工業電阻爐多參數能耗建模與預測
2021-03-13 08:38:10林利紅李雨龍李聰波
重慶大學學報 2021年2期
關鍵詞:模型
林利紅,李雨龍,李聰波,張 友
(重慶大學 機械工程學院,重慶 400044)
電阻爐是利用電流使電熱元件升溫,通過熱傳遞加熱爐內物體的裝置。在制造業中,電加熱裝置是耗能大戶,其耗電占據企業總耗電的25%~60%,全國熱處理電熱裝置總裝機量約15萬臺,年總耗能電量約100億度[1]。對工業電阻爐制定科學合理的能耗分析方法與生產計劃能提高能源效率,實現可持續的清潔生產和節能降耗[2]。因此,工業電阻爐的能耗預測研究具有深遠的意義。
傳統的工業電阻爐能耗預測研究主要是通過數值分析法來建立的理論數學模型,模擬加熱時爐內的熱傳遞輻射。Fu等[3]基于計算流體動力學(computational fluid dynamics,CFD)軟件FLUENT數值模擬了高溫合金坯在電阻爐內的加熱過程,對爐膛內自然對流和表面熱輻射進行了數值分析,預測了高溫合金的溫度分布和平衡時間。Jang等[4]采用共軛梯度法和打靶法相結合的優化方法,研究表明隨著預熱區溫度降低,能耗也顯著降低。以上傳統的數學建模方法需要提供詳細的數據信息,模型建立困難,預測誤差大,不夠精確。

綜上所述,雖然能耗預測在各方面研究早已開展,但具有非線性、大慣性、時變性特點[13]的大功耗的工業電阻爐,目前還沒有給出泛化性高的多參數預測方法。因此筆者對電阻爐工作狀態下的多個過程參數進行研究,分析各個加熱階段的能耗特性,基于數據驅動下建立小樣本、非線性的多參數能耗預測模型,并以粒子群優化算法(particle swarm optimization,PSO)對支持向量回歸的超參數進行尋優,提高模型精度。
1 工業電阻爐能耗分析
1.1 工業電阻爐能耗特性分析
工業電阻爐工作階段按不同工藝可分為預熱階段、加熱階段、保溫階段和冷卻階段。預熱階段是將電阻爐升溫到預熱溫度后放入工件為止;加熱階段是在工件放入后加熱達到電阻爐的工作溫度為止;保溫階段是電阻爐持續保持工作溫度到設定時長為止;冷卻階段是保溫結束后關閉溫度控制系統,使工件隨爐冷卻到一定溫度,直到將其從電阻爐中取出為止。
經現場采集三相電輸出數據,繪制電阻爐能耗趨勢圖,如圖1所示。
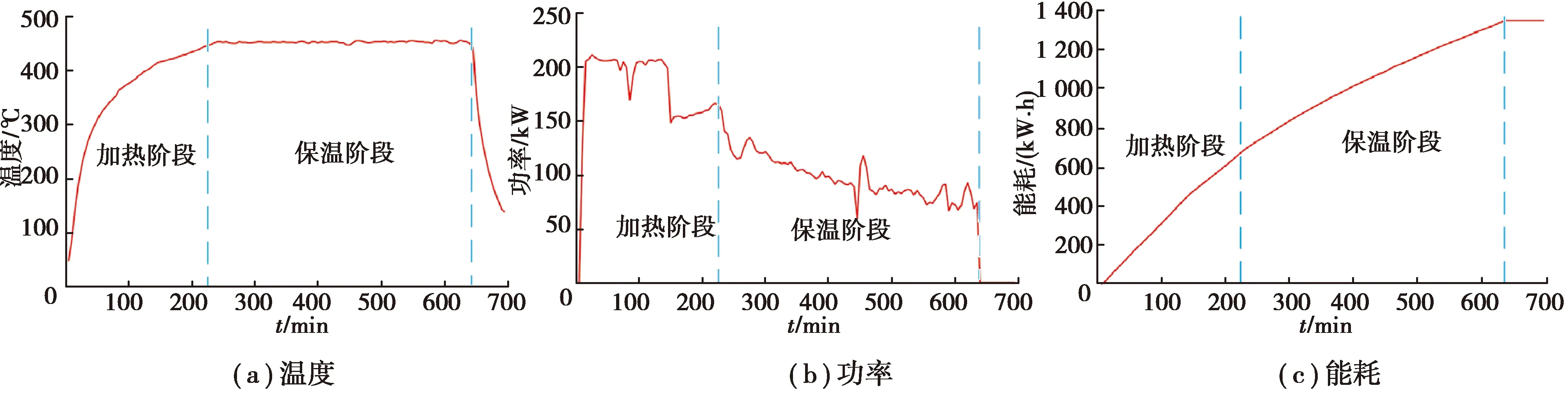
圖1 電阻爐溫度、功率、耗電趨勢圖Fig.1 Trend of temperature, power and power consumption of resistance furnace
1.1.1 工業電阻爐加熱階段能耗分析
由圖1可知,工件放入,打開電阻爐開關后開始記錄能耗數據,可以看到加熱階段持續到爐內溫度達到設定值。此階段的功率為電阻爐額定輸出功率Pheat,即加熱電阻導電后的發熱功率。該爐電阻絲為星形接法,根據三相電路功率公式,總功率等于各相功率之和:
Pheat=PA+PB+PC,
(1)
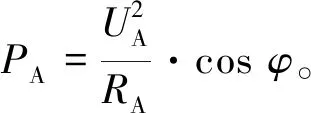
(2)
式中:UA為A相電壓;cosφ為功率因數;RA為A相負載電阻的阻值;PA為三相電路A相有功功率,三相電阻爐因為是純阻性負載,電流與電壓沒有相位差,所以功率因數取1,PB,PC以此類推。因此電阻爐的加熱階段能耗可表示為
(3)
式中ti是加熱階段的采樣時間。
1.1.2 工業電阻爐保溫階段能耗分析
當爐溫達到設定溫度后,此時PID溫度控制系統開始工作,控制繼電器通斷電路改變電阻爐有功功率,如圖2所示。
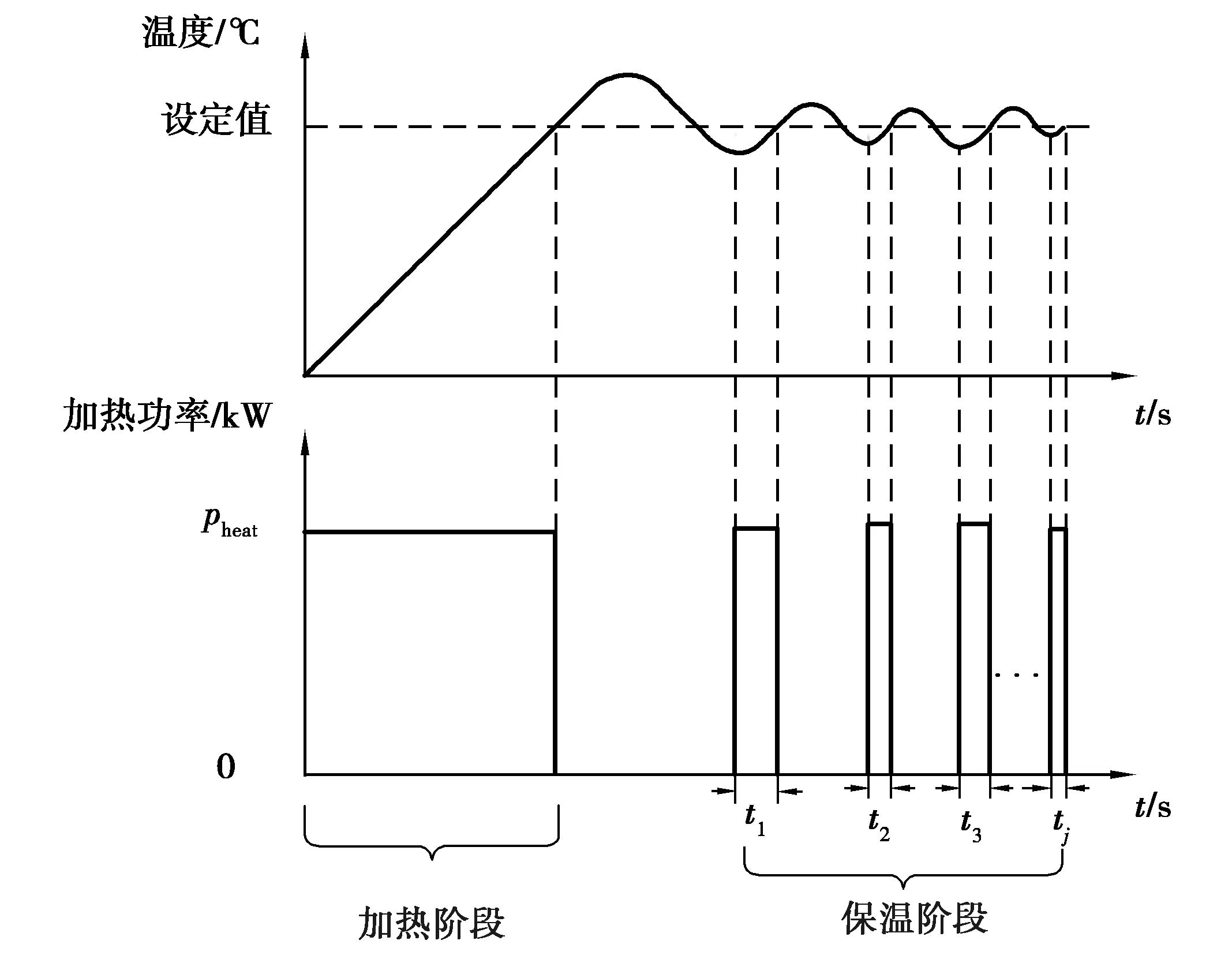
圖2 加熱與保溫階段溫度、功率對照圖Fig.2 Comparison of temperature and power in heating and holding stage
圖2中t1,t2,…,tj表示加熱電阻保溫階段的運行時長,此時電阻爐的保溫階段能耗可表示為
(4)
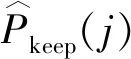
(5)
1.1.3 工業電阻爐輔助系統能耗分析
電阻爐的精確穩定運行受溫控系統的控制,控制系統包括上位機監控終端和PID溫控儀,其功率消耗相對穩定,受負載影響較小,因此實際輸入功率可用額定功率Pe代替。在放入和取出工件的過程中,電阻爐機械動力系統也會消耗一定電量,動力系統的額定功率為Pm。加熱與保溫階段需開啟安裝在爐頂的循環風扇,保證爐內熱流循環以及各爐區溫度均勻,風扇額定功率為Pf。工業電阻爐輔助系統的能耗Eaux為
Eaux=Pe(theat+tkeep+tcool)+4Pmtm+Pf(theat+tkeep),
(6)
式中:theat,tkeep,tcool分別為加熱、保溫、冷卻的時長;tm為爐門打開或關閉過程電機運行時長。
1.2 工業電阻爐工作階段能耗模型
由式(3)(4)及(6),電阻爐工作能耗可近似為
Ework=Eheat+Ekeep+Ecool+Eaux。
(7)
Fu等[14]指出電阻爐在加熱階段,加熱元件的熱量通過輻射到電阻爐內壁表面,內壁表面吸收輻射后轉化為熱流遍布整個區域,此時爐內空氣介質、內壁、耐火爐襯、隔熱層以及外殼等吸收加熱電阻散發的熱量,通過對流傳熱和輻射傳導至周圍環境中;Cheng等[15]提出此過程會產生加熱能耗損失Ehl和保溫能耗損失Ekl。
(8)
(9)
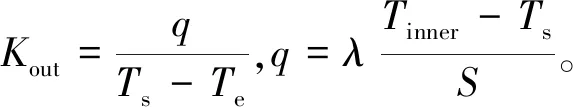
(10)
式中:S為爐壁厚度;th,tk為加熱階段、保溫階段持續時間;Ts為爐外表面溫度;Te為環境溫度;Tinner為爐內溫度;Kout為外壁傳熱系數;q為熱通量;λ為導熱系數。根據以上公式,電阻爐理論能耗模型為
Ereal=Eheat+Ekeep+Ecool+Eaux+Ehl+Ekl。
(11)
在工程實際中,電阻爐的實際損失能耗與多種因素有關,如爐的內外壁的傳熱系數隨著溫度提高不斷改變;爐內各個加熱區由于輻射換熱、對流換熱,溫度場分布有一定差異;爐內氣體并不是理想氣體等,從而難以進行精確計算。為簡化模型,假設電阻爐的電源輸入能耗等于發熱電阻的能耗與損失能耗之和,則理論模型如式(12)。
Etotal=EA+EB+EC+Eaux。
(12)
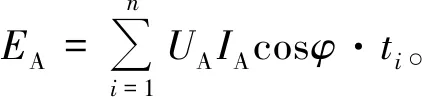
(13)
式中:UA,IA、是三相電A相的相電壓、電流;EA是A相有功功率與采樣時間之積的累加;EB,EC同理可得。
2 基于數據驅動的電阻爐多參數能耗預測方法
利用數據采集平臺動態獲取電阻爐工作參數,通過功率特征判斷電阻爐的運行狀態,將該狀態下的電流、爐內外溫度、功率、能耗等各個特征信息輸入模型訓練,運用多個評價指標評價模型,獲得最佳預測方法。
2.1 多參數數據采集及特征提取
采集系統中的功率傳感器、溫度傳感器與主機通訊,實時獲取電阻爐3個加熱區(1區、2區及3區)的功率、電流以及爐內、外殼溫度信息。采集信息流程如圖3所示,圖(a)(b)中3條曲線分別代表1區、2區及3區的電流、功率,圖(c)中采集3個區的溫度以及電阻爐外殼溫度。
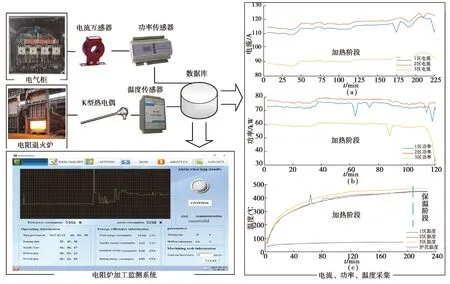
圖3 采集信息流程圖Fig.3 Information collection process
為了實時反映爐內外溫度、電流及功率的變化,剔除波動較大或明顯異常的采樣點。圖3中的溫度曲線在加熱階段具有明顯的非平穩性,而保溫階段序列是平穩的,電流與功率在加熱階段也是平穩的。如果對以上電流、功率以及溫度3組采集數據均提取時域特征,導致數據維度過大,直接使用機器學習建模將增大模型的復雜度。由于電阻爐的功率、發熱與三相電流的大小息息相關,因此只提取電流信號的時域特征參數,包括3個加熱區的測量電流I,3個區的電流方差Ivar、均方根Irms、峰峰值Iptp與偏度Iske共12個時域特征參數作為電流信號的特征量,以及3個加熱區的爐內溫度、爐殼溫度、室溫及電阻爐總功率共21個參數作為模型的輸入向量。
2.2 基于數據驅動的電阻退火爐多參數能耗預測模型
2.2.1 回歸型支持向量機預測模型
支持向量機(SVM)是Corinna Cortes和Vapnik[16]在1995年提出的機器學習方法,在分類和回歸任務中已得到許多運用。支持向量回歸(support vector regression,SVR)是SVM中的一項重要應用分支[17],近年來在回歸估計和非線性問題的解決中受到越來越多的重視。SVR是將原始數據向高維特征空間的非線性映射,將其轉化為線性回歸關系。假設一個回歸函數F,訓練樣本為{(xi,yi)},其中xi是輸入,yi是輸出。SVR使用線性方程預測目標值,即
F(x)=wTφ(x)+b,
(14)
式中:F(x)為輸出;w為權向量;b為偏差;φ(x)為高維的實際輸入向量;權向量w和偏差b是通過最小化風險函數計算所得。最小化風險函數的推理過程如式(15)~(21)。
(15)
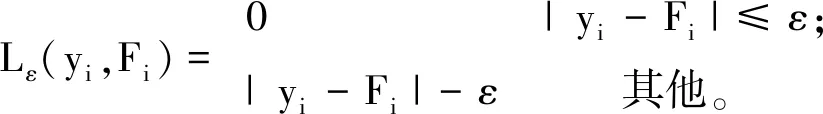
(16)
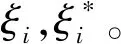
(17)
(18)
式(14)可考慮非線性回歸的情況、特征空間的映射以及添加拉格朗日乘子轉換為以下形式:
(19)
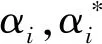
(20)
最常用的核函數是RBF函數,其定義如下:
(21)
其中γ表示RBF函數的寬度,γ值越大映射的維度越高,訓練的結果越好,但是容易引起過擬合,即泛化能力低。
2.2.2 模型參數尋優方法
1)粒子群優化算法。
粒子群優化算法(PSO)由Kennedy和Eberhart[18]在1995年受到鳥類捕食的啟發而設計一種無質量的粒子來模擬鳥群的群聚行為。粒子群優化算法是一種基于總體的并行全局搜索策略,它具有更快的收斂速度,在解決大量維數問題的方面具有優勢。在優化過程中,每個粒子都有自己的速度、位置和適應度。每次迭代,粒子會根據經過的單個最佳位置Pbest和全局最佳位置gbest來更新其速度和位置。對于維度為D的第i個粒子其更新速度和位置的公式如下:
(22)
(23)
其中t是迭代數;c1,c2是學習因子;r1,r2是0到1之間的隨機數,ω是用于平衡全局和局部搜索的權重系數。
2)基于PSO優化SVR。
SVR的泛化能力在很大程度上取決于超參數,即懲罰因子C和核函數γ,但是通過先驗知識很難確定這些參數的適當值,且手動調整參數的過程非常耗時。為使模型評估更加準確可信,采用粒子群優化算法(PSO)對式(15)與式(21)中的C和γ參數進行尋優。
PSO-SVR參數優化算法流程圖如圖4所示。
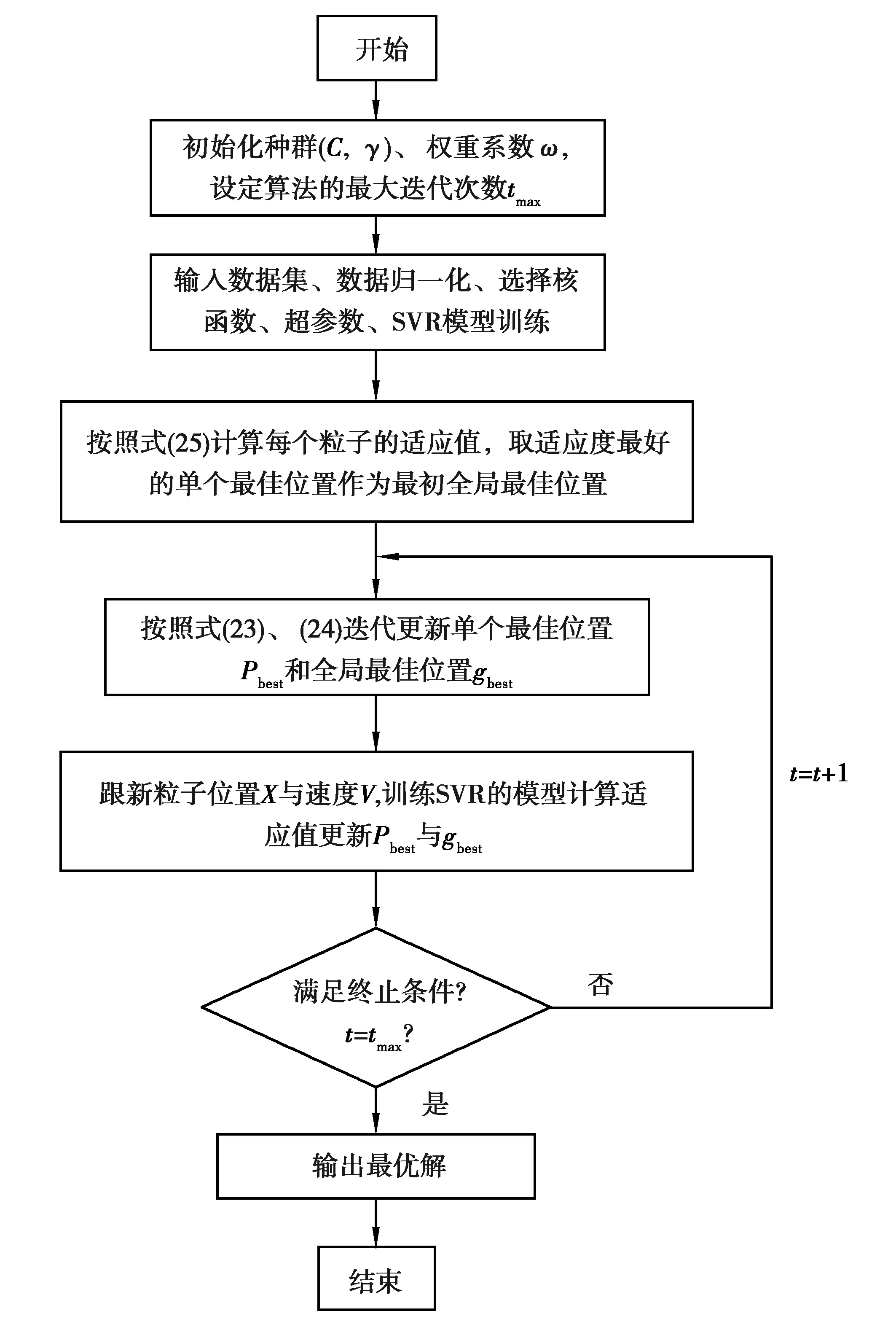
圖4 PSO-SVR參數優化算法流程圖Fig.4 Process of PSO-SVR parameter optimization algorithm
2.3 模型性能評估標準
為了評估文中模型性能,需應用不同評估標準,標準包括平均絕對誤差Wmae、均方差Wmse、平均絕對百分比誤差Wmape以及決定系數R2。
(24)
(25)
(26)
(27)
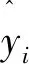
3 案例分析
3.1 實驗條件
本案例以重慶某公司退火爐車間為平臺,以重慶大學自主研發的退火爐實時狀態監控系統獲取加工任務和加工狀態信息。功率的實時監測通過HC-33D6L功率傳感器實現,溫度監測通過HC-208溫度采集模塊與K型熱電偶實現,分別采集退火爐的輸入功率、電流、爐內外溫度等信息,通過Modbus-RTU通信協議傳輸至智能終端。數據采集系統軟硬件平臺如圖5所示。

圖5 數據采集系統軟硬件平臺Fig.5 Software and hardware platform of the data acquisition system
3.2 實驗數據處理
實驗對象為間歇式爐,加熱工件為鋁絞線(BLVV),截面積120 mm2,長度9 000 m,工作時長10 h,采樣時長設置為2 min,采集獲得外界溫度Te、爐殼溫度Ts、3個加熱區的爐內溫度Tin、功率P、能耗E、3個加熱區的電流I,提取電流特征參數:方差Ivar、均方根Irms、峰峰值Iptp及偏度Iske,獲得數據整理表1、表2所示。
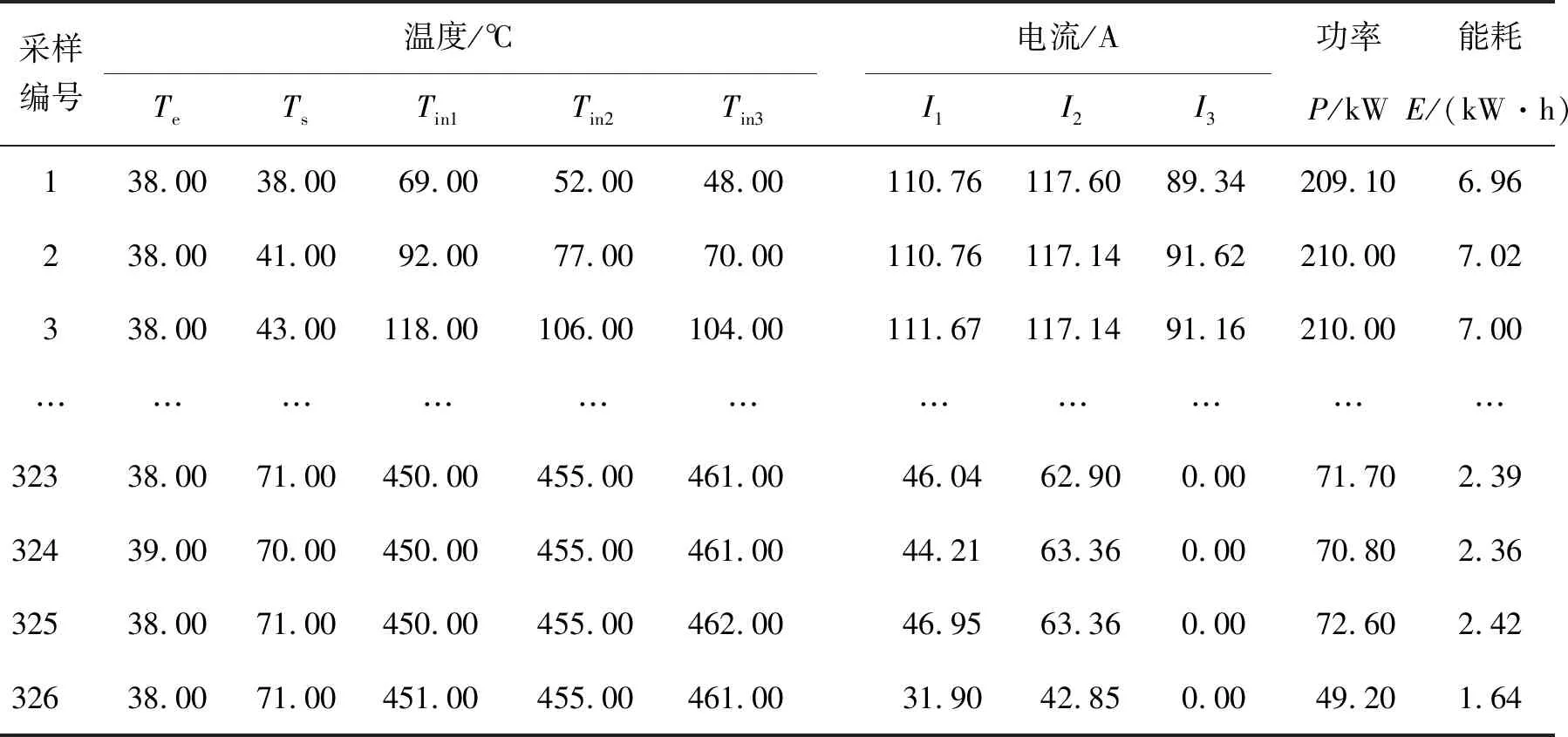
表1 電阻爐溫度、電流、能耗參數(2 min采樣時長)Table 1 Temperature, current and energy consumption parameters of the resistance furnace (2 min sampling time)
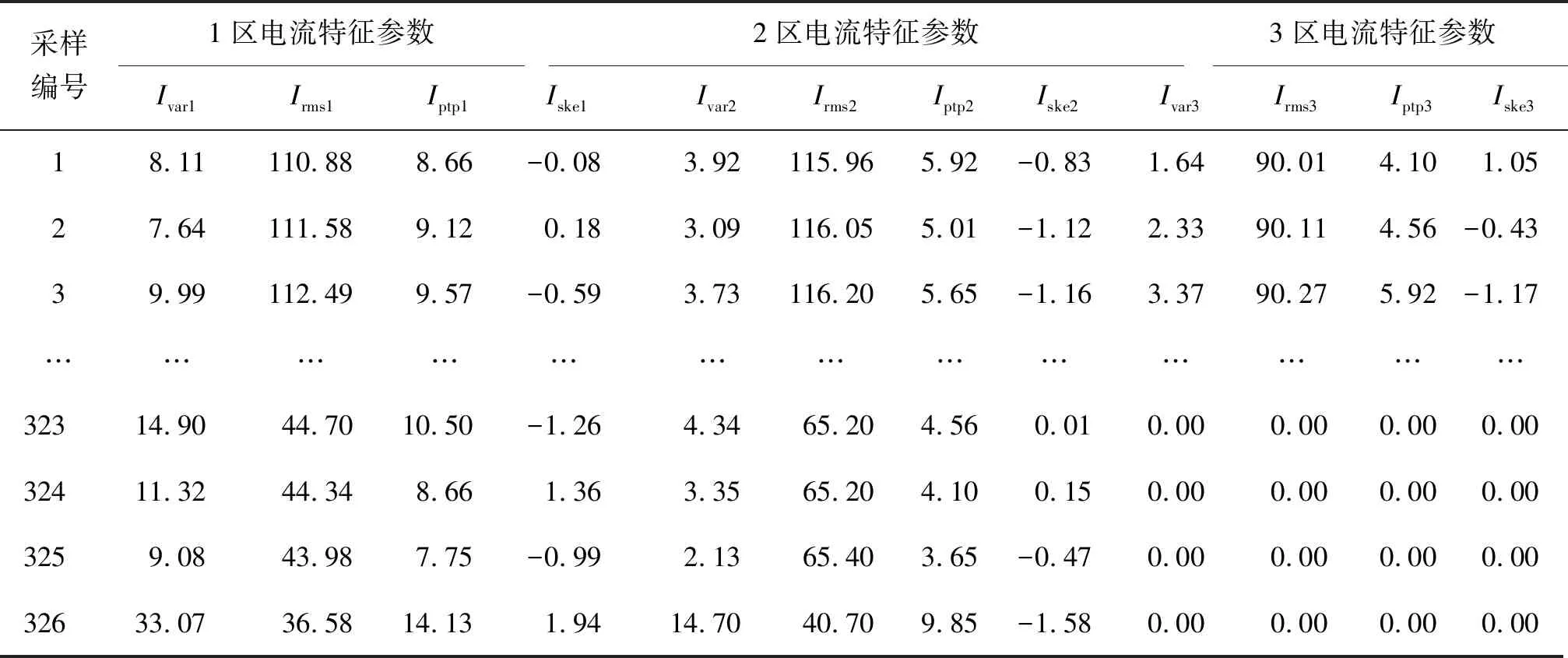
表2 電流特征參數Table 2 Characteristic parameters of the current
3.3 實驗驗證與結果對比
本次案例中共收集326組數據,使用交叉驗證法對訓練數據和測試數據進行劃分,其中訓練數據與測試數據的比例為3∶1。
1)多參數PSO-SVR、SVR、GPR、ANFIS模型對比。
高斯過程回歸(Gaussian process regression,GPR)和自適應模糊神經推理系統(adaptive network-based fuzzy inference system,ANFIS)是兩種常用的能耗預測算法。為驗證SVR算法效果,使用以上兩種建模方法與SVR進行對比分析。將表1中Te,Ts,3個加熱區的Tin、3個加熱區的電流I,P,E以及表2中電流特征參數:Ivar,Irms,Iptp,Iske,帶入集合{(xi,yi)}中,E作為輸出y,其余作為輸入x,導入PSO-SVR、SVR、GPR、ANFIS模型中得到測試集圖像對比圖,如圖6所示。
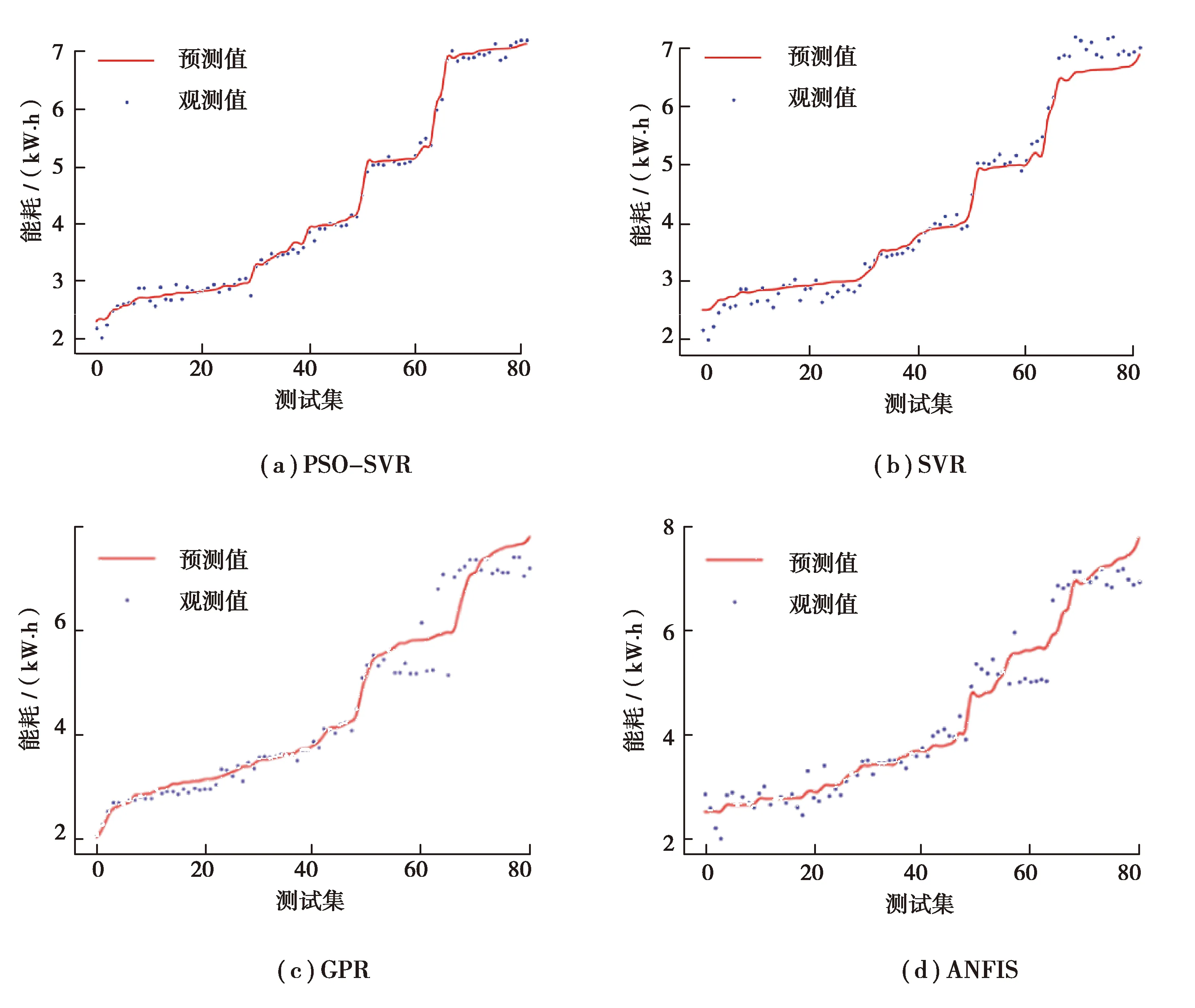
圖6 PSO-SVR、SVR、GPR、ANFIS預測結果對比Fig.6 Comparison of prediction results of PSO-SVR, SVR, GPR and ANFIS
3種預測模型訓練集與測試集評價指標如表3所示。
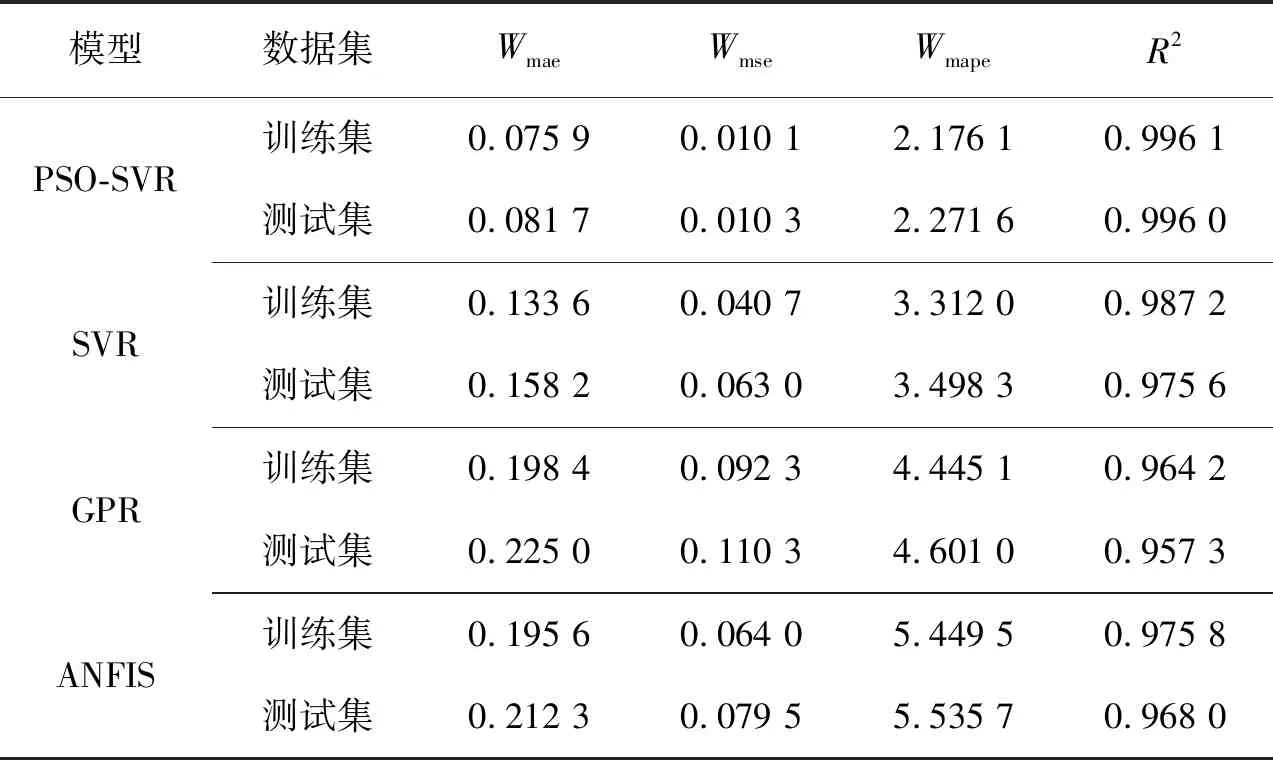
表3 3種預測模型訓練集與測試集評價指標對比Table 3 Comparison of evaluation indexes of three prediction models
由圖6、表3可知,PSO-SVR模型的評價指標均優于SVR、GPR、ANFIS模型,在測試集中PSO-SVR與SVR相比Wmae減少了48.46%,Wmse減少了83.65%,Wmape減少了35.06%,R2提高了2.09%。PSO-SVR、SVR、GPR、ANFIS模型中,GPR采用高斯核函數,模型對超參數的調優有一定要求;ANFIS采用自學習生成模糊規則的特點,難以準確表達函數關系,需要憑借專家經驗來手動調整模糊規則。實驗表明PSO-SVR模型的評價指標明顯優于SVR、GPR和ANFIS模型,因此,PSO優化下的SVR模型具有更高的精度、更好的泛化性和擬合能力。
2)單參數與多參數PSO-SVR模型對比。
將表1中的溫度、電流、功率分別帶入模型中得到預測結果與多參數模型對比,如圖7所示。
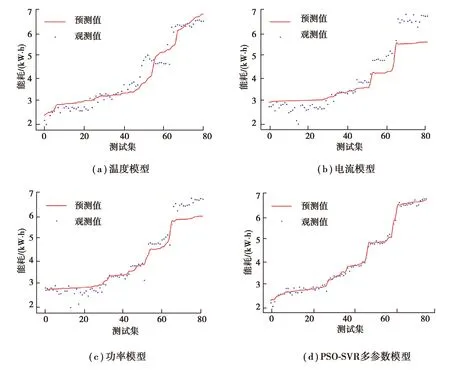
圖7 單參數與多參數模型預測結果對比Fig.7 Comparison of prediction results between single parameter model and multi-parameter model
3種預測模型訓練集與測試集評價指標如表4所示。
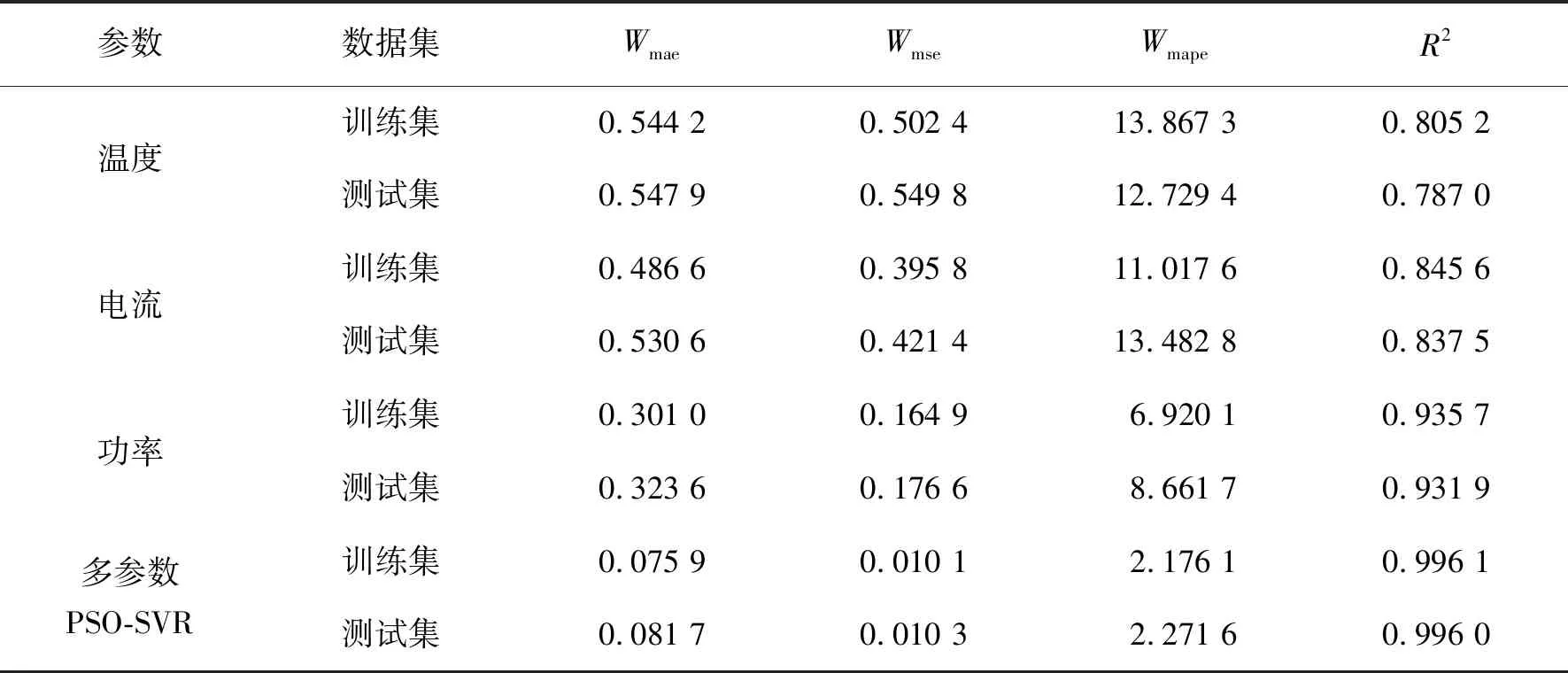
表4 單參數與多參數預測模型訓練集與測試集評價指標對比Table 4 Comparison of evaluation indexes of single parameter and multi-parameter model
由圖7、表4可知,電阻爐能耗受溫度、電流、功率等多種參數影響,模型精度與模型輸入數據維度成正相關,Wmae、Wmse、Wmape的多參數模型指標相比溫度、電流、功率建立的單參數模型指標明顯減小,R2也顯著增大。這是因為多參數預測模型的輸入是基于理論模型中的參數,再提取主要特征,能較好地表示輸入輸出向量的相關性,而單參數預測模型在非線性、大慣性的時變系統中擬合性能較差。因此,多參數模型各項評價指標均優于單參數模型指標,基于數據驅動的電阻爐多參數能耗預測模型比單參數預測模型有更高的精度和更好的泛化性。
3)數據驅動模型與理論模型對比。
根據公式(12)基于功率和時間信息建立退火爐工作的理論能耗模型,各個評價指標如表5所示。

表5 PSO-SVR多參數數據驅動模型與理論模型評價指標對比Table 5 Comparison of evaluation indexes between PSO-SVR multi-parameters data driven model and theoretical model
從表5中可知,理論模型的各項評價指標均低于數據驅動建立的PSO-SVR模型。理論模型是基于功率、時間建模,建模因素單一,并且理論模型中的功率為瞬時功率,其大小受到瞬時電流、加熱電阻阻值、對流換熱等多種因素影響,導致建立的模型精度較低,只能在一段時間內粗略預估電阻爐的能耗,而基于數據驅動下的多參數模型輸入根據實際系統的實驗分析獲得,克服了理論建模精度不高的缺點,能實時追蹤電阻爐工作狀態,實現電阻爐能耗的動態預測。
4 結 論
1) 分析了工業電阻爐各個加工階段的工作狀態,結合電阻爐的特征,基于功率、時間建立了理論能耗模型。
2) 根據所測得環境溫度、爐外表溫度、爐內溫度、功率、電流、以及提取的電流特征向量,建立了PSO-SVR、SVR、GPR及ANFIS能耗預測模型,通過Wmae、Wmse、Wmape以及R2指標分析,證明基于數據驅動下的PSO-SVR多參數能耗預測模型具有更高的精度和更好的泛化性。
3) 對比理論能耗模型與數據驅動多參數模型的各項評價指標,實驗表明數據驅動的多參數模型具有實時系統的分析能力,能反映電阻爐的實時工作狀態,提供可靠的動態能耗預測數據,為優化退火工藝、電爐的檢修或更改生產計劃提供詳細的數據支持。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
