客戶無線網絡投訴的預防措施研究
2021-01-12 03:55:02吳亞楠
無線互聯科技 2020年24期
吳亞楠
(中國移動通信集團四川有限公司,四川 成都 610097)
0 引言
隨著客戶服務意識的提高,客戶對網絡質量的要求也越來越嚴格。若投訴問題無法及時有效解決,會增加客戶產生重復投訴和升級投訴的風險,客戶滿意度也將受到嚴重影響。針對無線網絡類投訴問題,傳統的處理和修復存在以下缺陷:
(1)故障網元定位難:由于無線傳播特性,在某點位存在多個小區同時覆蓋的情況,無法及時定位故障網元。
(2)投訴排查范圍大:同一投訴地點,不同客戶描述的故障現象不同,故障時間不同,時間跨度大,投訴分析時無法有效縮小排查范圍。
(3)指標映射不精準:常見的KPI/KQI感知分析,基于經驗值確定質差門限去判斷客戶感知影響,與實際感知影響不匹配。
(4)投訴修復滯后性:傳統修復手段是“先著火,后救火”,從“著火”到“成功滅火”耗費時長與客戶感知修復的痊愈度息息相關。
(5)網絡感知敏感差異性:不同年齡、ARPU值、使用習慣的客戶群體對網絡感知下滑的敏感度不一樣。
(6)場景和社會動態差異:傳統投訴分析思路是由點及面,無法根據社會動態、特定場景的特定需求預測未來趨勢。
1 體系設計
在傳統投訴分析時,各項指標無法與客戶感知關聯分析。在此背景下,結合客戶歷史投訴點位聯合周邊小區進行虛擬小區的KPI/KQI進行相關性計算,從前期大量投訴中發現與KPI/KQI各種組合的相關規律,再將規律應用到原始投訴和后續投訴作為驗證,在驗證結果準確度較高的情況下,將客戶感知、投訴和現網的KPI/KQI建立聯系。結合客戶特性標簽、社會實時動態,對感知劣化的潛在投訴區域發布預警,高風險場景/區域前移處理,同時識別風險區的潛在投訴客戶群,提前安撫,將傳統投訴處理“救火式”前置為“防火式”。
針對傳統投訴處理和修復存在的問題:(1)建立小區集解決故障網元定位難的問題;(2)自適應KPI/KQI容忍值和權值界定解決監控指標不確定性及客戶反映的故障現象及時間參差不一的難題;(3)基于客戶特性標簽、地理環境、社會實時動態的多元數據分析,彌補特定場景投訴無法預警及敏感客戶前置安撫的缺陷。
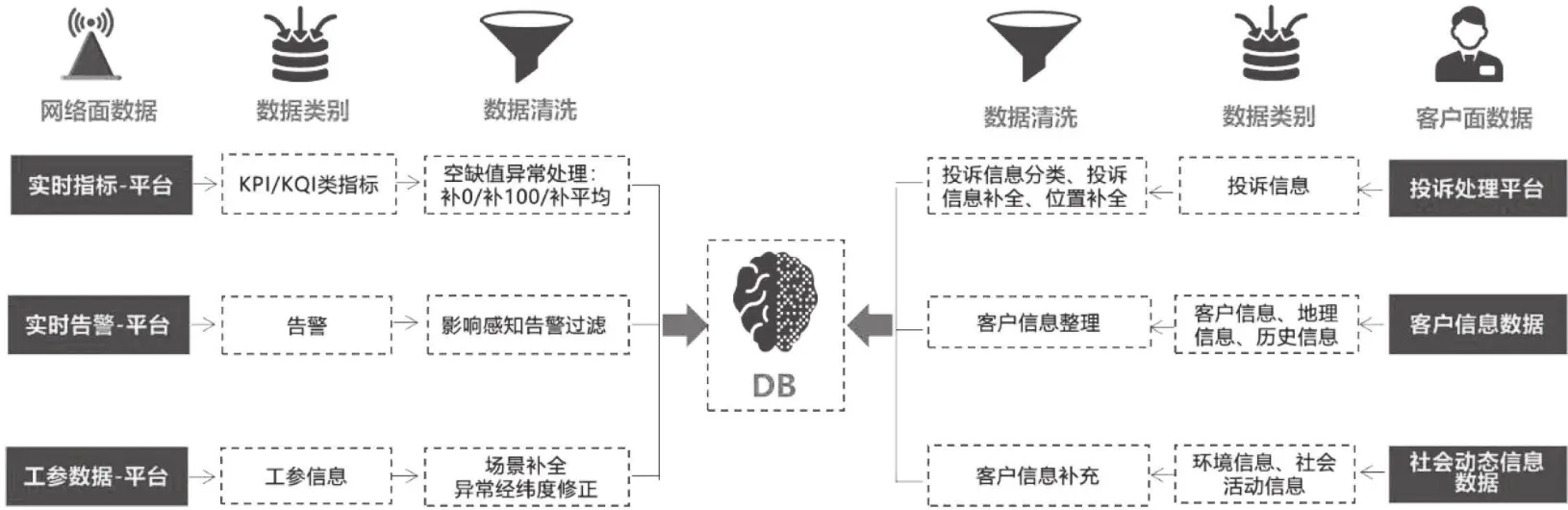
圖1 投訴數據匯聚處理示意
2 實現過程
2.1 數據收集及數據預處理
數據收集主要涉及網絡面和客戶面兩部分,網絡面包括:實時指標、實時告警、工參信息等,客戶面包括:投訴信息、客戶信息、社會動態環境信息等。需對采集的網絡面數據和客戶面數據進行檢查、清洗和規整,剔除異常信息,使數據在合理范圍以內[1]。
2.2 小區集的建立
常規分析投訴關聯小區的方式有兩種:一是關聯周邊區域小區:根據不同場景設定半徑R,關聯半徑R內的N個基站;二是關聯常駐小區:根據投訴客戶的常駐小區,找到駐留時長TOP N的小區。這兩種方式均有一定的局限性,通常情況下,一個單點的網絡異常,就會導致客戶投訴,而不是該區域或常駐小區的覆蓋區域存在問題。因此采用區域小區關聯和常駐小區關聯都可能會對投訴問題挖掘精度造成誤判。針對該問題,可以在沒有定位數據或投訴客戶小區數據下引入虛擬小區概念,將投訴點位最近N個基站的最差指標集合作為一個虛擬集,用作該投訴問題分析關聯的虛擬小區。
2.3 自適應KPI/KQI容忍值和權值界定
常見的KPI/KQI感知分析,是基于經驗值確定質差門限。如下行PRB利用率,根據業務類型不同,一般將大包、中包、小包門限定為70%,50%,40%,高于70%,50%,40%就認為感知異常。實際上,不同群體投訴時對應的KPI/KQI閾值可能存在差異,不同場景下客戶對相同KPI/KQI閾值的容忍度也存在差異。因此需建立一套更多維度的分析模型,參與建模的指標項集合不限定個數和類別,根據后續自適應算法,分為強相關指標、弱相關指標和無相關指標,以指標權值進行區分。
(1)自適應KPI/KQI容忍值界定。
針對每個指標輸出正態分布圖,尋找平穩區域及拐點。根據分布拐點對投訴點位的關鍵KPI/KQI指標進行等權重評分。
(2)KPI/KQI權值界定。
現網存在大量的KPI指標,若對指標無差異的全量分析,不僅工作量巨大費時費力,還可能定位不到導致投訴的關鍵問題。通過對投訴客戶和全網其他客戶的KPI差異分析,找到影響投訴的關鍵KPI集,再根據各項KPI/KQI與感知容忍的相關度界定權值。
均值門限界定法:分別設定每個指標權值為100%,其他指標權值為0,計算準確率60%時處理小區比例與潛在小區比例比值,得出單項KPI/KQI指標權重[3]。
個性門限界定法:對均值門限問題的收斂和精細化,以不同權重對多指標項進行分析,輸出帶不同指標權值的低分小區并評估低分小區與實際投訴點位的相關性。如某區域個性門限擬合,檢測地市在各項KPI/KQI上的權重發生差異,該區域在KPI指標上,小區下行PRB利用率和小區上行PRB利用率權重分別為18%和12%,表示該區域的高負荷問題與客戶投訴的相關度最高。通過KQI指標權重分析,該地點該時段投訴客戶對視頻始緩沖時延和Web頁面顯示成功率的容忍度較低。
2.4 模型擬合評估方法
為驗證問題收斂性,通過等權重評分方法,確定KPI/KQI不同分值段與投訴定位的匹配度。根據KPI/KQI指標門限,對所有小區指標打分,并進行等權值匯總,按照小區分值分段與投訴點位虛擬小區下邏輯小區進行匹配。對于KPI/KQI集合分數對應投訴匹配度,設定關鍵指標:
(1)已知小區投訴的投訴概率=該分段投訴數量/該分段虛擬小區內邏輯小區數量
(2)已知投訴點位數量占比=該分段投訴點位數量/整體投訴數量
(3)潛在投訴擴散比(潛藏率)=該分段非虛擬小區的邏輯小區數/該分段內差小區總數
以某地市3月為例:
通過KPI指標體系:可處理26%的投訴點位,潛在小區占比30.54%;即1 982個投訴點位可通過處理755個差小區關聯517個投訴點位,且另外找出226個潛在投訴點位。
通過KQI指標體系:可處理45.21%的投訴點位,潛在小區占比12%。
2.5 基于客戶特性標簽、地理場景、環境信息、社會活動多元分析
使用kmeans++算法聚合最差小區集,調用投訴處理平臺GIS頁面,輸出潛在投訴風險區。針對不同場景,制定歷史投訴量、邏輯小區數、業務量等閾值,并持續觀察投訴風險區。從該區域的潛在投訴擴散比在時間維度上的變化,分級輸出持續風險、加強風險區、衰退風險區、閉環風險區等4個風險區級別,可根據不同級別的風險采取相應策略。
鎖定虛擬小區集中worst小區下的常駐客戶,遍歷客戶的套餐信息、歷史投訴、年齡、ARPU值、業務使用習慣、終端類型等特性標簽,通過特征對比和重疊特征選取,經決策樹(Decision Tree)判斷[2],結合社會實時動態和場景信息(調用百度熱力圖、百度慧眼、新浪微博、騰訊位置大數據開放接口數據)等輸出投訴傾向客戶群體,并提前安撫關懷。
3 結語
通過基于KPI和KQI及網絡告警信息擬合客戶特征、場景、社會動態信息、歷史投訴等多維數據挖掘,預警潛在投訴風險區域,通過前置干預,實現投訴量的壓降和客戶滿意度的雙提升。
猜你喜歡
今日農業(2021年9期)2021-11-26 07:41:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
當代陜西(2019年15期)2019-09-02 01:52:00
學苑創造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
