基于Hadoop的高校學生行為預警決策系統研究
2021-01-15 08:21:40葛蘇慧白成杰
計算機應用與軟件 2021年1期
關鍵詞:學生
葛蘇慧 萬 泉 白成杰
1(青島工學院信息工程學院 山東 青島 266300) 2(山東師范大學信息科學與工程學院 山東 濟南 250358)
0 引 言
大數據帶來的信息風暴正在改變著人們的日常生活、工作模式和思維方式,但目前很多高校教育管理手段存在諸多弊端,管理方式大多停留在宣傳教育、定期檢查階段,管理模式多數是事后分析,管理手段既落后又被動,很難適應大數據時代智慧校園智能管控的要求。學業危機、安全危機、心理危機、就業危機、輿情危機等成為高校學生管理亟須解決的問題。因此,大數據背景下,要求高校管理者轉變思維,運用大數據分析技術,開展多維、動態、全面、智能的教育管理新模式,建立動態的預警決策機制,主動掌握學生生活、學習、行為規律,對不良思想行為做到事先警示教育、事后跟蹤管理,從而實現個性化的管理新模式,探索實效性的管理新路徑。
本文主要利用Hadoop大數據框架及HDFS、Map-Reduce、Spark、Kafka、Flume大數據技術研發智慧校園預警決策系統,使用Kafka、Flume進行日志采集,HDFS為海量學生校內軌跡數據提供存儲,MapReduce提供并行運算,從而提供動態的學生校內行為軌跡地圖和查詢功能。利用基于距離的聚類方法,對經過降維后的學生特征數據進行分類,分離出偏離中心點的狀態異常的學生;使用Echart、D3.js可視化呈現,采用SaaS形式交付,生成“學生畫像”對學生行為進行監控、預警、根源分析的閉環管理,并通過網頁版和手機版html5技術以微信、短信的方式主動推送預警,實現異常事件的閉環管理,為智慧校園的學生行為管理提供智能的手段,實現一種全新的智能管控新思路。
1 Hadoop大數據技術
Hadoop是一個開源的海量數據處理框架,最核心的設計是HDFS和MapReduce,HDFS為海量數據提供存儲和管理功能,處理非結構化的數據,MapReduce自動實現分布式并行計算,二者的巧妙結合使Hadoop擁有了高效的存儲和計算能力[1]。Hadoop可利用集群實現對海量數據的高效專業化處理,是一個對大規模數據存儲、計算、分析、挖掘的軟件平臺,具有低成本、高效率等優點,能可靠地存儲和處理PB級的數據[2-3]。
本文利用Hadoop框架的分布式文件系統HDFS和MapReduce對智慧校園多維學生軌跡數據進行數據清洗、建模、計算、分析與可視化呈現,HDFS負責學生多維校內行為軌跡的存儲和管理[4],MapReduce負責對大規模數據集的并行處理。Hadoop能將一臺機器的計算能力無限次、高速地復制到集群機上,使集群具有超強的計算能力,不斷擴充處理速度與運算能力[5-7]。
2 預警決策系統整體結構
基于Hadoop的高校學生行為預警決策系統分為權限管理、安全認證、技術支撐四層模型、預警決策可視化呈現[8-9]四大部分。其中技術支撐四層模型分為數據采集層、運行數據層、核心能力層、場景應用層。數據采集層對學生的歷史數據、點擊流、實時日志等數據市場的數據進行采集;運行數據層利用Hadoop集群、云存儲、云數據庫等對多維數據進行計算;核心能力層是對計算之后的數據進行清洗、建模、分析,實現即時查詢;場景應用層對數據進行可視化呈現[10-11]。權限管理分用戶管理、角色管理、用戶組管理、文件管理。安全認證可以分為iPaas、Ldap和Kerberos三類。預警決策系統可實現校園足跡、行為軌跡實時監測、預警反饋、預警信息主動推送,并利用Echart、D3.js可視化呈現,采用SaaS形式交付。該預警決策系統整體結構如圖1所示。

圖1 預警決策系統整體結構圖
2.1 數據采集清洗
通過高校智慧校園中的校園信息化基礎設施以及物聯網、智能感知、云計算等技術,利用Kafka、Flume大數據采集工具,收集學生的靜態和動態特征屬性,靜態屬性包括姓名、性別、專業、年級、宿舍、年齡、籍貫、愛好等特征;動態屬性包括課堂考勤信息、線上線下學習情況、圖書館借閱情況、宿舍回歸率、門禁系統、校園一卡通、餐廳就餐情況、校內上網情況、洗澡頻率等數據。通過大數據采集工具實現海量學生校內軌跡數據的抓取與存儲,將多維的學生活動狀態數據進行集成分類存儲,生成學生在校畫像屬性值。把軌跡數據的屬性值進行分類,將當前時刻數據屬性值的樣本,合并上一個周期采集到的并且已經處理完畢的數據屬性值的樣本進行清洗,采用曼哈頓函數計算目標區域為半徑之外的數據距離本域中心點的偏離距離。然后計算某個屬性的異常度,通過排序設定一定的閾值,將所有離群點的偏離程度進行比對,判斷該點與本域中心點之間的偏離距離,計算每個屬性值的異常情況[12-15]。步驟如下:
依據n個數據的屬性值,設每個屬性值的數據為m維,S(t0)為這次數據屬性值的樣本,不同時刻tk(tk∈[T,t0])采集到的數據屬性值的樣本為S(tk),因為校內軌跡數據的時序性,需要把當前時刻屬性值的樣本用式(1)合并上一周期已處理完的“干凈”數據進行清洗。
(1)
式中:Sc(t-1)表示t-1時刻清洗完畢的軌跡數據;r(Sc(t-1))表示對t-1時刻數據采集的結果;S+(t0)表示當前時刻與上一周期合并之后待處理的數據集,為了防止較高密度簇影響異常數據的分離需要將冗余刪除。
設s為軌跡數據屬性值集合S+(t0)中的點,區域半徑RAD(s)表示分析目標距離中心點為第k遠的對象的曼哈頓長度:
d(i,j)=∑|Xik-Xjk|
(2)
式中:Xik和Xjk表示第k遠對象的坐標值。
把點s作為本域的中心,該區域包含k個對象,這些對象的集合為Nk(s)。由此可以得出結論,分布不均勻的、密度較大的區域RAD(s)較小,反之密度較小的區域RAD(s)則較大。
定義點s與點p之間的距離:
REA(s,p)=max{RAD(Pp),d(s,p)}
(3)
利用式(3)可以求出軌跡數據集合S+(t0)內的第i個屬性值的異常度LOF(si),對其排序,然后設置最大的閾值,從而分離出偏離中心點的異常數據。
(4)
式中:Lnr(p)和Lnr(s)分別為點p和點s的閾值長度。
(5)
式中:Lrdk(s)為Nk(p)軌跡數據集合中平均可達距離密度的倒數。
由式(3)、式(4)、式(5)可知,如果點s偏離中心點的距離較小,那么對于同一屬性的軌跡數據的可達距離RAD(s)則較大,并且分布較為均勻;反之如果點s是偏離中心距離較遠的異常點,那么可達密度的方差就較大,證明該點距離所有簇都相對較遠,通過設置閾值計算偏離中心點的異常數據。
2.2 聚類分析
利用Hadoop框架的HDFS、MapReduce技術,采用分布式文件系統和并行計算,將學生的靜態和動態特征屬性貼上標簽,生成協方差特征矩陣的特征值及特征向量,使用主成分分析法進行降維處理,提取關鍵特征值,利用基于距離的方法進行聚類分析,將多維數據進行歸一化處理。把嚴重偏離中心點的學生特征異常信息提取出來,從而分離出學生的異常狀態,對異常行為作出科學的預測和研判。
主成分分析法利用降維的思想,使用線性變換的方法,將給定的一組相關變量轉換成另一組不相關的變量,轉換之后的新的變量按照方差依次遞減的順序排列,在數學變換中保持變量的總方差不變[16-18]。利用主成分分析法,首先計算學生樣本屬性的協方差矩陣,再求出協方差矩陣的特征向量,根據這些特征向量生成變換矩陣的行向量,最后依據數據協方差矩陣的特征向量構成新的坐標系的基矢量。根據學生不同屬性向量的特征可以得到如下結論。樣本集在較大特征值對應的特征向量上的投影方差較大,所以該分量對于區分樣本的貢獻就較大[19-20]。由此可見,通過主成分分析法可以清晰地找出區分性大的維和區分性不大的維。主成分分析法的具體實現步驟如下:
(1) 將n個學生,每個學生的m個特性屬性數據,構成n行m列的在校畫像矩陣S:
(6)
如果用j來表示學生畫像的某一項屬性,那么所有學生的這一項屬性xj可表示為:
(7)

(8)
(3) 將學生畫像屬性矩陣S進行計算,得出協方差矩陣R:
(9)
為了使統計分析的結果達到更好的處理效果,需要對學生特征屬性的多維數據進行歸一化處理,把經過數據清洗、處理之后的特征矩陣代替原來的矩陣S,式(10)可以計算特征矩陣S的有關系數。
(10)
(4) 特征值表示為λ,協方差矩陣R的特征值λi=(λi1,λi2,…,λim),特征向量ɑi=(ɑi1,ɑi2,…,ɑim),貢獻率w由式(11)計算,特征值λi的貢獻率為w。
(11)
(5) 從標準化處理之后的學生的特征屬性數據中選擇主成分,按照貢獻率w將學生的特征屬性值由高到低降序排列,根據統計的實際需要提取屬性的前若干行,從而形成降維后的學生特征矩陣S。
(6) 采用KHM(K-HarmonicMeans)算法對特征矩陣S進行聚類分析,如圖2所示,該算法根據式(12)最終計算出每個學生的特征屬性數據到各聚類中心的調和平均值的和。

圖2 學業成績分析
(12)
式中:第i個學生的m個特征表示為Si={Si1,Si2,…,Sim},第l個聚類中心表示為Cl=[Cl1,Cl2,…,Clm],第i個學生到中心點l的距離為d(Si,Cl)。利用初始值通過公式不斷迭代,最終使得各類趨于穩定,從而分離出狀態異常的學生[21]。
2.3 預警決策
最終該預警決策系統使用Echart、D3.js可視化輸出,采用SaaS形式交付,生成學生在校畫像,并提供學生校內行為軌跡和查詢功能。學校管理人員可以實時感知學生生活、學習及活動狀態,從而動態監測學生異常,對于可能會發生的異常問題或已經出現危機前兆的問題,通過網頁版和手機版html5技術以微信、短信的方式主動推送預警,實現學生異常事件的閉環管理,對異常事件真正做到可查、可管、可追溯。
3 算例分析
實驗在真實環境下進行,采用基于Hadoop框架搭建的HDFS、MapReduce技術,HDFS提供存儲和管理,MapReduce實現分布式計算。集群相關配置情況如表1所示。

表1 集群配置參數
3.1 軌跡數據分析
為驗證Hadoop架構和MapReduce算法的性能,實驗樣本集為某高校數據采集系統10個月的學生校內軌跡數據,學生軌跡數據每天采集量為120個點,將原數據集橫向表示為10個不同大小的樣本集[22]。前 5 個軌跡數據樣本的差異性較小,在處理少量文件時Hadoop無法體現它的優勢,但當樣本集數據量日志增大時,Hadoop便能對大規模的學生軌跡數據集進行分布式并行處理,清洗速度與清洗量近似正相關[23]。算例中采集了學生10個月的校內軌跡數據,最大樣本集中有5萬個監測點,100萬條數據,數據清洗時間大約為10 s,其速度和處理能力完全滿足目前乃至今后一段時間內的校內軌跡數據采集量的要求。
圖3所示是某天15 870個軌跡數據采集點的日清洗情況,其中折線為平均斜率,表示平均變化趨勢。因為校內軌跡數據采集所需的時間與學生異常數據的規模無關,且Hadoop能夠處理大規模的非結構化數據,并將原數據分類進行差異化處理、添加時間戳,所以數據的質量不會影響軌跡數據的清洗效率。為驗證算法的高效性,在樣本數據的24個時間段中隨機生成大規模異常數據。通過實驗驗證得出,Hadoop具有強大的快速處理能力,10萬條數據的清洗時間大約是5 636~6 340 ms,而且不同規模的異常數據量的清洗時間變化較為穩定。
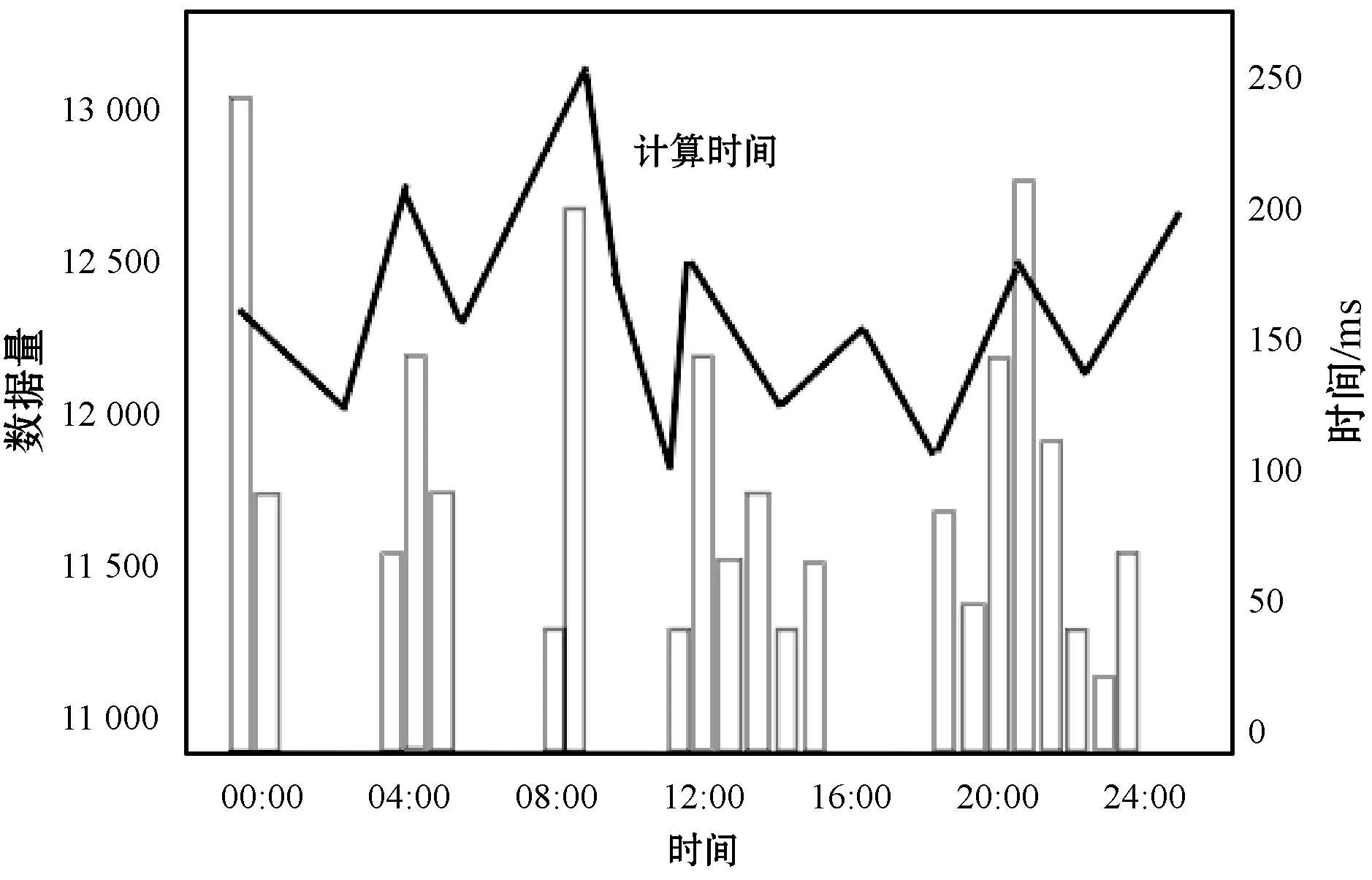
圖3 軌跡數據日清洗狀況
通過此預警決策系統對全校30多個專業,10 000多名學生進行了校內活動軌跡數據的采集、清洗、處理和聚類分析,讀取歷史數據,形成時間節點的數據集合,并合并上一次采集周期的數據進行清洗,設置目標區域半徑。通過曼哈頓長度計算異常數據距離中心點的離群程度,利用主成分分析法進行降維處理,生成學生靜態和動態屬性的特征矩陣,使用基于距離的方法進行聚類分析,并通過此預警決策系統最終可視化呈現,將嚴重偏離中心點的學生異常提取出來。圖4為學生校內軌跡數據聚類圖,通過采集10個月期間的大規模學生校內軌跡數據,進行清洗以及聚類分析,然后將此預警決策系統測試的結果與學生的實際狀態進行比對,得出的結論如表2所示。可以看出此預警決策系統分析的結果與這些學生在校內的實際狀態基本一致,數據預測成功率接近95%,誤差率可以控制在6.5%之內。

圖4 校內軌跡數據聚類圖

表2 系統預警與實際狀態結果比對
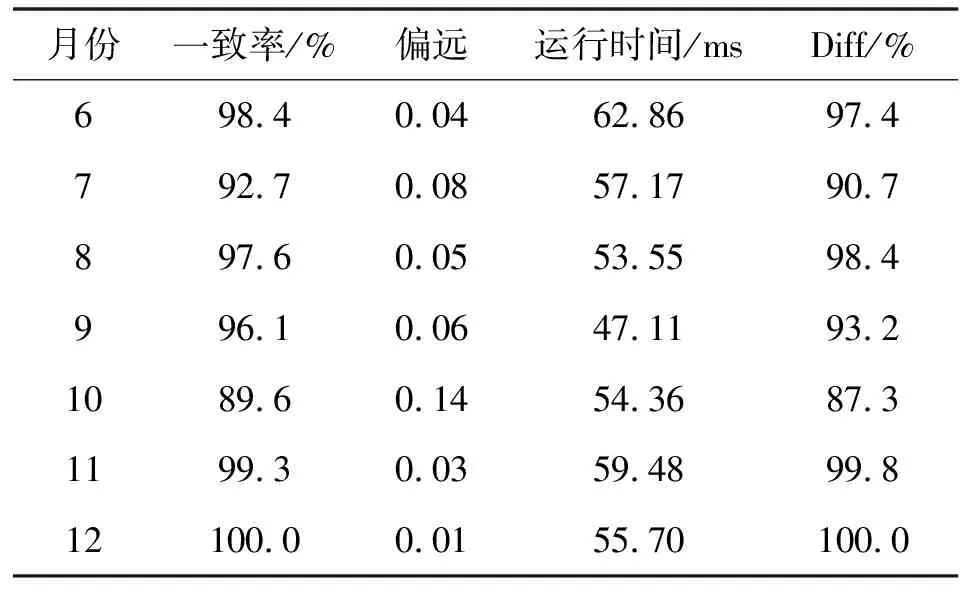
續表2
3.2 學生畫像規則
學生畫像標簽分為內容和權重。標簽是可變的,權重也是實時變化的,隨時間延長而衰減。以學生成績記錄為例:張三,數學成績90,為學生打上某一學科成績的標簽。通過編寫學生畫像規則,來計算標簽權重,基本權重=90/100=0.9。時間衰減因子為R,隨著時間D(天數)的延長,R會線性減少,R=1-0.05×D。標簽權重=基本權重×衰減因子。 由此計算出張三的數學成績標簽權重為0.9,標簽內容為科目名稱“數學”,因此該學生的一個標簽為:數學,0.9。一周之后如果衰減因子變為0.7,標簽權重變為0.63,那么該生的標簽為:數學,0.63。當標簽權重不斷減小到某個值,如0.5時,就要為該生“撕下”數學的標簽,從而更好地體現標簽的實時性,因此將0.5記為閾值。再使用Hive規則生成學生標簽,存入標簽庫,表3為學生畫像表(User_Profile)。

表3 學生畫像表
HiveQL標簽生成語句:
insert into table User_Profile select g. School_ID ,g.Student_ID,g.Student_Name,001,“數學”,0.9,2016-12-01 from Grade g where Subject=“數學”。
不是異常學生的概率為:
P(A2|B1)=1-P(A2|B1)=1-0.15=0.85
(13)
如果所具有的一項信息不是B1,而是B2、B3、B4,則是否是異常的概率分別為:
P(A1|B2)=0.13P(A2|B2)=0.87P(A1|B3)=0.11P(A2|B3)=0.89P(A1|B4)=0.16P(A2|B4)=0.84
(14)
再計算同時有2、3、4項特征的學生是異常狀態的概率,如表4所示。例如,同時有B1、B2兩項與B1、B2、B3三項的學生是異常的概率分別為:
P(A1|B1B2)=
(15)
P(A1|B1B2B3)=
(16)

表4 具有各種異常特征的概率
4 結 語
本文提出了基于Hadoop的智慧校園預警決策系統。通過智慧校園中各種智能終端、可感知設備,動態獲取學生海量活動軌跡與狀態數據,利用Hadoop大數據技術對多維數據進行關聯、分類、降維及聚類分析,生成“學生畫像”,實時監測學生狀態,科學研判異常行為,實現對異常事件監控、預警、根源分析的閉環管理,預警信息主動推送,開創智慧校園管理決策的新途徑。該系統為高校智慧校園學生管理的決策科學化、監督過程化提供智能參考的依據,開創高校教育管理的新模式。同時該系統可在其他高校中逐步推廣,讓高校的智慧校園建設邁上一個嶄新的臺階,對高校的教學管理和人才培養具有重要的實際應用價值。
猜你喜歡
作文大王·笑話大王(2021年4期)2021-04-26 19:00:35
英語文摘(2020年9期)2020-11-26 08:10:12
甘肅教育(2020年6期)2020-09-11 07:45:16
甘肅教育(2020年22期)2020-04-13 08:10:54
甘肅教育(2020年20期)2020-04-13 08:04:42
當代陜西(2019年5期)2019-11-17 04:27:32
電影(2018年9期)2018-11-14 06:57:21
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
