學術文本詞匯功能識別
——基于標題生成策略和注意力機制的問題方法抽取
2021-02-25 10:37:32程齊凱李鵬程張國標
情報學報 2021年1期
程齊凱,李鵬程,張國標,陸 偉
(1.武漢大學信息管理學院,武漢430072;2.武漢大學信息檢索與知識挖掘研究所,武漢430072)
1 引言
學術文本作為一種高信息密度的文檔資源,是科研工作者實現知識生產和知識組織的重要載體。隨著可獲取數字圖書資源的日益激增,“信息爆炸”和“信息過載”使得信息精準檢索和知識快速獲取越發困難[1]。即便是在面對一個相對較小的研究課題時,研究者也需要耗費大量時間和精力來完成相關文獻的查閱工作。為方便研究者索引文獻和獲取知識,現有的符號系統制定了類目繁多的分類標引框架[2],研究者通過使用統一普適的分類號來提高檢索效率。然而,以文獻為粒度單元的檢索策略,并不能滿足研究者逐漸增長的細粒度、導向性的知識快速獲取需求。Ribaupierre等[3]指出,科研人員信息獲取行為往往基于目標和任務驅動,對于文章中的問題、方法或結果等特定語篇內容更為關注。因此,學者們試圖在理解文本語義信息的基礎上實現詞匯粒度層面的文本標簽構建,為知識密集型領域的知識服務體系提供底層索引支持。
學術文本詞匯功能識別的目的是抽取出學術文本中表征的問題、方法、對象和工具等詞匯,其本質為信息抽取問題。命名實體識別(named entity recognition,NER)作為信息抽取(information ex‐traction,IE)領域中的重要下游分支,其任務形式與學術文本詞匯功能識別也較為相似。鑒于命名實體識別的相關基礎技術(如分詞、詞性標注、句法分析)都日趨完善,一種行之有效的策略是使用命名實體識別中的序列標注完成學術文本詞匯功能的自動識別[11,18]。事實上,隨著基于統計學習的有監督模型蓬勃發展,現有研究多將信息抽取問題轉換為機器可解的標簽判定問題或分類問題[4-5],如在詞匯功能識別任務中是判別每一個詞匯或詞匯組合是否屬于特定類別。然而,“人工標注語料+機器學習算法”模式下的信息抽取需要大規模、高質量的標注語料來完成有監督學習模型的訓練擬合,難以批量獲取的源數據以及復雜煩瑣的數據預處理,使得語料構建的成本不斷攀升,由此造成現有判別式識別方法在準確率、召回率的提升上頗受掣肘。
在此背景下,本文提出了一種基于深度學習和標題生成策略的學術文本問題方法識別模型,應用Encoder-Decoder架構模型讀取文本的語義特征,以自動文摘的任務形式生成能夠揭示文本中核心問題與核心方法的特定樣式標題,最終利用正則化實現問題方法的指代詞匯抽取。相對于傳統的詞匯功能識別,本文所提出方法將功能性詞匯的抽取識別轉化為特定形式的標題生成問題,具有以下優點:①可直接利用數據庫中所存有的大量規則樣式標題作為模型的訓練標簽,省去了最為耗時費力的標注工作,使得高質量、大規模的語料構建成為可能;②本文能夠從涉及多方法、多問題的學術文本中直接識別出具有對應關系的核心問題與核心方法,可為問題方法對應的知識庫構建提供支持;③相比于判別式分類和序列標注的任務形式,序列到序列的功能詞匯生成須在深層分析和理解文本語義的基礎上實現,與人類行為模式更為契合。
全文后續內容安排如下:第2節簡要介紹本文的相關研究現狀,第3節詳細描述基于標題生成策略的詞匯功能識別模型構建,第4節為具體的實驗過程以及實驗結果,第5節在全文的基礎上給出了總結。
2 相關工作概述
2.1 詞匯功能識別
在自然語言處理領域中,學者們通常從語法、語義和語用三個層面對語言進行建模。語法研究是通過對語言結構的表示來描述語言符號的支配規則,早期的自然語言處理研究也多集中于此[6-8],如分析句子主謂賓結構和詞匯間依存關系的句法分析便是經典任務之一。在過去的二十余年里,語法層面的自然語言處理研究取得了較大發展,相關技術在諸多領域中也被廣為應用[9-10]。隨著統計學習和表示學習興起,如何在語義和語用層面表征語句的字符含義以及理解當前語境下所表達的內容信息,成為了學者們的關注熱點。
詞匯是語言構成中最小的基本語義單元,詞匯功能識別的目的則是從語義和語用的角度探究詞匯在文本中所承載的功能角色[18]。Kondo等[11]于2009年使用CRF(conditional random field)模型對科技文獻標題中的詞匯進行“領域(head)”“目標(goal)”“方法(method)”及“其他(other)”的類別判定,根據得到的方法/技術來描繪特定領域內技術的演化路徑和發展趨勢。隨后Nanba等[12]進一步將研究點聚焦于“技術(technology)”識別,應用SVM(support vector machine)方法在專利文本上取得了0.431的召回率和0.545的準確率。針對專利分析,Trappey等[13]及Choi等[14]使用“技術-功效”矩陣[15]實現專利文本中前沿技術的識別挖掘。Gupta等[16]使用句法模板從科技文獻中識別出“話題(focus)”“技術(technique)”及“應用(application)”。在前者基 礎上,Tsai等[17]對Bootstrapping算法進行了改進,使得計算量降低的同時提升了準確度。程齊凱[18]在已有文獻的基礎上對詞匯功能的概念進行了界定,詞匯或術語在文本中所承擔角色,并構建了較為完善的學術文本詞匯功能框架。此后,李信等[19]從語義理解的角度出發,依據程齊凱[18]所構建的詞匯功能框架設計和實現了一個基于詞匯功能識別的科研文獻分析系統。劉智鋒等[20]將詞匯功能研究的判別對象限定為關鍵詞,制定了計量學領域關鍵詞語義功能分類框架:領域、對象、主題、方法和數據,并基于該框架構建了關鍵詞語義功能標注數據集。
總而言之,詞匯功能識別的相關研究仍處于初步探索階段,出于研究目的和功能定義等主觀因素,學者們并未能夠就詞匯的具體功能類別劃分達成一致。除此之外,客觀上存在的諸多制約也使得詞匯功能的統一顯得殊為不易。例如,每個學科或領域中均可能存在獨有所屬的功能類別,窮盡各個領域中的所有類別需要極大的工作量;再者,明確各個功能類別的劃分界線,以及發現各個類別間的潛在上下位關系,也顯得極其困難。通過對上述研究的梳理分析發現,盡管學者們在詞匯功能類別的具體劃分上不盡相同,但對于“問題”和“方法”的功能類別卻表現出了一致的認同性。這是由于“問題驅動”在科學的進步乃至研究工作的推進中均扮演了關鍵角色。因此,本文沿用程齊凱[18]所提出的詞匯功能劃分體系,將學術文本詞匯功能分為領域無關詞匯功能和領域相關詞匯功能。其中,領域無關詞匯功能僅包含兩類:問題和方法。研究問題與研究方法作為科技文獻的核心知識單元,本文將聚焦于學術文本中領域無關詞匯功能——研究方法和研究問題識別,通過采取標題生成策略和引入注意力機制的方法實現學術文本問題方法的指代詞獲取。
2.2 標題生成及作用機理
標題生成,是指用限定長度的單句對既定的信息內容進行概括表示,信息對象包括且不限于文本[21-22]、圖像[23]以及視頻[24-25]等。學術文本的標題生成可理解為全文層面的自動文摘任務,即將全文信息高度凝練為一定形式的規則短句,使得其能夠扼要表示文本的核心研究內容。依據生成策略,自動文摘可分為抽取式和生成式兩種。抽取式是對文檔中的詞或句進行重要性排序[26],生成式則是在理解文本語義的基礎上實現對原文的復述[27]。針對句子級層面的文本摘要任務,Nallapati等[28]與Ayana等[29]分別使用抽取式和生成式方法進行了探討。隨著序列語言模型和NLP技術的日趨成熟,生成式文摘在語句可讀性和關鍵信息完整性上得到顯著提升,seq2seq+attention組合方案也逐步成為生成式文摘中的經典模式[30-31]。鑒于生成式文摘的思想和過程與人類的行為模式更為貼近,本文采用基于seq2seq架構的生成式模型實現學術文本的標題生成,并引入注意力機制以優化標題的生成效果。
標題作為一篇文獻的概括性描述,具有表達作者寫作意圖及文本主旨核心的重要作用。如Hoey所述,任何語篇中的閱讀和寫作過程都可看作是作者和讀者之間一種交流互動,標題為該互動提供了一種 可 視 化 對話窗 口[32]。Paiva等[33]與Jamali等[34]的研究指出,標題中涵蓋研究問題或研究結果的文獻傾向于得到更高的閱覽量和被引量。這是由于在現存形式的文獻檢索中,系統所返回的查詢結果多表現為相關文獻的標題羅列展示,其中讀者試圖通過標題信息預見作者將要回答的問題。在這一作用機理下,將研究問題和研究方法信息列入標題中,以直觀揭示本文主旨核心的做法在當前并不鮮見。在現有的期刊數據庫中,存在大量標題樣式為“Re‐search of A based on B”或“基于A的B研究”的期刊論文。考慮到這種規則特征在某種意義上是對文本研究內容的映射,Kondo等[11]利用該思想在英、日文獻的標題上實現了“領域(head)”“目標(goal)”和“方法(method)”等功能性詞匯的抽取。此外,采用標題生成的方式對學術文本中的關鍵信息予以揭示的研究也不乏先例。例如,程齊凱[18]闡述了標題生成策略在文檔級詞匯功能揭示中的作用機理;Putra等[35]則提出了一種涵蓋文本研究目的(research purpose)及研究方法(research method)的標題生成模型,以供作者在擬定標題時作為備選參考。
本文借助標題生成的思想來完成問題方法描述詞匯的獲取。值得注意的是,Putra等[35]與本文的任務目標較為相似,但在具體實驗方法上與本文有較大區別,其在數據預處理中需將句子進行目標(AIM)、方法(OWN_MTHD)和其他(NR)的類別標注,本文參考程齊凱[18]的策略,利用現存有的規則標題直接完成seq2seq模型輸出標簽的獲取。
3 研究方法
為了解決學術文本中詞匯功能的自動識別問題,本文提出了一種基于標題生成策略的神經網絡模型,通過將文本摘要轉化成規則標題的形式,實現學術文本中研究問題與研究方法指代詞的獲取。簡而言之,本文的研究任務可定義為:給定一個長度為m的文本序列T={s1,s2,…,sm},生成長度為n的句子序列S={w1,w2,…,wn}(m?n),最終從序列S中抽取出所需的問題字符串wi和方法字符串wj。
整體研究過程如下:①數據獲取及預處理。包括數據的采集、清洗及標注等工作;②標題生成模型構建。采用基于Encoder-Decoder架構的語言序列模型,在理解文本語義的基礎上,實現輸入文本序列的摘要化,生成既定形式的規則標題;③問題方法指代詞抽取。通過標題進行分詞、詞性標注及句法分析,利用規則匹配從中抽取出能夠描述文本核心研究方法與核心研究問題的功能性詞匯。
3.1 數據獲取及預處理
現有基于有監督學習的詞匯功能識別,偏好于采用分類或序列標注的方法來完成詞匯的功能類別判定[17-18],即通過在標注數據集上進行有監督訓練,以實現問題方法等標簽的功能判定。這一策略的缺點:必須為學習算法準備一定數量的高質量訓練數據集,要求能夠準確、完備標注出科技文獻中問題方法等功能性詞匯。同時,對于涉及多問題方法的文獻,還需考慮該問題和方法究竟是作為文中的主要研究對象出現,還是僅僅作為參考背景而提及。
大規模的科學文獻問題方法標注數據并不容易獲取。首先,現實場景中的開放式陳述使得研究方法和研究問題具有諸多變體和表達形式;其次,需要在對文獻仔細分析的基礎上才能完成核心問題與核心方法的標注工作;最后,必須有多名行業專家參與數據標注,以避免文檔主題的單一性。為克服訓練數據的獲取難題,文本提出了一種將信息抽取問題轉化為標題生成問題的詞匯功能識別方法,從待識別的全文或者摘要中生成類似于“基于[方法]的[問題]”的樣式標題,繼而間接識別出能夠描述學術文獻中核心問題和核心方法的功能性詞匯。
在中文學術文本中,存在著大量的類似于“基于X的Y研究”樣式的標題。與此相對應地,ACL數據庫和ACM數據庫收錄的論文中也存在著大量類似“X based on Y”“X using Y”“Y algorithm based X”的樣式標題。這些標題在一定程度上明確揭示了論文的核心問題和核心方法。圖1給出了一個標題與摘要的標注示例。在所示論文中,標題的形式為“基于X的Y方法”,標題文本給出了該文檔的核心問題和核心方法,分別是“微博情感分類”和“監督學習”,這些詞匯或者詞匯的同近義詞也同時在摘要中出現。
基于上述分析,本文將核心問題和核心方法的識別問題轉化為利用摘要(或全文)生成“基于X的Y研究”這一標題的問題。相對于前一問題,后一問題更容易解決,且后者的訓練數據更容易獲得。在學術數據庫中,存在著大量標題形似“基于X的Y”的論文,這些論文的標題和對應的摘要(或全文)構成了標題生成模型訓練天然存在的標注數據。
3.2 基于Encoder-Decoder的標題生成模型描述
Encoder-Decoder是seq2seq模型中的一種經典架構,其由三個部分組成:Encoder、Decoder以及連接兩者的中間狀態向量。其中,Encoder模塊負責對輸入信號的特征讀取,將所輸入的文本序列編碼成一個固定大小的狀態向量W。待Encoder逐步完成輸入的編碼操作后,將包含全部特征信息的W傳給Decoder,再通過Decoder對狀態向量W的學習來進行輸出。

圖1 論文標題與摘要的對照示例
在圖2所示的經典Encoder-Decoder模型結構圖中,每一個box代表了一個語義讀取單元(通常是LSTM(long short-term memory)或 者GRU(gated recurrent unit)),用以捕獲輸入序列的語義信息。待得到包含序列語義特征的中間狀態向量W=F(A,B,C)后,由Decoder模塊對W進行解碼操作,在每個時間步生成當前狀態的語義輸出X、Y、Z,其中,X=f(W),Y=f(W,X),Z=f(W,X,Y)。

圖2 Encoder-Decoder模型
學術文本的標題自動生成是在Encoder-Decoder架構基礎上完成,具體模型如圖3所示。輸入層為預處理過的學術文本序列,對于每一條摘要為{S1,S2,…,Sm}的數據語料,均對應標簽為{基于…的…}樣式的規則標題;在嵌入層中,使用word2vec方法[36]對輸入層中文本進行向量化表征,完成字符轉向量的操作;隨后,將該特征向量傳至由雙向LSTM所構成的Encoder層中并實現輸入信息的語義編碼,通過LSTM中的前后向迭代捕獲文本中的潛在語義信息。此外,為力求文獻摘要與生成標題間信息的充分交互,本文在編碼層與解碼層間引入了注意力機制,該機制可有效解決生成式文摘中的信息冗余問題,并廣泛應用于seq2seq架構神經網絡模型中[30]。本文通過使用注意力機制學習不同詞位在標題生成中的權重信息,以減少因文本字符長度增加而造成的細節丟失。最終,由同樣是雙向LSTM所構成的Decoder層對中間層向量進行語義解碼,并在全連接層輸出能夠揭示文中研究問題與研究方法的規則樣式標題——基于XX的XX。
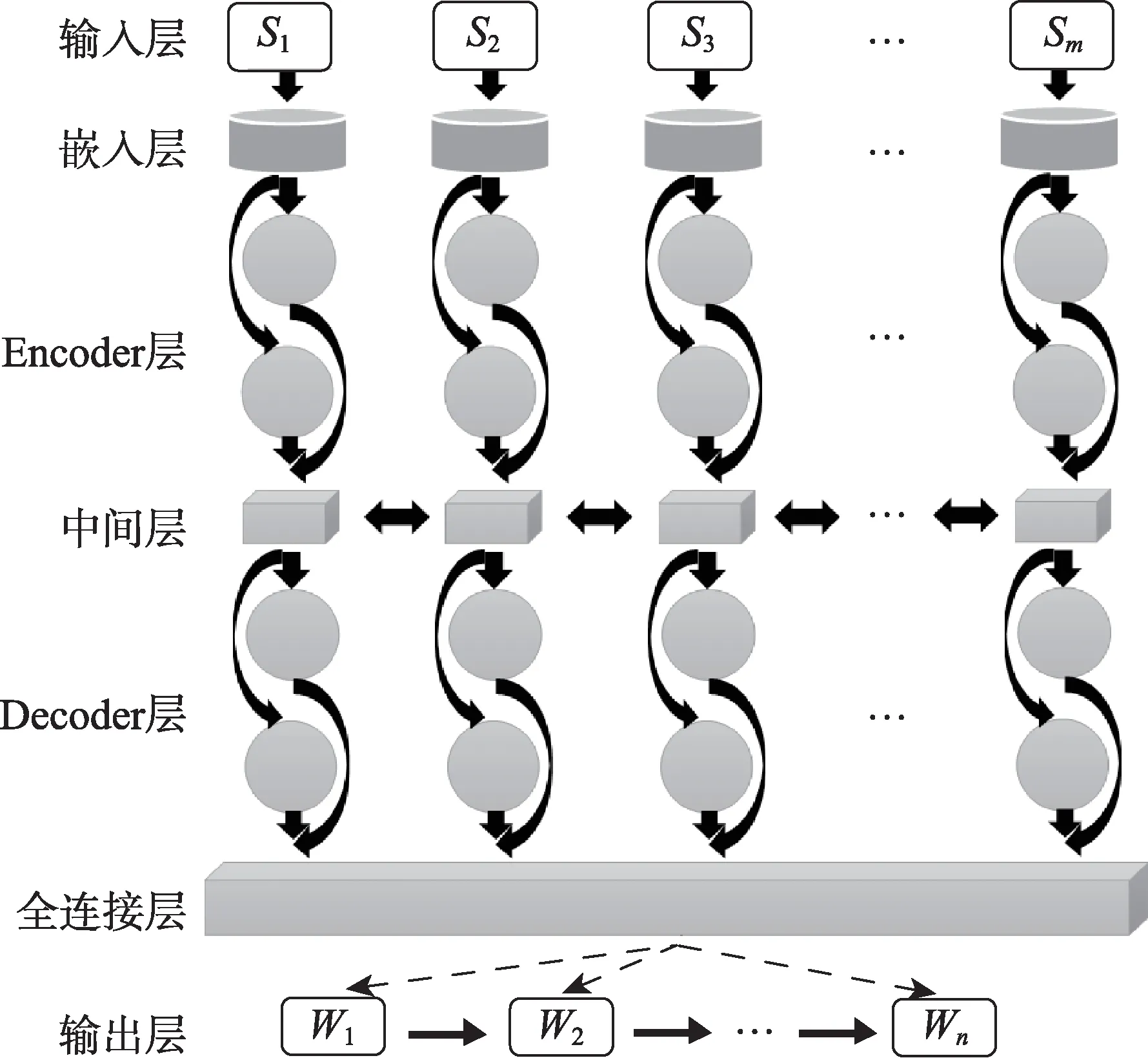
圖3 基于Encoder-Decoder的標題生成模型
以上為使用seq2seq Encoder-Decoder模型實現標題生成的概要流程,這一架構的序列語言模型在諸多其他任務上也都取得了較好的效果。但其也存在一定弊端:①Encoder將輸入編碼為固定大小狀態向量的過程實際上是一個“信息有損壓縮”的過程,轉化向量過程中信息的損失率和信息量的大小呈正相關。②隨著sequence length的增加,較長時間維度的序列輸入會引起RNN(recurrent neural net‐work)模型的擬合中出現梯度彌散。針對上述問題,本文采用信息密度更為富集的摘要代替全文作為輸入,并引入Attention機制加以輔助解決。盡管如此,模型效果仍有巨大的提升空間,后續研究中將進一步引入關鍵詞特征信息進行問題與方法的識別。
3.3 生成標題的后續處理
在實現特定樣式標題的生成后,本研究需要對所得到的生成結果進行分詞、句法分析以及詞性標注等后續處理,最終應用基于模板抽取的方法從標題中識別出相應的問題方法指代詞,完成學術文本中問題方法詞的識別獲取。
表1 給出了所生成標題中頻次最高的5種組合形式,以及對應的問題方法詞抽取規則。其中,對于形式為“基于A的B的C”的標題較為特殊,涉及3個對象主體。本文依循邏輯推理將A與C認定為該文的核心研究方法和核心研究問題(A和B是方法問題對應關系,B和C是方法問題對應關系)。此外,通過表1中的統計結果可發現,本文所提出的標題生成模型能夠較好的學習標題的樣式規則特征,使得所生成標題能夠滿足本文的任務需求。最后,為避免因不同抽取規則造成的實驗效果波動,依據生成標題的統計結果,選用占比最高(97%)的規則模板“基于A的B”統一完成所有生成標題中的問題方法抽取,即視A為文中的研究方法,B為研究問題。
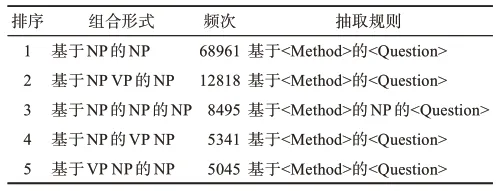
表1 標題統計及問題方法抽取規則
4 實驗與結果分析
4.1 實驗環境
本研究的所有實驗均在表2所示的環境配置中完成。
表2 實驗環境
4.2 實驗評價及指標
本文是在生成特定樣式標題的基礎上,應用規則匹配實現學術文本中問題方法指代詞的識別獲取。因此,本次實驗及評價涵蓋兩方面:標題的生成質量和問題方法的命中效果。由于當前研究多為基于有監督學習的判別式分類,少有采用生成式的策略實現詞匯功能的自動識別,故在文中并未設置對照實驗。
為了能夠對標題的生成質量以及問題方法的命中效果進行全面評估,本文共選取了四項評價指標:BLEU、Turing test、Exact match和Unigram。
Exact match是檢索領域中一種常用的關鍵詞匹配模式,要求匹配項之間的字符完全相同;Uni‐gram是在單個字符層面計算匹配項中出現相同字符的比率;BLEU是一種基于N-gram均值的相似度計算方法,被廣泛應用于機器翻譯評價中[37];Turing test則是一種驗證機器是否具備人類思維的著名測試,旨在消除機器與人類之間的模糊性,在本文中用以衡量標題生成模型的學習能力[38]。
具體而言,在標題生成質量評價上,使用BLEU和Turing test在語句級層面評測所生成標題的信息度和流暢度;在問題方法命中評價上,使用Exact match和Unigram在字符級層面評測問題與方法的命中率。
4.3 實驗數據集及參數設置
本文的實驗數據來自百度學術和Google學術,選取工程技術、計算機和圖書情報等多個領域的2000—2018年中文學術期刊論文共574752篇。經規則過濾后,得到標題樣式為“基于A的B”中文期刊文獻共計163367篇(占比約28%),其中每篇文獻包含文章標題及摘要字段。對數據集亂序處理后從中等比例隨機抽取出4000篇文獻作為測試集,其余則作為訓練集用于模型擬合。
訓練參數設定上,本實驗選擇生成式文本摘要任務常用的預設初始值并經多輪迭代調優后:神經網絡隱藏層維度為128;嵌入層向量化維度設為300(未使用預訓練詞向量);詞匯表(Vocab)mini_count為32;字符最大長度為400;訓練最小批量為64;迭代epoch次數為100,學習率采取衰減策略(初始值為1e-5,每訓練500步衰減5%)。
4.4 實驗結果及分析
4.4.1 標題生成質量評測
語句層面的標題生成評測需要同時考慮詞位信息和語義信息,如標題的可讀性和信息還原度。因此,本文選擇BLEU和Turing test兩種指標對標題的生成質量予以量化評價。
1)BLEU
BLEU的思想是判斷源標題與生成標題的相似度,其原理是計算兩個標題中N元共現詞的頻率,并依據N值(N=1,2,3)進行加權求和。一般而言,1-gram用以表示對原文信息的還原度,2-gram和3-gram則反映語句的流暢性和可讀性。BLEU具體計算公式為
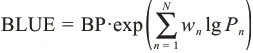
其中,BP(brevity penalty)為引入的懲罰因子,用于修正N-gram匹配值與句子長度間的負向關系;Pn為N-gram下的計算得分,wn為其對應權重值,通常為1/n。在本次BLEU測評中,選用測試集中的全部數據共計4000條,用以與標題生成模型的結果進行BLUE匹配計算。表3為BLEU測試的詳細結果。

表3 BLEU測試結果
由表3分析發現,1-gram、2-gram和3-gram的結果呈依次單調遞減狀態:1-gram最高,為0.640;3-gram最低,為0.390。然而,由于原標題與生成標題依循相同的樣式特征——即均含有“基”“于”和“的”這三個特定字符,因此,1-gram結果的單獨參考意義相對有限。通過差值比較分析發現,即使在1-gram結果略顯“虛高”的情況下,標題在2-gram上的測試表現較1-gram并未出現較大程度的下滑,1-gram、2-gram及3-gram的測試成績以相對平滑的幅度層級遞減。該實驗結果表明,由本文所設計的標題生成模型能夠在信息完整度與語句流暢性上較好的滿足需求。
2)Turing test
Turing test最初被用于判定機器能否表現出與人等價或無法區分的智能,在本文中用于衡量標題生成模型在模擬人類寫作上的學習能力。具體而言,本文采用文獻[38]中的Turing test測試方法:為每一段摘要配對兩個標題——原文標題和機器生成標題,在未告知的情況下由三名博士研究生依據摘要內容進行最優標題投票,選擇票數≥2的標題作為最終結果。
在表4所示的Turing test實驗樣例中,標題1和摘要均為原文內容(由人類撰寫),標題2則為對應機器生成結果。限于人工評測方法的既有缺陷,本次Turing test實驗只隨機選取了200條數據作為測試集,具體結果如表5所示。從表5結果可發現,在大多數情況下(65%),模型生成標題的質量在一定程度上能達到原文水準,少部分情況下表現更優(28%)。該實驗結果表明,基于Encoder-Decoder架構的seq2seq模型能夠較好的學習人類在標題上的行書特征,可為學術文本中核心問題與核心方法的識別研究提供有力支撐。

表4 Turing test樣例

表5 Turing test實驗結果
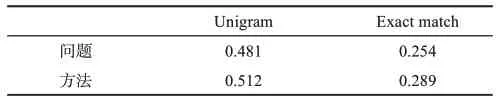
表6 問題方法命中評測結果
4.4.2 問題方法命中評測
問題方法的命中效果評價需在字符級和詞匯級層面,對得到的問題方法詞進行真實值匹配計算。因此,本文選擇Exact match和Unigram作為評測指標,以代替傳統抽取式方法中所選用的準確率、召回率和F1值。問題方法的命中評測結果如表6所示。其中,使用Unigram在單個字符粒度層面測試問題方法詞的命中效果;使用Exact match測試模型能夠在多大程度上對原標題中的問題方法詞予以還原。
從表6發現,更為嚴格的匹配規則使得Unigram與Exact match的實驗結果間存在顯著差距。其中,Unigram在問題方法上的結果均值為0.497,Exact match的結果均值為0.272,這表明模型具有以相同字段命中問題和方法的能力。此外,問題和方法在命中效果上的表現也不盡相同:方法的命中均值為0.401,高于問題的命中均值0.368。經分析發現,其原因是問題和方法在語言層面上的描述差異。通常而言,研究方法相對于研究問題具有更好的表述規范性。例如,對于計算機領域中大多數技術方法,往往能找到既有的約定術語或通用名稱,模型在迭代學習后就能夠較好的擬合其概率分布。而對于研究問題,開放性的語言組織使得問題的描述形式顯得更為多變和復雜,使得其特征學習更為困難。
4.4.3 綜合評測
鑒于以上評測方法均存在一定缺陷,本文采用了量化評分的方式對生成標題的質量以及問題方法的命中進行綜合評價。Unigram和Exact match無法識別問題和方法的同義詞及變體,如SVM與支持向量機雖指向同一實體,但Unigram與Exact match兩種指標均無法對其匹配。同時,Turing測試中無法指定可依循的評測規則,摻雜了較高主觀性。因此,本文從五個層面(表7)對標題的生成質量和問題方法的命中效果進行綜合評測。具體流程如下:①從測試集中隨機選出500條數據,每條數據包含標題和摘要字段;②將500條數據中的原標題均替換為對應的機器生成標題,并在未告知的情況下由三名博士研究生進行獨立評測;③要求在理解摘要語義的基礎上完成每個待測標題的量化評分;④獨立重復多次實驗,對結果累計求均值。綜合評測的最終結果如圖4所示。
從圖4中生成標題在得分序列上的分布可知,生成標題的評測結果集中于3~5分區間(70%)。其中,能夠準確描述文本問題或方法的高質量標題(分值≥4)占比達到46.4%。該結果表明通過深度學習方法的應用,本文所提出的基于標題生成策略學術文本問題的方法識別具備相當的可行性和有效性。

表7 綜合評測評分細則

圖4 綜合評測結果
由于本文的目的是通過生成特定樣式的規則標題實現文本中核心問題與核心方法的獲取,與傳統標題生成任務[29]或文本摘要任務[31]具有一定區別,因此,本研究并未與之進行對照實驗。從表8所示的結果樣例可發現,對于具有一定行文范式的摘要而言,通過大規模樣本的學習,模型能夠較好地捕獲摘要中的關鍵語義信息,繼而生成限定內容及形式的目標標題。
5 結語
學術文本詞匯功能識別的目的是抽取文本中具有特定意義的表征詞匯。受限于數據集等諸多因素的制約,目前基于有監督學習的分類式識別方法存在識別準確率低、召回率有限和泛化性差等問題。因此,本文提出了一種基于深度學習和標題生成策略的文檔級學術文本詞匯功能識模型,將問題方法指代詞的抽取問題轉化為特定形式的標題生成問題,在規則標題的基礎上實現特定功能詞匯的生成和獲取。實驗結果表明,通過深度學習方法的應用,標題生成策略能夠有效識別出描述學術文本研究問題和研究方法的功能性詞匯。
本研究仍然存在諸多不足:①學術文本的詞匯功能是對詞匯在學術文本中角色的定義,包括且不限于問題、方法、領域、工具以及指標等,本文為簡化處理,僅僅選取了學術文本中最為核心的問題和方法作為本次的研究對象,后續將采用其他特征和策略實現更為廣義的詞匯功能識別;②本文僅使用了LSTM、GRU等模型,未將BERT、Transformer等模型應用于文本信息的語義表征,這些模型的引入能進一步提升識別的效果;③模型僅僅使用了學術文本中的標題和摘要,在語義建模中未能加入關鍵詞、引文網絡、作者行文偏好等信息,這些信息的引入對提升模型的效果是有潛在價值的。后續研究將在更大的數據集上開展,應用Transformer、強化學習等表現力更強的深度學習方法,通過分析文獻的類型(技術研究論文、應用研究論文、綜述)、引文網絡、作者偏好等信息,實現更加精確和魯棒的詞匯功能識別。

表8 機器生成標題結果樣例
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
電子制作(2018年18期)2018-11-14 01:48:06
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
