基于DTW 和CNN的仿真駕駛手勢識別及交互
2021-03-22 04:26:56楊尊儉張淑軍
重慶理工大學學報(自然科學) 2021年2期
楊尊儉,張淑軍
(青島科技大學 信息科學技術學院,山東 青島 266061)
手勢是非語言交流的重要方式,也是非接觸式的人機交互中的重點研究課題。其在各個領域取得了廣泛的應用,如汽車自動駕駛過程中需要能夠識別交警手勢并做出正確響應,基于手勢交互的車輛控制[1]、智能教學[2],基于手勢的機器人控制[3-4]、3D模型控制等[5]。其中手勢的識別速度和精準度是研究和應用的關鍵。
非接觸式交互設備的出現,如Kinect、Leap Motion、HTC VIVE等,推動了基于手勢的交互技術的進一步發展。Shotton等[6]從Kinect提供的深度數據中評估出3D關節點的位置,為人體動作識別提供了重要的數據基礎。傳統的手勢識別主要通過數字圖像處理的方式對手勢進行跟蹤、分割等處理,對圖像進行分類。以骨架研究分為兩大類[7]:一種是將骨架用點來表示,對點的信息進行分析處理;另一種則是將部分骨架表示為剛體片段進行分析[8]。曹國強等[9]使用動態時間規整(dynamic time warping,DTW)與樸素貝葉斯分類(naive bayes classification,NBC)相結合進行模板訓練與匹配的方法,對手勢進行分類。石祥濱等[10]通過K-均值聚類算法提取視頻序列中關鍵幀的關節點位置和人體剛體部分之間的骨架角度來對動作序列分類。Ju等[11]結合RGB-D顏色空間的最大期望對Kinect捕獲的手勢進行分割。王鑫等[12]用LE(laplacian eigenmaps)流形學習對Kinect設備獲取的人體關節點信息進行降維運算,提取特征。
隨著卷積神經網絡(convolutional neural networks,CNN)的提出,基于深度學習的識別方法得到了迅速發展。Sanchez-Riera等[13]使用Kinect進行數據采集,利用深度學習方法對手勢的運行軌跡進行姿勢和方向上的評估。Dardas等[14]對圖像進行尺度不變性特征變換特征提取,使用多分類支持向量機(SVM)進行手勢識別。
本文以仿真駕駛為背景,提出了一種結合DTW 與深度學習的手勢識別技術,使用Kinect進行數據采集,以無人車在城市中行駛為背景,利用Unity進行場景搭建及定義交互事件,構建無人車駕駛仿真交互系統。
1 方法概述
在無人車行駛中,車輛的行進方向與行進速度是研究的關鍵。車輛需要對交警手勢、用戶自定義手勢等做出及時的反饋,以保證智能化行進。本文提出改進的DTW 算法與卷積神經網絡相結合的識別方法應用于無人車駕駛,并通過虛擬現實技術對其進行模擬仿真。系統流程如圖1所示。
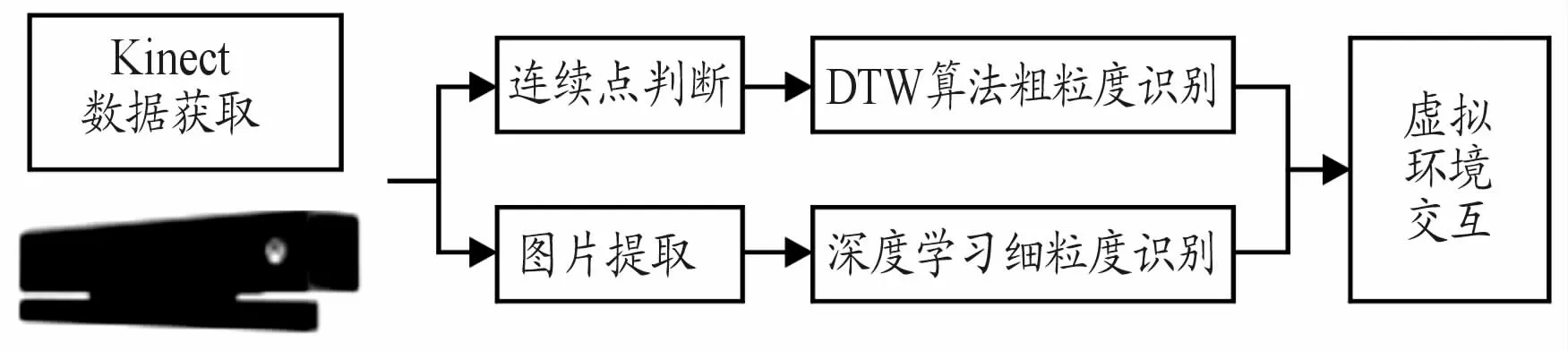
圖1 系統流程框圖
通常的手勢交互以上肢動作為主,識別需要做到實時才具有可用性。同一個人多次做相同手勢和不同的人做相同的手勢,手勢的速度和細節都存在差異,因此,適合使用DTW 算法進行識別。又考慮到在識別過程中,不同關節點貢獻率不同,所以本文提出了一種加權的DTW 算法,對手勢進行粗粒度識別。由于背景光照、顏色、遮擋等各種客觀因素影響,部分手勢在RGB圖像中比較模糊,使用傳統方法穩定性和魯棒性較差。為此,本文使用基于卷積神經網絡的手勢識別方法與DTW算法相結合,充分利用Kinect提取的關節點信息對手進行局部聚焦,同時識別上肢粗粒度手勢及手部細粒度語義,提高識別的速度與準確率。
本文通過Kinect獲取用戶的實時圖像并進行人體識別獲取關節點信息,改進的DTW 算法利用關節點信息進行特征向量的提取和匹配,對手勢進行粗粒度識別。基于深度學習的方法使用CNN網絡對手勢圖像進行細粒度識別。在仿真駕駛系統中,粗粒度識別結果決定汽車的行駛方向,細粒度識別結果對行駛速度等進行控制,2種方式同時作用,實現虛擬環境與用戶的實時無縫虛實交互。
2 基于K inect的人體關節點提取
Kinect由RGB攝像頭獲取彩色圖像,由紅外線發射器和紅外攝像機配合獲取深度圖像。紅外線發射器作為光源將結構光打在物體上,形成激光散斑,而紅外攝像機作為接收器,對這些激光散斑進行標定,計算得到深度數據,最后使用插值算法得到場景的三維數據。
Kinect獲取人體關節點的過程包括3個步驟:前景提取、人體骨骼分類和關節點定位。前景提取通過深度圖像上的深度信息,設置相應的閾值提取目標主體和形狀。人體骨骼分類用機器學習的算法對提取的形狀信息進行訓練,訓練出決策樹分類器依據形狀信息來匹配人體的各個部位。最后通過計算來匹配關節點在人體中的位置。
Kinect傳感器數據采集標準:Kinect設備水平放置于桌面上,目標面對Kinect傳感器,距離為0.8~2.5 m。獲取的彩色圖像與深度圖像分辨率均為640*480,幀頻為30 fps。傳感器使用的三維坐標為:以Kinect為原點,通過右手定則建立空間坐標系,x軸的正方向為水平向左,y軸的正方向垂直向上,z軸方向為攝像頭拍攝方向。三維空間坐標使用(x,y,z)表示,如圖2所示。

圖2 Kinect空間坐標系
通過Shotton等[6]提出的方法從深度圖像中提取人體25個關節點,如圖3所示。

圖3 Kinect25個關節點示意圖
從圖3中可以看出,左右雙臂和雙手各有不同的關節點,這為后續識別左側或右側手勢提供了有利的數據支持。
3 基于加權的DTW 算法識別粗粒度手勢
3.1 動態時間規整(DTW)
DTW 方法是Sakoe等[15]提出用于判斷時間序列相似性的方法。DTW 可以很好地匹配2個不同時間軸上的時序序列之間的匹配代價[16]。
基于DTW 的手勢識別主要分為3個步驟:建立樣本庫、訓練樣本、識別樣本。在識別時首先截取部分手勢幀作為測試樣本,然后與樣本庫中的樣本進行對比,找出與之最匹配的樣本。手勢樣本庫中的樣本表示為R={R(1),R(2),…,R(m),…,R(M)},測試樣本為T={T(1),T(2),…,T(n),…,T(N)},其中m和n為樣本幀的序號,R(m)為第m幀的動作特征矢量,T(n)為第n幀的動作特征矢量,M、N為模板中所包含的動作總幀數。構建一個M×N的矩陣,樣本庫樣本R為橫軸,測試樣本T為豎軸。將測試動作矢量T(n)映射到樣本庫動作矢量R(m),這種映射關系表示為(Rm,Tn),計算二者映射后對應的歐幾里得距離,對R和T中所有對應項求和:
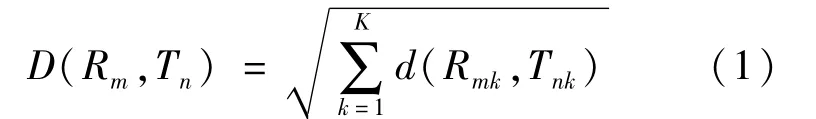
式中:K表示該幀特征向量的維數;Rmk表示樣本庫樣本的第m幀的第k個特征值;Tnk表示測試樣本的第n幀的第k個特征值。D越小說明測試樣本T與樣本庫樣本R相似度越大,D越大則相似度越小。
3.2 加權的DTW 方法
動態時間規整默認每個手勢的關節點在軌跡上的貢獻度是相同的,對樣本中的所有關節點使用相同處理標準,而在實際手勢中不同關節點的位移變化對手勢識別所起的作用并不相同,某些關節點起到決定性作用,因此,本文提出一種改進的DTW 算法,通過對關節點進行加權來進行更優的動態規劃,更精準地識別手勢。充分考慮各關節在上肢手勢中所起的作用,選取頸椎中部(1)、左肩(4)、左肘(5)、左手腕(6)、右肩(8)、右肘(9)、右手腕(10)、頸下脊椎(20)等8個關節(括號中的數字對應圖3中的關節點編號)用于連續手勢識別,可有效減少運算的復雜度。每一個關節由一個三維坐標表示,因此,一幀骨骼數據可以表示為由8個關節點坐標組成的24維的動作矢量:
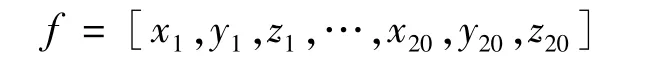
人與攝像頭之間的位置以及骨架的大小等都會造成關節坐標的改變,因此需要對關節坐標進行預處理。以人體頸椎關節為原點,將坐標系平移到人體,并以脊柱的距離作為標準,分別對各關節坐標進行標準化,以消除干擾因素的影響,獲得較為標準的關節數據。根據中國成年人人體尺寸(GB/T 10000—1988),以雙臂平伸站立姿態,左肘(5)、左手腕(6)、右肘(9)、右手腕(10)關節點到頸椎中部(1)、左肩(4)、右肩(8)、頸下脊椎(20)4點中心的距離作為權重標準,如左肘的權重為:
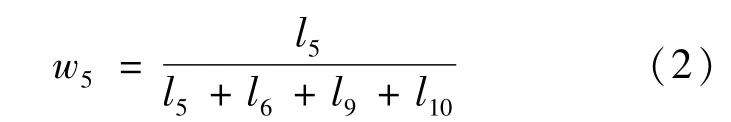
l為關節點到中心的距離,整體匹配代價如式(3)所示:
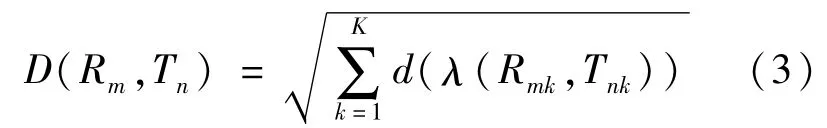
其中λ={wi},通過加權后的手勢序列匹配,對大幅度手勢動作得到識別結果。
4 基于深度學習方法識別細粒度手勢
DTW 算法能夠完成2個手勢序列的整體匹配,但對于手部的細節動作識別不夠準確,為此,本文采用基于深度學習的方法對動態手勢中的手部語義進行細粒度識別。深度學習方法已成功應用于圖像識別領域,并且具有較好的穩定性和魯棒性。
4.1 卷積神經網絡(CNN)
卷積神經網絡(convolutional neural network,CNN)由輸入層、卷積層、池化層、全連接層以及輸出層組成。一般有若干卷積層與池化層交替設置,卷積層的每個節點通過卷積核與上一層局部信息相連,卷積的結果經過激活函數得到該層特征圖;池化層中的每個特征面與上一層的一個特征面對應,對特征信息稀疏處理,獲取具有空間不變行的特征;在全連接層中,每個節點與上一層的節點全連接,整合卷積層和池化層中具有區分性的信息;在輸出層,通過Softmax分類器處理后的數據按概率返回分類結果。
4.2 手部ROI的計算
要想通過手部動作表達不同的語義,必須要對手部進行準確的定位和識別。傳統方法對復雜背景中的手分割和識別效果較差,本文通過Kinect提取的手部關節點來定位手部ROI,使用7層的CNN對手部圖像進行識別。
在Kinect獲取的25個關節點中,手部的關節點位一共有8個,左右手各4個,分別為腕、手、拇指和指尖,根據這4個關節點與手整體位置之間的關系,4個點的質心即可作為手部ROI的中心點,而ROI的邊長設定為人體前臂的長度,以保證手部區域的完整性。人體前臂的長度L可通過手肘到手腕的距離來計算:
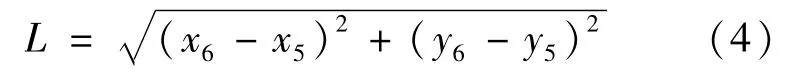
式中,(x5,y5)與(x6,y6)分別表示圖3中編號為5的關節點ElbowL以及編號為6的關節點WristL當前幀的坐標值。不同手勢情況下手部ROI的部分計算結果如圖4所示。

圖4 手部ROI的計算結果
4.3 基于CNN對手部ROI進行訓練和識別
本文使用的CNN模型分為輸入層、卷積層、池化層、全連接層和輸出層。對提取的ROI手部圖像進行歸一化處理,得到90×90大小的圖片,將其輸入到CNN網絡中。歸一化尺寸的選取是根據實驗中多次采集到圖像的統計結果確定的。7層卷積神經網絡對輸入圖像進行特征提取和采樣,再送入全連接層,最后通過Softmax函數得到分類結果,如圖5所示。
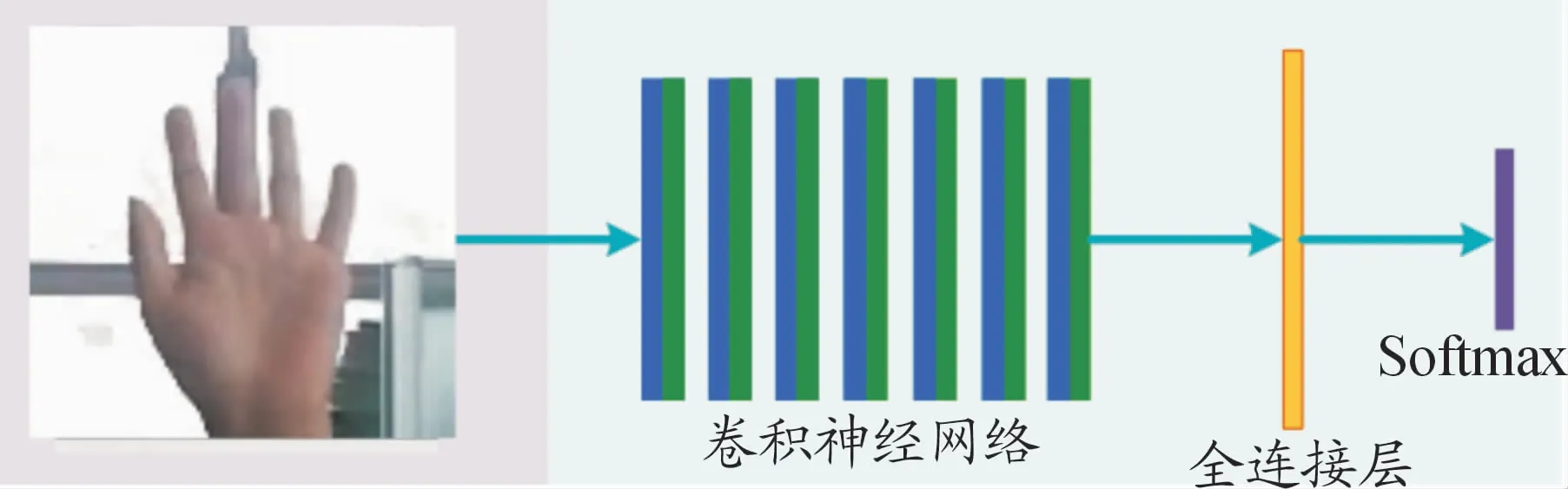
圖5 基于CNN進行手勢識別的分類結果
5 實驗結果與分析
實驗環境:采用Unity3.6.1f1建立仿真駕駛環境,使用Kinect采集用戶信息,通過手勢識別與虛擬環境進行自然交互。軟硬件配置如表1所示。
5.1 系統建模與界面
本文使用3DMax創建虛擬環境中的模型,導出為FBX場景文件,并在Unity中導入到Scene中,調整好度量單位、燈光、動畫、嵌入媒體以及骨骼幾何體等,保證導出的場景中包含所有模型的元素,在Unity-Scene中對模型進行合理布局。
所有的貼圖文件在Assets-Material文件夾中保存,FBX等模型文件在Models中保存,在導入好的模型的Inspector視圖中通過“Add Component”查找“MeshCollider”,加入網格碰撞功能。
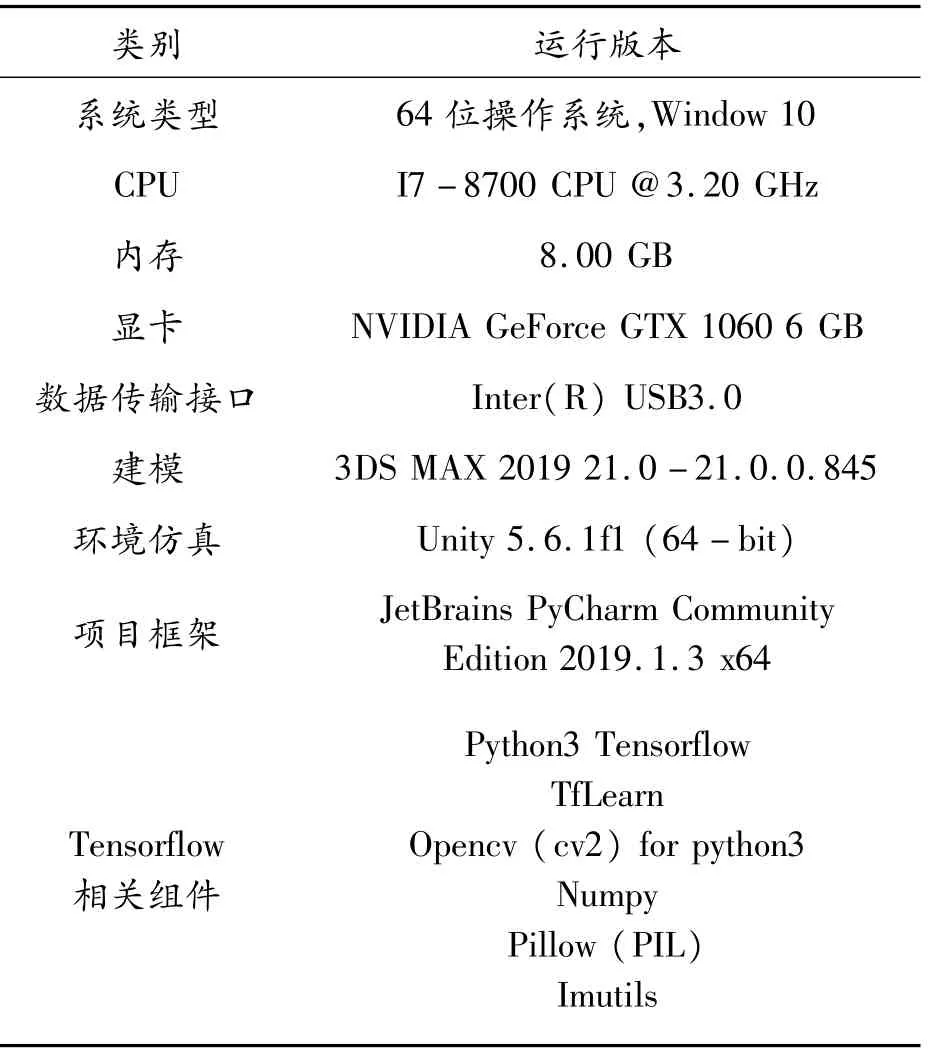
表1 軟硬件配置
Unity中車輛與場景模型通過坐標等修改使得輪胎與道路路面接觸,設置好車輛動力學特性、重力場、觸發器和碰撞器的檢測等各項技術參數,讓車輛模型能夠與場景的物體進行實時檢測。
構建了一個包含道路、車輛、交通信號燈、建筑物、樹木等在內的虛擬城市場景,系統交互界面如圖6所示。
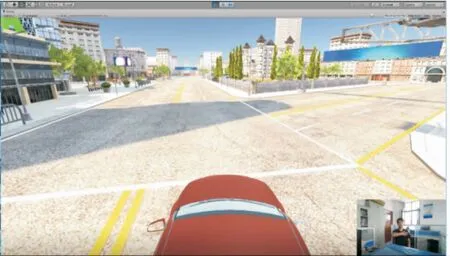
圖6 系統交互界面
5.2 手勢及交互效果定義
為了在虛擬環境中更好地展現無人車對手勢指令的反饋效果,定義5種動態手勢,分別控制無人車前進、停止、左轉彎、右轉彎、后退,同時為了交互控制汽車行駛速度,定義4種模式的手部動作,可以疊加在上述5種手勢過程中,構成復合手勢,使無人車同時在行駛方向和速度上有相應的反饋。手勢名稱及動作語義如表2所示。
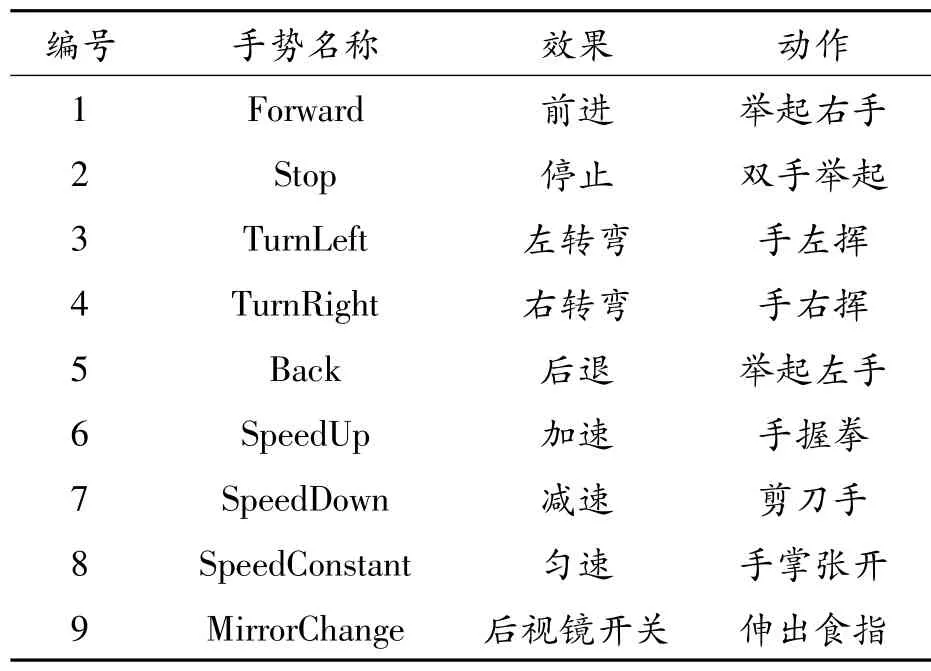
表2 手勢名稱及動作語義
表2中,手勢1—5由DTW 算法識別,手勢6—9由深度學習方法識別,二者組合,得到完整的手勢識別結果。手勢6—7中,每次識別之后速度按1個標準單位變化。
5.3 關節點數據分析
記錄實驗數據,以備后續數據分析。手勢數據按照關節點X、Y、Z軸分別存儲,以便于數據分析。表3給出了TurnRight手勢的右手腕關節點(編號為10)的坐標序列值。
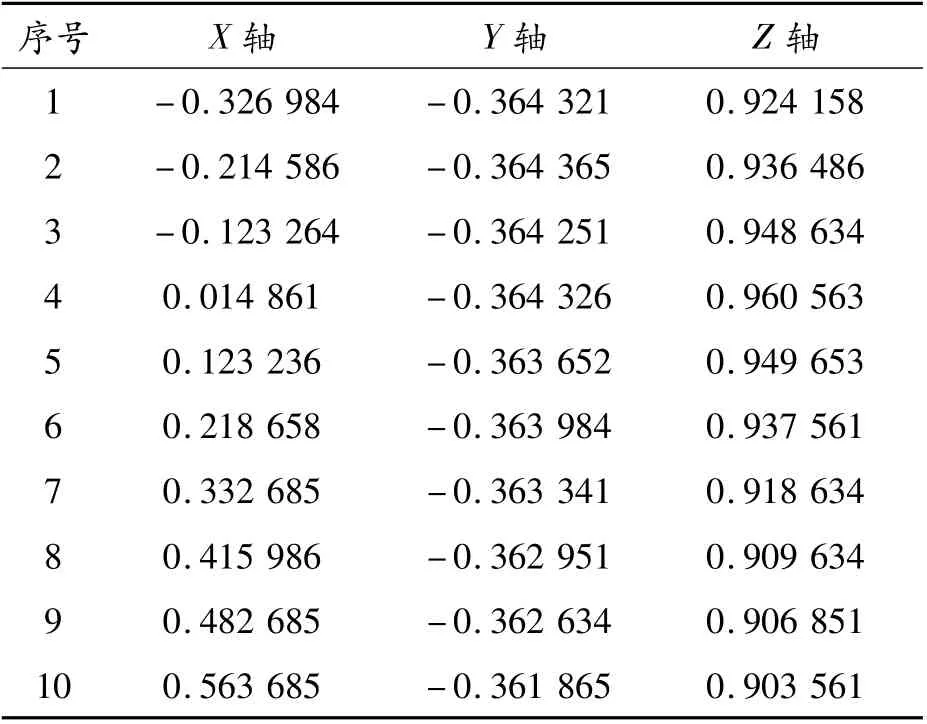
表3 TurnRight的右手腕(10)點坐標
由此可見,在TurnRight中,X軸數值逐漸上升,Y、Z軸無明顯變化。對于TurnRight,右手腕(10)關節點的X軸坐標影響較大,以此作為賦予權重依據。
5.4 基于深度學習的識別
該識別方法分為離線訓練與實時識別2個階段。離線訓練階段分為2個步驟:
1)數據集
數據集使用馬德里自治大學視頻處理與理解實驗室的HGDs數據集[17],選取其中的4種:手掌張開、手握拳、剪刀手和食指伸出。每種手勢200幅圖像。每類手勢按9∶1的比例分為訓練集與測試集,如圖7所示。

圖7 手勢數據集
2)訓練網絡模型
本網絡由7個帶有relu層的卷積層與一個全連接層組成,使用softmax作為分類器。加載在ImageNet上預訓練的網絡模型,在上述手勢數據集上進行訓練,batch_size=64,迭代次數為2 000次。在測試集上的最終識別準確率為96.6%。存儲該訓練參數模型用于實時識別階段。
5.5 手勢識別及虛實交互結果
對粗粒度和細粒度手勢識別的結果及虛擬車輛的交互反饋效果如圖8所示。
圖8(a)~(e)分別展示了舉起左手配剪刀手動作——汽車減速前進、舉起右手配拳頭動作——汽車加速后退、手左揮配手掌動作——汽車勻速左轉、手右揮配手掌動作——汽車勻速右轉、食指動作——后視鏡開關變化的交互效果。圖中左上角紅字為手勢識別結果,分別為DTW 算法識別結果(運動行進方向)、當前行駛速度、深度學習方法識別結果(速度或后視鏡變化)。

圖8 手勢識別及交互結果
為了進一步驗證本文方法的可行性,對每種手勢在仿真系統中測試其識別的精度,每種手勢分別測試100次,識別準確率如表4所示。
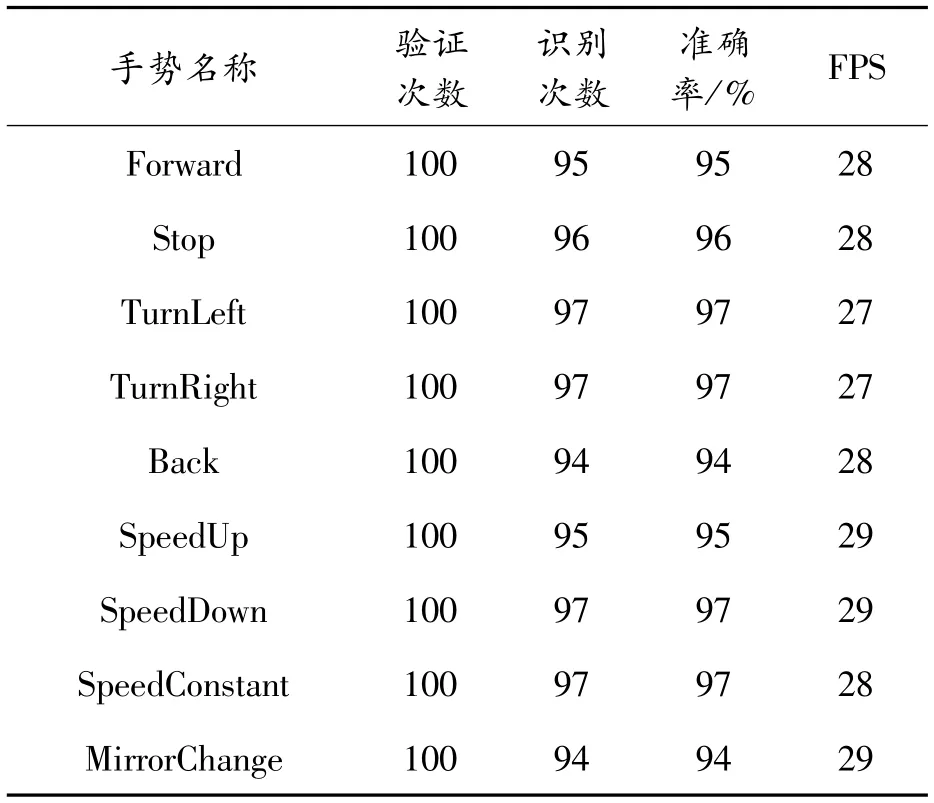
表4 實驗結果
實驗結果分析:從表4中可以看出SpeedUp和SpeedDown識別較為穩定,手部的左右移動識別較好,手部細粒度識別整體較好,行進方向控制的平均準確率為95.8%,平均FPS為27.6 Hz,行進速度控制平均準確率為95.75%,平均FPS為28.75 Hz,實驗表明本文提出的方法在無人車仿真中的有效性。
6 結論
隨著社會的進步,智慧城市的發展,汽車智能化與網聯化即將到來,無人車自動駕駛是重點研究項目。本文主要面向仿真駕駛場景,將改進的DTW 算法與卷積神經網絡方法相結合,對用戶的動態與靜態復合手勢進行實時識別,虛擬車輛根據識別結果進行交互反饋。
猜你喜歡
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
