小學生羞怯特質(zhì)預(yù)測及語言風格模型構(gòu)建*
2021-02-27 08:10:08姜力銘田雪濤肖夢格馬彥珍
心理學報 2021年2期
駱 方 姜力銘 田雪濤 肖夢格 馬彥珍 張 生
(1 北京師范大學心理學部,北京 100875) (2 北京交通大學計算機與信息技術(shù)學院,北京 100044)(3 中國基礎(chǔ)教育質(zhì)量監(jiān)測協(xié)同創(chuàng)新中心,北京 100875)
1 引言
羞怯是一種普遍存在的主觀體驗,每個人在日常生活中都會不同程度地感受到羞怯。小學階段是羞怯特質(zhì)形成的關(guān)鍵時期,持續(xù)且較高水平的羞怯對學生的社會交往、人格發(fā)展、身心健康等方面均具有消極影響。因此,對早期羞怯的測量尤為重要。以往對羞怯的測量主要為自陳量表法和觀察法,二者均存在一定的問題:被試容易對自陳量表作假回答(李亞紅 等,2005;駱方,張厚粲,2007),量表法也不適用于長期追蹤和動態(tài)反映學生羞怯的發(fā)展。觀察法雖然能夠評估個體是否具有羞怯行為,但是難以評估羞怯的認知和情緒體驗,這些特征是內(nèi)隱的,不易被觀察到(Leary,1986)。
基于個體留下的網(wǎng)絡(luò)痕跡來預(yù)測人格品質(zhì)是近些年的研究熱點(Azucar et al.,2018),通過對個體在線數(shù)據(jù)的挖掘構(gòu)建預(yù)測模型,能夠持續(xù)輸出對被試的評估結(jié)果,比如,研究者基于被試在微博上發(fā)布的內(nèi)容構(gòu)建抑郁預(yù)測模型(白朔天 等,2014),從而及時甄別博主的自殺傾向并進行及時干預(yù)。羞怯與焦慮和抑郁一樣具有較高的內(nèi)隱性,除非有明顯的羞怯行為表現(xiàn)出來,大部分內(nèi)心有強烈的羞怯認知和情緒體驗的個體難以被直接觀察到,但是他們的日常用語可能與普通個體存在差別。小學生的作文及日記中包含著其日常學習、生活的真實經(jīng)歷和感受,羞怯相關(guān)事件及體驗也能夠被記錄在內(nèi)。因此,本研究基于小學生的在線作文、日記和評論,擬采用自然語言處理以及機器學習技術(shù),挖掘羞怯學生的語言風格,即羞怯學生日常用語中的詞匯使用習慣和特點,構(gòu)建羞怯的語言風格模型,并據(jù)此建立羞怯特質(zhì)的自動預(yù)測模型,為實時監(jiān)測學生的羞怯狀況并進行干預(yù)提供可能。
1.1 羞怯及其測量
Lewinsky (1941)最早提出“羞怯”這一構(gòu)念,將其界定為一種心理狀態(tài):個體極度抑制,感到自卑、被忽略,對自己的感覺與情緒過分敏感,同時伴隨有許多常見的生理癥狀,如臉紅、出汗、發(fā)抖、說話不流利等;Zimbardo 等人(1975)提出,羞怯是指個體不愿意接近他人,或不愿意進入到被他人關(guān)注的、難以回避的情境中,強調(diào)了“不愿意”的行為反應(yīng)傾向;Cheek 和Buss (1981)將羞怯界定為在人際交往的情境中,個體由于感覺到他人在評價自己而產(chǎn)生緊張、害怕、尷尬或困窘的情緒。從上述定義可以看出,羞怯包含了行為、認知、情緒及生理反應(yīng)多個維度的表現(xiàn)。
羞怯從兒童五、六歲左右開始發(fā)展(張昌 等,2012)。兒童期羞怯對青春期的外傾性、開放性、情緒穩(wěn)定性(Baardstu et al.,2019)、人際關(guān)系(Karevold et al.,2012)、內(nèi)在問題(如焦慮、低自尊等) (Caspi et al.,1988)以及各領(lǐng)域的適應(yīng)問題(Rubin et al.,1995)均具有預(yù)測作用。羞怯個體往往缺乏足夠的應(yīng)對策略,傾向于情緒化地應(yīng)對問題,如攻擊、自我傷害等(Eisenberg et al.,1998;Findlay et al.,2009;Kagan,1997),導致更加嚴重的社會問題。然而,早期羞怯的消極影響和測量尚未得到教育工作者的充分關(guān)注,這一方面是由于羞怯的學生沉默寡言,符合課堂規(guī)范(Evans,2010),通常成為老師眼中安靜順從的好學生,導致羞怯所帶來的消極影響難以被發(fā)現(xiàn);另一方面是由于中國傳統(tǒng)文化鼓勵約束和克制的態(tài)度或行為,羞怯的相關(guān)表現(xiàn)在某種程度上被認為是個體在社交方面的成熟(Chen,2010;Ho,1986)。因此,在我國文化背景下,對早期羞怯進行及時、有效的測量尤為重要。
研究者認為,羞怯的測量應(yīng)當全面捕捉羞怯在行為、認知、情緒、生理四個維度上的表現(xiàn)(Henderson et al.,2014),因為人們在羞怯情感和羞怯行為上的困擾程度往往不同(Pilkonis,1977),許多羞怯個體能夠掩飾羞怯的內(nèi)在焦慮體驗,抑制羞怯的行為反應(yīng),從而維持自身的社會功能,這些個體被稱為“外向羞怯者” (Zimbardo,1977)。目前,羞怯的主流測量方法是自陳量表法。國外應(yīng)用較廣的羞怯量表有Zimbardo (1977)編制的斯坦福羞怯量表(Stanford Shyness Scale)以及Cheek 和Buss (1981)編制的羞怯量表(Cheek & Buss Shyness Scale)。國內(nèi)研究者多采用徐春蓉 (2001)編制的《國小兒童害羞量表》,例如,孫源泉等人(2009)采用該量表研究震區(qū)喪親兒童的羞怯、創(chuàng)傷后應(yīng)激障礙癥狀和心理健康之間的關(guān)系。自陳量表能夠全面地捕捉羞怯在行為、認知、情緒、生理四個維度上的表現(xiàn),但該方法難以實現(xiàn)對羞怯特質(zhì)的重復(fù)測量和持續(xù)監(jiān)測。除自陳量表法外,研究者還通過生理指標法、行為觀察法等方式對羞怯進行測量,這兩種方法均無法全面地測量羞怯各個維度:生理指標法(例如心率)僅能捕捉到羞怯的情緒及生理反應(yīng),且更適用于測量狀態(tài)性羞怯而非特質(zhì)性羞怯(Brodt & Zimbardo,1981;Martin,1961);行為觀察法僅能測量到羞怯的外顯行為,難以測量內(nèi)隱的羞怯情緒和認知,且個體表現(xiàn)出的羞怯行為可能受到個體的控制(Henderson et al.,2014),因此,觀察的結(jié)果不完全可靠。
為進一步驗證行為觀察法的實際有效性,檢驗教師的日常觀察是否能夠有效測量學生的羞怯水平,本研究選擇華西小學三年級2 班的49 名學生作為預(yù)研究樣本,要求該班學生作答《國小兒童害羞量表》,作為學生自評數(shù)據(jù)。同時,要求班主任從“害羞行為”、“害羞認知”、“害羞情緒反應(yīng)”三個維度對該班學生進行7 點評分,作為教師評定數(shù)據(jù)。結(jié)果顯示,教師評分與學生自評之間相關(guān)較低。由此可見,班主任的觀察難以有效地識別羞怯學生,因此,我們需要尋找更加有效的測評手段,捕捉學生內(nèi)隱的羞怯認知和情緒。
語言是人們表達內(nèi)在的思想和情緒的有效途徑(Tausczik & Pennebaker,2010),小學生的作文及日記是學生在自然狀態(tài)下的自我表達,文本的內(nèi)容主要為日常學習、生活的真實經(jīng)歷,羞怯相關(guān)事件及體驗也能夠被充分記錄在內(nèi)。因此,本研究將探索一種全新的羞怯測量方法,即通過獲取小學生在較長時間內(nèi)的大量作文及日記文本,采用文本挖掘方法建立監(jiān)測個體羞怯特質(zhì)的模型。
1.2 文本挖掘預(yù)測心理特質(zhì)
羞怯是一種典型的人格特質(zhì),人格與語言有密切的關(guān)系(Mairesse et al.,2007;Pennebaker & King,1999),尤其是與社交性相關(guān)的特質(zhì)(Allport,1937;Cattell,1943;Goldberg,1982;Norman,1963)。對自然語言的分析能夠揭示該語言背景下個體的語言特征與心理特質(zhì)之間的關(guān)系,進而通過語言模式預(yù)測心理特質(zhì)(Yarkoni,2010),而詞匯特征則是個體的思維、感覺、觀點和人格特質(zhì)的重要線索(Argamon et al.,2005)。
以往基于自然語言的心理學研究受到文本數(shù)據(jù)收集的局限,通常要求被試在實驗室中完成命題寫作,例如,描述個人的過去經(jīng)歷或未來計劃(Fast& Funder,2008;Hirsh & Peterson,2009)。然而,這種方式收集到的文本受情境、新近經(jīng)驗等偶然因素影響較大,且數(shù)據(jù)量較小,不足以對個體的特征進行穩(wěn)健的估計。隨著社交媒體、在線學習平臺的普及,研究者能夠收集到更加開放、更長時間跨度的文本數(shù)據(jù),從而提取出感興趣的、有意義的信息,揭示個體的心理特質(zhì)(D?rre et al.,1999;Feldman &Sanger,2006)。劍橋心理測量中心的研究團隊基于Facebook 用戶發(fā)布的文本內(nèi)容,借助LIWC 等詞典提取語言特征,預(yù)測用戶的大五人格(Markovikj et al.,2013);微軟研究團隊基于Facebook用戶發(fā)布的文本內(nèi)容和大五人格理論,構(gòu)建基于社交媒體的人格預(yù)測系統(tǒng)(Bachrach et al.,2014);Aung 和Myint(2019)采用LIWC、SPLICE 兩個詞典的特征以及用戶的社交網(wǎng)絡(luò)特征,預(yù)測Facebook 用戶的大五人格;Marouf 等人(2019)采用LIWC 詞典特征,應(yīng)用樸素貝葉斯、決策樹、隨機森林、線性回歸以及支持向量機多種分類模型,預(yù)測Facebook 用戶的神經(jīng)質(zhì)人格。我國研究者多依托微博平臺對個體的特質(zhì)、心理狀態(tài)進行預(yù)測,譬如,利用中文版LIWC提取特征,檢測用戶發(fā)布的內(nèi)容中所表達的心理狀態(tài)(汪靜瑩 等,2016),識別對大五人格各維度具有預(yù)測作用的詞匯(Gu et al.,2018;Qiu et al.,2017),以及檢測用戶的抑郁、焦慮以及自殺傾向(Cheng et al.,2017)。
前述研究顯示出文本挖掘技術(shù)應(yīng)用于人格特質(zhì)預(yù)測的有效性,為本研究利用文本挖掘技術(shù)預(yù)測羞怯奠定了方法學基礎(chǔ)。此外,監(jiān)測抑郁、焦慮等心理狀態(tài)以及預(yù)測大五人格的研究也為本研究提供了理論基礎(chǔ):一方面,羞怯內(nèi)在地表現(xiàn)為一種社交焦慮(Leary,1986),而文本挖掘是檢測焦慮等心理狀態(tài)的理想工具,相關(guān)研究結(jié)果能夠為羞怯情緒的識別提供重要參考;另一方面,羞怯與內(nèi)傾性和神經(jīng)質(zhì)等人格特質(zhì)存在顯著的相關(guān)(Hofstee et al.,1992;Jones et al.,2014;Kwiatkowska et al.,2019;La Sala et al.,2014;Sato et al.,2018),內(nèi)傾性在羞怯中表現(xiàn)為傾向于獨處但能夠應(yīng)對必要的社交,而神經(jīng)質(zhì)在羞怯中表現(xiàn)為孤獨感、低自尊以及對可能出現(xiàn)的尷尬情境的過度擔憂(Eysenck,1969),因此,大五人格的文本挖掘結(jié)果有助于更好地理解和解釋羞怯個體的文本特征,例如,高外傾性和高宜人性的個體傾向于使用更多的積極情緒詞和社會歷程詞,人稱代詞“我們”與宜人性顯著正相關(guān)(Gill et al.,2009;Mehl et al.,2006;Nowson,2006;Oberlander& Gill,2006;Qiu et al.,2012;Yarkoni,2010)。
因此,本研究收集了小學生在線教學平臺“教客學伴” (https://www.jiaokee.com/)上的作文、日記及長評論作為文本數(shù)據(jù)集,據(jù)此對小學生羞怯群體進行自動識別。該文本數(shù)據(jù)集具有較長的時間跨度,其內(nèi)容、主題均有較高的自由度,能夠充分反映小學生的日常學習生活。此外,已有研究發(fā)現(xiàn)存在不同類型的羞怯個體,比如,一些羞怯個體報告的消極想法較少但回避反應(yīng)明顯,一些羞怯個體報告的焦慮水平很高但幾乎沒有表現(xiàn)出行為困難,還有一些羞怯個體體驗到強烈的負面情緒但生理反應(yīng)不明顯(Henderson et al.,2014)。因此,本研究將對羞怯的三個維度分別進行特征提取和模型構(gòu)建,比較三個維度的語言風格和詞匯使用特點,同時比較模型在三個維度上的預(yù)測精度。
2 研究過程
本研究采用文本分析方法來訓練小學生羞怯的分類模型。首先,由小學生作答羞怯量表,基于量表分數(shù)將被試分為“羞怯群體”和“普通群體”,這個過程通常被叫做“打標簽”,即對被試群體進行分類;其次,收集被試的在線寫作文本,由于文本是非結(jié)構(gòu)化的,計算機無法直接對其進行處理與分析,因而需要進行文本的向量化表征。本研究旨在關(guān)注小學生羞怯的詞匯特征,即羞怯學生在日常寫作文本中的詞匯使用特點,因此,采用基于心理詞典提取文本特征的方法,將每名學生的全部文本表征為一系列詞頻特征。然后,采用卡方算法來篩選重要特征。最后,采用機器學習算法,基于篩選后的特征構(gòu)建小學生羞怯的預(yù)測模型。
2.1 數(shù)據(jù)收集
2.1.1 量表數(shù)據(jù)
在問卷星(https://www.wjx.cn/)上發(fā)布《國小兒童害羞量表》,邀請“教客學伴”平臺上2~5 年級的小學生在線作答量表,共回收問卷2734份,其父母在線簽署了知情同意書。量表分為羞怯行為、羞怯認知、羞怯情緒三個維度,共29 道題目,均采用4點計分,“1”表示“非常符合”,“2”表示“較符合”,“3”表示“較不符合”,“4”表示“非常不符合”。量表題目示例:羞怯行為“同學邀請我參加活動的時候,我經(jīng)常找借口拒絕”;羞怯認知“如果我拒絕了別人的請求,我認為他們一定會對我產(chǎn)生不好的看法”。羞怯情緒“老師叫我回答問題的時候,不管我會不會,我都會心跳加快或手心冒汗”。
采用SPSS 23.0 軟件對量表數(shù)據(jù)進行清理。根據(jù)學生的作答用時以及總題量分析,剔除了用時過短(平均每題用時小于2 秒)、全卷作答相同選項數(shù)量大于70%,以及在相同數(shù)量的正反向題目上得分標準差小于0.4 (說明被試沒有考察題目的語義,無論正向或反向題目均給予了一致的回答)的無效被試,得到有效問卷2476 份,男生1284 名,女生1192 名;各年級人數(shù)分布為:二年級937 人,三年級1012 人,四年級449 人,五年級78 人。
基于上述2476 名學生數(shù)據(jù),采用Mplus 7.0 軟件對量表進行驗證性因素分析及修訂。基于修訂后的量表,分別計算被試在3 個維度上的原始得分,個體的量表得分越高表示其羞怯水平越高,隨后將原始得分轉(zhuǎn)換成標準分數(shù)。依據(jù)標準分數(shù)對個體進行分類是一種常用方法,比如,兒童行為評估系統(tǒng)(Behavior Assessment System for Children Third Version)將標準分大于2 (即原始得分高于均值2 個標準差以上)的個體判為“存在嚴重問題”,標準分大于1 小于2 (得分高于均值1 個標準差到2 個標準差之間)的個體判為“有風險” (Sandoval &Echandia,1994)。本研究將標準分數(shù)大于1 的個體劃入“羞怯組” (標簽為1),表示個體在該維度上表現(xiàn)出羞怯,將標準分數(shù)小于等于1 的個體劃入“普通組(標簽為0),表示個體的羞怯特征不明顯。各維度羞怯組與普通組人數(shù)比例為,羞怯行為 281 :1026,羞怯認知176 :1131,羞怯情緒217 :1090。
2.1.2 文本數(shù)據(jù)
依據(jù)填寫量表的學生ID,收集學生在“教客學伴”上2013 年6 月至2018 年1 月的所有文本數(shù)據(jù)。該平臺為語文教改背景下的實驗教學平臺,語文老師每天上課都會使用該教學平臺,學生在語文課上經(jīng)常被要求在平臺上寫作文,寫作頻率很高。除老師要求的寫作任務(wù)外,學生還會寫日記、對同學的寫作進行評論,這部分內(nèi)容比較少。本研究將上述文本數(shù)據(jù)合并在一起,共同作為文本數(shù)據(jù)來挖掘語言特征。由于小學生的寫作形式僅限于記敘文,寫作內(nèi)容也多圍繞小學生的真實經(jīng)歷,例如,記敘國慶假期的趣事、你最好的朋友等主題,因而合并后的文本數(shù)據(jù)記錄了學生日常生活學習的方方面面,話題非常豐富,能夠充分地反映出學生的語言風格和表達方式。
對上述文本數(shù)據(jù)進行清理,刪去引用文本(如摘抄等)、無意義文本(如亂碼等)、短文本(“已閱”等)以及重復(fù)文本,僅保留學生原創(chuàng)的作文、日志以及長評論。隨后,將同一ID 的文本進行匯總,剔除文本總量過低的個體。最后,將量表數(shù)據(jù)與文本數(shù)據(jù)的進行匹配,得到有效被試1306 人。卡方檢驗結(jié)果顯示,是否能夠匹配與性別之間的卡方值不顯著(χ2=1.19,df=
1,p
=0.552),即與性別獨立;各年級學生的文本數(shù)據(jù)缺失情況(能夠匹配的人數(shù) :不能夠匹配的人數(shù)):二年級416 :521,三年級614 :398,四年級229 :220,五年級47 :31。這一分布主要是由于低年級在線寫作任務(wù)較少。學生文本示例:“有一次,我在書法課里,我正在和一個朋友上課,突然,老師說了一句話,說:明天就是書法競賽,誰要參加?我們紛紛議論,大家都異口同聲說:不想去。老師想:機會難得,只有兩個名額,然后老師說了出來,我們又推人出來,而我靜靜地坐在教室里的一角,認認真真地寫字,后來,老師大發(fā)雷霆,火冒三丈地說:大家都回座位。我們就坐好了。老師說這樣就讓,老師還沒說出來,同學們都響起了掌聲,說著我。我有點害羞了,心砰砰地跳個不停,那掌聲真讓我入迷,我都說不出來了。老師說:那就××去吧,還有他后面的那個誰一起去參加比賽。我很緊張當時,然后就讓我回家好好練,最后就推選了我,還有我的朋友,那一次真讓我難忘,我不會忘記的。”
2.2 心理詞典修訂與特征提取
在文本分析領(lǐng)域,詞典是指定義了特定類別的單詞的集合,包含詞語歸屬的類別名稱以及詞列表。目前在心理學領(lǐng)域應(yīng)用較廣的是上世紀90 年代開發(fā)的“語言探索與字詞計數(shù)”詞典(Linguistic Inquiry and Word Count,LIWC) (Pennebaker et al.,2015),它包含80 個詞類,約4500 個字詞,已被用來研究人格特質(zhì)、注意指向、思維方式、親密關(guān)系、社會關(guān)系、情緒與心理健康等眾多問題(Tausczik &Pennebaker,2010)。將文本中的詞語與詞典進行一一比對,輸出各類詞語的詞頻結(jié)果,這是一個將文本向量化的過程,叫做特征提取(Tausczik &Pennebaker,2010)。
研究者認為,基于詞典的方法適用于聚焦特定的研究問題或主題的任務(wù)(Guo et al.,2016)。因此,詞典的適用性對研究結(jié)果具有至關(guān)重要的影響,如果詞典本身涵蓋的詞類不適于進行目標構(gòu)念(羞怯)的分析,特征提取的有效性將會被削弱。本研究選擇中科院心理所計算網(wǎng)絡(luò)心理實驗室研發(fā)的“文心(TextMind)”中文心理分析系統(tǒng),該系統(tǒng)的核心詞典(下稱文心詞典)參照LIWC 開發(fā),詞庫分類體系也與LIWC 兼容一致(朱廷劭,2016)。文心詞典包含102 個詞類,超過一萬個詞,在心理學研究中應(yīng)用廣泛,其有效性得到了充分的驗證(Lin et al.,2018;Shen et al.,2018;Wan et al.,2019;趙楠 等,2020)。本研究基于小學生羞怯的語言特征,對文心詞典進行了擴充和改編:情緒是羞怯特質(zhì)的重要表現(xiàn)指標,文心詞典中對情感歷程詞的分類比較粗糙,本研究參照大連理工大學開發(fā)的中文情感詞匯本體庫中的情緒詞類別,在文心詞典的正向情緒詞與負向情緒詞下補充7 個二級子類,包括“樂”、“好”、“怒”、“哀”、“懼”、“惡”、“驚”;將原詞典的“生氣詞”、“悲傷詞”與中文情感詞匯本體庫中的“憤怒”、“悲傷”合并為“怒”、“哀”兩個類別,將原詞典的“焦慮詞”歸入“懼”這一類別下。此外,“動物詞”在小學生文本中的出現(xiàn)頻率較高,將其補充到詞典中;最后,刪去中文分析時不常用的“冠詞”類,分別合并了過去、現(xiàn)在、將來時態(tài)下的多個子類。修訂后的文心詞典共包含118 個類別。
此外,文心詞典中的詞匯貼近成人語言,而小學生的語言與成人存在較大差異。為保證詞典適用于提取小學生文本特征,本研究對收集到的“教客學伴”上的小學生文本進行匯總,統(tǒng)計所有詞匯的詞頻并由高到低排序,將小學生使用頻率較高但未包含于原文心詞典的詞匯納入詞典,對各詞類下的詞匯進行擴充。
對每個小學生的全部文本進行分詞后,基于修訂后的詞典,統(tǒng)計每個學生的文本在118 個類別上的詞匯頻率,從而生成118 個文本特征變量。
2.3 特征篩選
采用文本分析來預(yù)測人格的相關(guān)研究大多預(yù)先進行特征篩選(如,Tadesse et al.,2018;Tandera et al.,2017;Yuan et al.,2018),挑選重要的特征構(gòu)建預(yù)測模型,有利于提高模型的計算效率和預(yù)測準確性。本研究不僅構(gòu)建預(yù)測模型,而且著力于識別羞怯學生的日常用語與普通學生的差異從而刻畫小學生羞怯的語言風格,因此,篩選出能夠有效區(qū)分羞怯群體和普通群體的詞匯進行分析是一個關(guān)鍵步驟。
首先,對基于詞典提取的118 個特征進行初步篩選,剔除與研究目的無關(guān)的特征。C1~C98 為98個詞類,這些詞類之間存在層級關(guān)系,例如,感知歷程詞類別下包含視覺詞、聽覺詞、感覺詞;情感歷程詞類別下包含正向情緒詞以及負向情緒詞。本研究認為不同層級的詞類均有研究意義,因此C1~C98 均作為特征納入模型。C99~C109 為10 種標點符號,本研究重點關(guān)注小學生羞怯的詞匯特征,因此C99~C109 不納入模型。C110~C118 為系統(tǒng)自動生成的統(tǒng)計特征,C110 為“總詞數(shù)”,由于學生開始使用平臺進行在線寫作的時間不同,總詞數(shù)相差較大,因此不納入模型,僅利用該特征對C1~C98的詞頻進行標準化;C111 為“每句平均詞數(shù)”,我們認為這一特征能夠反映出羞怯個體說話長短的語言特征,因此將該特征納入模型;C112 為“詞典覆蓋率”,即該個體文本用詞對整個詞典的覆蓋程度,這一特征無法反映出羞怯群體與普通群體具體在哪一詞類上存在差異,因此不納入模型;C113“數(shù)字比率”、C114“詞長等于4 的比率”、C115“詞長大于4 的比率”、C116“英文比率”、C118“URL 數(shù)量”,均與本研究內(nèi)容無關(guān),且小學生文本中基本不包含數(shù)字和英文文本,因此這部分特征也不納入模型;C117“情感詞比率”與C37“情感歷程詞”對本研究的意義相同,因此前者不納入模型。
然后,采用卡方算法(Oakes et al.,2001)針對C1~C98 以及C111 共計99 個詞頻特征進行進一步的篩選,識別特征集合中能夠最大程度地區(qū)分羞怯群體與普通群體的特征。卡方算法是特征篩選的常用算法(Forman,2003),例如Paudel 等人(2018)通過卡方算法提取特征以實現(xiàn)對推特用戶發(fā)布內(nèi)容的情感分析。卡方算法在鎖定文本中具有代表性的關(guān)鍵詞等方面具有很高的有效性,通過確定最小的特征集合,使模型僅利用部分重要特征達到理想的預(yù)測水平。例如,Agarwal 等人(2011)對推特文本進行情感分類時,使用語義以及句子成分等大量文本特征達到 75.39%的分類準確性,Chamansingh 和Hosein (2016)在此基礎(chǔ)上僅增加了卡方算法提取特征這一步驟,將模型的分類準確性提高至78.07%,并且大大降低了模型的計算時間和內(nèi)存需求。
卡方算法檢驗詞頻特征在兩個群體的文本中出現(xiàn)的頻率差異,并且考慮兩類文本長度的影響。卡方值越大,表示該類詞匯在兩類人群中的使用頻率差異越大。具體計算公式為:

O
表示第i 類詞(W)在羞怯群體文本中出現(xiàn)的頻次,O
表示W(wǎng)在普通群體文本中出現(xiàn)的頻次;O
表示除W外的其它詞(?W)在羞怯群體文本中出現(xiàn)的頻次,O
表示?W在普通群體文本中出現(xiàn)的頻次,N 表示訓練文本中所有詞語的頻次總和,N
=O
+O
+O
+O
。本研究基于量表中羞怯行為、羞怯認知以及羞怯情緒三個維度的得分,分別將小學生分為存在行為羞怯、認知羞怯和情緒羞怯的個體以及普通個體,以χ> 100 作為篩選標準,得到羞怯行為、羞怯認知以及羞怯情緒上的三組典型特征,這部分特征除以總詞數(shù)并標準化后,納入機器學習預(yù)測模型。
2.4 建立模型
基于篩選后的特征,采用機器學習算法構(gòu)建文本特征對羞怯類別的預(yù)測模型。機器學習算法可以構(gòu)建高維預(yù)測變量及非線性的預(yù)測模型。首先,將數(shù)據(jù)集分為訓練集和測試集,基于訓練集來訓練機器學習模型,達到可接受的預(yù)測效果后,在測試集中評估模型預(yù)測的準確性。訓練集和測試集的劃分比例見表1。
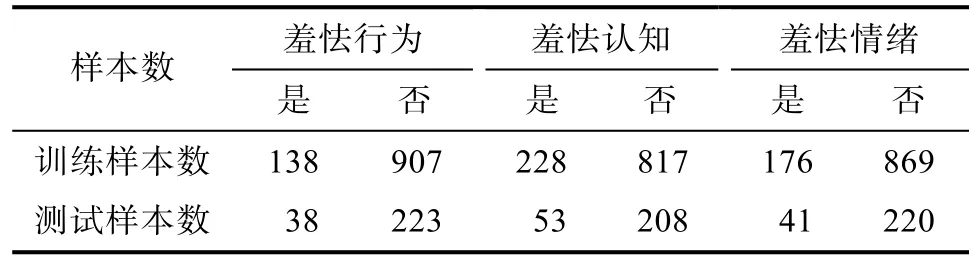
表1 訓練集及測試集劃分
模型評估指標為:準確率、召回率及F1 值。結(jié)合表2 對各個指標進行解釋:準確率表示被模型分到某類別的個體中,實際屬于該類的比例。例如,模型在羞怯群體上的準確率表示被分類為羞怯的學生中,實際也為羞怯(標簽為1)的比例,公式為TP/(TP+FP);模型在普通群體上的準確率表示被分類為普通的學生中,實際也為普通(標簽為0)的比例,公式為TN/(FN+TN);兩個準確率的均值代表總準確率。召回率表示實際屬于某類別的個體中,被模型正確分到該類的比例。例如,模型在羞怯群體上的召回率表示實際為羞怯的學生中,被正確分類為羞怯的比例,這一指標也被稱為“敏感度”,體現(xiàn)出該工具將“陽性”個體檢測出來的有效性,公式為TP/(TP+FN);模型在普通群體上的召回率表示實際為普通的學生中,被正確分類為普通的比例,這一指標也被稱為“特異度”,體現(xiàn)出工具將“非陽性”個體拒絕掉的有效性,公式為TN/(FP+TN);兩個召回率的均值代表總召回率。F1 值為準確率與召回率的調(diào)和平均數(shù),是模型的綜合指標,羞怯群體的F1 值為羞怯群體的準確率和召回率的調(diào)和平均數(shù),普通群體的F1 值為普通群體的準確率和召回率的調(diào)和平均數(shù),總F1 值為總準確率和總召回率的調(diào)和平均數(shù)。
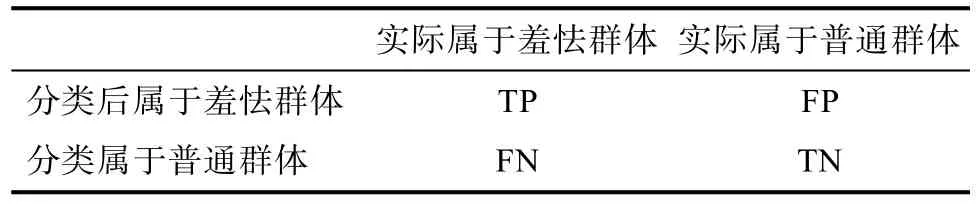
表2 模型分類結(jié)果及數(shù)據(jù)的實際分布
本研究使用Python 3.6.2 進行模型構(gòu)建,嘗試采用決策樹(Decision Tree,DT)、隨機森林(Random Forest,RF)、支持向量機(Support Vector Machine,SVM)、邏輯斯蒂克回歸(Logistics Regression,LR)、K 近鄰(K-Nearest Neighbor,KNN)以及多層感知機(Multi-Layer Perceptron,MLP)六種分類模型,上述模型在人格相關(guān)研究中應(yīng)用廣泛并表現(xiàn)出較高的有效性(Aung & Myint,2019;Farnadi et al.,2013;Majumder et al.,2017;Marouf et al.,2019)。
本研究中羞怯群體的比例遠遠小于普通群體,這種“樣本類別分布不均衡”的情況普遍存在于心理學相關(guān)研究中,對模型預(yù)測的有效性具有負面影響(He & Garcia,2009)。原始的分類器,如邏輯斯蒂克回歸、決策樹和支持向量機,均適用于均衡的數(shù)據(jù)集,在樣本類別分布不均衡問題上表現(xiàn)不佳(López et al.,2013)。研究發(fā)現(xiàn),在應(yīng)用領(lǐng)域,構(gòu)建損失敏感模型的結(jié)果往往優(yōu)于其它方法(Liu &Zhou,2006;McCarthy et al.,2005),該方法通過設(shè)定錯誤分類的損失矩陣使模型達到最優(yōu)預(yù)測效果(Ting,2002)。本研究的主要目的是篩選出羞怯學生,因此為羞怯樣本的錯誤分類設(shè)定更高的損失,并對各個模型進行獨立調(diào)參,使模型達到最優(yōu)的分類結(jié)果。
最后,綜合比較各模型的預(yù)測結(jié)果,選擇最優(yōu)模型進行交叉驗證。交叉驗證的意義在于規(guī)避由于單次抽取的訓練集和測試集導致的偏差,該方法能夠?qū)δP偷姆夯芰M行可靠的估計,評估模型的穩(wěn)定性(Hawkins et al.,2003)。交叉驗證結(jié)果較好,表明預(yù)測模型對個體的分類是穩(wěn)定的,這與測量信度的概念較為一致。本研究采用Geisser (1975)提出的V 折交叉驗證方法,V 設(shè)置為5,即將數(shù)據(jù)平均分為5 份,每次以其中1 份作為測試集,以其余的4份作為訓練集,進行多次驗證。已有研究結(jié)果表明當V 取值為5~10 時,能夠在達到驗證效果穩(wěn)定性的同時,保證模型計算的高效性(Friedman et al.,2001)。
3 研究結(jié)果
3.1 教師評分與學生自評的相關(guān)
預(yù)研究選擇華西小學三年級2 班的49 名學生作為樣本,收集學生在《國小兒童害羞量表》上的自評結(jié)果以及班主任對學生羞怯水平的評定結(jié)果。相關(guān)分析顯示(表3),教師評分與學生自評之間相關(guān)較低。
3.2 小學生羞怯量表修訂
首先,剔除題總相關(guān)小于0.2 的3 道題目(5.我會主動和剛認識的人說話;7.在班上,我經(jīng)常主動舉手回答問題;27.老師或長輩跟我說話的時候,我不會緊張)。隨后,對羞怯量表進行驗證性因素分析。其中部分題目存在較為明顯的語義重疊,對這部分題目進行精簡(例如:20.我和不熟悉的人在一起的時候,我會發(fā)抖或心跳加速;21.如果我和很多不認識的人在一起,我會感到身體不舒服;22.如果陌生人跟我說話,我會心跳加快;26.如果我和不熟悉的人在一起,我會感到緊張不安)。最終量表包含19 道題目,模型擬合良好(χ2=898.599,df
=149,RMSEA=0.04,CFI=0.94,TLI=0.94,SRMR=0.04)。羞怯行為維度、羞怯認知維度、羞怯情緒維度以及量表整體的內(nèi)部一致性(Cronbach’s α 系數(shù))分別為0.79、0.66、0.78 以及0.86。
表3 教師評分與學生自評的相關(guān)
3.3 描述統(tǒng)計
根據(jù)問卷的作答結(jié)果標定樣本在羞怯行為、羞怯認知和羞怯情緒三個維度上的標簽,個體維度總分Z 分數(shù)大于1 視為該維度的羞怯個體(標簽為1),其余個體為普通個體(標簽為0),由此劃分出6 組樣本,各組樣本量、詞頻等數(shù)據(jù)如表4 所示。
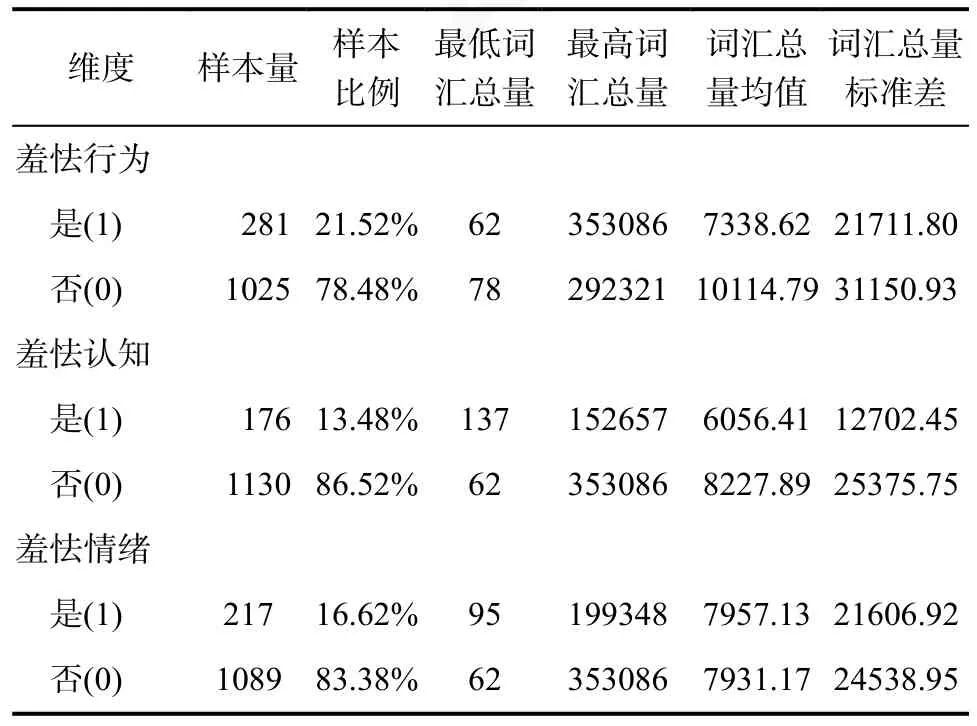
表4 描述統(tǒng)計結(jié)果匯總
3.4 心理詞典修訂
匯總“教客學伴”上所有學生的文本數(shù)據(jù),使用哈工大社會計算與信息檢索研究中心研發(fā)的語言技術(shù)平臺(LTP)對文本進行自動分詞,統(tǒng)計每個詞出現(xiàn)的頻次,將所有詞頻由高到低進行排序,并且將詞頻逐個累加得到累計詞頻率。結(jié)果顯示,前6000 個詞的累積詞頻率超過90%,此后每再增加1000 個詞,累積詞頻率的增量均不超過1% (累積詞頻率和累積詞頻率增量見圖1 圖2)。因此,保留前6000 個詞作為小學生文本的高頻詞。將6000 個高頻詞與原詞典中的詞匯進行比較,其中3119 個詞能夠完全匹配,其余2881 個詞根據(jù)詞義分別歸入118 個詞類,該歸類任務(wù)由兩名心理學研究生協(xié)商共同完成。擴充后的詞典詳見https://xttian.osscn-beijing.aliyuncs.com/shyness dictionary。
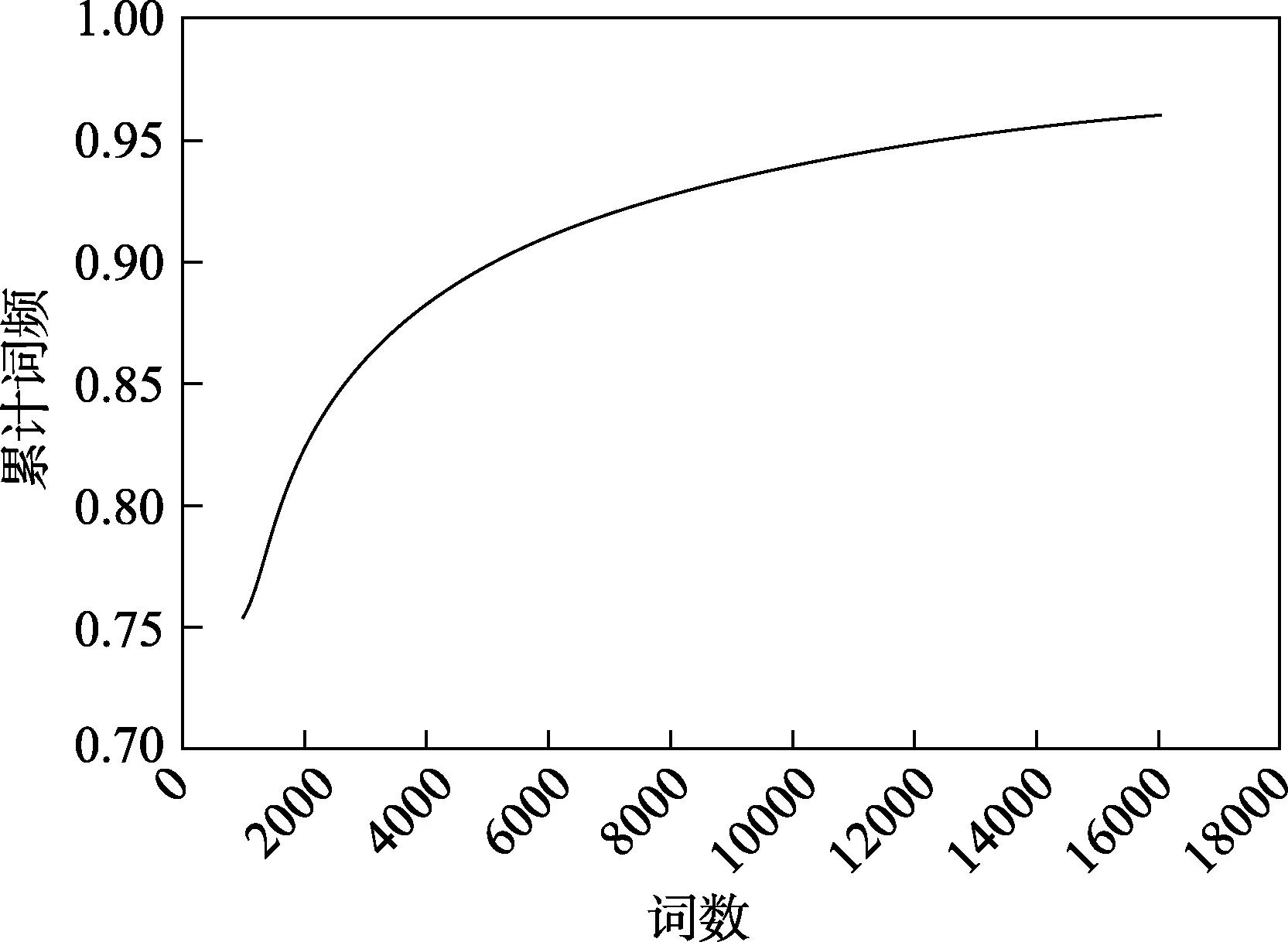
圖1 小學生日志文本累計詞頻
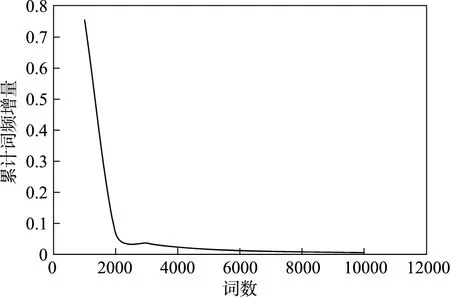
圖2 小學生日志文本累計詞頻增量
3.5 特征提取
基于修訂后的心理詞典,計算羞怯群體文本以及普通群體文本在各個詞類上的詞頻。采用卡方算法,以卡方值大于100 為標準,挑選出在兩類群體文本中存在明顯的頻率差異的詞類。羞怯行為共計提取23 個詞頻特征,羞怯認知共計提取16 個詞頻特征,羞怯情緒共計提取20 個詞頻特征。將特征按“多維度共有”或“單一維度特有”的原則整理,結(jié)果顯示:1)每句平均詞數(shù)對羞怯行為、羞怯認知和羞怯情緒均有負向預(yù)測作用;2)社會歷程詞對羞怯認知、羞怯行為以及羞怯情緒均具有負向預(yù)測作用;3)羞怯個體文本中的各類人稱代名詞均較少,其中,第一人稱復(fù)數(shù)代名詞對羞怯行為具有正向預(yù)測作用,而對羞怯認知和羞怯情緒具有負向預(yù)測作用;4)口語詞、功能詞、認知歷程詞等詞類對羞怯行為具有正向預(yù)測作用,而對羞怯認知和羞怯情緒具有負向的預(yù)測作用;5)時間詞中的過去詞對羞怯行為具有正向預(yù)測作用,而延續(xù)詞則對羞怯情緒有明顯的負向預(yù)測作用;6)感知歷程詞,尤其是視覺詞,對羞怯行為具有明顯的正向預(yù)測作用;7)生理歷程詞,主要是攝食詞,對羞怯情緒具有明顯的負向預(yù)測作用。
各維度特征及卡方值詳見表5。
3.6 模型預(yù)測
基于篩選后的特征,分別對羞怯行為、羞怯認知、羞怯情緒建立預(yù)測模型。本研究使用6 種分類模型均在原始模型中加入損失敏感函數(shù)。比較不同模型的預(yù)測效果(見表6)發(fā)現(xiàn),對于普通群體的準確率,各模型間差異不大,均在0.8 左右;對于羞怯群體的準確率,隨機森林和邏輯斯蒂克回歸的表現(xiàn)相對較好(0.15~0.50);對于普通群體的召回率(即特異度),邏輯斯蒂克回歸和K 近鄰的表現(xiàn)相對較好(大于0.9);對于羞怯群體的召回率(即敏感度),隨機森林和支持向量機的表現(xiàn)較好(0.15~0.44,其中情緒維度較高,行為和認知維度較低);對于總F1 值,隨機森林的結(jié)果表現(xiàn)最好(0.55~0.57)。
結(jié)果還表明,模型對普通群體預(yù)測的準確率和召回率比較高,對羞怯群體預(yù)測的準確率和召回率比較低,這與羞怯群體的人數(shù)較少,難以從大群體中識別出來有關(guān),雖然在原始模型中增加了損失敏感函數(shù)來提高羞怯群體的預(yù)測準確率,但是提升效果有限。
整體來看,隨機森林模型在本研究任務(wù)中的表現(xiàn)最優(yōu),進而對該模型進行交叉驗證,結(jié)果見表7。結(jié)果顯示,總F1 的穩(wěn)定性非常高,取值在0.52~0.57之間。普通群體的準確率和召回率都比較穩(wěn)定,波動最大不超過0.17,大部分的波動都不超過0.1。羞怯群體的穩(wěn)定性相對差一些,波動最大為0.27,大部分波動都不超過0.15。
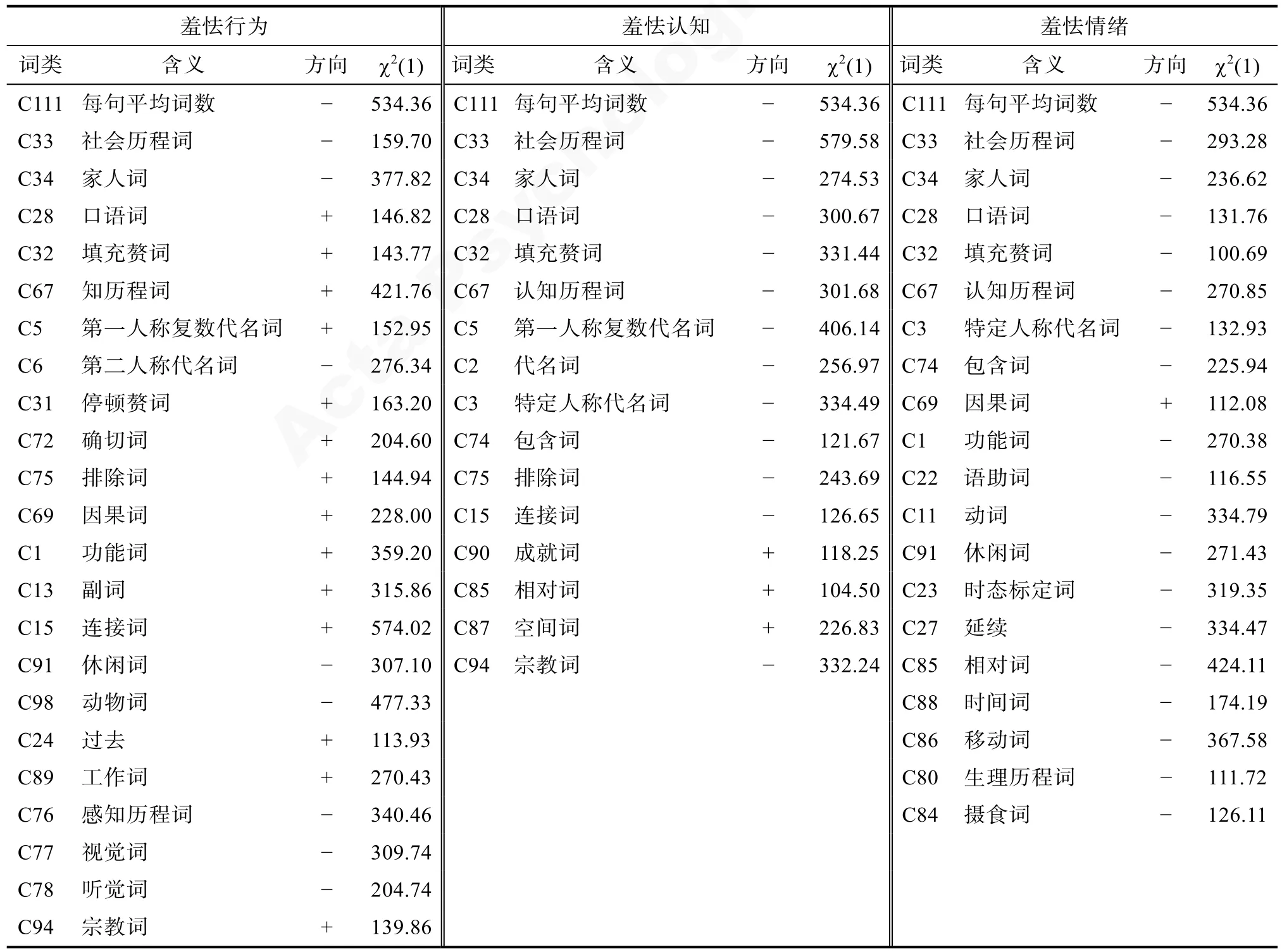
表5 各維度提取特征
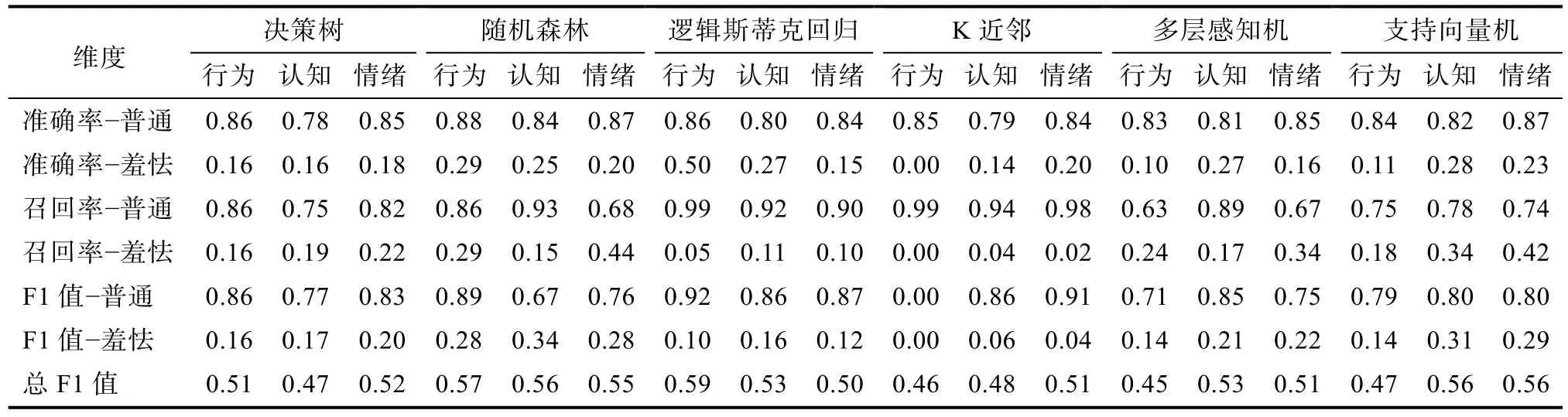
表6 模型預(yù)測結(jié)果
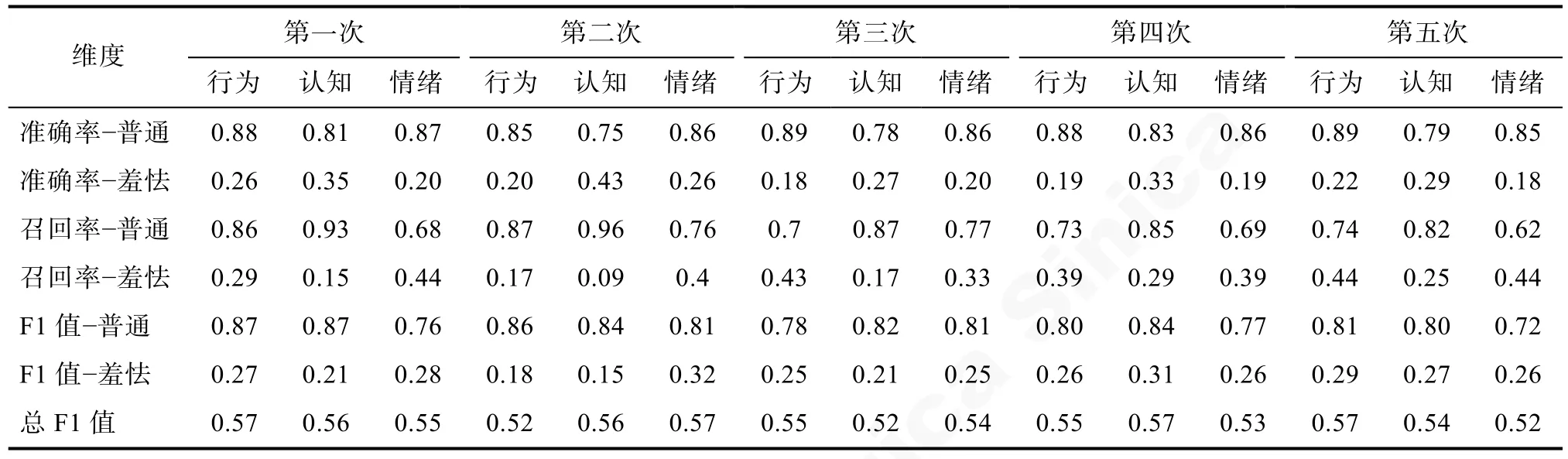
表7 隨機森林模型交叉驗證結(jié)果
4 討論
本研究旨在探索小學生羞怯的語言風格,關(guān)注羞怯群體與普通群體的詞匯使用差異,因此預(yù)先采用卡方算法進行詞頻特征的篩選,再基于篩選后的特征來構(gòu)建預(yù)測模型。與此相反,有一些研究以模型準確率為主要目標,不強調(diào)模型結(jié)果的解釋性,采用神經(jīng)網(wǎng)絡(luò)等更加復(fù)雜的深度模型處理高維特征,而不進行特征篩選(如,Xue et al.,2018),采用該方式建模雖然預(yù)測精度較高,但是并不能夠?qū)︻A(yù)測群體的語言風格進行直觀的描述和解釋。因而,采用卡方算法預(yù)先提取特征再構(gòu)建預(yù)測模型更符合本研究的目標。下面分別從羞怯群體的詞匯使用的共性和差異性以及羞怯預(yù)測模型的精度展開討論。
4.1 羞怯各維度的文本表現(xiàn)既有共性也有特性
本研究基于真實的小學生文本對“文心詞典”進行擴充,構(gòu)建出適用于兒童的心理詞典,實現(xiàn)更為精準的特征提取,并通過卡方檢驗對詞頻特征進行篩選。結(jié)果顯示,羞怯群體和普通群體在用詞上確實存在明顯差異。部分特征為多個維度所共有,即羞怯行為、羞怯認知和羞怯情緒的普遍的語言特點;同時也存在某些特征為單一維度所有,能夠充分體現(xiàn)出該維度的特點。
羞怯行為、羞怯認知以及羞怯情緒的文本特征的共性主要體現(xiàn)在“每句平均詞數(shù)”以及“社會歷程詞”兩方面:首先,高羞怯行為、高羞怯認知以及高羞怯情緒個體的文本中,每句平均詞數(shù)均小于普通個體文本,這與羞怯個體說話少、回答較短、表達不流利等行為模式有直接關(guān)系。已有研究顯示,高內(nèi)傾性個體的每句平均詞數(shù)比外傾性個體更少(Mehl et al.,2006),而羞怯的青少年更有可能是內(nèi)傾性人格(Lawrence & Bennett,1992),且越內(nèi)傾的個體羞怯感越強(韓磊 等,2011)。因此,羞怯個體的語言風格與高內(nèi)傾性個體相近,在文本中體現(xiàn)為使用更短的句子;其次,高羞怯認知、高羞怯行為以及高羞怯情緒個體的文本中,社會歷程詞均較少。已有研究顯示,高外傾性的個體文本中的社會性詞匯更多(Gill et al.,2009;Mehl et al.,2006),因此,較少的社會歷程詞進一步體現(xiàn)出羞怯個體的內(nèi)傾性。社會歷程詞對羞怯的負向預(yù)測作用主要體現(xiàn)在家人詞這一子類,高羞怯個體的文本中更少提及家人詞。已有研究顯示,兒童期羞怯與親子關(guān)系、父母的社交能力等均有關(guān)系(Arroyo et al.,2012;Huang,1999),羞怯兒童的父母往往對兒童表達的需求不敏感,且更傾向于采用強硬的策略(Engfer,1993),控制型或過度保護型的家庭涉及頻繁的矯正和羞辱,更可能引起兒童羞怯(Bruch,1989)。因此,盡管家人詞是小學生文本中的高頻詞,但羞怯學生文本中這類詞相對更少,反映出家庭環(huán)境對羞怯特質(zhì)發(fā)展的影響。
已有研究者認為,羞怯的內(nèi)在認知及情緒體驗應(yīng)當與其外在行為表現(xiàn)區(qū)分(Leary,1986)。本研究對羞怯行為、羞怯認知和羞怯情緒三個維度分別提取特征,結(jié)果顯示,羞怯行為在文本表現(xiàn)上確與羞怯認知及情緒存在較為明顯的差異。首先,高羞怯認知和高羞怯情緒的個體更少提及“我們”等第一人稱復(fù)數(shù)代名詞,而高羞怯行為個體的文本中這類詞匯則較多,可能反映出羞怯個體的趨避沖突(Coplan et al.,2004),即高社交趨向動機和高社交回避動機的組合,盡管羞怯個體感到社交焦慮和壓力,但同樣期望進行社交活動以維持自尊水平(Dennissen et al.,2008);其次,口語詞(包含填充贅詞等)、功能詞(包括連接詞等)、認知歷程詞(包含因果詞、包含詞、排除詞等)對羞怯行為具有正向預(yù)測作用,而對羞怯認知和羞怯情緒具有負向預(yù)測作用。已有研究顯示,較多的填充贅詞反映出個體更多地考慮他人和環(huán)境,即對他人接受自己所表達內(nèi)容的期待(Laserna et al.,2014)。上述特征提取結(jié)果反映出羞怯行為維度的獨特性。另外,羞怯行為往往受到外部限制,具有較高的情境性(Henderson et al.,2014),在寫作文本中的特征體現(xiàn)可能不明顯。
時間詞包含過去、現(xiàn)在、未來以及延續(xù)四個子類,其中過去詞對羞怯行為具有明顯的正向預(yù)測作用,而延續(xù)詞則對羞怯情緒有明顯的負向預(yù)測作用。已有研究表明,高羞怯個體往往存在低自我認知、低自尊等問題(Caspi et al.,1988;Dennissen et al.,2008)。黃希庭和鄭涌(2000)研究發(fā)現(xiàn),高自我認同個體有更大的現(xiàn)在廣度,更積極的未來取向,而低自我認同個體則有更強的過去取向,且與未來中斷的現(xiàn)象更易發(fā)生。低自我認同者往往對現(xiàn)實感到無所適從、對未來感到彷徨,因此轉(zhuǎn)向過去。因此,較多過去詞、較少延續(xù)詞的現(xiàn)象可能反映出羞怯個體的自我意識發(fā)展問題。
感知歷程詞對羞怯行為具有明顯的正向預(yù)測作用,尤其體現(xiàn)在視覺詞,這一結(jié)果與量表中的相關(guān)項目(如“我覺得別人在注意我”)相吻合。研究者普遍認為,羞怯包含個體對他人如何看待和評估自己的擔憂,當個體關(guān)注他人對自己的印象時,往往會激起羞怯的相關(guān)反應(yīng)(Leary & Schlenker,1981;Leary,1983;Schlenker & Leary,1982),較多的感知歷程詞體現(xiàn)出高羞怯行為個體在日常生活中頻繁地感覺到被注視、被評價,充分反映出羞怯個體的過度自我中心以及過度關(guān)注社會評價的特點(Zimbardo,1982)。
生理歷程詞對羞怯情緒具有明顯的負向預(yù)測作用,尤其體現(xiàn)在攝食詞。基于新浪微博的研究結(jié)果顯示,攝取詞與神經(jīng)質(zhì)呈顯著正相關(guān)(Gu et al.,2018),而羞怯與神經(jīng)質(zhì)也顯著相關(guān)(Hofstee et al.,1992;Jones et al.,2014;Kwiatkowska et al.,2019;La Sala et al.,2014;Sato et al.,2018)。進食障礙個體往往存在社會依賴與自主的趨避沖突,渴望保持獨立的同時也依賴人際關(guān)系以維持自尊(Narduzzi &Jackson,2000),并且存在對錯誤的過度關(guān)注和對自我表現(xiàn)的焦慮(Cassin & von Ranson,2005),這些特征均與羞怯個體相似。
4.2 基于文本特征構(gòu)建分類模型能夠預(yù)測小學生羞怯水平
基于卡方算法識別重要的詞頻特征,據(jù)此構(gòu)建分類預(yù)測模型并計算模型的各個精度指標,在識別重要特征組合的同時,保證了模型的預(yù)測效果。結(jié)果顯示,隨機森林在三個維度的表現(xiàn)較為均衡。已有研究中,同樣有研究者采用隨機森林在人格預(yù)測、心理問題篩查等任務(wù)中達到最優(yōu)效果(Chen et al.,2017;Kwiatkowska et al.,2019;Papamitsiou &Economides,2017;Skowron et al,2016)。
由于前人尚未有針對羞怯特質(zhì)的文本挖掘研究,因此將已有的人格預(yù)測研究結(jié)果與本研究對比分析。已有基于LIWC 提取特征預(yù)測Facebook 用戶的大五人格的研究中,模型最終準確率、召回率以及F1 值往往在45%~65%范圍內(nèi)(如,F(xiàn)arnadi et al.,2013;Marouf et al.,2019),本研究結(jié)果接近已有研究結(jié)果,顯示出基于在線寫作文本預(yù)測小學生羞怯特質(zhì)的可行性,尤其是模型的特異度很高(大于0.9),說明對普通群體的誤判非常小。羞怯情緒維度的敏感度在0.4 左右,其它兩個維度在0.2 左右,這個結(jié)果并不理想,這主要是由于本研究的主要目標為探索小學生羞怯在詞匯層面的表現(xiàn),模型僅納入詞頻特征,未采用對語言風格不具有可解釋性的文本向量化表征方式,因此預(yù)測力有限。已有研究顯示,采用多元類型的特征(如用戶的在線社交網(wǎng)絡(luò))以及深度學習模型,能夠明顯提高預(yù)測效果(Aung & Myint,2019;Farnadi et al.,2013;Tandera et al.,2017),比如,F(xiàn)arnadi 等人(2013)在詞匯特征的基礎(chǔ)上加入社交網(wǎng)絡(luò)特征,模型的預(yù)測準確率從54%提升至71%。因此,未來將嘗試在已有發(fā)現(xiàn)的基礎(chǔ)上,結(jié)合學生的在線行為數(shù)據(jù)等特征,構(gòu)建更加復(fù)雜且具有良好解釋性的模型。此外,羞怯群體的準確率和召回率不高,而且交叉驗證的結(jié)果也顯示羞怯群體的穩(wěn)定性相對差一些,這一情況主要是受到了樣本類別分布不均衡的影響(Diamantidis et al.,2000;Oommen et al.,2011),未來將持續(xù)收集文本數(shù)據(jù),擴充文本數(shù)據(jù)庫,提升模型的預(yù)測效果。
目前,學生在教學平臺上學習并在線完成作業(yè)和任務(wù)逐漸成為常態(tài),未來必將產(chǎn)生更大量級的數(shù)據(jù),為研究者基于文本挖掘?qū)W生心理品質(zhì)提供豐富的原始語料。心理學研究應(yīng)當充分發(fā)揮這一數(shù)據(jù)資產(chǎn)的價值,來挖掘和揭示心理特點和規(guī)律。本研究旨在探索基于在線教學平臺上的文本數(shù)據(jù)來揭示和預(yù)測心理特質(zhì)的新方法,期望為未來更多相關(guān)研究的開展提供參考。
5 結(jié)論
本研究嘗試利用文本挖掘技術(shù)對小學生在線寫作文本進行分析,挖掘羞怯特質(zhì)的詞匯特征,構(gòu)建小學生羞怯特質(zhì)的語言風格模型并實現(xiàn)自動預(yù)測。本研究的主要結(jié)果如下:
(1)基于真實的小學生文本對“文心詞典”進行擴充,構(gòu)建出適用于兒童的心理詞典,實現(xiàn)更為精準的特征提取,并利用卡方算法篩選文本特征,構(gòu)建出羞怯特質(zhì)的多維度語言風格模型,識別出羞怯在行為、認知及情緒上的文本表現(xiàn)的共性和差異;(2)基于篩選后的詞典特征建立多種預(yù)測模型,顯示出機器學習模型在檢測小學生羞怯特質(zhì)上的有效性。
本研究揭示了小學生羞怯行為、羞怯認知和羞怯情緒的語言風格和詞匯使用特點,為研究者更加深入地了解羞怯個體提供建議和啟發(fā)。同時,本研究采用詞匯特征構(gòu)建多種機器學習模型,為未來采用更豐富的特征以及深度學習模型預(yù)測羞怯提供了基礎(chǔ)。
猜你喜歡
甘肅教育(2020年22期)2020-04-13 08:10:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小天使·一年級語數(shù)英綜合(2016年5期)2016-05-14 12:21:05
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
河南科技(2014年23期)2014-02-27 14:19:15
