
基于網絡行為的人物心理刻畫方法
2021-02-03 08:47:26張文凱李衛巍
無線互聯科技 2021年1期
耿 琦,張文凱,李衛巍
(江蘇金盾檢測技術有限公司, 江蘇 南京 210042)
1 引言
用戶畫像又稱用戶角色,是根據用戶在網絡上留下的各種個人信息而制作的由詞匯組成的畫像。作為一種描述用戶自身情況、了解用戶訴求與其思考方向的工具,用戶畫像在各種互聯網服務業中得到了廣泛的應用。在實際繪制過程中,畫像者往往會以最為簡潔明了與接近現實的語言將用戶的各種心理上的屬性與實際行為形成映射。作為用戶的虛擬形象,用戶畫像會根據用戶社交狀態、日常習慣以及消費偏好等信息描繪出一個由標簽組成的用戶形象。標簽,是對某一類指定群體或個體其中的某種特征進行分類概括所得的文字。用戶畫像的核心與基礎組成就是標簽。通過標簽,用戶畫像能夠對用戶的特征進行具體又多樣的描述,同時又具有對指定特征的針對性,從而以此作為心理分析的一種依據。標簽的定義需要對用戶的數據進行分析與篩選而得到。
用戶畫像主要用于對用戶的網絡行為進行心理分析。網絡行為是指人們直接或間接借助互聯網所做出的現實行為。用戶在進行自己的個人網絡行為時會在運行這些功能的網絡應用上留下自己的使用痕跡,即行為記錄。包括購買記錄、支付記錄、觀看記錄等。這些記錄能夠充分反映個人的起居習慣、工作習慣、娛樂習慣等個人心理的展示媒介,用戶畫像對他們的總結與分析能允許研究者進一步對用戶的心理進行充分的了解。
用戶畫像的關鍵就是標簽,通過對個人形象的標簽化處理,它可以描摹出一個用戶的信息“輪廓”,來大致了解用戶的行為、消費習慣等可以用于分析用戶心理的重要個人信息。且易于及時修改,無須在出現重大變動后重新對用戶進行實際調查,而是在用戶數據中修改變動后重新繪制即可。同時,用戶畫像的標簽是由用戶的海量歷史數據中分析所得的,可以較為準確地反映不同的時間與空間下用戶的屬性與行為,受用戶個體的自身當前喜惡、心情等精神狀態影響較小(如問卷受此影響就較大),使得心理刻畫更為準確。此外,用戶本身的標簽“畫像”是心理刻畫的優秀媒介,它能夠較為直觀地展示用戶的需求與行為,成功刻畫用戶心理。
同時,在對個人用戶進行心理分析時,若采用傳統的問卷調查等人工方式,不僅因為紙質媒介的局限性而使搜集到的個人數據有限,而且由于個人對他人了解自己日常生活行為或多或少的抵觸感,被調查者往往不會對自己的個人行為進行完全詳細且準確的描述,從而使得個人心理分析出現一定量的偏差。而用戶畫像是對用戶自己獨自進行的網絡行為進行分析,能夠在用戶不產生抵觸感的情況下真實反映其心理情況,并且由于行為記錄的多渠道與多方面,網絡行為對個人心理情況的反饋是多樣的,因此用戶畫像的心理分析能夠更加全面且準確。除此之外,用戶畫像的研究是基于計算機的,計算機的強大處理能力使得它進行數據處理的效率大大提高,從而在心理分析方面具有更大優勢。
在用戶畫像的定義與構成方面,國外研究者D. Travis[1]提出了7個用戶畫像的基本特征: 基本性、情感性、真實性、獨特性、目標性、數量性和應用性,并將這7個特性的英文首字母組合后即成為“用戶畫像”這個名稱。而T. Lafouge[2]等認為用于對用戶的特征信息進行分析的因素主要包括兩個方面:與用戶個人相關的靜態因素(如該用戶的個人基本信息、日常行為以及習慣等不易改變的因素) 與用戶外部的動態因素(如機進行分析時所處的網絡環境、搜索的目標等可變的因素)。國內研究者中,曾建勛[3]提出從用戶的專業知識、興趣、工作等方面提取用戶畫像標簽。李映坤[4]對用戶畫像的基本構成進行了拓展,提出了基于自然屬性、關系屬性、興趣屬性、能力屬性、行為屬性與信用屬性的用戶畫像構建方法。劉海鷗等[5]在研究中對用戶自身的情境要素進行了探究,將用戶畫像的構成劃分為自然屬性、社交屬性、興趣屬性和能力屬性。
在用戶畫像的具體方法上,國外研究者Nasraoui.O等[6]提出可以利用數據挖掘技術從網站日志中發現用戶的行為模式,并采用K-Means聚類算法將用戶分成不同的集群,構建集群的用戶畫像;而Q. Liu 等[7]通過隱含狄利克雷分布模型對用戶社交中感興趣的話題進行分析,由此構建融合了用戶的興趣的畫像模型。而在國內研究者中,王洋等[8]通過廣泛研究發現,可將用戶在互聯網上的訪問記錄以及用爬蟲獲取的數據作為用戶畫像構建的基礎,并通過大數據技術對用戶網絡行為數據進行處理,以此構建的用戶畫像在準確度方面得到了明顯改善。
盡管目前的用戶畫像方法已經在用戶心理分析方面取得顯著效果并被廣泛應用于實際推薦系統中,這些方法仍然存在一定的缺陷:首先,這些已有的方法大多數都基于人工抽選的較為分散且不相關的特征,這些特征無法對用戶數據的相關聯信息一起進行刻畫,因此對于被畫像者的形象描述程度有限。其次,現有的用戶畫像方法通常基于較簡單的線性回歸或分類模型,無法在處理數據的過程中學習到更高級的特征分析,因此不能對各特征之間的關系進行更深層次的描述。
用戶畫像雖然能夠通過標簽較為精確地反映用戶個體的屬性與行為,但其以標簽為基礎的性質使得其只能對一個人的性格進行碎片化處理,研究者從用戶畫像中得到的是也只能是個人心理屬性的一種概括,并不能完全從一個人的各方面描述其情感與習慣。“貼標簽”的心理分析,在強調個人屬性的一方面的同時,也掩蓋了此屬性的其他潛在衍生部分,忽略了更多的分析可能性。而且,用戶畫像其中包含的無關數據與冗雜數據也相對于人工方式來說更多,從而使數據的處理變得更加復雜和充滿可變性,個人的心理分析偏差度甚至會超過人工分析方式。且無法收集用戶的一般現實社會日常行為的記錄,而一般現實行為對用戶更加基礎的心理反應也因此被忽略,整個個體心理分析的實際程度會打折扣[9-10]。
1 用戶畫像基本理論與技術
1.1 用戶畫像基本理論與繪制流程
1.1.1 目標確定
構建用戶畫像之前,需要確定構建者的目的,用戶畫像服務于何種對象,以及對象的具體數目,以便選擇合適的構建方法。用戶畫像分為個人畫像與群體畫像,由構建對象的數目來決定。對于心理刻畫與性格確定,一般偏向選擇個人畫像,使用Python與網絡爬蟲進行實現。而對于商品推薦、精準營銷等商業用途,則更偏向于群體畫像,需借助大數據技術進行數據收集與分析,再根據數據完成畫像。本文采用個人畫像進行實驗。
1.1.2 確定并尋找數據源
用戶畫像的來源是用戶數據,而用戶數據的來源一般來自互聯網上的各種網絡應用。不同應用中的用戶使用記錄會反映用戶的不同屬性。因此通過多種渠道搜集用戶數據是進行用戶畫像的前提,同時搜集到的數據與畫像目的的關聯性能夠直接反應用戶畫像的準確性。
若搜集數據的對象為個人,則不僅可以在網絡上獲取相關用戶數據,也可以將用戶個體實際調研作為一種補充數據的備選方案,因其操作難度相對于大眾調研來說降低很多。同時要務必注意在搜集他人私密數據時需要獲得他人許可。
1.1.3 數據分析
確定了數據源并搜集到數據后,需要對各種數據進行分析,去掉其中相對不關聯的數據與冗雜、重復數據,為后續的畫像做好準備。數據的分析通常需要相應的算法來實現,算法需要提前確定來及時完成分析。可參考相關文獻與類似設計來了解算法,或對現有算法進行一定程度上的優化,使其更符合自己程序的目標。用戶畫像如今一般使用的數據分析算法為K-means算法與TF-IDF算法。K-means算法一般用于對數值文本所反映的用戶屬性進行總結,而TF-IDF算法會對用戶的文本記錄進行其中的關鍵字提取。
K-means聚類算法,又稱k均值聚類算法。它是聚類算法中的一種,因其實現方法較簡單,且聚類效果顯著,因此在進行數據聚類時經常采用的算法之一。它基于數據均值來對各樣本點進行聚類,K表示將數據分成k個聚類,又稱簇,means表示均值,是指取每一個簇中的數據值的均值作為該簇的中心,又稱為聚類中心或質心,它可以視為整個簇的代表。K-means算法基于這些變量進行聚類分析,讓簇內的點盡量緊密地連接在一起,而簇間的距離要保證盡量的大。means算法的基本流程圖如圖1所示。

圖1 K-means算法流程圖
TF-IDF算法,也稱詞頻-逆文本頻率算法。是一種常用于數據信息檢索的算法,用于評估一個字或詞對于一份普通文件或語料庫(指經過科學分類的電子文本庫)中的一份文件的重要性。圖2為TF-IDF算法流程圖。

圖2 TF-IDF算法流程圖
1.1.4 標簽構建
用戶畫像的核心就是標簽。標簽的構建是整個用戶畫像構建的重中之重。根據數據分析中得到的結果形成關鍵字,而關鍵字就是標簽的原型。對關鍵字進行適當的處理后就會形成標簽。標簽代表了用戶畫像的主體各屬性。若標簽較多,也可以將標簽組成標簽樹,形成分層結構,從而對不同屬性值進行再一次分類,使屬性分類更加詳細。同時可以制作一張標簽表,便于對所有標簽進行總覽,進行增刪改查。在用戶畫像中,標簽表一般會存儲在文本文件中。
標簽一般會采用能夠最直觀反映用戶的基本信息或內心需求的相關詞語,如生日,常聽的音樂,購買的商品等。對它們的選擇傾向即是用戶畫像側重點的選擇。如多選擇用戶的購買喜好和商品價格就是偏向對用戶的購物心理進行畫像,而多選擇用戶體重、健身卡辦理次數和行動距離就是偏向對用戶的運動心理進行畫像。
此外,確定標簽的權重也是在創建標簽中的一個重要步驟。標簽權重表示此標簽對應屬性在整個用戶屬性集中的占比,因為不同標簽所對應的屬性重要性不同,而不同屬性對用戶的心理反應全面程度也是不同的。而標簽的權重,就是對這種反映全面程度的量化表示。權重可以是不同的計算單位,由具體研究情況決定,通常情況下是標簽或其代表關鍵字的出現概率,此值可由TF-IDF算法確定。畫像時可以將其附加在標簽自身屬性上,形成映射,凸顯不同標簽的重要性大小。而凸顯的方式也是各異,大多數選擇體現在標簽字體大小上。
1.1.5 繪制畫像
在獲得所有需要的標簽后,需要的就是將標簽按順序填充進用戶指定的圖片中,組成一個人形。這個人形,就是由用戶畫像構建的用戶個體的虛擬形象,個體的大部分屬性均可以在此幅圖像上體現出來,在之前計算出的標簽的權重在此幅圖中會根據畫像者的需求來表示。若有需要,可以在用戶畫像旁進行屬性的總結,以顯示用戶個體的一些更加貼近現實生活的細節。
繪制出的用戶畫像可以充分展示用戶個體的內心傾向、喜惡、性格等心理元素,是心理刻畫的優秀產物。借助計算機的計算能力,人們可以僅僅利用自己的“歷史記錄”就能勾勒出自己或者他人的基本性格外框,為了解他人乃至以此獲得商業利益奠定了基礎,在這個信息時代開辟了一塊全新領域。

圖3 用戶畫像算法需要實現的主要功能
2 用戶畫像具體算法實現
在本文中,用戶畫像算法要實現數據搜集、數據處理、用戶畫像繪制、用戶畫像顯示4個功能。其中數據處理功能又分為混合數據分離、文字數據處理與數值數據處理3個子功能。算法的主要功能如圖3所示。
2.1 數據搜集
為了保證數據的真實、全面與可獲得性,數據搜集模塊中使用的網絡爬蟲軟件為“八爪魚采集器”,通過它的自定義采集數據功能,可以搜集到較為全面的網絡用戶數據,如淘寶購買記錄、微博關注列表、個人音樂歌單等。而對于需要用戶登錄才能進行數據采集的情況也能很好地進行解決。并且搜集到的數據會作為csv文件導出,供用戶畫像程序使用。
2.2 數據處理
數據處理部分主要完成3個工作:混合數據分離,數值文本處理和文字文本處理。通過這3個過程,可以從搜集到的數據中提取出關鍵字并加工成標簽,是整個用戶畫像中的核心。
2.2.1 混合數據分離
在進行數據處理時,可能會出現數值與文字結合在一起的混合數據文本。由于用戶數據中的數值部分與文字部分分別會提取出不同性質的關鍵詞,所以需要進行分離。此功能只需在通過網絡爬蟲獲得的文件為混合數據文件時使用。
通過網絡爬蟲讀取它們的混合方式一般是作為文件中前后兩個不同的列出現,可以在使用Python中的文字處理模塊pandas進行csv文件的讀取后,利用loc方法再對讀取到的文件進行逐列的讀取。而csv模塊中的writer方法可以創建新的csv文件并進行輸入與輸出,將讀取到的各列按照讀取到的不同數據,再通過pandas模塊的逐行輸入方法writerows分別輸入進創建的新csv文件中,從而做到分離混合數據。
2.2.2 數值數據處理
在數值中提取出的關鍵詞雖然不是用戶標簽的主要組成部分,但它們反映的用戶屬性往往更為直接且透徹,成功分析商品價格、使用次數等數值數據來得到用戶關鍵詞是用戶畫像流程的核心之一。
2.2.3 文字數據處理
在文字中提取出的關鍵詞是用戶標簽的主要組成部分。用戶使用、訪問記錄等文字數據廣泛存在于各種網絡應用中,對它們的分析是一個用戶畫像繪制程序的又一個核心。本文利用TF-IDF算法來計算關鍵詞的出現頻率,并可以根據用戶數據中的每個詞的出現頻率進行關鍵詞的提取。因此,文字數據處理能夠提取的關鍵詞非常多,雖然步驟較少,但獲得關鍵字的速度較快。
2.3 用戶畫像繪制
在獲得標簽表后,就可以進行用戶畫像繪制工作。Python中的wordcloud詞云模塊算法是用戶畫像繪制功能的主要使用算法。它會根據用戶提供的文本和圖片自動將文本填充進圖片輪廓內的空白處,形成非常直觀的用戶畫像,且可設置多種自定義參數,如標簽字體、標簽大小、圖片輪廓顏色、生成圖片大小等,不同需求環境下的用戶畫像均可繪制。并且,在繪制完成后還可以將其保存為任何可用格式的圖片文件。將基礎圖片、字體、背景、畫像大小等必要參數設置完畢后就可進行繪制。
2.4 用戶畫像顯示
繪制用戶畫像并以圖片文件保存后,需要進行用戶畫像的展示。可以直接利用Python的圖片處理模塊PIL進行圖片懸浮窗口展示。用PIL模塊下的Image類中的open函數讀取圖像文件,再使用ImageTk類中的PhotoImage類形成可以被Python直接調用的圖片數據,最后創建一個全新懸浮窗口,在其中創建一個標簽控件,將其背景設置為需要展示的用戶畫像圖片,即可進行展示,如圖4所示。

圖4 懸浮窗口示例
3 實驗結果分析
3.1 實驗過程
3.1.1 用戶畫像配置環境
操作系統:Windows 10
編程語言:Python 3.7.2
開發環境:PyCharm
網絡爬蟲軟件:八爪魚采集器
3.1.2 實驗任務
繪制用戶畫像需要對互聯網上搜集到的數據根據其類型進行分類,之后分別進行分析,并對分析結果進行關鍵字提取。接著將關鍵字加工成為標簽,并輸入指定文本中形成標簽表。最后根據標簽表進行用戶畫像的繪制,并將其作為一般圖片文件進行輸出。全部任務可以整合至一個用戶畫像程序中完成。
3.1.3 程序流程圖
用戶畫像的所有實現算法可以在一個程序中實現,此項程序的核心功能是繪制個人用戶畫像。其主要運行流程如圖5所示。

圖5 程序流程圖
3.1.4 基本窗口UI設計
對于一個用戶畫像程序,簡單的操作是一個十分重要的要求。而簡潔又實用的窗口UI就是實現這種功能的好方法。由于此用戶畫像程序的主要操作功能為文字數據處理、數值數據處理、混合數據分離、用戶畫像繪制、用戶畫像展示這五個,所以UI界面需要將這些功能在一個界面中直觀地展示出來。Python中的tkinter模塊可以進行基本的UI設計與編寫,利用其中可以生成的標簽、文本框和按鈕等控件來實現所需要的UI。
3.1.5 程序具體運行流程
輸入需要分離的混合數據文件名,點擊“混合數據分離”按鈕,進行混合數據分離工作,完成數據分離后會有提示框跳出并指出分離出的文件的名稱。
輸入需要進行文本數據處理的文件名,點擊“關鍵字生成”按鈕,進行文本數據處理,程序完成處理后會有提示框跳出。
輸入需要進行數值數據處理的文件名和數值數據的主體名,點擊“kmeans聚類”按鈕。
會顯示本數值數據進行K-means聚類適合的簇數k。
重復(2)、(3)步驟,直至將所有需要進行分析的數據文件進行處理后,點擊“生成用戶畫像”按鈕,會將文件中用戶指定的肖像作為原材料進行畫像,完成后會提示任務完成。
點擊“顯示用戶畫像按鈕”,顯示生成的用戶畫像,如圖6所示。

圖6 用戶指定的肖像
經過用戶畫像的繪制與展示步驟后出現的圖片為用戶畫像程序的結果。它由人物輪廓與標簽組成,能夠直接反映用戶數據的大致信息與用戶的心理情況,如圖7所示。

圖7 用戶畫像展示
3.2 實驗結果與探討
3.2.1 K-means算法實驗結果分析
K-means聚類完成后,只使用其各屬性進行結果展示十分難以理解,與Python代碼可讀性強的特性不符。為了使K-means聚類分析的結果更加簡單易懂,可以使用Python中運算模塊Matplotlib下的Scatter函數來繪制散點圖。其繪圖方式基于數組,是數值分析結果展示的絕佳選擇。將獲取的數值文件的序號與數據本體分別作為x、y軸,并輔以不同的標記點與顏色,使得數據本體一目了然。同時使用同屬Matplotlib的plot函數進行單獨樣本點,在本實驗中也就是聚類中心的添加,以凸顯聚類結果。以下將不同K-means算法聚類結果用散點圖表示出來(見圖8—10)。

圖8 k=2時數據聚類散點圖

圖9 k=3時數據聚類散點圖
由散點圖中的實驗結果可以看出,k=2和k=4時的聚類效果都比k=3時效果要差,在k=2時,y值處在600~700的幾個點無法獨立成一個簇,使得其中一個簇的成員分布過于分散。而k=4時將最大的簇中的一些樣本點強行分割成新簇,反而使聚類結果過于復雜化。
這種情況的出現,是因為對于K-means來說,它的算法在一些方面存在著局限性[11]。
在選定初始聚類中心時,一般只能在樣本點中隨機選擇或者直接指定平均值,而這些值可能與理想位置相差甚遠,導致在開始聚類時就已經可能出現誤差。
由于K-means的簇數k值只能自選定,缺乏有效性和可檢驗性。

圖10 k=4時數據聚類散點圖
在樣本點中,經常出現距離較近但實際上數據相關性較低,或是距離較遠但數據相關性很高的多個樣本點。而K-means算法只是基于樣本點與類之間的距離進行劃分的,無法有效辨別此兩種樣本。
上文提到的情況就是K-means算法局限性中的k值自選定問題。為了解決這種因為不同k值而導致的聚類分析效果差異問題,本文采用了上文提到的最優間距來提前衡量不同k值下K-means聚類的效果[12-15]。以搜集到的購買商品價格記錄為例,計算出k值分別從2取到9時的最優間距,具體見表1。

表1 不同k值下的最優間距
根據多次計算,k值在超過樣本數量1/5后最優間距幾乎不再進行上下波動,這是因為簇過多,最優間距完全是隨其趨勢變化,開始穩定,導致實驗效果不準確。為了保證聚類效果,k值限定在樣本數量的1/5之內。由于此樣本記錄約有50個,故將k限制在10以下。根據上表,我們可以畫出k值與最優間距關系的折線圖(見圖11)。
由圖我們可以得出,當k值取3時,聚類的效果與平衡性之和達到了最大。因此可以確定,在正式使用K-means算法時將k值設置為3的聚類效果最好。

圖11 k值與最優間距的關系折線圖
3.2.2 用戶畫像繪制結果分析
用戶畫像中的標簽各式各樣,雖然均是從用戶數據中提取而來,但其是否真正起到描述用戶心理情況的作用,仍需要進行檢驗。因此,用戶畫像中的標簽是否有效,是用戶畫像繪制結果的衡量標準之一。關于文字數據的關鍵字提取部分,本文提出了“假高頻關鍵字”這個概念。它代表著那些出現概率高但毫無實際意義的關鍵字,實際上就是無效關鍵字。TF-IDF算法在完成關鍵字提取時,經常會出現無效關鍵字。將它們篩選掉是本文需要進行解決的問題之一[16]。
經常出現的“不與其他文字搭配的獨立數字”(以下簡稱“獨立數字”)就是假高頻關鍵字的代表[17-20]。因此在這里,我們將通過這種獨立數字的出現程度來衡量用戶畫像的誤差值。計算獨立數字出現的概率,首先需要讀取所有已經通過數據處理功能獲得的關鍵字。之后,需要對所有已經讀取的關鍵詞進行遍歷,找出其中出現的獨立數字,并統計其數量。因為獨立數字的取值范圍一般為0~999,所以可以將所有找到的符合關鍵字強制轉換為浮點數進行檢測。最后,計算獨立數字出現概率與所有關鍵字的比值,就是此次用戶畫像的誤差值。其核心公式為:,其中mis為誤差值,topw為關鍵字總數,count為獨立數字(或任何假高頻關鍵字)的總數。
在用戶畫像研究領域中,上文提到的停用詞篩選是比較常見的提高用戶畫像準確度的方法。在這里,我們使用極其容易出現獨立數字的淘寶用戶購買商品名稱記錄來統計此用戶數據的用戶畫像的誤差值[21]。
首先,分別在extract_tag方法中將采集關鍵字總數topK設置為40、30、20、10、5來計算獨立數字的出現次數,并計算出現次數與關鍵字總數的比值,即用戶畫像的誤差值。其結果如表2所示。
而如果我們使用停用詞篩選,向停用詞文本中逐個輸入0~1000內的數來將所有可能出現的獨立數字,將其作為停用詞進行過濾后,再執行extract_tag方法進行誤差值統計,其結果如下表所示,誤差值有了非常明顯的下降。因此,在用戶畫像的關鍵字采集時啟用停用詞篩選功能能夠有效提高用戶畫像標簽的有效性,進而提高用戶畫像的準確度(見表3)。

表2 誤差值統計表
同時,由于TF-IDF算法是基于詞在不同文本的出現頻率來進行關鍵字的提取,而這種算法勢必會忽略掉一些關鍵字,為了解決這個問題,本文還采用了基于有向有權圖pagerank的textrank算法進行了關鍵字補遺操作。它的在通過TF-IDF算法篩選并提取關鍵字時同時采用textrank算法進行并行提取,在將關鍵字作為輸入標簽表前,會將textrank算法篩選出的關鍵字與TF-IDF算法篩選出的關鍵字進行比較,相同的關鍵字就直接輸入標簽表,若出現未被TF-IDF算法而是被textrank篩選篩選出的關鍵字,就將其加入標簽表作為補遺,以此進一步提高用戶畫像的準確度。分別對文本進行TF-IDF算法和textrank算法的關鍵字分析,運行結果如圖12所示。可以看出,textrank算法篩選出的關鍵字與TF-IDF算法的有一定重合,而其不重合部分正好可以作為補遺部分。
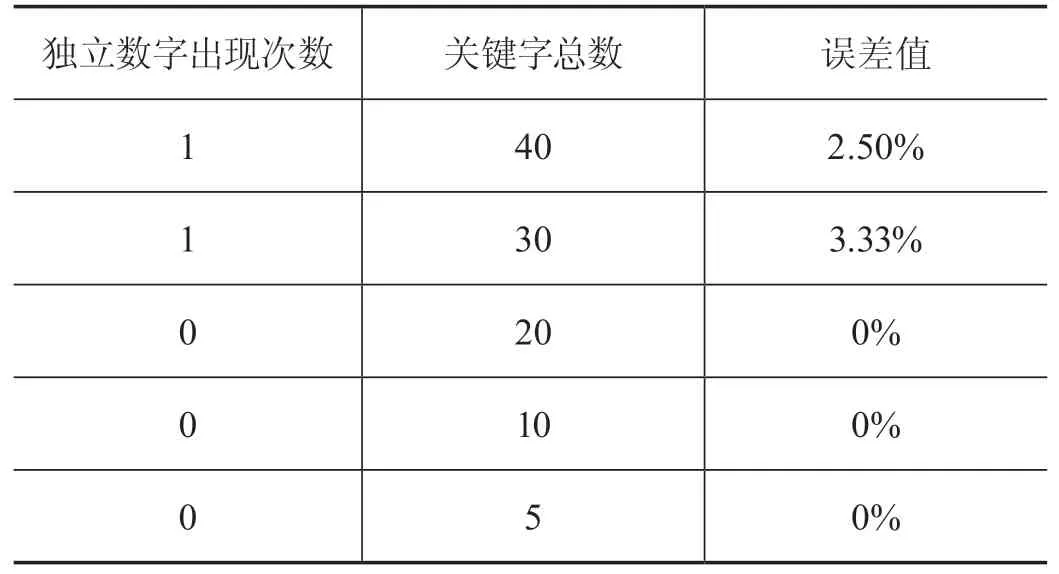
表3 停用詞篩選后的誤差值統計表

圖12 兩種算法運算結果對比
綜上所述,我們在進行用戶畫像時,可以使用停用詞文本對無效的關鍵字進行過濾,同時使用額外的關鍵字提取算法,如textrank算法進行關鍵字的補充,從而在進行用戶畫像時提高其準確性。
4 結語
隨著互聯網的發展和網絡用戶的增多,針對用戶個體的心理需求而進行服務的更新成了很多互聯網企業的挽留客戶的手段。而根據用戶網絡行為來進行心理刻畫也就因此變成了服務中的一個必要工作。用戶畫像作為個人心理刻畫的重要手段之一,一直在互聯網研究領域中占有重要地位。本文對用戶畫像的繪制方式進行了探討與實踐,并隊用戶畫像算法中的一些不足進行了研究與改進。本文在繪制用戶畫像的具體算法上采用了K-means算法和TFIDF算法來分別對數值文本和文字文本進行關鍵字提取和標簽生成,并設計通過wordcloud算法實現了用戶畫像圖片的生成。所有的算法均在PyCharm開發環境上使用Python語言實現,并通過tkinter模塊實現用戶界面操作。K-means算法存在著其k值上必須要事先由用戶指定的問題,而TF-IDF算法在關鍵字提取時有著無效關鍵字過多和關鍵字遺漏的問題。本文通過研究K-means算法中的k值與聚類間距的關系,而在聚類執行前算出最適合當前數據的k值,然后直接代入算法,優化了K-means算法的執行效率;同時采用停用詞過濾功能與textrank算法補遺,在TF-IDF算法執行完畢后對其獲得的關鍵字結果進行了優化,提高了標簽的有效性。
猜你喜歡
光明少年(2024年5期)2024-05-31 10:25:59
當代陜西(2022年4期)2022-04-19 12:08:54
International Journal of Nursing Sciences(2022年1期)2022-02-08 03:23:58
娃娃畫報(2019年11期)2019-12-20 08:39:45
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
