面向AI的語音數據采集服務平臺的設計與實現
2021-02-26 16:53:56王子韻鈕辰洋
電腦與電信 2021年11期
王子韻 鈕辰洋
(中國傳媒大學信息與通信工程學院數字媒體技術系,北京 100024)
1 引言
人工智能的細分領域眾多,比如大家最為熟知的視覺人工智能與語音識別[1],其中語音識別在近幾年發展迅速,特別是深度神經網絡的出現[2],使語音識別正確率達到了98%以上,語音識別也在語音輸入、語音機器人[3]、智能客服[4,5]等眾多領域大顯身手。識別能力方面,以科大訊飛為例,除支持中文普通話和英文外,還支持35 個語種、24 種方言和1 個民族語言的語音識別。
語音識別中一大難點是方言和少數民族語音識別[6]。海量的語音數據是語音識別模型獲得高識別率的關鍵。由于中國地域遼闊,方言眾多,每個省份都有可能有多種方言口音,同種方言的個體發音也有所區別,如果單靠人工主動收集各種方言語音數據,難度極大,數據覆蓋面和樣本分布很難做到均衡。因此,如何有效拓展語音數據收集渠道,擴大數據覆蓋范圍,如何對數據進行高質量的標注[7],從而獲得精準的有價值的語音數據也是目前語音AI亟待解決的問題。
本文設計開發的面向AI 的語音數據采集服務平臺,旨在提供萬眾參與的語音,特別是方言語音的數據采集方式,平臺采用游戲方式采集語音數據,同時設置競爭性任務對語音數據進行交叉校驗和標注,提升語音數據采集的質量和可用性。同時,平臺具備定制化的語音采集功能,可以實現定向采集某種方言語音數據,使語音數據采集更加方便、高效,同時降低企業的數據采集與標注成本。
2 語音數據采集服務平臺的設計
2.1 功能模塊設計
語音AI 數據采集與服務平臺總體分為三個功能子模塊,包括基礎服務、語音數據收集服務、數據集服務。
基礎服務模塊用于提供用戶管理、數據標簽管理、公告管理、客服交流、積分管理等基礎服務,如圖1所示,以提供系統的基礎數據管理功能,保證系統基本功能的正常運行。
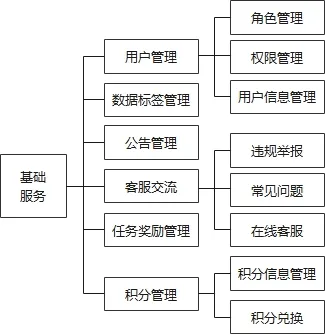
圖1 基礎服務模塊功能
語音數據收集服務的目的在于以較低的成本獲取較高價值的語音樣本數據。該模塊又可分為語音數據收集、語音數據管理兩個子模塊。
數據收集模塊提供的主要功能有:語音游戲、定制任務、出題答題、交叉糾錯和數據標注。用戶可以參與系統提供的各種有趣的游戲,結交朋友,領取任務,賺取積分與獎勵。在用戶參與游戲過程中,后臺采集和存儲用戶的語音相關數據,例如方言音頻、方言文字等信息,對其進行保存和處理,是語音數據的主要來源。
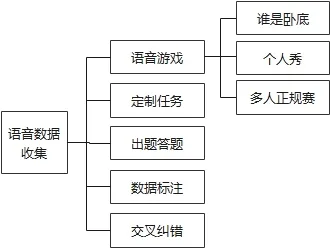
圖2 語音數據收集服務模塊功能
語音數據管理模塊提供語音數據相關的管理功能,包括語音數據保存、審核、打包下載等功能。
2.2 語音游戲設計
2.2.1 誰是臥底
該語音游戲圍繞具體文字來設計游戲規則,通過游戲獲取語音數據,游戲規則如下:系統隨機匹配7 個不同地區玩家,然后隨機選擇6個相同詞語和1個發音相近詞語(用方言讀不容易分辯,如餃子、轎子)給7個玩家,玩家每輪都用各自方言讀出詞語,結束后投票,票數最多的出局,如果臥底到最后一輪則臥底獲勝。游戲過程如圖3所示。
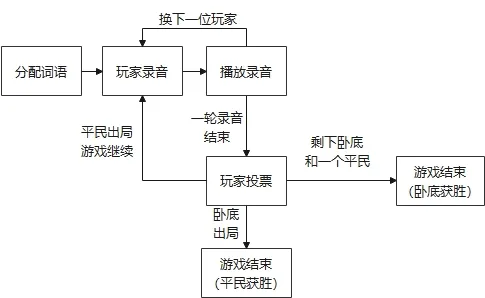
圖3 語音游戲“誰是臥底”的基本流程
2.2.2 多人正規賽
“多人正規賽”的設計目標是產生帶有精準標簽的語音數據,減小人工審核和管理的壓力。
游戲題目由后臺決定,因此后臺可以收集任意想要的語音數據。在游戲過程中,后臺將文字題目發給出題錄音玩家,該名玩家查看題目后,錄音上傳語音數據,后臺保存語音數據和標簽,同時將題目中的文字打亂后發送給其他玩家,玩家擊敗對手贏取積分,兌換獎勵。游戲流程如圖4所示。
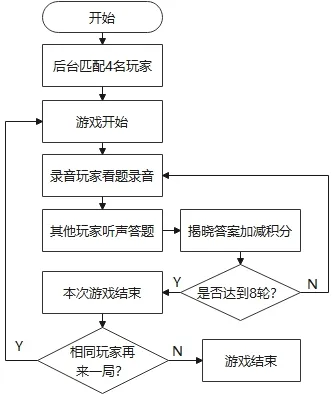
圖4 語音游戲“多人正規賽”的基本流程
2.2.3 個人秀
語音游戲“個人秀(方言秀)”的主要功能是收集同一段文本所對應的不同的方言數據,具體功能設計如下:用戶可以主動發起一個話題,格式不限,可以是文本、歌曲、古詩等等,并為其配音,經過審核后展示出來,供其它用戶欣賞,其它用戶可以發起新的話題,或者為已有的話題配音,以此獲得該段文本所對應的不同方言數據。
2.3 其他主要功能
2.3.1 出題答題
出題答題的模式是用戶出題,用戶答題。用戶不僅可以回答來自五湖四海的方言題目,還可以自己出題,讓其他的用戶回答。這樣可以豐富方言題目類型及方言題庫,增加游戲的新鮮度,同時提高用戶參與的積極性和游戲的趣味性,增強用戶黏性。
2.3.2 交叉糾錯
交叉糾錯任務要求任務領取者對他人發送的音頻和文字做審核,檢查音頻中的方言是否正確,也可以在審核過程中上傳正確的語音數據,目的是為了解決大量語音數據審核的問題,通過有效的獎勵機制讓大量用戶參與到數據審核工作中,利用糾錯功能可以對數據庫中還未審核的方言語音數據進行人工審核,提高語音數據及其標注數據的可靠性。
2.3.3 數據標注
每份數據需要多種不同的標注才能具備相應的價值。有效標注越多,越準確,數據具備的價值將會越高。系統通過完善用戶的基本信息,將用戶通過游戲和活動所產生的數據自動加上盡可能多的有效標注,比如方言類型、地域、性別等。同時系統為用戶提供更改數據標注的服務,用戶對數據的標注有異議,可以更改數據的標注。平臺為積極參與數據標注工作的用戶提供獎勵。
2.3.4 定制任務
可定制的數據采集任務能夠滿足客戶的個性化語音數據采集需求,可以按照語音類別、地域、目標人群等屬性設置定制語音采集需求。系統也會根據具體的屬性設置將任務定向發放給滿足要求的用戶進行語音數據采集。
3 語音數據采集服務平臺的實現
3.1 開發框架
3.1.1 Vue.js框架
Vue.js是一種漸進式UI設計框架[8],它提供了簡易的、響應式的數據模型與視圖層之間的狀態管理機制,當數據模型狀態發生改變,視圖就會做響應式更新。Vue的核心組件只關心視圖層,在本系統中主要用于Web頁面的開發。
3.1.2 Spring Boot
通過簡化配置,Spring Boot使得Spring應用的搭建更為簡單,能夠更好地解決之前存在的多個框架依賴包之間的版本沖突問題[9]。開箱即用、約定優于配置是Spring Boot 框架的兩個重要策略。Spring Boot中嵌入了Tomcat、Jetty等服務器容器,不用單獨安裝web服務器就能運行。
3.1.3 Spring MVC
Spring MVC 框架是一款輕量級的、優秀的MVC(Model,View,Controller)框架[10]與Spring框架無縫集成,具有優越的性能,是業界主流的Web開發框架。
Spring MVC 中的控制器負責接收請求,并調用相應的模型進行處理,最后將處理結果返回。控制器可以調用相應的視圖組件對處理結果進行渲染,并將其通過響應返回給客戶端。Spring MVC 的組件結構具有高度可配置性,具有很好的靈活性和可擴展性,開發效率較高。
3.1.4 MyBatis
MyBatis是一種基于Java的數據持久層框架,簡單易學,不依賴第三方組件,能夠將SQL 語句與代碼分離,提供業務邏輯和數據訪問的邏輯分離,使得系統設計更加清晰,可維護性更好。
3.2 技術框架設計
平臺技術框架設計如圖5 所示。客戶端分為Web 客戶端、Android手機APP和微信小程序。客戶端與服務端以HTML、XML和JSON三種數據格式與服務端進行數據通信。
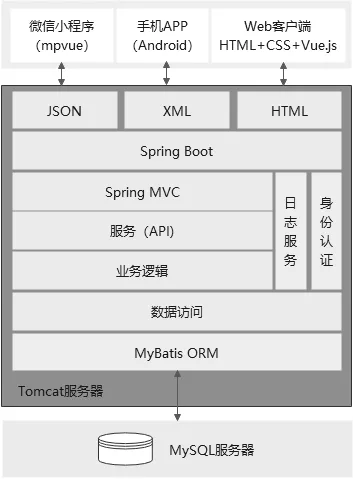
圖5 平臺采用的技術框架
服務端使用Spring Boot、Spring MVC 等技術進行搭建,通過MyBatis完成數據持久化訪問,數據保存在MySQL數據庫中。服務端應用部署在Tomcat服務器上。
3.3 數據庫設計
數據設計與系統的功能需求及其數據需求密切相關,語音數據采集服務平臺的功能較多,設計完成了用戶基本信息表、出題記錄表、答題記錄表、多人賽人員匹配表、多人正規賽隊伍信息表、多人正規賽輪次信息表、語音采集數據表、積分明細表等25個數據庫表。其中語音采集數據表的設計如表1所示。
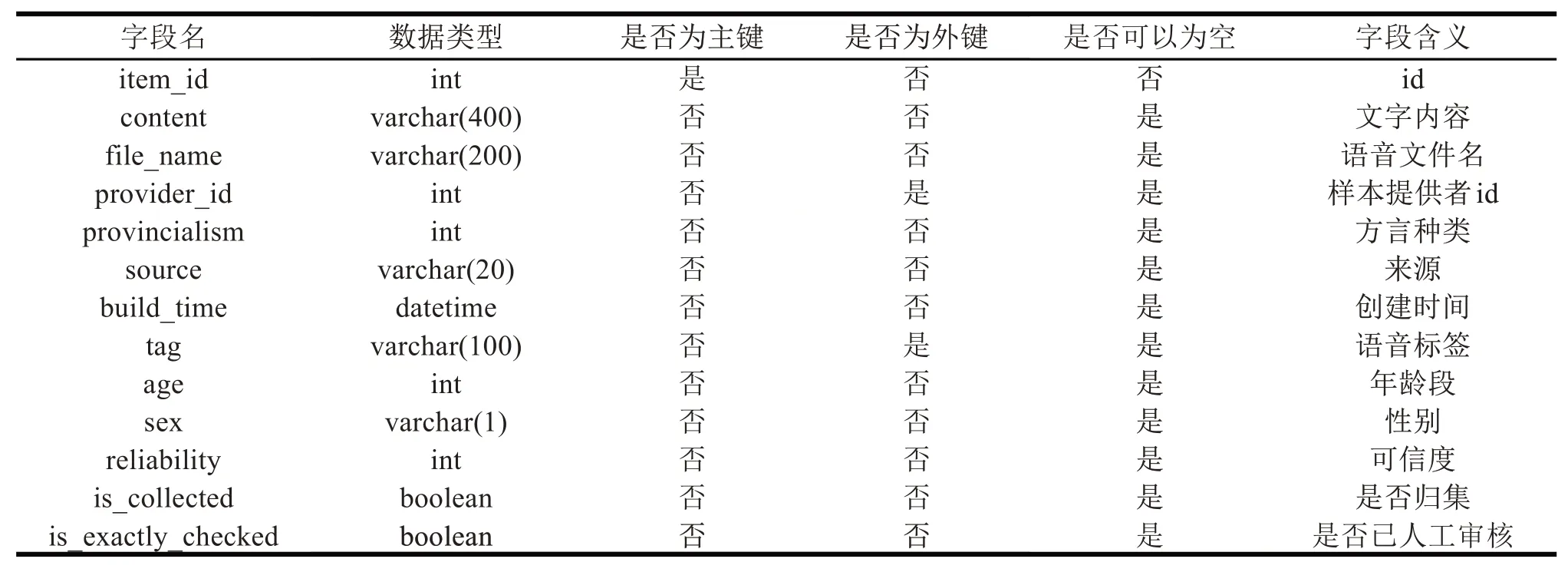
表1 語音采集數據表結構
3.4 主要功能實現
下面以多人正規賽游戲為例介紹一下相關系統實現。
3.4.1 多人正規賽在Android APP中的實現
游戲實現的功能界面如圖6所示。
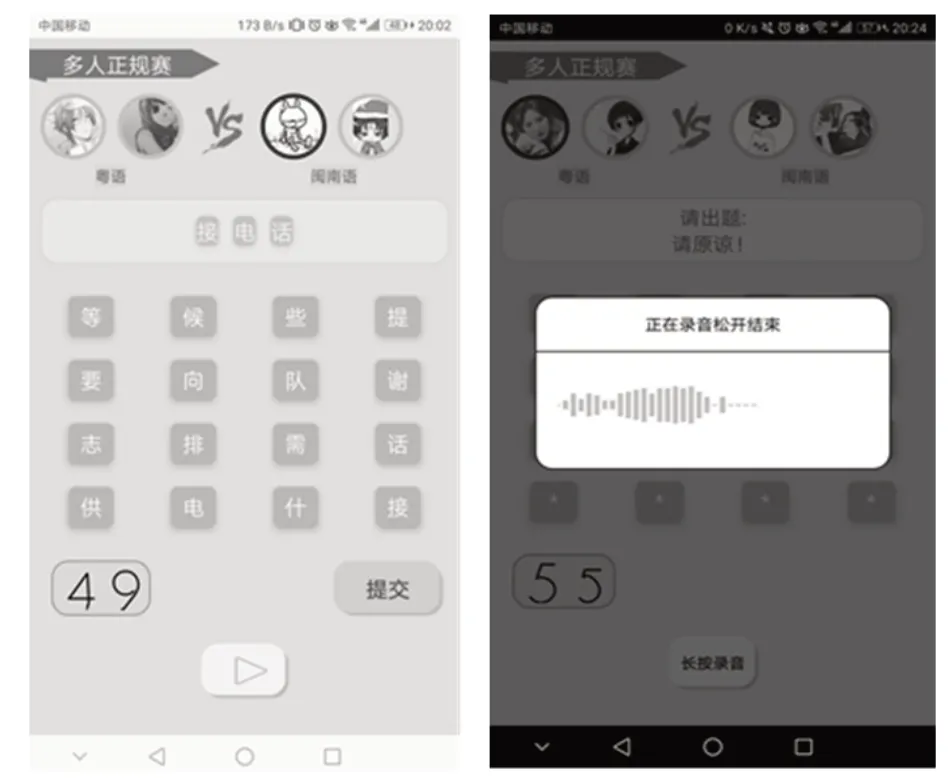
圖6 Android APP中的游戲界面
定義碎片類MultimatchFragment,該類中定義了一些匿名多線程類的對象,完成游戲計時等功能,如表2所示。

表2 多線程對象的定義
此外,多人正規賽游戲的功能主要在該類中定義實現,負責加載游戲界面、初始化游戲數據、進行游戲功能的控制,包括:錄音、播放錄音、提交錄音、游戲倒計時等功能,該類的主要方法定義及其功能如表3 所示。其中實現錄音功能的startRecording()方法定義如下:
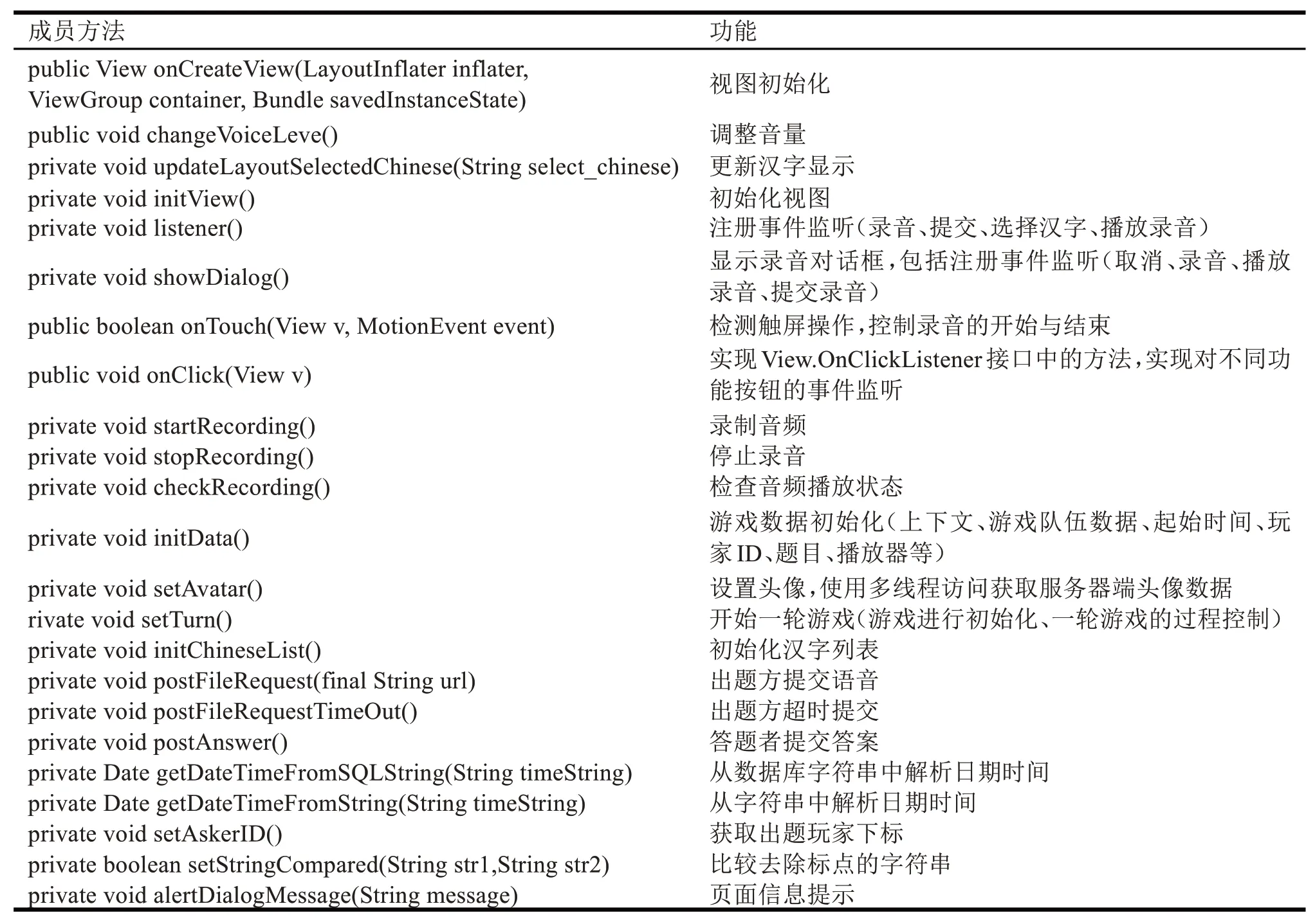
表3 MultimatchFragment中的方法定義

3.4.2 多人正規賽在微信小程序中的實現
微信小程序中的多人正規賽的功能由四個文件來實現,分別是:team_battle.js、team_battle.wxm l 和team_battle.wxss,其中的wxss 文件用于設置樣式,wxm l 文件用于設置頁面布局,js 文件用于定義實現功能的各種JavaScript 函數,如表4所示。
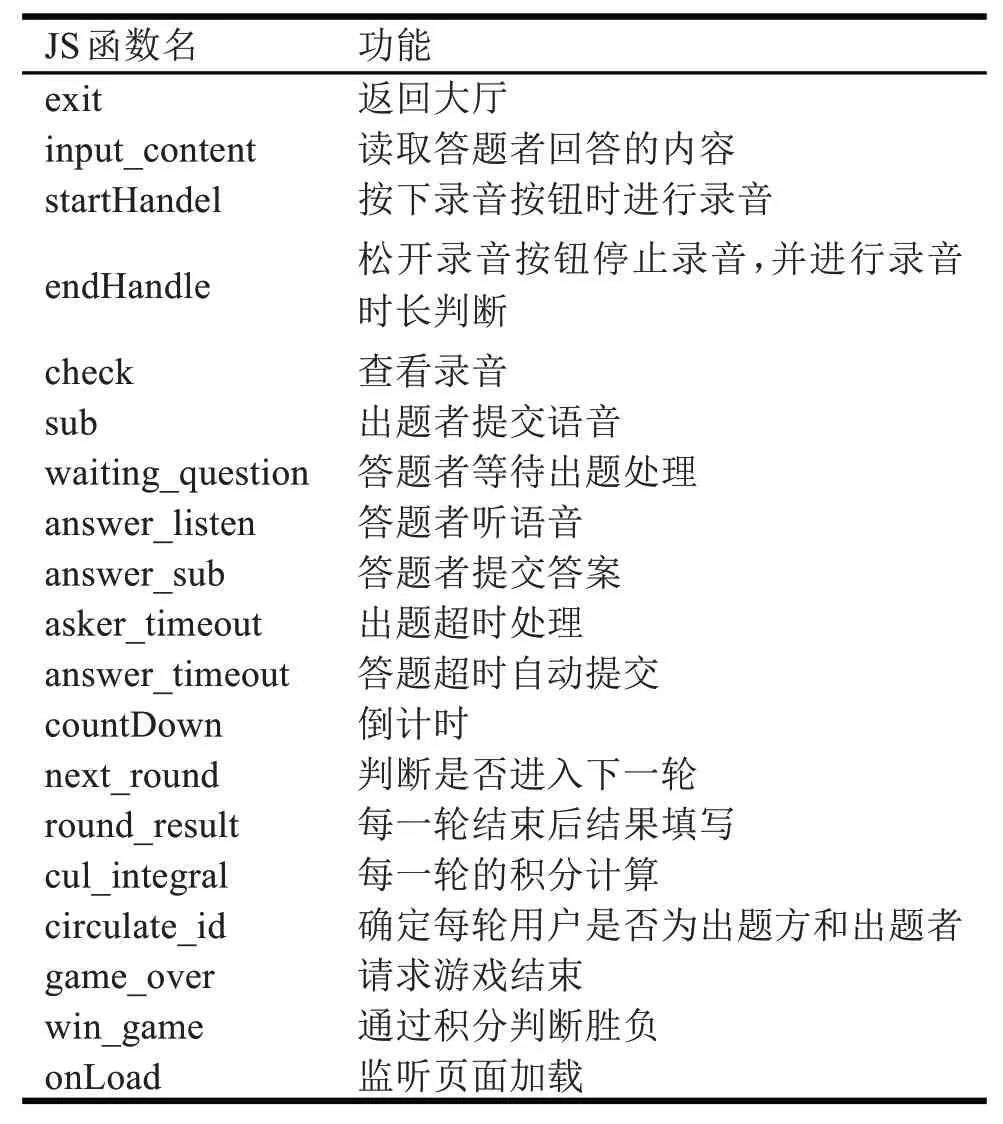
表4 team_battle.js中的函數定義
按下錄音按鈕時進行錄音的startHandel函數定義如下:


多人正規賽游戲在微信小程序中的功能界面如圖7所示。
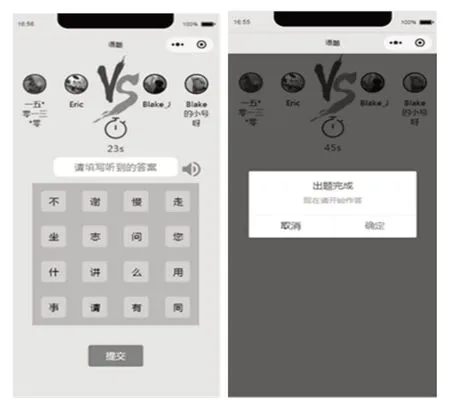
圖7 微信小程序中的游戲界面
4 結語
本文針對目前語音AI 面臨的語音數據采集問題,提出基于移動客戶端的語音數據采集與服務平臺,通過各種語音游戲的方式吸引用戶參與,并通過游戲機制的設置獲得語音數據收集、校驗、標注的功能,定制任務能夠很好地進行定向語音數據采集,可以較好地解決個別方言數據不均衡的問題,為語音識別提供更為有效的語音數據。
猜你喜歡
中華詩詞(2022年6期)2022-12-31 06:41:24
中國科技論壇(2017年7期)2017-07-25 08:49:53
商用汽車(2016年11期)2016-12-19 01:20:16
初中生學習·低(2016年10期)2016-11-25 04:51:34
飛碟探索(2016年11期)2016-11-14 19:34:47
作文大王·笑話大王(2016年8期)2016-08-08 11:28:22
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
小學科學(2015年7期)2015-07-29 22:29:00
創業家(2015年5期)2015-02-27 07:53:25
