結(jié)合RGB-D視頻和卷積神經(jīng)網(wǎng)絡(luò)的行為識(shí)別算法*
2021-01-19 11:01:52李元祥謝林柏
計(jì)算機(jī)與數(shù)字工程 2020年12期
關(guān)鍵詞:融合
李元祥 謝林柏
(江南大學(xué)物聯(lián)網(wǎng)工程學(xué)院物聯(lián)網(wǎng)應(yīng)用技術(shù)教育部工程中心 無錫 214122)
1 引言
近年來,人體行為識(shí)別被廣泛應(yīng)用于人機(jī)交互、視頻檢索和視頻監(jiān)控等日常生活場(chǎng)景中,利用人體行為識(shí)別算法可以有效自動(dòng)地提取視頻數(shù)據(jù)中高層語義,從而大大降低人力成本。目前,基于傳統(tǒng)RGB相機(jī)的人體行為識(shí)別算法對(duì)環(huán)境要求較為苛刻,如光照、對(duì)象遮擋等因素。隨著3D體感傳感器的推出,如微軟的Kinect,許多研究者開始利用Kinect提供的多源信息,如深度圖序列、骨骼位置信息,降低環(huán)境因素對(duì)行為識(shí)別算法的影響,提高算法的魯棒性。
目前,傳統(tǒng)的行為識(shí)別算法主要集中對(duì)RGB視頻序列的處理,包括分類器或特征提取算法的設(shè)計(jì),如Laptev等[1]提出使用哈里斯角點(diǎn)檢測(cè)器在時(shí)空3D空間檢測(cè)興趣點(diǎn),取得了一定的識(shí)別效果。隨著低成本Kinect深度傳感器的推出,許多研究者開始嘗試?yán)蒙疃葦?shù)據(jù)或骨骼位置數(shù)據(jù)解決人體行為識(shí)別遇到的挑戰(zhàn),Bulbul[2]等通過DMM計(jì)算輪廓梯度方向直方圖特征(CT-HOG)、局部二值模式特征(LBP)和邊緣方向直方圖特征(EOH),并利用分類器KELM進(jìn)行分類識(shí)別,一定程度上降低光照變化和物體遮擋等不利環(huán)境因素的影響。
隨著卷積神經(jīng)網(wǎng)絡(luò)在圖像領(lǐng)域取得了巨大的成功,受此鼓舞,研究者將卷積神經(jīng)網(wǎng)絡(luò)應(yīng)用到行為識(shí)別領(lǐng)域并取得了顯著的效果。Tomas[3]等利用二維卷積神經(jīng)網(wǎng)絡(luò)和堆疊編碼器(SAE)分別學(xué)習(xí)RGB視頻序列和骨骼位置信息序列的高層語義,其中RGB視頻序列被預(yù)處理為運(yùn)動(dòng)歷史圖像序列(MHI)以提取其長(zhǎng)時(shí)域運(yùn)動(dòng)信息。宋立飛[4]等在經(jīng)典雙流網(wǎng)絡(luò)結(jié)構(gòu)上,利用2D殘差網(wǎng)絡(luò)和多尺度輸入3D卷積融合網(wǎng)絡(luò)提取視頻的時(shí)空維度信息,并決策融合兩路神經(jīng)網(wǎng)絡(luò)的預(yù)測(cè)分?jǐn)?shù)。
行為識(shí)別與靜態(tài)圖像識(shí)別最主要的區(qū)別是視頻序列包含行為的時(shí)域信息,因此人體行為識(shí)別難點(diǎn)之一就是如何從復(fù)雜場(chǎng)景的視頻序列中,有效提取動(dòng)作行為的時(shí)域信息。Hochreiter[5]等在傳統(tǒng)遞歸神經(jīng)網(wǎng)絡(luò)(RNN)進(jìn)行改進(jìn),提出了長(zhǎng)短期記憶遞歸神經(jīng)網(wǎng)絡(luò)(LSTM),能夠有效提取視頻序列的時(shí)域特征。Imran[6]等利用RGB視頻序列與深度圖序列分別計(jì)算MHI和DMM,并輸入到多路獨(dú)立的卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練,最后分別比較了均值法和乘積法這兩種決策融合策略的識(shí)別效果。
本文主要貢獻(xiàn)為以下三個(gè)方面:
1)為了提取RGB視頻序列中靜態(tài)表觀與短時(shí)域運(yùn)動(dòng)信息,以及深度圖序列中長(zhǎng)時(shí)域運(yùn)動(dòng)信息,提出了一種結(jié)合RGB-D視頻序列和卷積神經(jīng)網(wǎng)絡(luò)的人體行為識(shí)別算法。
2)在深度圖序列中,通過引入表示能量大小的權(quán)值變量,對(duì)不同深度圖進(jìn)行加權(quán),從而保留視頻序列中更多的細(xì)節(jié)信息。
3)為了有效融合多路卷積神經(jīng)網(wǎng)絡(luò)的預(yù)測(cè)分?jǐn)?shù),基于常用的決策融合方法,提出一種改進(jìn)的加權(quán)乘積融合策略,實(shí)現(xiàn)端到端的行為識(shí)別算法。
2 數(shù)據(jù)預(yù)處理
卷積神經(jīng)網(wǎng)絡(luò)在靜態(tài)圖像識(shí)別任務(wù)中,表現(xiàn)出遠(yuǎn)超人工設(shè)計(jì)的特征提取算法識(shí)別效果,但在行為識(shí)別任務(wù)中一直較難取得顯著的效果,其中一個(gè)主要原因就是用于訓(xùn)練神經(jīng)網(wǎng)絡(luò)的行為數(shù)據(jù)集偏小,使得網(wǎng)絡(luò)模型參數(shù)很難達(dá)到最優(yōu),且在訓(xùn)練過程中網(wǎng)絡(luò)模型易出現(xiàn)過擬合。為了解決該問題,首先,使用預(yù)訓(xùn)練網(wǎng)絡(luò)模型初始化神經(jīng)網(wǎng)絡(luò)參數(shù)。其次,針對(duì)于深度圖序列,除了采用常規(guī)的尺度變換和裁剪翻轉(zhuǎn)等手段,同時(shí)利用仿射變換[7]模擬數(shù)據(jù)集在相機(jī)視角變化的情況,從而進(jìn)一步擴(kuò)大數(shù)據(jù)樣本量。為了保留視頻的更多細(xì)節(jié)信息,在將深度圖序列壓縮到一幀DMM圖像時(shí),引入表示能量大小的權(quán)值變量,同時(shí)將改進(jìn)的深度運(yùn)動(dòng)圖進(jìn)行彩虹編碼[8]處理。
2.1 相機(jī)視角擴(kuò)增
為了擴(kuò)大數(shù)據(jù)樣本量,可以利用仿射變換得到不同相機(jī)視角下的深度圖像,如圖1所示。假設(shè)Kinect相機(jī)從P O位置移到P d位置,此過程可以分為以下兩步:首先,從位置P O繞y軸旋轉(zhuǎn)θ角度到位置Pt,然后再由位置Pt繞x軸旋轉(zhuǎn)β角度到P d。
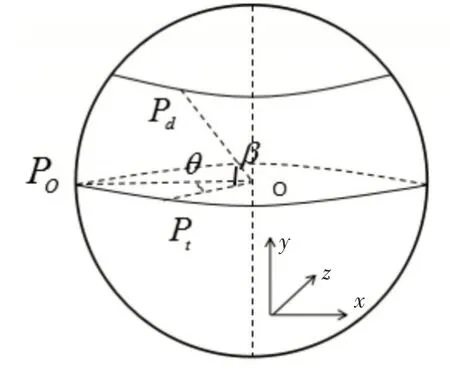
圖1 相機(jī)視角變化
設(shè)點(diǎn)(X,Y,Z)為P O的位置坐標(biāo),則P d位置坐標(biāo)(X1,Y1,Z1)可以由下式得到:
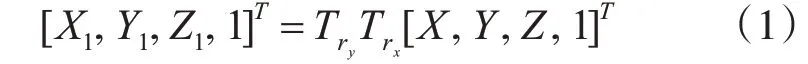
其中T r y和T r x分別表示位置P O到位置P t、位置Pt到P d的的變換矩陣,可表示為
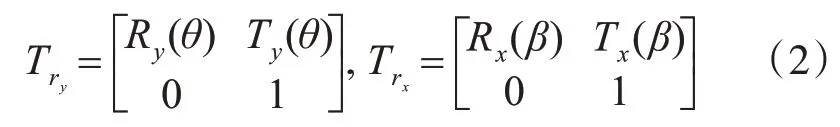
其中R y(θ),R x(β),T y(θ),T x(β)為
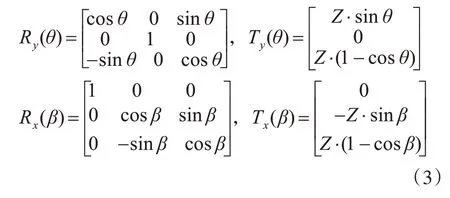
2.2 速度擴(kuò)增
為了模擬出同一個(gè)動(dòng)作序列下不同實(shí)驗(yàn)者執(zhí)行效果,需要對(duì)給定的動(dòng)作序列以不同采樣間隔進(jìn)行下采樣,其計(jì)算公式如下:
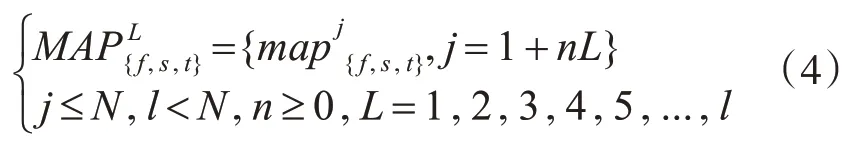
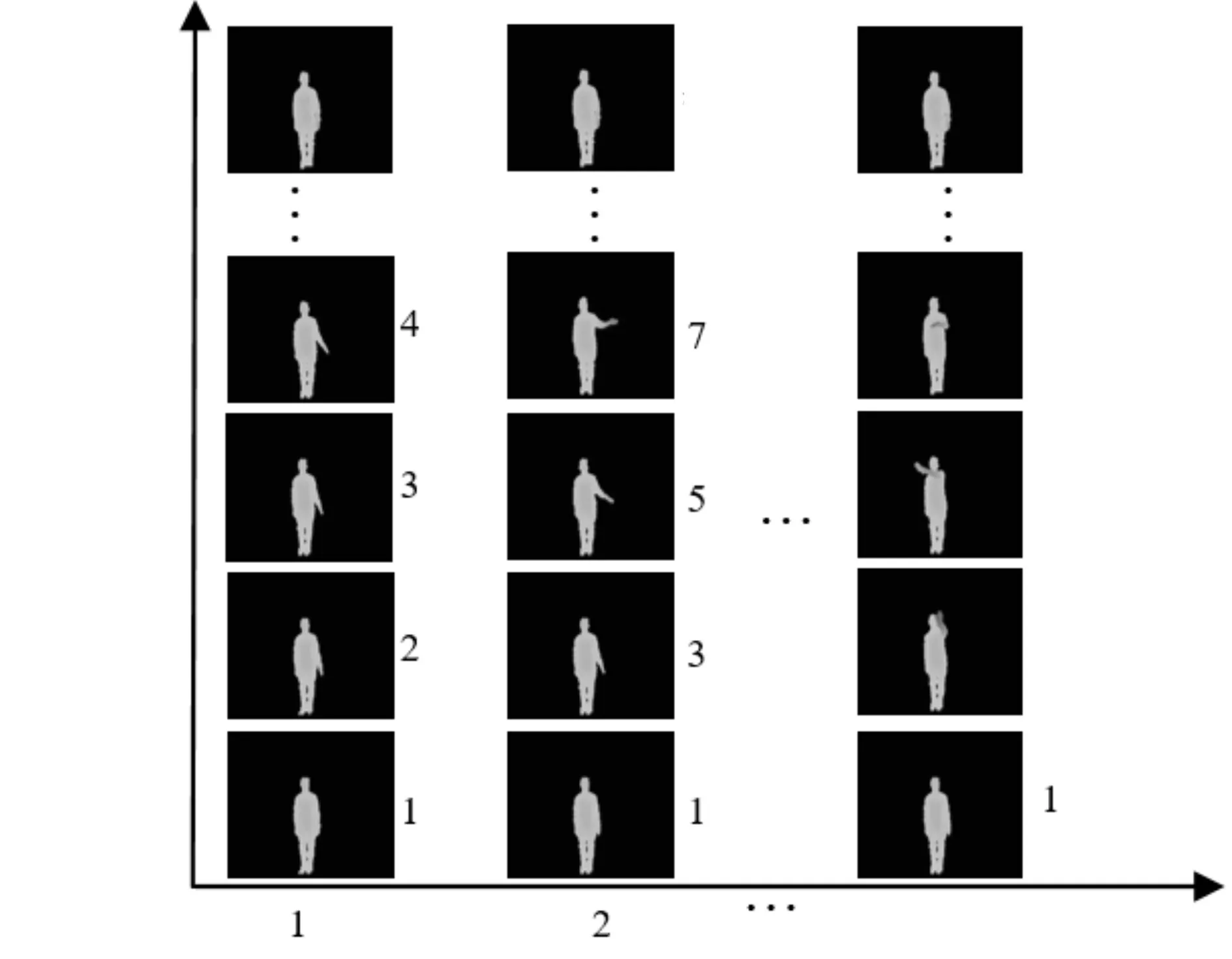
圖2 下采樣示意圖
2.3 改進(jìn)的深度運(yùn)動(dòng)圖
近年來,卷積神經(jīng)網(wǎng)絡(luò)在圖像分類、目標(biāo)檢測(cè)和人臉識(shí)別等計(jì)算機(jī)視覺領(lǐng)域都表現(xiàn)出卓越的性能。本文利用二維卷積神經(jīng)網(wǎng)絡(luò)善于處理靜態(tài)圖片分類與識(shí)別的特點(diǎn),嘗試將深度圖視頻序列分別投影到三個(gè)正交平面(正平面、側(cè)平面和頂平面)上,然后在每個(gè)投影平面上將深度圖序列處理為一幀深度運(yùn)動(dòng)圖像。
為了克服動(dòng)作速度和幅度對(duì)動(dòng)作識(shí)別的影響,在將深度圖序列壓縮到一幀DMM時(shí),引入表示能量大小的權(quán)值變量來保留深度圖序列更多的細(xì)節(jié)信息。在速度擴(kuò)增中,不同的采樣間隔能夠得到對(duì)應(yīng)不同時(shí)間尺度的采樣序列。表示在采樣間隔為l的下采樣序列中,累計(jì)計(jì)算到第i幀的深度運(yùn)動(dòng)圖,其中ε(i)v∈{f,s,t}表示第i幀的能量,表示第i幀深度圖投影到正平面、側(cè)平面和頂平面得到的投影圖像。
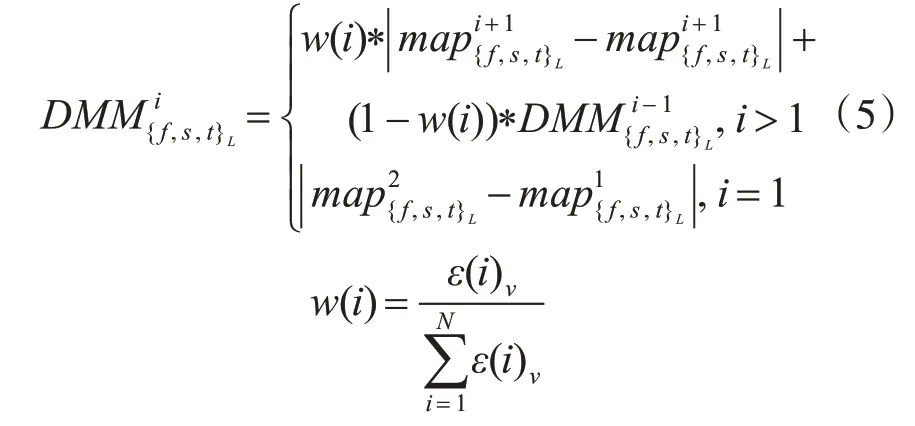
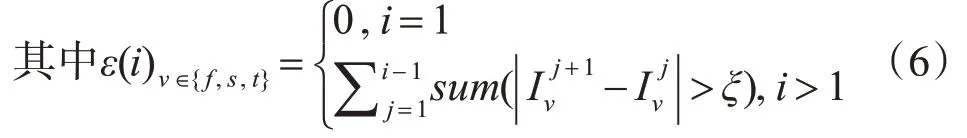
其中ξ為設(shè)定的閾值,sum(.)為計(jì)算二值圖中非零的個(gè)數(shù)。

圖3 “right hand draw circle(counter clockwise)”動(dòng)作在不同模擬速度下DMM圖像
3 多路卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)
為了提取RGB視頻序列中靜態(tài)表觀、短時(shí)域運(yùn)動(dòng)信息和深度圖序列中長(zhǎng)時(shí)域運(yùn)動(dòng)信息,本文提出了一種結(jié)合ResNet(2+1)D[9]和GoogLeNet InceptionV2(BN-Inception)[10]的多路端到端卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)。四路網(wǎng)絡(luò)結(jié)構(gòu)相互獨(dú)立訓(xùn)練,其中三路BN-Inception網(wǎng)絡(luò)參數(shù)共享,分別用于訓(xùn)練DM M f,DM M s,D MM t數(shù)據(jù)。為了避免直接融合神經(jīng)網(wǎng)絡(luò)高層特征帶來的特征維度高、計(jì)算復(fù)雜等問題,采用后期分?jǐn)?shù)融合方式計(jì)算最終行為視頻序列的預(yù)測(cè)分?jǐn)?shù)。
3.1 ResNet(2+1)D網(wǎng)絡(luò)層
對(duì)于給定一段RGB視頻序列V,在提取視頻序列短時(shí)域運(yùn)動(dòng)信息時(shí),首先將動(dòng)作視頻可重疊地分割為K個(gè)子序列片段{ }T1,T2,...,T k,利 用ResNet(2+1)D對(duì)其訓(xùn)練,最后對(duì)K個(gè)子序列片段聚合得到視頻級(jí)的預(yù)測(cè)分?jǐn)?shù),其過程描述如下:

其中R(T1,T2,...,T k)V表示視頻序列V最終的預(yù)測(cè)分?jǐn)?shù),(T1,T2,...,T k)代表子序列片段,f(T k,W)函數(shù)表示基于模型參數(shù)W的ResNet(2+1)D網(wǎng)絡(luò)在子序列片段Ti輸入下得到的類別得分,g函數(shù)為采用均值法的聚合函數(shù),以融合T1,T2,...,T k子序列片段的類別分?jǐn)?shù)。
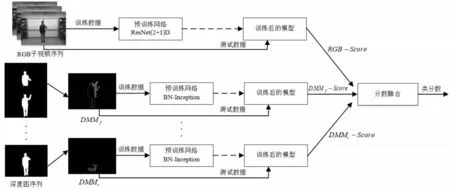
圖4 多路卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)
ResNet(2+1)D網(wǎng)絡(luò)是在3D ResNet[11]網(wǎng)絡(luò)結(jié)構(gòu)基礎(chǔ)上,將3D卷積分解為2D空間卷積和1D時(shí)間卷積。在與3D ResNet網(wǎng)絡(luò)保持相同參數(shù)量下,通過在2D空間卷積與1D時(shí)間卷積之間引入非線性激活函數(shù)ReLu,同時(shí)分別優(yōu)化2D空間卷積和1D時(shí)間卷積,使得ResNet(2+1)D的訓(xùn)練錯(cuò)誤率比3D ResNet更低。本文采用連續(xù)32幀圖像作為片段T i,并基于R(2+1)D結(jié)構(gòu)的ResNet-34網(wǎng)絡(luò)下訓(xùn)練子序列片段。
3.2 BN-Inception網(wǎng)絡(luò)層
對(duì)于一段給定的深度圖視頻序列,首先分別投影到正平面、側(cè)平面和頂平面,并根據(jù)不同的采樣間隔l,得到對(duì)應(yīng)的下采樣序列和。然后分別計(jì)算得到多個(gè)深度運(yùn)動(dòng)圖作為三路BN-Inception網(wǎng)絡(luò)的訓(xùn)練集。
GoogLeNet Inception V1[12]是Google在2014年提出一種22層網(wǎng)絡(luò)的深度學(xué)習(xí)架構(gòu),通過對(duì)卷積神經(jīng)網(wǎng)絡(luò)的傳統(tǒng)卷積層進(jìn)行修改,提出了Inception結(jié)構(gòu)用于增加網(wǎng)絡(luò)模型的深度和寬度,并在減小網(wǎng)絡(luò)參數(shù)數(shù)量的同時(shí)提高了神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)能力。BN-Inception是在Inception V1基礎(chǔ)上進(jìn)行了改進(jìn),一方面使用兩個(gè)3×3卷積代替Inception結(jié)構(gòu)的5×5卷積,另一方面增加了Batch Normalization層,進(jìn)一步降低網(wǎng)絡(luò)的參數(shù)數(shù)量,同時(shí)提高了網(wǎng)絡(luò)訓(xùn)練速度。
3.3 多分類器融合
對(duì)于多個(gè)獨(dú)立分類器融合(Multiple Classifier Fusion MCF)[13],常分為有監(jiān)督分?jǐn)?shù)融合[14]和無監(jiān)督分?jǐn)?shù)融合。其中有監(jiān)督分?jǐn)?shù)融合是將每個(gè)分類器的輸出作為另一個(gè)分類器的輸入再次進(jìn)行訓(xùn)練,為了設(shè)計(jì)一個(gè)端到端的行為識(shí)別算法,本文基于無監(jiān)督分?jǐn)?shù)融合方式設(shè)計(jì)多分類器融合算法。
設(shè)V為卷積神經(jīng)網(wǎng)絡(luò)的輸入(子序列片段或深度運(yùn)動(dòng)圖),{ }1,2,...,c為設(shè)定數(shù)據(jù)集的類別標(biāo)簽,M為獨(dú)立分類器的數(shù)量,Pi,j(V)表示在第i個(gè)分類器下類別標(biāo)簽為j的預(yù)測(cè)分?jǐn)?shù),則決策矩陣可表示為

目前常用的多分類器無監(jiān)督分?jǐn)?shù)融合有加權(quán)求和融合(weight sum rule)、乘積法(product rule)和投票法(majority voting)。
1)加權(quán)求和融合
對(duì)于一個(gè)測(cè)試深度圖序列V,首先利用求和法得到三路BN-Inception網(wǎng)絡(luò)的融合分?jǐn)?shù)B NV,然后使用不同的權(quán)值融合ResNet(2+1)D網(wǎng)絡(luò)和BN-Inception網(wǎng)絡(luò)的預(yù)測(cè)分?jǐn)?shù),得到視頻序列V在多路卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)下的預(yù)測(cè)分?jǐn)?shù)scoreV:
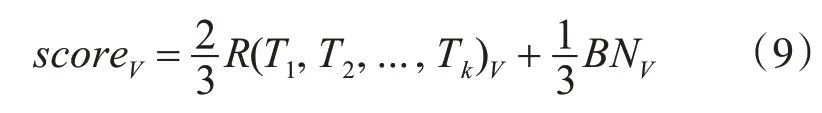
2)乘積法
設(shè)類別標(biāo)簽j在M個(gè)分類器下得到的預(yù)測(cè)分?jǐn)?shù)矩陣DV(V)如下:
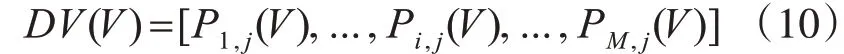
根據(jù)product rule,類別標(biāo)簽j的融合預(yù)測(cè)分?jǐn)?shù)如下:
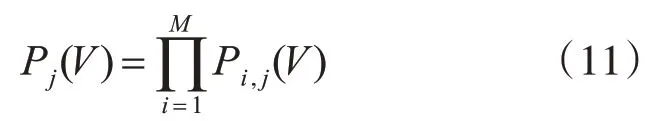
3)投票法
對(duì)于視頻序列V,傳統(tǒng)投票法是分別統(tǒng)計(jì)各個(gè)分類器給出的類別標(biāo)簽,最后選擇類別標(biāo)簽重復(fù)次數(shù)最多的標(biāo)簽作為最終的分類結(jié)果,如果存在多個(gè)相同重復(fù)次數(shù)的標(biāo)簽,則會(huì)在相同次數(shù)標(biāo)簽中隨機(jī)選擇一個(gè)標(biāo)簽作為最終的分類結(jié)果。
基于多分類器融合方法中的均值法和乘積法,提出一種改進(jìn)的加權(quán)乘積融合法(weight product rule)。對(duì)于任意一個(gè)測(cè)試深度圖序列V,利用均值法求得三路BN-Inception網(wǎng)絡(luò)下類別標(biāo)簽為j的預(yù)測(cè)分?jǐn)?shù):
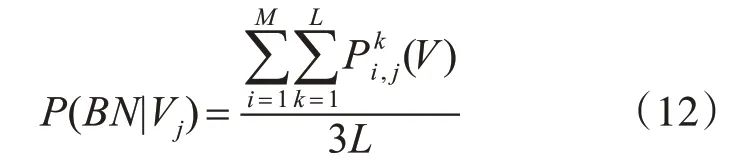
其中M=3表示三路BN-Inception網(wǎng)絡(luò)對(duì)應(yīng)的softmax分類器,L表示時(shí)間尺度,(V)表示在第i路BN-Inception網(wǎng)絡(luò)對(duì)應(yīng)的softmax分類器下,時(shí)間尺度為k且類別標(biāo)簽為j的預(yù)測(cè)分?jǐn)?shù),P(BN|V j)表示在三路BN-Inception網(wǎng)絡(luò)下,類別標(biāo)簽為j的均值融合分?jǐn)?shù)。
在多路卷積神經(jīng)網(wǎng)絡(luò)下,類別標(biāo)簽為j的乘積融合分?jǐn)?shù)如下:
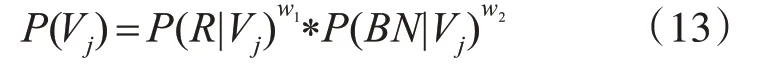
其中P(R|V j)由式(7)計(jì)算得到的類別標(biāo)簽為j的分 數(shù),w1,w2為 對(duì) 應(yīng) 的ResNet(2+1)D網(wǎng) 絡(luò) 和BN-Inception網(wǎng)絡(luò)的權(quán)值,最后測(cè)試視頻序列V的類別標(biāo)簽判定如下式所示:
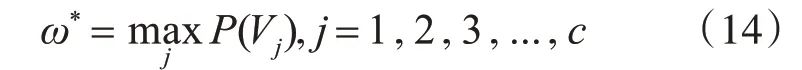
其中ω*表示最終識(shí)別的類別標(biāo)簽,c為設(shè)定的類別標(biāo)簽。
4 實(shí)驗(yàn)結(jié)果與分析
4.1 參數(shù)設(shè)置
在數(shù)據(jù)預(yù)處理中,時(shí)間尺度L設(shè)為5,即采樣間隔l取值分別為1,2,3,4,5。在三路BN-Inception網(wǎng)絡(luò)中,網(wǎng)絡(luò)模型采用基于動(dòng)量值為0.9的批處理隨機(jī)梯度下降法和誤差反向傳播進(jìn)行模型參數(shù)更新,網(wǎng)絡(luò)訓(xùn)練參數(shù)設(shè)置如文獻(xiàn)[15],同時(shí)使用在ImageNet[16]的預(yù)訓(xùn)練模型,批次次數(shù)設(shè)置為64,學(xué)習(xí)率設(shè)置為0.001,訓(xùn)練的最大迭代次數(shù)設(shè)置為20000次,其中每5000次迭代學(xué)習(xí)率下降0.1倍。在ResNet(2+1)D網(wǎng)絡(luò)中,網(wǎng)絡(luò)訓(xùn)練參數(shù)設(shè)置如文獻(xiàn)[9]。利用caffe2實(shí)現(xiàn)ResNet(2+1)D網(wǎng)絡(luò)結(jié)構(gòu),同時(shí)使用基于Kinetics[17]的預(yù)訓(xùn)練模型,批次次數(shù)設(shè)置為4,學(xué)習(xí)率設(shè)置為0.0002,訓(xùn)練的最大迭代次數(shù)設(shè)置為40000次,其中每10000次迭代學(xué)習(xí)率下降0.1倍。在改進(jìn)的加權(quán)乘積融合法中,權(quán)值w1=w2=1 2。
4.2基于UTD-MHAD數(shù)據(jù)庫的行為識(shí)別
UTD-MHAD是由Chen[18]等利用Kinect和可穿戴式傳感器制作的RGB-D公開行為數(shù)據(jù)集,該數(shù)據(jù)集中存在一些相似動(dòng)作,如“順時(shí)針畫圓”,“逆時(shí)針畫圓”,因此在該數(shù)據(jù)集進(jìn)行行為識(shí)別仍有一定的難度。
在上文相機(jī)視角擴(kuò)增中,θ,β分別從[-30°,30°]區(qū)間中等間隔取5個(gè)離散值,速度擴(kuò)增中,時(shí)間尺度L設(shè)為5,同時(shí)在UTD-MHAD數(shù)據(jù)集中,選擇序號(hào)為奇數(shù)的數(shù)據(jù)作為訓(xùn)練集,其余作為測(cè)試集。最后,對(duì)所有類別動(dòng)作的分?jǐn)?shù)使用算術(shù)平均法計(jì)算最終的識(shí)別率。
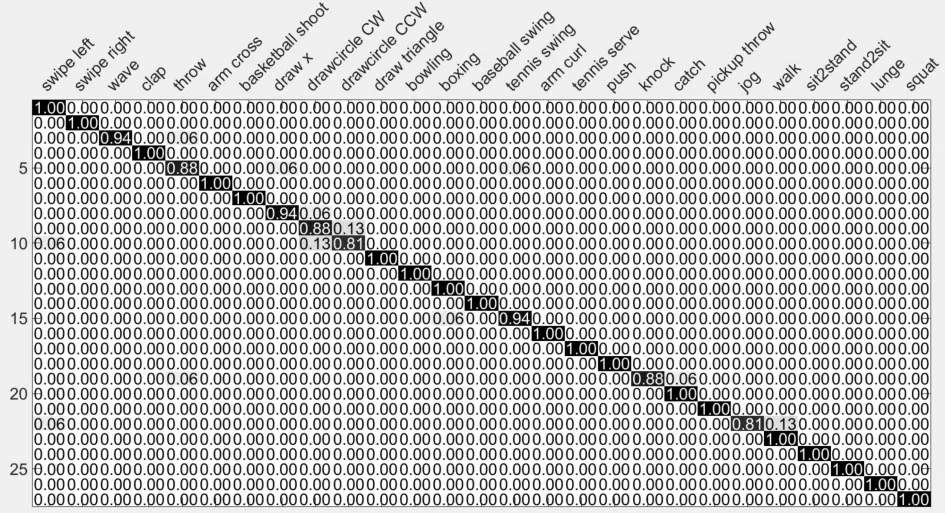
圖5 混淆矩陣:平均識(shí)別率為96.49%
圖5 為本文算法在UTD-MHAD數(shù)據(jù)集上得到的混淆矩陣,可以看出:本文算法在很多動(dòng)作上都取得了優(yōu)異效果,但對(duì)于一些相似動(dòng)作依然存在誤識(shí)別。表1對(duì)比了不同輸入流以及不同融合策略的識(shí)別效果。可以看出,在不同輸入流下,D MM f對(duì)應(yīng)的Softmax分類效果優(yōu)于DM M s和DMMt對(duì)應(yīng)的Softmax,主要由于將深度圖視頻序列分別投影到側(cè)平面和頂平面計(jì)算得到的深度運(yùn)動(dòng)圖,會(huì)損失部分動(dòng)作時(shí)域信息;在不同融合策略下,結(jié)合各個(gè)分類器分?jǐn)?shù)的加權(quán)求和融合法、乘積法和本文提出改進(jìn)的加權(quán)乘積融合法,優(yōu)于基于分類器標(biāo)簽的投票法。同時(shí)改進(jìn)的加權(quán)乘積融合法相對(duì)乘積法提高了0.63%,主要原因是乘積法要求各個(gè)分類器都具有較好的分類效果,才能得到較高的識(shí)別率,但從表1可以看出DMM s和DMMt對(duì)應(yīng)的Softmax分類效果遠(yuǎn)低于DMMf對(duì)應(yīng)的Softmax。表2將本文算法與近幾年的其他優(yōu)秀方法進(jìn)行了比較,相比文獻(xiàn)[2]、[6]和[20]分別提高了8.09%、5.29%和3.23%,主要由于R(2+1)D網(wǎng)絡(luò)結(jié)構(gòu)能有效提取RGB視頻序列短時(shí)域運(yùn)動(dòng)信息,同時(shí)在計(jì)算DMM時(shí)引入能量權(quán)重,并且采用改進(jìn)的加權(quán)乘積融合多分類器的結(jié)果。
4.3 基于MSR Daily Activity 3D數(shù)據(jù)庫的人體行為識(shí)別
MSR Daily Activity 3D[21]數(shù)據(jù)庫是采用Kinect深度傳感器錄制的人體行為公共數(shù)據(jù)庫,該數(shù)據(jù)庫包含骨骼關(guān)節(jié)位置、深度信息和RGB視頻三種數(shù)據(jù)。在本實(shí)驗(yàn)中我們僅使用了該數(shù)據(jù)庫中的深度信息和RGB視頻序列,同時(shí)采用和UTD-MHAD數(shù)據(jù)集相同的數(shù)據(jù)擴(kuò)增方式和實(shí)驗(yàn)參數(shù)。
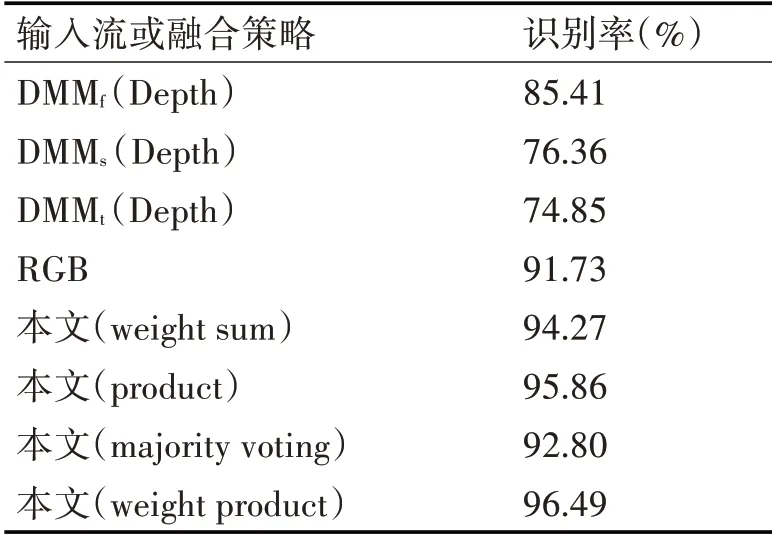
表1 UTD-MHAD數(shù)據(jù)庫,不同輸入流或融合策略的識(shí)別率比較

表2 在UTD-MHAD數(shù)據(jù)庫上,現(xiàn)有方法與本文方法的識(shí)別率比較
在該數(shù)據(jù)庫上的混淆矩陣如圖6所示。可以看出在一些相似動(dòng)作依然存在誤識(shí)別,如“看書”與“寫字”。表3比較了不同輸入流及不同融合策略的識(shí)別效果,其中改進(jìn)的加權(quán)乘積融合法相對(duì)乘積法提高了1.36%,主要原因是DM M s和D MM t對(duì)應(yīng)的Softmax分類效果遠(yuǎn)低于D MM f對(duì)應(yīng)的Softmax,因此對(duì)三路BN-Inception網(wǎng)絡(luò)的輸出分?jǐn)?shù)采用均值融合要優(yōu)于乘積法融合策略。表4將本文算法與近幾年的其他優(yōu)秀方法進(jìn)行了比較,相比文獻(xiàn)[23]和[3]分別提高了6.87%和2.45%,相對(duì)于UTD-MHAD數(shù)據(jù)庫,MSR Daily Activity 3D數(shù)據(jù)庫背景更為復(fù)雜,同時(shí)很多動(dòng)作存在與物體交互的情況,因此識(shí)別率提升相對(duì)較低。
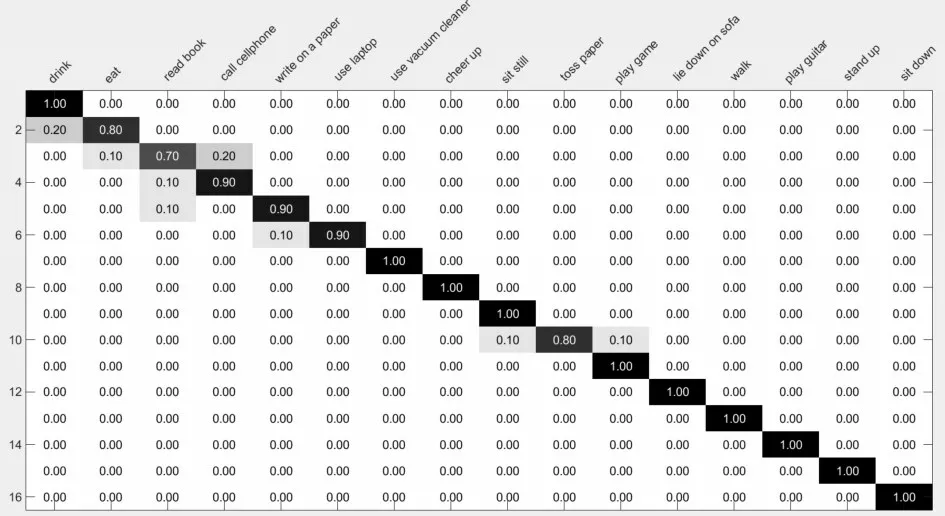
圖6 混淆矩陣:平均識(shí)別率為93.75%

表3 MSR Daily Activity 3D數(shù)據(jù)庫,不同輸入流或融合策略的識(shí)別率比較
5 結(jié)語
為了提取行為動(dòng)作的靜態(tài)表觀和時(shí)域運(yùn)動(dòng)信息,同時(shí)解決行為特征在融合時(shí)存在計(jì)算量較大,融合后特征維度高等問題,提出了結(jié)合RGB-D視頻序列和卷積神經(jīng)網(wǎng)絡(luò),并實(shí)現(xiàn)端到端的行為識(shí)別算法。首先利用ResNet(2+1)D網(wǎng)絡(luò)提取RGB視頻的靜態(tài)表觀和短時(shí)域運(yùn)動(dòng)信息,三路獨(dú)立BN-Inception網(wǎng)絡(luò)提取深度圖序列的長(zhǎng)時(shí)域運(yùn)動(dòng)信息,最后利用改進(jìn)的加權(quán)乘積法融合上述四路網(wǎng)絡(luò)的輸出分?jǐn)?shù),得到最終行為動(dòng)作的類分?jǐn)?shù)。在兩個(gè)公開數(shù)據(jù)集上實(shí)驗(yàn)表明,我們的算法對(duì)相似動(dòng)作具有一定的判別性,但如何在樣本背景復(fù)雜、動(dòng)作交互的情況下,有效提取行為動(dòng)作的長(zhǎng)時(shí)域運(yùn)動(dòng)信息,這將是我們下一步的工作方向。
猜你喜歡
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
數(shù)學(xué)年刊A輯(中文版)(2022年4期)2022-02-16 08:17:34
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
無線電通信技術(shù)(2021年4期)2021-07-13 08:58:28
無線電通信技術(shù)(2021年3期)2021-06-08 03:33:48
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
福利中國(2015年4期)2015-01-03 08:03:38
