基于時空緩存數據庫的醫院圖書館人臉識別應用研究
2021-02-28 02:37:46馮瑛
電氣自動化 2021年6期
馮瑛
(延安市人民醫院,陜西 延安 716000)
0 前 言
醫院圖書館管理關系到醫護人員借閱的便捷性,也是醫院技術水平提高的象征性標志之一[1]。現有技術中,出入醫院圖書館的人員大多采用電腦登記和刷卡方式進行管理,這種方式管理落后。
隨著人工智能和人臉識別技術的逐步發展和應用,在醫院圖書館中,出現了相關技術研究[2]。文獻[3]公開了一種將人臉識別和門禁系統相結合的方法,這種方法雖然能夠在一定程度上解決醫院圖書館的安全性問題,但是人臉識別系統還是存在高錯誤率。文獻[4]公開了一種打破傳統的新型Adaboost算法,將這個算法運用到人臉識別中。這種方法雖然能夠在一定程度上增加人臉識別的準確率,但是在人多情況下識別需要消耗大量的時間[5]。針對上述技術問題的不足,本文采用一種新型的圖書館人臉識別方法。
1 總體方案結構圖
本文應用了一種時空緩存數據庫的管理方法,該方法將時空數據模型和新型Adaboost算法恰當地融合在一起,能夠實現進出圖書館人臉信息的動態索引和查詢,進而解決現有技術中人臉識別技術的識別準確率差和速度慢的問題[6],其中時空數據模型在實際應用中有多種形式,例如時空耦合模型、連續快照模型、基態修準模型、立體時空模型和時空對象模型等。模型以時空數據庫為基礎,對采集到的醫院圖書館人臉數據信息進行綜合管理。本文方案的總體架構如圖1所示。
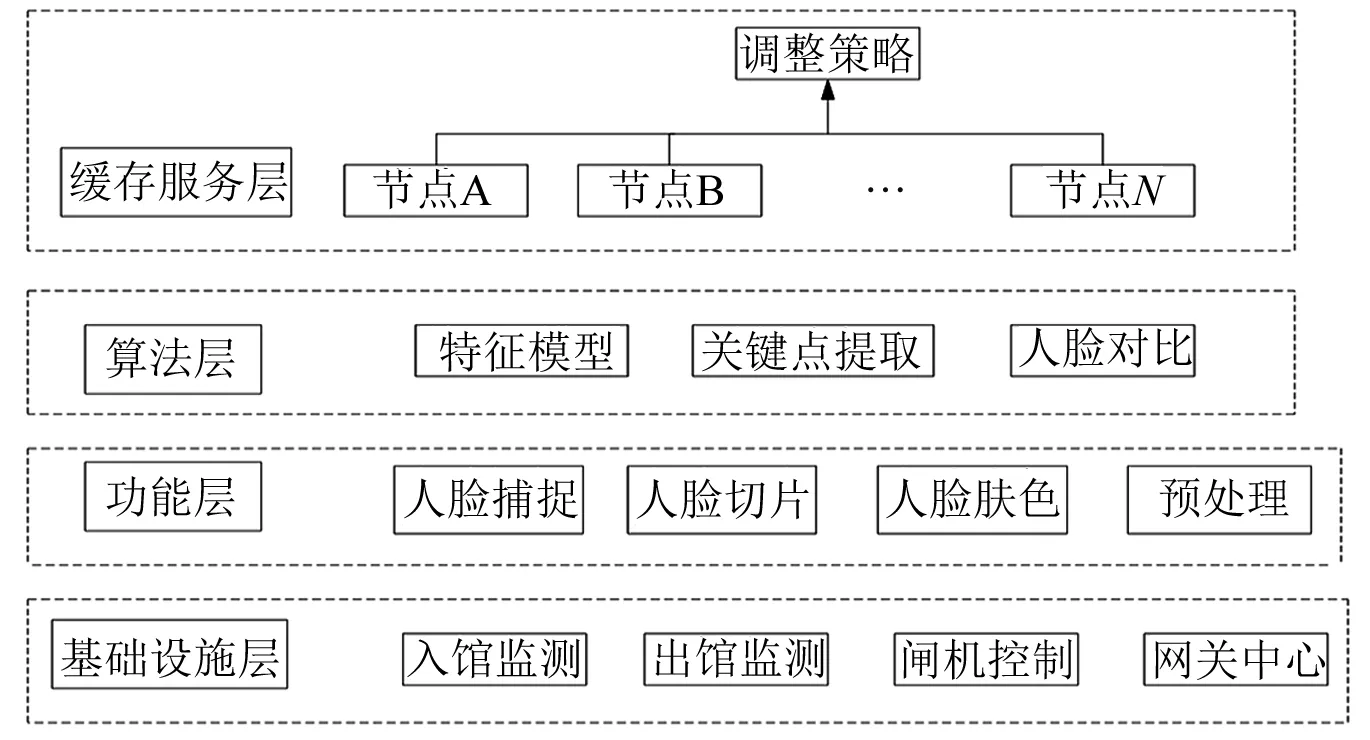
圖1 總體架構示意圖
在本文研究的技術方案中,將整體的結構圖劃分為多個不同模塊,這些模塊分別為基礎設施層、功能層、算法層和緩存服務層4個模塊,通過這4個模塊,能夠實現圖書館入館人員的信息監測、信息捕捉、特征算法和人臉對比等處理,最終實現人臉識別應用。下面分別進行說明。
(1) 基礎設施層。基礎設施層主要是醫院圖書館的門禁系統的操作設施,其中包括入館監測、出館監測、閘機控制和網關中心。入館監測和出館監測均通過智能攝像頭智能掃描采集人臉圖像數據信息。閘機控制在接收到人臉識別正確的數據信息后自動開啟,紅外線掃描人員通過后自動關閉等待下一個信息。網關中心主要是保證網絡的通信正常和安全,若出現緊急狀況則放棄閘機通道開啟緊急安全通道,人員進行人臉識別記錄后直接穿過即可。
(2) 功能層。功能層為基礎設施層提供相關的技術支持,該層主要是對人臉數據的收集和預處理。當人員人臉對上智能攝像頭時,采用靜態圖像分析人臉的不同位置、不同角度和不同表情收集數據信息進行保存。人臉切片是對于人臉的小范圍進行識別掃描,這樣能將人臉特征識別得更為細微精確。通過小區域的人臉膚色特征,首先選擇顏色空間,然后根據亮度的分級和色度值分類,接著建立膚色特征模型,最后將人臉圖像數據信息進行簡單的預處理。
(3) 算法層。算法層是根據功能層提供的數據信息進行分析計算,將結果反饋至基礎設施層。算法層包含的內容有特征模型、關鍵點提取和人臉對比。關鍵點提取是把特征模型的圖像信息進行數字化,得到這個特征的人臉編號序列。人臉對比是利用緩存服務層搜索不同的人臉編號序列,并對比不同人臉的特征模型,從中來判斷該人臉圖像數據信息是否需要進行緩存。
(4) 緩存服務層。緩存服務層是為算法層提供很好的訪問性能。該層是利用Redis集群構建時空緩存數據庫,用來存儲人臉圖像的數據信息,為算法層進行人臉對比提供便利。
2 關鍵技術設計
在實際工作中,圖書館人員進出比較復雜,采集到的圖片信息蘊含了多種具有多維度和時間維度的數據量,基于這些數據量,常規技術的索引和查詢方式在動態識別人臉方面顯得尤為困難。因此,為了提高圖書館人臉識別水平,動態檢索和查詢就非常必要。本文還通過Redis集群分布式緩存構架實現圖書館的時空緩存數據庫數據存儲,這種方法能夠解決圖像識別困難和識別時間長的問題。
2.1 Adaboost算法模型在人臉識別中的應用
本文采用改進型Adaboost算法,分類模型架構如圖2所示。
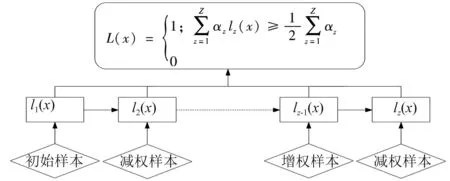
圖2 Adaboost算法模型應用示意圖
Adaboost算法模型的應用過程說明如下:
(1) 假設將進出圖書館的人臉特征集合記作為{(x1,y1),(x2,y2),…,(xn,yn)}。在該數據集合中,將x記作為一種類型的人臉特征,用字母y表示經過分類器分類后的人臉特征標識,為了區分對待,將人臉特征可以記為0和1。在y=0的情況下,該特征表示為非人臉數據樣本,在y=1的情況下,表示該特征為分類屬性范圍內的人臉樣本。n為分類特征中人臉特征類型的數量[7]。
(2) 然后對分類后的人臉特征進行賦值、計算,其中賦值的數據集合記作為:
D={D0,1,D0,2,…,D0,n}
(1)

(3) 然后再歸一化處理分類器輸出的人臉特征樣本權值,輸出的樣本數據集合為:
pz={pz,1,pz,2,…,pz,n}
(2)
式中:pz為人臉特征樣本權值;pz,n為第n特征集合的人臉特征樣本權值。
(3)
式中:πz,n為分類器的屬性。
(4) 經過權值歸一化處理后,弱分類器可以轉換為以下形式:
lz:{x1,x2,…,xn}→{0,1}
(4)
式中:xn為不同的弱分類器。每個不同的分類錯誤率可以通過式(5)來表示。
(5)
式中:ξz為分類錯誤率;Pz,j為第j特征集合的人臉特征樣本權值;hz(xi)為分類器;yi為第i個數據集。
(5) 在歷經弱分類器經過Z次分類后,弱分類器可以轉換成強分類器L(x),可以通過式(6)表示。
(6)
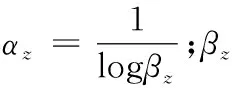
經過上述公式討論后,再進行圖書館人臉識別時,可以針對不同類型的用戶進行人臉識別,大大提高了人臉識別程度。針對非人臉特征樣本的圖像識別如圖3所示。
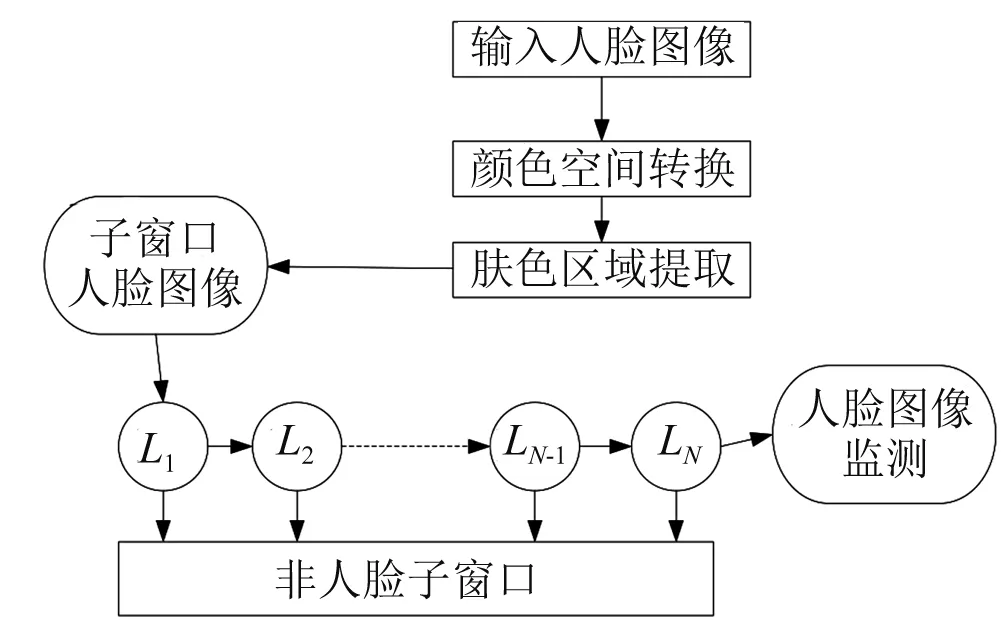
圖3 非人臉特征樣本處理示意圖
在進行非人臉特征樣本進行識別時,首先需要設置分類閾值,如果抽取的樣本數據信息的權值處于設定的閾值范圍內,可以再進一步增加樣本的權值。當抽取的樣本數據信息的權值沒有在設定的閾值范圍內時,則將權值進行減小處理。由于選擇的弱分類器不同,輸出的權值也不同。通過調整不同分類器的權值,可以提高樣本訓練的正確率。而強分類器是將多種強分類器串聯在一起,每個強分類器都由多種弱分類器組合而成,這樣通過多層次地對人臉特征進行篩選,提高了人臉精度。
在上述步驟中,尤其是在提取膚色區域時,需要構建膚色模型。這是由于膚色模型不同,需要構建不同的數學建模,以進一步描述膚色在不同色彩空間之間的分布情況,通過這種方式,能夠識別出圖像中那些部分屬于膚色[8]。再進行閾值計算,通過閾值的不同,能夠構建起膚色模型和非膚色模型,通過這種方式以將膚色區域和非膚色區域區分開來。
2.2 Redis集群設計
2.2.1 Redis和Redis集群
Redis集群和Memcached集群在結構上比較類似,都是NoSQL中的一種,屬于內存比較高、運行比較快的高性能key-value(k-v)數據庫。這種方式與Memcached所表現不同的是,Redis集群能夠支持string、list、set、zset(sorted set)和hash類型數據類型,上述的這些數據類型大部分都能夠支撐push/pop、add/remove交集、并集和差集等多種、多項操作,與memcached集群表現形式比較類型。在工作過程中,為了保證數據集合的應用效率,大部分數據被緩存在內存中[9]。有待區分的是redis集群,該集群能夠周期性地把更新后的數據信息讀入磁盤,或者將修改后的操作信息存儲到記錄文件中,進而使得master-slave能夠實現(主從)同步工作。在應用redis集群之后,能夠將memcached集群這類key/value存儲信息的不足給充分地利用起來。該數據庫信息提供了多種應用信息,比如Java、C/C++、C#、PHP、JavaScript、Perl、Object-C、Python、Ruby和Erlang等客戶端。
2.2.2 Redis-Cluster 集群構建時空緩存數據庫
在對Redis進行初始分布時,通常應用分片的方式進行,在具體應用時,應用客戶端和Proxy分片的方式進行,在應用客戶端時,在水平方面的擴展程度比較不易,硬件資源內耗比較大,需要的硬件環境也比較高。需要在Redis3.0集群的情況下提出Cluster集群模式,模式示意圖如圖4所示。

圖4 Redis-Cluster集群架構示意圖
通過圖4可以看出,當應用Redis-Cluster集群時,通常是無中心結構的。圖4中的每個應用網絡節點都能夠將數據和整個集群狀態存儲起來,其中節點之間實現了互聯互通,不同的Redis節點之間互聯(PING-PONG機制)過程中實現信息交互。集群架構中還使用二進制協議進行數據優化,以進一步優化網絡的傳輸速度和帶寬。網絡節點的fail能夠借助于集群中節點(通常超過一半)才能實現正常工作。
在客戶端,通過將應用的硬件設備與Redis節點實現直接連接,該過程無需中間Proxy層即可完成。因此,在客戶端應用的用戶不必連接集群內的所有節點,任意一個連接節點即可滿足需求。在應用過程中,還需要根據人臉識別系統,對 Redis集群的應用方法進行設置或者配置。
(1) 節點的配置或者創建。對三個不同的主節點進行創建,假設其不同的節點分別為 A、B、C,并且A、B、C三種不同的節點可以分別為一臺機器上的三個端口,也可以為三臺不同的服務器的三個節點。
(2) 空間分片。空間分片能夠實現節點數據的快速應用,在具體工作時,能夠采用哈希槽 (hash slot)對16 384個slot進行分類,如果應用了3個不同的節點,則這三個節點能夠實現不同的應用功能,比如在slot 區間范圍內:在節點A,能夠覆蓋0~5 460范圍內的數據信息;在節點B,能夠覆蓋5 461~10 922范圍內的數據信息;在節點C,能夠覆蓋10 923~16 383范圍內的數據信息。在具體應用過程中,假設對一個數據信息數據進行存儲,可以根據Redis-Cluster哈希算法進行計算,計算式有:
CRC16(‘key’)384 = 6 782
在這種情況下,能夠將key 的數值存儲在B中。通過這種方式,當對(A,B,C)內任一節點進行“key”信息獲取時,能夠將內部節點跳轉到B節點,以進一步獲取相關數據信息。
(3) 節點時間調度。如果在應用過程中,需要對某個節點進行增加或者刪除,集群量不會減少,集群過程也不會停止。根據該原理,在大量人員入館和離館過程中,將全部的緩存節點緩存起來,能夠大大提高進入館人員的人臉識別度。
3 仿真試驗與分析
為了能夠證實Redis集群構建時空緩存數據庫能夠提高人臉識別技術的計算速度、增強過的Adaboost算法能夠提高人臉識別準確率,下面將分別進行仿真試驗。
3.1 Redis 集群的構建時空緩存數據庫
首先要構建Redis 集群,來檢驗人臉識別系統加入時空緩存數據庫能有效地提升識別計算速度。本文采用CentOS6.8(x64)操作系統、4.0.1版本的Redis和2.4.6版本的ruby腳本,Intel(R) Xeon(R) CPU E5-2640 v2、2.00 GHz主頻、千兆網卡、8核16G內存、512 GB硬盤的硬件環境[10]。創建三個服務器主節點,分別復制備份出2個虛擬節點,一共9個節點搭建Redis集群作為分布式緩存。為了檢驗各種類別測試人臉特征的識別效果,試驗調取了100張人臉圖像,從不同年齡段、不同性別、不同膚色和不同人臉角度分別測試每張圖像的識別效果。采用時空緩存數據庫和Redis集群的識別時間,與傳統人臉識別方法識別的時間進行對比,結果如表1所示。

表1 人臉識別耗時對比 ms
如表1所示,有關人臉識別的四個數據類型,采用100張人臉圖像,基于時空緩存數據庫和Redis集群的識別方法與傳統識別方法相比,耗時全部都要短。為了對比更加清晰,本文將以柱狀圖形式展現,對比示意圖如圖5所示。

圖5 人臉識別耗時對比圖
如圖5所示,用時空緩存數據庫和Redis集群使人臉識別的執行速度得到有效提升,比傳統識別方法快了大約10%。因此得出結論:對于醫院圖書館人臉識別系統來說,構建時空緩存數據庫的效果還是很明顯的。
3.2 Adaboost算法驗證
與傳統的Adaboost算法不同,本文采用的新型Adaboost算法在漏檢率方面大大降低,下面來進行仿真試驗。采用Pentium(R)CPU、8核16G內存,電腦的硬盤容量為256G的硬件環境,軟件的操作系統Windows XP, JDK1.5,通過MATLAB軟件系統進行仿真。分別對單人臉的正面、單人臉側面和多人臉正面圖像進行識別,數量均為 100張人臉圖像,統計成功識別的次數,結果如表2所示。
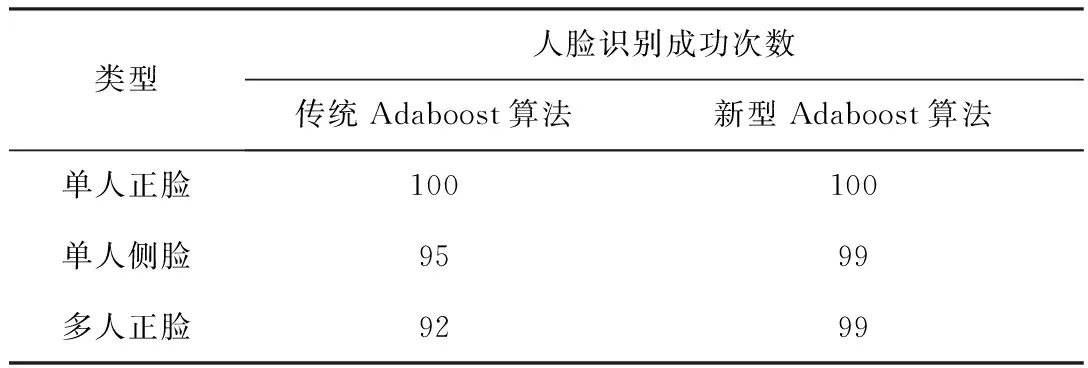
表2 人臉識別成功次數對比 次
通過上述數據,在單人正臉方面,由于人臉識別比較容易,傳統Adaboost算法和改進過的Adaboost算法均能全部成功識別,沒有表現出差距。在單人側臉和多人正臉方面,存在識別的關鍵點減少等因素影響,有時會無法完全識別人臉圖像特征,識別率為95%和92%。根據膚色特征可以大大減少上述因素的影響,利用新型的Adaboost算法識別率均提高到99%。仿真試驗結果表明:新型Adaboost算法可以提高準確度。
4 結束語
本文基于時空緩存數據庫設計了新穎的人臉識別系統,利用Redis集群在空間上增減節點的同時,在時間上對不同的節點設置不同的停止服務時間,達到時間和空間上的緩存優化,可快速且高效地進行人臉識別。類似人臉識別這樣的智能技術與傳統圖書館服務的結合,也必將為智慧圖書館的建設帶來更廣闊的發展空間。
猜你喜歡
作文中學版(2022年1期)2022-04-14 08:00:34
學生天地(2020年31期)2020-06-01 02:32:06
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
計算機工程(2015年8期)2015-07-03 12:19:07
