強(qiáng)化學(xué)習(xí)算法與應(yīng)用綜述①
2021-01-21 06:48:40李茹楊彭慧民李仁剛
計(jì)算機(jī)系統(tǒng)應(yīng)用 2020年12期
李茹楊,彭慧民,李仁剛,趙 坤
1(浪潮(北京)電子信息產(chǎn)業(yè)有限公司,北京 100085)
2(浪潮集團(tuán)有限公司 高效能服務(wù)器和存儲(chǔ)技術(shù)國(guó)家重點(diǎn)實(shí)驗(yàn)室,北京 100085)
3(廣東浪潮大數(shù)據(jù)研究有限公司,廣州 510632)
1 引言
近年來(lái),強(qiáng)化學(xué)習(xí)(Reinforcement Learning,RL)因其強(qiáng)大的探索能力和自主學(xué)習(xí)能力,已經(jīng)與監(jiān)督學(xué)習(xí)(supervised learning)、無(wú)監(jiān)督學(xué)習(xí)(unsupervised learning)并稱為三大機(jī)器學(xué)習(xí)技術(shù)[1].伴隨著深度學(xué)習(xí)的蓬勃發(fā)展,功能強(qiáng)大的深度強(qiáng)化學(xué)習(xí)算法層出不窮,已經(jīng)廣泛應(yīng)用于游戲?qū)筟2-4]、機(jī)器人控制[5,6]、城市交通[7-9]和商業(yè)活動(dòng)[10-12]等領(lǐng)域,并取得了令人矚目的成績(jī).AlphaGo[2]之父David Silver 曾指出,“深度學(xué)習(xí)+強(qiáng)化學(xué)習(xí)=通用人工智能(artificial general intelligence)”[13],后續(xù)大量的研究成果也表明,強(qiáng)化學(xué)習(xí)是實(shí)現(xiàn)通用人工智能的關(guān)鍵步驟.
1.1 馬爾可夫決策過(guò)程(MDP)
強(qiáng)化學(xué)習(xí)的核心是研究智能體(agent) 與環(huán)境(enironment)的相互作用,通過(guò)不斷學(xué)習(xí)最優(yōu)策略,作出序列決策并獲得最大回報(bào)[14].強(qiáng)化學(xué)習(xí)過(guò)程可以描述為如圖1所示的馬爾可夫決策過(guò)程(Markov Decision Process,MDP),其中參數(shù)空間可表示為一個(gè)五元組〈A,S,P,R,γ〉,包括動(dòng)作空間(action space)A,狀態(tài)空間(state space)S、狀態(tài)轉(zhuǎn)移P:S×S×A→[0,1]、回報(bào)(reward)R:S×A→R和折扣因子(discounted factor)γ ∈[0,1].在一些情況下,智能體無(wú)法觀測(cè)到全部的狀態(tài)空間,這類問(wèn)題被稱為部分觀測(cè)馬爾可夫決策過(guò)程(Partially Observed Markov Decision Process,POMDP),在多智能體強(qiáng)化學(xué)習(xí)(multi-agent RL)設(shè)置中尤其常見(jiàn)[15].
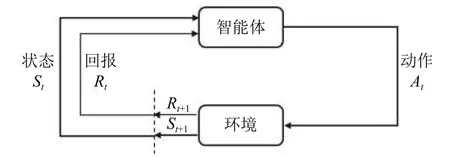
圖1 MDP 中智能體與環(huán)境的交互作用[14]
具體實(shí)施過(guò)程中,智能體在時(shí)刻t觀測(cè)到所處環(huán)境和自身當(dāng)前的狀態(tài)st∈S,根據(jù)策略(policy) π,采取一個(gè)動(dòng)作at∈A(S).下一個(gè)時(shí)刻t+1,環(huán)境根據(jù)智能體采取的行動(dòng)給予一個(gè)回報(bào)rt+1∈R?R,并進(jìn)入一個(gè)新的狀態(tài)st+1,智能體根據(jù)獲得的回報(bào)對(duì)策略進(jìn)行調(diào)整,并進(jìn)入下一個(gè)決策過(guò)程.MDP 過(guò)程中得到的序列為:
Herbertus giraldianus(Steph.)W.E.Nicholson.熊源新等(2006);楊志平(2006)
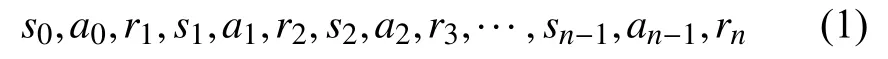
智能體通過(guò)不斷學(xué)習(xí),找到能夠帶來(lái)最大長(zhǎng)期累積回報(bào)的最優(yōu)策略π?.時(shí)刻t之后,帶有折扣因子γ ∈[0,1]的長(zhǎng)期累積回報(bào)如下:
血清同型半胱氨酸與神經(jīng)元特異性烯醇化酶聯(lián)合檢測(cè)對(duì)進(jìn)展性腦梗死的預(yù)測(cè)價(jià)值………………………………………………………………………… 代鳴明,等(8):938
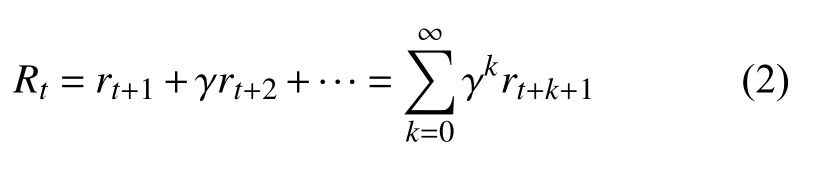
經(jīng)典的策略梯度算法REINFORCE[32]使用蒙特卡洛(MC)方法估計(jì)梯度策略,具有較好的穩(wěn)定性.但樣本效率較低,同時(shí)MC 方法包含整個(gè)軌跡上的信息,會(huì)帶來(lái)較大的策略梯度估計(jì)方差.通過(guò)引入少量噪聲的無(wú)偏估計(jì),例如在回報(bào)中減去基線的方式,能夠有效降低估計(jì)方差.Kakade 在2002年提出自然策略梯度(natural policy gradient)[44]來(lái)提升算法的穩(wěn)定性和收斂速度,由此引出了后續(xù)的置信域(trust region)方法,例如著名的置信域策略優(yōu)化算法TRPO (Trust Region Policy Optimization)[33]和近端策略優(yōu)化算法PPO(Proximal Policy Optimization)[34].TRPO 和PPO 均為同步策略(on-policy)算法,在經(jīng)典策略梯度算法的基礎(chǔ)上通過(guò)人為或自適應(yīng)的方式選擇超參數(shù),將更新步長(zhǎng)約束一定范圍內(nèi),以確保每一步回報(bào)單調(diào)不減,持續(xù)獲得更優(yōu)的策略,防止出現(xiàn)策略崩潰(Policy Collapse)的問(wèn)題.此外,Nachum 等在2017年提出了樣本效率更高的異步策略(off-policy)置信路徑一致性學(xué)習(xí)算法Trust_PCL (Trust Path Consistency Learning)[15],同年Heess 等將PPO 算法推廣到分布式策略梯度的Distributed PPO 算法[45].
1.2 價(jià)值函數(shù)
當(dāng)智能體學(xué)習(xí)到最優(yōu)策略 π?之后,MDP 在給定策略下退化成馬爾可夫回報(bào)過(guò)程(Markov Reward Process,MRP).由此,狀態(tài)價(jià)值(state value)函數(shù)Vπ(s)和動(dòng)作價(jià)值(action value)函數(shù)Qπ(s,a)分別表示為:
鄉(xiāng)村旅游顧名思義都是在鄉(xiāng)村,且森林資源比較富集的地方。漫山遍野的花草樹(shù)木能夠給城市人帶來(lái)好心情,同時(shí)也讓他們呼吸到新鮮的空氣,被贊譽(yù)為“洗肺”。但好些鄉(xiāng)村旅游的從業(yè)者,喜歡選擇靠山的地方修建房屋,大規(guī)模營(yíng)造避暑山莊、鄉(xiāng)村旅館,結(jié)果隨意砍伐樹(shù)木,導(dǎo)致翠綠的山野呈現(xiàn)光禿禿的境況,他們把鋼筋水泥延伸到森林中,如不加制止,破壞后果不堪設(shè)想。現(xiàn)在各地因鄉(xiāng)村旅游破壞森林資源的現(xiàn)象普遍存在,且存在一些屢禁不止的惡習(xí)。
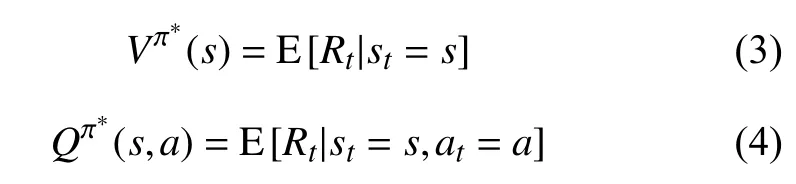
將上式轉(zhuǎn)換為貝爾曼最優(yōu)方程(Bellman optimality equations)形式即為:
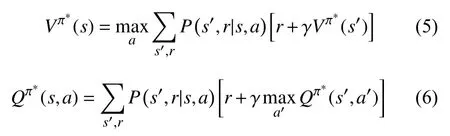
獲得狀態(tài)價(jià)值函數(shù)和動(dòng)作價(jià)值函數(shù)后,理論上可以通過(guò)策略迭代的方式獲得最優(yōu)策略,進(jìn)而求解價(jià)值函數(shù).但在具體的實(shí)踐過(guò)程中,策略迭代效率低、計(jì)算成本高,因此通常采用人工設(shè)計(jì)的線性函數(shù),或非線性函數(shù)(如神經(jīng)網(wǎng)絡(luò))來(lái)近似估計(jì)價(jià)值函數(shù)[16].
1.3 探索與利用
對(duì)照組:阿托伐他汀鈣膠囊,20 mg/d,1次/d,口服,連用8周。試驗(yàn)組:瑞舒伐他汀鈣片,10 mg/d,1次/d,口服。兩組患者均連續(xù)接受8周藥物治療,并在第4、8周時(shí)分別檢測(cè)血脂水平。
隨著網(wǎng)約車(chē)經(jīng)濟(jì)的發(fā)展,越來(lái)越多的人選擇網(wǎng)約車(chē)的方式出行.為提升服務(wù)效果,強(qiáng)化學(xué)習(xí)被大量應(yīng)用于網(wǎng)約車(chē)派單業(yè)務(wù)中.以滴滴出行AI Lab 為代表的企業(yè)研究院進(jìn)行了大量的研究工作和應(yīng)用實(shí)踐[9,94,95].其中,乘客與潛在司機(jī)之間的距離、道路擁堵程度和司機(jī)服務(wù)評(píng)分等多種因素作為環(huán)境狀態(tài),派單系統(tǒng)不斷優(yōu)化策略進(jìn)行派單,為乘客匹配最合適的司機(jī),最小化乘客等待時(shí)間,以及減少司機(jī)空車(chē)等待時(shí)間,獲得最大的收益.
1.4 本文章節(jié)設(shè)置
針對(duì)國(guó)內(nèi)外強(qiáng)化學(xué)習(xí)的研究歷程和發(fā)展現(xiàn)狀,本文第2 章和第3 章集中闡述經(jīng)典強(qiáng)化學(xué)習(xí)算法與前沿研究方向,第4 章介紹強(qiáng)化學(xué)習(xí)的應(yīng)用情況,第5 章給出結(jié)論與展望.
很多學(xué)術(shù)期刊微信公眾號(hào)更新頻率較低,也沒(méi)有形成統(tǒng)一規(guī)律。一般是在紙刊文章刊出后對(duì)文章進(jìn)行宣傳推送,或是在刊物有相關(guān)新聞報(bào)道時(shí)進(jìn)行推送,有些微信公眾號(hào)甚至長(zhǎng)期沒(méi)有更新,成了名存實(shí)亡的“僵尸號(hào)”。這種不定期更新的頻率無(wú)法吸引讀者,更無(wú)法保持固有用戶的黏度。
2 強(qiáng)化學(xué)習(xí)經(jīng)典算法
從Bellman 提出動(dòng)態(tài)規(guī)劃方法[19]到AlphaGo 打敗人類圍棋冠軍[2],強(qiáng)化學(xué)習(xí)經(jīng)歷60年的發(fā)展,成為機(jī)器學(xué)習(xí)領(lǐng)域最熱門(mén)的研究和應(yīng)用方向.2006年,深度學(xué)習(xí)[20]的提出,引領(lǐng)了機(jī)器學(xué)習(xí)的第二次浪潮,在學(xué)術(shù)界和企業(yè)界持續(xù)升溫,并成功促進(jìn)了2010年之后深度強(qiáng)化學(xué)習(xí)的蓬勃發(fā)展.
現(xiàn)在北京汽車(chē)維修企業(yè)基本都要求招收高職院校或6年制中職院校畢業(yè)生,在崗維修人員如不提高診斷技術(shù)就會(huì)長(zhǎng)期處于低技術(shù)水平從而導(dǎo)致被淘汰。以前汽車(chē)維修技術(shù)含量低,高級(jí)技師可以“挑大梁”,而今后則必須是精于診斷技術(shù)的技師才能“挑大梁”。我國(guó)政府號(hào)召“培育精益求精的工匠精神”,古代工匠魯班發(fā)明鋸,現(xiàn)代工匠工作精雕細(xì)刻。當(dāng)代汽修技工必須在診斷技術(shù)上不斷提高,弘揚(yáng)工匠精神,才能成就維修技術(shù)人員的精彩人生。
強(qiáng)化學(xué)習(xí)算法有眾多分類方式,如根據(jù)是否構(gòu)建模型可以分為無(wú)模型(model-free) 算法和基于模型(model-based)算法;依據(jù)執(zhí)行策略與評(píng)估策略是否一致,分為同步策略(on-policy) 算法和異步策略(offpolicy)算法;根據(jù)算法更新機(jī)制,分為回合更新的蒙特卡洛(Monte-Carlo,MC)算法和單步更新的時(shí)間差分(Temporal-Difference,TD)算法.其中,無(wú)模型(modelfree)算法、同步策略(on-policy)算法、時(shí)間差分算法(TD)算法,是各自分類下的主流方向,不同分類下的算法存在一定交叉.另外,依據(jù)智能體動(dòng)作選取方式,可將強(qiáng)化學(xué)習(xí)算法分為基于價(jià)值(value-based)、基于策略(policy-based),以及結(jié)合價(jià)值與策略(actor-critic)3 類,這也是目前最主流的分類方式[21].表1中給出3 類主流強(qiáng)化學(xué)習(xí)算法的對(duì)照,下文將對(duì)每一類算法展開(kāi)介紹.
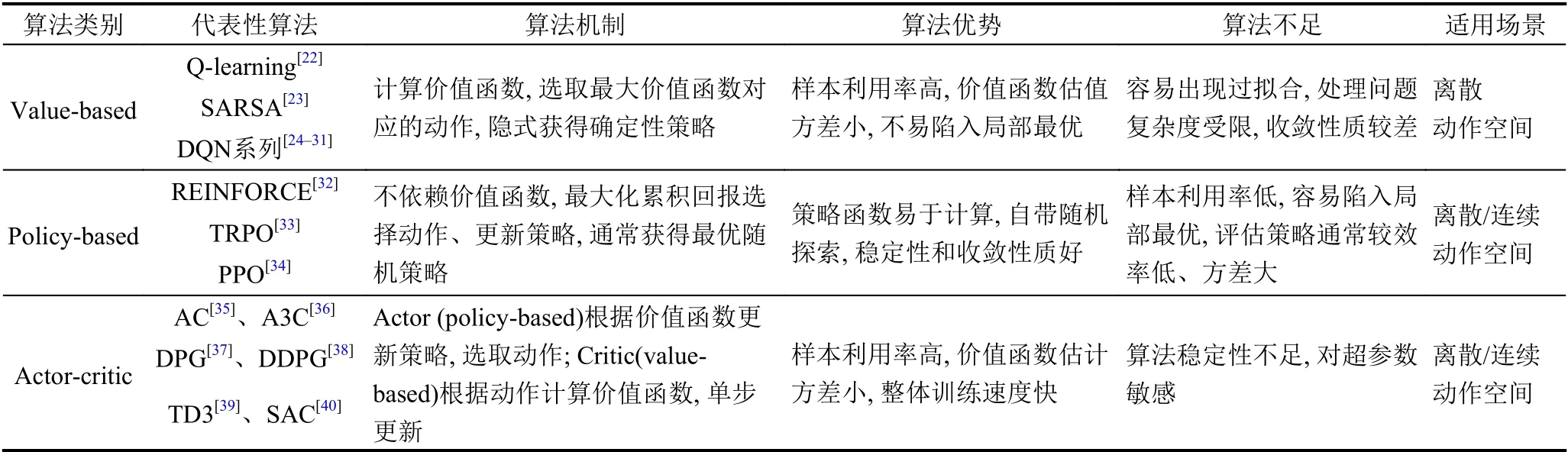
表1 3 類主流強(qiáng)化學(xué)習(xí)算法對(duì)照
2.1 基于價(jià)值(value-based)的強(qiáng)化學(xué)習(xí)算法
基于價(jià)值(value-based)的強(qiáng)化學(xué)習(xí)算法通過(guò)獲取最優(yōu)價(jià)值函數(shù),選取最大價(jià)值函數(shù)對(duì)應(yīng)的動(dòng)作,隱式地構(gòu)建最優(yōu)策略.代表性算法包括Q-learning[22]、SARSA[23],以及與深度學(xué)習(xí)相結(jié)合的Deep Q-Network (DQN)算法[24,25].此類方法多通過(guò)動(dòng)態(tài)規(guī)劃(dynamic programming)或值函數(shù)估計(jì)(value function approximation)的方法獲得最優(yōu)價(jià)值函數(shù),且為確保效率采用時(shí)間差分(TD)方法進(jìn)行單步或者多步更新,而不是蒙特卡洛(MC)回合更新方式.例如,異步策略(off-policy)的Q-learning算法使用非探索策略計(jì)算時(shí)間差分誤差(TD error),而同步策略(on-policy)的SARSA 算法使用探索策略計(jì)算時(shí)間差分誤差(TD error).Value-based 算法的樣本利用率高、價(jià)值函數(shù)估值方差小,不易陷入局部最優(yōu).但是,此類算法只能解決離散動(dòng)作空間問(wèn)題,容易出現(xiàn)過(guò)擬合,且可處理問(wèn)題的復(fù)雜度受限.同時(shí),由于動(dòng)作選取對(duì)價(jià)值函數(shù)的變化十分敏感,value-based 算法收斂性質(zhì)較差.
近年來(lái),發(fā)展出眾多改進(jìn)的actor-critic 算法,最具代表性的算法包括:確定性策略梯度算法DPG (Deterministic Policy Gradient)[37]及其深度改進(jìn)版本DDPG(Deep Deterministic Policy Gradient)[38]、異步優(yōu)勢(shì)actor-critic 算法A3C (Asynchronous Advantage Actor-Critic)[36]、雙延遲確定性策略梯度算法TD3 (Twin Delayed Deep Deterministic policy gradient)[39],以及松弛actor-critic 算法SAC (Soft Actor-Critic)[40]等.DPG算法[37]僅在狀態(tài)空間整合確定性策略梯度,極大降低了采樣需求,能夠處理較大動(dòng)作空間的問(wèn)題.DDPG 算法[38]繼承了DQN 的目標(biāo)網(wǎng)絡(luò),采用異步策略的Critic估計(jì)策略梯度,使訓(xùn)練更加穩(wěn)定簡(jiǎn)單.著名的A3C 算法[36]使用在線Critic 整合策略梯度,降低訓(xùn)練樣本的相關(guān)性,在保證穩(wěn)定性和無(wú)偏估計(jì)的前提下,提升了采樣效率和訓(xùn)練速度.TD3 算法[39]在DDPG 的基礎(chǔ)上,引入性能更好的Double DQN,取兩個(gè)Critic 之間的最小值來(lái)限制過(guò)擬合.與TD3 同期的SAC 算法[40]中,Actor在獲得最大回報(bào)之外,也具有最大熵,大大提升算法的探索能力.圖4中對(duì)比了幾種最先進(jìn)的policy-gradient算法在同一個(gè)強(qiáng)化學(xué)習(xí)基準(zhǔn)問(wèn)題上的表現(xiàn),整體對(duì)比效果約為SAC=TD3>DDPG=TRPO=DPG>VPG[50].其中,VPG 指經(jīng)典的策略梯度算法,如REINFORCE[32].
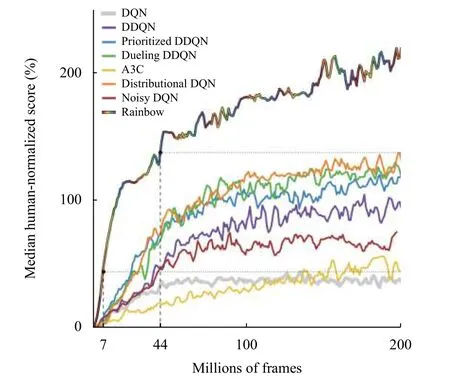
圖2 各類DQN 算法在Atari 游戲(57 種)中的表現(xiàn)[31]
需要指出的是,DQN 及其各變體算法(后文簡(jiǎn)稱DQN 算法)雖然在以電子游戲?yàn)榇淼碾x散動(dòng)作空間問(wèn)題上取得了優(yōu)異的表現(xiàn),甚至在一些游戲上以壓倒性優(yōu)勢(shì)戰(zhàn)勝人類玩家[25],但針對(duì)實(shí)際生產(chǎn)、生活中大量存在的連續(xù)動(dòng)作空間問(wèn)題,如機(jī)械手臂控制、車(chē)輛駕駛等,面向離散動(dòng)作空間的DQN 算法無(wú)法應(yīng)對(duì).同時(shí),相比SARSA 等同步策略算法,雖然異步策略的DQN 算法已經(jīng)具有較高的樣本效率,但正如圖2所示,即使DQN 系列中最先進(jìn)的Rainbow DQN 算法,在面對(duì)簡(jiǎn)單的Atari 游戲時(shí),仍然需要學(xué)習(xí)約1500 萬(wàn)幀圖像(樣本)、持續(xù)訓(xùn)練1 天時(shí)間才能達(dá)到人類玩家的水平[31],而人類只需幾個(gè)小時(shí)就能掌握同一游戲.因此,DQN 算法的采樣效率問(wèn)題仍然不可忽視.
2.2 基于策略(policy-based)的強(qiáng)化學(xué)習(xí)算法
盡管強(qiáng)化學(xué)習(xí)具有很好的研究和應(yīng)用前景,但從頭開(kāi)始訓(xùn)練算法時(shí),獲取樣本的代價(jià)過(guò)于高昂,嚴(yán)重阻礙強(qiáng)化學(xué)習(xí)研究與應(yīng)用的發(fā)展.“Learning to learn”的元學(xué)習(xí)(meta-learning)為快速、靈活的強(qiáng)化學(xué)習(xí)提供了可能[65].在元強(qiáng)化學(xué)習(xí)(meta RL)體系當(dāng)中,通過(guò)在大量先驗(yàn)任務(wù)(prior tasks)上訓(xùn)練出泛化能力強(qiáng)的智能體(agent)/元學(xué)習(xí)者(meta-learner),在面對(duì)新任務(wù)時(shí)只需少量樣本或訓(xùn)練步即可實(shí)現(xiàn)快速適應(yīng).
一系列的實(shí)踐經(jīng)驗(yàn)證明,大口井運(yùn)用一定時(shí)間后,會(huì)有不同程度的淤塞,從而出水量會(huì)大大降低。眾多水文地質(zhì)學(xué)家已經(jīng)通過(guò)大量的理論探討和工作時(shí)間證明:大口徑輻射井技術(shù)可以用于增加單井出水量。大口井輻射井是以傳統(tǒng)的大口井為基礎(chǔ),在井下部的井筒中增加了多個(gè)集水管,并將其整個(gè)徑向延伸到蓄水層中,使地下水流入集水管中并最終進(jìn)入取水井中。
考慮智能體所處環(huán)境的隨機(jī)性,以及回報(bào)獲取存在延遲,MDP 使用折扣因子反映越是深入未來(lái)的回報(bào),對(duì)當(dāng)前t時(shí)刻累積回報(bào)的貢獻(xiàn)越小[14].
TRPO 和PPO 算法因其良好的實(shí)驗(yàn)效果,被選為許多研究工作的基礎(chǔ)算法[46-49],PPO 更是成為了OpenAI的默認(rèn)算法[1].然而,盡管TRPO 和PPO 算法具有十分優(yōu)秀的超參數(shù)性能,在學(xué)術(shù)研究中獲得了廣泛關(guān)注,但是作為典型的同步策略算法,每次策略更新時(shí)都需要在當(dāng)前策略下采樣大量樣本進(jìn)行訓(xùn)練和確保算法收斂.因此,TRPO 和PPO 算法的局限性也非常明顯,算法采樣效率低,需要大量算力作為支撐,這些都極大限制了算法在應(yīng)用領(lǐng)域的推廣.
2.3 執(zhí)行者-評(píng)論者(actor-critic)強(qiáng)化學(xué)習(xí)算法
執(zhí)行者-評(píng)論者(actor-critic)算法將value-based(對(duì)應(yīng)評(píng)論者,critic)方法與policy-based (對(duì)應(yīng)執(zhí)行者,actor) 方法進(jìn)行結(jié)合,同時(shí)學(xué)習(xí)策略和價(jià)值函數(shù)[35].Actor 根據(jù)critic 反饋的價(jià)值函數(shù)訓(xùn)練策略,而critic 訓(xùn)練價(jià)值函數(shù),使用時(shí)間差分法(TD) 進(jìn)行單步更新.Actor-critic 算法的框架如圖3所示.通常情況下,actorcritic 被認(rèn)為是一類policy-based 方法,特殊之處在于使用價(jià)值作為策略梯度的基準(zhǔn),是policy-based 方法對(duì)估計(jì)方差的改進(jìn).Actor-critic 兼?zhèn)鋚olicy-based 方法和value-based 方法兩方面的優(yōu)勢(shì),值函數(shù)估計(jì)方差小、樣本利用率高,算法整體的訓(xùn)練速度快.與此同時(shí),actor-critic 方法也繼承了相應(yīng)缺點(diǎn),例如actor (policybased)對(duì)樣本的探索不足,critic (value-based)容易陷入過(guò)擬合的困境.并且,本身不易收斂的critic 在與actor結(jié)合后,收斂性質(zhì)更差.后續(xù)發(fā)展的算法中,通過(guò)引入深度學(xué)習(xí)等手段,在一定程度上緩解了這些問(wèn)題.
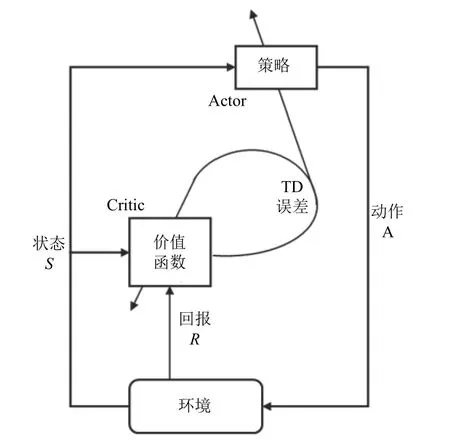
圖3 Actor-critic 算法框架
DQN 算法[24]中使用卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)估計(jì)價(jià)值函數(shù),是第一個(gè)深度強(qiáng)化學(xué)習(xí)算法,將value-based 方法的應(yīng)用范圍拓展到高維度問(wèn)題和連續(xù)空間問(wèn)題.DQN 這種端到端(end-toend)的強(qiáng)化學(xué)習(xí)算法中使用經(jīng)驗(yàn)重放(experience replay)和目標(biāo)網(wǎng)絡(luò)(target network)穩(wěn)定了價(jià)值函數(shù)估計(jì),顯著降低對(duì)特定領(lǐng)域知識(shí)的要求,并提高了算法的泛化能力.此后,DQN 算法演化出眾多變體,如使用不同網(wǎng)絡(luò)評(píng)估策略和估計(jì)價(jià)值函數(shù)的Double DQN 算法[26],差異化不同經(jīng)驗(yàn)重放頻率的優(yōu)先經(jīng)驗(yàn)重放(prioritized experience replay)算法[27],采用競(jìng)爭(zhēng)網(wǎng)絡(luò)結(jié)構(gòu)分別估計(jì)狀態(tài)價(jià)值函數(shù)和相關(guān)優(yōu)勢(shì)函數(shù)、再結(jié)合兩者共同估計(jì)動(dòng)作價(jià)值函數(shù)的Dueling DQN 算法[28],添加網(wǎng)絡(luò)參數(shù)噪聲以提升探索度的NoisyNet 算法[29],拓展到分布式價(jià)值函數(shù)的Distributional DQN (C51)算法[30],以及綜合以上各種算法的Rainbow DQN[30].這些DQN 算法能夠有效解決過(guò)擬合的問(wèn)題,具備更高的學(xué)習(xí)效率、價(jià)值函數(shù)評(píng)估效果和更充分的空間搜索能力,以及更廣泛的適用性.圖2中展示了DQN 算法及各類變種算法的性能對(duì)比.
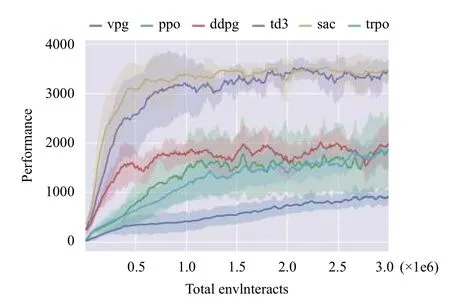
圖4 基于策略的強(qiáng)化學(xué)習(xí)算法(含actor-critic)在Hopper 問(wèn)題的效果對(duì)比[50]
Actor-critic 的代表性算法,如DPG、DDPG、TD3 及SAC 算法,其中critic 采用了異步策略的Qlearning、DQN 算法,都是典型的異步策略算法,而A3C 可根據(jù)critic 所采用的算法進(jìn)行同步/異步訓(xùn)練,能適用于同步策略、異步策略.因此,actor-critic 算法多是異步策略算法,能夠通過(guò)經(jīng)驗(yàn)重放(experience replay)解決采樣效率的問(wèn)題.然而,策略更新與價(jià)值評(píng)估相互耦合,導(dǎo)致算法的穩(wěn)定性不足,尤其對(duì)超參數(shù)極其敏感.Actor-critic 算法的調(diào)參難度很大,算法也難于復(fù)現(xiàn),當(dāng)推廣至應(yīng)用領(lǐng)域時(shí),算法的魯棒性也是最受關(guān)注的核心問(wèn)題之一.
3 強(qiáng)化學(xué)習(xí)前沿研究
近年來(lái),在傳統(tǒng)強(qiáng)化學(xué)習(xí)算法的基礎(chǔ)上,結(jié)合多智能體系統(tǒng)理論、元學(xué)習(xí)、遷移學(xué)習(xí)等研究手段,延伸出眾多前沿研究方向,如面向更現(xiàn)實(shí)場(chǎng)景的多智能體強(qiáng)化學(xué)習(xí)(Multi-Agent RL,MARL)、借助元學(xué)習(xí)泛化能力的元強(qiáng)化學(xué)習(xí)(Meta RL)、致力于解決大規(guī)模問(wèn)題維度爆炸的分層強(qiáng)化學(xué)習(xí)(Hierarchical RL),以及遷移先驗(yàn)知識(shí)的強(qiáng)化學(xué)習(xí)等.本節(jié)選取關(guān)注度最高、研究最廣泛的多智能體強(qiáng)化學(xué)習(xí)和元強(qiáng)化學(xué)習(xí)方向,介紹其中核心思想和代表性算法.
3.1 多智能體強(qiáng)化學(xué)習(xí)
復(fù)雜的現(xiàn)實(shí)場(chǎng)景中往往包含多個(gè)智能體協(xié)作、通信和對(duì)抗,例如生產(chǎn)機(jī)器人、城市交通信號(hào)燈、電商平臺(tái)搜索平臺(tái)等,都是典型的多智能體系統(tǒng).目前,應(yīng)用于多智能體系統(tǒng)的強(qiáng)化學(xué)習(xí)正在逐漸發(fā)展成為研究和應(yīng)用熱點(diǎn)[51].除了傳統(tǒng)強(qiáng)化學(xué)習(xí)中的稀疏回報(bào)和采樣效率問(wèn)題,多智能體強(qiáng)化學(xué)習(xí)還面臨著更多的挑戰(zhàn),例如多智能體如何達(dá)到納什均衡[52],每個(gè)智能體如何應(yīng)對(duì)其他智能體造成的非平穩(wěn)環(huán)境,如何僅憑自身觀測(cè)到的部分信息做出決策和更新策略[53],如何實(shí)現(xiàn)各個(gè)智能體之間的通信[54],以及在多智能體系統(tǒng)中十分重要的信用分配(credit assignment)問(wèn)題[51].此外,當(dāng)智能體數(shù)量增多時(shí),維度爆炸的問(wèn)題也愈發(fā)突出[1].
式中:為梁補(bǔ)差預(yù)期值(的取值在一定的區(qū)間并可正可負(fù));H為預(yù)計(jì)竣工時(shí)橋梁高度;Hjg1為最終竣工標(biāo)高。
根據(jù)任務(wù)的類型,多智能體強(qiáng)化學(xué)習(xí)(Multi-Agent RL,MARL)可分為完全合作、完全競(jìng)爭(zhēng)和混合模式.MARL 的關(guān)鍵是學(xué)習(xí)聯(lián)合動(dòng)作價(jià)值函數(shù)和優(yōu)秀的分布式策略,實(shí)現(xiàn)系統(tǒng)均衡和回報(bào)最優(yōu)[55].早期的MARL算法,如針對(duì)兩個(gè)智能體零和博弈的MiniMax-Q learning[56]、擴(kuò)展到多個(gè)智能體一般和博弈的Nash-Q learning[57],以及將一般和博弈轉(zhuǎn)化為兩個(gè)零和博弈的FFQ (Friend-or-Foe Q-learning)算法[58],需要使用巨大空間來(lái)存儲(chǔ)Q 值,同時(shí)線性規(guī)劃也導(dǎo)致算法整體學(xué)習(xí)速度較慢,因此多適用于小規(guī)模的問(wèn)題.此外,Tan 在1993年提出IQL (Independent Q-Learning)算法[59],按照傳統(tǒng)強(qiáng)化學(xué)習(xí)的步驟對(duì)每一個(gè)智能體分別執(zhí)行Qlearning.由于多智能體問(wèn)題的環(huán)境是動(dòng)態(tài)不穩(wěn)定的,IQL 算法無(wú)法收斂,但仍在部分應(yīng)用中取得良好的效果.
近幾年,以actor-critic 架構(gòu)為基礎(chǔ)的MARL 算法成為重要發(fā)展方向之一.代表性算法有MADDPG(Multi-Agent Deep Deterministic Policy Gradient)[60]和COMA (COunterfactual Multi-Agent actor-critic)[61].此類算法采用集中式訓(xùn)練、分布式執(zhí)行(centralized training for decentralized execution),利用聯(lián)合動(dòng)作的所有狀態(tài)信息訓(xùn)練出一個(gè)集中的critic,每個(gè)智能體通過(guò)自身觀測(cè)到的歷史信息學(xué)習(xí)策略,都有自己的回報(bào)函數(shù),并分別執(zhí)行各自的actor,能夠較好地處理非平衡問(wèn)題,可應(yīng)用于合作任務(wù)、對(duì)抗任務(wù)和混合任務(wù).然而,這種中心化算法中critic 使用全局信息,當(dāng)智能體數(shù)目增多時(shí),算法的可擴(kuò)展性較差,集中的critic 更難訓(xùn)練,多智能體信用分配問(wèn)題更難解決.同時(shí),一旦環(huán)境中某個(gè)智能體學(xué)習(xí)到較好的策略,其他智能體將會(huì)變得懶惰,進(jìn)而影響整體進(jìn)度.
不同于actor-critic 類型的方法中,每一個(gè)智能體都有各自獨(dú)立的回報(bào)函數(shù),在基于價(jià)值分解(valuedecomposition)的MARL 算法中,多個(gè)智能體通過(guò)各自的觀測(cè)得到局部?jī)r(jià)值函數(shù),再合并為聯(lián)合動(dòng)作價(jià)值函數(shù),代表性算法有簡(jiǎn)單加和局部?jī)r(jià)值函數(shù)的VDN(Value-Decomposition Network)[62],以及采用非線性混合網(wǎng)絡(luò)(mix network)來(lái)聯(lián)合價(jià)值函數(shù)的QMIX[63].因此,基于價(jià)值函數(shù)分解的方法只能應(yīng)用于合作問(wèn)題,在此過(guò)程中理解智能體之間的關(guān)系尤為關(guān)鍵.此外,Yang等提出的平均場(chǎng)方法MFMARL (Mean Field Multi-Agent Reinforcement Learning)[64],將一個(gè)智能體與其鄰居智能體間的相互作用簡(jiǎn)化為兩個(gè)智能體間的關(guān)系,即智能體與其鄰居智能體均值的相互作用,極大減緩了智能體數(shù)量增加帶來(lái)的維數(shù)爆炸問(wèn)題.平均場(chǎng)方法只能將智能體的動(dòng)作空間進(jìn)行維度縮減,而每個(gè)智能體進(jìn)行策略更新時(shí)仍然需要獲取全局狀態(tài)信息.
3.2 元強(qiáng)化學(xué)習(xí)(Meta RL)
基于策略(policy-based)的強(qiáng)化學(xué)習(xí)算法跨越價(jià)值函數(shù),直接搜索最佳策略.Policy-based 算法通過(guò)最大化累積回報(bào)來(lái)更新策略參數(shù),分為基于梯度(gradientbased)算法和無(wú)梯度(gradient-free)算法[41].無(wú)梯度算法[42,43]能夠較好地處理低維度問(wèn)題,基于策略梯度算法仍然是目前應(yīng)用最多的一類強(qiáng)化學(xué)習(xí)算法,尤其是在處理復(fù)雜問(wèn)題時(shí)效果更佳,如AlphaGo[2]在圍棋游戲中的驚人表現(xiàn).相比value-based 算法,policy-based算法能夠處理離散/連續(xù)空間問(wèn)題,并且具有更好的收斂性.與此同時(shí),policy-based 方法軌跡方差較大、樣本利用率低,容易陷入局部最優(yōu)的困境.
早期的元強(qiáng)化學(xué)習(xí)研究中多使用循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN)表示智能體[46,66].之后,加州大學(xué)伯克利分校的人工智能研究組BAIR(Berkeley Artificial Intelligence Research)提出了著名的模型無(wú)關(guān)元學(xué)習(xí)方法(Model-Agnostic Meta-Learning,MAML)[53],通過(guò)“二重梯度”算法找到泛化能力最強(qiáng)的參數(shù),只需一步或幾步梯度下降實(shí)現(xiàn)對(duì)新任務(wù)的快速適應(yīng).MAML 不限定具體的網(wǎng)絡(luò)模型,通過(guò)改變Loss函數(shù)去解決各類問(wèn)題,如回歸、分類和強(qiáng)化學(xué)習(xí).之后眾多工作以此為基礎(chǔ)發(fā)展出性能更優(yōu)的算法,如增加結(jié)構(gòu)化噪聲擴(kuò)大搜索范圍的MAESN (Model-Agnostic Exploration with Structured Noise)算法[48],識(shí)別模型任務(wù)分布、調(diào)整參數(shù)的多模型MMAML (Multimodel Model-Agnostic Meta-Learning)算法[67].同時(shí),MAML算法因其良好的泛化性能,已被推廣到自適應(yīng)控制[68]、模仿學(xué)習(xí)[69-71]、逆強(qiáng)化學(xué)習(xí)[72]和小樣本目標(biāo)推理[73]等研究領(lǐng)域.然而,以MAML 為基礎(chǔ)的一系列算法中,“二重梯度”過(guò)程極大增加了計(jì)算量,同時(shí)外層循環(huán)采用TRPO、PPO 等同步策略方法,算法在元訓(xùn)練階段的采樣效率較低.
除了以上同步策略算法之外,Rakelly 等提出了一種異步策略的、概率表示的強(qiáng)化學(xué)習(xí)算法PEARL[74](Probabilistic Embeddings for Actor-critic RL),極大提高了樣本效率,并采用后驗(yàn)采樣提高探索效率,相比同步策略算法實(shí)現(xiàn)了20-100 倍的元訓(xùn)練(meta-training)采樣效率提升,以及顯著的漸進(jìn)性能提升.同時(shí),由于概率表示量的引入,PEARL 算法具有更強(qiáng)的探索能力,能夠很好地解決稀疏回報(bào)問(wèn)題.需要指出的是,PEARL算法并不針對(duì)一個(gè)新任務(wù)去更新策略參數(shù),而是利用概率表示的潛在上下文信息泛化到新任務(wù).一旦新任務(wù)與元訓(xùn)練任務(wù)間存在較大差異,PEARL 算法的表現(xiàn)將大幅下降.此外,Mendonca 等在最近的工作中提出一種新的引導(dǎo)式元策略學(xué)習(xí)方法GMPS (Guided Meta-Policy Search)[49],通過(guò)多個(gè)異步策略的局部學(xué)習(xí)者(local learner)獨(dú)立學(xué)習(xí)不同的任務(wù),再合并為一個(gè)中心學(xué)習(xí)者(centralized learner)來(lái)快速適應(yīng)新的任務(wù),同樣實(shí)現(xiàn)了元訓(xùn)練效率跨量級(jí)的提升.此外,GMPS 算法能夠充分利用人類示范或視頻示范,適應(yīng)稀疏回報(bào)的操縱性問(wèn)題.雖然GMPS 算法在采樣效率、探索效率、稀疏回報(bào)問(wèn)題上均有十分優(yōu)異的表現(xiàn),但其中的元(訓(xùn)練)策略非常復(fù)雜,進(jìn)一步增加了異步策略超參數(shù)的敏感性,算法的復(fù)現(xiàn)和應(yīng)用難度極大.
4 強(qiáng)化學(xué)習(xí)應(yīng)用
從提出至今的60 多年里,強(qiáng)化學(xué)習(xí)已經(jīng)在科學(xué)、工程和藝術(shù)等領(lǐng)域獲得了越來(lái)越廣泛的應(yīng)用,并產(chǎn)生了眾多成功案例[1].本節(jié)選取強(qiáng)化學(xué)習(xí)應(yīng)用較多的游戲?qū)埂C(jī)器人控制、城市交通和商業(yè)等領(lǐng)域,針對(duì)近年來(lái)的應(yīng)用進(jìn)展作簡(jiǎn)要介紹.
4.1 強(qiáng)化學(xué)習(xí)在游戲?qū)诡I(lǐng)域的應(yīng)用
游戲作為人工智能算法絕佳的實(shí)驗(yàn)床,從中誕生了眾多代表性算法.在之前的眾多電子游戲中,強(qiáng)化學(xué)習(xí)算法取得了不錯(cuò)的成績(jī),在一些游戲中甚至超過(guò)了人類玩家,例如DQN 及其各類變種在Atari 2600 游戲中表現(xiàn)優(yōu)異[24,31].當(dāng)然,最著名的還是Silver 等提出的針對(duì)零和、信息完備的回合制棋類游戲程序AlphaGo、AlphaGo Zero 和Alpha Zero[2,75,76].“Alpha 系列”使用蒙特卡洛樹(shù)搜索(Monte-Carlo Tree Search,MCTS)[77]的基礎(chǔ)架構(gòu),將價(jià)值網(wǎng)絡(luò)(value network)、策略網(wǎng)絡(luò)(policy network)和快速走子(fast rollout)模塊結(jié)合起來(lái),形成一個(gè)完整的系統(tǒng).強(qiáng)化學(xué)習(xí)拓展了樹(shù)搜索的深度和寬度,平衡探索(exploration)與利用(exploitation)的關(guān)系,通過(guò)智能體的自我博弈(self-play)獲得了非常顯著的效果.“Alpha 系列”程序先后戰(zhàn)勝了當(dāng)時(shí)的人類世界圍棋冠軍,并將這種優(yōu)勢(shì)推廣到中國(guó)象棋與日本將棋.
同時(shí),強(qiáng)化學(xué)習(xí)算法也被應(yīng)用于多人參與游戲,如在非完備信息、涉及心理學(xué)的多人博弈游戲——德州撲克中,利用反事實(shí)后悔最小化(Counter Factual Regret minimization,CFR)[3,78]的遞歸推理,處理信息不對(duì)稱的問(wèn)題,實(shí)現(xiàn)廣義的納什均衡,并在六人德州撲克游戲中首次戰(zhàn)勝了5 名人類頂尖選手.另外,地圖不完全公開(kāi)的多人電子游戲中,OpenAI Five 在高度復(fù)雜、局部觀測(cè)、玩家高度配合的5v5 Dota2 游戲中戰(zhàn)勝人類高手[79],Pang 等設(shè)計(jì)的程序也在StarCraft II 游戲中表現(xiàn)優(yōu)異[4].
4.2 強(qiáng)化學(xué)習(xí)在機(jī)器人領(lǐng)域的應(yīng)用
機(jī)器人是強(qiáng)化學(xué)習(xí)最經(jīng)典也最具發(fā)展?jié)摿Φ膽?yīng)用方向[72],強(qiáng)化學(xué)習(xí)核心的MDP 序列決策特性為機(jī)器人復(fù)雜的工程設(shè)計(jì)提供了可能,如機(jī)械臂運(yùn)動(dòng)[69-71,80],直升機(jī)、無(wú)人機(jī)操控[6,81]、機(jī)器人自動(dòng)導(dǎo)航[82,83]等.在機(jī)器人打乒乓球[80]的應(yīng)用中,機(jī)器人觀測(cè)到乒乓球的位置、速度變化,以及手臂關(guān)節(jié)的位置和速度等狀態(tài)信息,通過(guò)不斷調(diào)整揮臂策略和動(dòng)作,直至學(xué)會(huì)將不同方向飛來(lái)的乒乓球擊回.近年來(lái),基于元強(qiáng)化學(xué)習(xí)的機(jī)器人模仿學(xué)習(xí)獲得了快速發(fā)展,在BAIR 基于MAML 算法[53]的系列工作中[69-71],分別讓機(jī)器人觀看人類動(dòng)作示范和視頻示范,通過(guò)在大量元任務(wù)上訓(xùn)練,逐步學(xué)會(huì)根據(jù)示范學(xué)會(huì)元學(xué)習(xí)策略.隨后,機(jī)器人面對(duì)沒(méi)有見(jiàn)到過(guò)的新任務(wù)時(shí),能夠很快完成對(duì)物品的抓取、歸類等動(dòng)作.另外,已經(jīng)有一些研究開(kāi)始探索實(shí)際生產(chǎn)線上的人機(jī)協(xié)作問(wèn)題[84,85].
在實(shí)際的應(yīng)用過(guò)程中,由于樣本獲取困難,智能體狀態(tài)空間維度高,以及模型很難抓取動(dòng)態(tài)系統(tǒng)的特征等問(wèn)題,還沒(méi)有實(shí)現(xiàn)真正的工業(yè)級(jí)應(yīng)用[5].
4.3 強(qiáng)化學(xué)習(xí)在城市交通領(lǐng)域的應(yīng)用
現(xiàn)代城市交通中,機(jī)動(dòng)車(chē)數(shù)量日益增多,部分道路擁堵嚴(yán)重,行人與非機(jī)動(dòng)車(chē)又具有很高的隨機(jī)性,路況十分復(fù)雜,對(duì)順暢交通和參與者的安全帶來(lái)巨大挑戰(zhàn).由此,城市交通網(wǎng)絡(luò)調(diào)配和機(jī)動(dòng)車(chē)駕駛紛紛將目光投向人工智能技術(shù)領(lǐng)域,發(fā)展城市智慧交通和自動(dòng)/輔助駕駛技術(shù)[86].其中,強(qiáng)化學(xué)習(xí)算法因其核心的MDP 過(guò)程與城市交通網(wǎng)絡(luò)調(diào)配的需求高度吻合,獲得了越來(lái)越多的關(guān)注與應(yīng)用.最近的一些工作研究了實(shí)際城市交通中交通信號(hào)燈的統(tǒng)一調(diào)控[7,87,88],以及城市道路設(shè)計(jì)問(wèn)題[89],研究如何改善真實(shí)的城市交通.同時(shí),機(jī)動(dòng)車(chē)自動(dòng)/輔助駕駛技術(shù)深受各大汽車(chē)生產(chǎn)廠商和技術(shù)公司的關(guān)注[90].其中,輔助/自助駕駛控制系統(tǒng)作為MDP 過(guò)程中的智能體,通過(guò)觀測(cè)機(jī)動(dòng)車(chē)行駛狀態(tài)、交通信號(hào)燈,以及周?chē)?chē)輛、行人和非機(jī)動(dòng)車(chē)的運(yùn)動(dòng)和分布情況,充分感知周?chē)窙r信息.根據(jù)觀測(cè)到的環(huán)境狀態(tài),借由基于價(jià)值函數(shù)或策略的強(qiáng)化學(xué)習(xí)方法,控制系統(tǒng)發(fā)出方向盤(pán)轉(zhuǎn)向、加速、減速、急停、等待等一系列指令,輔助人類駕駛員實(shí)現(xiàn)智能導(dǎo)航、路線規(guī)劃,避讓行人、非機(jī)動(dòng)車(chē)和緊急避險(xiǎn)等操作,保障各交通參與者的安全和道路暢通[8].后續(xù)工作中,研究人員進(jìn)一步針對(duì)城市交通中車(chē)輛稠密[91,92]和少數(shù)極端路況[93]進(jìn)行自動(dòng)駕駛汽車(chē)模擬.
在強(qiáng)化學(xué)習(xí)問(wèn)題中,智能體需要平衡探索(exploration)與利用(exploitation)的關(guān)系來(lái)獲得最優(yōu)策略,進(jìn)而得到最大累積回報(bào)[17].采取隨機(jī)動(dòng)作來(lái)充分探索全部不確定的策略,可能經(jīng)歷大量較差策略,導(dǎo)致回報(bào)較低;然而,持續(xù)利用現(xiàn)有最優(yōu)策略來(lái)選取價(jià)值最高的動(dòng)作,缺乏對(duì)狀態(tài)空間的探索,可能導(dǎo)致錯(cuò)過(guò)全局最優(yōu)策略,且回報(bào)不穩(wěn)定.
針對(duì)強(qiáng)化學(xué)習(xí)中的探索與利用問(wèn)題,多采用簡(jiǎn)單的貪婪探索,即 ε?greedy 方 法進(jìn)行改善,其中ε ∈[0,1]是一個(gè)接近于0 的小量.在ε?greedy方法中,智能體有1?ε的較大概率選取現(xiàn)有最優(yōu)策略下價(jià)值最高的動(dòng)作a=argmaxa∈AQ(s,a),但同時(shí)保留ε 的小概率隨機(jī)選取動(dòng)作,實(shí)現(xiàn)對(duì)狀態(tài)空間的持續(xù)探索.實(shí)現(xiàn)過(guò)程中,貪婪探索的 ε不斷衰減,直到降低到一個(gè)固定的、較低的探索率.在 ε?greedy這類最常用的貪心探索方法之外,置信上界(Upper Confidence Bound,UCB)等方法[18]還考慮了價(jià)值函數(shù)本身的大小和搜索次數(shù),能夠自動(dòng)實(shí)現(xiàn)探索和利用的自動(dòng)平衡,并能夠有效減少探索次數(shù).
4.4 強(qiáng)化學(xué)習(xí)在商業(yè)領(lǐng)域的應(yīng)用
近年來(lái),搜索引擎、數(shù)字媒體、電子商務(wù)逐漸深入到人們的日常生活中,深刻改變了人們的生活方式.強(qiáng)化學(xué)習(xí)作為一種有效的基于用戶與系統(tǒng)交互過(guò)程建模和最大化累積收益的學(xué)習(xí)方法,在信息檢索、商品推薦、廣告推送等場(chǎng)景中都具有十分廣闊的應(yīng)用潛力和眾多成功案例[96].
相關(guān)性排序是信息檢索應(yīng)用的關(guān)鍵,而學(xué)會(huì)排序(Learning-to-Rank,LTR)又是其中的核心技術(shù)[97].信息檢索系統(tǒng)中,搜索引擎(agent) 在用戶(environment)每次請(qǐng)求時(shí)做出相應(yīng)排序決策(action),用戶根據(jù)搜索引擎給出的結(jié)果反饋點(diǎn)擊、翻頁(yè)等信號(hào).據(jù)此,搜索引擎在收到新的請(qǐng)求時(shí)會(huì)做出新的排序決策.這個(gè)決策過(guò)程會(huì)持續(xù)到用戶購(gòu)買(mǎi)商品或退出搜索為止[10,98].推薦系統(tǒng)的核心是根據(jù)用戶的歷史行為,盡可能準(zhǔn)確地推薦最符合用戶偏好的商品/信息[99].在MDP 設(shè)定下,用戶的偏好即環(huán)境狀態(tài),而轉(zhuǎn)移函數(shù)則描述一段時(shí)間內(nèi)用戶偏好的動(dòng)態(tài)變化屬性.每次系統(tǒng)向用戶推薦商品/信息,用戶給出相應(yīng)的反饋,如跳過(guò)、點(diǎn)擊瀏覽或購(gòu)買(mǎi),其中體現(xiàn)用戶對(duì)被推薦商品的滿意度.根據(jù)用戶的歷史行為,系統(tǒng)調(diào)整對(duì)用戶偏好的判定,即環(huán)境狀態(tài)發(fā)生改變,并做出下一次推薦[100].推薦系統(tǒng)的目標(biāo)是向用戶推薦最相符的商品/信息,實(shí)現(xiàn)用戶點(diǎn)擊率和逗留時(shí)間的最大化[11].在線廣告的目標(biāo)是將正確的廣告推送給正確的用戶,強(qiáng)化學(xué)習(xí)在其中為廣告發(fā)布者提供最大化目標(biāo)的合作策略[101]和競(jìng)價(jià)策略[12],從而使廣告活動(dòng)的收入、點(diǎn)擊率(Click Through Rate,CTR)或投資回報(bào)率(Rate Of Investment,ROI)最大化.
滾,二十四把壺,就那一把壺是漏的,你專提它是不?我看你狗咬石匠想挨錘哩。李老鬼這樣說(shuō)著,幾滴老淚呱唧呱唧掉在木船上,像是摔死了幾只綠色的青蛙。
1.1.3 主要試劑。1,1-二苯基-2-三硝基苯肼(DPPH,Sigma-Aldrich,USA),2,2-聯(lián)氨-二(3-乙基苯并噻唑啉-6-磺酸)二銨鹽(ABTS,東京化成),其他試劑均為分析純(成都科龍)。
5 結(jié)論與展望
強(qiáng)化學(xué)習(xí)作為一種端到端的學(xué)習(xí)過(guò)程,以MDP 為基礎(chǔ)做出序列決策和訓(xùn)練最優(yōu)策略,具有很強(qiáng)的通用性,已經(jīng)吸引了學(xué)術(shù)界與企業(yè)界的廣泛關(guān)注,也被認(rèn)為是實(shí)現(xiàn)通用人工智能的關(guān)鍵步驟.本文綜述了強(qiáng)化學(xué)習(xí)算法與應(yīng)用的研究進(jìn)展和發(fā)展動(dòng)態(tài),重點(diǎn)介紹基于價(jià)值函數(shù)、基于策略搜索、結(jié)合價(jià)值與搜索的代表性強(qiáng)化學(xué)習(xí)方法,以及多智能體強(qiáng)化學(xué)習(xí)和元強(qiáng)化學(xué)習(xí)等前沿研究的最新進(jìn)展,這些算法都促進(jìn)強(qiáng)化學(xué)習(xí)向著更加通用化、更加便捷的方向發(fā)展.最后,本文概述了強(qiáng)化學(xué)習(xí)在游戲、機(jī)器人、城市交通和商業(yè)領(lǐng)域的成功應(yīng)用,展示了強(qiáng)化學(xué)習(xí)智能決策特性的優(yōu)勢(shì)和潛力.
實(shí)地調(diào)研中,盡管村民對(duì)專合社的總體態(tài)度是認(rèn)可并支持的,但是滿意度卻并不高。專合社剛成立時(shí),各方發(fā)展信心都很足,理事會(huì)也很賣(mài)力,不僅引進(jìn)了許多新業(yè)態(tài),通過(guò)對(duì)村民開(kāi)展相關(guān)的旅游服務(wù)技能和服務(wù)規(guī)范培訓(xùn),提高了村民的服務(wù)意識(shí)。2017年,由于鎮(zhèn)政府的大力宣傳,游客很多,幾乎家家戶戶都被分配了客源,部分家庭還多次接待游客。尤其是詩(shī)歌節(jié)期間,更是全村爆滿。但是今年,政府扶持重心有所轉(zhuǎn)移,游客量較去年減少,專合社的業(yè)務(wù)也少了許多,社員熱情退卻,開(kāi)會(huì)次數(shù)也明顯減少。
盡管強(qiáng)化學(xué)習(xí)在研究和應(yīng)用領(lǐng)域已經(jīng)取得了一定的成功,但本質(zhì)上仍局限于模擬環(huán)境中理想、高度結(jié)構(gòu)化的實(shí)驗(yàn)數(shù)據(jù),強(qiáng)化學(xué)習(xí)還不具備類人的自主學(xué)習(xí)、推理和決策能力.為了進(jìn)一步向通用人工智能的目標(biāo)邁進(jìn),強(qiáng)化學(xué)習(xí)研究與應(yīng)用有以下幾個(gè)努力方向:
采用電抗子模塊分段投切的模塊化多電平換流器降電容方法//李鈺,李帥,趙成勇,許建中,曹均正//(19):90
(1)借助監(jiān)督學(xué)習(xí)手段,提高強(qiáng)化學(xué)習(xí)魯棒性.基于策略梯度的強(qiáng)化學(xué)習(xí)算法是現(xiàn)有研究的主流,然而不可避免地帶有方差大的缺點(diǎn),對(duì)算法的穩(wěn)定性造成影響.對(duì)此,可以結(jié)合更高效、更穩(wěn)定的監(jiān)督學(xué)習(xí)方法,如模仿學(xué)習(xí)(imitation learning)、行為克隆(behavioral cloning),充分利用專家經(jīng)驗(yàn)快速訓(xùn)練出更優(yōu)的策略.
(2)構(gòu)建更智能的強(qiáng)化學(xué)習(xí)表示與問(wèn)題表述方式.關(guān)注算法的數(shù)學(xué)本質(zhì),設(shè)計(jì)具有可解釋性、簡(jiǎn)單的強(qiáng)化學(xué)習(xí)策略,摒棄單純“調(diào)參”手段,從根源上拓展算法的適用性,降低算法復(fù)雜度,突破強(qiáng)化學(xué)習(xí)中探索與應(yīng)用、稀疏回報(bào)和樣本效率等核心問(wèn)題.
(3)添加記憶模塊,利用上下文信息增強(qiáng)強(qiáng)化學(xué)習(xí)的自主學(xué)習(xí)能力.在強(qiáng)化學(xué)習(xí)模型中整合不同類型的記憶模塊,如LSTM、GRU 等模型,引入額外的回報(bào)和之前的動(dòng)作、狀態(tài)信息,使得智能體學(xué)習(xí)到更多任務(wù)級(jí)別信息,從而使智能體掌握更多的自主學(xué)習(xí)、推理和決策等功能.
(4)將元學(xué)習(xí)、遷移學(xué)習(xí)拓展到多智能體強(qiáng)化學(xué)習(xí)研究和應(yīng)用領(lǐng)域.針對(duì)真實(shí)任務(wù)場(chǎng)景中普遍存在的多智能體系統(tǒng),如生產(chǎn)線機(jī)器人、城市道路車(chē)輛等,避免大量智能體從頭開(kāi)始訓(xùn)練的高成本與不確定性,吸收元學(xué)習(xí)、遷移學(xué)習(xí)的思想,利用先驗(yàn)知識(shí)訓(xùn)練出快速適應(yīng)新任務(wù)的模型,緩解MARL 對(duì)強(qiáng)大算力支撐的需求,向復(fù)雜場(chǎng)景的應(yīng)用更進(jìn)一步.
(5)開(kāi)發(fā)針對(duì)實(shí)體輸入的強(qiáng)化學(xué)習(xí)算法,應(yīng)對(duì)實(shí)際工業(yè)生產(chǎn)應(yīng)用.實(shí)際生產(chǎn)、生活中,智能體面對(duì)高維環(huán)境如實(shí)際物品、視頻畫(huà)面等實(shí)物信息,而非原始的像素級(jí)信息.在此過(guò)程中,利用無(wú)監(jiān)督學(xué)習(xí)或其他機(jī)器學(xué)習(xí)技術(shù)對(duì)實(shí)物、實(shí)物間關(guān)系進(jìn)行理解和特征提取,將大幅提高強(qiáng)化學(xué)習(xí)算法的效率,促進(jìn)強(qiáng)化學(xué)習(xí)算法在真實(shí)場(chǎng)景中的應(yīng)用.
猜你喜歡
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學(xué)生作文(低年級(jí)適用)(2019年9期)2019-10-08 08:37:10
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
數(shù)學(xué)大世界(2018年1期)2018-04-12 05:39:14
文理導(dǎo)航·科普童話(2016年7期)2017-02-04 15:09:20
小天使·四年級(jí)語(yǔ)數(shù)英綜合(2016年11期)2016-11-29 22:37:30
時(shí)代英語(yǔ)·高三(2014年5期)2014-08-26 02:49:51
