目標上下文卷積神經網絡高分遙感影像語義分割
2021-03-03 01:20:28劉艷飛丁樂樂孟凡效
遙感信息 2021年6期
劉艷飛,丁樂樂,孟凡效
(天津市勘察設計院集團有限公司,天津 300000)
0 引言
隨著高分辨率遙感衛星的成功發射,高分辨率遙感影像已經成為對地精細觀測的重要數據來源,為地理國情普查、數字城市建設、精細農業等科學和生產領域提供了數據支撐。然而,高分辨率遙感影像所具有的可用光譜波段少、影像信息高度細節化、“異物同譜,同物異譜”等特點為高分辨率遙感影像的分類識別帶來了困難和挑戰。針對高分辨率遙感影像語義分割任務,國內外學者展開了系列研究,并形成了基于空間結構特征的分割方法[1-3]、面向對象的分割方法[4-6]、基于空間上下文的分割方法[7]和基于深度學習的分割方法[8-12]。
基于空間結構特征的方法挖掘像元和鄰域像元的空間模式,提取各種形式的空間結構特征。如何挖掘影像的空間信息,獲取描述地物目標的特征是該方法的關鍵,常用的空間結構特征主要有紋理特征和幾何特征。如Zhao等[13]利用高斯馬爾可夫隨機場提取紋理特征用于高分影像語義分割,Huang等[14]基于加權均值、長寬比和標準差等統計幾何信息構建空間結構特征用于像素表達。面向對象的分類方法將無監督分割和語義分割結合,不再將單一像元作為特征提取和分割的研究單元,通過無監督分割獲得同質性區域,然后從同質性區域中提取特征并用于同質性區域的語義分割。如許高程等[15]通過多尺度分割在SPOT 5衛星影像上獲取不同空間尺度結構下海域使用的地物斑塊,并從分割對象中提取光譜、形狀和語義特征,建立分類規則集,實現池塘養殖用海域的信息提取。曹凱等[16]采用面向對象的方法對南京市區部分主城區進行水體提取,基于空間上下文的分割方法假設相鄰像元更可能屬于同一地物類別。首先通過面向像素的分割方法獲得類別概率圖,然后基于局部濾波或者擴展隨機游走算法對類別概率圖進行精化,從而得到最終考慮空間信息的分類結果。Zhao等[17]在成對條件隨機場模型的基礎上,集成光譜信息、局部空間上下文信息以及空間位置信息構建高階勢能函數挖掘影像的大尺度空間上下文信息,從不同視角提供地物判別的互補信息,提高分類制圖效果。Zhang等[18]提出用超像素代替單個像素用于條件隨機場構圖,提出超像素-條件隨機場模型考慮空間上下文用于高分影像語義分割。
以上三類方法都需要手工設計特征以及專家先驗知識,而且分類過程和特征提取過程分離,分類器無法為特征提取過程提供指導監督信息。深度學習作為一種數據驅動的模型方法,可以從數據中自動學習特征,且在深度學習模型中,分類器也被設計為網絡的一層,完成了形式的統一,實現特征提取和分類器學習過程的一體化。由于深度學習強大的特征學習能力,已經被成功應用于高分遙感影像語義分割,并獲得廣泛關注。如Tao等[19]為解決高分影像語義分割中網絡深度增加導致的梯度彌散問題,提出稠密連接網絡實現網絡深度和表達能力的平衡。
在高分影像語義分割中,由于 “異物同譜,同物異譜”問題,單純依靠光譜信息無法對地物目標進行精細分類,還需依賴像素空間上下文進行特征提取和分類。卷積神經網絡通過堆疊卷積層、池化層進行層次化特征提取,隱式地將空間上下文信息融合到特征提取過程中。然而這種方式僅僅融合了像素自身局部范圍的上下文信息,忽略了全局影像中同類目標像素之間的關系。針對這一問題,本文顯式地對全局空間目標上下文建模,將目標上下文卷積神經網絡(object-context representation CNN,OCRNet)[20]用于高分遙感影像語義分割。OCRNet包含雙分支網絡,分別為粗分割分支和精分割分支。首先,利用粗分割分支獲得每一個像素的類別概率分布;然后,基于粗分割分支得到的類別概率分布和精分割的特征圖計算每個類別的特征中心,根據類別特征中心對每個像素進行編碼得到編碼特征;最后,將像素的編碼特征和精分割特征疊加作為最終的表達特征用于精分割分支的語義分割任務。
1 目標上下文卷積神經網絡高分遙感影像語義分割
本文采用的方法主要包含四個部分,即骨干網絡特征提取、粗語義分割、全局類別中心計算和精細語義分割。總體流程圖如圖1所示。

圖1 目標上下文卷積神經網絡高分遙感影像語義分割流程圖
設輸入影像為I∈RH×W×C及其對應的標注影像為Y∈RH×W,其中H、W、C分別表示影像的行、列和通道數,在本文中通道數為3,即C=3。對于輸入影像I,本文利用HRNet作為骨干網絡進行基本特征提取,得到基礎特征fb,如式(1)所示。
fb=backbone(I)
(1)
式中:backbone表示骨干網絡;fb表示提取得到的基礎特征圖。對于得到的基礎特征圖fb,對其進行上采樣至H×W,并進行卷積操作,得到像素特征圖fp=RH×W×S,其中每一個位置處的向量表示像素的特征向量。
在粗語義分割階段,本文將特征圖fb作為粗語義分割網絡分支輸入進行初步語義分割,得到粗語義分割圖fcorse∈RH×W×Cla,其中Cla表示類別數,如式(2)所示。
fcorse=branch-corse(fb)
(2)
式中:branch-corse為粗語義分割模塊。在訓練階段,得到fcorse后,計算粗語義分割損失函數,如式(3)所示。
Lcorse=CrossEntropy(fcorse,Y)
(3)
式中:CrossEntropy表示交叉熵損失函數。在粗語義分割模塊branch-corse的Cla個通道輸出中,每一個通道代表像素對某一類別的響應。因此,在某一類別對應的通道上,屬于該類別的像素在該通道上響應值大,不屬于該類別的像素在該通道響應值小。在全局類別中心計算階段,本文利用這一特性從全局中考慮空間上下文,獲得每一類像元在特征空間的類別中心。本文將fcorse的每一通道分別進行歸一化,并將之作為權值獲得該類別對應的類別中心,如式(4)所示。
(4)
式中:mk∈RH×W為fcorse歸一化后的第k通道,fcorse,k∈RH×W為fcorse的第k通道,fcorse,k,i∈R表示第i個像素在通道k上的響應值。得到權重mk后,計算每一類對應的特征中心,如式(5)所示。
(5)
式中:fp,i∈RS為像素特征圖fp的第i個特征向量;mk,i表示第權重圖mk的第i個元素;fcentor,k為第k類的類別中心。
在精細語義分割階段,本文利用得到的類別中心作為碼本對像素特征fp進行編碼,得到新的編碼特征fc∈RH×W×T,實現全局信息融合,如式(6)所示。
κ(a,b)=φ(a)Tψ(b)
(6)
(7)
(8)
式中:κ(·)為距離函數;φ(·)、ψ(·)、σ(·)和ρ(·)為轉換網絡,其網絡結構為1×1卷積層-BN歸一化層-ReLU響應層;wi,k為像素-中心關系矩陣w中的元素,表示第i個像素與第k個類別中心的編碼權重;fc,i為全局編碼特征圖fc的第i個元素,表示第i個像素的編碼特征。通過這種編碼方式,編碼特征fc融合了全部范圍內的空間上下文信息。在本文中,得到編碼特征fc后,將編碼特征與像素特征進行疊加和轉化,得到最終的深度融合特征ffus用于遙感影像語義分割,表達如式(9)至式(10)所示。
fcon=[fp,fc]
(9)
ffus=g(fcon)
(10)
式中:[·]表示將兩個特征圖首尾相連進行疊加;g(·)為轉換網絡,網絡結構同樣為1×1卷積層-BN歸一化層-ReLU響應層。利用ffus進行精細化分類,表達如式(11)至式(12)所示。
ffine=conv1×1(ffus)
(11)
Lfine=CrossEntropy(ffine,Y)
(12)
式中:conv1×1(·)表示1×1卷積。本文的最終目標函數L如式(13)所示。
L=Lfine+λLcorse
(13)
式中:λ為粗語義分割分支損失函數權重。
在本文采用的方法中,粗語義分割分支提供了基本的類別信息用于對精細分割分支像素特征進行全空間區域的“軟聚類”,獲得精細分割分支像素特征空間的語義類別中心,并以此為碼本對精細分支像素特征進行編碼,建立單個與全局內其他同類像素的空間聯系,融合全局內同類像素的信息,提高表達能力。相比于傳統僅通過逐層卷積來考慮局部區域像素之間空間關系的高分語義分割方法,本文采用的方法為像素之間建立了更為廣闊的空間聯系。
2 實驗與分析
2.1 實驗設置
數據集上選用GID[21]和WHU building 數據集[22-23]兩個數據集進行實驗。GID數據集包含150張高分2號衛星影像,每張影像大小為6 800像素×7 200像素,包含建筑物、農田、森林、草地和水域五個類別。在實驗中隨機抽取120張影像用于訓練,剩余30張用于測試。WHU building數據集是建筑物提取數據集,包含四個子數據集,本文使用WHU building 數據集中的aerial imagery dataset和building change detection dataset兩個子數據集進行實驗,其中選用“the cropped image tiles and raster labels”和“a_training_aera_before_change”兩個數據作為訓練集進行模型訓練,選用“after_change”和“before_change”作為測試集(測試集為同一區域不同時期的兩幅影像)。在實驗中,為避免顯存溢出問題,本文將每張影像切割成512×512大小作為輸入用于模型訓練。圖2為實驗數據代表樣本。為使網絡獲得一個較好的初始化,本文選用在cityscapes數據集[24]上進行過預訓練的HRNet對骨干網絡參數進行初始賦值。實驗在配置有10塊Nvidia 2080Ti顯卡服務器上進行,迭代次數為3 000,初始學習率為0.003,學習率變化策略為多項式衰減,衰減參數power為0.9,最小學習率設置為0.001,優化方法選用隨機梯度下降。本文選用FCN、DeepLabV3Plus[25]、PSPNet[26]、PointRend[27]等方法進行對比實驗,采用Kappa系數、總體精度OA、平均交并比MIoU、每類分類精度作為評價指標,對于WHU building dataset,另增加一個交并比IoU作為評價指標。

圖2 實驗數據示例樣本
2.2 實驗結果與分析
1)GID數據實驗。表1給出了本文的方法OCRNet與對比方法在GID數據集上的語義分割結果。從表1可以看出,本文采用的方法OCRNet在GID數據集上的Kappa、平均交并比MIoU以及總體精度OA分別為97.14、95.08和97.99,獲得了最優的分割結果,相比于次優的PointRend,在Kappa、MIoU、OA三個指標上分別提升0.9、1.87、0.6,有效證明了OCRNet有效性。在單類分割結果上,本文的方法OCRNet在建筑物,草地以及水域三個類別獲得最高的分割精度,在農田和森林上低于DeepLabV3Plus的結果,在這兩個類別獲得次優的分割精度。圖3給出了本文的方法OCRNet和對比方法在GID數據集上的可視化對比情況,其中GT表示真實標注影像。從Image的區域1和區域2中,對比方法分別將水域錯分為農田、農田錯分為水域,而本文的方法OCRNet對每一個像素在全局范圍內提取上下文信息精細融合,有效地減少了水域和農田的錯分。然而在邊界處,如Image中的區域2處,OCRNet仍然無法完全消除類別之間的錯分現象,這主要是因為卷積神經網絡在卷積的過程中不可避免地會造成圖像的空間平滑,使得在類別邊緣處造成錯分。

表1 GID數據集語義分割結果評價表 %

圖3 OCRNet及其他方法在GID數據集上的分類結果可視化對比
2)WHU building數據實驗。為進一步驗證OCRNet的有效性,本文在WHU building數據集進行實驗。表2給出了在WHU building數據集上的對比實驗情況。從表2可以看出,OCRNet在Kappa系數、平均交并比MIoU、總體精度OA、每類分類精度以及交并比IoU等五個指標上均高于對比方法,取得最優的分割精度,其中在IoU指標上,相對于次優方法FCN,在IoU指標上有2.17個點的提升,證明了算法在提高語義分割精度方面的有效性。圖4給出了所有方法在WHU building數據集上的可視化分割結果。對于區域2、3、4,對比方法FCN、DeepLabV3Plus、PSPNet和PointRend得到的分割結果較為破碎,而采用的OCRNet對每一個待分像素在全局范圍內進行空間信息融合,可以有效地獲得影像中同類像素的信息用于最終的表達,所以相比于對比方法,可以獲得完整的分割結果。在區域1上,OCRNet仍然獲得相對較為完整的建筑物提取結果,然而在局部區域存在提取不完整的現象。圖5給出了OCRNet在其中一張測試數據上的建筑物提取結果。

表2 WHU Building數據集語義分割結果評價表 %

圖4 OCRNet及其他方法在WHU building數據集上的分類結果可視化對比

圖5 OCRNet在WHU building數據集上的建筑物提取結果
本文采用的WHU building測試數據集為同一地區的不同時相數據,因此本文對兩時相的分割結果做對比,獲得建筑物的變化情況。表3給出了對比方法與OCRNet在該數據集上的變化檢測精度。從表3可以看出,在召回率Recall這個指標上,OCRNet與FCN、PointRend相比沒有提升,略有下降。然而在Precession和F1分數指標上,OCRNet均有明顯提升,在Precessions上與PSPNet相比提升7.13(從85.43提升至91.73),證明OCRNet在該數據集上具有更低的虛警率。圖6展示了OCRNet在WHU building數據集上的建筑物變化檢測結果,區域1和區域2為OCRNet提取出完整的變化圖斑,區域3為漏檢圖斑,區域4為虛警。

表3 WHU Building建筑物變化檢測結果評價表 %
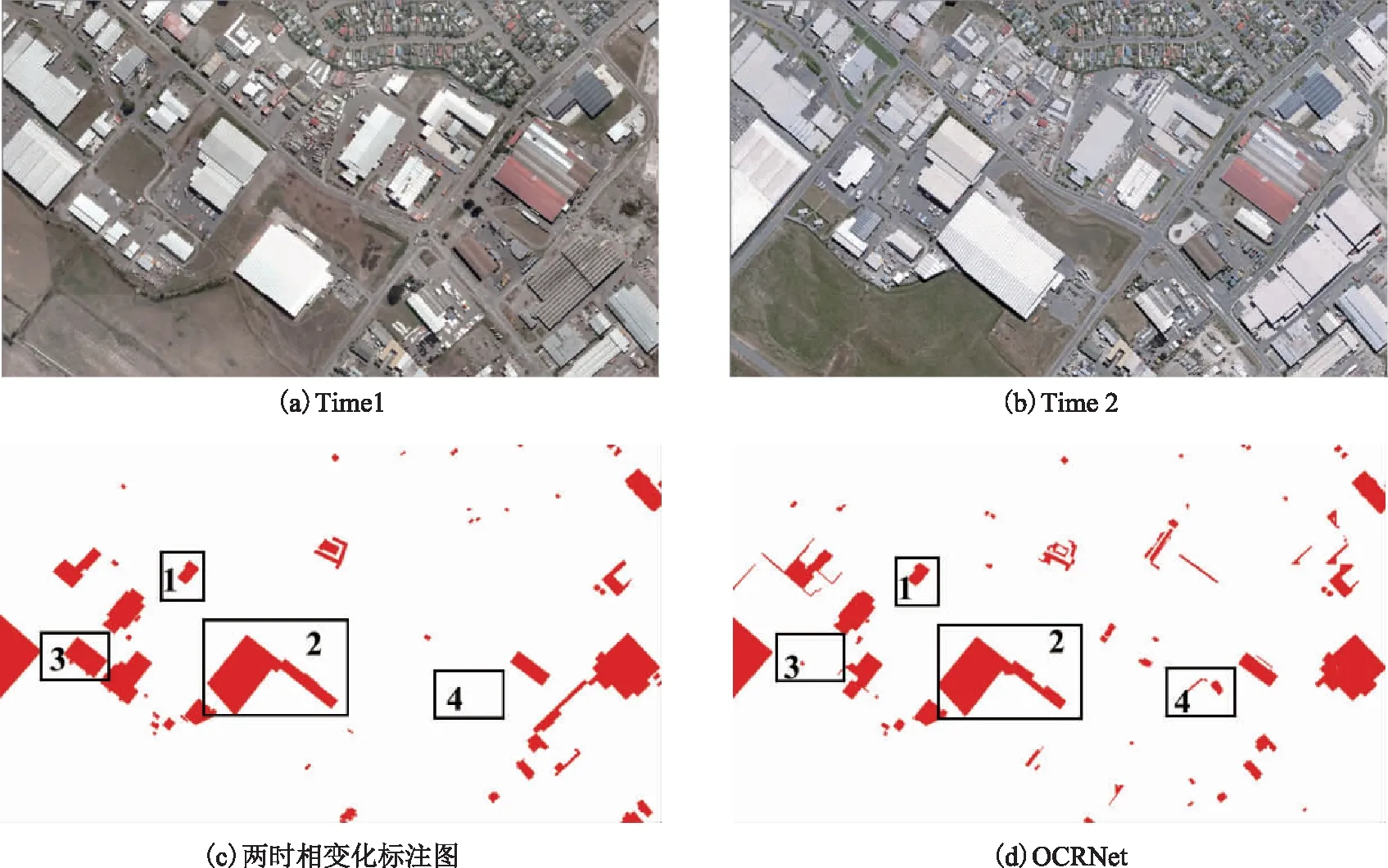
圖6 OCRNet在WHU building數據集上的變化檢測結果
2.3 參數分析
在本文使用的方法中,同時訓練粗語義分割分支和精細語義分割分支,并將兩個分支的損失函數進行加權疊加,加權系數為λ。為研究加權系數λ對語義分割結果的影響,本文分別令λ={0.2,0.4,0.6,0.8,1.0}進行實驗。實驗結果如圖7所示,其中MIoU、Kappa和OA為本文中網絡最終預測時的分割結果,C-MIoU、C-Kappa和C-OA為粗語義分割分支的分割精度指標。
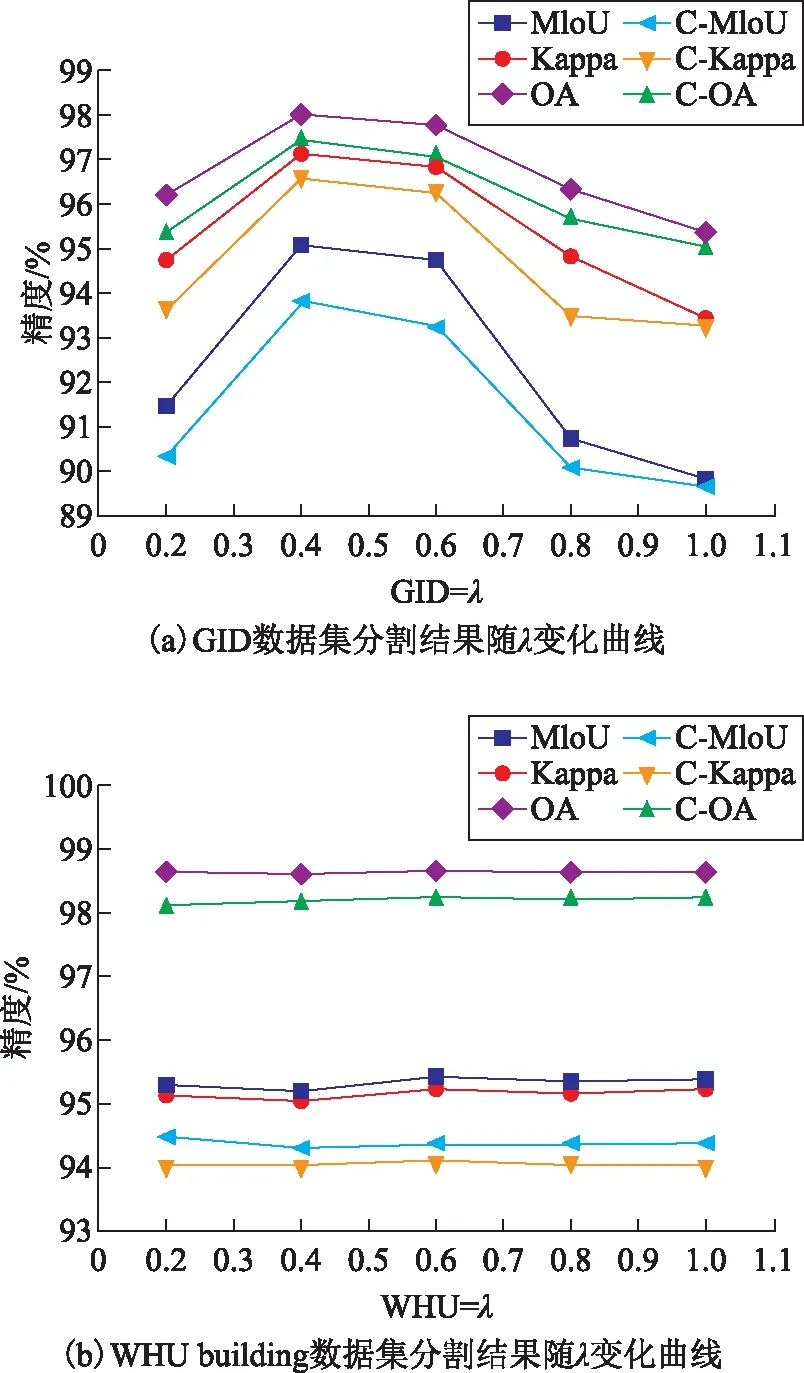
圖7 λ不同取值下,OCRNet在GID和WHU building數據集上的分割結果變化
從圖7可以看出,對于GID數據集,當λ從0.2增加至0.4的過程中,分割精度指標MIoU、Kappa和OA不斷提升,在λ=0.4時取得最優值,隨后隨著λ的繼續增加,分割精度不斷下降。對于WHUbuilding數據集,建筑物提取結果基本不受系數λ影響,隨著λ改變,分割精度基本不變。在OCRNet中,粗語義分割分支的輸出將用于類別中心的特征編碼,進而影響待分割像素在特征空間的最終表達,因此粗語義分割分支的分割精度會影響最終的分割精度。從圖7也可以看出,最終的分割精度與粗語義分割精度具有相似的變化曲線,基本隨著粗語義分割分支的分割精度變化而變化。對于GID數據集,由于其數據在空間上分布跨度較大(從中國60多個城市獲取得到的),類內異質性較大,粗語義分割分支精度隨其加權系數λ變化,并在λ=0.4時取得最優結果,因此使得OCRNet在λ=0.4獲得最優精度。然而對于WHU building數據集,由于該數據覆蓋區域多為相鄰區域,數據同質性較強,相比于GID數據,較為容易分割,粗語義分割分支對λ較為魯棒,因此最終的分割結果對于λ也表現出較為魯棒的特點,基本不隨λ波動。
圖8給出了OCRNet在GID和WHU building數據集上的預測結果與真實值對比情況。對于第一行數據GID-Ⅰ,其為典型的森林,區域內部較為同質,OCRNet在該區域完全分類正確。然而對來自其他區域的第二行數據GID-Ⅱ中,森林內部如1、2、3地區表現出較大差異,同質性較差,地區1和地區2被錯分為草地,地區3被錯分為農田。尤其是地區3,與第一行中的森林差異大,視覺上與農田這一類別較為相似。第3行給出了在WHU building數據集上的對比結果,相比于GID,WHU building建筑物和非建筑物之間具有更明顯的差異,相對更加容易分類。在第四行中,區域1、2、3是真實標簽圖中被遺漏標注卻被我們的模型給正確識別的。雖然區域1、2、3相對于其他房屋尺寸較小,然而其仍然表現出典型的建筑物的特征,而且與周圍背景差異較大,所以可以被正確識別。因此相較于WHU building,GID具有較高的類別復雜度,在OCRNet中粗語義分割分支精度對其對應的權重λ較為敏感,最終表現出分割精度曲線隨粗語義分割分支權重λ起伏較大的現象。而在WHU building上,粗語義分割分支較為容易獲得不錯的分割結果,基本受λ影響不大,進而分割精度曲線變化較小。
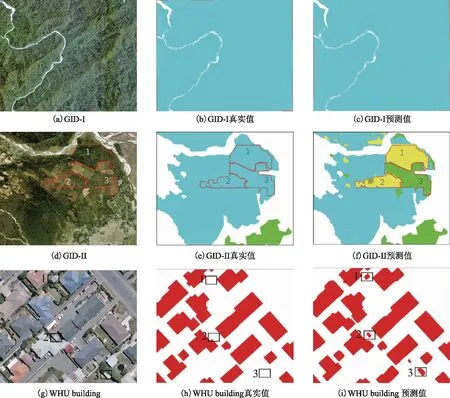
圖8 OCRNet和WHU building數據集上的預測結果與真實值對比情況
3 結束語
深度卷積神經網絡已經在高分遙感影像語義分割獲得成功應用,并成為當前高分語義分割的研究熱點。然而傳統基于卷積神經網絡的高分影像語義分割方法,通過堆疊卷積層、池化層進行層次化特征提取,隱式地將空間上下文信息融合到特征提取過程中。這種方式僅僅融合了像素自身局部范圍的上下文信息,忽略了全局影像中同類像素之間的關系。本文顯式地對全局空間目標上下文建模,將目標上下文卷積神經網絡用于高分遙感影像語義分割。在采用的方法中,包含了粗語義分割分支和精細語義分割分支的雙分支語義分割網絡。利用粗語義分割分支獲得每一個像素的類別概率分布,并結合精細語義分割分支獲得像素特征獲得全局空間的類別中心特征。隨后,將類別中心特征作為碼本對像素特征進行變化,獲得融合了全局上下文信息的變換特征,并將變換特征與像素特征融合用于最終的像素表達,進行語義分割。為驗證算法的有效性,本文在GID和WHU building語義分割數據集上進行實驗,實驗結果證明所用算法可以有效利用全局空間上下文進行特征融合,提高高分影像語義分割精度。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
河南科技(2014年23期)2014-02-27 14:19:15
當代修辭學(2011年6期)2011-01-29 02:49:50
