病歷數據挖掘技術的應用研究*
2021-03-11 13:26:12陳小文唐翠娥
科學與信息化 2021年6期
陳小文 唐翠娥
貴州醫科大學 計算機教育與信息技術中心 貴州 貴陽 550025
引言
電子病歷(Electronic Medical Record,EMR)是醫務人員在醫療活動過程中形成的電子化病人記錄,是現代醫院診療、科研及管理工作所必需的重要臨床信息資源[1],其蘊含了大量的、準確的詳細的患者的醫療信息。通過對住院電子病歷完成知識分析和實體識別,準確提取患者各項醫療信息,可幫助醫學研究者構建臨床決策支持系統,減少個人的醫療失誤問題。文獻[2]提出了一種基于雙向長短時記憶網絡與 CRF(conditional random field)結合的實體識別和實體關系抽取方法,對識別結果知識圖譜化。文獻[3]提出了基于bootstrapping的識別算法和基于條件隨機場的識別算法,有效地提高了條件隨機場識別結果的準確率、召回率和F1值。利用快速樹算法降低了抽取算法的時間復雜度,獲得了標準樹片段庫和局部樹片段庫;提出了啟發式和機器輔助的方法來解決數據不一致問題;提出了一種基于多特征和CRF相結合的命名實體識別方法,利用分層融合聚類的方法對存儲庫中從未出現的實體進行聚類;提出了一種基于卷積神經網絡的多類別分類方法,用于從EMR中挖掘命名實體;設計了病歷數據到RDF三元組格式的轉化方案和存儲方案,提高了數據檢索速度,同時避免空值所導致的問題。采用否定術語對中文電子病歷進行檢測,降低了標點錄入錯誤而出現假陽性術語的概率。提出了改進后的逆向最大匹配算法,提高了分詞準確度和分詞效率。分別采用C4.5、BP對腫瘤病歷數據進行了分類實驗,結果表明:C4.5算法更有利于輔助醫生進行腫瘤疾病診斷。針對國際疾病分類標簽提出端到端的深度學習方法,在分類性能上有顯示的提升。
1 數據提取與模型描述
病歷文本數據中包含了非常重要的醫療信息,通過對住院電子病歷完成知識分析和實體識別,準確提取患者各項醫療信息,可協助醫學研究者構建臨床決策支持系統,幫助醫生解決知識上的局限性問題,從而減少個人的醫療診斷失誤。借鑒OEM(Object Exchange Model)模型描述方式,采取四元組(oid,label,type,value)來表示,type可為原子型也可為集合,value表示具體的值。其結果如圖1所示。
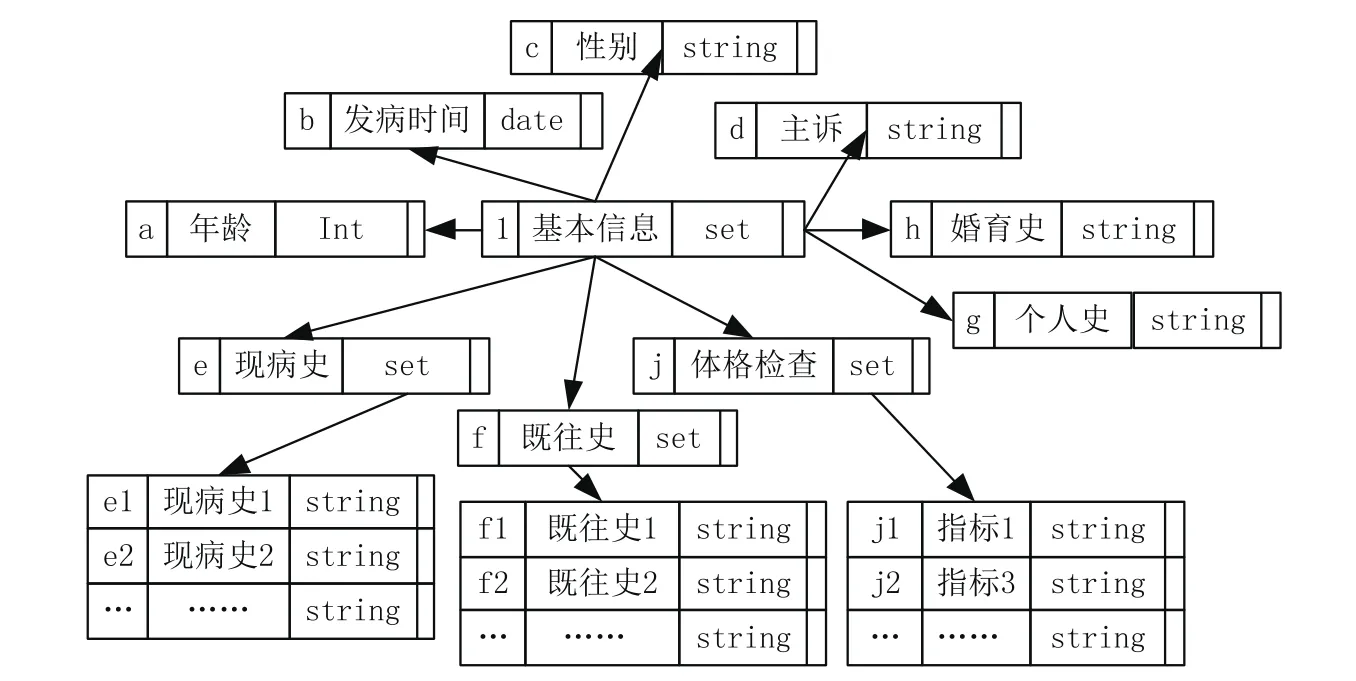
圖1 病歷基本信息模型圖
病歷文本數據以半結構化數據居多,構建病歷文本數據提取和分類規則,將非結構化、半結構化的數據轉換成可挖掘的結構化數據,并創建數據模型結構化模型M={N,F,I,P,D},其中N為當前病史集合、F為既往史集合、I為人個史集合、P則為體格檢查集合,D為診斷結果集合。其中N={惡心、嘔吐,頭昏,畏光、畏聲,頭痛,乏力及麻木,大小便異常,體重明顯增減},F={傷寒、結核,肝炎,糖尿病,高血壓,冠心病,中毒史,過敏史},I={吸煙,戒煙,飲酒},P={體溫,呼吸,脈搏,血壓},D={腦供血不足,腦出血,腦梗,緊張性頭痛,神經癥焦慮,椎基底動脈供血不足,帕金森病,前庭神經元炎,后循環缺血,良性位置性眩暈}。
2 數據預處理
電子病歷中包含的醫療信息十分豐富,借助數據分割提取從Word文件中提取相應的關鍵信息,按患者基本信息模型進行數據關聯與存儲,并將最終生成的二維表以EXCEL格式導出,項目組累計完成384份神經內科住院電子病歷數據提取工作,依據診斷結果進行分類匯總,其中腦供血不足113份、腦梗89份、緊張性頭痛67份、腦出血28份、后循環缺血23份、神經癥焦慮狀態19份、良性位置性眩暈18份、帕金森氏病11份、椎基底動脈供血不足8份、前庭神經元炎7份。在數據預處理階段進缺失數據記錄進行補充或丟棄,針對缺少5項以下的數據記錄采取填充眾數的方式進行補充,對缺失5個及以上數據項的記錄進行丟棄處理。為避免數據提取的數據類型異常而導致的錯誤,將所有的對象數據編碼成數值型。考慮到病歷數據的特征以文本形式呈現且跨度大,特將所有數據進行標準化處理,并統一到0~1范圍內。
3 算法分析
挖掘算法直接影響實驗數據的結果,依據病歷文本數據的自身特征、數據項,選擇合適的算法進行數據挖掘、分析尤為重要。在前期算法調整階段設定驗證集的比例為10%,等待超參數調整結束并穩定后,訓練與驗證數據的比例分別為80%和20%。實驗所采用的處理器為Intel(R) i5-8250U 1.8GHz 4核 8個邏輯處理器,內存24G。
3.1 決策樹
決策樹是一個預測模型,它是對象屬性與對象值之間的一種映射關系。決策樹是一種樹型結構,每個葉子代表一種類型。決策樹能直接體現數據,而且能夠同時處理數據型和常規則屬性,相對較為易于理解和實現。設置起始深度為1、終止深度為15、深度探索步長為4進行模型訓練與測試,模型訓練與測試花費130ms,其測試結果為51.04。在對超參數進行調整后,測試結果波動較小。由模型結果而知,當深度為4時能獲取最大的準確率。
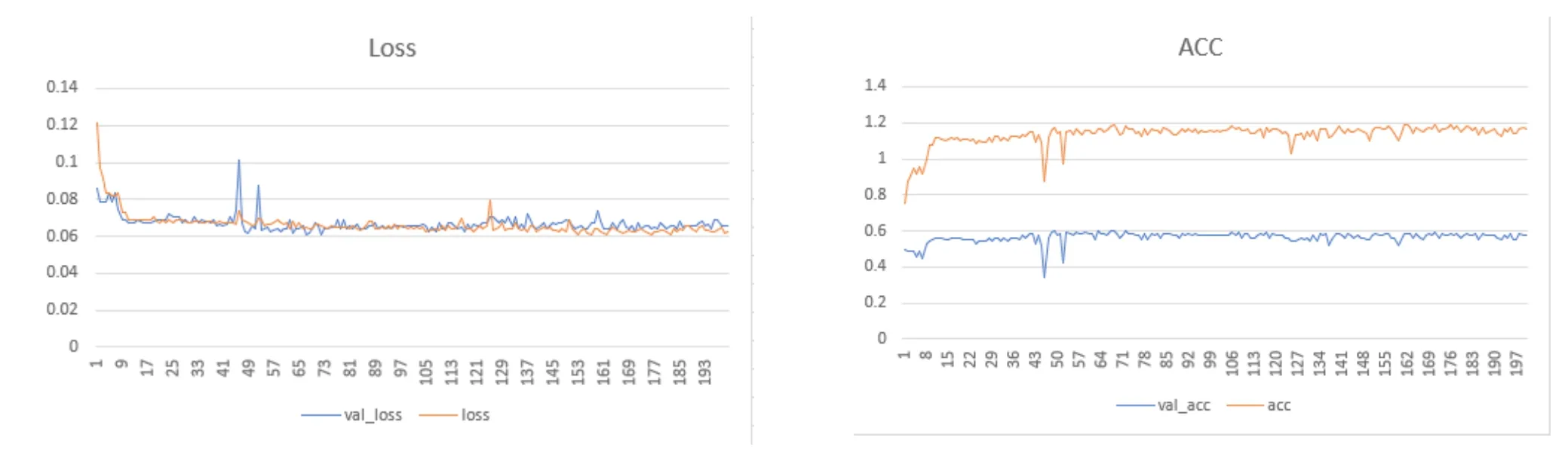
圖4 深度學習結果趨勢圖
3.2 深度學習
深度學習是學習樣本數據的內在規律和表示層次,最終目標是讓機器能夠像人一樣具有分析學習能力,能夠識別文字、圖像和聲音等數據。借助深度學習模型對病歷數據進行訓練與測試。以batch_size=8進行200輪訓練,其訓練與測試結果如下圖所示,模型訓練與測試花費63000ms(每輪315ms),其測試結果為57.29。深度學習運行結果如圖4所示。
3.3 隨機森林
隨機森林利用多棵樹對樣本進行訓練并預測的一種分類器,其利用平均決策樹可降低過擬合的風險性。其分類性能非常穩定,當半數以上的基分類器出現差錯時才會導致錯誤的預測。隨機森林的算法較為復雜,對其模型訓練和測試的成本相對較高。模型訓練與測試花費0.92秒,其測試結果為65.62。
3.4 實驗小結
深度學習、決策樹、隨機森林三種算法的執行時間、測試結果如下表1所示。在算法執行性能上,決策樹的執行時間最短,測試結果得分近為51.04。深度學習的執行時間是決策樹的2.42倍,在測試結果方面提高了6.25。隨機森林的執行時間是920ms,模型的執行時間為決策樹的7.07倍,在測試結果方面相比決策樹和嘗試學習分別提高了14.58和8.33。

表1 分類實驗性能與結果對比
4 實驗小結
在電子病歷挖掘過程中有兩個重要的步驟:①從半結構化、非結構化的電子病歷中提取相應的現病史、既往史、個人史、體格檢查等重要信息,病歷數據特征的提取質量直接影響到后續的數據挖掘的質量和執行速度。②挖掘算法的選取,通過對三種不同挖掘算法測試結果可知:隨機森林準確率較高65.62,但耗時相對較高。后續研究將改進數據提取的算法和挖掘算法數據結構。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
