多維度注意力和語義再生的文本生成圖像模型
2020-12-25 06:07:56莊興旺丁岳偉
計算機技術與發展 2020年12期
莊興旺,丁岳偉
(上海理工大學 光電信息與計算機工程學院,上海 200093)
0 引 言
文本生成圖像(text to image,T2I)是指生成與給定文本描述匹配的視覺真實圖像。由于其在許多應用領域的巨大潛力,T2I已經成為自然語言處理和計算機視覺界的一個重要研究領域。雖然在使用生成對抗網絡(GAN)生成視覺逼真的圖像方面取得了重大進展,如文獻[1-8]所示,但確保生成的圖像與輸入文本的語義對齊仍然具有很大的挑戰性。
與基本的圖像生成問題相比,T2I是以文本描述為條件的,而不是僅從噪聲開始。利用GAN[9]的強大功能,提出了不同的T2I方法來生成視覺逼真的文本圖像。例如,Reed等人提出了一種解決文本到圖像合成問題的方法,即找到文本描述的視覺識別表示,并利用該表示生成真實的圖像[10]。Zhang等人提出了在兩個獨立的階段生成圖像的Stackgan[2]。Hong等人提出了從輸入文本中提取語義布局,然后將其轉換為圖像生成器,以指導生成過程[5]。Zhang等人提出在網絡層次結構中引入了伴隨的層次嵌套對抗性目標,它規范了中間層的表示,并幫助生成器訓練來捕獲復雜的圖像統計信息[3]。這些方法都僅利用鑒別器來區分。然而,由于文本和圖像之間域的差異,當單獨依賴于這樣一個鑒別器時,很難對語義一致性進行建模。最近,人們利用注意力機制[4]來解決這一問題,它引導生成器在生成不同的圖像區域時關注于不同的單詞。然而,由于文本和圖像形式的多樣性,僅在單詞級別使用注意力并不能確保全局語義的一致性。T2I生成可以看作是圖像字幕(或圖像到文本生成,I2T)的逆問題[11-12]。如果T2I生成的圖像在語義上與給定的文本描述一致,那么T2I重新描述的語義應該與給定的文本描述完全相同。基于這一觀察,該文在MirrorGAN的基礎上提出了一種新的文本到圖像到文本的模型MirrorGAN++來改進T2I的生成。MirrorGAN++有兩個模塊:MCAM和STRM。MCAM是多維度的注意力協同模塊,利用單詞級別的注意和全局句子級別的注意逐步增強生成圖像的多樣性和語義一致性。STRM是語義文本再生模塊,它可從最后生成的圖像重新生成文本描述,在語義上與給定的文本描述對齊。對兩個公共基準數據集進行的深入實驗表明,在視覺真實性和語義一致性方面,MirrorGAN++優于其他方法。
1 相關工作
CycleGAN[13-15]可以讓兩個領域的圖片互相轉化[16-17],傳統的GAN是單向生成,而CycleGAN是互相生成。MirrorGAN++部分靈感來自CycleGAN,但有兩個主要區別:
(1)MirrorGAN++專門解決T2I問題,而不是圖像到圖像的轉化。文本和圖像之間的跨媒體域間隙可能比具有不同屬性(例如樣式)的圖像之間的間隙大得多。此外,每個域中存在的不同語義使得保持跨域語義一致性變得更加困難。
(2)MirrorGAN++通過使用成對的文本圖像數據進行監督學習,而不是從不成對的圖像數據進行訓練。此外,為了體現通過重新描述學習T2I生成的思想,使用基于CE的重構損失來規范重新描述的文本的語義一致性,這與CycleGAN中的L1循環一致性損失不同,后者處理視覺相似性。該模型是基于MirrorGAN的,然而,由于MirrorGAN對輸入的文本是用RNN來處理,使用RNN生成的詞嵌入和句嵌入表現沒有BERT生成的好,所以選擇用BERT來生成詞嵌入和句嵌入,這樣可以更好地提升模型生成圖片的質量。對于語義文本再生模塊,選用更加先進的圖像字幕模型來更好地提升模型的語義一致性。
2 模型實現
如圖1所示,MirrorGAN++集成了T2I和I2T模塊,它利用了重新描述學習T2I生成的思想。生成圖像后,MirrorGAN++會重新生成其描述,從而將其語義與給定的文本描述對齊。從技術上講,MirrorGAN++由兩個模塊組成:MCAM和STRM。模型的細節將在下面介紹。
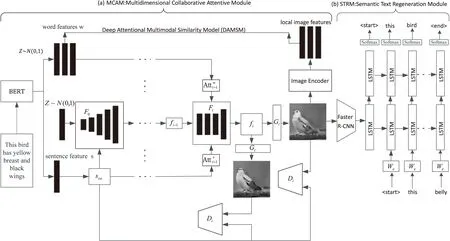
圖1 用于文本到圖像生成的模型MirrorGAN++示意圖
2.1 MCAM:多維度的注意力協同模塊
首先,引入文本編碼器,將給定的文本描述嵌入到本地單詞級特征[18]和全局句子級特征中。如圖1最左邊的部分所示,BERT[19]用于從給定的文本描述T中提取語義嵌入,其中包括單詞嵌入w和句子嵌入s。
w,s=BERT(T)
(1)
其中,T={Tl|l=0,1,…,L-1},L表示句子長度,w∈RD×L,s∈RD,D是w和s的維數,由于文本域的多樣性,組合較少的文本可能具有相似的語義。因此,使用條件增廣方法[2]來增廣文本描述。這將產生更多的圖像文本對,具體來說,使用Fca來表示條件增強函數,并獲得增廣后的句子向量:
sca=Fca(s)
(2)
其中,sca∈RD',D'為增廣后的維數。
下一步將三個圖像生成網絡依次疊加,構造一個多級級聯生成器。采用了文獻[4]中描述的基本結構,因為它在生成真實圖像方面具有良好的性能。在數學上,使用{F0,F1,…,Fm-1}表示m個視覺特征變換器,{G0,G1,…,Gm-1}表示m個圖像生成器。每個階段的視覺特征fi和生成的圖像Ii可以表示為:
(3)
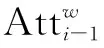
首先,使用文獻[4]中提出的單詞級注意模型來生成一個注意詞的上下文特征。它以詞嵌入w和視覺特征f作為每個階段的輸入。詞嵌入w首先被感知層Ui-1作為Ui-1w轉換成視覺特征的公共語義空間,然后將其與視覺特征fi-1相乘,得到注意力得分。最后,通過計算注意力得分與Ui-1w之間的內積,得到注意詞的上下文特征:
(4)
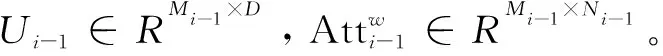
然后,提出了一個句子級注意模型,在生成期間對生成器實施全局約束。通過與單詞級注意模型的類比,將增廣的句子向量sca通過感知層Vi-1轉換為視覺特征的潛在公共語義空間Vi-1sca。然后,將其與視覺特征fi-1進行元素相乘,得到注意力得分。最后,通過計算注意力得分與Vi-1sca的元素相乘得到注意句上下文特征:
(5)
2.2 STRM:語義文本再生模塊
就像之前說的那樣,MirrorGAN++包含一個語義文本再生模塊(STRM),用于從生成的圖像中重新生成文本描述,該圖像在語義上與給定的文本描述對齊。具體來說,使用了一個自下而上和字幕模型相結合的注意力模型[20]作為基本的STRM的體系結構。
其中,自下而上的注意模型(使用Faster R-CNN)用于提取圖像中的興趣區域,獲取對象特征。預先將它在ImageNet[21]上訓練。而字幕模型用于學習特征所對應的權重(使用2個LSTM模塊)。
在自下而上的注意力模型中,把最后階段生成器生成的圖像Im-1送入這個注意力模型中,如下所示:
(6)
其中,vi是一個視覺特征,在字幕模型中用作輸入。
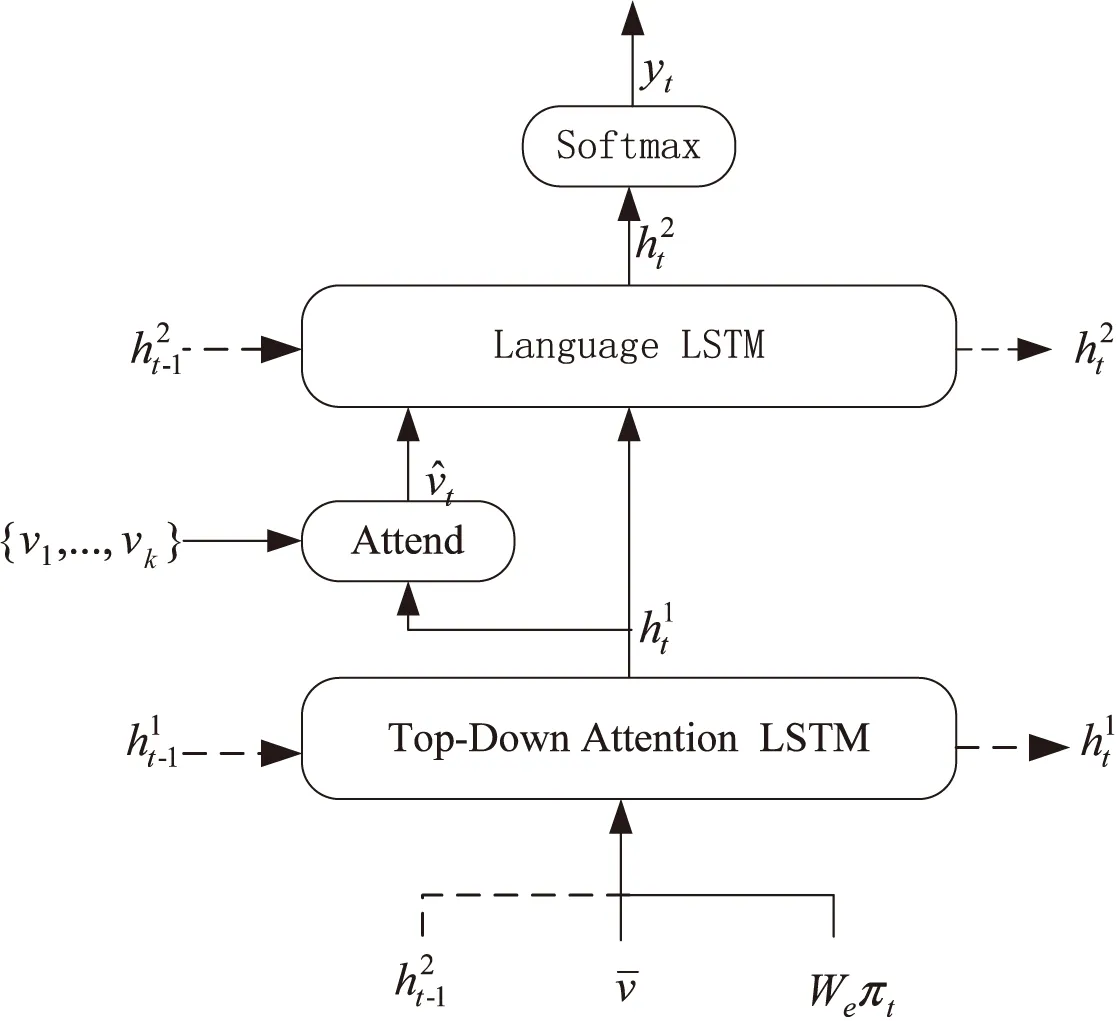
圖2 字幕模型的示意圖
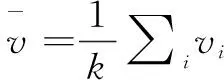
(7)
其中,We表示一個詞嵌入矩陣,它將文字特征映射到視覺特征空間,∏t是輸入單詞的獨熱編碼。
(8)
其中,Wva∈RH×M,Wha∈RH×M,wa∈RH是學習參數。
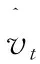
(9)
Language LSTM的輸入包括圖像特征和Attention LSTM的輸出,由下式給出:
(10)
詞的概率分布為:
(11)
其中,Wp∈R|∑|×M,bp∈R|∑|是學習的權重和偏差。
2.3 目標函數
根據普遍的做法,首先采用了兩種對抗性損失:視覺和真實的對抗性損失和文本圖像對語義一致性的對抗性損失,定義如下:
在模型訓練的每個階段,生成器G和鑒別器D交替訓練。特別是生成器Gi在第ith階段通過最小化損失進行訓練,如下所示:
(12)
其中,Ii是在第i階段的分布pIi中采樣生成的圖像。第一項是視覺和真實的對抗性損失,用來區分圖像是真實的還是虛假的。第二項是文本圖像對語義一致性的對抗性損失,用來確定圖像和句子語義是否是一致的。
進一步提出了一個基于CE的文本語義重構損失,以在STRM的重新描述和給定的文本描述之間對齊語義。從數學上講,這種損失可以表示為:
(13)
值得注意的是,在STRM預訓練期間,也使用了Lstrm。當訓練Gi時,從Lstrm到Gi的梯度通過STRM反向傳播,其網絡權重保持不變。
使用AttnGAN的DAMSM損失[4]LDAMSM來測量圖像和文本描述之間的匹配度。LDAMSM使生成的圖像更好地依賴于文本描述。
生成器的最終目標函數定義為:
(14)
其中,λ1和λ2是調節文本語義重構損失和DAMSM損失的相應權重。
鑒別器Di被交替訓練,以避免被生成器騙過去,將輸入分為實輸入和假輸入。與生成器類似,鑒別器的目標函數包括視覺和真實的對抗性損失和文本圖像對語義一致性的對抗性損失。在數學上,它可以定義為:

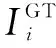
鑒別器的最終目標函數定義為:
(16)
3 實驗研究
在這一部分中,進行了大量的實驗,以評估提出的模型。首先將MirrorGAN++與之前的T2I方法,如GAN-INT-CLS[10]、StackGAN[2]、StackGAN++[22]、PPGN[23]、AttnGAN[4]和MirrorGAN[8]進行比較。然后,介紹了對MirrorGAN++中MCAM和STRM的關鍵部分的消融研究。
3.1 實驗方案
3.1.1 數據集
在兩個常用數據集上(CUB bird數據集[24]和MS COCO數據集[25])對模型進行評估。CUB bird數據集包含8 855個訓練圖像和2 933個測試圖像,包含200個類別,每個鳥圖像有10個文本描述。COCO數據集包含82 783個訓練圖像和40 504個驗證圖像,每個圖像有5個文本描述。兩個數據集使用文獻[2,4]中的方法進行預處理。
3.1.2 評價指標
首先,Inception Score[26]被用來衡量生成圖像的客觀性和多樣性。使用文獻[2]提供的兩個模型來計算分數。然后,使用文獻[4]中引入的R-precision來評估生成的圖像與其相應文本描述之間的視覺語義一致性。對于每個生成的圖像,使用其真實的文本描述和從測試集中隨機選擇的99個不匹配描述來形成文本描述池。然后,在計算R-precision之前,計算了池中每個描述的圖像特征和文本特征之間的余弦相似性。R-precision的值越高表示生成的圖像和輸入文本之間的視覺語義一致性越高。Inception Score和R-precision按文獻[2,4]計算。
3.1.3 實現細節
MirrorGAN++總共有三個生成器,最后兩個生器采用MCAM,如式(3)所示。逐步生成64×64、128×128、256×256像素的圖像。使用預訓練的BERT[19]計算文本描述中的語義嵌入。詞嵌入D的維數是256。句子長度L是18。視覺嵌入的維度Mi設置為32。視覺特征尺寸為Ni=qi×qi,三個階段的qi分別為64、128和256。增廣后的句嵌入D'的維度設置為100。文本語義重構損失的損失權重λ1設置為20,DAMSM損失權重λ2在CUB bird數據集中設置為5,在MS COCO數據集中設置為50。
3.2 實驗結果與分析
在本節中,將定量和定性地與其他方法進行比較。首先,對MirrorGAN++使用CUB bird和COCO數據集的Inception Score和R-precision與之前的文本生成圖像方法[2,4,8,10,22-23]進行比較。然后,對MirrorGAN++和之前的方法進行了主觀視覺比較,以驗證MirrorGAN++的有效性。
3.2.1 定量結果
將MirrorGAN++與CUB和COCO測試數據集上的其他模型進行了比較,結果見表1和表2。
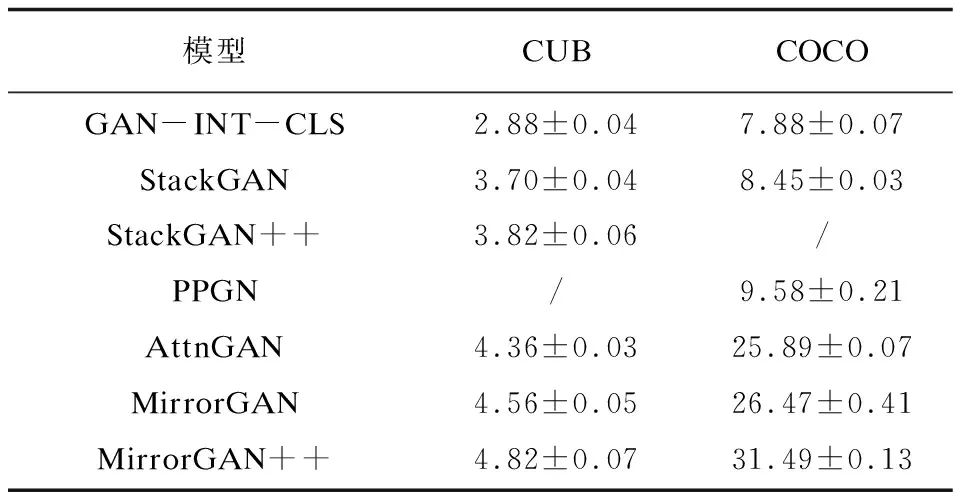
表1 不同模型在CUB和COCO數據集下的IS(越高越好)
如表1所示,MirrorGAN++模型在CUB數據集上IS達到了4.82,遠優于其他方法。與MirrorGAN相比,MirrorGAN++將CUB數據集的IS從4.56提高到4.82(提高5.70%),將COCO數據集的IS從26.47提高到31.49(提高18.96%)。實驗結果表明,MirrorGAN++模型生成的圖像質量更好。
如表2所示,MirrorGAN++與MirrorGAN相比將CUB數據集的RI提高了0.91%,COCO數據集的RI提高了1.42%。較高的RI表明,MirrorGAN++生成的圖像和輸入文本之間的視覺語義一致性較高,進一步證明了所采用的語義文本再生模塊的有效性。
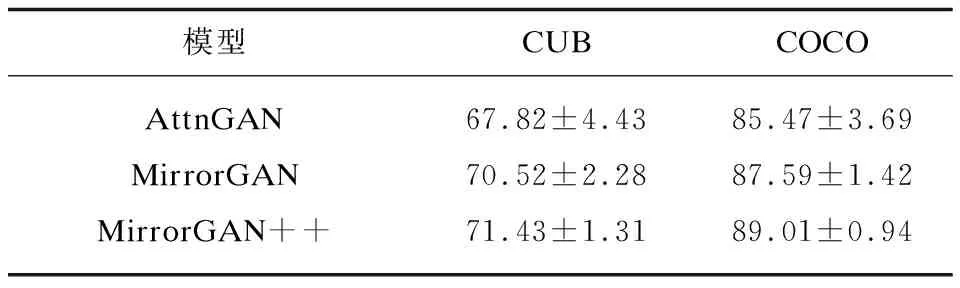
表2 不同模型在CUB和COCO數據集下的RI(越高越好)
3.2.2 定性結果
對于定性評估,圖3和圖4顯示了MirrorGAN++和之前模型生成的文本到圖像合成示例。與GAN-INT-CLS、StackGAN 和AttnGAN相比,STRM-AttnGAN++方法生成的圖像質量更高,細節更多,文本圖像的語義一致性也更好。這是因為MCAM和STRM有助于生成具有更多細節和更好語義一致性的細粒度圖像。

圖3 不同的模型在CUB測試集上的文本生成圖像
在單主題生成方面,即圖3中CUB數據集上生成的樣本,MirrorGAN++模型更好地突出了圖像的主題鳥并且細節呈現得更豐富,MirrorGAN++方法能夠更好地理解文本描述的邏輯,并呈現出更清晰的圖像結構。例如,圖3的第1列、第2列和第4列中AttnGAN生成的示例的鳥的頭部到圖片的外面,而文中模型就沒有這個問題。
在多主題生成方面,即圖4中的COCO數據集生成的樣本,當文本描述更復雜且包含多個主題時,生成圖像更具挑戰性。MirrorGAN++根據最重要的主題精確地捕捉主場景,并合理地安排其余的描述性內容,從而改善了圖像的整體結構。例如,在圖4的第2列需要標識浴室所需的組件,而MirrorGAN++是唯一一種成功的方法。還可以看出,圖4的第3列和第4列中GAN-INT-CLS、StackGAN 和AttnGAN生成的示例的形狀看起來很奇怪并且缺乏一些細節,而文中模型要好很多。
視覺結果表明,MirrorGAN++方法生成的圖像質量更高,細節更多,文本圖像的語義一致性也更好。

圖4 不同的模型在COCO測試集上的文本生成圖像
3.3 消融研究
MirrorGAN++關鍵部分的消融研究:接下來對所提出的模型進行消融研究。為了驗證STRM和MCAM的有效性,通過在MirrorGAN++中移除和添加這些成分進行了幾個比較實驗。結果見表3和表4。

表3 不同權重設置下的MirrorGAN++IS結果

表4 不同權重設置下的MirrorGAN++RI結果
首先,參數很重要。在CUB數據集上,λ2設置為5,當λ1從5增加到20時,IS從4.03增加到4.82,RI從45.77%增加到71.43%。在COCO數據集上,λ2設置為50,當λ1從5增加到20時,IS從21.15增加到31.49,RI從59.36%增加到89.01%。將λ1設為20作為默認值。
沒有MCAM和STRM(λ1=0)的MirrorGAN++已經比StackGAN++[22]和PPGN[23]取得了更好的效果。將STRM集成到MirrorGAN++中會進一步提高性能。IS在CUB中從3.87分提高到4.71分,在COCO中從19.78分提高到30.37分,RI呈相同趨勢。值得注意的是,沒有MCAM的MirrorGAN++已經超過了之前的AttnGAN(見表1),后者也使用了單詞級的注意力。這些結果表明,STRM在幫助生成器獲得更好的性能方面很有效。具體來說,STRM從最后生成的圖像重新生成文本描述,在語義上與給定的文本描述對齊。此外,STRM與MCAM的結合進一步提高了IS和RI,使最后的結果超越了MirrorGAN。這些結果表明,提出的改進的多維度的注意力協同模塊MCAM和語義文本再生模塊STRM是非常有效的。
4 結束語
提出了改進的多維度的注意力協同模塊MCAM和語義文本再生模塊STRM,以解決具有挑戰性的T2I生成問題。MCAM具有從粗到細生成目標圖像的級聯結構,利用本地單詞注意和全局句子注意逐步增強生成圖像的多樣性和語義一致性。STRM通過從生成的圖像中重新生成文本描述來進一步監督生成器,使該圖像在語義上與給定的文本描述對齊。通過對兩個公共基準數據集的深入實驗,證明了MirrorGAN++優于其他方法。
猜你喜歡
公民與法治(2022年5期)2022-07-29 00:47:28
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
燕山大學學報(2015年4期)2015-12-25 02:19:49
大連民族大學學報(2015年2期)2015-02-27 08:28:11
