的建立,第三部分為bG-BERT模型訓練。
2.1 BERT模型輸入表征及預訓練
與傳統(tǒng)的word2vec和glove模型相比較,傳統(tǒng)模型的嵌入為文本內(nèi)的每個字詞提供一個只含有局部信息表示的表示。BERT模型,目的是利用無標注預料進行訓練,獲得包含豐富語義信息的表示。BERT模型的輸入可以是一個句子或句子對c=[w1,w2,…,wn],[s1],[s2],…,[sn]](wn為第一句話里面的第n個單詞,sn表示一段話里的第n個句子),實際的輸入值是經(jīng)過Word Piece?token的中文字向量(Token Embedding),Etoken=,判 斷 前 后 句 的Segment Embedding,Esegment={EA1,EA2,…EAn,EB1,EB2…,EBn}(An表示句子對中的前一句話的第n個單詞,Bn表示對子對后面一句話的第n個單詞)和區(qū)分不同位置字詞所攜帶信息存在差異的Position Em?bedding,Eposition={E0,E1,…,En},三者的信息的總和。
BERT模型預訓練分成兩個階段,第一個階段是Masked LM,為訓練雙向transformer[15]表示,采用隨機掩蓋每個序列中的15%的輸入詞,然后基于上下文來預測被掩蓋的詞語。第二個階段是Next Sentence Prediction,這一任務中主要學習判斷兩個句子之間的關聯(lián)性,使模型具備理解長序列上下文的聯(lián)系能力。
2.2 bG-BERT模型結構特征
該混合模型由3部分組成:首先BERT提取文本的語義表示特征,主要使用BERT的核心模塊Transformer獲取全局的語義信息;其次使雙向GRU加強深層特征表示,最后引入分類器,主要由dropout防止混合網(wǎng)絡過擬合,使用softmax函數(shù)預測新聞文本所屬類別。模型如圖1所示。
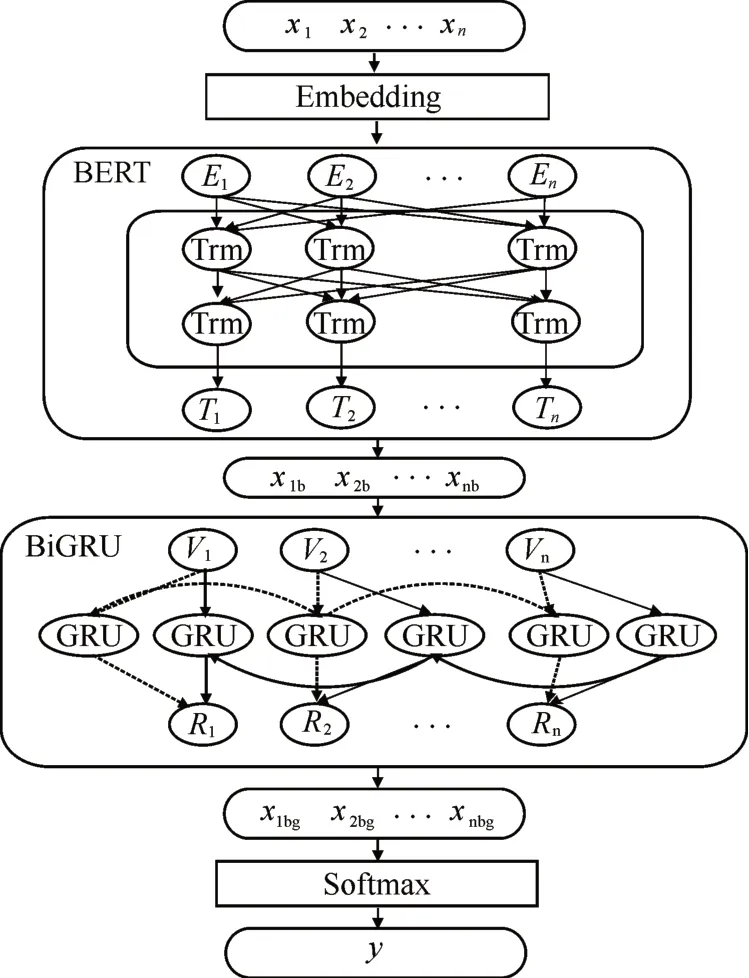
圖1 bG-BERT模型Fig.1 bG-BERT model
1)獲取輸入表征后,首先使用具有12個Transformer特征抽取器,逐層傳遞并細化特征表示,計算如公式1所示:
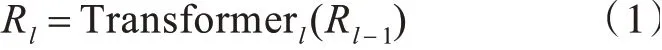
式中,l表示對應的層數(shù),Rl為經(jīng)過對應層的特征的上下文表示。
Self-Attention機制是Transformer中的關鍵部分,Self-Attention機制主要分為4個步驟:首先輸入為目標字詞、上下文各個字詞的語義向量表示,通過線性變換獲取目標字詞的Query向量表示、上下文各個字詞的Key向量表示和目標字詞與上下文各個字詞的原始Value向量表示;其次計算Que?ry向量和各個Key向量的相似度得到權重,常用的相似度函數(shù)有點積、拼接、感知機等;然后使用softmax函數(shù)對這些權重進行歸一化處理;最后將權重和目標詞的原始Value和各上下文字的Value向量進行求和,得到最后的增強語義向量表示;作為Attention的輸出,計算過程如下:

式中,Q為文本中的字詞,K為上下文的各個字,V為目標字及其上下文的字都有各自的原始Value,Ki為第i個字的Key值,Wi為第i個字時的權值向量,為相似度,Self-Attention為注意力概率分布,j表示維數(shù),J表示維數(shù)上界。
通過Embedding的向量輸入到BERT模型的Transformer的編碼器和解碼器之后,對于單文本分類來說,BERT模型在文本前插入一個[CLS]符號,與其他文本中已有的字詞相比,該符號無明顯語義信息會更公平地融合文本中各個字詞的相關信息,該符號對應的輸出向量作為整篇文檔的語義表示,可作為輸入到后續(xù)模型進行特征加強或分類。
2)將BERT模型輸出的融入語義篇章信息的特征向量,輸入到BiGRU模型。其中更新門和重置門是其核心組件。更新門Ut用于控制前一時刻的狀態(tài)信息傳入到當前狀態(tài)的程度,重置門Ft用于遺忘前一時刻狀態(tài)信息的程度。將重要特征保留,保證其在long-term傳播的時候也不會被丟失。其計算過程如公式6~9所示。式中,Ut表示t時刻的更新門,F(xiàn)t表示t時刻的重置門表示t時刻的候選激活狀態(tài),ht表示t時刻的激活狀態(tài),Wt為權值矩陣,xt為t時刻GRU的輸入。
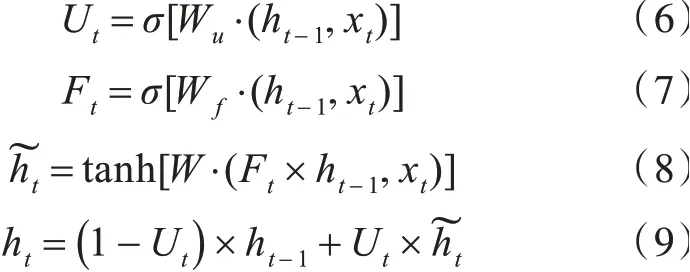
3)獲取語義篇章信息,加強特征的表示向量,傳給softmax函數(shù)進行預測分類結果b={y1,y2,…,yn},對應相應的新聞主題。
2.3 bG-BERT模型訓練
訓練模型是為了最小化損失函數(shù)。本文選取的損失函數(shù)為交叉熵損失函數(shù),優(yōu)化器選取Adam。
算法:bG-BERT模型的新聞文本分類算法
輸入:訓練數(shù)據(jù)集x=[x1,x2,…,xn],對應標簽y=[y1,y2,…,yn]
輸出:輸入樣本屬于每個類別的概率pi=(0,0,0,1,0,0,0,0,0,0)
初始化模型中的參數(shù)。
數(shù)據(jù)預處理:將分類的文本轉(zhuǎn)化為字向量、句子向量和位置向量三者的綜合e=[e1,e2,…,en]。然后作為bG-BERT模型的輸入。
For each text:
用softmax進行分類:

其中k為維數(shù),z為實向量。y是10維向量表示預測屬于該類的概率。
3 結果與討論
3.1 實驗數(shù)據(jù)、環(huán)境與參數(shù)
實驗采用的數(shù)據(jù)集是THUCNews,數(shù)據(jù)來自新浪新聞RSS訂閱頻道2005-2011年的歷史數(shù)據(jù)篩選過濾生成,包含74萬篇新聞文檔。從原始數(shù)據(jù)集上選取10個分類標簽(體育、娛樂、家居、房產(chǎn)、教育、時尚、時政、游戲、科技、財經(jīng))。訓練集、驗證集和測試集分別為5 000×10,500×10,1 000×10,總共6.5萬條。對本文提出的bG-BERT模型新聞文本分類方法進行驗證和分析。
實驗環(huán)境配置如下,語言:Python3.7,工具:Google Colaboratory,框架:Keras2.2.5,處理器:Tes?la K80 GPU。
本文模型參數(shù)具體設置如下:嵌入向量維度VEC的維度為128,BERT的 維 度 為768,BiGRU的維度為10,BERT的學習率為0.000 01,VEC的學習率為0.001。
3.2 對比實驗設置
為測試模型的有效性,選擇了多個對比模型進行比較,主要包括以下5個:
1)Word2Vec-BiGRU(W2V-bG):單一的BiGRU網(wǎng)絡,利用word2vec訓練得到的詞向量作為輸入。
2)CNN-BiLSTM-Attention(CNN-bL-Att):CNN-bL-Att組合的復合網(wǎng)絡模型。
3)BERT:單一的bert模型。
4)BERT-BiLSTM(bL-BERT):單一的BiLSTM網(wǎng)絡,利用BERT訓練得到的詞向量作為輸入。
5)bG-BERT:單一的BiGRU網(wǎng)絡,利用BERT訓練得到的詞向量作為輸入。
1、5對照為證明BERT特征抽取能力高于word2vec模型。3、4、5對照為證明BiGRU模型的能使特征更加優(yōu)化。2、5比較證明比現(xiàn)已提出的國際最新的新聞文本分類的效果更加優(yōu)化。
3.3 實驗結果分析
由于用測試集所得的評測指標分數(shù)比用訓練集所得的分數(shù)更能反映一個模型的優(yōu)劣。實驗選擇在測試集上的具體驗證對比結果如表1所示。
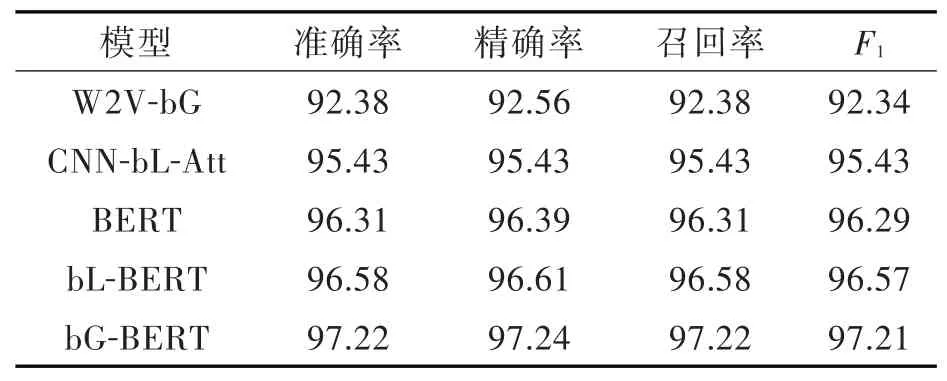
表1模型對比結果Tab.1 Results of model comparison %
從表1可以看出,bG-BERT模型的準確率和F1值均高于第3組和第4組,可以證明BiGRU對于序列化的語義特征具有更好的更新強化作用。在與第1、2組實驗對比結果可以看出,BERT能有效提升準確率和F1值,證明BERT對于預訓練時能準確高效地提取文本中的特征,有利于下游任務進行分類。整體來看,本文提出的bG-BERT模型的分類效果更好,充分發(fā)揮了BERT對于語義表示特征的能力,并遷移到下游分類任務提升模型整體的性能,BiGRU對于預處理的特征表示的特征抽取以及深層次特征學習的能力。并且與現(xiàn)已提出的國際最新的CNN-BiLSTM-Attention復合網(wǎng)絡模型新聞文本分類的的F1值高出1.78個百分點。其中bG-BERT在Accuracy、F1上取得最高值為97.22%、97.21%。
為清晰地反映5組模型的優(yōu)劣,分別繪制了各模型的準確率a和損失率l在驗證集上的變化曲線,如圖2所示。
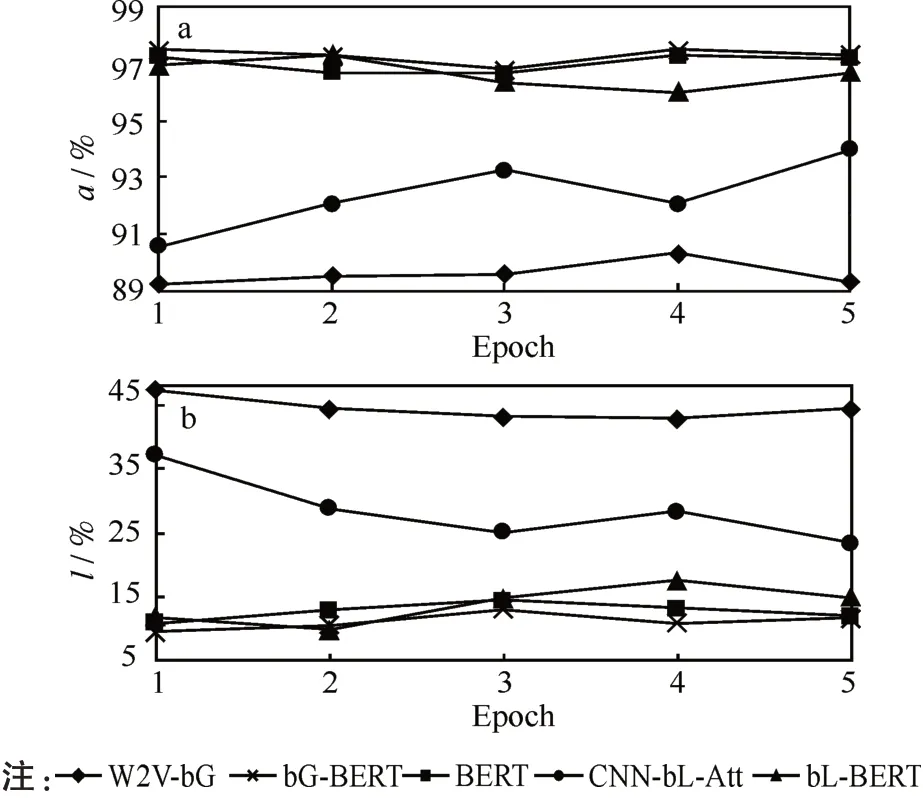
圖2驗證集評測圖:(a)準確率變化,(b)損失率變化Fig.2 Validation set evaluation diagrams:(a)accuracy rate variation,(b)loss rate variation
本次實驗訓練迭代次數(shù)為5次(W2V-bG,CNN-bL-Att的Epoch為10,圖2中 的W2V-bG,CNN-bL-Att的取值為訓練10次中的后面5次的數(shù)據(jù)),從圖2的準確率和損失率變化可以看出,使用BERT進行特征抽取,明顯要優(yōu)于傳統(tǒng)的Word2Vec模型。而使用BERT的3組模型雖然很接近,但是結果相比BERT模型、bL-BERT模型仍然有微小的提升。準確率的最高值97.52%,損失率的最低值9.51%均為bG-BERT模型上計算得出(Epoch為1時),此外bG-BERT模型整體也較為穩(wěn)定,在新聞文本分類上更具有優(yōu)勢。
綜上所述,在相同數(shù)據(jù)集中,bG-BERT表現(xiàn)性能優(yōu)于其他模型,能夠提高文本分類的準確率,且具有很好的應用能力。
4 結論
本文采用復合網(wǎng)絡的bG-BERT模型,應用在中文新聞文本分類任務中,在中文新聞文本上進行訓練和測試取得較好的分類效果。并且與單獨的BERT模型,BiGRU以及最新融入注意力的bL-BERT模型進行比較,取得的準確率和F1值更優(yōu),結果表明基于bG-BERT模型能有效學習到長文本中的深層次重要特征,以及上下文的信息。但由于混合后的模型需要的網(wǎng)絡參數(shù)更多,結構更加復雜,需要更多的算力和時間代價。下一步的研究目標將探究如何優(yōu)化高分類準確率下且計算與時間代價和損失更小的參數(shù)更少的輕量型復合網(wǎng)絡模型。
猜你喜歡
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
