激光誘導擊穿光譜技術結合神經網絡和支持向量機算法的人參產地快速識別研究*
2021-03-04 05:54:06董鵬凱趙上勇鄭柯鑫王冀高勛郝作強林景全
物理學報 2021年4期
關鍵詞:分類
董鵬凱 趙上勇 鄭柯鑫 王冀? 高勛? 郝作強 林景全
1) (長春理工大學理學院, 長春 130022)
2) (山東師范大學物理與電子科學學院, 濟南 250358)
利用激光誘導擊穿光譜技術結合機器學習算法, 對東北5 個產地(大興安嶺、集安、恒仁、石柱、撫松)的人參進行產地識別, 建立了主成分分析算法分別結合反向傳播(BP)神經網絡和支持向量機算法的人參產地識別模型.實驗采集了5 個產地人參共657 組在200—975 nm 的激光誘導擊穿光譜, 經光譜數據預處理后, 對C, Mg, Ca, Fe, H, N, O 等元素的8 條特征譜線進行主成分分析, 原光譜數據的前3 個主成分累積貢獻率達到92.50%, 且樣品在主成分空間中呈現良好的聚集分類.降維后的前3 個主成分以2∶1 進行隨機抽取,分別作為分類算法的訓練集和測試集.實驗結果表明主成分分析結合BP 神經網絡及支持向量機的平均識別率分別為99.08%和99.5%.發生誤判的原因是集安和石柱兩地地理環境的接近而導致的H, O 兩元素在Ca 元素離子發射譜線下的歸一化強度相似.本研究為激光誘導擊穿光譜技術在人參產地的快速識別提供了方法和參考.
1 引 言
人參(panax ginseng)是五加科多年生草本植物, 在中國已有4000 多年的藥用和食用歷史.人參中主要有效成分為人參皂苷和多糖, 還含有維生素類、酶類、有機酸及其酯、蛋白質、甾醇及其苷、多肽類、含氮化合物、木質素、黃酮類和無機元素等多種成分, 具有滋補強身、預防疲勞、抗衰老、抗腫瘤、提高免疫功能等多種功效, 被廣泛應用于制藥、保健產品、美容產品、飲料等領域, 對內分泌系統、心血管疾病和中樞神經系統等方面有突出療效[1,2].研究發現, 人參皂苷、多糖等主要有效成分在人參內形成、轉化與積累等過程與人參產地的土壤環境、日照環境和氣候環境有關, 因此不同人參產地的相同品種人參在臨床療效上存在著較大的差異.目前, 中國人參產地眾多, 同一品種人參質量參差不齊, 質量監控困難.東北三省是我國重要的人參產地, 目前不法商人借“長白山人參”等噱頭出售人參來牟取利益, 導致人參市場充斥大量偽品及混淆品, 嚴重影響人參的有效使用以及國際市場的推廣.所以人參產地的識別對人參質量品牌保護非常重要, 并且對提高中藥制劑的臨床療效均一性和穩定性及人參市場的發展具有重要研究意義.
傳統的“五行”“六體”識別方法對人參種類和質量的判斷易受人為因素影響.隨著現代科技的發展, 通過對藥效成分含量的測定來確定不同產地藥材的差異是重要的中草藥識別方法.光譜技術因能客觀地反映藥材內在質量從而被廣泛應用于中草藥鑒定中, 常用的光譜檢測方法主要有近紅外光譜(near infrared spectroscopy, NIR)技術、拉曼光譜(Raman spectroscopy)技術、熒光光譜(fluorescence spectroscopy)技術等[3?6].常規的光譜技術由于光譜信號微弱很容易受到背景光的影響, 且檢測樣品時處理時間長且復雜, 無法實現實時、在線和快速檢測.因此, 亟需一種快速可靠的人參產地檢測方法.
激光誘導擊穿光譜技術(laser inducted breakdown spectroscopy, LIBS)是一種原子發射光譜技術[7?9], 適用于所有物質(氣態、液態、固態), 具有快速、微損、樣品準備簡單和多元素同時探測等優點, 廣泛地應用于爆炸物檢測[10]、文化遺產[11]、生物醫學分析[12]、土壤重金屬檢測[13]、地質分析[14]、食品安全[15]等領域.利用LIBS 技術和化學計量學方法結合可實現待測樣品的分類識別.Junjuri和Gundawar[16]利用主成分分析(principal component analysis, PCA)方法和人工神經網絡(artificial neural network, ANN)兩種算法結合LIBS 技術,采用PCA 方法對樣品進行分析, 以主成分數據作為ANN 的輸入量實現了對5 種消費塑料進行鑒定, 最終識別精確度為97%—99%; Velioglu 等[17]利用LIBS 結合PCA 實現了純下腳料和混合下腳料摻假牛肉樣品的識別; Lin 等[18]使用LIBS 技術結合偏最小二乘(PLS-LDA)及支持向量機(support vector machines, SVM)方法實現了鋼種的識別,采用偏最小二乘支持向量機算法(LSSVM)將識別精度由96.25%和95%提高到了100%; Wang 等[19]利用LIBS 結合PCA 算法和ANN 算法對不同產地、不同部位的當歸、黨參、川芎3 種中藥材進行分析鑒定, 達到99.89%的識別精度; 鄭培超等[20]利用隨機森林分類模型結合LIBS 技術對石斛進行價格等級分類, 利用袋外數據誤差率估計隨機森林在不同的決策樹個數和分裂屬性集中屬性個數下的分類效果, 選取最優參數, 將平均識別率提高到了96.46%.
目前關于LIBS 結合機器學習算法對人參產地分類還有待研究.本文基于LIBS 技術結合機器學習算法對人參產地快速識別, 首先通過PCA 提取人參樣品的LIBS 光譜數據的特征量, 分別采用BP 神經網絡(back propagation artificial neural network, BP-ANN)算法、SVM 算法建立人參產地識別模型, 對東北5 個產地的同種人參(白參)進行聚類分析, 實現了人參產地的識別.結果表明,LIBS結合機器學習方法是實現人參產地快速識別的有效方法.
2 實驗部分
2.1 實驗裝置
激光誘導擊穿光譜技術用于人參產地識別的實驗裝置如圖1 所示.激光光源為輸出波長1064 nm,脈寬10 ns, 重復頻率10 Hz 的Nd:YAG 激光器(Continuum, surellite II), 激光光束直徑為6 mm,激光光束通過由半波片和格蘭棱鏡組成的能量調節系統對誘導擊穿人參等離子體的脈沖能量進行調控, 激光光束經焦距為120 mm 的熔石英玻璃平凸透鏡聚焦在人參樣品表面誘導擊穿產生等離子體.激光光束聚焦焦點位于人參樣品表面內0.8 mm, 目的為避免誘導擊穿空氣等離子體, 減少對人參光譜分析帶來干擾.在與人參等離子體膨脹軸向方向成45°的人參等離子體發射光譜方向上,用焦距為75 mm 的熔石英透鏡收集耦合人參等離子體發射光譜耦合到配有ICCD 探測器(1024 ×1024 pixel, DH334)的中階梯光柵光譜儀(Andor,Me5000)的光纖探頭, 光譜儀焦距為195 mm, 光譜分辨率為 λ /?λ ≈5000 , 一次光譜探測范圍為200—975 nm.激光器和ICCD 探測器均由數字脈沖延時發生器(Standoff, DG645)同步觸發工作,通過優化激光脈沖與ICCD 探測器間的時間延時和ICCD 探測器的探測時間門寬, 設定延時和門寬分別為1 和5 s, 獲得高信背比的人參LIBS 光譜信號.為避免人參樣品過度燒蝕, 人參樣品固定在三維平移臺上, 使每個激光脈沖作用在人參樣品表面新的位置.實驗中人參LIBS 光譜為100 個脈沖進行平均, 降低脈沖能量抖動對人參LIBS 光譜的穩定性影響.實驗均在標準大氣壓、室內溫度為22 ℃、空氣相對濕度為25%的條件下開展.
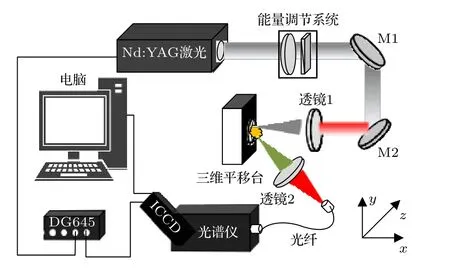
圖1 激光誘導擊穿光譜實驗裝置示意圖Fig.1.Schematic diagram of the experimental setup of LIBS.
2.2 樣品制備
實驗所用的人參樣品均為生長年限15 年的白參, 產地分別為遼寧省石柱(SZ)、恒仁(HR), 黑龍江省大興安嶺(DXAL), 吉林省撫松(FS)、集安(JA).LIBS 光譜信號受樣品密度、干燥度及研磨均勻性等物理屬性的影響, 在實驗前先對5 個產地的人參樣品進行純凈、干燥處理, 取干燥后的人參中間支干部位, 使用振動研磨機(安合盟(天津)科技發展有限公司, PrepM-01)研磨至粉末, 分別經50 目和100 目過篩, 取1.5 mg 樣品過篩人參粉末, 使用機械壓片機(安合盟(天津)科技發展有限公司,FW-40)在25 MPa 壓力下壓制25 min, 制成直徑30 mm、厚度為2 mm 的圓形人參樣品, 用于人參產地識別實驗樣品.
2.3 主成分分析算法
主成分分析(principal component analaysis,PCA)算法是一種數據降維的高效信息處理方法,它采用特征分解獲得最大方差的主成分代替原來變量, 可以消除原變量的相關性, 降低數據的維數,提高建模速度和穩定性.PCA 分析方法為將人參樣品LIBS 光譜的采樣值整理并代入向量Xi=(xi1,xi2,···,xin) 中( n 為光譜特征值), m 為進行降維的m 組光譜數據, 對樣本標準化: 標準化采用P維隨機變量, 選取m 個樣品, 構造樣本陣, 對樣本陣進行標準變換:



其中, λ 稱為 R 的特征值, 非零向量 R 稱為A 對應于特征值 λ 的特征向量; 根據主成分貢獻率選擇主成分, 計算主成分得分, 將所得主成分作為分類算法的輸入參量, 對人參進行產地識別.
2.4 BP 神經網絡算法
誤差反向傳播(back-propagation algorithm,BP)神經網絡[21]是一種按誤差逆傳播算法訓練的多層前饋網絡, 它利用大量的數據進行訓練獲得輸入與輸出間的映射關系, 再通過梯度下降法不斷調整網絡的權值和閾值, 使網絡的誤差達到最小.圖2為典型的BP 人工神經網絡結構示意圖.網絡 N 個輸入節點, L 個輸出節點, 隱含層包含 Z 個神經元.x1,x2,··· ,xN為網絡的實際輸入, y1,y2,··· ,yL為網絡的實際輸出.

圖2 BP 神經網絡結構示意圖Fig.2.Structure of BP neural network.
BP 神經網絡通常由輸入層(input layer)、輸出層(output layer)、一個或多個隱含層(hidden layer)組成.傳遞函數對誤差和訓練時間會有很大的影響, 合理地選擇傳遞函數能夠降低網絡誤差, 四種傳遞函數為trainlm, trainda, traindm, Traindx.激活函數以及傳遞函數的確定需要根據訓練數據來進行測試、對比與篩選.在進行BP 神經網絡仿真前, 還需要先進行LIBS 光譜數據的訓練集和測試集選擇, 從而能夠快速實現人參產地鑒定識別.
2.5 SVM 算法
支持向量機[22](support vector machine, SVM)實現分類的本質是找一條分割線, 將所有樣本點盡可能遠離分割線, 即最優超平面.設訓練樣本集{(xi,yi),i=1,2,··· ,l} , xi對應樣本屬性值, yi對應屬性值標簽.對于非線性訓練集, 通過一個非線性函數將訓練數據 x 映射到一個高維特征空間, 映射在高維空間中的不同產地人參屬性值向量?(xi)變為線性可分問題.此時需構造最優分類超平面并得到決策函數.

其中 C 為識別參數, ξi,i=1,··· ,l 為引入的非負松弛變量.采用拉格朗日(Lagrangian)乘子法求解該問題, 得到對偶形式.

其中 K (Xi,Xj)=?(Xi)T?(Xj) 為核函數, 本實驗采用徑向基函數(radial basis function, RBF)作為 核函數, 即

式 中, σ 表示高斯核函數寬度.最終, 決策函數

SVM 核心問題是優化懲罰因子 C 及核函數g( g =1/σ2).懲罰因子控制對大間隔和最小訓練錯誤率之間的平衡, 用于核空間上非線性可分數據.本實驗基于交叉驗證和網格搜索對 C 與 g 進行訓練, 獲得最佳參數 C , g 進行訓練支持向量機算法 , 從而能夠快速實現人參產地鑒定識別.
3 結果與分析
3.1 特征光譜的選取
進行人參產地識別, 需要考慮實驗待測產地人參的LIBS 全光譜信息, 但LIBS 全光譜信息量很大, 進而導致機器學習算法計算量過大, 從而人參產地的識別快速性不能得到保證.為此, 選取合適的特征譜線代表人參樣品的全光譜信息, 從而實現快速人參產地識別尤為重要.激光誘導人參的等離子體發射光譜由線狀光譜疊加在連續光譜上組成,連續背景光譜的存在, 導致了LIBS 光譜的信背比變低, 本文采用窗口平移平滑法降低背景連續光譜, 5 個產地人參的激光誘導擊穿光譜如圖3 所示.根據美國NIST 原子光譜數據庫對人參LIBS 光譜進行了元素標記, LIBS 光譜中存在Mg, Ca, Fe 等礦質營養元素以及C, H, N, O 等人參組成元素的原子發射光譜.不同產地人參中元素含量不同, 對應的LIBS 特征譜線強度有一定的差異, 因而通過多條元素特征光譜強度可對人參產地進行識別.特征光譜的選擇應滿足光譜線的重疊少、自吸收現象弱、譜線強度大(信背比高)等條件, 最終選取Mg,Ca, Fe, C, H, N, O 共7 個元素8 條特征譜線進行人參產地識別(特征譜線信息如表1 所列).

圖3 人參LIBS 光譜(產地分別為大興安嶺、集安、恒仁、石柱、撫松)Fig.3.LIBS spectra of ginseng(the ginseng origins are DXAL, JA, HR, SZ and FS).

表1 人參特征譜線及波長Table 1.Characteristic line and wavelength of ginseng.
在LIBS 實驗過程中, LIBS 光譜強度受到外部氣體流動、激光脈沖能量抖動及樣品表面元素含量的變化等因素影響, 從而導致在給定實驗條件下的LIBS 光譜強度存在一定的起伏, 這將對依據LIBS 光譜譜線強度作為元素定量分析產生一定的誤差.因此, 選取LIBS 光譜中多次重復性實驗較為穩定且光譜強度值較大的特征譜線進行LIBS光譜強度歸一化處理, 能夠有效降低外部實驗環境等因素造成的LIBS 光譜強度起伏對定量分析的影響.本文人參樣品LIBS 光譜中Ca I 393.40 nm特征譜線強度最大, 且多次重復實驗的光譜強度穩定, 因此選取譜線強度最大的Ca I 393.40 nm 作為歸一化標準.為降低譜線強度波動對分類結果的影響, 每個LIBS 光譜中的8 條特征譜線強度均以Ca:393.40 nm 光譜強度作歸一化處理, 最終得到5 個產地人參的657 組數據(DXAL 117 組、JA 150組、HR 153 組、SZ 96 組、FS 141 組), 每組數據有8 個屬性, 作為PCA 的輸入: Xi=(xi1,xi2,··· ,xi8).
3.2 主成分分析
由PCA 分析出人參LIBS 光譜中Mg, Ca,Fe, C, H, N, O 共7 個元素8 條特征譜線對LIBS全譜的主成分貢獻情況, 得到前10 個主成分的貢獻率和主成分的累計貢獻率如圖4(a)所示, PC1,PC2 和 PC3 主成分累計貢獻率為92.5%, 可認為PC1, PC2, PC3 包含了原始人參LIBS 光譜的大量信息.PC1, PC2 和 PC3 3 個主成分向量組成的三維散點圖如圖4(b)所示.圖4 中每個散點代表一個人參樣本, 可以看出同產地人參樣品的特征LIBS 光譜經PCA 處理后存在特定的聚集區域,顯示了良好的聚類效果.結果表明結合PCA 處理后的LIBS 光譜數據能夠表征人參的產地特征信息, 且能將不同產地人參間的差異進行有效區分.由圖4(b)可知, HR, FS 和DXAL 等產地人參的聚類性較好, 相互之間區分度高, JA 和SZ 產地人參樣品也可聚在一起, 但存在部分重疊.
3.3 結合機器學習對人參產地進行識別
通過PCA 算法對5 個人參產地、共657 組LIBS數據進行光譜數據降維處理, 優化PCA 算法參量,實現PC1, PC2 和 PC3 前3 個主成分累計貢獻率為92.5%, 就以PC1, PC2 和 PC3 主成分代替人參的LIBS 特征光譜, 從而構建出人參樣品LIBS光譜的特征空間向量, 特征向量構成的 6 57×3 的數據矩陣分別作為BP 神經網絡與SVM 產地識別算法的輸入量, 進而依據PCA-BP 和PCA-SVM算法實現人參產地分類識別.BP 神經網絡人參產地識別算法按產地以2:1 隨機選取經主成分降維處理的657 組數據, 分為438 組測試集(Test)和219 組訓練集(Train).訓練集構成的 4 38×3 維數據矩陣作為神經網絡訓練輸入量.網絡的輸入向量為三維數據, 因此BP 神經網絡的輸入層和輸出層的神經元分別為3 和5.運行經多次訓練, 最佳隱含層神經元個數為11, 輸入層激勵函數為tansig,輸出層激勵函數為purlin.網絡初始化參數的迭代數設為1000, 學習率為0.1, 誤差目標為0.0001.

圖4 (a)各主成分貢獻率和主成分累積貢獻率; (b)前3 個主成分的三維散點圖Fig.4.(a) Contribution rate of each principal component and cumulative contribution rate of principal component; (b) three-dimensional scatter plot of first three principal components.
圖5 (a)為BP 神經網絡最佳驗證性能圖, 訓練誤差隨訓練次數不斷減小, 測試均方差(MSE)也趨于平緩, 驗證曲線MSE 不再變化時網絡訓練截止, 網絡性能最佳坐標為(28, 0.03), 達到了最佳網絡識別精度.在此基礎上, 以BP 神經網絡機器學習對人參產地分類結果如圖5(b)所示, 圖中“*”表示測試標簽, “○”表示實際標簽.當“*”和“○”重合時表明預測準確, 結果顯示有2 個JA 產地的人參被誤判為SZ 產地, 其他產地100%識別, 平均識別精度達到99.08%, 人參產地識別算法模型運行時間為2.48 s, 同時結果表明神經網絡收斂性良好, 誤差個數穩定, 高質量地實現了人參產地判別.
人參產地識別的SVM 算法的數據選取經主成分降維處理的657 組數據, 建立與BP 神經網絡算法相同的訓練集和測試集, 使用交互檢驗法優化參數, 得到PCA-SVM 的網格參數優化如圖6(a)所示.圖6(a)的x, y 軸分別表示C, g 取以2 為底的對數的值, 使用網格搜索方法的分類(SVC)參數計算出最佳懲罰因子 C 為0.14, 最優核函數g 為36.76, 此時交叉驗證準確率為99.09%, 訓練集準確率為99.07%.經參數優化后SVM 算法對人參產地識別的預測運行結果如圖6(b)所示.圖6(b)中“△”表示預測標簽, “○”表示實際標簽.結果表明, 1 個JA 產地的人參被誤判為SZ, 識別精度為99.8%.其他產地的識別精度均為100%, 平均識別精度為99.5%, 人參產地識別算法模型運行時間為14.03 s.
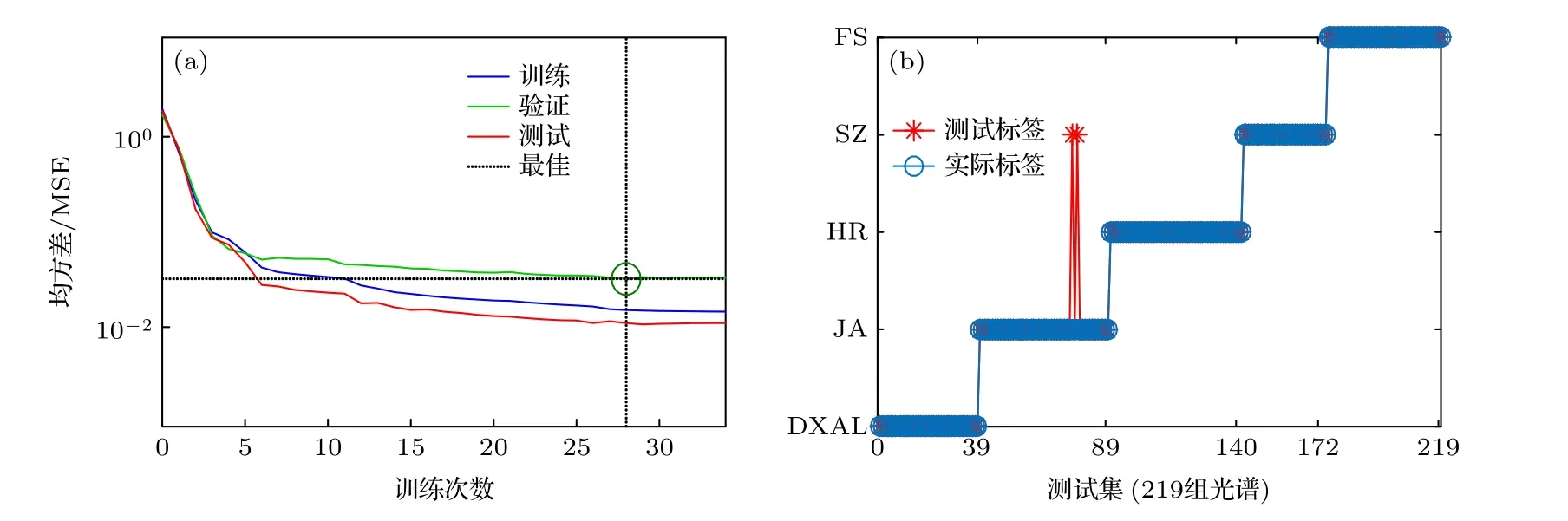
圖5 (a) BP 神經網絡訓練性能曲線; (b) 分類結果圖Fig.5.(a) BP neural network training performance curve; (b) classification results.
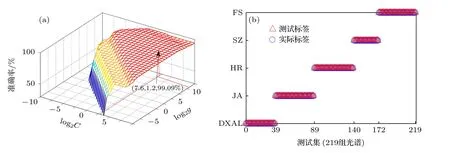
圖6 (a) PCA-SVM 網格參數優化; (b)分類識別結果圖Fig.6.(a) PCA-SVM grid parameter optimization; (b) classification recognition result graph.

表2 人參產地識別結果對比Table 2.Comparison of ginseng origin identification results.
PCA-BP, PCA-SVM 分類算法對人參產地的識別結果如表2 所列.由LIBS 技術結合機器學習的研究結果可知, PCA-BP 和PCA-SVM 兩種分類算法的分類精度均達到了99%以上, 實現了目標分類精度, 但在JA 人參產地的識別上均發生了一定數量的誤判.在算法模型運行時間上, PCABP 算法和PCA-SVM 算法的人參產地識別運算時間分別為2.48 和14.03 s, PCA-BP 算法相對于PCA-SVM 算法的建模速度快了11.545 s, 有明顯優勢.主要原因可能為BP 神經網絡算法具有自主學習能力, 而SVM 算法需通過核函數將非線性問題實現線性的轉化, 識別能力依靠分類超平面的劃分, 需尋找最優的核函數以滿足識別精度要求, 因而建模時間較BP 神經網絡算法慢.
人參的品質主要由人參皂苷及人參多糖的含量決定, 人參皂苷是固醇類化合物, 人參中皂苷和多糖主要由C, H, O 等元素決定.通過分析5 個產地人參C I 247.8 nm, H I 656.39 nm, O I 777.42 nm元素在Ca II 394.2 nm 元素譜線強度下的歸一化強度結果如圖7 所示.可以看出, JA 和SZ 兩地人參在組成成分上雖因產地的不同導致金屬元素的原子發射譜線強度存在差異, 但其H I 656.39 nm與O I 777.42 nm 兩條譜線強度的歸一化強度幾乎相同, 從而導致JA 和SZ 人參產地分類時發生誤判.
4 結 論

圖7 人參LIBS 譜中C, H, O 元素譜線的歸一化強度比Fig.7.Normalized intensity ratios of C, H and O element lines in the LIBS spectrum.
基于激光誘導擊穿光譜技術結合機器學習算法對5 個產地的人參進行了產地的分類識別, 測試集219 組光譜中, PCA-BP 算法和PCA-SVM 算法分別正確識別了217 組和218 組, 兩種算法的識別精度分別為99.08%和99.5%.但在分類速度上,主成分分析結合神經網絡(PCA-BP)算法明顯優于主成分分析結合支持向量機(PCA-SVM)算法.JA和SZ 兩種人參樣本LIBS 譜線中的H I 656.39 nm和O I 777.42 nm 譜線在以Ca:393.40 nm 光譜強度作歸一化處理后的強度幾乎相同, 最終導致兩產地發生誤判.實驗結果證明, PCA-BP 算法較PCASVM 算法訓練速度快, 訓練結果較為穩定, 對5 個產地人參的分類精度較高, 因此利用LIBS 技術結合機器學習算法可實現人參產地的快速識別.
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
