
智能版與紙版CAM?ICU 譫妄評估的一致性研究
2021-01-22 03:00:30馮雅笛楊芳宇李京連
護理研究 2021年1期
馮雅笛,楊芳宇,李京連
1.首都醫科大學附屬北京天壇醫院,北京100050;2.首都醫科大學
譫妄是一種急性意識和認知功能障礙,在重癥監護室(ICU)中經常發生,根據對超過16 000 例ICU 病人的大型薈萃分析發現,其發生率接近1/3,機械通氣病人的發生率為80%或更高[1‐2]。ICU 譫妄的影響也很大,研究已顯示與短期和長期的不良后果有關。在短期內,發生譫妄病人的機械通氣時間明顯延長,ICU的住院時間也延長,并且醫院內死亡風險也高出兩倍以上[3]。從長遠來看,入住ICU 時出現譫妄的病人在住院后長達12 個月的死亡率也更高,并且更可能出現長期的認知障礙[4‐5]。由于譫妄帶來的一系列嚴重的后果,譫妄的早期觀察、預防和管理至關重要。2018年,疼痛(pain)、躁動/鎮靜(agitation/sedation)、譫妄(delirium)、制動(immobility)及睡眠紊亂(sleep disrup‐tion)指南發布,簡稱PADIS[6]。新版本指南仍然推薦ICU 意識模糊評估法(Confusion Assessment Model for Intensive Care Unit,CAM‐ICU)為ICU 譫妄的常規評估工具,但是在臨床應用中存在譫妄的診斷正確率不太高、護士感覺其操作復雜、需要系統培訓、病人意識的基線狀態查找不便等問題[7‐8]。智能化譫妄評估系統(智能化CAM‐ICU)為解決這些問題,以紙質原版CAM‐ICU 為藍本,通過綜合運用移動智能終端、計算機網絡、數據庫等智能化手段開發而成,并已完成雛形階段的可用性評價[9]。本研究采用前瞻性隊列研究設計,評價智能版CAM‐ICU 與紙版CAM‐ICU 對譫妄評估結果的一致性,驗證智能版CAM‐ICU 評估結果的準確性,為未來推廣ICU 護理人員應用智能版CAM‐ICU 監測危重癥病人譫妄狀態提供參考。
1 對象與方法
1.1 研究對象
1.1.1 納入與排除標準 納入標準:入住ICU 的病人;預期入住至少達到24 h;年齡50 歲以上;急性生理與慢性健康狀況評分系統Ⅱ(APACHEⅡ)10 分以上。排除標準:有會影響譫妄診斷的神經系統疾病病史或精神疾病病史;不能聽懂普通話,無法進行有效交流;嚴重視力障礙或聽力障礙;持續昏迷3 d 或鎮靜程度評估表(RASS)評分為?4~?5 分;拒絕參與研究者。
1.1.2 樣本量 采用非劣性試驗比較兩組計數資料的樣本量計算公式:n=2×(Uα+Uβ)2×P(1?P)/δ2,估算樣本量。采用單側檢驗水準α,允許二類誤差概率不超過β,假設智能版與紙版CAM‐ICU 的靈敏度相同,取靈敏度P=0.90,檢驗界值δ=0.09(一般取P的1/3~1/10,這里取1/10),α=0.05,單側U0.05=1.645,β=0.2,單側U0.20=0.845,計算得到樣本量為137 例。
1.2 研究工具
1.2.1 紙版CAM‐ICU 紙版CAM‐ICU 是Ely 等[10]根據《精神疾病診斷與統計手冊(DSM‐Ⅳ)》對意識模糊評估法(Confusion Assessment Method,CAM)進行改良而成的譫妄評估工具,主要用于對ICU 病人的譫妄評估。該工具為紙質形式,評估者需要按照培訓手冊所示流程實施評估并填寫,將病人的各特征情況進行累計,最后判斷病人是否發生譫妄。該工具中文版本的靈敏度和特異度分別為93.4%和90.8%[11]。該工具分別對病人的意識基線狀態波動(特征1)、注意力障礙(特征2)、意識水平改變(特征3)以及思維混亂(特征4)4 個特征進行評估,并依據以上特征的評估結果做出是否發生譫妄的判斷。①特征1:需要觀察病人精神狀態是否與基礎水平不同或過去24 h 內是否出現意識狀態的波動,即與基線狀況相比,或多次用RASS 評估的得分不等或有波動,如果出現上述任意1 種情況則特征1 評定為陽性;②特征2:注意缺損,讓病人在聽到特定字母時捏手示意或選出正確圖片,如果錯誤超過2 個,則特征2 評為陽性;③特征3:思維紊亂,分為兩部分考察,一部分為4 個常識性是非問題,共有兩組問題可以交替使用,每答對1 個問題計1 分,另一部分要求病人依次完成兩個指令動作,完成全部指令計1 分,兩個部分總分相加<4 分則特征3 評定為陽性;④特征4:意識清晰度改變,根據病人的RASS評分判定,RASS 得分只要不為0 分則評為陽性。譫妄陽性診斷標準:譫妄陽性指特征1 和特征2 均為陽性,加上特征3 或特征4 的任意1 條為陽性。否則為譫妄陰性。
1.2.2 智能化CAM‐ICU 智能化CAM‐ICU 是一款以譫妄評估工具CAM‐ICU 為藍本,運用計算機編程實現的交互式應用程序。評估者通過人機交互頁面對病人是否發生譫妄進行評估,其頁面和流程由登錄界面、譫妄評估界面組成。其中,評估界面又包括3 個子界面:意識評估、注意力評估和思維評估。評估者根據系統的提示進行評估,在系統界面上依次點選病人的意識、注意力和思維評估結果,系統自動完成對病人的譫妄診斷,無須人工計算和判斷評估結果[9],評估結果中,譫妄陽性指特征1 和特征2 均為陽性,加上特征3陽性或特征4 陽性則為譫妄陽性,否則為譫妄陰性。智能化CAM‐ICU 譫妄評估系統通過基線提前輸入、評估時系統自動對比結果、整合RASS 量表進入系統(不需要另外查找)、自動計算病人的出錯次數、自動彈縮每步的評估指導語、自動輸出評估結果等智能設計,實現能用、易用、易學、可信賴的設計目的。該系統經過智能化方案設計、美工設計和雛形可用性評價等工作,已形成正式版安裝于安卓系統的掌上電腦(personal digital assistant,PDA)上進行使用。
1.3 研究方法
1.3.1 研究者收集納入病人的基線資料 ①人口學資料:性別、年齡、文化程度、職業、婚姻狀況、醫療費用支付方式。②臨床資料:既往疾病史和手術情況,既往疾病史包括高血壓、糖尿病、慢性阻塞性肺疾病(COPD)、肝功能不全、腎功能不全、心臟疾病、甲狀腺功能亢進、甲狀腺功能減退、癡呆、譫妄、腦卒中、抑郁癥、高脂血癥及其他精神或軀體疾病病史。
1.3.2 譫妄評估 按照CAM‐ICU 規定的使用方法和培訓手冊對3 名護理研究者進行培訓后,3 名研究者按照研究對象的納入標準和排除標準選擇病人,每天09:00~11:00 評估病人。其中1 人使用紙版CAM‐ICU,另外2人使用分別安裝在兩個PDA中的智能版CAM‐ICU(以下簡稱為智能版A 和智能版B)對同一病人進行評估,由于譫妄具有波動性,因此規定3 人的評估在2 h內完成。3 名資料收集者每人只知道自己的評估結果,不知道對方的結果,填寫好的紙版評估單放入信封由第4 個人保管,智能版評估結果由后臺直接發送到第4 人電子郵箱中,評估結果的歷史記錄由系統自動進行屏蔽。
1.4 倫理審查和知情同意 ①本研究獲得首都醫科大學倫理委員會的審查并通過。②向研究對象承諾本調查僅屬于研究性質,所有資料和結果僅用于本次研究,取得病人同意并與病人簽署知情同意書。
1.5 評價指標 Kappa 值是評價臨床測量結果一致性的重要指標,其主要用于評價定性測量結果的一致性,兩者的值愈高,說明測定結果的一致性愈好。一般而言,Kappa 值≤0.40 時,表明一致性較差;0.41~0.60時,表明中度一致;0.61~0.80 時,表明有較高度的一致性;>0.80 時,表明有極好的一致性。
1.6 統計學方法 采用Epidata 3.1軟件建立數據庫,進行雙人數據錄入,系統邏輯檢錯,采用SPSS20.0 軟件包進行統計分析。計量資料采用均數(x)、標準差(s)、中位數(M)、四分位間距(Q)表示;采用單樣本Kolmogorov Smirnov 檢 驗(one‐sample Kolmogorov Smirnov test)進行正態性檢驗。計數資料采用百分比(率)進行描述,智能版與紙版CAM‐ICU、兩智能版之間評估結果的關聯性采用一致性Kappa 值進行統計分析。以P<0.05 為差異有統計學意義。
2 結果
2.1 研究對象的基本特征 本研究共納入符合入選標準的病人263例,排除57例,入選206例;入選的206例病人中,剔除12 例缺失評估結果及中途退出的病人,最終進行統計分析的病例為194 例,研究對象納入過程見圖1。納入統計分析的194 例病人年齡(69.24±10.34)歲;其中男109例,已婚184例,住院天數4(3,6)d,中學/中專文化程度84 例,已退休143 例,術后病人146 例,醫療費用支付方式為醫療保險118 例,日常生活能力(ADL)得分為80(35,100)分。見表1。
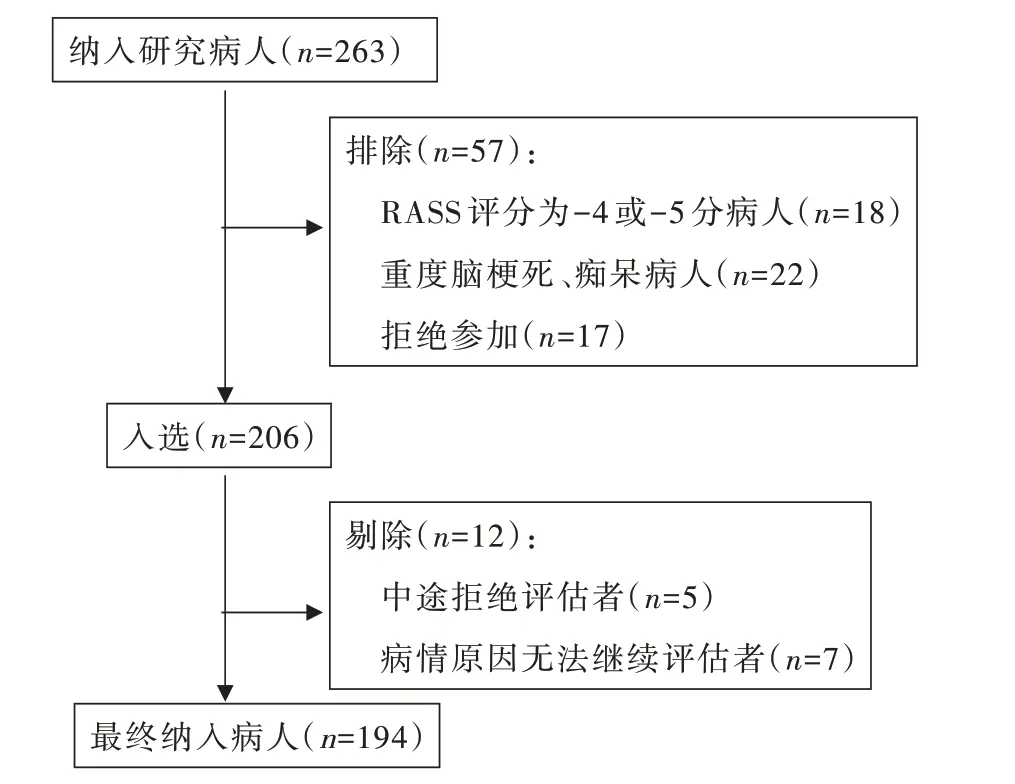
圖1 研究對象納入流程圖
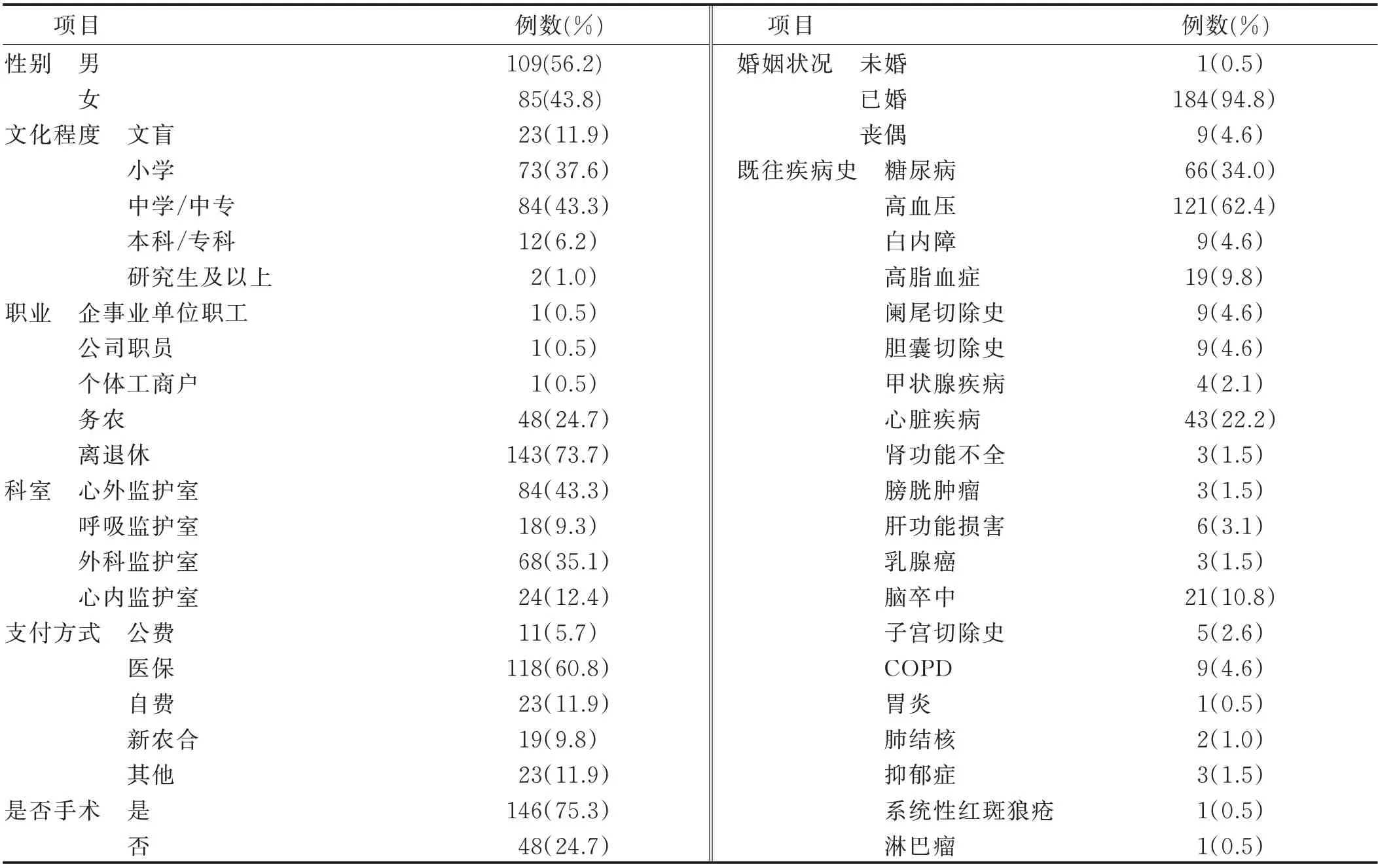
表1 入選病人的基本特征(n=194)
2.2 譫妄評估結果一致性的比較
2.2.1 紙版與智能版CAM‐ICU 譫妄評估結果的一致性 在評估的194 例病人中,紙版CAM‐ICU 檢測出譫妄陽性病人47 例,智能版A 檢測出譫妄陽性病人49 例,其中紙版CAM‐ICU 檢出陽性而智能版A 檢出陰性者2 例,智能版A 檢出陽性而紙版CAM‐ICU 檢出陰性者4 例。Kappa 一致性檢驗結果顯示,紙版CAM‐ICU 與智能版A 評估結果具有較高的一致性,Kappa 值為0.916,P<0.001。見表2。

表2 紙版CAM‐ICU 與智能版A 的評估一致性 單位:例
智能版B 檢測出譫妄陽性病人47 例,其中紙版CAM‐ICU 檢出陽性而智能版B 檢出陰性者3 例,智能版B 檢出陽性而紙版CAM‐ICU 檢出陰性者3 例。通過Kappa 一致性檢驗,紙版CAM‐ICU 與智能版B 評估結果具有較高的一致性,Kappa 值為0.917,P<0.001。見表3。

表3 紙版CAM‐ICU 與智能版B 的評估一致性 單位:例
2.2.2 智能版A 與智能版B 譫妄評估結果的一致性
在評估的194 例病人中,智能版A 檢測出譫妄陽性病人49 例,智能版B 檢測出譫妄陽性病人47 例,其中智能版A 檢出陽性而智能版B 檢出陰性者2 例,而智能版B 檢出陽性而智能版A 檢出陰性者0 例。通過Kappa 一致性檢驗,智能版A 與智能版B 評估結果具有 較 高 的 一 致 性,Kappa 值 為0.972,P<0.001。見表4。

表4 智能版A 與智能版B 的評估一致性 單位:例
2.3 譫妄不同類型評估結果的一致性 譫妄根據臨床表現不同分為不同類型[12],本研究依據Spronk 的分類方法[13]將譫妄評估結果分為:①活動減弱型(hypoactive state),RASS 得分為?3~?1 分;②活動型(active state),RASS 得分為0~1 分;③極度活躍型(hyperactive state),RASS 得分為2~5 分,比較智能版與紙版以及智能版A 與智能版B 之間對譫妄不同類型評估結果的一致性。
2.3.1 紙版CAM‐ICU 與智能版A 對譫妄不同類型評估結果的一致性 紙版CAM‐ICU 與智能版A 評估結果均為陽性者有44 例,二者對譫妄不同類型評估結果存在一定差異,詳見表5。通過Kappa 一致性檢驗,紙版CAM‐ICU 與智能版A 評估結果的一致性Kappa 值為0.405,P<0.001。

表5 紙版CAM‐ICU 與智能版A 對譫妄不同類型評估結果的一致性 單位:例
2.3.2 紙版CAM‐ICU 與智能版B 對譫妄不同類型評估的一致性比較 紙版CAM‐ICU 與智能版B 評估結果均為陽性者有45 例,二者對譫妄不同類型評估結果具有較高的一致性,詳見表6。通過Kappa 一致性檢驗,紙版CAM‐ICU 與智能版B 評估結果的一致性Kappa 值為1.00,P<0.001。
2.3.3 智能版A 與智能版B 對譫妄不同類型評估的一致性 智能版A 與智能版B 評估結果均為陽性者有47 例,二者對譫妄不同類型評估結果存在一定差異,詳見表7。通過Kappa 一致性檢驗,智能版A 與智能版B 評估結果的一致性Kappa 值為0.407,P<0.001。

表6 紙版CAM‐ICU 與智能版B 對譫妄不同類型評估結果的一致性 單位:例

表7 智能版A 與智能版B 對譫妄不同類型評估結果的一致性 單位:例
3 討論
3.1 智能版與紙版CAM‐ICU 譫妄評估結果具有很高的一致性 一致性指對同一個體用兩種工具或從兩種角度進行觀測,測量值之間接近程度或測量效果相似性的一個指標。Kappa 值是評價臨床測量結果一致性的重要指標,一般而言,Kappa 值≤0.40 時,表明一致性較差;Kappa 值為0.41~0.60 時,表明中度一致;Kappa 值為0.61~0.80 時,表明有較高度的一致性;Kappa 值≥0.80 時,表明有極好的一致性。本研究采用前瞻性隊列研究設計,評價紙版與智能版CAM‐ICU 對譫妄病人評估結果的一致性,推測和驗證智能版CAM‐ICU測量結果的準確性。
CAM‐ICU 是Ely 等[10]根據DSM‐Ⅳ對CAM 進行改良而成[14],該量表依據CAM 的4 個主要標準,制定了具體的評估方法,并且在譫妄評估之前加入了RASS 量表,量化意識水平的評估,CAM‐ICU 量表不需要評估者具有神經精神科知識背景,適合非精神科醫護人員使用,且對病人意識狀態的評估不依賴于病人的言語能力,增加了評分的客觀性,尤其適用于ICU機械通氣言語受限的病人[15‐19]。目前,國外多數國家已經廣泛使用CAM‐ICU,CAM‐ICU 被翻譯成了多種版本,例如泰國版本[15]、葡萄牙語版本[20]、瑞典版本[21]以及中文版本[14]等,經驗證均具有較高的靈敏度和特異度。
智能化CAM‐ICU 依據以用戶為中心的理念,以紙質原版CAM‐ICU 為藍本,綜合運用智能移動終端、計算機網絡、數據庫等智能化手段開發研制的交互式運用程式,旨在通過人性化、智能化、交互化的技術,解決紙版CAM‐ICU 在評估過程中便利性不強、對記憶和判斷等認知資源消耗過高等方面的不足。該智能系統雖改變了紙版工具的表現形式,調整畫面配色和界面布局,自動計算病人出錯次數和判斷結果,降低了紙版工具對護士記憶和計算能力的高要求,但未對量表的4 個特征的內容及評估流程進行改動,診斷結果的判斷標準也未進行變動。因此,從理論上,智能版CAM‐ICU 應該具有紙版CAM‐ICU 的診斷準確性和可靠性,智能版與紙版CAM‐ICU 的評估結果應該具有很高的一致性。
本研究所有評估者均經過統一培訓,掌握CAM‐ICU的評估方法,并且在研究正式開始之前進行了評估者間一致性檢驗。在研究進行過程中嚴格按照納入標準和排除標準選擇樣本,采用連續入組法降低選擇性偏倚。同一研究者對同一病人在規定的時間點只進行1 次評估,盡量避免多次重復評估,以免病人對同一問題產生記憶而影響正確的判斷。所有評估者之間保持盲法,填寫好的紙版評估單放入信封由第4 個人保管,智能版評估結果的記錄由后臺直接發送到第4 人電子郵箱中,評估結果的歷史記錄由系統自動進行屏蔽。通過以上質量控制措施,盡可能地避免選擇偏倚和信息偏倚,保證了評估結果的真實性。結果顯示,智能版A 與紙版CAM‐ICU 評估結果的一致性Kappa 值為0.916,智能版B 與紙版CAM‐ICU 評估結果的一致性Kappa 值為0.917,智能版A 和智能版B 評估結果之間的一致性Kappa值為0.972,三者均具有統計學意義(P<0.001)。以上結果表明,紙版與智能版CAM‐ICU 的評估結果具有較高的一致性,說明智能版CAM‐ICU評估譫妄病人結果的準確性不低于紙版CAM‐ICU。智能版CAM‐ICU 與紙版CAM‐ICU 的評估結果未完全一致,例如紙版CAM‐ICU 檢出陽性而智能版A 檢出陰性者2 例,智能版A 檢出陽性而紙版CAM‐ICU檢出陰性者4 例。紙版CAM‐ICU 檢出陽性而智能版B檢出陰性者3 例,智能版B 檢出陽性而紙版CAM‐ICU檢出陰性者3 例。可能的原因為3 名研究未同時評估病人,由于譫妄具有波動性,不同時間點評估會有差異。但從總體結果來看智能版和紙版評估結果的一致性很高。
3.2 智能版與紙版CAM‐ICU 對譫妄不同類型的評估結果有一定差異 智能版與紙版CAM‐ICU 以及智能版A 與智能版B 之間對譫妄不同類型評估結果的一致性結果顯示,紙版CAM‐ICU 與智能版B 對譫妄不同類型評估結果具有很高的一致性,而紙版CAM‐ICU 與智能版A 對譫妄不同類型評估結果存在著一定的差異,可能原因為臨床譫妄病人存在混合型譫妄,國內研究顯示,臨床混合型譫妄病人占34.3%[22]。混合型譫妄的特征是活動減弱型和極度活躍型表現在同一病人交替出現[23]。而由于不同版本評估者評估時并非同時進行,由于混合型的這個特征,導致不同評估者評估時,病人的譫妄類型可能已轉換,從而導致了智能版之一在評估譫妄類型上與紙質版的一致性不夠高。另外,兩個智能版評估者之間一致性也存在差異,其可能的原因也與上述推斷相同。再者,由于譫妄陽性的病人在數量上還不夠多,對不同類型的評估一致性判斷上還存在一定限制。
另外,評估結果顯示,雖然紙版與智能版CAM‐ICU以及智能版A 與智能版B 的RASS 評分不完全一致,但是譫妄最終評估結果仍然都為陽性,此現象應是CAM‐ICU 對譫妄是否陽性的判斷規則所致。在其判斷規則中,RASS 評分只是CAM‐ICU 評估譫妄的特征之一,CAM‐ICU 評估譫妄的最終結果是由病人的意識基線狀態波動、注意力障礙、意識水平改變以及思維混亂4 個特征決定,判斷病人譫妄陽性需同時滿足特征1(意識基線狀態波動)和特征2(注意力障礙)均為陽性,加上特征3(意識水平改變)或特征4(思維混亂)的任意一條為陽性。RASS 評估的結果主要代表意識水平的改變情況,無論病人是活動減弱型還是極度活躍型,只有同時再滿足意識基線狀態波動和注意力障礙均為陽性,其譫妄最終評估結果才為陽性。本研究中,紙版CAM‐ICU 與智能版A 以及智能版A 與智能版B 之間對譫妄不同類型評估結果還存在一定差異,這可能與病人為混合型譫妄有關,未來可擴大樣本量、增加譫妄陽性病人例數進一步進行驗證。
3.3 本研究存在的局限性 本研究存在一定的局限性,由于評估者在1 d 內未對病人進行多次評估且采用的譫妄分類方法中無混合型的分類,因此單憑1 d的1 次評估結果來對比兩種方法在不同類型上的評估一致性,可能造成評估結果的一致性不高,未來可擴大樣本量、增加譫妄陽性病人例數進一步進行驗證。
4 小結
本研究采用前瞻性隊列研究設計,評價智能版CAM‐ICU 與紙版CAM‐ICU 對譫妄病人評估結果的一致性,進而驗證智能版CAM‐ICU 評估結果的準確性,為未來推廣ICU 護理人員應用智能版CAM‐ICU監測危重癥病人譫妄狀態提供參考。研究結果得出,智能版A 與紙版CAM‐ICU 評估結果的一致性Kappa值為0.916,智能版B 與紙版CAM‐ICU 評估結果的一致性Kappa 值為0.917,智能版A 和智能版B 評估結果之間的一致性Kappa 值為0.972,智能版與紙質版CAM‐ICU 譫妄評估結果具有很高的一致性。
猜你喜歡
公民與法治(2022年5期)2022-07-29 00:47:28
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
